Security Of Big Data Using Multitier Classifier
Sujit R. Borey1, Dr.P.MJawandhiya 2.M.E.CSE PLIT 1 ,PRINCIPAL PLIT 2
Email:sujeetbore3@gmail .com1 , [email protected]
ABSTRACT: This topic introduces Big data achieves more attention from researchers in recent years because it has
become in numerous application domains. The Random forest and LIME classifiers with base classifiers for improving performance of classification. Random Forest is higher accuracy and it can produce powerful results in range from excellent. The planed LIME classifier is large because it is tailored for handling big data. In this ensemble classifiers are combined at each tier. Next tier will collect outputs from previous tier, analyses and combine them and send their output to the next tier. Here multitier are used because of many tiers, work is divided into each of these tiers so that speed and accuracy increases [1]. It is easy to run. It includes different ensemble classifiers on several levels, combining strengths of their methods. This classifier is also concern for security of big data. They are generated automatically as a result of several iterations in applying ensemble Meta classifiers. The ensemble meta classifiers into several tiers simultaneously and combine them into one automatically generated iterative system so that many ensemble meta classifiers function as integral parts of other ensemble meta classifiers at higher tiers[2].
1. INTRODUCTION
This article introduces five-tier Large Iterative Multitier Ensemble (LIME) classifiers specifically designed for applications concerning the information security of web products and generate product review. The main aim of this paper is to develop LIME classifiers as a general technique that may be useful for the analysis of random forest in various application domains. the technology to extract the knowledge from the pre-existing databases. It is used to explore and analyses the same. The data which is to be mined varies from a small data-set to a large data-set i.e. Big Data. Big data is so large that it does not fit in the main memory of a single machine, and it need to process by efficient algorithms i.e. Random forest. Modern computing has entered the era of web Data[1]. The investigation of this new construction is important, because the [2]. This construction is illustrated in Figure 1.
Fig1.Five-tierclassifierprocessingbigdata.The directionofarrowsshowsdataflow.
Five-tier LIME classifiers achieved well higher performance compared with the base classifiers or standard ensemble Meta classifiers. This demonstrates that our new technique of combining diverse ensemble Meta classifiers into one unified five-tier ensemble incorporating diverse ensemble Meta classifiers as elements of different ensemble Meta classifiers can be applied to enhance classifications. This paper is organized as follows. Contains brief overview of previous related work [3]. Describes five-tier classifier investigated in this. Describes the base classifier which is used in this planned classifier and deals with the ensemble Meta classifiers used in this classifier [1].
With the increase in the popularity of social networking, micro-blogging and blogging websites, a huge quantity of data is generated. We know that the internet is the collection of networks. The age of the internet has changed the way people express their thoughts and feelings. The people are connecting with each other with the help of the internet through the blog post, online conversation forums, and many more .online user-generated reviews are of great practical use, because: 1) They have become an inevitable part of decision making process of consumers on product purchases ,hotel bookings, etc. 2) They collectively form a low cost and efficient feedback channel, which helps businesses to keep track of their reputations and to improve the quality of their products and services[4]. As a matter of fact, online reviews are constantly
growing in
quantity, while varying largely in content
huge amount of raw review data, many
sentiment analysis techniques have been
developed for past years [1].
1.1 Sentiment Analysis
An important part of the information era has been to seek the opinions and views of other individual. In the generation where there were no internet resources, it was customary for an individual to ask his or her friends and relatives for their thoughts before making decision. Organizations conducted opinion polls, surveys to understand the sentiment and opinion of general public towards its product or services. In the past some years, web documents are receiving great attention as a new communication mean that describes individual thoughts, experiences and opinions [12]. Sentiment analysis is a type of data mining that measures the inclination of people’s opinions through natural language processing (NLP), computational linguistics and text analysis, which are used to extract and analyze subjective information from the Web - mostly social media and similar sources. The analyzed data quantifies the general public's sentiments or reactions toward certain products, people or ideas and reveal the contextual polarity of the information [14]. There have been a large number of research studies and industrial applications in the area of public sentiment tracking and modeling sentiment. Sentiment Analysis is the method of determining whether or not a section of writing is positive, negative or neutral. It is conjointly referred to as opinion mining, derivation the opinion
perspective of a speaker [7]. A typical case for this technology is to get however individuals feel a few particular topics. Sentiment analysis is a method where the dataset consists of emotions, attitude or assessment that takes into consideration the way an individual’s thinks. The features used to categorize the sentences should have a realer strong adjective so as to summarize the review. These contents are even written in different approaches which are not easily inferred by the users or the organizations making it difficult to classify them. Sentiment Analysis influences to classify whether the information about the product is satisfactory or not before they get it. Marketers and organizations use this analysis to understand about their products or services in such a way that it can be offered as per the user’s needs [8]. Sentiment Analysis is more than just a feature in social analytics tool- it is a field of study. This is a field that is still being studied, not at great lengths due to the complexity of this analysis, in the same way that some aspects of linguistics are still up to debate or not fully understood [15].
1.2 What is aspect based Multitier Classifier?
domain-independent model for detecting explicit and implicit aspects in reviews for analysis. In the model, first a generalized method is proposed to learn multi-word aspects and then a set of heuristic rules is employed to take into account the influence of an user opinion word on detecting the aspect. Second a new metric based on mutual information and aspect frequency is proposed to score aspects with a new bootstrapping iterative algorithm [2].
2. LITERATURE REVIEW
In recent years, multiple classifier analysis, also known as user review mining, has been widely applied to various document types, such as mobile or product reviews, web pages and blogs. Sentiment analysis has caught attention as one of the most active research areas with the explosion of social networks. It is the process of analyzing which are extracted from different sources like the comments given on forums, reviews about products, various policies and the topics mostly associated with social networking sites and tweets. Social media technologies take on many different forms including magazines, Internet forums, weblogs, social blogs, micro blogging, social network, photographs, video, rating and social bookmarking. Micro blogging websites have evolved to become source of varied kind of information. This is due to nature of micros blogs on which people post real time messages about their opinions on a variety of topics, discuss current issues and express positive, negative sentiment for products they use in daily life. Companies manufacturing such products have started to poll these micro blogs to get a sense of general sentiment for their product. E-commerce website is a
worldwide popular website, which offers a social networking and micro blogging services, enabling its users to update their status in tweets, follow the people they are interested in, others posts and even communicate with them directly. Applying sentiment analysis on E-commerce website is the upcoming trend with researchers recognizing the scientific trials and its potential applications. The challenges unique to this problem area are largely attributed to the dominant informal tone of the micro blogging. Challenges are, E-commerce website contains an enormous number of text posts and it grows every day. The collected corpus can be arbitrarily large. Sentiment analysis is an exhaustive research field which has been in the study for decades. The research on sentiment analysis so far has mainly focused on two things: identifying whether a given textual entity is subjective or objective, and identifying the polarity of subjective texts. Various research works have been done in this area in recent years. A lot of interest has been generated in the field of sentiment analysis, with researchers recognizing the scientific trials and applications supported by the processing of subjective language.
2.1 Random Forest : The Random Forest builds a forest of random trees by generating many decision
tree predictors with randomly selected variable
subsets and utilizing a different subset of training and
validation data for each of these trees, as partitioning.
To control the variation in creating the set of random
trees, Random Forest uses the process of random
selection of features proposed. After creating many
trees, the resulting class prediction is based on votes
variables with lower rank are eliminated based on the
basis of empirical performance heuristics. [1]
3. PROBLEM DEFINITION to algorithmically detect and analyze all expressions of sentiment towards the different aspects of a reviewed product or service. This problem setting involves mainly two subtasks. • Product aspects: Given a specific type of product or service (e.g., digital cameras or hotels), we want to automatically derive the most relevant product aspects for this particular type. Which aspects characterize a product? Which aspects are most commonly discussed in customer reviews of this product (e.g., picture quality, battery life, ease of use)? Knowing the relevant product aspects, we must further develop methods to detect mentions of them in natural language text. • Sentiment expressions: Reviewers refer to product aspects in different contexts. They may use factual language and simply describe some aspects (e.g., "the camera has a 3x optical zoom") or they may express their opinion towards an aspect (e.g., "the 3x optical zoom works perfectly"). We are primarily interested in the latter case. Our goal is to automatically detect expressions of sentiment in customer reviews. We further aim at analyzing the polarity of these expressions. We want to know whether an utterance is predominantly positive (e.g., "works perfectly") or negative ("is totally crap").
One of the most difficult problem in database mining is the large volume of data needs to be handled. E-commerce website is a media where an individual can tweet their reviews regarding various sections such as movies, products, social as well as current affair. It has been seen that it is only use for comments or posting for product, but one cannot decide the polarity or one cannot analyze the reviews related to products are good or bad. Ranking of reviews not be perform. It is generally difficult to find the exact causes of sentiment variations since they may involve complicated internal and external factors. Before sentiment analysis is done on only text it doesn’t tell about human emotions or emoticons. Most of the People uses their local languages or mother tongue to express their feelings in E-commerce website, it has been seen that in rare amount the people tweets in English. Mining emerging events/topics is challenging, the events and topics related to opinion variations are hard to represent. Accuracy of the previous system can be more enhanced by using different technique.
and evaluating the relevant subtasks/subcomponents of such a system. In detail, our contributions are as follows:
3.2 Feasibility Study
A project must be feasible in all three ways to merit further development.
3.2.1 Technical Feasibility:
A large part of determining resource has to do with assessing technical feasibility. The analyst must find out whether current technical resources can be upgraded or added to in a manner that fulfills the request under consideration. Sometimes “add-ons” to existing systems are costly and not worthwhile, because they meet needs inefficiently. If existing systems cannot be added onto, the next question becomes whether there is technology in existence that meets the specifications. The project is analyzed along with the technical resources which are required for developing the proposed system. The technical resources are found to be feasible.
3.2.2 Economic Feasibility:
Economic feasibility is the second part of resource determination. The basic resources to consider are the time and the cost of doing a full systems study including the estimated cost of hardware, and the estimated cost of software. The concerned business must be able to see the value of the investment it is pondering before committing to an entire systems study. If short-term costs are not overshadowed by long-term gains or produce no intermediate reduction in operating costs, the system is not economically feasible and the project should not proceed any further. The resources required for developing the system are identified such as software
and hardware. The requirement of software and hardware are found to be economical.
3.2.4 Five Tier Classifier: After choosing proper choices, the whole system is generated automatically by the SimpleCLI, using the embedded iterative and recursive capability of Java programming.
Fig.2Initializationoffive-tierclassifier.
third tier ensemble Meta classifiers and produces the final decision of the classifier.
Our work shows that large five-tier LIME classifiers are quite easy to use and can be applied to improve classifications, if diverse ensemble Meta classifiers are combined at different tiers. It is an interesting question for future research to investigate LIME classifiers for other large datasets [3]. Random Forest outperformed other base classifiers for the malware data set, and Decorate improved its outcomes better than other ensemble Meta classifiers did. The best outcome of AUC 0.998 was obtained by the fourth-tier LIME classifier where MultiBoost was used at the fourth tier, Decorate was used at the third tier and Bagging was applied at the second tier. The performance of ensemble Meta classifiers considered in this paper depends on several numerical input parameters. In all experiments we used them with the same default values of these parameters in order to have a uniform equivalent comparison of outcomes across all of this ensemble Meta classifier [1].
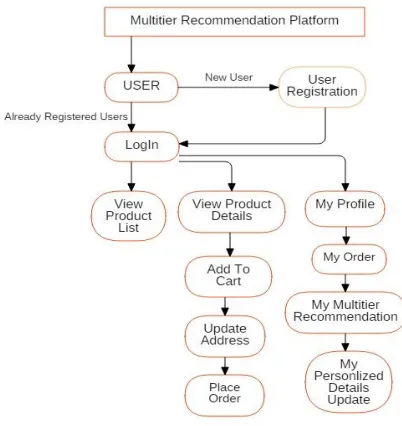
4. SYSTEM DESIGN
4.
1 Data flow diagramThis is stage of the project when the theoretical design is turned out in working system. Thus it can be considered to be the most critical stage in achieving a successful new system and in giving the user, confidence that the new system will work and be effective. The framework involves careful
planning, investigation of existing system and its constraints on implementation, designing of methods to achieve.
Figure 6.1 Data flow diagram
5. IMPLEMENTATION
5.1 Execution Details
product, and that graph represent positive, neutral, negative status.
There are two modules
1. User
2. Admin
7.2.1 User
Login page
Screenshot User Login Page
In computer security, logging in, is the process by which an individual gains access to a computer system by identifying and authenticating themselves. User credentials are some form of “username” and a matching “password”, and those credentials themselves are sometimes referred to as a login. When access is no longer needed, the user cans logout the page.
1. Home Page
Screenshot Home Page of e-commerce site
Screenshot 7:2 is home page of ecommerce website. On home page there is a list of product which are categories such as Mobiles, Smart TV, Tabs
Screenshot Combine Product list of Ecommerce
Website
Screenshot 7.3 shows the list of all types of product in this page. Costumer may view all products to get just idea of what the costumer himself wants to find.
3.Smart TV product
Screenshot List of Smart TV product page
Screenshot 6.4 shows the various products related to television sector .so user can find and buy easily any product.
4.Tab
Screenshot List of Tabs product section
Screenshot shows the various products related to tabs sector .so user can find and buy easily any product.
5.LIME classifier for 5 layer Multitier
Screenshot LIME classifier for 5 layer Multitier
6. CONCLUSIONS:
ratings of reviews as supervision and constraint data, and can jointly infer hidden aspects and sentiments that are not only meaningful but also predictive of overall of the review documents. We conducted experiments using publicly available real-world review data, and extensively compared gender, age, products with seven well-established representative baseline methods. For se-mantic aspect detection and aspect-level sentiment identification problems, LIME classifier outperforms all the generative benchmark models,
7. Future Work:
Online user-generated reviews are often associated with location or time-stamp information. For future work, we will extend the proposed model by modeling the meta-data to cope with the spatio-temporal sentiment analysis of online reviews. Probabilistic topic modeling approaches to sentiment analysis often requires the number of latent topics to be specified in advance of analyzing review data. An-other interesting future direction of our work is to develop Bayesian nonparametric model, which can automatically estimate the number of latent topics from review data, and also allow the number of the topics to increase as new data examples appear. We have illustrated a method for extracting both explicit and implicit aspects from opinionated text.
The proposed framework only leverages on common-sense knowledge and on the dependency structure of sentences and, hence, is unsupervised. As future work, we aim to discover more rules for aspect extraction. Another key future effort is to combine existing rules for complex aspect extraction; we have developed an aspect knowledge base using WorldNet
and SenticNet. We will focus on extending the scalability of such knowledge base.
8. PROPOSED SYSTEM AND ADVANTAGES
8.1The Proposed system
Develop a novel supervised joint aspect and five tier multitier classifier which is able to cope with aspect-based on web analysis and overall project analysis in a unified framework. Represents each review document in the form of user opinion pairs and can simultaneously model aspect terms words of the review for hidden aspect and sentiment detection. It also uses global which often comes with Online, various reviews are detected by forming pairs of aspect terms and their user opinions using model.
It leverages sentiment prior information, and can explicitly build the correspondence between detected sentiments (latent variables) and real world sentiment orientations (e.g., positive or negative).
REFERENCES
[1]. Jemal H. Abawajy, Andrei Kelarev, Morshed Chowdhury,” Large Iterative Multitier Ensemble Classifiers for Security of Big Data” , in IEEE TRANSACTIONS ON EMERGING TOPICS IN COMPUTING, 30 October 2014.
[2]. Laura Auria, Rouslan A. Moro, “Support Vector Machines (SVM) as a Technique for Solvency Analysis”, in Berlin, August 2008.
[3]. C. Liu et al.”An iterative hierarchical key exchange scheme for secure scheduling of big data applications in cloud computing,'' in Proc. 12th classifier rescheduling,'' in Proc. 10th ISPAN, 2009, pp. 789-793.
[5]. R. Islam and J. Abawajy, ``A multi-tier phishing detection and filtering approach,'' J. Netw. Comput. Appl., vol. 36, no. 1, pp. 324_335, 2013.
[6]. Tan, Shulong, et al. "Interpreting the public sentiment variations on E-commerce website." IEEE transactions on knowledge and data engineering 26.5 (2014): 1158-1170.
[7]. Gautam, Geetika, and DivakarYadav. "Sentiment analysis of E-commerce website data using machine learning approaches and semantic analysis." Contemporary Computing (IC3), 2014 Seventh International Conference on. IEEE, 2014. [8]. Jha, Vandana, et al. "HOMS: Hindi opinion mining
system." Recent Trends in Information Systems (ReTIS), 2015 IEEE 2nd International Conference on. IEEE, 2015.
[9]. Larsen, Mark E., et al. "We Feel: mapping emotion on E-commerce website." IEEE journal of biomedical and health informatics 19.4 (2015): 1246-1252.
[10].Luo, Yan, and Wei Huang. "Product Review Information Extraction Based on Adjective Opinion Words." Computational Sciences and Optimization (CSO), 2011 Fourth International Joint Conference on. IEEE, 2011.
[11].Khan, Aurangzeb, and BaharumBaharudin. "Sentiment classification using sentence-level semantic orientation of opinion terms from blogs." National Postgraduate Conference (NPC), 2011. IEEE, 2011.
[13].Agarwal, Basant, Vijay Kumar Sharma, and Namita Mittal. "Sentiment classification of review documents using phrase patterns." Advances in Computing, Communications and Informatics (ICACCI), 2013 International Conference on. IEEE, 2013.
[14].Binali, Haji, VidyasagarPotdar, and Chen Wu. "A state of the art opinion mining and its application domains." Industrial Technology, 2009. ICIT 2009. IEEE International Conference on. IEEE, 2009. [15].Myriam D. Munezero, CalkinSuero Montero
Member, IEEE, ErkkiSutinen, and John Pajunen "Are They Different? Affect, Feeling, Emotion, Sentiment, and Opinion Detection in Text. DOI 10.1109/TAFFC.2014.2317187,. IEEE transactions on affective computing,
[16].Pallavi Sharma and Nidhi Mishra "Feature level Sentiment Analysis on Movie Reviews." 2016 2nd International Conference on Next Generation Computing Technologies (NGCT-2016) Dehradun, India 14-16 October 2016
[17].Pang, Bo, and Lillian Lee. "Opinion mining and sentiment analysis." Foundations and trends in information retrieval 2.1-2 (2008): 1-135
[18].Bifet A and Frank E, “Sentiment Knowledge Discovery in E-commerce website Streaming Data”, In Discovery Science, Springer, pp 1-5,2010. [19].Luciano Barbosa and JunlanFeg,“Robust Sentiment
Detection on E-commerce website from Biased and noisy Data”, 23rd International Conference on Computational Linguistic, pp 36- 44, 2010.
[20].M.Hu and B. Liu, “Mining and Summarizing Customer Reviews”,4 th proceeding International