A New Framework for Sign Language Recognition based on 3D Handshape Identification and Linguistic Modeling
6
0
0
Full text
Figure
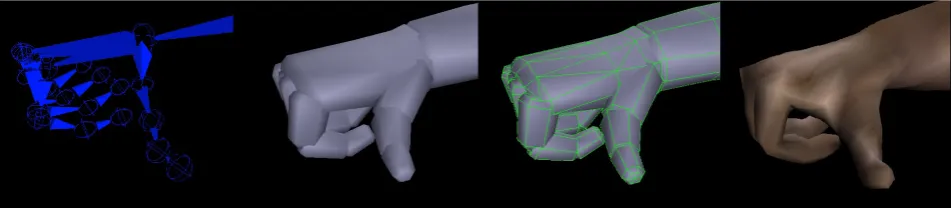
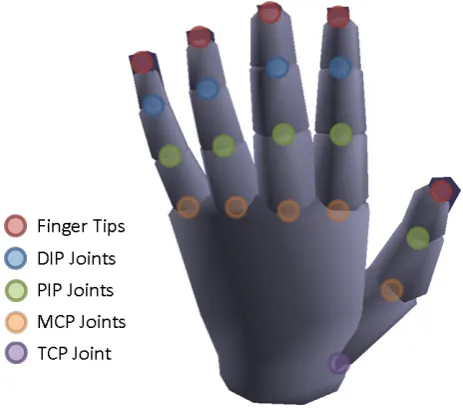
Related documents