ABSTRACT
GONG, ZHENHUAN. Multi-level Data Layout Optimization for Heterogeneous Access Patterns. (Under the direction of Dr. Nagiza F. Samatova.)
Recent years have seen an enormous increase in computation power of leadership computing facilities. As a result, huge amounts of data, from terascale to petascale, are being produced by scientific applications running on supercomputers. However, the I/O subsystems have not de-veloped with a comparable speed, making data I/O and storage the major bottleneck in modern computing architectures. The problem gets exacerbated by the need to perform data-intensive analytic jobs, such as queries with multiple constraints on these datasets stored on external stor-age. Scientific applications produce multi-dimensional, multi-variate, double-precision datasets, and these datasets are usually stored on large-scale parallel file systems. The datasets are not well-represented by traditional relational data models. Queries on scientific datasets involve multiple constraints, thus producing heterogeneous I/O access patterns. How extreme-scale datasets are linearized and organized on parallel file systems is crucial to the data read per-formance for queries: the optimized layout results in more sequential reads on contiguous data blocks, which are much faster than seek-and-reads on non-contiguous small blocks. Existing data layout optimization techniques, while successfully improved read performance for certain application-specific access patterns, have failed to address more general and heterogeneous ac-cess patterns. They also often do not scale to the expected substantial growth in data size reaching exascale in the near future. Moreover, existing technology usually performs data lay-out optimization in a post-processing way on datasets on storage systems. The post-processing approaches read the entire datasets on storage, perform layout optimization, and write the pro-cessed data back to storage, which is extremely inefficient due to the I/O bottleneck in modern computer architecture, and the huge size of the datasets. There is a lack of a general framework to perform data layout optimization for scientific datasets at simulation run time or I/O time, before datasets are written to storage, to reduce I/O and storage overhead, and speed up the entire process.
c
Copyright 2013 by Zhenhuan Gong
Multi-level Data Layout Optimization for Heterogeneous Access Patterns
by Zhenhuan Gong
A dissertation submitted to the Graduate Faculty of North Carolina State University
in partial fulfillment of the requirements for the Degree of
Doctor of Philosophy
Computer Science
Raleigh, North Carolina
2013
APPROVED BY:
Dr. David J. Thuente Dr. Xiaosong Ma
BIOGRAPHY
ACKNOWLEDGEMENTS
First, I would like to thank my advisor, Professor Nagiza F. Samatova, for her endless inspiring guidance and assistance throughout my research work. Also, I would like to thank Professor David J. Thuente, Professor Xiaosong Ma and Professor Anatoli V. Melechko for serving on my thesis committee, and providing many useful suggestions in the research work and thesis writing.
I would like to thank all the members in our research group, including Drew Boyuka, Sri-ram Lakshminarasimhan, John Jenkins, Eric Schendel, Xiaocheng Zou and Zhengzhang Chen, and so on for their continuous help in all the research projects. Also, I would like to thank our collaborators, Dr. Qing Liu, Dr. Norbert Podhorszki and Dr. Scott Klasky in Oak Ridge National Laboratory, and Dr. Rob Ross in Argonne National Laboratory for the collaborations and helps in the research projects and papers.
Finally and especially, I want to thank my parents and my wife, for all their love and support, both in general, and during my doctoral studies.
TABLE OF CONTENTS
LIST OF TABLES . . . vi
LIST OF FIGURES . . . vii
Chapter 1 Introduction . . . 1
1.1 Multi-level Layout Optimization for ISABELA Lossly Compressed Datasets . . . 3
1.1.1 Problems and Challenges . . . 3
1.1.2 Proposed Approach and Results . . . 4
1.2 Multi-level Layout Optimization Framework for Compressed Scientific Data Ex-ploration with Heterogeneous Access Patterns . . . 5
1.2.1 Problems and Challenges . . . 5
1.2.2 Proposed Approach and Results . . . 5
1.3 Parallel Run-time Layout Optimization Integrated with I/O Middleware . . . 6
1.3.1 Problems and Challenges . . . 6
1.3.2 Proposed Approach and Results . . . 7
Chapter 2 Multi-level Layout Optimization for Efficient Spatio-temporal Queries on ISABELA-compressed Data . . . 8
2.1 Introduction . . . 8
2.2 Background . . . 11
2.2.1 ISABELA . . . 11
2.2.2 ISABELA-QA . . . 11
2.2.3 Hilbert Space-Filling Curves . . . 12
2.3 Method . . . 12
2.3.1 Data Layout using Hilbert Curve Mapping and Value-constrained Binning 13 2.3.2 Data Organization on File System . . . 14
2.3.3 Query Processing . . . 17
2.3.4 Parallel Data Access Optimization . . . 19
2.3.5 Optimization and Discussion . . . 20
2.4 Results . . . 21
2.4.1 Experiment Setup . . . 21
2.4.2 Data Layout Analysis . . . 24
2.4.3 Region Query Performance . . . 25
2.4.4 Value Query Performance . . . 26
2.4.5 Component Analysis . . . 31
2.4.6 Parallel Performance on Lustre File System . . . 32
2.5 Related Work . . . 33
2.6 Conclusion . . . 34
Chapter 3 Multi-level Layout Optimization Framework for Compressed Sci-entific Data Exploration with Heterogeneous Access Patterns . . . 36
3.1 Introduction . . . 36
3.3 Method . . . 40
3.3.1 Approach Overview . . . 40
3.3.2 Optimization Techniques in Each Level . . . 42
3.3.3 File Organization on Parallel File Systems . . . 45
3.3.4 Parallel Data Access Requests Handling . . . 46
3.4 Results . . . 49
3.4.1 Experiment Setup . . . 49
3.4.2 Storage Space Overhead Measurement . . . 51
3.4.3 Data Access Performance . . . 51
3.4.4 Multi-resolution Access Evaluation . . . 55
3.4.5 Optimization Order Evaluation . . . 57
3.5 Related Work . . . 58
3.6 Conclusion . . . 59
Chapter 4 Parallel Run-time Layout Optimization Integrated with I/O Mid-dleware . . . 60
4.1 Introduction . . . 60
4.2 Background . . . 62
4.2.1 MLOC: Multi-level Layout Optimization for Compressed Scientific Datasets 62 4.2.2 I/O Middleware and Run-time Data Transformation . . . 63
4.2.3 ADIOS I/O Middleware and BP File Format . . . 64
4.3 Method . . . 65
4.3.1 Approach Overview . . . 66
4.3.2 Run-time Layout Optimization with ADIOS Parallel I/O Middleware . . 67
4.3.3 Layout Optimization and Query Index Building . . . 69
4.3.4 Query Support at ADIOS Read Side . . . 72
4.4 Results . . . 72
4.4.1 Experiment Setup . . . 72
4.4.2 Query Performance Evaluation . . . 73
4.4.3 Run-time Layout Optimization Performance Evaluation . . . 74
4.5 Related Work . . . 75
4.6 Conclusion . . . 77
Chapter 5 Future Work . . . 78
LIST OF TABLES
Table 2.1 Space requirement for data and/or DBMS index . . . 23 Table 2.2 Average number of seek operations within a bin . . . 23 Table 2.3 False-positive rates for different approaches . . . 24
Table 3.1 Space requirements of data and DBMS index for 8 GB raw data.∗SciDB replicates data along chunk boundaries to minimize the number of chunks read by queries, increasing the data size over the raw data. . . 51 Table 3.2 Region query response time (sec.) on 8 GB datasets. NoSC are set. Value
selectivity is 1% and 10%. . . 52 Table 3.3 Value query response time (sec.) on 8 GB datasets. NoVC are set. Region
selectivity is 0.1% and 1%. . . 52 Table 3.4 Region query response time (sec.) on 512 GB datasets. No SC are set.
Value selectivity is 1% and 10%. . . 53 Table 3.5 Value query response time (sec.) on 512 GB datasets. No SC are set.
Region selectivity is 0.1% and 1%. . . 53 Table 3.6 Histogram andK-means error rates for S3D data. . . 56 Table 3.7 Query response time (sec.) of different orders of optimizations for
value-retrieval data access (1% selectivity) on 512 GB S3D datasets. . . 57
LIST OF FIGURES
Figure 2.1 The first three iterations of the Hilbert space-filling curve. . . 12 Figure 2.2 A mapping from the input data, split into blocks, into bins based on
variable ranges. Each bin shows, top-to-bottom, the (relative) order of the first few blocks in file, using Hilbert curve mapping. . . 14 Figure 2.3 An overview of data layout on the disk. The three parts are stored in
separate files, and accessed based on requirements of queries. . . 15 Figure 2.4 Bin-based index file format for spatial regions. Block IDs refer to their
ordering relative to the Hilbert curve organization. . . 16 Figure 2.5 Bin-based index file formats for quantized errors. The errors are
com-pressed using the standard compression libraryzlib. The error lengths are stored using a prefix-sum for quick lookup of errors within the block. . . . 16 Figure 2.6 An overview of the query processing. . . 17 Figure 2.7 A query on a sub-region of 2-D data. The area within solid green
rectan-gular line is the query region. . . 18 Figure 2.8 Dimension selectivity based region-only query response time comparison
on single disk. Value constraint is fixed to 50% of the variable range (50% of all bins). Dimension selectivity ranges from 0.001% to 1.0%. . . 25 Figure 2.9 Bin number based region-only query performance comparison on single
disk. Dimension selectivity is fixed to 1.0%. Value constraints range from 20% to 80% of the variable range so that 20% to 80% of total bins are accessed. . . 26 Figure 2.10 Performance comparison of accessing 1-D plane in GTS data and 2-D
plane in S3D data on single disk. . . 27 Figure 2.11 Dimension selectivity based value query performance comparison on single
disk. Value constraint is fixed to 50% of the variable range. Dimension selectivity ranges from 0.001% to 1.0%. . . 28 Figure 2.12 Bin number based value query performance comparison on single disk.
Dimension selectivity is fixed to 1.0%. Value constraints range from 20% to 80% of the variable range so that 20% to 80% of total bins are accessed. 29 Figure 2.13 I/O and computation overhead analysis of value queries accessing 0.1%
of S3D data and 1% of GTS data respectively on single disk. . . 30 Figure 2.14 Performance of region and value queries on Lustre file system, Lens
clus-ter. OpenMP parallel implementation is used for ISABELA-based ap-proaches. FastBit is also implemented to access subsets of indices in parallel. 31 Figure 2.15 MPI-based parallel data access performance on Lustre file system, Lens
cluster. All GTS/S3D data are fetched and decompressed. . . 33
Figure 3.1 Overview of multi-level architecture of MLOC. Positions of levels for layout optimization (LO) are flexible. . . 41 Figure 3.2 Memory layout of double-precision floating point number and division of
Figure 3.3 A mapping from the input data, split into blocks, into bins based on variable ranges. Each bin shows, top-to-bottom, the (relative) order of
the first few blocks in file, using Hilbert curve mapping. . . 44
Figure 3.4 An overview of data layout on the disk. The indices and data for each bin are stored in separate files, and accessed based on requirements of data access patterns. . . 45
Figure 3.5 Overview of the work flow of parallel data access processing. Blocks of same color are assigned to the process if the same color. . . 47
Figure 3.6 Execution time of different components for value-retrieval data access (0.1% selectivity) on 512 GB S3D datasets. . . 54
Figure 3.7 Performance of value queries with more processes, 10% selectivity on 512 GB datasets. . . 55
Figure 3.8 Multi-resolution data access performance for value queries (1% selectivity) under differentAPLOD levels on 512 GB datasets. . . 56
Figure 4.1 An overview of MLOC’s multi-level architecture. The positions of levels for layout optimization (LO) are flexible. . . 63
Figure 4.2 The structure and ADIOS BP file format. . . 64
Figure 4.3 An overview of PARLO integrated with ADIOS at both write and read side. . . 65
Figure 4.4 ADIOS XML configuration file with PARLO configured. . . 67
Figure 4.5 Layout optimization inside ADIOS. . . 68
Figure 4.6 Example storage layout schemes for intra-PG layout optimization. . . 69
Figure 4.7 Query performance of 3-level layout optimization schemes in comparison to queries on the original ADIOS BP file without optimization. . . 73
Chapter 1
Introduction
The past years have seen an enormous increase in amounts of data produced by large-scale scientific applications. Driving this growth is the increasing complexity of fine-grain simula-tion models and the increasing computasimula-tional capability and capacity of high-performance computing (HPC) systems. Multivariate, spatio-temporal scientific datasets—in the order of tera-and-peta-byte sizes—are easily attainable by recent scientific computing projects, such as S3D combustion [23], XGC edge plasma fusion [46], and GTS core plasma fusion simulation codes [61].
Furthermore, there are requirements forglobal–context,space+time,multi–variateanalysis of the extreme-scale datasets as an integral part of their scientific discovery cycle. Typical analyses include visualization of simulation states over time and various data mining and predictive tasks, such as classification, clustering, and so on. Typical analytical workflows consist of iterative data querying with various spatio-temporal and variable constraints to fetch subsets of data stored on parallel storage systems that induceheterogeneous I/O access patterns. Current data management solutions are hardly optimized for the access patterns generated by such queries. Global-context analysis is data-intensive and thus I/O-bound. However, a well-known fact is that effective I/O bandwidth growth is not expected to match data production rates brought by much faster growing computation power. The expectation is that bandwidth to this kind of external storage will increase by one-to-two orders of magnitude in the next ten years; yet, the data being produced by simulations codes on future systems is anticipated to increase by up to three orders of magnitude, due to increases in processor count and through the incorporation of accelerators (e.g., GPGPU-like elements) into HPC systems. The variability of data and access patterns further limits the effective I/O bandwidth [38].
DataStager [4], PreDatA [71]). However, such optimizations have been primarily driven by needs for fast data offloads from the simulation runtime environment through maximizing the throughput of data writes. Storage access patterns induced by data writes in simulations are not only knowna priori but alsofixed, thus allowing for individual pattern-driven performance optimizations.
In contrast, read performance for exploratory analysis of the simulation data has not been sufficiently addressed. With the emerging trends of utilizing leadership-class computing facilities (LCF) not only for running simulations but also for performing visual exploratory analyses of their products, it is becoming imperative to optimize the I/O costs over the entire lifetime of the scientific discovery cycle and to accept potential extra up-front costs to mitigate performance degradation under different I/O access patterns. Scientific simulation codes generate multi-dimensional, multi-variate, time-series data of floating point values (usually double-precision) over different meshes and spatial grids and store them on PFS. Analytic jobs, such as queries, induce access patterns that are highly heterogeneous,arbitrary, andhard–to–predict. The data layout on storage is crucial for optimal read performance [37]. The goal for layout optimization is to store data subsets to be accessed as contiguously as possible, so that when answering user queries more sequential reads on contiguous data chunks can be achieved. This offers a much better performance than random seeks and reads on small data chunks. The multitude of possi-ble access patterns during datareads is inherently combinatorial, makingoptimal linearization of the simulation data and subsequent multi–file partitioning of this linearized representation and PFSlayout an extremely challenging task.
Another limitation of existing layout optimization techniques is a lack of a run-time frame-work to achieve layout optimization for datasets at application run time before the data is written to storage. Most of previous work has been built as post-processing methods [13], which involve reading the datasets from storage, processing data, and writing processed results back to storage. This process is very inefficient due to a large data size and I/O bottlenecks, and additional storage is required for optimized data layout. Some previous studies addressed layout optimization at file system level [53] [60]. However, they require application-level knowl-edge and only optimize for specific access patterns. They are also specific to particular file system implementation, and are not easily portable to other file systems. It is imperative to provide users with a general and portable run-time framework, within which fine-grained layout optimization can be achieved at application run-time to save both I/O and storage resources.
To address the problem, a multi-level data layout scheme is presented, which optimizes for heterogeneous access patterns induced by different queries for scientific data analysis. First, a hybrid layout scheme for a lossly compressed data format is presented, which incorporates constrained binning and Hilbert space-filling curve mapping to optimize for both value-constrained and space-value-constrained (e.g., space+time) access patterns. Based on this hybrid lay-out scheme, a flexible multi-level architecture is presented, within which different optimization techniques can be organically organized in user-specified hierarchical orders, so that different access patterns are optimized in different priorities based on user requirements. The archi-tecture also incorporates a novel byte-level precision-based multi-resolution data storage and access technique. Finally, a parallel run-time layout optimization framework is presented, which is integrated with ADIOS, a high-performance parallel I/O library designed for large-scale HPC applications. It provides users with general and flexible interface to achieve high-performance run-time layout optimization, and outputs datasets in portable file formats. The following parts briefly summarize the motivations and contributions of this work.
1.1
Multi-level Layout Optimization for ISABELA Lossly
Com-pressed Datasets
1.1.1 Problems and Challenges
Final-ly, existing scientific database management systems (SDBMs) only optimize their performance for specific types of data access patterns.
1.1.2 Proposed Approach and Results
Our group has presented ISABELA (In-situ Sort-And-B-spline Error-bounded Lossy Abate-ment, [28]) andISABELA-QA[27] as initial solutions towards the above problems.ISABELA offers five-to-seven-fold data reduction by partitioning the data intocompression windows, sort-ing, and encoding using B−spline curves with quantized errors to ensure a user-controlled ac-curacy. ISABELA-QAhas been built upon ISABELA for use in a query-processing context withknowledge priors, usingvariable-based binning of the compressed data to form an extremely light-weight index for fast query processing. Essentially, ISABELAand ISABELA-QAtrade I/O costs for computational costs instorage-bound applications.
However, ISABELA-QAonly optimizes for value-constrained queries, without considering other types of queries. For instance, space(region)-constrained queries can at best be filtered point-by -oint, only after loading the compression windows into memory. This can lead to significantly wasted computation and I/O bandwidth. To allow for bothvalue constrained and space-constrained efficient query processing onISABELA-compressed data with low overhead, a multi-level data layout optimization scheme is presented for both serial and parallel data accesses. To the best of my knowledge, no existing SDBM systems are optimized for both types of queries over spatio-temporal scientific data.
The proposed system implements a multi-level data storage layout optimization methodolo-gy to accelerate different access patterns on the compressed multi-dimensional data. The layout scheme divides data into blocks and interleaves data blocks across value-constrained bins along Hilbert space-filling curves to optimize for both value and region queries with both value and space constraints, which contrasts any existing SDBM system that optimizes only for asingular data access pattern. It enables efficient query processing with various combinations of query-driven data access patterns induced byvalue-constrained andspace-constrained queries. It also makes data compression the first class citizen of the SDBMS design. As a result, its small index footprint enables 3 to 30 times improvement of query response time on real scientific data, in addition to a significant reduction in storage requirements for the datasets.
1.2
Multi-level Layout Optimization Framework for Compressed
Scientific Data Exploration with Heterogeneous Access
Pat-terns
1.2.1 Problems and Challenges
In the previous section, a hybrid layout scheme is presented for lossly compressed scientific datasets. While successful in saving I/O resources by achieving 3–5 folds of data reduction, it only supports ISABELA’s lossly compressed data. However, users may want their data to be compressed in other ways (e.g., lossless compression), or even do not need compression at all. Moreover, the previous scheme optimizes value-constrained access patterns at the first place and space-constrained patterns at the second place. However, users may desire different orders of optimization techniques based on the frequency of different query types they execute. The limitations motivate us to create more general and flexible data layouts to meet varieties of requirements from users to optimize for heterogeneous access patterns. It is a challenging task to optimize data layout for heterogeneous access patterns without replication. To reduce search space and response time for data access, layout optimization for one access pattern attempts to store data together to reduce seek overhead for that access pattern. For other patterns, the data that needs to be accessed may be scattered over different areas, increasing seek time. Thus, the layout optimized for one access pattern will almost always conflict the desired layout of the other patterns and affect the overall performance.
1.2.2 Proposed Approach and Results
To address the challenges, MLOC (Multi-level Layout Optimization of Compressed Scientif-ic Data) is presented, whScientif-ich optimizes the storage layout of scientifScientif-ic data for effective data exploration with heterogeneous access patterns in PFS environments. In its core are multiple fine-grained data layout optimization kernels that can be organically consolidated to support various combinations of access patterns. The kernels are optimized for patterns induced by (a) query–driven multivariate, spatio-temporal constraints, (b) precision–driven data analytics, (c) compression–driven data reduction, (d) multi–resolution data sampling, and (e) multi–file data partitioning and organization on a parallel file system.MLOCorganizes these layout optimiza-tion kernels within a multi–level architecture, on which all the levels can be flexibly re-ordered by user–defined priorities.MLOCshows its novelty and contributions in the following aspects: First, it presents, a multi-level data layout optimization framework on top of PFS for HPC environments. By incorporating fine-grained data layout optimization techniques tuned for
sup-port. The solution achieves higher detail preservation than what is possible with a traditional multi-resolution data sampling. Third, it offers a first-class treatment of lossless and lossy data compression through support of different formats of compressed data, and optimizes data layout for each of them to reduce storage and I/O overhead and to improve access performance. It also implements a data processing pipeline that is readily incorporated with existing data stag-ing frameworks [4] [71] to achieve efficient in-situ data layout optimization and compression. Experiments show that compared to the state-of-the-art techniques like FastBit, the presented approach achieves both lower query delays and storage overhead.
This work is published in the 41st International Conference on Parallel Processing (ICP-P’12) [21].
1.3
Parallel Run-time Layout Optimization Integrated with I/O
Middleware
1.3.1 Problems and Challenges
Traditional approaches, including MLOC, rely on post-processing to perform data layout opti-mization (and also other data processing operations, such as indexing and compression). The post-processing approach reads the entire datasets from storage, performs layout optimiza-tion, and writes the data back to storage. Significant I/O, storage, and CPU resources are required in this process, especially, for the huge and ever-growing datasets that modern scien-tific applications are generating. Run-time processing is necessary on data in memory instead of storage. Previous work [25] [60] either relies on application-level knowledge, or specific file system implementation. There lacks a general, portable and parallel framework for users to achieve fine-grained data layout optimization at run time.
1.3.2 Proposed Approach and Results
The limitations of existing approaches motivate the design and implementation of PARLO, PArallelRun-timeLayoutOptimization framework to achieve layout optimization for scientific datasets at run time, when the datasets are still in memory before they are written to storage. To provide users with a general and transparent solution compatible with existing state-of-the-art, PARLO is integrated with ADIOS parallel I/O middleware to output data with optimized layout in portable file formats. PARLO extends the previous work, MLOC, to optimize for heterogeneous access patterns on scientific datasets, including, but not limited to: 1) space-constrained sub volume access; 2) value-space-constrained range queries, and 3) byte-level precision-based multi-resolution access. User transparency and convenience in engineering for users are improved by enabling XML-based configuration for different layout optimizations at run time, without modifying or recompiling the application code.
Chapter 2
Multi-level Layout Optimization for
Efficient Spatio-temporal Queries on
ISABELA-compressed Data
In this chapter, a two-level hybrid data layout optimization method is presented to optimize for both value-constrained and space-constrained data access patterns within one layout scheme. The layout is built upon ISABELA-compressed datasets, which is a lossy compression method presented in previous work from our group. By integrating value-based binning and Hilbert space-filling curve mapping in the layout scheme, the method improves the data locality for both value-constrained and space-constrained access patterns. ISABELA lossy compression helps to significantly reduce I/O cost. Experiments have shown that the method is efficient with respect to storage, computation, and I/O compared to existing database technologies optimized for query processing on scientific data.
2.1
Introduction
The past years have seen an enormous increase in amount of data produced by large-scale sci-entific applications. Driving this growth is the conception of more complex and fine-grain sim-ulation models and the increasing computational capability and capacity of high-performance computing (HPC) systems increases. Multivariate, spatio-temporal scientific datasets—in the order of tera-and-peta-byte sizes—are easily attainable by recent scientific computing projects, such as S3D combustion [23], XGC edge plasma fusion [46], and GTS core plasma fusion sim-ulation codes [61].
classification and clustering, and, in general, executing user-based query processing based on various spatio-temporal and variable constraints.
Global-context analysis is data-intensive and thus I/O-bound. Yet, effective I/O bandwidth growth is not expected to match data production rates. Significant progress has been made to narrow this gap. In fact, 10s to 100s of GBytes per second have been seen in production when using parallel file systems, such as IBM’s GPFS [49], Lustre [50], Panasas PanFS [62], and PVFS [29] in conjunction with parallel I/O libraries such as ADIOS [39], HDF5 [16], Parallel netCDF [33], and ROMIO [58]. However, the expectation is that bandwidth to this kind of external storage will increase by one to two orders of magnitude in the next ten years; yet, the data being produced by simulations codes on future systems is anticipated to increase by up to three orders of magnitude, due to increases in processor count and through the incorporation of accelerators (e.g., GPGPU-like elements) into HPC systems. The variability of data and I/O further limits the bandwidth [38].
There are a number of problems that arise from this emerging trend. First, the I/O bot-tleneck will become more acute as simulations continue producing data faster than the I/O software and hardware are capable of writing it out. Scientists will be forced to make tough choices as to what data will be saved, potentially missing key insights.
Second, from a cost perspective, disk space will always be insufficient for numerous scientists on user-shared resources. Thus, even data that is written to external storage may not be kept for very long.
Third, post-processing, efficient analytics, and query-processing on huge datasets are ex-tremely time-consuming activities due to multiple data reads with irregular data access pat-terns, which is the task that traditional database management system (DBMS) are unable to handle gracefully (see details in Section 2.5). Thus, even if data is stored outside the HPC system and retained, the ability to extract knowledge from it is limited.
Finally, existing scientific database management systems (SDBMS) only optimize their per-formance for specific types of data access patterns. SciDB [9] applies array-based data model which is planned to be optimized for access subvolumes in multi-dimensional arrays based solely on space constraints, and must perform an entire database read to perform range queries. Mon-etDB [8] is a pioneer in column-store databases, and FastBit [63] offers a state-of-the-art bitmap indexing for answering range queries and resort to entire data set read to perform queries with space constraints.
(e.g., Pearson correlation of at least 0.99, NRME less than 0.01, and per-value relative error of less than 0.1%).
ISABELA-QAhas been built upon ISABELAfor use in a query-processing context with knowledge priors, using variable-based binning of the compressed data to form an extremely light-weight index (≈3% vs. 33%−300% by others [63, 14]) for at least an order of magnitude fastervalue-constrained (e.g., 50≤T emperature≤70) query processing than the state-of-the-art DBMS systems could offer (see Section 2.2 and [27]). Essentially,ISABELAand
ISABELA-QA trade I/O costs for computational costs instorage-bound applications.
However, ISABELA-QA only optimizes for value-constrained queries, without consider-ing other types of queries. For instance, dimension(region)-constrained queries (e.g., latitude-longitude box of Western Africa at sea surface level, or data from thexz−plane or sub-cube in a multi-dimensional data) can at best be filtered through point-by-point, only after loading the compression windows into memory. This can lead to significantly wasted computational and I/O bandwidth (see Section 2.4).
To allow for both value-constrained and space-constrained efficient query processing on IS-ABELA-compressed data with low overhead, in this work a multi-level data layout optimization technique is presented for both serial and parallel data accesses. To the best of my knowledge, no existing DBMS systems are optimized for both types of queries over spatio-temporal scientific data.
The proposed system is innovative in a number of ways:
• It enables efficient query processing withvarious combinations of query-driven data access patterns induced byvalue-constrained and space-constrained queries. This contrasts any existing SDBMS that optimizes only for asingular data access pattern.
• It introduces a multi-level data storage layout optimization methodology to accelerate different access patterns on the compressed multi-dimensional data. The layout scheme divides data into blocks and interleaves data blocks across value-constrained bins along Hilbert space-filling curves to optimize for both value and region queries with both value and space constraints.
• It makes data compression the first class citizen of the SDBMS design. In fact, itindexes the metadata—rather than the raw data—about the ISABELAcompression results along with multi-level data storage layout. As a result, its smal index footprint enables 3 to 30 times improvement of query response time on real scientific data, in addition to significant reduction in data storage requirements.
• It particularly optimizes data layout for compressed scientific data to meet the trend of
data format, and can be easily expanded to other formats. The index size is only about 1% of the index sizes of existing SDBMS systems, and the compression achieves 4–5 folds of data reduction, which significantly reduce storage and I/O overhead.
• The indexing and storage layout for the compressed data format is designed and optimized to support parallel data access, and achieves fast queries over large amount of data in production HPC environments.
2.2
Background
2.2.1 ISABELA
Our group has introducedISABELA as a compression technique suited for hard-to-compress scientific datasets [28]. In short, double-precision data stream is split intocompression windows of a fixed size (1,024) and sorted. The resulting list of values is monotonically increasing, and is thus suitable for curve-fitting techniques. For ISABELA, B−spline interpolation was used to fit the data. At this point, most of the data points closely resemble the fitted curve, but there are no guarantees about the error of reconstructing the original points. Thus, quantized error values were introduced to encode the relative error between the original values and the
B−spline reconstructed values. The indices of sorted locations back into the unsorted windows requiredlog(W)ebits, or 10 bits for a window of size 1024.
For a relative per-value error bound of 1%,ISABELAreported a compression ratio of about 15%, that is, raw datasets could be reduced to 15% of their original size. Given the cost of I/O vs. the cost of computation, especially on distributed systems, the compute-I/O trade-off is consistent with the rate of growth of each in current HPC.
2.2.2 ISABELA-QA
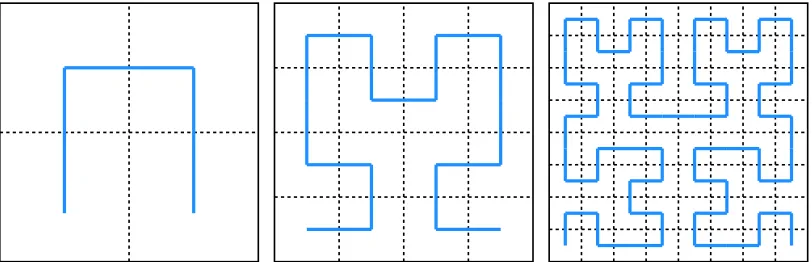
Figure 2.1: The first three iterations of the Hilbert space-filling curve.
focus is on reducing the I/O costs due to heterogeneous data storage access patterns induced by both value-based and dimension-based constraints.
2.2.3 Hilbert Space-Filling Curves
A space-filling curve, of which a Hilbert curve [47] is a particular instance of, is a curve whose range covers the entiren-dimensional hypercube. These curves are typically recursively defined. Figure 2.1 shows the first three iterations of the Hilbert space-filling curve. The 2-dimensional data is divided into blocks, and the blocks are organized on disk following the order of the Hilbert curve. The value of space-filling curves to query processing is that, given region-based query constraints, they allow both an efficient organization of spatial data to increase data locality on the storage and an efficient traversal of the data with respect to query constraints. Lawder and King identified the Hilbert curve as having strong clustering properties and created a tree-based traversal algorithm for query processing, utilizing bitmaps to encode quadrants of the tree [31].
2.3
Method
The query processing and storage methodology presented in this work is aimed toward a few important classes of queries with respect to spatio-temporal data:
• Value-constrained (also known as range queries)—queries that request spatial regions and/or their corresponding variable values, subject to constraints on those or other vari-able values. E.g., what (latitude,longitude) pairs at some time in a simulation have an abnormally high temperature? What are those temperature values?
North Carolina at some time?
• Value-and-region-constrained—queries that request spatial regions and/or their corre-sponding variable values, subjects to constraints on both the regions as well as variable values. E.g., what are the regions within North Carolina with an abnormally high tem-perature?
Bin-based value-constraint processing is applied on compressed data blocks that are orga-nized in storage using the Hilbert curve block ordering on the input space. The following sections describe the mapping from raw data into compression units calledblocks for use byISABELA the organization of blocks through the use of Hilbert space-filling curves, the partitioning of inter-block values into value-separated bins, and the query processing over these modified data structures with the optimized layout in file.
2.3.1 Data Layout using Hilbert Curve Mapping and Value-constrained Bin-ning
In a nutshell, the proposed data layout scheme interleaves data blocks across value-constrained bins along Hilbert space-filling curves to optimize for both value and region queries with both value and space constraints.
Given an n-dimensional grid of variable values, the first step is to split the grid up into blocks, or regular-sized subgrids. For instance, a 128×128 2-dimensional grid of values is split into 16 32×32 blocks. Rather than storing these blocks in row-major or column-major order, the blocks are stored in the order defined by the Hilbert space-filling curve. Each block is then independently compressed using ISABELA(Section 2.2).
It is worth noting that since the order of blocks is based on the Hilbert curve itself and, contrary to other methods, every grid point is representative of a block, no additional metadata must be stored to track this order, beyond the dimensions of the dataset in blocks. By organizing data blocks in the order of the space-filling curve, it is ensured that spatially contiguous blocks in multi-dimensional space are placed contiguously on disk. This reduces potential seek operations in queries accessing certain spatial regions, since one pair of seek and read operations should be able to load as many contiguous blocks as possible. The reason for choosing Hilbert space-filling curve is that it has been demonstrated to best preserve the spatial locality properties among popular space-filling curves [41] [40].
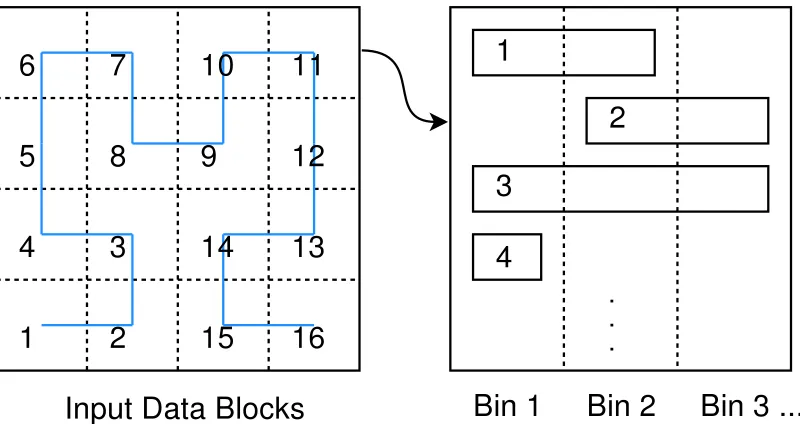
Figure 2.2: A mapping from the input data, split into blocks, into bins based on variable ranges. Each bin shows, top-to-bottom, the (relative) order of the first few blocks in file, using Hilbert curve mapping.
method works by sorting the values prior to generating theB−spline coefficients to ensure low error rates, the mapping between position in the spline and original position within the block is all that is needed to regenerate the correct value (handling of quantized errors is discussed in Section 2.3.2).
Given a block sizeB, onlydlog(B)ebits per item are needed to represent the position of the item, e.g., 10 bits for a block size of 1024. These positions are placed into their respective bins, as well as necessary identifying block information, such as block index (see Section 2.3.2). The order in which these blocks are put into the bins follows their Hilbert curve ordering. Figure 2.2 shows organization of data blocks with the combination of Hilbert mapping and binning. Through this combination, it is ensured that (1) points with close values are co-located together in the same bin and (2) points that are spatially close are co-located inside each bin.
2.3.2 Data Organization on File System
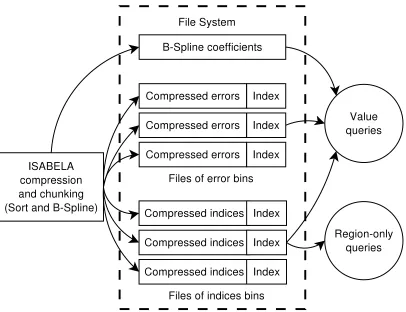
Figure 2.3: An overview of data layout on the disk. The three parts are stored in separate files, and accessed based on requirements of queries.
The ISABELA-compressed data is divided into three parts: B-spline coefficients, binned quantized errors, andbinned indices. The B−spline coefficients generated per-block are stored linearly in memory in the same order as the blocks, and each window has fixed size of coefficients (30 coefficients, which are 240 bytes) so that no additional indices are required. For the bin-specific quantized errors and indices, zlib [3] compression is used for compressing each window. Since each window may have different number of elements distributed to different bins, an additional index is required for each bin to locate the position of errors/indices for each window. To answer region-only queries, only the binned indices need to accessed. To answer value-queries, all three parts need to be accessed, and details are explained in Section 2.3.3.
<N number of timesteps>
<File offset for timestep t> (0≤t < N) (Repeat 0≤t < N)
<B number of blocks in timestep t> <Block ID i> (0≤i < B)
<Block offset i> (0≤i < B) <Block length i> (0≤i < B)
<Block indices> (PBj=0−1 block length j) (End Repeat)
Figure 2.4: Bin-based index file format for spatial regions. Block IDs refer to their ordering relative to the Hilbert curve organization.
<N number of timesteps>
<File offset for timestep t> (0≤t < N) (Repeat 0≤t < N)
(B - number of blocks per timestep) <Block ID i> (0≤i < B)
<Block offset i> (0≤i < B) <Block length i> (0≤i < B) <Block compressed error length prefix sum i> (0≤i < B)
<Block compressed error i> (0≤i < B) (End Repeat)
Figure 2.5: Bin-based index file formats for quantized errors. The errors are compressed using the standard compression libraryzlib. The error lengths are stored using a prefix-sum for quick lookup of errors within the block.
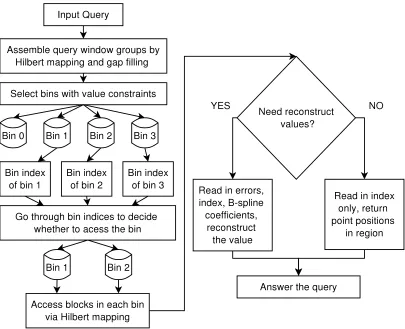
Figure 2.6: An overview of the query processing.
2.3.3 Query Processing
The overview of the query processing from the data flow and data access stand-point is pre-sented in Figure 2.6. Given a query on a sub-region/volume with a set of variable value and space constraints, the system first decides the bins to access by comparing the bounds of value constraints and the bounds of each bin. After that, the blocks to access in the chosen bins is calculated, by mapping the blocks in query region to the Hilbert curve order. The indices of each qualified bin are loaded first to see whether the bin contains the blocks for the query, thus to further filter out the bins that do not need to be accessed. The indices tell the offsets and length of each block. If the query requires the exact variable values at region points, the values are reconstructed using theB-spline algorithm. Note that the nature of theB-spline algorithm offers the benefits of per-point value decompression. Otherwise, only the indices are fetched, and the positions of points are returned (see Section 2.3.3 and 2.3.3).
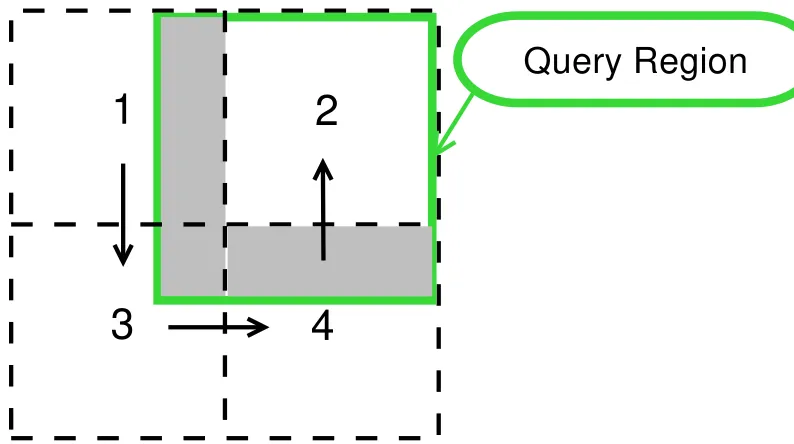
Figure 2.7: A query on a sub-region of 2-D data. The area within solid green rectangular line is the query region.
with four blocks, and by mapping the four blocks using Hilbert curve order, the blocks on disk will be accessed in the order of 1, 3, 4, and 2. Since the errors/indices within a window are compressed/packed and stored together, it is necessary to retrieve the compressed errors and packed indices within all the four blocks to perform the decompression. Note that for block 1, 3, and 4, only parts of the blocks overlap with the query region, which are shown as grey shaded areas. The other parts retrieved from the disk are not useful and they are defined as false-positive points.
False positive points are an artifact of queries not matching up with the pre-selected data decomposition and are typical. However, thefalse-positive points do not harm the performance of the queries for two reasons. 1). Operating Systems operate in terms of disk blocks or pages (in the 512 byte-4K range), unless told otherwise. To access a single byte on the disk, the entire page on the disk is loaded into memory. So, even if only the shaded area is read from disk, the other parts of the blocks might also be automatically loaded into memory as long as they are in the same page which means this false-positive is inherent. 2). Although thefalse-positive points are read into memory and decompressed/unpacked together with the shaded area, noB−spline reconstruction will be performed on these points, since it is easy to identify that they are not in the region of query. This filtering process helps to avoid additional CPU overhead and reduces query response time.
Region-only Query
Region-only queries are defined as queries answering the positions of points that satisfy a specific variable value constraints. In this case, the values of variables are not required as output. Furthermore, if the bounds of bins are contained within the bounds of the value constraint, the values of the points do not need to be reconstructed, and it is just necessary to return the indices as output. Such bins are defined asaligned bins. As shown in Figure 2.3, for the aligned bins, it is not necessary to access the coefficients and quantized error bins. The overhead of reconstructing values using B−spline algorithm is also eliminated. So in this case, significant time is saved by less I/O and CPU overhead and the responses to the queries are extremely fast.
Bins with bounds not contained within the query bounds are defined as misaligned bins. In these bins, there might be spatial regions that fail to satisfy the value constraints. Since determining in advance which of these points violate the value constraints is impossible for compressed data, all the values in the spatial region must be decompressed/reconstructed. The processing for misaligned bins is similar to the value queries.
Value Query
Value queries are defined as queries that answer the exact values of points that satisfy specific value and space constraints. Exact values of points are required as output. So for these queries, the values of all points satisfying the constraints need to be reconstructed. As shown in Fig-ure 2.3, all three parts of the compressed dataset need to be accessed to retrieve the coefficients, quantized errors, and indices to performB−spline reconstruction. Thefalse-positive points are identified and discarded without reconstruction overhead, as described in Section 2.3.3.
2.3.4 Parallel Data Access Optimization
When answering queries with loose value/space constraints, large amount of data can be fetched and reconstructed. The CPU resource becomes the bottleneck due to the non-trivial overhead of B-spline reconstruction algorithm on all data points, and the challenge is to speed up the recon-struction procedure to remove this bottleneck. To address this challenge, the layout scheme is optimized to support parallel processing, utilizing the modern multi-core and GPU architecture and parallel techniques such as MPI, OpenMP and CUDA.
process will gather reconstruction results from all working processes. Since each block can be fetched and reconstructed independently, the communication overhead among all processes is minimal except for the final results gathering. This block-level parallelization significantly improves query performance by reducing the reconstruction time. It also utilizes the distributed storage and data striping provided by parallel file systems [50] [11] to speed up data access through parallel I/O. Both OpenMP-based and MPI-based parallel query engines are designed and implemented to speed up data access and reconstruction.
2.3.5 Optimization and Discussion Block Grouping
A large number of I/O operations on small data chunks deteriorates I/O performance compared to accessing large contiguous data blocks [42]. The adjacent reads on sets of indices are ag-gregated, taking advantage of the Hilbert-based layout. One observation for the Hilbert curve organization is that there are often few blocks between the contiguous blocks to be accessed, which are calledgaps. By loading blocks in those gaps into memory, potential seek operations are reduced, with a relatively small false-positive rate.
To quantify this rate, the ratioµis defined, which is the ratio of matching vs. non-matching query blocks by which I/O will perform bulk reads. For instance, it would likely be less costly to read 10 contiguous blocks worth of data with 2 blocks thrown out rather than seek and read two sets of 4 blocks. The idea is similar to data sieving in MPI I/O by grouping reads (or writes) of small chunks together [57]. Note that the redundant blocks loaded will not be decompressed and reconstructed, so no additional computational overhead is introduced. Only for blocks to be accessed, the corresponding quantized errors can be loaded, decompressed, and applied to the values reconstructed from the B−splines in a manner similar to loading the indices.
Binning Analysis
Another optimization is to filter out bins that do not contain the blocks within the space constraints. One possible solution is to build another set of indices to map the blocks to the bins. However, one block contains 1024 points, and simple evaluation shows that the values of the points can easily get distributed across all the bins, which makes one block to map to all the bins. A more fine-grained solution is to build a point-level bitmap, However, the space overhead of such fine-grained bitmap is non-trivial.
This optimization is addressed by the light-weight indices at the head of each bin, as shown in Figures 2.4 and 2.5. The indices contain information about the start point and the count of points in a block that fall in this bin. So by going through the indices, the query engine can quickly filter out the bins that do not contain points in a specific region. Since the size of each index is small (see Table 2.1), it is reasonable to assume that they can be loaded into memory to gain higher performance.
2.4
Results
2.4.1 Experiment Setup Hardware Configuration
To evaluate the performance of the data layout optimization and queries, extensive experiments have been set up and conducted on two hardware configurations.
• The single disk environment, which is setup on a server with 8 CPU cores, 16GB memory
and 1TB WD RE3 hard drive installed with Linux ext3 file system.
• The distributed file system environment for supercomputing, which is setup on Oak Ridge
Lens cluster [1] with 16 CPU cores, 64GB memory, and a popular high-performance distributed file system, Lustre [50], over the distributed storage space.
Datasets
Two scientific datasets are used, which are generated by different scientific simulation codes running on supercomputers to evaluate the performance. As these simulation codes are typical scientific codes, it is believed that the experimental results are also representative, indicating that the data layout optimizations is capable of dealing with various multi-dimensional scientific data. The datasets are:
• The GTS data (GTS). GTS [61] is a particle-based simulation for studying plasma
nuclear reactors. The data is 1-dimensional so data from multiple time steps are aggre-gated into one time step to form a 2-dimensional data space. In each time step, there are 32,768×32,768 double precision floating point numbers, totalling to 8GB of data.
• The S3D data (S3D). The S3D code [23] performs first principles based direct numerical simulation (DNS) of reacting flows which aids the modeling and design of combustion devices. Thevvelocity variable produced by the code is used for the experiments. In each time step, the subset of the original 3-D 400×250×200 double precision floating point data in one time step is duplicated to form a 3-D 1024×512×512 datasets so that each time step contains 2GB of data. Four time steps of data are used so that the total size is 8GB.
Data is divided into blocks for ISABELA and each block contains 1024 elements to get a sufficient tradeoff between the compression ratio and query response times [28]. Otherwise, a smaller block size could decrease the compression ratio, while a larger block size could increase the error rate as well as increase false-positive rate during data decompression. For binning, the datasets are distributed to ten equal-frequency bins, each containing 10% of all the data.
Scenarios for Comparison
Among existing SDBMSs, FastBit and SciDB are chosen to compare with the method presented in this work. Also, the na¨ıve sequential scan of the raw data file is compared. Furthermore, the performance over a number of scenarios based on the ISABELA compression methodology is shown, including: (a) binning over linear blocks (ISABELA-Row-Major, I-Row for short) without optimizations for space constraints, (b) binning over block-divided data without Hilbert reordering (ISABELA-Block,I-Block for short), and (c) the presented multi-level layout opti-mization system (ISABELA-Hilbert,I-Hilbertfor short). The performance results are reported for various percentages of the full database returned by the query, to assess the performance under a broad range of queries.
In all the experiments, it is assumed that all the data is located on a storage system (i.e., single hard disk or distributed storage). This assumption is important, since the explosive growth of data makes it impossible for the physical memory (RAM) to hold all the data. After each round of experiments, the system file cache in memory is cleared to ensure that all data are fetched from disk before answering the next query.
Table 2.1: Space requirement for data and/or DBMS index
Data size Index size Total size I-Hilbert 2.7GB 60MB 2.8GB
FastBit 8GB 10GB 18GB
Sequential Scan 8GB N/A 8GB
Table 2.2: Average number of seek operations within a bin
GTS(1%) GTS(10%) S3D(1%) S3D(10%)
I-Hilbert 14 42 20 71
I-Block 103 325 217 939
I-Row 3,277 3,277 221 476
Sequential scan1 3,277 10,363 24,531 113,288
1 The total numbers of seeks are shown since binning is not used.
can be answered by analyzing the index alone without the need to perform disk access. No matter which indexing technique is used, the time to retrieve values from the disk remains the dominant factor, and the overall response time remains more or less similar for most techniques. Also, the cache clear configuration makes FastBit to work with poor performance, since it is designed for in-memory indexing. But the bitmap indices generated by FastBit can be huge if fine-grain binning is used [64]; thus, users can hardly assume that index data fits into memory. SciDB is designed and built to access sub-plane/volume of multi-dimensional matrices chunking techniques [54], which is optimized for answering value queries with dimension con-straints. In the experiments, the same chunking sizes as ISABELA-based approaches is ap-plied. However, for region queries with value-constraints, SciDB has to scan the entire sub-plane/volume to select qualified points.
Table 2.3: False-positive rates for different approaches
GTS(1%) GTS(10%) S3D(1%) S3D(10%)
I-Hilbert 9.9% 3.5% 33.2% 18.7% I-Block 1.9% 0.6% 16.9% 8.3% I-Row 23.5% 9.0% 78.5% 53.7%
Sequential scan2 N/A N/A N/A N/A
2
The rate cannot be determined since it relies on value constraints.
step are accessed and reconstructed. In each group of the experiments, one of the constraints is fixed, and the other is changed to evaluate the performance sensitivity to these two constraints.
2.4.2 Data Layout Analysis
Table 2.1 summarizes the storage requirements for each approach: the multi-level layout (I-Hilbert), FastBit, and sequential disk scan. By usingISABELA, the data and index size com-bined is reduced to 20%-30% of the original data size. This data reduction not only saves disk storage space, but also improves the I/O performance. The light-weight index (less than 3%) can be held in memory, but for the sake of fair comparison, in the experiments, they are stilled kept on disk. Experiments show that this reduction plays an important role in improving the query response time, although the trade-off is that more CPU resources are spent on data reconstruction.
0 2 4 6 8 10 12
0.001% 0.01% 0.1% 1.0%
Response time (sec.)
Dimension selectivity
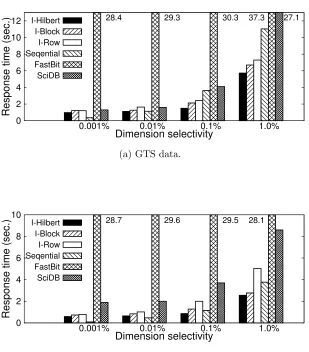
28.4 29.3 30.3 37.3 26.9 I-Hilbert I-Block I-Row Seqential FastBit SciDB
(a) GTS data.
0 1 2 3 4 5 6 7 8 9
0.001% 0.01% 0.1% 1.0%
Response time (sec.)
Dimension selectivity
28.7 29.6 29.5 28.1 I-Hilbert I-Block I-Row Seqential FastBit SciDB
(b) S3D data.
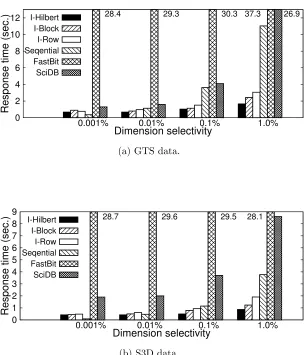
Figure 2.8: Dimension selectivity based region-only query response time comparison on sin-gle disk. Value constraint is fixed to 50% of the variable range (50% of all bins). Dimension selectivity ranges from 0.001% to 1.0%.
2.4.3 Region Query Performance
0 5 10 15 20 25 30
20% 40% 60% 80%
Response time (sec.)
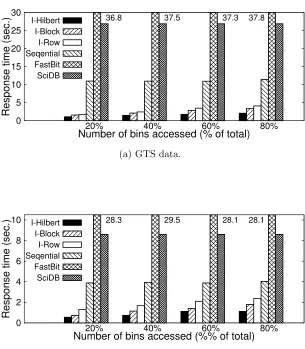
Number of bins accessed (% of total) 36.8 37.5 37.3 37.8 I-Hilbert I-Block I-Row Seqential FastBit SciDB
(a) GTS data.
0 2 4 6 8 10
20% 40% 60% 80%
Response time (sec.)
Number of bins accessed (%% of total) 28.3 29.5 28.1 28.1 I-Hilbert I-Block I-Row Seqential FastBit SciDB
(b) S3D data.
Figure 2.9: Bin number based region-only query performance comparison on single disk. Di-mension selectivity is fixed to 1.0%. Value constraints range from 20% to 80% of the variable range so that 20% to 80% of total bins are accessed.
2.4.4 Value Query Performance Plane Access Performance
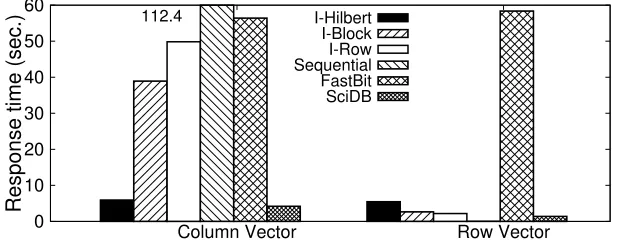
0 10 20 30 40 50 60
Column Vector Row Vector
Response time (sec.)
112.4 I-Hilbert I-Block I-Row Sequential FastBit SciDB
(a) Plane access in 2D space, GTS data
0 5 10 15 20 25 30
ij plane ik plane jk plane
Response time (sec.)
125.8 I-Hilbert
I-Block I-Row Sequential FastBit SciDB
(b) Plane access in 3D space, S3D data
Figure 2.10: Performance comparison of accessing 1-D plane in GTS data and 2-D plane in S3D data on single disk.
datasets and ij vs.jk vs.ik planes in 3-D datasets.
As expected, for the plane access along the slowest growing dimension (column for 2-D and
0 2 4 6 8 10 12
0.001% 0.01% 0.1% 1.0%
Response time (sec.)
Dimension selectivity
28.4 29.3 30.3 37.3 27.1 I-Hilbert I-Block I-Row Seqential FastBit SciDB
(a) GTS data.
0 2 4 6 8 10
0.001% 0.01% 0.1% 1.0%
Response time (sec.)
Dimension selectivity
28.7 29.6 29.5 28.1 I-Hilbert I-Block I-Row Seqential FastBit SciDB
(b) S3D data.
Figure 2.11: Dimension selectivity based value query performance comparison on single disk. Value constraint is fixed to 50% of the variable range. Dimension selectivity ranges from 0.001% to 1.0%.
Note that in this experiment, no value constraints are added while retrieving a plane, which means that for I-Hilbert, all the bins need to be accessed and reconstructed, which is the worst case for I-Hilbert. If value constraints are added, like 50% of the entire value range, the response time would reduce to nearly half, as demonstrated in the next section.
Sub-Region/Volume Access Performance
0 5 10 15 20 25 30
20% 40% 60% 80%
Response time (sec.)
Number of bins accessed (% of total) 36.8 37.5 37.3 37.8 I-Hilbert I-Block I-Row Seqential FastBit SciDB
(a) GTS data.
0 2 4 6 8 10
20% 40% 60% 80%
Response time (sec.)
Number of bins accessed (% of total) 28.3 29.5 28.1 28.1 I-Hilbert I-Block I-Row Seqential FastBit SciDB
(b) S3D data.
Figure 2.12: Bin number based value query performance comparison on single disk. Dimension selectivity is fixed to 1.0%. Value constraints range from 20% to 80% of the variable range so that 20% to 80% of total bins are accessed.
for example, querying the temperature for points in a region, where temperature is higher than a threshold. The approaches with binning benefits from such value constraints since fewer number of bins will be accessed to answer the query.
0 0.5 1 1.5 2
I-Hilbert I-Block I-Row Sequential
Execution time (sec.)
Indexing Seek Read Processing
(a) S3D data. Data selectivity is 0.1% and num-ber of bins is 50%.
0 2 4 6 8 10 12
I-Hilbert I-Block I-Row Sequential
Execution time (sec.)
Indexing Seek Read Processing
(b) GTS data. Data selectivity is 1.0% and number of bins is 50%.
0 2 4 6 8 10 12
I-Hilbert I-Block I-Row Sequential
Execution time (sec.)
Indexing Seek Read Processing
(c) GTS data. Data selectivity is 1.0% and number of bins is 50%. Optimized with Open-MP parallel processing.
Figure 2.13: I/O and computation overhead analysis of value queries accessing 0.1% of S3D data and 1% of GTS data respectively on single disk.
0.001% to 1.0%. The figures show that the optimizations for space constraints used in I-Hilbert consistently achieve low response times compared to the other methods from 0.1% to 1.0% data selectivity.
0 5 10 15 20 25 30
GTS 1% GTS 10% S3D(16G)
1% S3D(16G)10%
Response time (sec.)
Dimension selectivity I-Hilbert
I-Block I-Row Seqential FastBit
(a) Region query on Lustre.
0 5 10 15 20 25 30
GTS 1% GTS 10% S3D(16G)
1% S3D(16G)10%
Response time (sec.)
Dimension selectivity I-Hilbert
I-Block I-Row Seqential FastBit
(b) Value query on Lustre.
Figure 2.14: Performance of region and value queries on Lustre file system, Lens cluster. Open-MP parallel implementation is used forISABELA-based approaches. FastBit is also implement-ed to access subsets of indices in parallel.
tial scan approach achieves almost the same performance in all cases since it has to scan the entire query area despite the value constraints. For SciDB, similar performance is observed as in region queries, since it does not have specific optimizations for region queries. Region queries and value queries apply almost the same access techniques.
2.4.5 Component Analysis
indexing, seeking, reading, and post-processing and collect statistics of execution time for each part respectively. Figure 2.13 shows the execution times for different components for queries accessing 0.01% and 10% of the total data, respectively. Figure 2.13a shows that for small bulk of data, the sequential scan achieves good performance since the amount of data read-in is small. The ISABELA-Hilbert performs better than other layouts, because of lower seeking, reading, and indexing times. Figure 2.13b shows that ISABELA-Hilbert approach achieved balanced seeking/reading. ISABELA-Row-Major order achieves best performance, because the seeking and reading times are lower when accessing large bulk of data. But the post-processing time is larger since it fetches and processes more redundant data than the other ISABELA layouts. Sequential scan performs the worst in this case, because it has to read much more data than the other cases.
There are significant computational costs from decompression and reconstruction, leading the post-processing time to become high as data selectivity grows. However, those reduce the I/O reading costs, sometimes dramatically. As mentioned before, post-processing can be easily optimized by parallel processing techniques. Figure 2.13c shows the value of each component after parallel optimization using OpenMP [15]. Post-processing time is significantly reduced by this optimization. More results of parallel optimization on distributed file systems will be presented in the next section.
2.4.6 Parallel Performance on Lustre File System
OpenMP and MPI are applied to achieve parallel data access and processing. The performance on Lustre distributed file system is evaluated on a single node of Oak Ridge Lens Cluster. Since the environment has larger computing and I/O capacity, queries with larger data access areas are tested. For S3D data, the datesets used in single disk are duplicated environment from 2GB per time step to 16GB per time step. To make fair comparison, FastBit is also configured to access 2GB subsets of 8GB/16GB data in parallel using 4/8 cores. Figure 2.14 shows the performance comparison for both region and value queries using OpenMP parallel technique. The region query performance forISABELA-based approaches is much better than the others, as shown in Figure 2.14a. For value queries shown in Figure 2.14b, I-Hilbert still achieves better performance in most scenarios because of less I/O as well as less reconstruction time with parallel optimization. For larger datasets, the sequential scan performs well. This is because Lustre file system distributes big files across different OSTs for fast parallel access. File reads are much faster than single-disk environment, and sequential scan does not need much time for post-processing.
0
2
4
6
8
10
12
14
8 16 32 64
Execution time (sec.)
# of processes
Indexing Seek Read Processing
(a) Value query on Lustre, accessing all GTS data.
0
5
10
15
20
25
30
8 16 32 64
Execution time (sec.)
# of processes
Indexing Seek Read Processing
(b) Value query on Lustre, accessing all S3D (16GB) data.
Figure 2.15: MPI-based parallel data access performance on Lustre file system, Lens cluster. All GTS/S3D data are fetched and decompressed.
cessing capability on larger data. The performance of all I/O and computation components are measured. The figure shows that the overall query response time decreases almost linearly as number of processes increases, indicating that the system is suitable for processing large data using parallel techniques.
2.5
Related Work
Traditional relational databases, such as Postgres [56], have a number of characteristics making them unoptimized for scientific data. Unlike most scientific data sets, which can be consid-ered read-only post-simulation, databases have been designed for frequent, small read/write transactions, using indexing algorithms and structures such as B-Trees [14]. Also, compres-sion/decompression typically happens as a post-processing step and does not directly play a part in query processing. Finally, in most scientific analytics scenarios, ACID (atomicity, consistency, isolation, durability) constraints are relaxed or even not required, allowing for across-the-board optimizations of query processing.
the raw data size in addition to requiring access to the raw data.
A more recent database software being developed for array-centric scientific data is
SciD-B[9].SciDBprovides a design and language elements that are specifically aimed toward use on large-scale, multi-dimensional matrices in a distributed computing environment, such as array slicing and joining operations, and array division into regular/irregular chunks [54]. However, the majority of the work, to my knowledge, has been on spatial division of chunks and on performing algorithms at the chunk level, rather than providing structures optimized for range queries.
To map multi-dimensional scientific data to one dimensional space to achieve high spatial locality, space-filling curves [47] have been extensively studied. Lawder et. al.[31] [32] studied the usage of Hilbert space-filling curves in indexing to optimize data layout and speed up multi-dimensional data retrieval. Balmelli et. al. [5] introduced a Z−order indexing scheme for the quadtree to navigate pairs of nodes in constant time. Pascucciet. al.[44] [43] used a multi-level
Z−order indexing scheme to develop a storage layout for rectilinear grids of data that minimizes the amount of disk access. Seamonset. al. presented PANDA [51], a parallel I/O framework to handle multi-dimensional data using space filling curves. Among different space-filling curves, Hilbert space-filling curve has been shown to have strong geometric locality properties [41] [40], motivating us to choose it in the design. Recently, Tianet. al. presented EDO[60], an elastic data organization approach that uses Hilbert curve re-ordering and chunking to optimize parallel access to subsets of multi-dimensional data on parallel file systems.
These works try to theoretically understand the nature of placing chunks of data on different disks, in order to increase throughout by minimizing seeks, and maximizing concurrency for many common access patterns. In contrast, this work presents a hybrid approach that combines compression, binning, and Hilbert curve mapping together to ensure optimized performance for queries with different types of constraints.
2.6
Conclusion
Chapter 3
Multi-level Layout Optimization
Framework for Compressed
Scientific Data Exploration with
Heterogeneous Access Patterns
This chapter presents MLOC, a Multi-level Layout Optimization framework for Compressed scientific data, which extends the work presented in the last chapter. MLOC implements a flexible multi-level architecture, in which multiple layout optimization kernels are organized in hierarchical orders, based on user-defined priorities of the access patterns to be optimized. Besides value-constrained and space-constrained access patterns, MLOC also incorporates a new byte-level precision-based multi-resolution data storage and access technique, which divides the bytes of double-precision numbers and access part of them for low-resolution access to reduce I/O overhead. Experiments have shown that MLOC effectively improves the end-to-end query performance of queries with heterogeneous access patterns on scientific datasets.