Classifying mood in plurks
Mei-Yu Chen* [email protected]
Hsin-Ni Lin* [email protected]
Chang-An Shih** [email protected]
Yen-Ching Hsu* [email protected]
Pei-Yu Hsu* [email protected]
Shu-Kai Hsieh* [email protected]
*Department of English, National Taiwan Normal University ** Institute of Linguistics, Academia Sinica
Abstract
In this paper, we present a simple but efficient approach for the automatic mood classification of microblogging messages from Plurk platform. In contrast with Twitter, Plurk has become the most popular microblogging service in Taiwan and other countries1; however, no previous research has been done for the emotion and mood recognition, nor the Chinese affective terms or corpus available. Following the line of mashup programming, we thus construct a dynamic plurk corpus by pipelining Plurk APIs, Yahoo! Chinese segmentation APIs, etc to preprocess and annotate the corpus data. Based on the corpus, we conduct experiments by way of combining textual statistics and emoticons data, and our method yield the results with high performance. This work can be further extended to combine with affective ontology designed with emotion theory of appraisal.
Keyword: mood classification, plurks, keyness, emotion paradox
1
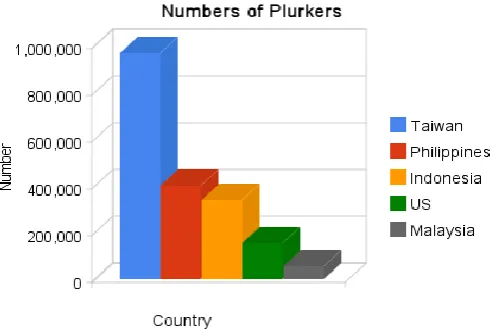
According to Alvin, the cofounder of Plurk website, the number of the plurkers in Taiwan had reached approximately 1 million, which was one-third of the total plurkers in October, 2009. Another statistic data is collected from Google trend for website, manifesting that Taiwan is the rank one region of visiting Plurk website (August,2010).
1.
Introduction
Recently, with the emergence of Web 2.0 content, sentiment and opinion mining in social media and network domains like Blogs, has gained great attention from computational linguistics and other fields. Mood/Emotion classification, as related to sentiment classification, whose goal is set to tag a text based on whether it expresses positive or negative sentiment, has been surveyed on lyrics in music domain.
Mood classification is useful for various applications; the mood intelligence module can be incorporated in (affective) dialogue systems, learning tutors, etc. to improve the naturalness of human-machine interaction.
Figure 1. Number of Plurkers
This paper addresses the task of classifying microblogging posts by mood. What motivates us to conduct this research is the fact that the above figure shows: Plurk2 is the most commonly used microblogging platform in Asia, and in contrast with other social networks, it has also become one of the most common forms of computer-mediated communication in Taiwan. In this paper, we aim to propose a simple and effective method in automatic classifying emotion of plurk messages for emotion.
The rest of the paper is organized as follows. Section 2 introduces the emoticons in plurk messages. Section 3 describes the construction of plurk corpus. Section 4 presents the experiment results and evaluation. Finally, Section 5 concludes the paper and summarizes our future work.
2.
Emoticon and Emotional Expression in Social Media
In the previous studies, computer systems have been designed to perform automatic sentiment analysis using elements from machine learning such as latent semantic analysis (LSA), Naive Bayes, support vector machines (SVM) etc. [1] [2]. A different set of features was utilized. For example, Mishne [1] uses many features extracted from Live Journal web blog service to train the SVM binary classifier for sentiment analysis.
2
It becomes even harder in the task of identifying (multiple) emotions. Jung et al. [3] show that there are some idiosyncratic natures of mood expression in plurk messages; for example, the initial mood may not be maintained all the way to the end (which also known as the fluctuation of moods). In addition, some blogs are so intertwined that even human readers would have difficulties in indentifying the mood, not to mention for the machine.
By scrutinizing the plurk data, we found that the emoticons3 can be utilized as useful features in presenting the emotional content of a conversation, especially in computer-mediated communication (CMC). As graphic representation of facial expressions, emoticons are used to remedy the lack of some non-verbal cues, such as head nodding, smiles, and it is why they are often imbued in the textual messages, where we want to set different tones, such as humor, irony, sarcasm, cuteness, flippancy or other emotions that our face is not there to deliver [4].
With the advantages of that fact that plurk messages are augmented with many plugins support for emoticons, we propose to extract the affective terms by 'bag-of-words' bootstrapped from the emoticons (non-verbal expressions) widely used in plurk domains, and use them to determine the overall emotion embedded within a plurk message.
3.
Plurking a Social Web Corpus
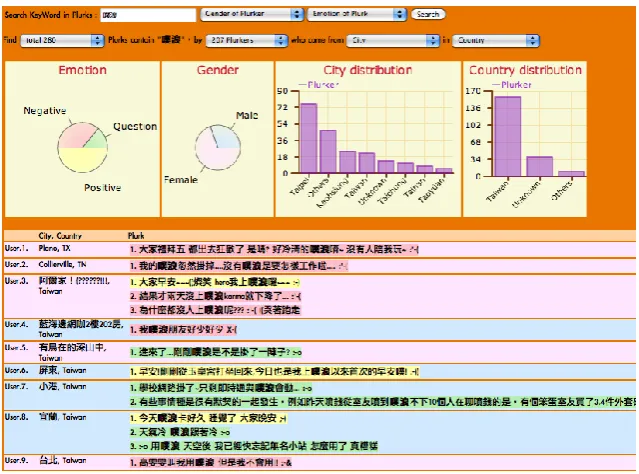
For this research, we constructed a Plurk social web-as-corpus (SocialWaC) in Taiwan. Plurk is a social journal service that allows users to showcase the events that make up their life, and follow the events of the people that matter to them in messages called plurks. Plurkers just post a new plurk and it'll appear on the timeline.
Figure 2. Snapshot of plurk timeline
3.1 Crawling and Preprocessing
3.1.1 Crawling Data
We use the official Plurk API4 to crawl the Plurk data. These include plurk data (with attributes of plurk_id, qualifier, date when the plurk was posted, content, response, emoticons,
3
Note that in this paper, we do not consider smileys, which is often used in other CMCs like emails communication.
4
fragments, with abundant use of emoticon, and available meta-information of users. As emoticons convey the sentiment that plurkers use to express their particular state of mind, the annotation is based on plurk level, with POS information and emoticons tagged.
One particularly interesting property that can be observed from our corpus data, is the availability of users‟ meta-information, which can be coupled with lexical information for computational sociolinguistic surveys. For instance, Figure 3 shows a socialized lexical network extracted from our corpus, visualized by vister software. The colored areas demonstrate the shared lexical patterns among certain social community.
Figure 3. Socialized lexical network
In addition, through the meta–information, we are also able to know when a certain gender or people from a certain location use a lexicon, how accompanying emotion is distributed. This is demonstrated in the website introduced in Section 3.3.
3.3 Availability
We‟ve made a website for the query of our corpus, which can be accessed via
http://140.122.83.235/plurk/.
[Step four] Manual Validation: After the automatic emoticon assignment, a manual validation is conducted. Two evaluators are requested to validate the emoticon assignment. This step aims to not only validate the results but also recall the accurate judgment of the aforementioned automatic emotion classification.
4.2 Data and Resource Description
To examine emoticons and emotional expression, we extract plurks in our corpus. Of 436,487 plurks, 103,171 (24%) were found that contain emoticons, 32,851 found containing default emoticons. To simplify the classification of emoticon categories, only default emoticons 9 are concerned in this current research.
We randomly divide the data with default emoticons into 80/20 division for training and testing, respectively. The keyword and keyness lists of 3 different emoticon categories are generated by the 80 division, and the testing data are construed by the 20 division.
4.3 Experiments with heuristic rules (H-rules)
All the test plurks are assigned to one of the three valences by the method described in Section 4.1. The second and third experiment is conducted with the following heuristic rules, respectively.
4.3.1 H1-Rule: Decomposing the plurks
The focus of our proposed method is similar to sentiment classification at the
sentence-level. However, according to the Pragmatic Information Structure, new information, the purpose of communication, is conveyed later than old information in sentences. As Emoticon possessing the communicative function, its regular sentence final position is corresponded to the Information Structure, and is closely related to the later fragment of sentence, especially in disjunctive sentence. For example, “Fragment 1 [I won the lottery this morning,] Fragment 2 [ but I lost the ticket in the afternoon .]” The fragment 1 conveys a proposition of positive emotion, but the real conveying information of this sentence is the second fragment, conveying a negative emotion and denoting by the emoticon in sentence final position. We thus wish to examine whether the sentence final fragment is most probable to contain affective content by restrict the Score Domain to the sentence final fragment only.
4.3.2 H2-Rule: Deleting inappropriate keywords
A few words cannot serve as Negative keywords due to the properties of their meanings; therefore, we delete those content words in our keyword lists. There are 3 words being deleted.
The first one is hao3 (好) 'good (adj.)/very (adv.).' As shown in the English translation, hao3 (好) can be a word of positive emotion ( i.e. "good") or an adverb of degree
9
(i.e. "very"), which conveys neutral emotion but usually be used in negative emotion to amplify the negative degree.
The second keyword being deleted is le (了), a Chinese aspectual particle. The particle provides no meaning but aspectual information. Therefore, le (了), like stop words, was not supposed to be a keyword.
The other word being deleted is chu fu2 (舒服) 'comfortable', a word is positive per se but is misanalyzed as a keyword of negation emotion. The misanalysis appears in several positive words in the experiment because those words usually follows bu4 (不) 'not', a negation adverb, to form a negative meaning. A problem arises here is that Yahoo! Chinese Segmentation system segmented the bu4-plus-word(s) pattern inconsistently. Sometimes bu4 is separated with the following adjective or verb; sometimes the bu4 and the adjective or verb together are segmented as a single word. To avoid the problem caused by inconsistence, we examine the 30-most-frequent separated words following bu4 in negative keywords. Among the 30 keywords, only chu fu2 'comfortable' is a word with positive emotion, so we delete only the word here.
4.4
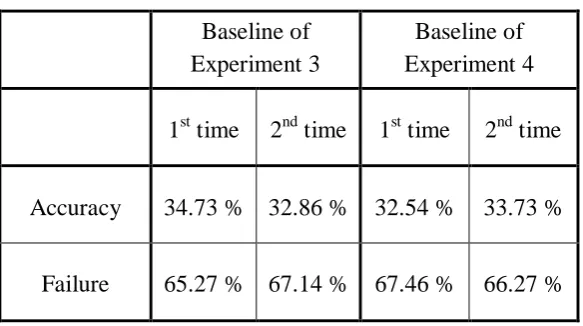
Baseline
Given no similar experiments have been conducted before, the baseline of our experiments is set as the results of randomly classifying each plurk in the testing data as one of valences (i.e. positive, interrogative, or negative). The random classification is automatically performed by a program written in Python.
4.5
Results and Analysis
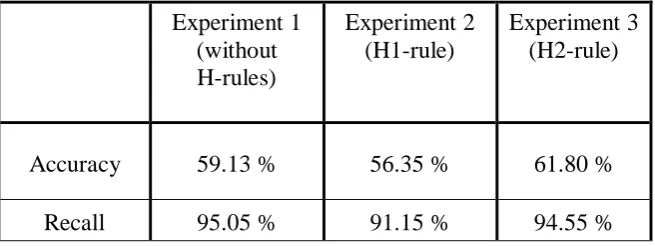
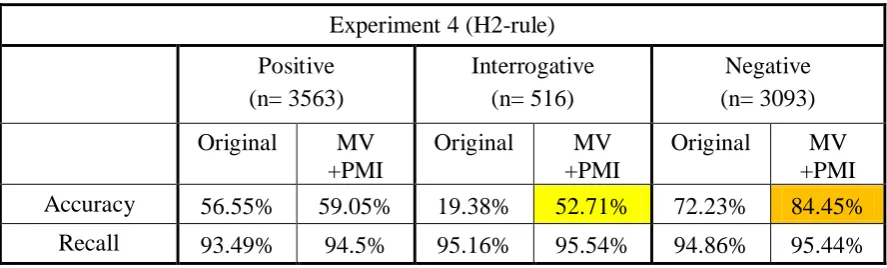
The results of the three experiments described in Section 4.1 and 4.3 are illustrated in Table1.
Table 1. The results of 3 experiments with and without heuristic rules
Experiment 1
(without H-rules)
Experiment 2 (H1-rule)
Experiment 3 (H2-rule)
Accuracy 59.13 % 56.35 % 61.80 %
Recall 95.05 % 91.15 % 94.55 %
[6] E. Spyropoulou, S. Buchholz, and S. Teufel, “Sentence-based Emotion classification for text-to-speech synthesis,” presented at Computational Aspects of Affectual and Emotional Interaction-2008, Patras, Greece, 2008.
[7] L. Anthony, “AntConc: A Learner and Classroom Friendly, Multi-Platform Corpus Analysis Toolkit,” in Proceedings of IWLeL 2004: An Interactive Workshop on Language e-Learning, pp. 7-13, 2004.
[8] A. Kilgarriff, “Comparing corpora,” International Journal of Corpus Linguistics, vol. 6, no. 1, pp. 97-133, 2001.
[9] P. Turney, “Thumbs Up or Thumbs Down? Semantic Orientation applied to Unsupervised Classification of Reviews,” in Proceeding of the Meeting of the Association for