A Survey On Entity Resolution by Query Driven Approach
SIVASANKARKUMAR GUBBALA
& NADELLA SUNIL
P G Student, Dept.Of M.Sc., Ideal College Of Arts & Science, East Godavari
Professor, Dept. Of M.Sc., Ideal College Of Arts & Science, East Godavari
Abstract: This paper explores “on-the-fly” data cleaning in the context of a user query. A novel Query-Driven Approach (QDA) is developed that performs a minimal number of cleaning steps that are only necessary to answer a given selection query correctly. The comprehensive empirical evaluation of the proposed approach demonstrates its significant advantage in terms of efficiency over traditional techniques for querydriven applications.
Keywords: Query-driven approach, QDA, query-aware, entity resolution, SQL selection queries.
1 Introduction
Organizations and administrative associations around the globe distribute a colossal volume of information, which can be put away in various information sources. Keeping in mind the end goal to get to and break down these information, systems for information combination are required. The point of information incorporation is to consolidate heterogeneous and self-ruling information hotspots for giving a solitary view to the client.
An imperative segment of the information coordination process is the Entity Resolution (ER) undertaking. The ER objective is to distinguish tuples alluding to the same real word element (in this work, tuple is synonymous of case and record). This issue is known by an assortment of names: Record Linkage, Entity Resolution, Object Reference, Reference Linkage, Duplicate Detection or Deduplication. In this paper, we receive the term Entity Resolution (ER).
procedures to help continuous ER for dynamic and extensive databases.
For instance, assume an arrangement of information wellsprings of bibliographic information and an inquiry to recover all papers from a given creator (e.g. "Getoor"). To answer this inquiry, it isn't important to search for other creator's papers and to play out the ER thinking about the entire arrangement of papers. For this situation, it is smarter to concentrate on the tuples depicting just papers from the creator indicated in the question.
In this paper, we propose a Query-Driven and Incremental process for Entity Resolution (QuID). The QuID procedure considers question comes about on various information sources. It is an incremental procedure, i.e., for each new question result, QuID reuses the past ER bunch to answer future inquiries. In our approach, ER is considered as a grouping issue, in which each bunch compares to tuples of a solitary certifiable element. Amid the ER, the aftereffects of inquiries are examined, and each tuple of the inquiry result is embedded incrementally in a bunch. Our answer holds a file for the tuples, and performs incremental bunching, bringing about groups of tuples that allude to a similar true substance. Whatever is left of the paper is sorted out as takes after. In Section 2 we examine related work. In Section 3 we formally characterize the issue and portray
the QuID procedure and in Section 4 we finish up.
2. RELATED WORK
Element determination is a notable issue and it has gotten noteworthy consideration in the writing in the course of recent decades. An exhaustive diagram of the current work around there can be found in overviews. We characterize the ER methods into two classes as take after: Generic ER. A run of the mill ER cycle comprises of a few periods of information changes that include: standardization, blocking, comparability calculation, grouping, and consolidating, which can be intermixed.
practices of substances, and outside learning bases, for example, ontologies and web indexes. The following ER stage is bunching where coordinating records are assembled together into groups. At last, the blending stage joins components of every individual bunch into a solitary record. On-the-fly coordinating methods have been proposed. The approach in answers inquiries on the whole utilizing a two-stage "extend and resolve" calculation. It recovers the related records for an inquiry utilizing two extension administrators, and afterward answers the question by just considering the removed records. A case of an inquiry is to recover all papers composed by creator 'J. Smith'. Not at all like our work, does that paper not considers upgrading for different kinds of choice inquiries, for example, run questions or questions where the sort of the condition property isn't a string.
Despite the fact that the ER system is likewise "on-the-fly", it tackles an alternate issue since it settle inquiries under information vulnerability by interfacing thoughts of record linkage and probabilistic databases. The term inquiry alludes to a mix of (quality name/esteem) sets and every element returned as an answer is joined by a likelihood that this substance will be chosen among every single conceivable world.
The creators handle element vulnerability at querytime for OLAP applications. Not at all like
our own, this work accept the presence of a record-to-bunch mapping table and its objective is to answer assemble by OLAP questions by returning outcomes as strict extents.
Note that the methodologies can't answer non specific determination questions like: select just very much refered to (e.g., with reference tally over 45) papers composed by 'J. Smith' – which is the essential concentration of our paper. That is, none of the current arrangements consider improving non specific SQL choice inquiries examined in our paper.
approaches, the procedure proposed in this paper is incremental and inquiry driven. To the best of our insight there are no different methodologies that consolidate these two highlights.
3 PROBLEM STATEMENTS
3.1 Problem Definition
Given an arrangement of tuples, the ER procedure is basically a bunching issue, in which each group contains tuples that speak to a solitary genuine element. In the event that we consider the ER issue in various information sources, each tuple can be from an alternate source. In this paper, our attention is on incremental bunching calculations. The objective of the incremental grouping approach is to influence the ER to process speedier than different procedures that don't utilize this system. The principle objective of utilizing the inquiry comes about is to decrease the volume of tuples. This system will likewise diminish the quantity of examinations made between tuples.
Formally, we denote S = {S1, S2, ..., Sn} a set of data sources and Q = {Q1, Q2, ..., Qm} a set of queries running on S. Each source has a set of entities Si .E, where E = {E1, E2, ...,Ew}. Each entity Ejfrom Si .E has a set of tuples Si .Ej .T = {t1, t2, ...,tn}, where each tp is an instance of the entity Ej . A tuple tp is defined as follows.
Definition 1: Each tuple tp belonging to Si .Ej .T, is represented by a set of pairs of attributes (Ak) and values (vk), tp= {(Si,Ej,A1,v1),(Si,Ej,A2,v2), …, (Si,Ej,An,vn)}. Each attribute Ak belongs to an entity (Ej ) of a data source (Si ), denoted by Si .Ej .Ak. Each tuple tp has a pair (Si,Ej,Ak,vk), which represents a single identifier of the tuple (Id).
An inquiry Qi may not contain every one of the qualities essential (important) to characterize whether two tuples speak to a similar genuine element. In this manner, the question is submitted to an extension procedure for gathering the pertinent qualities [8] that were not educated in the underlying inquiry. This extension produces an inquiry Qi '. The contribution of the QuID procedure is the consequence of the inquiry Qi ', characterized as follows.
Definition 2: A query result, Qi ’.R, is represented by a set of tuples (Definition 1) that belongs to an entity Ej. . The attributes that describes the tuples of the result Qi ’.R includes the set of relevant attributes (Ar ), Si.Ej.Ar , where Si.Ej.Ar⊆Si.Ej.A. For each new received query result, the ER process reuses the results of previous ER tasks, i.e., previous generated clusters, to respond the query.
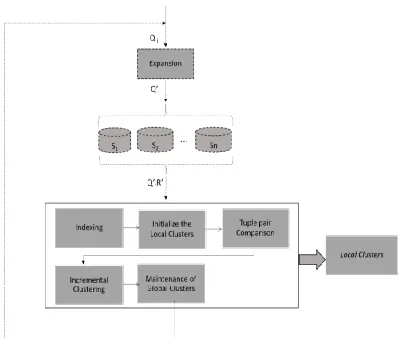
In this area, we portray the proposed procedure (QuID). Fig. 1 demonstrates the stream of data in QuID. The contribution of the procedure is an inquiry result (Q'i .R'). The procedure begins with the Indexing step, which expects to lessen the quantity of examinations between sets of tuples. Amid this progression, two lists are utilized: the Similarity Index and the Cluster Index. The first keeps up incrementally the closeness esteems between each combine of tuples. The second one keeps up incrementally an arrangement of bunches of tuples identifiers.
Fig. 1. Proposed process (QuID)
Our approach, utilizes two sorts of bunches: worldwide groups and neighborhood bunches. Worldwide Clusters (Gc) are made just once and refreshed, incrementally, at each inquiry result Qi '.R'. A Gc offers support to the inquiry driven process reusing past outcomes in future questions. A worldwide group is characterized in the accompanying.
Definition 3: A Global Cluster (Gc) is defined by a set of triples, Gc={(ClusterId, Si.Ej,Si.Ej.tp.Id)}, where ClusterId is an
identifier of the cluster, Si.Ej is the entity and the data source of the tuple tp and Si.Ej.tp.Id is the tuple identifier.
Local Clusters (Lc) are created for each query result Qi ’.R’. The output of the ER process is the Lc containing the duplicated tuples detected in the query result. Lc will use previously classified information from the global cluster Gc. We define local cluster as follows.
Definition 4: A Local Cluster (Lc) is defined by a set of pairs, Lc={(Si.Ej.tk,ClusterId)}, where Si.Ej.tk is a tuple and ClusterId is the identifier of the cluster which the tuple belongs to.
After the Indexing step, the nearby group (Lc) is instated from Gc, reusing the aftereffects of past ER assignments. After the introduction of Lc, the tuples not prepared already will be handled amid the Tuple Pair Comparison step. In this progression, similitude esteems are recouped from the Similarity Index, or new closeness esteems between two tuples are computed.
objective of the Incremental Clustering is to embed into the nearby bunch (Lc) and worldwide group (Gc) the tuples not handled some time recently. At last, after the Incremental Clustering, the yield of QuID is Lc and Gc as of now refreshed for reuse in the following ER assignments.
4 CONCLUSIONS
In this paper, we have studied the Query-Driven Entity Resolution problem in which data is cleaned “on-the-fly” in the context of a query. We have developed a query-driven entity resolution framework which efficiently issues the minimal number of cleaning steps solely needed to accurately answer the given selection query. We formalized the problem of query-driven ER and showed empirically how certain cleaning steps can be avoided based on the nature of the query. This research opens several interesting directions for future investigation. While selection queries (as studied in this paper) are an important class of queries on their own, developing QDA techniques for other types of queries (e.g., joins) is an interesting direction for future work. Another direction is developing solutions for efficient maintenance of a database state for subsequent querying.
REFERENCES
1. Lenzerini, M. Ontology-based Data Management. In: international conference on
Information and knowledge management (CIKM’11). New York, NY, USA, pp. 5-6, 2011.
2. Christen, P. Data Matching: Concepts and Techniques for Record Linkage, Entity Resolution, and Duplicate Detection. Springer. 2012.
3. Gruenheid, A.; Dong, X. L.; Srivastava, D. Incremental Record Linkage. In: VLDB’2014. Hangzhou, China. 2014.
4. Bhattacharya, I., Getoor, L. Query-time Entity Resolution. Journal of Artificial Intelligence Reserche. 2007.
5. Altwaijry, H., Kalashnikov, D. D., Mehrotra, S. Query-Driven Approach to Entity Resolution. VLDB 2013, Italy. 2013.
6. Su, W., Wang, J., Lochovsky, F, H. Record Matching Over Query Results from Multiple Web Databases. IEEE Transactions on Knowledge and Data Engineering. Vol. 22, No. 4. 2010.
7. Berkhin, P. A Survey of Clustering Data Mining Techniques. Grouping Multidimensional Data: Recent Advances in Clustering. Pp 25 – 71. Springer Berlin Heidelberg. 2006.
9] Z. Chen, D. V. Kalashnikov, and S. Mehrotra. Exploiting context analysis for combining multiple entity resolution systems. In SIGMOD, pp. 207–218, 2009.
[10] M. Hernandez and S. Stolfo. The merge/purge problem for large databases. In SIGMOD, pp. 127–138, 1995.
[11] X. Dong, A. Halevy, and J. Madhavan. Reference reconciliation in complex information spaces. In SIGMOD, pp. 85–96, 2005.
[12] E. Elmacioglu, M.-Y. Kan, D. Lee, and Y. Zhang. Web based linkage. In WIDM, pp. 121– 128, 2007.
[13] A. Elmagarmid, P. Ipeirotis, and V. Verykios. Duplicate record detection: A survey. In KDE, pp. 1-16, 2007
[14] W. Fan, X. Jia, J. Lo, and S. Ma. Reasoning about record matching rules. In VLDB, pp. 407-418, 2009.
[15] I. P. Fellegi and A. B. Sunter. A theory for record linkage. In JASA, pp. 1183-1210, 1969.
[16] E. Ioannou, W. Nejdl, C. Nieder´ee, and Y. Velegrakis. On-the-fly entity-aware query processing in the presence of linkage. In VLDB End., pp. 429–438, 2010.
[17] Y. Sismanis, L. Wang, A. Fuxman, P. J. Haas, and B. Reinwald Resolution-aware query
answering for business intelligence. In ICDE, pp. 976–987, 2009
SIVASANKARKUMAR GUBBALA is current pursuing M.Sc. (Computer Science) in M.Sc. dept., Of Ideal College of Arts & Science, Kakinada, A.P
NADELLA SUNIL
M.Sc.,M.Tech.,M.Phil.,P.G.D.C.S.,(PhD)
Working as Associate Professor in
P.G.Department of Computer Science, IDEAL COLLEGE OF ARTS & SCIENCES, Kakinada, AP
QUALIFICATIONS
(PhD) Computer Science
JNTU,
Kakinada
M.Tech (Computer Science &
Engineering)
JNTU,
Kakinada
M.Phil (Applied Mathematics)
ANDHRA UNIVERSITY
M.Sc (Applied Mathematics)
ANDHRA UNIVERSITY
PGDCS HYDERABAD CENTRAL
UNIVERSITY
SET Computer Science and
Applications
ACHIEVEMENTS
Gold medalist from Andhra University in
Applied Mathematics at Post Graduation level.
Topper in Andhra University at Post
Graduation level(M.Sc.,) in Applied Mathematics.
Stood topper in M.Tech(CSE)., in
University College of Engineering in JNTU Kakinada
SET (Mathematical Sciences)
SET (Computer Science and Applications)
AWARDS RECEIVED
UNIVERSITY FIRST IN M.Sc.,(APLLIED MATHEMATICS)IN 1998-2000
Prof.I.VENKATA RAYUDU SHASTABDI POORTI GOLD MEDAL
APPLIED MATHEMATICS PRIZE T.S.R.K.MURTHY SHASTABDI