Avoidance of Long Mononucleotide Repeats in Codon Pair Usage
Tingting Gu,*
,1Shengjun Tan,*
,1Xiaoxi Gou,* Hitoshi Araki*
,†,2and Dacheng Tian*
*State Key Laboratory of Pharmaceutical Biotechnology, Department of Biology, Nanjing University, Nanjing 210093, China and †
Department of Fish Ecology and Evolution, Eawag, Swiss Federal Institute of Aquatic Science and Technology, Center of Ecology, Evolution and Biogeochemistry, 6047 Kastanienbaum, Switzerland
Manuscript received July 20, 2010 Accepted for publication August 27, 2010
ABSTRACT
Protein is an essential component for life, and its synthesis is mediated by codons in any organisms on earth. While some codons encode the same amino acid, their usage is often highly biased. There are many factors that can cause the bias, but a potential effect of mononucleotide repeats, which are known to be highly mutable, on codon usage and codon pair preference is largely unknown. In this study we performed a genomic survey on the relationship between mononucleotide repeats and codon pair bias in 53 bacteria, 68 archaea, and 13 eukaryotes. By distinguishing the codon pair bias from the codon usage bias, four general patterns were revealed: strong avoidance of five or six mononucleotide repeats in codon pairs; lower observed/expected (o/e) ratio for codon pairs with C or G repeats (C/G pairs) than that with A or T repeats (A/T pairs); a negative correlation between genomic GC contents and the o/e ratios, particularly for C/G pairs; and avoidance of C/G pairs in highly conserved genes. These results support natural selection against long mononucleotide repeats, which could induce frameshift mutations in coding sequences. The fact that these patterns are found in all kingdoms of life suggests that this is a general phenomenon in living organisms. Thus, long mononucleotide repeats may play an important role in base composition and genetic stability of a gene and gene functions.
A
MONG the many components of life, protein is most essential because living organisms use pro-teins not only for body structuring but also for its functioning. After the discovery of the genetic code for protein biosynthesis (Crick et al. 1961), redundancy in the genetic code attracted great attention. Highly biased use of synonymous codons is one of them, and the codon usage bias is common not only among spe-cies but also within spespe-cies (Grosjeanand Fiers1982; Akashi2001). Previous studies showed that codon us-age bias is linked to several factors, such as efficiency and accuracy of translation (Robinson et al. 1984; Bulmer1991; Akashi1994; Plotkinet al.2004), com-positional bias (Mutoand Osawa1987; McLeanet al. 1998), and genome size or other nonselective forces (Lawrenceand Ochman1998;dosReiset al.2004).One additional factor is the sequence environment. It is known that nucleotides surrounding a codon can influence the codon usage preference, called context-dependent codon bias (Yarusand Folley1985). The context-dependent codon bias affects the efficiency and accuracy of translation (Taniguchi and Weissmann 1978; Irwin et al. 1995) and the suppression of both
premature stop codons and missense codons (Bossi and Ruth 1980; Murgolaet al. 1984). Reflecting the context-dependent codon bias, a strong codonpairbias is detected in both prokaryotic and eukaryotic genomes (Gutmanand Hatfield1989; Buchanet al.2006; Tats et al. 2008). It has been suggested that codon pair preference is influenced by all three nucleotides of the ribosomal A-site codon and the third nucleotide of the P-site codon (Buchan et al. 2006). Therefore, tRNA geometry within the ribosome was presumed to be the key factor governing genomic codon pair patterns, as it might enhance the fidelity and/or rate of translation.
A mononucleotide repeat is a homogeneous run of the same nucleotides. Potentially deleterious effects of a mononucleotide repeat in coding sequences (CDS) have been pointed out: the mononucleotide repeats in CDS are prone to transcriptional and translational slippage, which leads to functional disruption of the corresponding gene products (Wagner et al. 1990; Gurvich et al. 2003; Baranov et al. 2005); a strong association between mononucleotide repeats and the occurrence of insertion/deletion (indel) during the DNA replication process will elevate the risk of frame-shift mutations (Strauss 1999), which might have severe fitness consequences. The list of diseases result-ing from changes of unstable repeats continues to grow (Gatchel and Zoghbi 2005). In addition, previous studies suggested that in long mononucleotide runs, errors during the process of DNA synthesis are easier to Supporting information is available online athttp://www.genetics.org/
cgi/content/full/genetics.110.121137/DC1.
1These authors contributed equally to this work. D.T. and H.A. are equal senior authors.
2Corresponding author:Seestrasse 79, 6047 Kastanienbaum, Switzerland. E-mail: [email protected]
1997). C/G mononucleotide runs are found to be more unstable than A/T runs inEscherichia coli(Sagheret al. 1999), yeast (Harfeand Jinks-Robertson2000), and mammalian cells (Boychevaet al.2003). Indeed, some of the mononucleotide repeats, such as GGGGGn, are found to be among the unpreferred codon pairs in various species (Tatset al.2008). Therefore, the num-ber of mononucleotide repeats, as well as their base compositions (A/T runs or C/G runs), might affect the occurrence of indels and the genetic stability of CDS.
In this study, we conducted a systematic survey of 134 genomes in bacteria, archaea, and eukaryotes to evalu-ate the potential influence of the mononucleotide repeats on codon pair preference. We used the ob-served/expected (o/e) ratio of codon pairs with mono-nucleotide repeats to distinguish the codon pair bias from the codon usage bias. Our results suggest a strong avoidance of long (five or six) mononucleotide runs in CDS, most likely due to natural selection against the high mutability, which may shed new light on the forces exerted on both codon and codon-pair usage.
MATERIALS AND METHODS
Databases: To cover a diverse range of species, 13 eukary-otic, 53 bacterial, and 68 archaeal genomes were selected from online databases (supporting information,Table S1,Table S2, andTable S3). In addition, four sequence alignments (Sac-charomyces cerevisiaeandS. paradoxus,Caenorhabditis elegansand C. briggsae, Drosophila melanogaster and D. yakuba, and Homo sapiens and Mus musculus) were obtained from the UCSC Genome Informatics website (http://hgdownload.cse.ucsc. edu). Protein-coding regions were determined on the basis of the annotations in these databases. The 13 eukaryotic genomes, including fungi, plants, and animals, were ran-domly selected to represent a wide range of species (Table S1). The 53 bacterial genome sequences were selected on the basis of a criterion of.4 Mb to give sufficient data (Table S2), whereas this criterion was not applied to the archaeal genomes because of their small genome sizes (2.24 Mb on average;Table S3).
Studied codon pairs:We first analyzed codon pairs that have mononucleotides spanning the two codons (sense:sense pairs, Table S4). Among 4096 (¼ 46) possible codon pairs, 928 sense:sense pairs contained two to six mononucleotides in the pair junction, when excluding the pairs containing a stop codon. A/T pairs (codon pairs with A’s or T’s spanning two codons) or C/G pairs (codon pairs with C’s or G’s spanning two codons) were analyzed together not only because A and T or C and G are parallel in the nucleotide chain position, but also because the level of bias was similar (Figure S1). Codon pairs with the same number and composition (A/T or C/G) of mononucleotide runs in the pair junction were classified as a group.
In the analysis, codon pairs containing mononucleotide repeats other than those spanning the two codons are excluded because in such codon pairs the mononucleotide run size is not affected by the adjacent codon. For example, the number of longest mononucleotide repeats in codon pair AAATCG is three, which is the same as the single codon AAA.
the actual target, independent of the adjacent codons. We refer this as codon bias, not codon pair bias.
To further confirm the effect of mononucleotide repeats on codon pair bias, we also analyzed synonymous codon pairs, which are defined as a codon pair that has a choice of nucleotide bases that alter the number of mononucleotide repeats (from two to six) without changing the encoded amino acid sequences (Table S5). The possible longest mono-nucleotide run in the codon pair was two, three, five or six (Table S5). For example, codon pairs encoding dipeptide lysine:lysine had four possible compositions: AAGAAG, AA-GAAA, AAAAAG, and AAAAAA, for which the numbers of the longest mononucleotide runs were two, three, five, and six, respectively.
The two types of codon pairs above have a partial overlap especially when we consider long mononucleotide repeats. Particularly, six mononucleotide repeats (6N) are entirely shared by both types of codon pairs (Table S4andTable S5). For shorter mononucleotide runs (#5N), however, these types of codon pairs generally include different sets of codon pairs. We also analyzed sense:sense codon pairs excluding synony-mous codon pairs.
Normalizing codon pair frequencies:Codon pair bias could be attributed to codon usage bias. To eliminate this effect, we normalized the expectation of codon pair occurrence by the frequency of used codons (Gutman and Hatfield 1989; Buchanet al.2006). First we calculated the observed (oij) and the expected number (eij) of a codon pair (codoniand codon j), on the basis of the estimated codon frequencies in thekth open reading frame (ORFk) (Buchanet al. 2006),
eij;k ¼ cicjNp N2tot
;
where ci is the observed count of codon i, Ntot is the total number of codons, andNp¼ Ntot 1 represents the total number of codon pairs in the ORFk. The effect of dipeptide bias on codon pairing was removed by normalizing the expected values of each codon pair, to generateenor,
enor ¼ enorij;k ¼ P
mnðodip;mnÞ P
mnðedip;mnÞ3eij;k ¼ P
mnðodip;mnÞ P
mnðcmcn=N2 tot3NpÞ
3eij;k
(Gutman and Hatfield 1989; Buchan et al. 2006), where odip,mnandedip,mnare the observed and expected codon pair counts, respectively, encoding dipeptide mn. Observed and expected codon pair counts were then summed up at the genomic level. The numbers of codon pairs were calculated using a Perl script.
Because the codon pairs in each type encode the same dipeptide for synonymous pairs, the sum of the observed counts (enor) is equal to the sum of expectation. For sense: sense pairs, on the other hand, the sum of the observed counts is equal to the sum of expectation only when all 4096 possible codon pairs are included (the 0–1 mononucleotides in the pair junction).
Analyzing codon pair bias:Theo/eratio for each group of codon pairs with the same number (p) of mononucleotideQ in the pair junction was calculated as follows:
o=epQ ¼ P
oij P
eij:
To measure the difference between the observed and expected values of a single codon pair, a normalized offset value defined asrwas calculated,
r ¼ oij eij Dexp
¼ ffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffioij eij eij 3ð1 eij=NtotÞ p
(Boychevaet al.2003), where Dexpis the expected random deviation. Thervalue is considered to be significant when the absolute value is.2.0 (Boychevaet al.2003).
Analyzing codon pair usage in conserved regions: A Perl script was written to calculate the number of nucleotide substitutions and indels throughout the following combina-tions of alignments:S. cerevisiae and S. paradoxus, C. elegans andC. briggsae,D. melanogasterandD. yakuba, andH. sapiens andM. musculus.The average nucleotide divergence (D) was adjusted with the Jukes and Cantor correction ( Jukes and Cantor1969).
First, CDS were extracted according to the annotations ofS. cerevisiae, C. elegans, D. melanogaster, and H. sapiens, respec-tively. Then the CDS of each of the four comparisons were classified into three groups according toD. Each group had an equal length of sequences, and the one with the smallestD was regarded as the highly conserved region, while the one with the largestDwas the less conserved region. The observed and expected counts of each codon pair were analyzed in both highly and less conserved regions (see Table S6 for details).
RESULTS
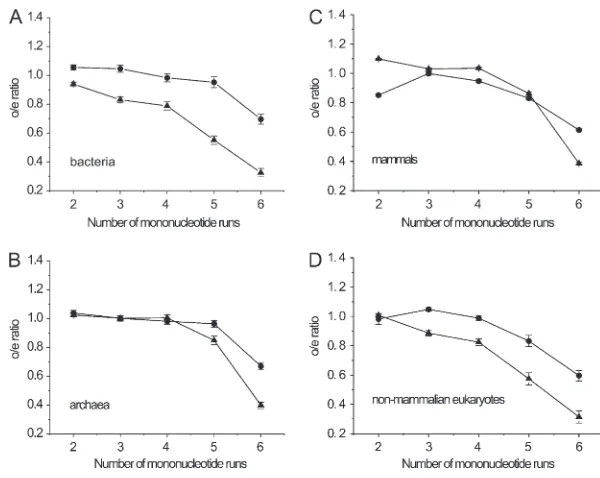
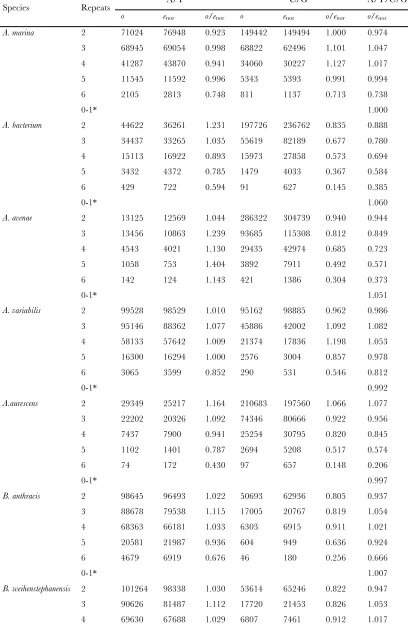
Avoidance of long mononucleotide runs in codon pairs: In the sense:sense codon pairs, theo/eratio was apparently less than one in codon pairs with long mononucleotide runs, such as five- or six-mononucleo-tide repeats for C/G pairs (o/e5C/Goro/e6C/G) and 6N for A/T pairs (o/e6A/T, Figure 1). The geometric mean of theo/eratio for the 6N pairs was 0.528 in eukaryotes, 0.488 for bacteria, and 0.596 for archaea (Table S7,
Table S8, andTable S9). The ratios for codon pairs with shorter runs (,4N mononucleotides) were significantly larger than those for pairs with longer runs (.4N mono-nucleotides) (P , 0.05,t-test). The consistently lower number of observations than expected values (o/e,1.0 for the 6N pairs in 133/134 genomes, or 99.2%;Figure S2 and Table S7, Table S8, and Table S9) suggests a universal avoidance of long mononucleotide runs for sense:sense codon pairs in these organisms. The only exception was Geobacter uraniireducens, which showed o/e¼1.084 for the 6N pairs (Table S8).
In addition, theo/eratios for codon pairs with long A/T mononucleotide runs (o/e5A/T or o/e6A/T) were significantly higher than those for C/G pairs in both prokaryotes and eukaryotes (P , 0.05, paired t-test, except for o/e5A/T vs. o/e5C/G in mammals, discussed below). For example, in eukaryotic genomes, o/e6A/T was 1.8 times higher thano/e6C/G, where theo/e6C/Gwas only 0.335. This result indicates that the 6C/G is the most unfavorable of codon pairs.
Synonymous codon pairs showed similar patterns (Figure S3,Table S10,Table S11, andTable S12), and the elimination of synonymous codon pairs from sense:-sense codon pairs resulted in virtually the same patterns (Figure S4). The negative relationships between theo/e ratio and the number of mononucleotide runs in both sense:sense and synonymous codon pairs further sup-port the consistent avoidance of long mononucleotide runs in codon pairs in the genome evolution of prokaryotes and eukaryotes.
Effect of prokaryotic GC content on the o/e ratio: The results above revealed a stronger avoidance of codon pairs with long C/G runs relative to A/T runs. Because genomes with higher GC content would con-tain more C/G pairs under random expectation, we evaluated the effect of genomic GC content on the tolerance of genomes to the C/G mononucleotide runs. The wide range of GC content in prokaryotic genomes (29.9–72.8% in bacteria and 27.6–68.0% in archaea) provided an opportunity for investigating a correlation betweeno/eratio and GC content.
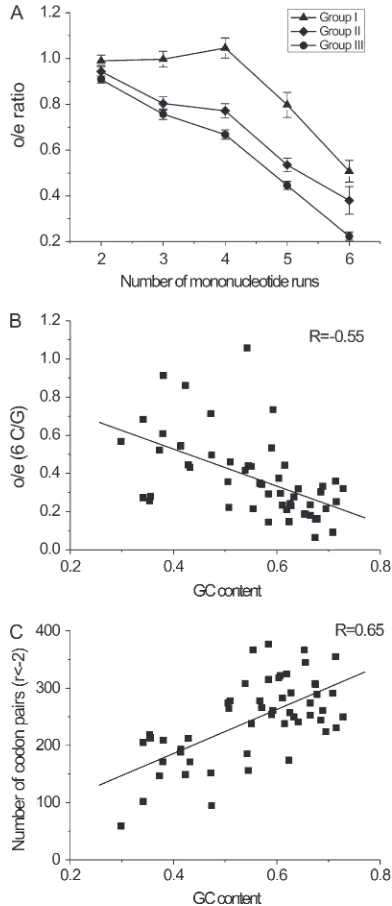
When the 53 bacterial genomes were classified into three groups depending on GC content—group I (GC%, 50%), group II (50% # GC%, 60%), and group III (GC% $ 60%)—their o/e ratios for sense: sense pairs were quite different (Figure 2A). The o/e ratios for C/G pairs in group I were significantly higher than those in group III (P,0.05,t-test). For C/G pairs, theo/eratios for group II were between those of groups I and III. Notably, o/e6C/G for the high GC content, group III decreased to a very low value (0.223, Figure 2A). This observation suggested that the avoidance of long C/G mononucleotide runs was much stronger in genomes with higher GC content. This propensity was also shown through the negative correlation between GC content of individual genomes and theiro/eratios for C/G codon pairs,e.g.,o/e6C/Gin Figure 2B (R¼ 0.550, P,0.0001), and the other ratios inFigure S9B (P,0.05). For A/T pairs, on the other hand, the negative relation-ship between the o/eratio and GC content was much weaker (Figure S5 and Figure S9A). All the patterns observed in bacteria were also present in three groups of the archaeal genomes (Figure S6 andFigure S8, A–C; group I with GC%,40%, group II with GC% ranging from 40 to 50%, and group III with GC%$50%).
The normalized offset value (r) measures the differ-ence between the observed and the expected counts of a certain codon pair (Boychevaet al.2003). Our calcu-lations showed that the number of C/G codon pairs, in which the observed counts are significantly less than expected (r # 2), is positively correlated with the genomic GC content (Figure 2C;P ,0.0001), reflect-ing the strong propensity of genomes with higher GC contents to avoid C/G pairs. According to the linear regression, in the bacterial genomes with GC content of
70%, the proportion of significantly underrepresented C/G pairs with mononucleotides in pair junctions was 55.2% (274/496), whereas it was only 28.0% (139/496) in the genomes with low GC content (30%). The number of A/T pairs, which are significantly less than expected, was weakly correlated with genomic GC content in prokaryotes (Figure S5A andFigure S7A).
to produce indels, a lower o/e ratio was expected in more conserved CDS. Since 6Ns had the smallest o/e ratios in analyzed codon pairs with mononucleotides in pair junctions in eukaryotes (Figure 1 andTable S7), o/e6N was analyzed in conserved regions in the four alignments of the eight genomes (seematerials and methods).
Indeed, o/e6N was significantly smaller in highly conserved than in less-conserved regions in all align-ments of nonmammalian eukaryotes (Figure 3A, P , 0.01 by chi-square test). Moreover, the 6N codons appeared less frequently in highly conserved regions in those three comparisons (Figure 3B). In the mam-malian sequences, no such differences were observed. Although o/e6N was slightly smaller in less-conserved regions in the human–mouse comparisons, the differ-ence was not significant.
DISCUSSION
The biased usage of codons or codon pairs is a common phenomenon in a wide range of species (Gutmanand Hatfield 1989; Buchanet al.2006). A variety of factors, selective or nonselective, might be responsible for such bias. For example, the synonymous codons decoded in the ribosomal A site by the same tRNA exhibit significantly similar ribosomal P-site pair-ing preference (Buchanet al.2006). In other words, the codon pair preference is primarily determined by the interplay between nucleotides cP3 (the third nucleotide of the codon positioned at the ribosomal P site) and cA1/cA2 (the first/second nucleotide of the codon positioned at the ribosomal A site) (Buchanet al.2006). Our results suggest that the avoidance of mononucleo-tide repeats in pair junctions is an additional explana-tion. For codon pairs encoding a certain dipeptide, nucleotides cP3 and cA3 are degenerate, and cP3 is more important in determining the mononucleotides run size. The interplay between cP3 and cA1/cA2 largely determines the mononucleotide run size in the degenerate codon pairs. Thus, the deleterious effect of indels and the consequent avoidance of long mono-nucleotide repeats in CDS can contribute to the close connection between cP3 and cA1/cA2 as well.
In this study, we confirmed a deficit of codon pairs with long mononucleotide runs relative to those with
short mononucleotide runs in a variety of species by analyzing two kinds of codon pairs. This result is also consistent with previous studies, such as Tats et al. (2008) in which certain mononucleotide repeats are identified as avoided codon pairs among several other kinds (e.g., nnTAnn). In addition, we revealed three additional patterns: higher o/e ratio for A/T codon pairs than for C/G pairs; negative correlation between GC content of individual genomes and theiro/eratios, particularly for C/G codon pairs; and lower o/e ratio for codon pairs with long mononucleotide runs in conserved coding sequences. These patterns cannot be explained by the simplest tRNA geometry hypothesis. InE. coli, for example, the deficit of long mononucleo-tide A/T runs in codon pairs cannot be elucidated by tRNA geometry because the synonymous codons, AAG and AAA, and TTC and TTT, are recognized by the same tRNA.
Natural selection on mutability of codons or codon pairs might be an alternative explanation. The high frequency of indel occurrence has been confirmed to be closely associated with simple nucleotide repeats (Strauss 1999). The previous investigation of the mutability of mononucleotide runs in yeast showed that the mutation rate of 6N mononucleotide repeats was
10-fold of that of 2N or 3N (Greene and Jinks
-Robertson 1997). The high indel mutability of long mononucleotide runs and the severely detrimental effect of coding indels can enforce the choice of the codon or codon pair usage. Consequently, the avoid-ance of long mononucleotide runs in coding sequences will minimize the change of coding function, particu-larly in highly conserved regions. Thus, this model can explain a scarcity of long runs in codon pairs and why the conserved genes have less codon pairs with long mononucleotide runs.
runs may be due to stabilization of a stacked interme-diate (Sagheret al. 1999). Both the DNA polymerase fidelity (primarily avoidance of slippage) and the efficiency of the removal of frameshift intermediates by the MMR system are affected by the composition of mononucleotide runs; DNA polymerase slippage occurs more often while the MMR system removes frameshift intermediates less efficiently in C/G than in A/T mononucleotide runs (Gragget al.2002). Considering the greater ability to produce indels, long C/G runs are less favored in those regions sensitive to frameshifts and their appearance would be underrepresented. In con-trast, A/T mononucleotide runs would exert less in-fluence on the maintenance of sequence stability. In higher eukaryotes, there are no experimental data on the mutability of mononucleotides, but it has been reported that the mutation rate of G17repeat sequences was much higher than those of A17 and (CA)17 in mismatch repair-proficient embryonic mouse fibro-blasts (Boyeret al.2002).
If the avoidance of slippages from long mononucle-otide runs contributes to the biased usage of codon pairs, it is understandable that there is a negative correlation between GC content of individual genomes and theiro/e ratios because the genomes with higher GC content are expected to have a higher possibility of forming long mononucleotide sequences. In the three bacterial groups with GC%,50%, 50%,GC%,60%, and GC% . 60%, the expected numbers of six C/G pairs were 466, 745, and 1406 (P¼0.057,P,0.01, and P,0.05 for comparison of groups 1 and 2, 1 and 3, and 2 and 3, respectively,t-test), whereas the observed counts were roughly the same, 285, 329, and 361, respectively (P¼0.5240.787 for comparison of groups byt-test). The same tendency was observed in archaea as well. Therefore, prokaryotes may have evolved a mechanism to control the mutability of their genomes.
All analyzed genomes have o/e6C/G less than one except G. uraniireducens. This bacterium was isolated from subsurface sediment undergoing uranium bio-remediation. This species reduces metals including uranium with acetate and other organic acids serving as the electron donor (Shelobolina et al.2008). It is generally accepted that uranium induces DNA damage and subsequent high mutation rate through a combi-nation of chemical and radiological effects (Stearns et al. 2005). G. uraniireducens may be able to tolerate more 6C/G codon pairs, due to its higher tolerance of mutational constraints or the advantage of rapid evolu-tion for adaptaevolu-tion to its harsh environment.
A more frequent occurrence of indels in longer C/G mononucleotides may partly explain why some amino acids have more synonymous codons than others. It has been shown that the genetic code is not a random assignment of codons to amino acids and that the code
strategy to avoid mutation would be a reduced usage of codons with higher GC content, potentially to minimize the risk of longer C/G runs. To achieve this goal, such codons would have evolved as synonymous codons that are used less often. In fact, this hypothesis can be tested by a GC analysis for all codons. There are 8 amino acids
with $4 synonymous codons. In these codons, the
average GC content is as high as 68.1%, which is significantly.33.3% (P,0.001,t-test), the GC content of the other 12 amino acids with ,3 synonymous codons. Notably, only 6 codons of 23 for these 12 amino acids have two GCs each, while 26/38 such codons are found for the 8 amino acids with .3 synonymous codons. In addition, the start and stop codons have only one or no G. Thus, almost all AT-rich codons are used for the amino acids with limited synonymous codons or stop/start codons. Clearly, these codons have little chance of forming long C/G mononucleotides and therefore a higher opportunity to maintain stable gene function.
The indel-mutability model can shed light on the usage of codons and codon pairs. Our results suggest that the avoidance of long mononucleotides can main-tain the conserved gene function by preventing indel occurrence in coding sequences. This may be the best way to minimize mutation by constructing an appropri-ate gene composition,e.g., the choice of GC content and specific nucleotide combination. In highly conserved genes, on which mutations are supposed to be highly deleterious, the maximal avoidance of long mononu-cleotide repeats might be essential. Our results on the conserved regions (Figure 3) are very consistent with this scenario.
One exception was the case of mammalian genomes, which showed no consistent pattern compared to the other comparisons (Figure 3). Further study is required to understand the cause of the different patterns in mammals, although less efficient natural selection due to the smaller effective population size in mammals relative to invertebrates and prokaryotes, typically at the magnitude of one or two orders (Lynchand Conery 2003), might explain the phenomenon.
slippage might be a consequence of adaptive evolution, which can explain why this mechanism works well for long C/G runs but less well for the same long A/T mononucleotide sequences. Theo/e ratio, particularly the o/eC/G ratio, could be used as a measure of the mutation potential for individual or multiple genes in a species. Therefore, these ubiquitous and selectively maintained mononucleotide runs can greatly contrib-ute to the high genetic diversities and to the molecular evolution. Analysis of the distribution of long mono-nucleotide runs will provide information for the evolu-tion of genes and genomes. With recent works that have revealed the possible causes for codon bias, our study suggests that the role played by mononucleotide runs in such bias can be very important in shaping genetic evolution.
We thank Gary Stormo and two anonymous reviewers for helpful comments on the earlier version of this manuscript. This study was supported by the National Science Foundation of China (30930049) (to D.T.) and the Swiss National Science Foundation (31003A_ 125213) (to H.A.).
LITERATURE CITED
Akashi, H., 1994 Synonymous codon usage inDrosophila melanogaster: natural selection and translational accuracy. Genetics136:927– 935.
Akashi, H., 2001 Gene expression and molecular evolution. Curr. Opin. Genet. Dev.11:660–666.
Baranov, P. V., A. W. Hammer, J. Zhou, R. F. Gestelandand J. F. Atkins, 2005 Transcriptional slippage in bacteria: distribution in sequenced genomes and utilization in IS element gene expres-sion. Genome Biol.6:R25.
Bossi, L., and J. R. Ruth, 1980 The influence of codon context on genetic code translation. Nature286:123–127.
Boycheva, S., G. Chkodrovand I. Ivanov, 2003 Codon pairs in the genome of Escherichia coli. Bioinformatics19:987–998. Boyer, J. C., N. A. Yamada, C. N. Roques, S. B. Hatch, K. Riesset al.,
2002 Sequence dependent instability of mononucleotide mi-crosatellites in cultured mismatch repair proficient and deficient mammalian cells. Hum. Mol. Genet.11:707–713.
Buchan, J. R., L. S. Aucottand I. Stansfield, 2006 tRNA proper-ties help shape codon pair preferences in open reading frames. Nucleic Acids Res.34:1015–1027.
Bulmer, M., 1991 The selection-mutation-drift theory of synony-mous codon usage. Genetics129:897–907.
Chen, J. Q., Y. Wu, H. Yang, J. Bergelson, M. Kreitman et al., 2009 Variation in the ratio of nucleotide substitution and indel rates across genomes in mammals and bacteria. Mol. Biol. Evol. 26:1523–1531.
Crick, F. H., L. Barnett, S. Brenner and R. J. Watts-Tobin, 1961 General nature of the genetic code for proteins. Nature 192:1227–1232.
dosReis, M., R. Savvaand L. Wernisch, 2004 Solving the riddle of codon usage preferences: a test for translational selection. Nucleic Acids Res.32:5036–5044.
Du, J., T. Gu, H. Tian, H. Araki, Y. H. Yanget al., 2008 Grouped nucleotide polymorphism: a major contributor to genetic varia-tion in Arabidopsis. Gene426:1–6.
Freeland, S. J., and L. D. Hurst, 1998 The genetic code is one in a million. J. Mol. Evol.47:238–248.
Gatchel, J. R., and H. Y. Zoghbi, 2005 Diseases of unstable repeat expansion: mechanisms and common principles. Nat. Rev. Genet.6:743–755.
Gragg, H., B. D. Harfe and S. Jinks-Robertson, 2002 Base composition of mononucleotide runs affects DNA polymerase
8762.
Greene, C. N., and S. Jinks-Robertson, 1997 Frameshift inter-mediates in homopolymer runs are removed efficiently by yeast mismatch repair proteins. Mol. Cell. Biol. 17: 2844– 2850.
Grosjean, H., and W. Fiers, 1982 Preferential codon usage in pro-karyotic genes: the optimal codon-anticodon interaction energy and the selective codon usage in efficiently expressed genes. Gene18:199–209.
Gurvich, O. L., P. V. Baranov, J. Zhou, A. W. Hammer, R. F. Gesteland et al., 2003 Sequences that direct significant levels of frameshift-ing are frequent in codframeshift-ing regions of Escherichia coli. EMBO J. 22:5941–5950.
Gutman, G. A., and G. W. Hatfield, 1989 Nonrandom utilization of codon pairs in Escherichia coli. Proc. Natl. Acad. Sci. USA86: 3699–3703.
Harfe, B. D., and S. Jinks-Robertson, 2000 Sequence composition and context effects on the generation and repair of frameshift intermediates in mononucleotide runs in Saccharomyces cerevi-siae. Genetics156:571–578.
Irwin, B., J. D. Heckand G. W. Hatfield, 1995 Codon pair utiliza-tion biases influence translautiliza-tional elongautiliza-tion step times. J. Biol. Chem.270:22801–22806.
Jukes, T. H., and C. R. Cantor, 1969 Mammalian protein metabo-lism, pp. 21–132 inEvolution of Protein Molecules.Academic Press, New York.
Kroutil, L. C., K. Register, K. Bebenek and T. A. Kunkel, 1996 Exonucleolytic proofreading during replication of re-petitive DNA. Biochemistry35:1046–1053.
Lawrence, J. G., and H. Ochman, 1998 Molecular archaeology of the Escherichia coli genome. Proc. Natl. Acad. Sci. USA 95: 9413–9417.
Lynch, M., and J. S. Conery, 2003 The origins of genome complex-ity. Science302:1401–1404.
McLean, M. J., K. H. Wolfeand K. M. Devine, 1998 Base compo-sition skews, replication orientation, and gene orientation in 12 prokaryote genomes. J. Mol. Evol.47:691–696.
Murgola, E. J., F. T. Pageland K. A. Hijazi, 1984 Codon context effects in missense suppression. J. Mol. Biol.175:19–27. Muto, A., and S. Osawa, 1987 The guanine and cytosine content of
genomic DNA and bacterial evolution. Proc. Natl. Acad. Sci. USA 84:166–169.
Plotkin, J. B., H. Robinsand A. J. Levine, 2004 Tissue-specific co-don usage and the expression of human genes. Proc. Natl. Acad. Sci. USA101:12588–12591.
Robinson, M., R. Lilley, S. Little, J. S. Emtage, G. Yarranton et al., 1984 Codon usage can affect efficiency of translation of genes in Escherichia coli. Nucleic Acids Res. 12: 6663– 6671.
Sagher, D., A. Hsuand B. Strauss, 1999 Stabilization of the inter-mediate in frameshift mutation. Mutat. Res.423:73–77. Shelobolina, E. S., H. A. Vrionis, R. H. Findlayand D. R. Lovley,
2008 Geobacter uraniireducens sp. nov., isolated from subsur-face sediment undergoing uranium bioremediation. Int. J. Syst. Evol. Microbiol.58:1075–1078.
Stearns, D. M., M. Yazzie, A. S. Bradley, V. H. Coryell, J. T. Shelley et al., 2005 Uranyl acetate induces hprt mutations and uranium-DNA adducts in Chinese hamster ovary EM9 cells. Mutagenesis 20:417–423.
Strauss, B. S., 1999 Frameshift mutation, microsatellites and mis-match repair. Mutat. Res.437:195–203.
Sun, X., Y. Zhang, S. Yang, J. Q. Chen, B. Hohn et al., 2008 Insertion DNA promotes ectopic recombination during meiosis in Arabidopsis. Mol. Biol. Evol.25:2079–2083. Taniguchi, T., and C. Weissmann, 1978 Inhibition of Qbeta RNA
70S ribosome initiation complex formation by an oligonucleo-tide complementary to the 39terminal region of E. coli 16S ribo-somal RNA. Nature275:770–772.
Tats, A., T. Tenson and M. Remm, 2008 Preferred and avoided codon pairs in three domains of life. BMC Genomics9:463. Tian, D., Q. Wang, P. Zhang, H. Araki, S. Yanget al., 2008
pair and DNA polymerase proofreading yeast mutants. Mol. Cell. Biol.17:2859–2865.
Wagner, L. A., R. B. Weiss, R. Driscoll, D. S. Dunn and R. F. Gesteland, 1990 Transcriptional slippage occurs during elon-gation at runs of adenine or thymine in Escherichia coli. Nucleic Acids Res.18:3529–3535.
Zhu, L., Q. Wang, P. Tang, H. Arakiand D. Tian, 2009 Genome-wide association between insertions/deletions and the nucleotide diversity in bacteria. Mol. Biol. Evol.26:2353–2361.
Supporting Information
http://www.genetics.org/cgi/content/full/genetics.110.121137/DC1
Avoidance of Long Mononucleotide Repeats in Codon Pair Usage
Tingting Gu, Shengjun Tan, Xiaoxi Gou, Hitoshi Araki and Dacheng Tian
Copyright
Ó
2010 by the Genetics Society of America
FIGURE S7.—Correlation between usage of A/T codon pairs and GC-content in archaeal genomes. A: average o/e ratios in three archaea groups. GC contents of the three archaea groups are GC%<40% for archaea I, 40%<GC%<50% for archaea II, and GC%>50%, for archaea III respectively. B: Correlation between GC-content and the number of significantly
TABLE S1
Eukaryotic genome data used in this study
Species Download Website
Saccharomyces cerevisiae http://www.yeastgenome.org Caenorhabditis elegans http://genome.wustl.edu Drosophila melanogaster http://flybase.bio.indiana.edu Arabidopsis thaliana http://www.arabidopsis.org/ Oryza sativa http://rice.plantbiology.msu.edu/
Populus trichocarpa http://genome.jgi-psf.org/Poptr1_1/Poptr1_1.home.html
Vitis vinifera http://www.genoscope.cns.fr/externe/Download/Projets/Projet_ML/data/ Danio rerio http://www.sanger.ac.uk
Gallus gallus http://www.ncbi.nlm.nih.gov/Genomes/ Homo sapiens http://www.sanger.ac.uk
Pan troglodytes http://www.ncbi.nlm.nih.gov/Genomes/ Mus musculus http://www.sanger.ac.uk
TABLE S2
Bacterium strains used in this study
King Group Size (Mb)
GC content (%)
Acidobacteria bacterium Ellin345 B Acidobacteria 5.7 58.4 Solibacter usitatus Ellin6076 B Acidobacteria 10.0 61.9
Arthrobacter aurescens TC1 B Actinobacteria 4.6 62.4
Salinispora arenicola CNS-205 B Actinobacteria 5.8 69.5 Nocardia farcinica IFM 10152 B Actinobacteria 6.3 70.7
Mycobacterium vanbaalenii PYR-1 B Actinobacteria 6.5 67.8 Mycobacterium smegmatis str. MC2 155 B Actinobacteria 7.0 67.4
Frankia alni ACN14a B Actinobacteria 7.5 72.8
Rhodococcus sp. RHA1 B Actinobacteria 9.7 67.0
Roseobacter denitrificans OCh 114 B Alphaproteobacteria 4.3 58.9 Beijerinckia indica subsp. indica ATCC 9039 B Alphaproteobacteria 4.5 57.0
Methylobacterium radiotolerans JCM 2831 B Alphaproteobacteria 6.9 71.0 Bradyrhizobium sp. ORS278 B Alphaproteobacteria 7.5 65.5 Mesorhizobium loti MAFF303099 B Alphaproteobacteria 7.6 62.5 Rhizobium leguminosarum bv. Viciae 3841 B Alphaproteobacteria 7.8 55.0 Bacteroides fragilis NCTC 9343 B Bacteroidetes/Chlorobi 5.2 43.1 Flavobacterium johnsoniae UW101 B Bacteroidetes/Chlorobi 6.1 34.1 Bacteroides thetaiotaomicron VPI-5482 B Bacteroidetes/Chlorobi 6.3 42.9 Dechloromonas aromatica RCB B Betaproteobacteria 4.5 59.2 Polaromonas naphthalenivoransCJ2 B Betaproteobacteria 5.3 61.7 Acidovorax avenae subsp. Citrulli AAC00-1 B Betaproteobacteria 5.4 68.5 Delftia acidovorans SPH-1 B Betaproteobacteria 6.8 66.5 Chloroflexus aurantiacus J-10-fl B Chloroflexi 5.3 56.7 Roseiflexus castenholzii DSM 13941 B Chloroflexi 5.7 60.7 Roseiflexus sp. RS-1 B Chloroflexi 5.8 60.4 Herpetosiphon aurantiacus ATCC 23779 B Chloroflexi 6.7 50.9 Cyanothece sp. ATCC 51142 B Cyanobacteria 5.4 37.9
Microcystis aeruginosa NIES-843 B Cyanobacteria 5.8 42.3 Anabaena variabilis ATCC 29413 B Cyanobacteria 7.1 41.4
Nostoc sp. PCC 7120 B Cyanobacteria 7.2 41.3 Trichodesmium erythraeum IMS101 B Cyanobacteria 7.8 34.1 Acaryochloris marina MBIC11017 B Cyanobacteria 8.4 47.0 Geobacter uraniireducens Rf4 B Deltaproteobacteria 5.1 54.2 Desulfatibacillum alkenivorans B Deltaproteobacteria 6.5 54.5 Myxococcus xanthus DK 1622 B Deltaproteobacteria 9.1 68.9 Sorangium cellulosum 'So ce 56' B Deltaproteobacteria 13.0 71.4
Lysinibacillus sphaericus C3-41 B Firmicutes 4.8 37.1
Bacillus anthracis str. Ames B Firmicutes 5.2 35.4
Clostridium beijerinckii NCIMB 8052 B Firmicutes 6.0 29.9
Pectobacterium atrosepticum SCRI1043 B Gammaproteobacteria 5.1 51.0 Colwellia psychrerythraea 34H B Gammaproteobacteria 5.4 38.0 Serratia proteamaculans 568 B Gammaproteobacteria 5.5 55.0 Escherichia coli APEC O1 B Gammaproteobacteria 5.5 50.3 Pseudomonas entomophila L48 B Gammaproteobacteria 5.9 64.2 Pseudomonas putida KT2440 B Gammaproteobacteria 6.2 61.5 Pseudomonas syringae pv. tomato str. DC3000 B Gammaproteobacteria 6.5 58.3 Pseudomonas aeruginosa PA7 B Gammaproteobacteria 6.6 66.4 Pseudomonas fluorescens Pf-5 B Gammaproteobacteria 7.1 63.3 Hahella chejuensis KCTC 2396 B Gammaproteobacteria 7.2 53.9 Opitutus terrae PB90-1 B Other Bacteria 6.0 65.3 Rhodopirellula baltica SH 1 B Planctomycetes 7.1 55.4
TABLE S3
Archaeal strains used in this study
King Group Size
(Mb)
GC content (%)
Aeropyrum pernix K1 A Crenarchaeota 1.7 56.3
Archaeoglobus fulgidus DSM 4304 A Euryarchaeota 2.2 48.6 Archaeoglobus profundus DSM 5631 A Euryarchaeota 1.6 42.0 Caldivirga maquilingensis IC-167 A Crenarchaeota 2.1 43.1 Candidatus Korarchaeum cryptofilum OPF8 A Other Archaea 1.6 49.0 Candidatus Methanoregula boonei 6A8 A Euryarchaeota 2.5 54.5 Desulfurococcus kamchatkensis 1221n A Crenarchaeota 1.4 45.3
Halobacterium salinarum R1 A Euryarchaeota 2.0 68.0
Halobacterium sp. NRC-1 A Euryarchaeota 2.0 67.9
Halomicrobium mukohataei DSM 12286 A Euryarchaeota 3.1 65.6 Haloquadratum walsbyi DSM 16790 A Euryarchaeota 3.1 47.9 Halorhabdus utahensis DSM 12940 A Euryarchaeota 3.1 62.9 Haloterrigena turkmenica DSM 5511 A Euryarchaeota 3.9 65.8 Hyperthermus butylicus DSM 5456 A Crenarchaeota 1.7 53.7 Ignicoccus hospitalis KIN4/I A Crenarchaeota 1.3 56.5 Metallosphaera sedula DSM 5348 A Crenarchaeota 2.2 46.2 Methanobrevibacter smithii ATCC 35061 A Euryarchaeota 1.9 31.0 Methanocaldococcus fervens AG86 A Euryarchaeota 1.5 32.2 Methanocaldococcus jannaschii DSM 2661 A Euryarchaeota 1.7 31.4 Methanocaldococcus vulcanius M7 A Euryarchaeota 1.7 31.5 Methanocella paludicola SANAE A Euryarchaeota 3.0 54.9 Methanococcoides burtonii DSM 6242 A Euryarchaeota 2.6 40.8 Methanococcus aeolicus Nankai-3 A Euryarchaeota 1.6 30.0 Methanococcus maripaludis C5 A Euryarchaeota 1.8 33.0 Methanococcus maripaludis C6 A Euryarchaeota 1.7 33.4 Methanococcus maripaludis C7 A Euryarchaeota 1.8 33.3 Methanococcus maripaludis S2 A Euryarchaeota 1.7 33.1
Methanococcus vannielii SB A Euryarchaeota 1.7 31.3
Methanocorpusculum labreanum Z A Euryarchaeota 1.8 50.0 Methanoculleus marisnigri JR1 A Euryarchaeota 2.5 62.1
Methanopyrus kandleri AV19 A Euryarchaeota 1.7 61.2
Methanosaeta thermophila PT A Euryarchaeota 1.9 53.5
Methanosarcina acetivorans C2A A Euryarchaeota 5.8 42.7 Methanosarcina barkeri str. Fusaro_1 A Euryarchaeota 4.8 39.3
Methanosarcina mazei Go1 A Euryarchaeota 4.1 41.5
Natronomonas pharaonis DSM 2160 A Euryarchaeota 2.6 63.4 Nitrosopumilus maritimus SCM1 A Crenarchaeota 1.6 34.2 Picrophilus torridus DSM 9790 A Euryarchaeota 1.5 36.0 Pyrobaculum aerophilum str. IM2 A Crenarchaeota 2.2 51.4 Pyrobaculum arsenaticum DSM 13514 A Crenarchaeota 2.1 55.1 Pyrobaculum calidifontis JCM 11548 A Crenarchaeota 2.0 57.2 Pyrobaculum islandicum DSM 4184 A Crenarchaeota 1.8 49.6
Pyrococcus abyssi GE5 A Euryarchaeota 1.8 44.7
Pyrococcus furiosus DSM 3638 A Euryarchaeota 1.9 40.8 Pyrococcus horikoshii OT3 A Euryarchaeota 1.7 41.9 Staphylothermus marinus F1 A Crenarchaeota 1.6 35.7 Sulfolobus acidocaldarius DSM 639 A Crenarchaeota 2.2 36.7
Sulfolobus islandicus L.S.2.15 A Crenarchaeota 2.7 35.1
Sulfolobus islandicus M.14.25 A Crenarchaeota 2.6 35.1 Sulfolobus islandicus M.16.27 A Crenarchaeota 2.7 35.0 Sulfolobus islandicus M.16.4 A Crenarchaeota 2.6 35.0 Sulfolobus islandicus Y.G.57.14 A Crenarchaeota 2.7 35.4 Sulfolobus islandicus Y.N.15.51 A Crenarchaeota 2.8 35.3 Sulfolobus solfataricus P2 A Crenarchaeota 3.0 35.8 Sulfolobus tokodaii str. 7 A Crenarchaeota 2.7 32.8 Thermococcus gammatolerans EJ3 A Euryarchaeota 2.0 53.6 Thermococcus kodakarensis KOD1 A Euryarchaeota 2.1 52.0 Thermococcus onnurineus NA1 A Euryarchaeota 1.8 51.3 Thermococcus sibiricus MM 739 A Euryarchaeota 1.8 40.2
Thermofilum pendens Hrk 5 A Crenarchaeota 1.8 57.7
Thermoplasma acidophilum DSM 1728 A Euryarchaeota 1.6 46.0 Thermoplasma volcanium GSS1 A Euryarchaeota 1.6 39.9 Thermoproteus neutrophilus V24Sta A Crenarchaeota 1.8 59.9 uncultured methanogenic archaeon RC-I A Euryarchaeota 3.2 54.6
TABLE S4
Examples of sense:sense codon pairs with mononucleotide repeats.
2 3 4 5 6
CGAATC (132) CAAATG (57) CAAAAC (29) CAAAAA (5) AAAAAA (1)
A/T
CGTTAC (108) GTTTAC (63) TTTTCG (30) TTTTTC (6) TTTTTT (1)
ATCCGA (144) ACCCGT (72) AACCCC (33) CCCCCA (6) CCCCCC (1)
sense:sense pairs
C/G
ACGGTA (132) CCGGGT (69) TGGGGA (32) TGGGGG (6) GGGGGG (1)
TABLE S5
Synonymous codon pairs with mononucleotide repeats
2 3 4 5 6
AAGAAG (1) AAGAAA (1) - AAAAAG (1) AAAAAA (1)
A/T
TTCTTC (1) TTCTTT (1) - TTTTTC (1) TTTTTT (1)
CCTCCA (9) CCTCCC (3) - CCCCCA (3) CCCCCC (1)
synonymous pairs
C/G
GGAGGT (9) GGTGGG (3) - GGGGGA (3) GGGGGG (1)
TABLE S6
The average nucleotide divergence (D) and o/e6N in four comparisons of eukaryote genomes
conserved level
CDS length(bp)
CDS
number D spectrum
D
average o/e(6N)
Frequency of 6N(10-3)
highly 1293144 1019 0 ~ 0.099 0.078 0.727 1.984
moderately 1294212 808 0.099 ~ 0.119 0.109 0.808 2.79
S. cerevisiae
less 1293987 1020 0.119 ~ 0.447 0.155 0.851 3.442
highly 1205748 730 0.005 ~ 0.066 0.051 0.368 0.438
moderately 1209369 658 0.066 ~ 0.089 0.077 0.399 0.471
D. melanogaster
less 1207668 939 0.089 ~ 0.646 0.14 0.591 0.956
highly 2923812 2541 0.013 ~ 0.227 0.181 0.509 0.946
moderately 2924169 2302 0.227 ~ 0.286 0.255 0.533 1.423
C. elegans
less 2923314 2674 0.286 ~ 0.665 0.36 0.581 1.931
highly 8411730 4986 0.015 ~ 0.131 0.101 0.532 1.41
moderately 8412294 4612 0.131 ~ 0.186 0.157 0.519 1.341
H. sapiens
TABLE S7
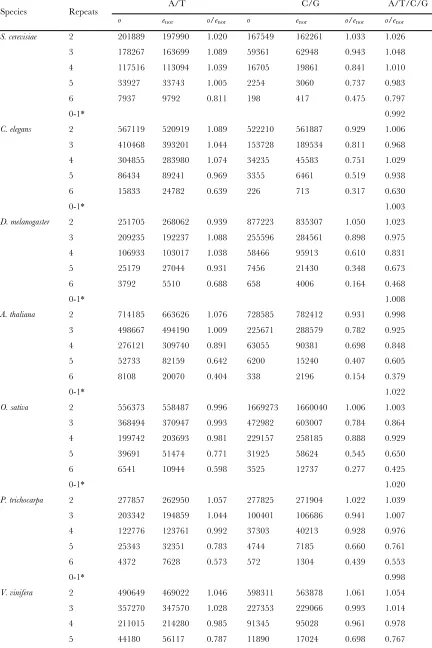
o/e ratio of the sense:sense codon pairs in eukaryote genomes
A/T C/G A/T/C/G
Species Repeats
o enor o/enor o enor o/enor o/enor
S. cerevisiae 2 201889 197990 1.020 167549 162261 1.033 1.026
3 178267 163699 1.089 59361 62948 0.943 1.048
4 117516 113094 1.039 16705 19861 0.841 1.010
5 33927 33743 1.005 2254 3060 0.737 0.983
6 7937 9792 0.811 198 417 0.475 0.797
0-1* 0.992
C. elegans 2 567119 520919 1.089 522210 561887 0.929 1.006
3 410468 393201 1.044 153728 189534 0.811 0.968
4 304855 283980 1.074 34235 45583 0.751 1.029
5 86434 89241 0.969 3355 6461 0.519 0.938
6 15833 24782 0.639 226 713 0.317 0.630
0-1* 1.003
D. melanogaster 2 251705 268062 0.939 877223 835307 1.050 1.023
3 209235 192237 1.088 255596 284561 0.898 0.975
4 106933 103017 1.038 58466 95913 0.610 0.831
5 25179 27044 0.931 7456 21430 0.348 0.673
6 3792 5510 0.688 658 4006 0.164 0.468
0-1* 1.008
A. thaliana 2 714185 663626 1.076 728585 782412 0.931 0.998
3 498667 494190 1.009 225671 288579 0.782 0.925
4 276121 309740 0.891 63055 90381 0.698 0.848
5 52733 82159 0.642 6200 15240 0.407 0.605
6 8108 20070 0.404 338 2196 0.154 0.379
0-1* 1.022
O. sativa 2 556373 558487 0.996 1669273 1660040 1.006 1.003
3 368494 370947 0.993 472982 603007 0.784 0.864
4 199742 203693 0.981 229157 258185 0.888 0.929
5 39691 51474 0.771 31925 58624 0.545 0.650
6 6541 10944 0.598 3525 12737 0.277 0.425
0-1* 1.020
P. trichocarpa 2 277857 262950 1.057 277825 271904 1.022 1.039
3 203342 194859 1.044 100401 106686 0.941 1.007
4 122776 123761 0.992 37303 40213 0.928 0.976
5 25343 32351 0.783 4744 7185 0.660 0.761
6 4372 7628 0.573 572 1304 0.439 0.553
0-1* 0.998
V. vinifera 2 490649 469022 1.046 598311 563878 1.061 1.054
3 357270 347570 1.028 227353 229066 0.993 1.014
4 211015 214280 0.985 91345 95028 0.961 0.978
6 7776 13017 0.597 1213 3465 0.350 0.545
0-1* 0.994
D. rerio 2 151680 198024 0.766 445213 441558 1.008 0.933 3 134432 125556 1.071 137434 154413 0.890 0.971 4 82117 89221 0.920 47664 56106 0.850 0.893 5 20039 24448 0.820 6869 10155 0.676 0.778 6 3952 7338 0.539 575 1789 0.321 0.496
0-1* 1.024
G. gallus 2 144489 160816 0.898 318367 306458 1.039 0.991 3 116509 109159 1.067 102821 107594 0.956 1.012 4 76297 77541 0.984 45823 47233 0.970 0.979 5 18799 22323 0.842 6506 8814 0.738 0.813 6 3751 6230 0.602 1159 2002 0.579 0.596
0-1* 1.006
H. sapiens 2 377178 433388 0.870 1193583 1081926 1.103 1.037 3 292616 285525 1.025 435475 418807 1.040 1.034 4 196623 202258 0.972 226520 214999 1.054 1.014 5 48859 57139 0.855 40482 45473 0.890 0.871 6 9542 15155 0.630 4767 11687 0.408 0.533
0-1* 0.992
P. troglodytes 2 315073 358318 0.879 931009 843754 1.103 1.037 3 248097 240328 1.032 336977 324156 1.040 1.036 4 167552 171994 0.974 170817 162067 1.054 1.013 5 41826 48876 0.856 29913 33455 0.894 0.871 6 8256 13032 0.634 3455 8318 0.415 0.549
0-1* 0.992
M. musculus 2 382538 459862 0.832 1216049 1112579 1.093 1.017 3 285771 294416 0.971 434098 425154 1.021 1.000 4 177784 193336 0.920 202323 199192 1.016 0.968 5 42836 53152 0.806 33101 39828 0.831 0.817 6 7897 13219 0.597 3241 8985 0.361 0.502
0-1* 1.002
R. norvegicus 2 256795 310109 0.828 855218 780508 1.096 1.020 3 193492 199737 0.969 305122 298271 1.023 1.001 4 119635 129586 0.923 143179 140749 1.017 0.972 5 28647 35564 0.805 23170 27776 0.834 0.818 6 5311 8897 0.597 2252 6228 0.362 0.500
0-1* 1.001
Eukaryotes 2 - - 0.940 - - 1.035 1.014 3 - - 1.032 - - 0.928 0.988 4 - - 0.975 - - 0.884 0.955 5 - - 0.831 - - 0.651 0.789 6 - - 0.602 - - 0.335 0.528
0-1* - - - - 1.004
3 - - 0.999 - - 1.031 1.018
4 - - 0.947 - - 1.035 0.992
5 - - 0.830 - - 0.862 0.844
6 - - 0.614 - - 0.386 0.520
0-1* - - 0.997
Non-mammal 2 - - 0.982 - - 1.008 1.008
3 - - 1.048 - - 0.886 0.975
4 - - 0.988 - - 0.824 0.939
5 - - 0.832 - - 0.574 0.765
6 - - 0.596 - - 0.314 0.531
0-1* - - - - 1.007
TABLE S8
o/e ratio of the sense:sense codon pairs in bacteria genomes
A/T C/G A/T/C/G
Species Repeats
o enor o/enor o enor o/enor o/enor
A. marina 2 71024 76948 0.923 149442 149494 1.000 0.974
3 68945 69054 0.998 68822 62496 1.101 1.047
4 41287 43870 0.941 34060 30227 1.127 1.017
5 11545 11592 0.996 5343 5393 0.991 0.994
6 2105 2813 0.748 811 1137 0.713 0.738
0-1* 1.000
A. bacterium 2 44622 36261 1.231 197726 236762 0.835 0.888
3 34437 33265 1.035 55619 82189 0.677 0.780
4 15113 16922 0.893 15973 27858 0.573 0.694
5 3432 4372 0.785 1479 4033 0.367 0.584
6 429 722 0.594 91 627 0.145 0.385
0-1* 1.060
A. avenae 2 13125 12569 1.044 286322 304739 0.940 0.944
3 13456 10863 1.239 93685 115308 0.812 0.849
4 4543 4021 1.130 29435 42974 0.685 0.723
5 1058 753 1.404 3892 7911 0.492 0.571
6 142 124 1.143 421 1386 0.304 0.373
0-1* 1.051
A. variabilis 2 99528 98529 1.010 95162 98885 0.962 0.986
3 95146 88362 1.077 45886 42002 1.092 1.082
4 58133 57642 1.009 21374 17836 1.198 1.053
5 16300 16294 1.000 2576 3004 0.857 0.978
6 3065 3599 0.852 290 531 0.546 0.812
0-1* 0.992
A.aurescens 2 29349 25217 1.164 210683 197560 1.066 1.077
3 22202 20326 1.092 74346 80666 0.922 0.956
4 7437 7900 0.941 25254 30795 0.820 0.845
5 1102 1401 0.787 2694 5208 0.517 0.574
6 74 172 0.430 97 657 0.148 0.206
0-1* 0.997
B. anthracis 2 98645 96493 1.022 50693 62936 0.805 0.937
3 88678 79538 1.115 17005 20767 0.819 1.054
4 68363 66181 1.033 6303 6915 0.911 1.021
5 20581 21987 0.936 604 949 0.636 0.924
6 4679 6919 0.676 46 180 0.256 0.666
0-1* 1.007
B. weihenstephanensis 2 101264 98338 1.030 53614 65246 0.822 0.947
3 90626 81487 1.112 17720 21453 0.826 1.053
5 21138 22471 0.941 662 1026 0.645 0.928
6 5164 7307 0.707 54 193 0.279 0.696
0-1* 1.006
B.fragilis 2 77608 78312 0.991 127573 118289 1.078 1.044 3 66468 62159 1.069 42091 45070 0.934 1.012 4 46063 46405 0.993 12681 14322 0.885 0.967
5 12105 14155 0.855 1307 1968 0.664 0.832
6 2782 4440 0.627 108 250 0.432 0.616
0-1* 0.997
B. thetaiotaomicron 2 98798 99423 0.994 148563 143103 1.038 1.020 3 83578 78330 1.067 46506 53792 0.865 0.985 4 52576 55764 0.943 13547 15241 0.889 0.931
5 12965 16659 0.778 1275 1950 0.654 0.765
6 2610 4849 0.538 92 207 0.444 0.534
0-1* 1.006
B. indica subsp 2 31199 26180 1.192 134784 148182 0.910 0.952 3 33380 25986 1.285 41978 59637 0.704 0.880 4 17586 13813 1.273 13965 20373 0.685 0.923
5 3868 3365 1.150 1723 3355 0.514 0.832
6 448 589 0.760 172 502 0.343 0.568
0-1* 1.027
B.sp. ORS278 2 23196 22600 1.026 307338 380962 0.807 0.819 3 17130 17633 0.971 74997 139409 0.538 0.587
4 5500 6093 0.903 17985 36640 0.491 0.550
5 844 1060 0.796 1611 5284 0.305 0.387
6 78 136 0.571 111 597 0.186 0.258
0-1* 1.108
C. aurantiacus 2 40609 42127 0.964 155138 170549 0.910 0.920 3 23224 30644 0.758 55240 67912 0.813 0.796 4 11880 14347 0.828 18481 24473 0.755 0.782
5 2370 3390 0.699 2071 3930 0.527 0.607
6 375 716 0.524 213 610 0.349 0.443
0-1* 1.047
C. beijerinckii 2 146755 143077 1.026 48404 48673 0.994 1.018 3 109494 105601 1.037 15422 17178 0.898 1.017
4 90548 89874 1.007 5494 5255 1.045 1.010
5 25430 26186 0.971 572 718 0.797 0.966
6 6147 7965 0.772 56 99 0.568 0.769
0-1* 0.997
C. psychrerythraea 2 95371 93660 1.018 62415 72083 0.866 0.952 3 81117 79027 1.026 26322 27568 0.955 1.008
4 62969 62187 1.013 6952 7261 0.957 1.007
5 18454 17622 1.047 650 863 0.753 1.034
6 4804 5473 0.878 88 96 0.913 0.878
C. ATCC 51142 2 101596 95028 1.069 62808 64148 0.979 1.033 3 93372 90963 1.026 38508 32125 1.199 1.071 4 69780 67402 1.035 23732 17747 1.337 1.098
5 21899 21674 1.010 4394 3389 1.297 1.049
6 4930 5841 0.844 482 791 0.609 0.816
0-1* 0.980
D. aromatica RCB 2 28401 24891 1.141 191122 200816 0.952 0.973 3 31502 26264 1.199 58218 78717 0.740 0.855 4 15647 13662 1.145 16286 21564 0.755 0.907
5 4161 3343 1.245 1807 3079 0.587 0.929
6 606 568 1.067 289 393 0.735 0.931
0-1* 1.026
D. acidovorans 2 16536 19449 0.850 360065 371228 0.970 0.964 3 17128 16198 1.057 117811 142832 0.825 0.849
4 8429 7099 1.187 31259 47919 0.652 0.721
5 1847 1404 1.315 3449 9265 0.372 0.496
6 243 263 0.926 262 1451 0.181 0.295
0-1* 1.043
D. alkenivorans 2 53659 38793 1.383 286613 230457 1.244 1.264 3 63014 42209 1.493 106455 95665 1.113 1.229 4 55781 35454 1.573 39223 41016 0.956 1.242
5 20657 12371 1.670 4661 7936 0.587 1.247
6 4238 3664 1.157 611 1389 0.440 0.959
0-1* 0.907
D. hafniense 2 68043 61476 1.107 174931 145952 1.199 1.171 3 61698 53509 1.153 66666 61713 1.080 1.114 4 46596 41144 1.133 30863 28334 1.089 1.115
5 14745 12991 1.135 3881 4571 0.849 1.061
6 2837 3498 0.811 441 888 0.497 0.747
0-1* 0.952
E. coli 2 51147 48682 1.051 149550 157571 0.949 0.973 3 44147 39740 1.111 46222 58227 0.794 0.922 4 33248 31226 1.065 13490 16906 0.798 0.971
5 10077 9577 1.052 1185 1993 0.594 0.973
6 2230 2900 0.769 105 294 0.357 0.731
0-1* 1.014
F. johnsoniae 2 147432 120427 1.224 73245 69992 1.046 1.159 3 129137 101106 1.277 24060 27636 0.871 1.190 4 129004 105011 1.228 4360 5896 0.739 1.202
5 36929 33521 1.102 275 661 0.416 1.088
6 10601 12986 0.816 17 62 0.273 0.814
0-1* 0.939
F. alni 2 12700 14847 0.855 379533 423321 0.897 0.895 3 5461 7348 0.743 153363 179549 0.854 0.850
5 196 219 0.893 8533 14686 0.581 0.586
6 18 28 0.639 919 2874 0.320 0.323
0-1* 1.072
G. uraniireducens 2 46581 39995 1.165 192878 178174 1.083 1.098
3 40075 33659 1.191 62165 69316 0.897 0.993 4 28196 22846 1.234 32299 30728 1.051 1.129
5 8642 6926 1.248 3987 4913 0.812 1.067
6 1977 1802 1.097 1010 954 1.059 1.084
0-1* 0.974
H. chejuensis 2 59918 56598 1.059 247494 261146 0.948 0.967
3 60572 52332 1.157 78656 94088 0.836 0.951 4 36439 33866 1.076 26080 32550 0.801 0.941
5 10534 9804 1.074 2802 5035 0.557 0.899
6 1937 2555 0.758 302 724 0.417 0.683
0-1* 1.015
H. aurantiacus 2 86642 66946 1.294 149147 171104 0.872 0.991
3 72525 67540 1.074 63578 69054 0.921 0.996 4 34885 34943 0.998 18840 23365 0.806 0.921
5 9952 9109 1.093 1372 3533 0.388 0.896
6 1574 2038 0.772 93 420 0.221 0.678
0-1* 1.007
L. sphaericus 2 77491 80151 0.967 64871 62929 1.031 0.995
3 72587 65066 1.116 19574 20713 0.945 1.074
4 54636 51513 1.061 7598 7471 1.017 1.055
5 17469 15921 1.097 759 983 0.772 1.078
6 4056 4823 0.841 94 180 0.523 0.830
0-1* 0.990
M. loti 2 35093 29020 1.209 294816 328383 0.898 0.923
3 34575 27328 1.265 74375 126778 0.587 0.707 4 14674 12166 1.206 17992 34130 0.527 0.706
5 2506 2502 1.002 1647 4866 0.338 0.564
6 257 348 0.738 125 541 0.231 0.430
0-1* 1.062
M. radiotolerans 2 8878 7711 1.151 332728 360218 0.924 0.928
3 5274 5687 0.927 121621 143866 0.845 0.848
4 1023 1431 0.715 33034 50478 0.654 0.656
5 169 204 0.829 3797 8093 0.469 0.478
6 33 30 1.107 310 1229 0.252 0.272
0-1* 1.063
M. aeruginosa 2 93611 83286 1.124 99129 93823 1.057 1.088
3 86176 78102 1.103 51837 41371 1.253 1.155 4 68568 59379 1.155 29336 22360 1.312 1.198
5 21875 19682 1.111 5155 4432 1.163 1.121
6 4930 5582 0.883 972 1129 0.861 0.879
M. smegmatis 2 20061 23054 0.870 326748 383968 0.851 0.852 3 12195 15870 0.768 107452 142610 0.753 0.755
4 3127 4516 0.692 34823 55117 0.632 0.636
5 451 703 0.642 3490 8917 0.391 0.410
6 20 70 0.285 88 1386 0.063 0.074
0-1* 1.087
M.vanbaalenii 2 19477 20966 0.929 310369 355110 0.874 0.877
3 10960 14158 0.774 107135 138276 0.775 0.775
4 2614 3948 0.662 37871 54565 0.694 0.692
5 316 586 0.539 4276 9031 0.473 0.477
6 20 58 0.346 239 1473 0.162 0.169
0-1* 1.077
M. xanthus 2 22470 22740 0.988 543975 548434 0.992 0.992
3 13028 16328 0.798 175859 199546 0.881 0.875
4 2738 4319 0.634 71659 87169 0.822 0.813
5 346 577 0.599 8412 15233 0.552 0.554
6 29 56 0.519 1143 3438 0.332 0.335
0-1* 1.031
N. farcinica 2 10846 11560 0.938 306985 354835 0.865 0.867
3 6898 8400 0.821 112963 142149 0.795 0.796
4 1047 2009 0.521 33089 53458 0.619 0.615
5 87 262 0.332 4455 9461 0.471 0.467
6 3 27 0.112 129 1404 0.092 0.092
0-1* 1.088
N. PCC 7120 2 101174 99869 1.013 96331 99846 0.965 0.989
3 96744 90059 1.074 46479 42562 1.092 1.080 4 59788 59117 1.011 21905 18299 1.197 1.055
5 16821 16758 1.004 2599 3043 0.854 0.981
6 3163 3695 0.856 289 533 0.542 0.817
0-1* 0.991
O. terrae 2 24375 20209 1.206 242758 306422 0.792 0.818
3 25404 18811 1.350 67113 110286 0.609 0.717 4 13098 10064 1.301 19202 37092 0.518 0.685
5 3662 2508 1.460 1880 5608 0.335 0.683
6 477 457 1.043 151 806 0.187 0.497
0-1* 1.093
P. atrosepticum 2 45340 48191 0.941 144636 160392 0.902 0.911
3 41669 39014 1.068 42824 56242 0.761 0.887 4 29957 28090 1.066 13812 18096 0.763 0.948
5 8502 8216 1.035 1208 2227 0.543 0.930
6 1732 2317 0.748 163 354 0.460 0.710
0-1* 1.031
P. naphthalenivorans 2 19026 15334 1.241 205635 218273 0.942 0.962
5 6057 3234 1.873 1323 4066 0.325 1.011
6 1053 851 1.238 124 513 0.242 0.863
0-1* 1.032
P. aeruginosa 2 17464 15834 1.103 373102 382759 0.975 0.980
3 18251 15817 1.154 108821 145311 0.749 0.789
4 5203 5830 0.892 25216 39579 0.637 0.670
5 1000 1095 0.913 2030 5540 0.366 0.457
6 171 179 0.956 144 610 0.236 0.399
0-1* 1.046
P. entomophila 2 18830 17621 1.069 307326 315901 0.973 0.978
3 17708 17620 1.005 101885 119950 0.849 0.869
4 5698 6583 0.866 27827 36222 0.768 0.783
5 1305 1347 0.969 2638 5044 0.523 0.617
6 218 207 1.055 215 674 0.319 0.492
0-1* 1.031
P. fluorescens 2 25967 22983 1.130 367159 356426 1.030 1.036
3 25702 23619 1.088 135495 143623 0.943 0.964 4 10803 10665 1.013 42915 48275 0.889 0.911
5 2698 2373 1.137 3385 7271 0.466 0.631
6 376 409 0.920 269 970 0.277 0.468
0-1* 1.001
P. putida 2 27115 26627 1.018 289368 294366 0.983 0.986
3 26122 24964 1.046 95457 112234 0.851 0.886 4 10890 10855 1.003 25264 32669 0.773 0.831
5 2611 2402 1.087 2487 4329 0.574 0.757
6 356 407 0.875 257 580 0.443 0.621
0-1* 1.023
P. syringae 2 37157 34831 1.067 234624 267347 0.878 0.899
3 34865 32214 1.082 78096 99115 0.788 0.860 4 19931 18237 1.093 18023 27327 0.660 0.833
5 5515 4653 1.185 1548 3507 0.441 0.866
6 940 1008 0.933 128 437 0.293 0.739
0-1* 1.044
R. leguminosarum 2 28215 22899 1.232 197763 226519 0.873 0.906 3 29282 22436 1.305 53447 84840 0.630 0.771 4 12201 10229 1.193 12599 22647 0.556 0.754
5 1959 1989 0.985 1204 3234 0.372 0.606
6 203 275 0.739 86 369 0.233 0.449
0-1* 1.056
R. RHA1 2 26712 28583 0.935 358440 419010 0.855 0.860
3 12767 18083 0.706 131830 163191 0.808 0.798
4 2460 4873 0.505 48436 66072 0.733 0.717
5 273 636 0.429 5944 10814 0.550 0.543
6 17 65 0.260 268 1679 0.160 0.163
R.baltica 2 92151 72214 1.276 228844 268980 0.851 0.941 3 78846 68796 1.146 66533 94091 0.707 0.893 4 32560 33095 0.984 22235 33283 0.668 0.825
5 6916 8256 0.838 2402 5412 0.444 0.682
6 819 1555 0.527 188 878 0.214 0.414
0-1* 1.032
R. castenholzii 2 34290 33519 1.023 188568 232168 0.812 0.839
3 21870 26451 0.827 48214 79488 0.607 0.662 4 10627 11966 0.888 19077 30948 0.616 0.692
5 2199 2856 0.770 1887 4459 0.423 0.559
6 330 554 0.596 224 758 0.296 0.422
0-1* 1.085
R. RS-1 2 35382 36136 0.979 197635 243391 0.812 0.834
3 22025 27250 0.808 55543 83691 0.664 0.699 4 11133 12307 0.905 21774 33015 0.660 0.726
5 2438 2955 0.825 2393 4886 0.490 0.616
6 319 556 0.574 328 873 0.376 0.453
0-1* 1.081
R. denitrificans 2 23575 23357 1.009 156714 170444 0.919 0.930
3 29926 23451 1.276 52747 63400 0.832 0.952 4 18548 14828 1.251 23872 29262 0.816 0.962
5 4368 3797 1.150 2851 4359 0.654 0.885
6 414 871 0.475 492 922 0.533 0.505
0-1* 1.024
S.arenicola 2 13336 18152 0.735 297474 308568 0.964 0.951
3 6464 9765 0.662 110957 129059 0.860 0.846
4 1653 2318 0.713 37365 49140 0.760 0.758
5 271 329 0.823 4593 8480 0.542 0.552
6 14 35 0.402 305 1416 0.215 0.220
0-1* 1.049
S. proteamaculans 2 39161 36594 1.070 213232 208091 1.025 1.032
3 39159 32998 1.187 61006 80244 0.760 0.885 4 26575 23141 1.148 19415 23186 0.837 0.993
5 7201 6643 1.084 1785 2818 0.633 0.950
6 1474 1868 0.789 175 401 0.437 0.727
0-1* 1.006
S. usitatus 2 65476 51345 1.275 436941 463126 0.943 0.977
3 53225 45719 1.164 126252 172919 0.730 0.821 4 22646 21337 1.061 45366 69268 0.655 0.751
5 4551 4966 0.916 4822 11829 0.408 0.558
6 421 771 0.546 447 2132 0.210 0.299
0-1* 1.039
S.cellulosum 2 22796 23780 0.959 603614 734549 0.822 0.826
5 558 660 0.846 12035 21442 0.561 0.570
6 67 79 0.850 1734 4827 0.359 0.367
0-1* 1.102
T. erythraeum 2 110636 107004 1.034 68293 63007 1.084 1.052
3 101064 93766 1.078 32841 28270 1.162 1.097
4 77174 73174 1.055 13499 10434 1.294 1.085
5 24320 23241 1.046 1753 1667 1.052 1.047
6 5656 6150 0.920 180 264 0.682 0.910
0-1* 0.975
geometric mean 2 - - 1.055 - - 0.940 0.962
3 - - 1.046 - - 0.831 0.898
4 - - 0.983 - - 0.788 0.861
5 - - 0.952 - - 0.551 0.737
6 - - 0.696 - - 0.325 0.488
0-1* - - - - 1.026
* codon pairs with 0-1 repeats represents those with no mononucleotides in the pair junction. For each species, if
TABLE S9
o/e ratio of the sense:sense codon pairs in archaeal genomes
A/T C/G A/T/C/G Species repeats
o enor o/enor o enor o/enor o/enor
A. pernix 2 15992 19076 0.838 62599 58359 1.073 1.015
3 7825 8767 0.893 28279 26638 1.062 1.020
4 3230 3488 0.926 16581 14980 1.107 1.073
5 475 587 0.809 3054 3007 1.016 0.982
6 35 88 0.397 555 813 0.683 0.655
0-1* 0.992
A. fulgidus 2 34868 27380 1.273 65443 67915 0.964 1.053
3 28630 21315 1.343 23753 25137 0.945 1.128
4 16783 13371 1.255 11190 10981 1.019 1.149
5 4599 3676 1.251 1346 1583 0.850 1.130
6 631 783 0.806 153 330 0.463 0.705
0-1* 0.970
A. profundus 2 33903 28932 1.172 30755 35392 0.869 1.005
3 26142 22822 1.145 12274 13715 0.895 1.051
4 13735 13948 0.985 3346 3858 0.867 0.959
5 3003 3423 0.877 321 482 0.666 0.851
6 398 704 0.566 19 73 0.259 0.537
0-1* 0.998
C. maquilingensis 2 50332 45251 1.112 50258 39265 1.280 1.190
3 15823 27266 0.580 25751 22070 1.167 0.843
4 4027 8250 0.488 9985 8762 1.140 0.824
5 470 1181 0.398 1484 1519 0.977 0.724
6 33 109 0.303 56 226 0.248 0.266
0-1* 0.990
C. Korarchaeum 2 23537 27571 0.854 43137 43248 0.997 0.941
3 11965 15365 0.779 22096 20347 1.086 0.954
4 4103 5021 0.817 12445 11328 1.099 1.012
5 650 763 0.852 1908 2056 0.928 0.907
6 81 124 0.652 209 504 0.415 0.462
0-1* 1.018
C. Methanoregula 2 21923 21332 1.028 96192 83986 1.145 1.122
3 16109 14775 1.090 39021 35527 1.098 1.096
4 13321 11199 1.189 16029 17402 0.921 1.026
5 4757 3896 1.221 2236 2720 0.822 1.057
6 1381 1328 1.040 330 640 0.516 0.869
0-1* 0.965
D. kamchatkensis 2 23833 27085 0.880 32018 29830 1.073 0.981
3 10915 13889 0.786 14210 13800 1.030 0.907
4 5226 7396 0.707 6374 6285 1.014 0.848
6 147 264 0.557 58 204 0.284 0.438
0-1* 1.022
H. salinarum 2 4379 4701 0.932 96719 112628 0.859 0.862
3 3267 3947 0.828 27541 35544 0.775 0.780
4 1084 1534 0.707 14672 18483 0.794 0.787
5 300 300 0.998 1709 2674 0.639 0.676
6 19 43 0.440 174 588 0.296 0.306
0-1* 1.073
H. sp. NRC-1 2 4452 4721 0.943 94553 109964 0.860 0.863
3 3249 3916 0.830 27007 34854 0.775 0.780
4 1080 1518 0.712 14412 18138 0.795 0.788
5 296 298 0.993 1699 2633 0.645 0.681
6 17 42 0.406 167 576 0.290 0.298
0-1* 1.072
H. mukohataei 2 7124 10506 0.678 134129 160943 0.833 0.824
3 4134 7455 0.555 39541 51383 0.770 0.742
4 1483 2451 0.605 16521 22884 0.722 0.711
5 432 465 0.929 1544 3110 0.496 0.553
6 28 69 0.408 141 626 0.225 0.243
0-1* 1.087
H. walsbyi 2 38559 40434 0.954 48943 60751 0.806 0.865
3 20631 25845 0.798 18326 21733 0.843 0.819
4 9028 11828 0.763 6170 8279 0.745 0.756
5 2088 2827 0.739 780 1194 0.653 0.713
6 347 464 0.747 85 223 0.382 0.629
0-1* 1.048
H. utahensis 2 12710 14790 0.859 126401 146933 0.860 0.860
3 9137 11726 0.779 41865 49070 0.853 0.839
4 3156 4173 0.756 17269 23238 0.743 0.745
5 706 793 0.891 1738 3173 0.548 0.616
6 25 89 0.281 165 721 0.229 0.235
0-1* 1.064
H. turkmenica 2 10898 10720 1.017 160816 197139 0.816 0.826
3 6400 8700 0.736 47936 62352 0.769 0.765
4 1791 2846 0.629 20107 27511 0.731 0.721
5 364 500 0.728 1705 3686 0.463 0.494
6 13 63 0.207 148 686 0.216 0.215
0-1* 1.084
H. butylicus 2 18267 21515 0.849 49468 49397 1.001 0.955
3 7756 9832 0.789 18376 19773 0.929 0.883
4 2814 3768 0.747 7235 7921 0.913 0.860
5 390 662 0.589 922 1192 0.773 0.708
6 19 99 0.192 80 235 0.340 0.296
0-1* 1.027
3 8789 9036 0.973 21068 20290 1.038 1.018
4 2664 3076 0.866 12812 12221 1.048 1.012
5 485 630 0.770 2333 2079 1.122 1.040
6 43 77 0.561 255 566 0.450 0.464
0-1* 0.982
M. sedula 2 38026 36259 1.049 62755 55349 1.134 1.100
3 23501 24207 0.971 28799 25782 1.117 1.046
4 9965 11366 0.877 11546 11513 1.003 0.940
5 1815 2387 0.760 1282 1892 0.677 0.724
6 212 412 0.514 81 364 0.223 0.378
0-1* 0.982
M. smithii 2 48951 44310 1.105 19276 15319 1.258 1.144
3 38671 35342 1.094 7292 6875 1.061 1.089
4 32868 32375 1.015 1933 1688 1.145 1.022
5 9757 9563 1.020 205 177 1.155 1.023
6 3032 3469 0.874 7 18 0.388 0.871
0-1* 0.968
M. fervens 2 37351 33572 1.113 18507 17005 1.088 1.104
3 30655 27101 1.131 7964 7199 1.106 1.126
4 28110 26251 1.071 3303 2823 1.170 1.080
5 8514 7887 1.080 371 404 0.919 1.072
6 2708 3007 0.901 58 80 0.725 0.896
0-1* 0.960
M. jannaschii 2 42360 38764 1.093 19085 18400 1.037 1.075
3 33754 30848 1.094 8734 7414 1.178 1.110
4 29601 29142 1.016 2925 2722 1.075 1.021
5 8838 8458 1.045 315 395 0.797 1.034
6 2786 3141 0.887 45 74 0.607 0.880
0-1* 0.973
M. vulcanius 2 43366 39120 1.109 19771 18752 1.054 1.091
3 31337 29434 1.065 8359 7649 1.093 1.070
4 33090 30495 1.085 3394 2879 1.179 1.093
5 9991 9173 1.089 415 427 0.971 1.084
6 3546 3777 0.939 40 76 0.525 0.931
0-1* 0.967
M. paludicola 2 18726 20969 0.893 115942 113721 1.020 1.000
3 15141 14102 1.074 44327 43018 1.030 1.041 4 11460 8560 1.339 15203 17727 0.858 1.014
5 4039 2563 1.576 1667 2545 0.655 1.117
6 796 632 1.259 120 452 0.265 0.845
0-1* 0.995
M. burtonii 2 43556 42739 1.019 47162 45516 1.036 1.028
3 29367 29462 0.997 17076 17771 0.961 0.983
4 20609 20312 1.015 5197 5436 0.956 1.002