ZHANG, QING. Microdata Privacy Protection Through Permutation-Based Approaches. (Under the direction of Professor Ting Yu and Professor Munindar P. Singh).
Data analysts often prefer access to data in the form of original tuples(i.e., microdata), instead of pre-aggregated statistics, since the former offers advantages in information flexibility and availability. Two problems should be addressed before releasing microdata. First, individual’s privacy needs to be adequately protected. In general, the data will be anonymized before shar-ing. Second, the utility of the anonymized microdata should be maintained and common aggregate queries should be answered with reasonable accuracy.
Most existing works on microdata anonymization are based on attribute generalization. Though popular, these approaches have limitations: the generalization of attributes make it difficult to answer typical aggregate queries with reasonable accuracy.
by
Zhang, Qing
A dissertation submitted to the Graduate Faculty of North Carolina State University
in partial fullfillment of the requirements for the Degree of
Doctor of Philosophy
Operations Research and Computer Science
Raleigh, North Carolina
2008
APPROVED BY:
Dr. Peng Ning Dr. Rada Chirkova
Dr. Munindar P. Singh Dr. Ting Yu
DEDICATION
To my parentsQingan Zhang and Jurong Yang my beloved wifeQian Zheng
and
BIOGRAPHY
ACKNOWLEDGMENTS
This dissertation would not be possible without the support and help from many profes-sors, friends, and my family members over many years.
First, I would like to thank my advisor Dr. Ting Yu. I feel very fortunate to have such a great advisor like you for my Ph.D study. Thank you for your patience, insightful suggestions, financial support and unending encouragement during my Ph.D research. Additionally, I would like to thank my co-advisor Dr. Munindar Singh, for your guidance and suggestions to my research. I would also like to thank my committee members Dr. Peng Ning and Dr. Rada Chirkova, for your valuable feedback and comments on my research.
I would like to thank Dr. Divesh Srivastava and Dr. Graham Cormode from AT&T - Labs Research, and Dr. Nick Koudas from University of Toronto. It has been an honor to work with you. And I have learned so much from our collaborations. The time I spent as a summer intern at AT&T labs in 2007 will always be a precious memory in my life.
I would thank all my friends in the Cyber Defense Laboratory, for their help to my re-search, and the happy times spent together in the office: Vinod Arjun, Keith Irwin, An Liu, Dong-gang Liu, Pai Peng, Kun Sun, Pan Wang, Dingbang Xu, Yan Zhai, Qinghua Zhang, Yi Zhang. And I would like to thank my friend from the Operation Research program, for their help when I ini-tially when I came to the U.S., and the friendship that encourage me all the time during my study in NCSU: Gangshu Cai, Chuan Lin, Wei Wan, Meng Wang, Yong Wang, Xinmin Wu, Yufeng Xin, Xiaoqing Yang, Yipeng Yang, Zhe Zhang, Wei Zhang, Jie Zhong, Xiang Zhou.
TABLE OF CONTENTS
LIST OF TABLES . . . viii
LIST OF FIGURES . . . ix
1 Introduction . . . 1
1.1 Privacy-Preserving Data Sharing . . . 1
1.2 Scope of The Research . . . 3
1.2.1 Data model . . . 4
1.2.2 Publishing model . . . 4
1.2.3 Query model . . . 5
1.2.4 Privacy model . . . 5
1.2.5 Attack model . . . 5
1.3 Contributions . . . 6
1.4 Dissertation Outline . . . 7
2 Anonymizing Numerical data . . . 8
2.1 Motivation . . . 8
2.2 Example . . . 9
2.3 Preliminaries . . . 14
2.3.1 Privacy in the Release of Microdata . . . 14
2.3.2 Anonymization Through Generalization . . . 16
2.4 Anonymization Through Permutation . . . 17
2.5 Aggregate Query Answering . . . 19
2.5.1 Lower and Upper Bounds . . . 19
2.5.2 Auxiliary Relation and Query Rewriting . . . 20
2.6 Criteria for(k, e)-Anonymous Partition . . . 21
2.6.1 The Minimum Sum-of-Error Problem . . . 22
2.6.2 The Minimum Max-of-Error Problem . . . 24
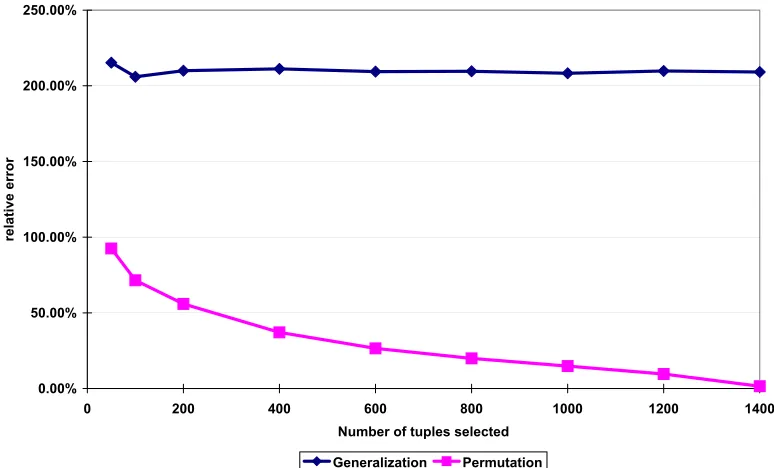
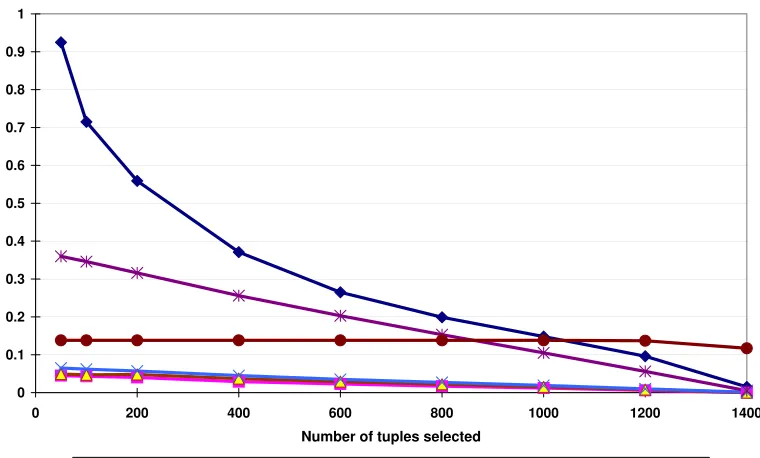
2.7 Experiments . . . 27
2.7.1 Accuracy . . . 28
2.7.2 Query Execution Overhead . . . 36
2.7.3 Scalability . . . 38
2.8 Summary . . . 40
3 Disguising Data Distribution . . . 41
3.1 Motivation . . . 41
3.2 Example . . . 43
3.3 Disguising Data Distribution . . . 48
3.3.1 Basic Concepts and Notations . . . 48
3.3.3 Answering Aggregate Queries . . . 50
3.4 Accurate Query Answering Optimization . . . 51
3.4.1 Minimize the Sum of Ranges of Sensitive Attribute Generalizations . . . . 51
3.4.2 Minimize Range of Quasi-Identifiers . . . 53
3.5 Integrating Fake Values into The Framework . . . 54
3.6 Approximate Target Distributions . . . 60
3.7 Experiments . . . 61
3.7.1 Performance of Anonymization through Sensitive Attribute Generalization 62 3.7.2 Impact of Integrating Fake Values . . . 65
3.7.3 Impact of Target Distributions . . . 67
3.7.4 Disguising Distribution for Different Parts of Data . . . 69
3.7.5 Approximate Target Distribution . . . 71
3.7.6 Discussion . . . 73
3.8 Summary . . . 73
4 Anonymizing Bipartite Graph Data Using Safe Groupings . . . 75
4.1 Motivation . . . 75
4.2 Preliminaries . . . 78
4.2.1 Graph Model . . . 78
4.2.2 Privacy Goals . . . 79
4.2.3 Query Types . . . 81
4.3 Applying Existing Techniques . . . 82
4.3.1 Representing as a relation . . . 82
4.3.2 Representing as a matrix . . . 84
4.3.3 Anonymization Through Permutation . . . 84
4.4 Privacy through Grouping . . . 87
4.4.1 Definition of Grouping . . . 87
4.4.2 Safe Groupings . . . 89
4.4.3 Security of(k, `)-Groupings . . . 94
4.4.4 Query answering on(k, `)-grouped graph . . . 96
4.4.5 Finding a safe grouping . . . 98
4.4.6 (k,1)- and(1, `)-Groupings . . . 100
4.4.7 Experimental Analysis of Utility . . . 101
4.5 Unions of groupings . . . 103
4.6 Summary . . . 108
5 Personalized Privacy . . . 109
5.1 Motivation . . . 109
5.2 Example . . . 110
5.3 Personalized Privacy Model . . . 111
5.4 Optimization for Accurate Query Answering . . . 112
5.4.1 Problem definition . . . 112
6 Discussion . . . 118
6.1 Summary of contributions . . . 118
6.2 Related Work . . . 120
6.2.1 Policy-based Privacy Enforcement . . . 120
6.2.2 Privacy-Preserving Data Mining . . . 121
6.2.3 Macrodata/Microdata Protection . . . 122
6.3 Future work . . . 125
LIST OF TABLES
Table 2.1 An example microdata table . . . 9
Table 2.2 An example3-anonymity microdata table after generalization. . . 10
Table 2.3 An example3-anonymous microdata table after permutation . . . 11
Table 2.4 An example help table. . . 13
Table 3.1 An example microdata table . . . 43
Table 3.2 An example microdata table after sensitive attribute generalization and permutation . 44 Table 3.3 An example microdata table after sensitive attribute generalization and permutation, where aggregate queries cannot be accurately answered. . . 47
Table 3.4 Inserting fake values into microdata . . . 47
Table 3.5 First two levels of ratios of each distribution . . . 73
Table 4.1 Example data set . . . 75
Table 4.2 Attempting to apply existing anonymization to graph data . . . 83
Table 5.1 An example microdata table . . . 110
LIST OF FIGURES
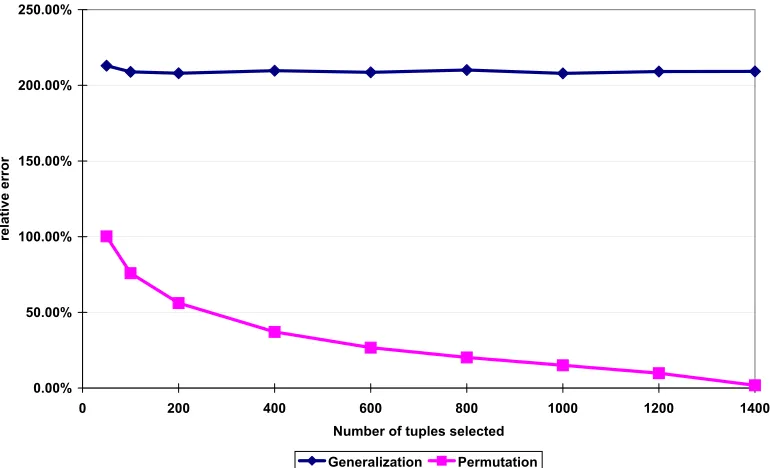
Figure 2.1 The association between identities and sensitive attributes through quasi-identifiers . 18 Figure 2.2 The relative errors of arbitrary queries when using the generalized table and the
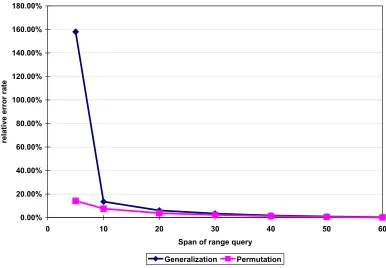
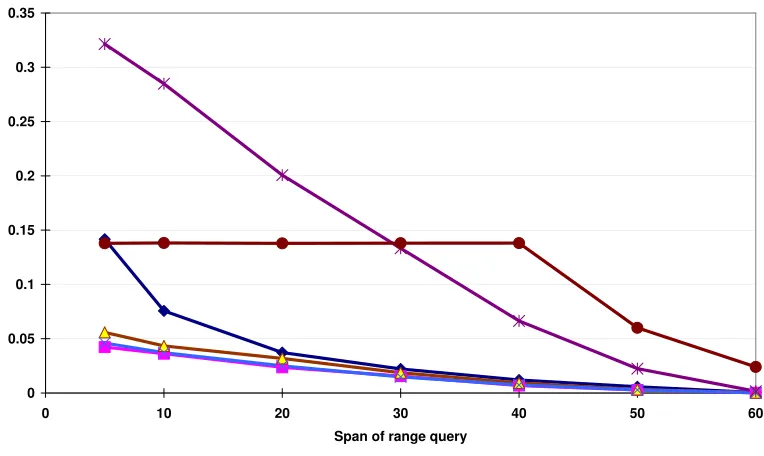
permuted table respectively. . . 30 Figure 2.3 The relative errors of range queries when using the generalized table and the
per-muted table . . . 31 Figure 2.4 The relative errors of range queries when using the generalized table and the
per-muted table with only one QI . . . 32 Figure 2.5 The relative errors of range queries when using the generalized table and the
per-muted table, with only one QI . . . 32 Figure 2.6 The relative errors of arbitrary queries when using different partitioning algorithms . 33 Figure 2.7 The relative errors of range queries using partitions from different partitioning
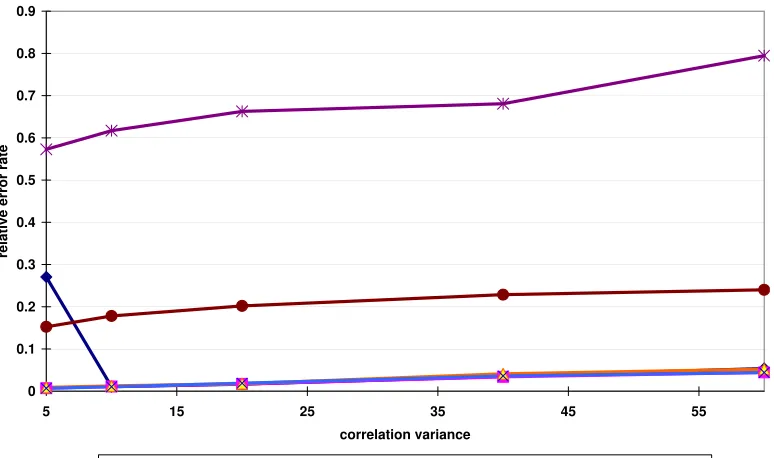
algo-rithms . . . 34 Figure 2.8 The relative errors of range queries using partitions from different partitioning
al-gorithms, when the strength of the correlation between quasi-identifiers and the sensitive attribute varies.. . . 35 Figure 2.9 The relative errors of range queries using partitions from different partitioning
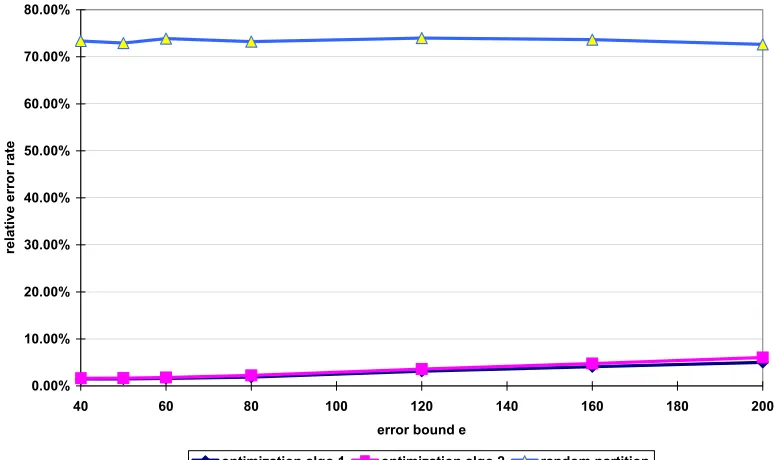
algo-rithms . . . 37 Figure 2.10The relative errors of range queries using partitions from different partitioning
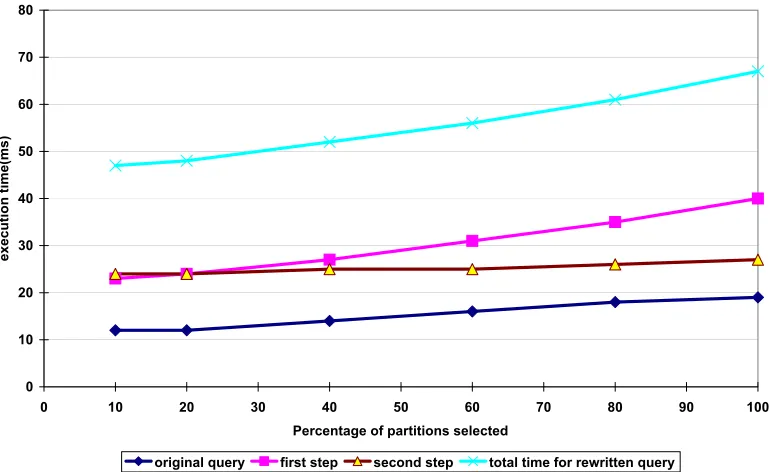
algo-rithms . . . 37 Figure 2.11The execution time of the constrained query and the rewritten controlled query when
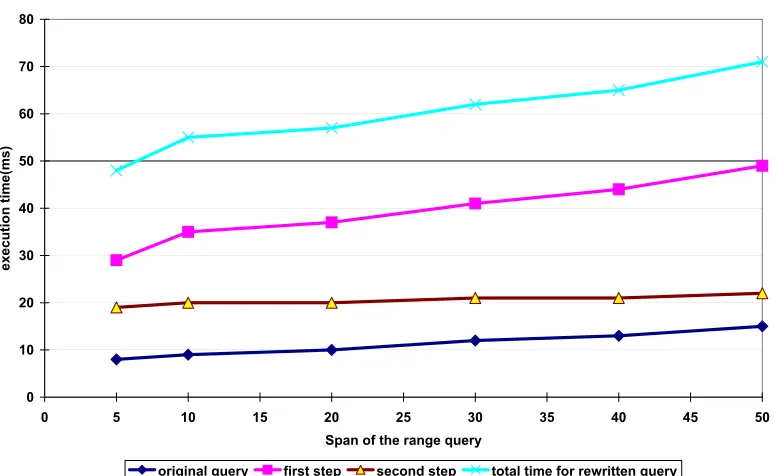
the percentage of selected groups in the partition varies . . . 38 Figure 2.12The execution time of the original range query and the rewritten range query when
the span of the range varies . . . 39 Figure 2.13The running time of an optimal partitioning algorithm when the microdata table size
scales up . . . 39
Figure 3.3 Relative error rate of SAonly with fake values . . . 66
Figure 3.4 Impact of target distribution . . . 68
Figure 3.5 Disguising the distributions of different parts of data . . . 70
Figure 3.6 Privacy-accuracy tradeoff . . . 72
Figure 4.1 Graph representation of example data set . . . 76
Figure 4.2 Permutation destroys the co-author relationship . . . 85
Figure 4.3 (3,3)-anonymization of example relation . . . 86
Figure 4.4 Lattice over groupings and privacy/utility tradeoff . . . 90
Figure 4.5 Safe Grouping Examples . . . 92
Figure 4.6 Impact of query selectivity and group size on three queries . . . 99
Figure 4.7 Expected Error Bounds . . . 104
Figure 4.8 Impact of Grouping and Clustering . . . 105
Chapter 1
Introduction
1.1 Privacy-Preserving Data Sharing
With the fast development of computer hardware and software, and the rapid computeri-zation of businesses and government operations, large amount of data have been collected. These data often need to be published, shared with, or outsourced to collaborating companies for further processing. For example, the government may need to publish the census data with household in-come information in a certain area; a hospital may need to share its patient records with public health researchers; a loan company may need to publish its customer finance data to demonstrate its business rules, and so on.
Such data often contains private information, and should not be disclosed directly. In the above example, the household income of a particular family in the census data, the health record of a particular patient, and the financial history of any individual in the loan report are all sensitive information, and its privacy should be maintained.
Traditionally, the data owner often choose some representative statistics to publish, or pre-aggregate parts of the data that others might be interested in. In this way, an individual’s privacy is better protected. However, data published in these forms lack flexibility. Others can only learn about the pre-computed statistics, but nothing else.
In recent years, researchers have proposed to publish data in the form of microdata, i.e., data in the original form of individual tuples. Obviously the release of microdata offers significant advantages in terms of information availability, as the original records are kept and people can issue arbitrary queries they are interested in. So it is particularly suitable for ad hoc analysis.
sensitive attributes (SA) of individuals are published. Existing privacy practice relies on de-identification, i.e., removing explicit identification information (e.g., name, SSN, home address and telephone numbers) from microdata. However, it has been well recognized [1, 2] that simple de-identification is not sufficient to protect an individual’s privacy. One’s other attributes (so-called quasi-identifiers, or QI for short, such as age, zip code, date of birth and race) are usually needed for data analysis, and thus are kept after de-identification. Individuals’ sensitive information may often be revealed when microdata are linked with publicly available information through quasi-identifiers. A famous example is given by Sweeney in [2], where she successfully identified the governor of Massachusetts using only his date of birth, gender, and ZIP code from local hospital records, and then combine this information with the census database.
k-anonymity [2] is a privacy model to address the above privacy problem. Through do-main generalization and record suppression,k-anonymity guarantees that publicly available infor-mation cannot be related with less thankrecords in a microdata database. In other words, given a sensitive attribute value in microdata, an attacker can at most relate it to a group of no fewer than kindividuals instead of any specific one. The concept of`-diversity [3] was recently proposed to further protect privacy in microdata. It is based on a stronger attack model where an attacker is assumed to have the knowledge that both the record corresponding to an individual and some values of its quasi-identifiers appear in a microdata database. In its basic scheme, each individual will be associated to at leastl different sensitive attribute values in the anonymized data. Thus in order to recover the original mapping, the attacker needs at leastl−1pieces of additional background information.
The privacy goals of k-anonymization and`-diversity are suitable for categorical sensi-tive attributes, such as the disease attribute in a patient record table. They assume that different attribute values are incomparable. In`-diversity, as long as it is ensured that an individual’s sensi-tive attribute value can at most be narrowed down to a group of no less thanktuples with no less than`distinct values, one’s privacy is protected. In practice, besides categorical attributes, many sensitive attributes in microdata databases are in fact numerical data, e.g., one’s salary, investment gains or losses. The privacy goals ofk-anonymity and`-diversity are often not sufficient to protect numerical attributes. For example, even when`-diversity is satisfied, if the group of salary values falls into a narrow range, an attacker can still obtain sensitive financial information of an individ-ual. Therefore, it is important to define new privacy goals for the protection of numerical sensitive attributes in microdata.
can be as sensitive as the private information of individual records. For example, consider a hospital in Beverly Hills that treats celebrities. Since reporters often keep monitoring which celebrities have checked into the hospital, it would be desirable for the hospital to disguise the distribution of the released sensitive attributes (e.g., symptoms and prescriptions) to a different “target distribution” which, e.g., exactly or approximately mirrors the distribution from the general population of patients in the Los Angeles area. It will be very useful to propose an anonymization scheme that ensures an attacker can only derive from the microdata that an individual record’s sensitive attribute follows a pre-specified target distribution.
Most of existing works are focusing on the privacy problems of tabular data. We also observe that private data often arises in the form of associations between entities. An example is the products bought by customers at a pharmacy. The set of products being sold and their properties are public knowledge, and it may be no secret which customers visit a particular pharmacy. How-ever, the association between a particular individual and a particular medication is often considered sensitive, since it is indicative of diseases or health issues that they have. The most natural way to model such data is to use a bipartite graph: nodes represent entities, and edges indicate associations between them. Graph data pose more privacy challenges than tabular data: a single piece of back-ground information combined with the graph structure can often leak a large amount of information [4]. New anonymization schemes are needed which can address the challenging privacy problems associated with graph structures.
In this dissertation, we propose solutions to all the privacy problems mentioned above. Furthermore, we identify that since most existing approaches achieve privacy through generalization of quasi-identifiers [5, 6, 3, 7, 8, 9], they cannot answer aggregate queries with any reasonable accuracy, thereby reducing the utility of the released microdata. We emphasize that complementing the desire for privacy of microdata is the need to support ad hoc aggregate analysis that select subsets of records based on arbitrary conditions on the quasiidentifiers and compute aggregates over sensitive attributes (e.g., what is the average salary of men over age 50 in Texas?). For each of the privacy models we addressed above, we also investigate effective techniques to support accurate aggregate query answering on microdata while preserving privacy.
1.2 Scope of The Research
more complex scenarios.
1.2.1 Data model
In this dissertation, we study the privacy of two types of data.
• First we consider the anonymization of a de-identified tabular data from one table, where each entry of the table corresponds to an individual. Attributes of each entry can be separated into quasi-identifiers and a sensitive attribute. For multiple tables, if they are non-correlated, which means there is no association between their attributes, we can anonymize them with our approach separately. If there are some associated attributes, we can construct a combined view on these tables based on those attributes. When we do need to publish multiple correlated tables separately, the problem is much harder. As pointed out by Yao et al. [10], the problem of checking k-anonymity in multiple views is generally NP-hard. We leave it as possible future work.
• For tabular data, we assume the data is already de-identified. The remaining attributes are either quasi identifiers or sensitive attributes. If there exist no quasi identifiers in the table, or if some of the quasi identifiers are also sensitive, it is difficult for attackers to link the identifiers in the outside database and tuples in the microdata. Thus we do not consider such situations.
• In Chapter 4, we will look at the privacy of bipartite graph data. We assume in the graph nodes represent entities, and edges indicate associations between them. Specifically, we only consider unweighted, and undirected graphs, and each pair of nodes have only a single edge between them.
1.2.2 Publishing model
more privacy leakage. Currently there is no solution to this kind of situation yet. We also leave it to future work.
1.2.3 Query model
We consider queries that select subsets of records based on arbitrary conditions on the quasi identifiers, and computes aggregates on sensitive attributes. Such queries are most commonly used in OLAP. For graph data, we further define different types of queries, based on their conditions on the attributes, graph structure, or different combinations of them in chapter 4.
1.2.4 Privacy model
For privacy of tabular data, we focus on protecting the sensitive attribute of individuals. In other words, the goal is to prevent attackers from knowing the sensitive attribute values of in-dividuals. For bipartite graph data, we focuses on the privacy of the association between the two types of entities. We do not constrain if attackers can infer whether someone or some entity is in the database. In other words, we do not take into account the “existential sensitivity”, where the mere fact that there exists a record for a specific individual Alice in the microdata table may also be considered sensitive, even though Alice’s sensitive attribute is unknown. The reason is, as stated in [3], besides public databases, attackers may often have external background knowledge. For exam-ple, Bob may physically see that Alice checked into a hospital. Thus, it is difficult if not impossible to prevent such information leakage. In this dissertation, revealing one’s sensitive attribute values is considered a privacy violation, but revealing the existence of a record with specific quasi-identifiers is not.
1.2.5 Attack model
For tabular data, we assume the only information attackers can access is the published anonymized table, and some other publicly available database that contains the association between the unique identifiers and quasi-identifiers in the microdata. We do not consider insider attacks. In other words, we assume attackers cannot access the original data, and do not have priori knowledge of the correlation between quasi-identifiers and sensitive attributes.
attackers may have some information about the graph structure. It is more complicated and we will leave the detailed discussions to chapter 4.
1.3 Contributions
The goal of privacy protection in microdata is essentially to break the association between the identifiers in publicly available information and the sensitive attributes in microdata, due to quasi-identifiers. Existing approaches are mostly based on generalizations on quasi-identifiers (QI-generalization) and aim to weaken the link between quasi-identifiers in publicly available databases and microdata. However, QI-generalization based approaches cannot maintain much utility of the anonymized data. In this dissertation, we proposepermutation-based approaches on sensitive at-tributes (SA-permutation) to reduce the association between quasi-identifiers and sensitive atat-tributes in microdata. We also identify the privacy requirements for several specific scenarios, and design corresponding anonymization schemes based on permutation approaches. In particular, the contri-butions of this thesis include the following:
1. We propose permutation-based techniques on sensitive attributes to anonymize microdata table and protect privacy. We show that SA-permutation based anonymization techniques can always answer aggregate queries more accurately than QI-generalization based approaches. 2. We propose (k, e)-anonymity, a new privacy goal to better capture privacy protection for
numerical sensitive attributes in chapter 2. Besides requiring a group of sensitive attribute values to have no less than kdistinct values, the proposed privacy goal requires the range of the group to be larger than a certain thresholde. We design an anonymization scheme to achieve this privacy goal based on SA-permutation. We further optimize the scheme so that it can provide the best query answers to aggregate queries, and anonymization algorithm runs efficiently on large dataset.
domains within each partition. We also develop efficient algorithms to optimize this scheme and provide the best query answers to aggregate queries.
When the target distribution is far from the source distribution, the query accuracy is often poor. We further propose two approaches to achieve better accuracy for query answering. The first approach allows data owners to approximate the target distribution in a controlled manner to tradeoff distributional privacy protection and accurate query answering during anonymiza-tion. The second approach is to inject fake tuples into the anonymized dataset.
4. Private data often comes in the form of association between entities. In chapter 4 we show that existing anonymization techniques for tabular data cannot give accurate answers to queries on graph properties: small changes on edges will change aggregate graph properties radically. We propose a novel group of anonymization techniques for bipartite graph data, called(k, l) -groupings. Graph data pose more security challenges than tabular data. A single piece of background information combined with the graph structure can often leak a large amount of information. We demonstrate such attacks, and study the security properties of (k, l) -groupings in detail.
5. In practice, users may not care about their privacy that much, which makes it possible that we relax the privacy protection for some users, and provide more accurate answers to aggregate queries. We initialize this privacy model in chapter 5 to give users choices to specify their own privacy preferences and proposed the personalized privacy model.
1.4 Dissertation Outline
Chapter 2
Anonymizing Numerical data
2.1 Motivation
The privacy goal ofk-anonymity[2] and`-diversity[3] is suitable for categorical sensitive attributes, such as the disease attribute in a patient record table, where different attribute values are incomparable. In practice, besides categorical attributes, many sensitive attributes in microdata databases are numerical, e.g., salary, investment gains or losses, credit score, white blood cell count, etc. Applying existing privacy goals ofk-anonymity and`-diversity is often not sufficient to protect numerical attributes. For example, even when`-diversity is satisfied, if the salary values fall in a narrow range, sensitive information is revealed. Thus, it is important to define new privacy goals for the protection of numerical sensitive attributes in microdata.
In this chapter, we propose a new privacy goal to better capture privacy protection for numerical sensitive attributes . Besides requiring a group of sensitive attribute values to have no less thankdistinct values, the proposed privacy goal further requires the range of the group to be larger than a certain thresholde; such a threshold prevents an attacker from determining an individual’s sensitive attribute value in a narrow range.
It is not hard to see that traditional domain generalization approaches can be used to achieve (k, e)-anonymity when handling numeric-valued sensitive attributes. After each domain generalization, besides checking whether every partition has no less thanktuples, we simply further check whether the partition has a range larger than or equal toe.
However, as we will show in section 2.2, generalization based techniques impose chal-lenges when answering ad hoc aggregate queries. In general, given an aggregate query whose condition over quasi-identifiers isc, and a microdata table generalized underD∗
Table 2.1: An example microdata table
ID Quasi-identifiers Sensitive tuple ID name age zipcode gender salary
1 Alex 35 27101 M $54,000
2 Bob 38 27120 M $55,000
3 Carol 40 27130 M $56,000
4 Debra 41 27229 F $65,000
5 Evan 43 27269 F $75,000
6 Frank 47 27243 M $70,000
7 Gary 52 27656 M $80,000
8 Henry 53 27686 F $75,000
9 Ina 58 27635 M $85,000
subset defined by D∗
QI. If for every possible r = (qi1, . . . , qik) that belongs toDi under D∗QI,
c(r) is true/false, then obviously all the sensitive attribute values in the partition should be in-cluded/excluded when computing the aggregate. Otherwise, to get correct lower/upper bounds of the query result, we have to act conservatively, and include none/all of the sensitive attribute values to compute the aggregate, which can be inaccurate.
In this chapter, we propose permutation-based approaches that can provide the same pri-vacy guarantee, and enable more accurate query answers on the anonymized tables at the same time. Before providing a formal description, we use some examples to illustrate the proposed privacy goal, and the basic idea of permutation-based anonymization and its advantages over a generalization-based approach in the next section.
2.2 Example
Consider the population table shown in table 2.1, which needs to be shared for business and economic research. Among the attributes of the table, “name” can be used to directly identify an individual in real life. To prevent the sensitive information (“salary” in this example) of individ-uals from being disclosed, such explicit identity attributes need to be removed before the table is disclosed. Other attributes of individuals, such as “age”, “zip code” and “gender”, often need to be disclosed, since valuable statistical analysis relies on these attributes. For this example, we consider the following aggregate queries:
• Query 1.The average salary of those with age over 50.
Table 2.2: An example3-anonymity microdata table after generalization. Quasi-identifiers Sensitive
tuple ID age zipcode gender salary
1 [31−40] 271* * $56,000
2 [31−40] 271* * $54,000
3 [31−40] 271* * $55,000
4 [41−50] 272* * $65,000
5 [41−50] 272* * $75,000
6 [41−50] 272* * $70,000
7 [51−60] 276* * $80,000
8 [51−60] 276* * $75,000
9 [51−60] 276* * $85,000
• Query 3.The minimum salary of females.
Clearly, after removing the identity attribute “name” from the table in table 2.1, we can still accurately answer these queries.
On the other hand, some public databases may also contain the attributes “age”, “zip code” and “gender”. They may also further be associated with people’s explicit identities. Due to this reason, these attributes are called “quasi-identifiers” since they may be used to reveal one’s identity when combined with public databases.
Current approaches to addressing potential privacy violations caused by quasi-identifiers generalize the domains of quasi-identifiers so that many tuples will have the same quasi-identifiers. Table 2.2 shows such a generalization, where “age” is generalized to a range of width 10, “zip code” only keeps the first 3 digits, and “gender” is totally suppressed. The resulting table satisfies 3-anonymity, which means that after generalization each tuple can find at least two other tuples with the same values of quasi-identifiers. It also satisfies 3-diversity since among those tuples with the same values of quasi-identifiers there are at least 3 different sensitive attribute values.
In this chapter, we propose a permutation-based approach to anonymization. In our ap-proach, tuples in the table are partitioned into several groups such that each group has at least k different sensitive attribute values. We then perform a permutation between the tuples’ quasi-identifiers with their sensitive attribute inside each group. Table 2.3 shows the table of table 2.1 after permutation, where each group has 3 different sensitive attribute values. In fact, the partition used in table 2.3 is the same as the one resulting from the generalization in table 2.2.
Table 2.3: An example3-anonymous microdata table after permutation Quasi-identifiers Sensitive
tuple ID age zipcode gender salary
1 40 27130 M $54,000
2 38 27120 M $55,000
3 35 27101 M $56,000
4 41 27229 F $65,000
5 43 27269 F $70,000
6 47 27243 M $75,000
7 52 27656 M $75,000
8 53 27686 F $80,000
9 58 27635 M $85,000
approach will achieve the same privacy protection as existing generalization-based approaches. One benefit of our permutation-based approach is that it will provide more accurate answers to aggregate queries.
Let’s consider the three queries previously mentioned in this section. Since both ap-proaches introduce imprecise information into the original table, they cannot always get the correct answer for aggregate queries. Instead, for each approach, we can get deterministic lower and upper bounds of the correct answer. We compare the accuracy of the bounds of each approach.
Query 1: The average salary of those with age over 50.This query covers all the tuples in the third group of both table 2.2 and 2.3. Therefore, by using either table, we can get the exact result for the query, which is $80,000.
Query 2: The sum of salaries of those with age between 35 and 55. In both tables, all the tuples in the second group should be included in the aggregation. But, by using the generalized table of table 2.2, we face a difficulty when dealing with tuples in the first and the third groups. Since only generalized ranges [31-40] and [51-60] of ages are available to get a correct lower/upper bound, we have to assume that none/all of the tuples participate in the aggregation. Therefore, the bounds based on table 2.2 can only be [$210K, $615K].
Query 3: The minimum salary of females. There is a great difficulty in answering this query using table 2.2, since the “gender” attribute is totally suppressed in order to achieve 3-anonymity. We do not even know whether there exists a tuple with gender female in the original table. Even if we assume that there is at least one female in the table, the best bound we can get is [$54K, $85K].
Based on the permuted table, we know that there are two female in groups 2 and one in group 3, but none in group 1. Since all the salaries in group 3 are higher than those in group 2, we can conclude that the minimum salary of females in this table is between [$65K, $70K]. Again, this is more accurate than the bounds derived from table 2.2.
In section 2.3.2, we will show that, given the same partitions, the permutation-based ap-proach always produces more accurate bounds for aggregation queries than the generalization-based approach.
In fact, since we know the exact number of tuples included in the aggregation in each group (we refer to it as the “number of hits”), more statistics about the query result can be derived. For example, besides the lower and upper bounds for SUM and AVERAGE, we may also compute the mean and variance among all the possible answers. Such statistics provide more information. This is not possible for generalized tables.
One nice property is that the lower and upper bounds for an aggregation operation over the whole table can be computed efficiently by combining bounds over each group of the partition. To facilitate efficient query answering over a permuted table, we propose to use ahelp table, which pre-computes the bounds for each group and all the possible numbers of hits. Given an aggregate query, we can simply rewrite it to query both the permuted table, determining the number of hits of each group, and then join this information with the help table to quickly get the bounds for the whole query result. An example help table, for the table of table 2.1, is shown in table 2.4. Due to space limitations, we only show the bounds for SUM and MIN in the table. It can certainly include those for other aggregation operations.
Table 2.4: An example help table
group ID hits sum-l-b sum-u-b min-l-b min-u-b
1 1 $54K $56K $54K $56K
1 2 $109K $111K $54K $55K
1 3 $165K $165K $54K $54K
2 1 $65K $75k $65K $75K
2 2 $135K $145K $65K $70K
2 3 $210K $210K $65K $65K
3 1 $75K $85K $75K $85K
3 2 $155K $165K $75K $80K
3 3 $240K $240K $75K $75K
Though the attacker cannot know the exact salary of Alex, this range might be narrow enough to be considered as sensitive. This example shows that for numerical sensitive attributes, besides distinct values in each group of a partition, we also need to consider the range of each group to prevent type of inference as the one described. In this chapter we introduce another privacy parametere, and further require the range of thekdistinct values in a group to be no less thane. We call this privacy objective (k, e)-anonymity. For instance, the above generalized and permuted tables only satisfy
(3,2000)-anonymity but violate(3,10000)-anonymity.
We note that several techniques already exist to protect the privacy of numerical sensitive attributes. In perturbation-based approaches [11, 12, 13], noise following a certain distribution is added to sensitive attribute of each tuple. Such an approach inevitably changes important statistics of the marginal distributions of sensitive attributes (e.g., vairance) [14]. Further, depending on the distribution of added noise (e.g., Gaussian Distribution), it is often difficult to derive deterministic bounds for answering aggregate queries.
To some extent, permutation-based anonymization is similar to data swapping techniques where privacy is achieved by exchanging the sensitive attributes of pairs of randomly selected records [15, 16]. Since no noise is introduced, both approaches preserve the marginal distributions of sensitive attributes. However, data swapping is done globally, which has a much larger impact on microdata utility. Even when done in a controlled manner (e.g., rank-based data swapping [17]), it will still produce big errors for aggregate queries. Our experimental results show this point clearly (see section 2.7).
2.3 Preliminaries
2.3.1 Privacy in the Release of Microdata
We introduce notations and concepts to facilitate our discussion on potential privacy vul-nerabilities in the release of microdata.
Microdata. There are three types of attributes in anoriginalmicrodata tableM: iden-tifiers, quasi-identifiers and sensitive attributes. An identifierID is an attribute, whose value, if known, canalwaysbe used touniquelyidentify an individual in real life. In practice, there may ex-ist multiple identifiers such as one’s SSN and telephone number. Quasi-identifiers{QI1, . . . QIk}
are a set of attributes associated with tuples that not only appear in the microdata table but may also appear in other publicly available databases. Example quasi-identifiers include age, date of birth, zip code, etc. Sensitive attributes, on the other hand, are only contained in the microdata table, and do not appear in public databases. The goal of privacy protection is thus to prevent attackers from knowing the specific values of sensitive attributes associated with individual tuples. Without loss of generality, we assume there is only one sensitive attributeSin a microdata table. We further assume that the domain of the sensitive attribute is numeric, which is widely true in a variety of microdata databases. Examples include salary in population databases, credit score in financial databases, and white blood cell count and other diagnosis indicators in public health databases. Table 2.1 is an example of an original microdata table where the identifier, quasi-identifiers, and sensitive attribute are shown.
A de-identified microdata tableDis a projection ofMover quasi-identifiers and sensitive attributes. We call the projection ofMoverIDandSthe sensitive information table, denotedS.
Note that in some situations the mere fact that there exists a record for a specific indi-vidual Alice in the microdata table may also be considered sensitive, even though Alice’s sensitive attribute is unknown. For example, the fact that Alice has a record in a microdata table released by a psychiatric hospital may seem quite sensitive. However, as stated in [3], besides public databases, attackers may often have external background knowledge. For example, Bob may physically see that Alice checked into a hospital. Thus, it will be very hard to prevent such information leakage. In my dissertation, revealing one’s sensitive attribute values is considered a privacy violation, but revealing the existence of a record with specific quasi-identifiers is not.
attributes{ID, QI1, . . . , QIk}. In practice, there may exist multiple sources of public information,
such as county real estate databases and voter registration records. The above model represents the overall public information that an attacker may derive when combining information from multiple sources.
Aggregate queries. We consider queries that select subsets of records from a micro-data table based on arbitrary conditions on the quasi-identifiers and compute aggregates over the sensitive attribute. Such aggregate queries are important during microdata analysis in a variety of domains. Since the domain of the sensitive attribute is assumed to be numeric-valued, a variety of SQL aggregation operations, such as COUNT, SUM, AVERAGE, MIN and MAX, can be used in aggregate queries.
Privacy is violated when an attacker successfully recovers one or more tuples in the sen-sitive information tableS. Formally, we have the following privacy definition, which is based on the one proposed in Yao et al. in [10].
Definition 2.3.1. Each tuple on(ID, S)is called anassociation. A setAof associations on(ID, S)
is called an association coverif all the tuples inAhave the sameID value andA ∩ S 6= ∅. An association cover of sizekis called ak-association-cover.
For example, considering the microdata table in table 2.1,{(Alex,$54,000),
(Alex,$55,000),(Alex,$56,000)}is a 3-association cover.
Definition 2.3.2. A de-identified microdata databaseD satisfiesk-Anonymityif fromD and any given public databaseP, an attacker cannot derive any association cover with size less thank.
The above definition captures the essence of privacy in microdata, i.e., preventing the association between an individual’s ID and its sensitive attribute value. The originally proposed concept ofk-anonymity was defined specifically for generalization based approaches. It required that, after generalization, for each tupletin the table, there should exist no less than k−1other tuples having quasi-identifiers equal to those oft. This original definition can be viewed as the goal for generalization in order to achievek-anonymity. Definition 2.3.2, on the other hand, is declarative and independent of specific techniques for anonymization. Therefore, it serves as a good privacy definition for the comparison of different anonymization techniques.
Definition 2.3.3. A de-identified microdata databaseDsatisfies(k, e)-anonymityif givenDand any given public databaseP, any association cover that an attacker can derive satisfies: (1) the size of the association cover is no lessk; and (2) the range of the sensitive attribute values in the association cover is no less thane.
2.3.2 Anonymization Through Generalization
Most existing works achievek-anonymity through domain generalization of quasi-identifiers. That is, instead of releasing the exact values of quasi-identifiers, the values are generalized in a way that many tuples appear to have the same values for quasi-identifiers. For example, instead of dis-closing one’s exact age, the microdata only shows that the age falls into a certain pre-defined range. Thus, an individual identifier can only be associated with those who have the same quasi-identifiers after generalization.
More specifically, following the notation introduced in [3], letDbe a domain. A gener-alized domainD∗ofDis a domain{D
1, . . . , Dr}, such that eachDiis a subset ofD,Di∩Dj =∅
wheni6= j, andSDi =D. Letx ∈D. The generalization ofxunderD∗, denotedg(x, D∗), is
Di∈D∗, wherex∈D
i.
LetD∗
QIi be a generalized domain for each quasi-identifierQIi. ThenD
∗
QI = DQI∗ 1 × · · · ×D∗
QIk forms a generalized domain for quasi-identifiers. Given a tuplet∈ D, its generalization
underD∗
QI, denotedg(t, DQI∗ ), is a tuplet0 such that t0[QIi] = g(t[QIi], DQI∗ i) andt
0[S] = t[S]. The generalization ofD, denotedg(D, D∗
GI), is thus{g(t, D∗QI)|t∈ D}.
In the example shown in table 2.2, the generalization domains for the three quasi-identifiers are{[1−10],[11−20], . . .}, the first 3 digits of zip codes, and{∗}(denoting any gender), respec-tively.
Given a microdata tableD, a generalized domainDQIin fact defines a partition
{D1, . . . ,Dr}ofDsuch that any two tuplest1 andt2 inD, belong to the sameDi if and only if
they have the same generalized quasi-identifiers underDQI. Letr = (qi1, . . . , qik)be a value of
quasi-identifiers. We sayrbelongs toDiif the generalization ofrunderDQI∗ is the same as that of
tuples inDi.
at least`distinct sensitive attribute values in eachDi after generalization. When`is set to bek,
the partition obtained by using`-diversity techniques will then guarantee k-anonymity. It is not hard to see that domain generalization can also be used to achieve(k, e)-anonymity when handling numeric-valued sensitive attributes. After each domain generalization, besides checking whether every partition has no less thanktuples, we simply further check whether the partition has a range larger than or equal toe.
However, as shown in section 2.2, generalization based techniques impose challenges when answering ad hoc aggregate queries. In general, given an aggregate query whose condition over quasi-identifiers isc, and a microdata table generalized underDQI∗ , letDibe one subset defined
byD∗
QI. If for every possibler = (qi1, . . . , qik)that belongs toDi underD∗QI,c(r) is true/false,
then obviously all the sensitive attribute values in the partition should be included/excluded when computing the aggregate. Otherwise, to get correct lower/upper bounds of the query result, we have to act conservatively, and include none/all of the sensitive attribute values to compute the aggregate, which can be inaccurate.
2.4 Anonymization Through Permutation
The essential reason that an attacker may recover an individual’s sensitive attribute value is the existence of the following three links: (1) the link between the identifier and quasi-identifiers in the public databaseP; (2) the link between the quasi-identifiers inPand those in the de-identified microdataD; and (3) the link between quasi-identifiers and the sensitive attribute inD. Figure 2.1 shows the association between identities and sensitive attributes through quasi-identifiers. Breaking or weakening the associations of any of the above links will help protect privacy. Domain general-ization actually weakens the second and the third links.
In our framework, we propose toonlybreak the third link through permutation. Given a set of tuples in a de-identified microdata table, we randomly permute the association between quasi-identifiers and the sensitive attribute instead of using domain generalization on the quasi-quasi-identifiers. Intuitively, even if an attacker can link an individual’s identifier with a tuple’s quasi-identifier (for example through background knowledge), he will not be able to know with certainty the exact value of the individual’s sensitive attribute.
Definition 2.4.1. LetT ={t1, . . . , tn}be a table with attributes{a1, . . . , am}, andpbe a random
De−identified Microdata
Public available information
link 3
link 2
link 1
Sensitive attributes
Quasi−identifiers
Quasi−identifiers
Identity
Figure 2.1: The association between identities and sensitive attributes through quasi-identifiers
denoted p(T,{a1, . . . , al},{al+1, . . . , am}) as the set of tuples {t0i | ∀j,1 ≤ j ≤ l, t0i[aj] =
ti[aj]and∀j, l+ 1≤j≤m, ti0[aj] =tp(i)[aj]}.
Definition 2.4.2. LetDbe a de-identified microdata table with attributes{QI1, . . . , QIk, S}, and
{D1, . . . ,Dn} be a partition ofD. A group Di is (k, e)-anonymousif the projection of Di over
the sensitive attribute S contains no less thankdifferent values, and the range of these different values inDiis no less thane. We say the partition is(k, e)-anonymousif everyDiin the partition is(k, e)-anonymous. We denoteD0
i =p(Di,{QI1, . . . , QIk},{S}). Dp =
S
i=1,...,nD0iis a(k, e)
-anonymous permutation ofD.
As an example, table 2.3 shows a (3,2000)-anonymous permutation of the table in ta-ble 2.1.
Theorem 1. Given a(k, e)-anonymous permutationDp and a public databaseP, any association
cover that an attacker can derive satisfies(k, e)-anonymity.
Proof. Prove by contradiction that, if attacker derives an association coverAof size less thankor with range less thane, then we can construct a microdata tableMsuch that its(k, e)-anonymous permutation is the same asDp, and the sensitive attribute of that identifier is not in the association
cover.
ef-fective against the permutation-based scheme. The essential reason is that, in order to maximize the utility of the anonymized data, the anonymization scheme often needs to do optimizations on the groupings of quasi identifiers, to create quasi-identifier equivalent classes (QI-EC). The opti-mizations will leak information about the sensitive attribute distribution in each QI-EC, and can be further used to deduce the actual sensitive value for each tuple, by exploring the generalization criteria during the quasi identifier generalization process. For our permutation-based techniques, we do not group tuples based on the quasi-identifiers, and we do not have such notion of QI-EC. Thus our approach does not have this vulnerability which most generalization-based approaches have. The minimality attack will not work in permutation-based schemes.
2.5 Aggregate Query Answering
Given a(k, e)-anonymous permutationDp and an arbitrary query condition over
quasi-identifiers, since the quasi-identifiers of a tuple are unchanged, we know exactly how many tuples satisfy the condition in each groupDi of the partition. Suppose this number ismi. Due to the
random permutation between quasi-identifiers and the sensitive attribute inDi, the actual result of
the aggregate inDimay be over the sensitive attribute of anymi tuples in the group. Thus, in the worst case, there may be totallyC(|Di|, mi) different results for the aggregate. It would be too
expensive to enumerate all the possible results when the size of the group is large. Instead, we are interested in efficiently computing important statistics, such as the lower and upper bounds, mean, variance, of all the possible aggregates. Such statistics will be very useful for ad hoc analyses.
2.5.1 Lower and Upper Bounds
Letmi be the number of tuples inDi that satisfy the condition of an aggregate queryQ.
If the aggregation operation is monotonic, then the lower/upper bound of the result ofQinDiis the
aggregation of themi smallest/largest sensitive attribute values inDi. Standard SQL aggregation
functions, such as SUM, AVERAGE, MIN, MAX and COUNT, are all monotonic. Therefore, the lower and upper bounds of the result of an aggregate query in eachDican be efficiently computed.
The lower and upper bounds of the query over the whole microdata table can be de-rived from those of each Di, depending on different aggregation functions. For sum, the overall
lower/upper bound is the summation of the lower/upper bound of eachDi, respectively. Since we
aver-age function can be directly computed from those of the sum function. It is also easy to see that the overall lower/upper bounds of the MIN function is the minimum among the lower/upper bounds of all theDi. The bounds for the MAX function can be obtained similarly.
Theorem 2. Let{D1, . . . ,Dr}be a partition ofDdefined by a generalization. Given any aggregate
query, the lower and upper bounds given by the generalized table always include that given by the permuted table using the same partition.
For sum and average, other statistics besides lower and upper bounds can also be com-puted by combining those of each group in a partition. We omit details for reasons of space.
2.5.2 Auxiliary Relation and Query Rewriting
We observe that, for the same aggregation operation, no matter what the query condition is, as long as the number of tuples satisfying the condition in eachDiis the same, the bounds of the
aggregation inDiremain unchanged. Therefore, we do not need to compute the bounds for eachDi
on the fly when answering a query. Instead, we propose to create ahelp tableto facilitate efficient query answering.
The primary key of the help table is “group ID” and “hits”, where the former indicates a group in the partition, and the latter represents the number of tuples in the group satisfying a query condition. For each group in the partition and the number of hits, the table lists the lower and upper bounds for each aggregation operation on the sensitive attribute. Table 2.4 shows the help table for the permuted table in table 2.3. It contains the bounds for SUM and MIN, though in practice it should also contain the bounds of AVERAGE, MAX and other aggregation operations supported by SQL. The number of tuples in the help table is the same as in the microdata table.
Besides the help table, we also create a binarymapping tablethat indicates which tuples the groups of a partition contain.
Given an aggregate query of the form “select agg(sensitive-attribute) from permuted-table whereC”, we rewrite it to get the bounds of the query result. The rewritten query first selects the tuple IDs of tuples that satisfy conditionC from the permuted tableP T. The result in the first step is then joined with the mapping tableM T to count the hits of each group of the partition. Once this information is available, it is further joined with the help table HT, and the bounds of the aggregation of each group are combined to compute the bounds for the final query result.
1. select groupID, count(tupleID) AS hits into R1 from MT
where MT.tupleID in (select tupleID from PT whereC) group by groupID
2. select sum(sum-lb), sum(sum-ub) from HT, R1
where HT.groupID = R1.groupID and HT.hits = R1.hits The processing of other aggregate queries is similar.
We emphasize that the help table can be constructed directly from the permuted table (using the mapping table), without requiring any access to the original microdata table. Therefore, the use of the help table does not compromise the privacy of microdata in any way. Further, we only need to compute the help table and the mapping table once for a released microdata database. It can be done offline, which will not affect the performance of ad hoc analyses.
2.6 Criteria for
(k, e)
-Anonymous Partition
We have shown that, given the same partition, the anonymized table obtained through per-mutation will always answer aggregate queries more accurately than that obtained through domain generalization. However, given an arbitrary partition, even with the permutation-based approach, it is unlikely to get satisfactory answers to aggregate queries. Thus, in this section, we turn our discus-sion to the problem of generating “good”(k, e)-anonymous partitions which are likely to produce accurate answers to aggregate queries.
Formally, let D denote a total order of the multiset of sensitive attribute values D =
x1, x2, . . . , xn, andP ={G1, . . . , Gm}be a partition ofD. SinceDis a totally ordered multiset,
we denote the indices of the first and the last data point in a groupGiasminiandmaxirespectively.
Thus, the range ofGi is obtained by [xmini, xmaxi]. Let E(Gi) denote an error measure defined
on a groupDi, andF be a point-wise additive function. We can now formally define the optimal
partition problem:
Problem 2.6.1(Optimal Partition). Given a total orderDof a sensitive attribute, obtain a(k, e) -anonymous partitionP ={G1,· · · , Gm}that minimizesF(E(G1), E(G2),
Given a point query xq, if xq ∈ Gi, our scheme will return any point inside Gi as an
answer. As a result, themaximumerror incurred for any point query inside a groupGiisE(Gi) =
xmaxi−xmini. Therefore, intuitively, the smaller is the range of each group, the smaller error will be
introduced to the answer of aggregate queries. Since all the groups ofP may be used for querying, it seems imperative to define the function F in a way that the error across all groups, assuming a uniform random workload of point queries, is minimized. It is natural to aim to minimize the additiveerror or themaxerror across all groups. Thus candidate point-wise additive functions are sumormax. We call the optimization problems using thesumand themaxfunctions theminimum sum-of-error problemand theminimum max-of-error problemrespectively. We denote the sum and the max of errors of all the groups in a partitionP assum of error(P) andmax of error(P)
respectively.
2.6.1 The Minimum Sum-of-Error Problem
Recall that the goal of this problem is to find a(k, e)-anonymous partitionP ={G1, . . . , Gm}
ofDsuch thatsum of error(P)is minimized. Without loss of generality, we assume thatG1, . . . , Gm
are ordered according to the index of the minimum value of each group, i.e., i < j implies that mini< minj, which also means thatxmini ≤xminj.
Lemma 2.6.1. There exists an optimal partitionP ={G1, . . . , Gm}to the minimum sum-of-error
problem such that for any groupsGiandGi+1, we havemaxi< mini+1.
Proof. We first observe thatmaxi < maxi+1. Otherwise, sincemini < mini+1, we can simply mergeGi+1andGiinto one group, whose maximum error is stillxmaxi−xmini, and obtain another
(k, e)-anonymous partitionP0. We havesum of error(P0) =sum of range(P)−(x
maxi+1−
xmini+1), contradicting the fact thatP is optimal.
Second, ifmaxi > mini+1, we can still mergeGiandGi+1. The maximum error of the
new group isxmaxi+1−xmini, which is less than or equal to the sum of the maximum errors ofGi
andGi+1.
Lemma 2.6.1 shows that the ranges of groups in an optimal partition are disjoint. It suggests that this problem has the optimal substructure property, thus it is amenable to dynamic programming solutions. Letf(i)denote the minimum cost way to partitionx1, . . . , xiinto a number
of groups, saym∗, such that the partition is(k, e)-anonymous forx
1, . . . , xi. Then
Thus, the optimal solution for partitioning the data pointsx1, . . . xiintom∗ groups is equal to the
minimum cost way of extending (according to the point wise additive functionF) the optimalm∗−1
partitioning ofx1, . . . xd−1 (for somed, 1 ≤ d ≤ i) with the group{xd, . . . , xi}. Algorithm 1
presents the dynamic programming solution for the sum-of-error problem. The algorithm considers all values ofi,1 ≤ i ≤ n, and for each value ofd,1 ≤ d ≤ i, assesses the sum of errors using equation 2.1. The index of the minimum item of each group is stored in the arraypartition. A linear scan of this array at the end of the algorithm (starting from partition[n] and going backwards) will extract the optimal group descriptions. The algorithm makes use of the arraydistinctthat returns inO(1)the number of distinct elements inDbetween the arguments supplied. The size of this array isO(n2)and can be populated in a preprocessing step inO(n2)time, so that access to it remains
O(1). It is evident that Algorithm 1 runs inO(n2).
Algorithm 1Optimal partition for the minimum sum-of-error problem f[0]= infinity
partition[0] = 0 fori= 1 tondo
f[i]= infinity
partition[i] = partition[i-1] ford= 1 toido
ifdistinct({xd, . . . , xi})≥kandxi−xd≥ethen
error=xi−xd
else
error= infinity end if
temp= max(f[d-1],error) iftemp < f[i]then
f[i] =temp partition[i] =d end if
end for end for
Theorem 3. Given a total order of a sensitive attributeD ofnitems, withO(n2) preprocessing
problem.
Proof. The proof is straightforward following the above analysis.
2.6.2 The Minimum Max-of-Error Problem
Though seemingly similar to the minimum sum-of-error problem, the minimum max-of-error problem turns out to be much more complex. We have shown that the groups of an optimal partition in the sum-of-error problem are disjoint, i.e., the ranges of different groups are not over-lapping (except possibly the boundary wherexmaxi = xmini+1). Therefore, each group can be described completely by using the indices of its first and last attribute valuesmini andmaxi, and
every attribute value with index between them belongs to the group. This property significantly reduces the search space for an optimal partition.
The non-overlapping property, however, does not hold for optimal partitions for the min-imum max-of-error problem. As a simple example, consider the following set of sensitive at-tributes{1,2,3,5,5,6,6,8}, the only optimal partition for(4,5)-anonymity isG1 = {1,2,5,6}
andG2={3,5,6,8}, whereG1’s range(1,6)overlaps withG2’s range(3,8).
On the other hand, we observe that the minimum max-of-error problem has the following property.
Lemma 2.6.2. There exists an optimal(k, e)-anonymous partitionP ={G1, . . . , Gm}forDsuch
that there are no more than two groups whose ranges overlap with each other. In other words, there is no value in the domain of the sensitive attribute such that the value falls into the ranges of more than two groups.
Proof. First, by a similar proof to that of lemma 2.6.1, no group’s range is included by that of another.
Second, given any optimal partition, suppose there are three groupsGi,Gj andGl,i <
j < l, whose ranges overlap with each other. Then we must havexmaxj ≥ xminl. Otherwise, sincexmaxi ≤ xmaxj, we have the ranges of Gi andGl are not overlapping. We thus can divide
all the items inGj into two groups, Gj1 including those less thanxminl, andGj2 including those
greater than or equal toxminl. We mergeGj1 withGi andGj2 withGl. The ranges ofGiandGl
LetP ={G1, . . . , Gm}be an optimal(k, e)-anonymous partition that satisfies the above
property. Consider the first two groupsG1andG2. If the ranges ofG1andG2 do not overlap, then
G1contains all the values fromxmin1 =x1toxmax1 inD. Then the remaining groups in fact form an optimal partition for the rest of the itemsxmax1+1, . . . , xn.
On the other hand, suppose the ranges of G1 and G2 overlap, which means min2 <
max1. We divideG2 into two parts, the former part G2f which includes those items less than or
equal to xmax1, and the latter partG2l which includes those items greater thanxmax1. Lett be the smallest index of items inDsuch thatxt > xmax1. According to lemma 2.6.2,G1 andG2f combined together include all the values inD that are less thanxt. Further, we havext ∈ G2l.
Otherwise, supposext ∈ Gi, i > 2. Thenxt must be the smallest value ofGi. This allows us to mergeG2f with G1 andG2l withGi. The resulting partition P0 is still optimal, and there is no
overlap between the first two groups inP0.
Based on the above observation, we have that G2l, G3, . . . , Gm forms a partition of
xt, xt+1, . . . , xn. Except G2l, every group is (k, e)-anonymous. For G2l, it has at least k −d
distinct values where dis the number of distinct values inG2f. Further, the width of the range
ofG2l is no less thane−r, where r = xt−xmin2. In other words, given any partition P0 = {G0
1, . . . , G0z} of xt, . . . , xn, such that G10 is (k−d, e−r)-anonymous and the rest are (k, e)
-anonymous, if the maximum ofE(G0
1) +r, E(G02), . . . , E(G0z) is minimized, then the partition
{G1, G2f∪G01, G20, . . . , G0z}also forms an optimal(k, e)-anonymous partition ofD.
Therefore, we study the following more general optimization problem:
Problem 2.6.2. Givendandr, obtain a partitionP ={G1, . . . , Gm}ofD, whereG1is(k−d, e−
r)-anonymous and the rest groups are(k, e)-anonymous, such thatmax(E(G1)+r, E(G2), . . . , E(Gm))
is minimized.
Clearly, the minimum max-of-error problem is a special case of the above problem where d= 0andr = 0.
The above argument shows that the above problem has the optimal substructure property. Intuitively, for each possiblemax1 andmin2, we move as many values betweenxmin2 andxmax1 as possible toG2f, the first part ofG2, as long asG1still hask−ddistinct values. After this step, we denote the number of distinct values inG2f as#(min1, max1, min2, d), as it is determined by these four parameters. Letg(d, r, i)denote the minimum cost way to partitionxi, . . . , xnsuch that
Algorithm 2Optimal partition for the minimum max-of-error problem fori=nto 1do
ford= 0 todistinct(1, n)do forj= 0 toido
r=xi−xj
ifdistinct({xi, . . . , xn})< k−dorxn−xi< e−rthen
g[i][d][r]=INF continue end if
g[i][d][r]=xn−xi
formax1 =iton−1do
ifdistinct({xi, . . . , xmax1)< k−dthen continue;
end if
formin2 =i+ 1tomax1+ 1do
d1= #(i, max1, min2, d)
r1=xmax1+1−xmin2
m=max(xmax1−xi+r, g[max1+ 1][d1][r1]) ifm < g[i][d][r]then
g[i][d][r] =m end if
end for end for end for end for end for
Algorithm 2 shows the dynamic programming solution to the minimum max-of-error problem. For simplicity, algorithm 2 only returns the maximum error of an optimal partition. With some simple bookkeeping, the algorithm can be easily modified to return the items contained in each group.
desirable to design efficient approximation algorithms for the problem. For this purpose, we limit our search space to those partitions whose groups do not overlap with each other. In other words, we consider the following problem:
Problem 2.6.3. Obtain a(k, e)-anonymous partitionP ={G1, . . . , Gm}ofD, where the ranges of
any two groups in the partition do not overlap, such thatmax(E(G1), . . . , E(Gm))is minimized.
We call the above problem the non-overlapping minimum max-of-error problem. With a similar argument to that of the optimal solution to the minimum sum-of-error problem, it is not hard to see that this problem also has the optimal substructure property, and thus can be solved by dynamic programming withO(n2)in both space and time complexities.
Theorem 4. LetPandP0be the optimal partitions ofDof the minimum max-of-error problem and the non-overlapping minimum max-of-error problem. Thenmin max error(P0)
≤2·min max error(P).
Proof. LetP = {G1, . . . , Gm}. According to lemma 2.6.2, overlapping ranges can only happen
between adjacent groups. We examine each group by order. If the range ofG1does not overlap with
that ofG2, we continue toG2. Otherwise,G2can be divided into two groups,G2f which includes those no less thanxmin3, andG2l which includes those greater thanxmin3 (G2l may be empty if the ranges ofG2 andG3 do not overlap). We mergeG2f intoG1 andG2l intoG3. Note that the
range ofG3does not change, while the range ofG1is at most increased bymax of error(P). We
next move toG3and check whether it overlaps withG4. We continue this process untilGm. The
resulting partitionP0does not contain overlapping groups, andmax of error(P0)is at most twice max of error(P).