A Survey on Process Migration
Full text
Figure
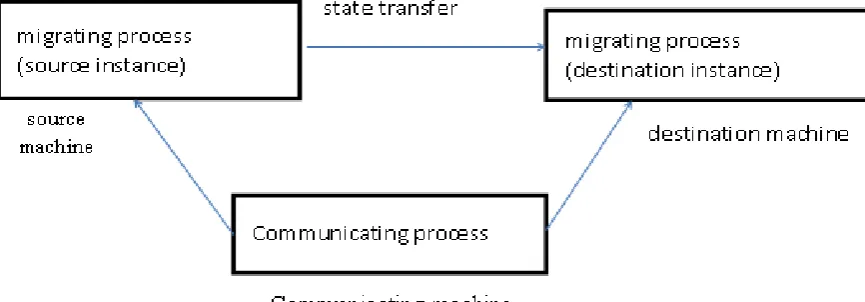
Related documents
In this research, we employed our key ideas within some famous heuristic and meta-heuristic algorithms, such as Genetic Algorithms (GAs), Simulated Annealing (SA), Hill
The Haida Nation trilogy of cases established the legal doctrine of duty to consult and where appropriate, accommodate Aboriginal peoples in every instance in advance of a
The stylohyoid process correlates with the anatomy and embryology of the second pharyngeal arch cartilage (Reichert’s cartilage), which is the origin of several struc- tures such
• Record sow body condition at weaning and include sow body condition in the genetic evaluation (together with the maternal ability to raise large and heavy litters), in order
For each plot, and for each data point (each model version) the average classification error is the average taken over all the simulation replications and over all the
Typically only a small number of ex- tra coefficients are retained in soft thresholding approach, so that the main difference in the denoising results comes from the shrinkage
Hire exceptional communicators, employees and leaders who actively listen, people who ask good questions, individuals who are ethical, people who do not manipulate others to get
– Biological input: Codon bias in coding regions, gene structure (start and stop codons, typical exon and intron length, presence of promoters, presence of genes on both
