Data Warehousing
& Data Mining
Wolf-Tilo Balke Kinda El Maarry
Institut für Informationssysteme
Technische Universität Braunschweig http://www.ifis.cs.tu-bs.de
7. Building the DW
7.1 The DW Project
7.2 Data Extract/Transform/Load (ETL)
7.3 Metadata
•
Building a DW, is a complex IT project
– A middle size DW-project contains 500-1000 activities
•
DW-Project organization
– Project roles and corresponding tasks, e.g.:
7.1 The DW Project
Roles Tasks
DW-PM Project Management
DW-Architect Methods, Concepts, Modeling
DW-Miner Concepts, Analyze(non-standard)
Domain Expert Domain Knowledge
DW-System Developer System- and metadata-management,
•
Usual tasks in a DW-Project
– Communication, as process of information exchange between team members
– Conflict management
• The magical triangle, compromise between time, costs
and quality
– Quality assurance
• Performance, reliability, scalability, robustness, etc.
– Documentation
•
Software choice
– Database system for the DW
• Usually the choice is to use the same technology provider as for the operational data
• MDB vs. RDB
– ETL tools
• Differentiate by the data cleansing needs
– Analysis tools
• Varying from data mining to OLAP products, with a focus on reporting functionality
– Repository
• Not very oft used
• Helpful for metadata management
•
Hardware choice
– Data storage
• RAID systems, SAN’s, NAS’s
– Processing
• Multi-CPU systems, SMP, Clusters
– Failure tolerance
• Data replication, mirroring RAID, backup strategies
– Other factors
• Data access times, transfer rates, memory bandwidth,
network throughput and latency
•
Project
Timeline
, depends on the development
methodology, but usually
– Phase I – Proof of Concept
• Establish Technical Infrastructure
• Prototype Data Extraction/Transformation/Load
• Prototype Analysis & Reporting
– Phase II – Controlled Release
• Iterative Process of Building Subject Oriented Data Marts
– Phase III – General Availability
• On going operations, support and training, maintenance and growth
•
The most important part of the DW building project
is defining the
ETL process
•
What is ETL?
– Short for extract, transform, and load
– Three database functions that are combined into one tool to pull data out of productive databases and place it into the DW
• Migrate data from one database to another, to form data marts and data warehouses
• Convert databases from one format or type to another
•
When
should we ETL?
– Periodically (e.g., every night, every week) or after significant events
– Refresh policy set by administrator based on user needs and traffic
– Possibly different policies for different sources
– Rarely, on every update (real-time DW)
• Not warranted unless warehouse data require current data
(up to the minute stock quotes)
DW & DM – Wolf-Tilo Balke – Institut für Informationssysteme – TU Braunschweig 9
7.2 ETL
•
ETL is used to integrate heterogeneous systems
– With different DBMS, operating system, hardware, communication protocols
•
ETL challenges
– Getting the data from the source to target as fast as possible
– Allow recovery from failure without restarting the whole process
•
This leads to balance between
writing data
to
staging tables or
keeping it in memory
•
Staging area,
basic rules
– Data in the staging area is owned by the ETL team
• Users are not allowed in the staging
area at any time
– Reports cannot access data from the staging area
– Only ETL processes can write to and read from the staging area
•
Staging area
structures
for holding data
– Flat files
– XML data sets
– Relational tables
•
Flat files
– ETL tools based on scripts, such as Perl, VBScript or JavaScript
– Advantages
• No overhead of maintaining metadata as DBMS does
• Sorting, merging, deleting, replacing and other data-migration
functions are much faster outside the DBMS
– Disadvantages
• No concept of updating
• Queries and random access lookups are not well supported
by the operating system
• Flat files can not be indexed for fast lookups
•
When should
flat files
be used?
– Staging source data for safekeeping and recovery
• Best approach to restart a failed process is by having data
dumped in a flat file
– Sorting data
• Sorting data in a file system may be more efficient as
performing it in a DBMS with Order By clause
• Sorting is important: a huge portion of the ETL processing cycles goes to sorting
•
When should
flat files
be used?
– Filtering
• Using grep-like functionality
– Replacing text strings
• Sequential file processing is much faster at system-level
than using a database
•
XML Data
sets
– Used as common format for both input and output from the ETL
system
– Generally, not used for persistent staging – Useful mechanisms • XML schema (successor of DTD) • XQuery, XPath • XSLT
7.2 Data Structures
•
Relational tables
– Using tables is most appropriate especially when there are no dedicated ETL tools
– Advantages
• Apparent metadata: column names data types and lengths,
cardinality, etc.
• Relational abilities: data integrity as well as normalized
staging
• Open repository/SQL interface: easy to access by any SQL
compliant tool
– Disadvantages
• Sometimes slower than the operating file system
•
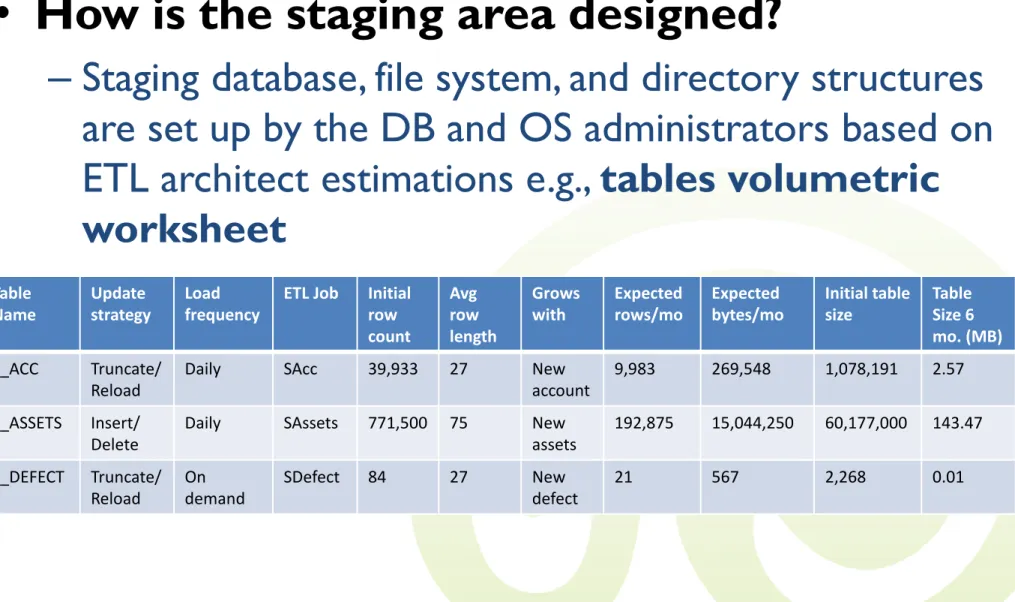
How is the staging area designed?
– Staging database, file system, and directory structures are set up by the DB and OS administrators based on ETL architect estimations e.g., tables volumetric
worksheet
7.2 Staging Area - Storage
Table Name Update strategy Load frequency
ETL Job Initial row count Avg row length Grows with Expected rows/mo Expected bytes/mo Initial table size Table Size 6 mo. (MB) S_ACC Truncate/ Reload
Daily SAcc 39,933 27 New account
9,983 269,548 1,078,191 2.57 S_ASSETS Insert/
Delete
Daily SAssets 771,500 75 New assets 192,875 15,044,250 60,177,000 143.47 S_DEFECT Truncate/ Reload On demand SDefect 84 27 New defect 21 567 2,268 0.01
•
ETL
– Data extraction
– Data transformation
– Data loading
•
Data Extraction
– Data needs to be taken from a data source so that it can be put into the DW
• Internal scripts/tools at the data source, which export the data to be used
• External programs, which extract the data from the source
– If the data is exported, it is typically exported into a text file that can then be brought into an intermediary
database
– If the data is extracted from the source, it is typically transferred directly into an intermediary database
•
Steps
in data extraction
– Initial extraction
• Preparing the logical map
• First time data extraction
– Ongoing extraction
• Just new data
• Changed data
• Or even deleted data
•
Logical map
connects the original source data
to the final data
•
Building the logical map
: first identify the data
sources
– Data discovery phase
• Collecting and documenting source systems: databases,
tables, relations, cardinality, keys, data types, etc.
– Anomaly detection phase
• NULL values can destroy any ETL process, e.g., if a foreign
key is NULL, joining tables on a NULL column results in
data loss, because in RDB NULL ≠ NULL
•
Example of solving NULL anomalies
– If NULL on foreign key then use outer joins
– If NULL on other columns then create a business rule to replace NULLs while loading data in DW
•
Ongoing Extraction
– Data needs to be maintained in the DW also after the initial load
• Extraction is performed on a regular basis
• Only changes are extracted after the first time
•
How do we detect changes?
•
Detecting changes (new/changed data)
– Using audit columns
– Database log scraping or sniffing
– Process of elimination
•
Using
audit columns
– Store the date and time a record has been added or modified at
– Detect changes based on date stamps higher than the last extraction date
•
Log scraping
– Takes a snapshot of the database redo log at a
certain time (e.g., midnight) and finds the transactions affecting the tables ETL is interested in
– It can be problematic when the redo log gets full and is emptied by the DBA
•
Log sniffing
– Pooling the redo log at small time granularity, capturing the transactions on the fly
– The better choice: suitable also for real-time ETL
•
Process of elimination
– Preserves exactly one copy of each previous extraction
– During next run, it compares the entire source tables against the extraction copy
– Only differences are sent to the DW
– Advantages
• Because the process makes row by row comparisons, it is
impossible to miss data
• It can also detect deleted rows
•
Data transformation
– Uses rules, lookup tables, or combinations with other data, to convert source data to the desired state
•
2 major steps
– Data Cleaning
• May involve manual work
• Assisted by artificial intelligence
algorithms and pattern recognition
– Data Integration
• May also involve manual work
•
Extracted data can be dirty. How does clean data
look like?
•
Data Quality
characteristics:
– Correct: values and descriptions in data represent their associated objects truthfully
• E.g., if the city in which store A is located is Braunschweig,
then the address should not report Paris
– Unambiguous: the values and descriptions in data can be taken to have only one meaning
– Consistent: values and descriptions in data use one constant notational convention
• E.g., Braunschweig can be expressed as BS or Brunswick, by
our employees in USA. Consistency means using just BS in all our data
– Complete
• Individual values and descriptors in data have a value (not
null)
•
The
data cleaning engine
produces 3 main
deliverables:
– Data-profiling results:
• Meta-data repository describing schema definitions, business
objects, domains, data sources, table definitions, data rules, value rules, etc.
• Represents a quantitative assessment of original data
sources
– Error event table
• Structured as a dimensional star schema
• Each data quality error identified by the cleaning subsystem
is inserted as a row in the error event fact table
7.2 Cleaning Deliverables
Data Quality Screen:
- Status report on data quality
- Gateway which lets only clean data go through
– Audit dimension
• Describes the data-quality context of a fact table record
being loaded into the DW
• Attached to each fact record
• Aggregates the information from the error event table on a
per record basis
7.2 Cleaning Deliverables
Audit key (PK)
Completeness category (text) Completeness score (integer)
Number screens failed Max severity score
Extract timestamp Clean timestamp
•
Overall Process Flow
•
Is data really dirty?
7.2 Data Cleaning
Data
•
Sometimes data is
just garbage
– We shouldn’t load garbage in the DW
•
Cleaning data manually
takes just…forever!!!
•
Use tools to clean data semi-automatic
– Commercial software
• SAP Business Objects
• IBM InfoSphere Data Stage
• Oracle Data Quality and Oracle Data Profiling
– Open source tools
• E.g., Eobjects DataCleaner, Talend Open Profiler
•
Data cleaning process: use of thesaurus, regular
expressions, geographical information, etc.
•
Regular expressions for date/time data
•
Core of the data cleaning engine: anomaly
detection phase
– Data anomaly is a piece of data which doesn’t fit into the domain of the rest of the data it is stored with
• E.g., Male named Marry???
•
Anomaly detection
– Count the rows in a table while grouping on the column in question e.g.,
• SELECT city, count(*) FROM order_detail GROUP BY city
7.2 Anomaly Detection
City Count(*) Bremen 2 Berlin 3 WOB 4,500 BS 12,000 HAN 46,000 …•
What if our table has 100 million rows with
250,000 distinct values?
– Use data sampling e.g.,
• Divide the whole data into 1000 pieces, and choose 1
record from each
• Add a random number column to the data, sort it an take
the first 1000 records
• Etc.
– Common mistake is to select a range of dates
• Most anomalies happen temporarily
•
Data profiling
– Pay closer look to strange values
– Observe data distribution pattern
• Gaussian distribution
7.2 Data Quality
SELECT AVERAGE(sales_value) – 3 * STDDEV(sales_value), AVERAGE(sales_value) + 3 * STDDEV(sales_value) INTO Min_resonable, Max_resonable FROM …
•
Data distribution
– Flat distribution
• Identifiers distributions (keys)
– Zipfian distribution
• Some values appear more often
than others
– In sales, more cheap goods are sold than expensive ones
•
Data distribution
– Pareto, Poisson, S distribution
•
Distribution discovery
– Statistical software: SPSS, StatSoft, R, etc.
•
Data integration
– Several conceptual schemas need to be combined into a unified global schema
– All differences in perspective and terminology have to be resolved
– All redundancy has to be removed
7.2 Data Integration
schema 2 schema 4 schema 3 schema 1•
There are
four basic steps
needed for
conceptual schema integration
1. Preintegration analysis 2. Comparison of schemas 3. Conformation of schemas 4. Merging and restructuring
of schemas
•
The integration process needs
continual refinement and
reevaluation
DW & DM – Wolf-Tilo Balke – Institut für Informationssysteme – TU Braunschweig 46
7.2 Schema Integration
schemas with conflicts modified schemas list of conflicts integrated schema identify conflicts resolve conflicts integrate schemasPreintegration analysis
Comparison of schemas
Conformation of schemas
Merging and restructuring
•
Preintegration analysis
needs a close look on
the individual conceptual schemas to decide for
an
adequate integration strategy
– The larger the number of constructs, the more important is modularization
– Is it really sensible/possible to integrate all schemas?
7.2 Schema Integration
Integration strategy
Binary approach n-ary approach
Sequential integration Balanced integration One-shot integration Iterative integration
•
Schema conflicts
– Table/Table conflicts
• Table naming e.g., synonyms, homonyms
• Structure conflicts e.g., missing attributes
• Conflicting integrity conditions
– Attribute/Attribute conflicts
• Naming e.g., synonyms, homonyms
• Default value conflicts
• Conflicting integrity conditions e.g., different data types or
boundary limitations
– Table/Attribute conflicts
•
The basic goal is to make schemas
compatible
for integration
•
Conformation usually needs
manual
interaction
– Conflicts need to be resolved semantically
– Rename entities/attributes
– Convert differing types, e.g., convert an entity to an attribute or a relationship
– Align cardinalities/functionalities
– Align different datatypes
•
Schema integration is a
semantic process
– This usually means a lot of manual work
– Computers can support the process by matching
some (parts of) schemas
•
There have been some approaches towards
(semi-)automatic matching
of schemas
– Matching is a complex process and usually only
focuses on simple constructs like ‘Are two entities semantically equivalent?’
– The result is still rather error-prone…
•
Schema Matching
– Label-based matching
• For each label in one schema consider all labels of the other schema and every time gauge their semantic similarity (Price vs Cost)
– Instance-based matching
• E.g., find correlations between attributes: ‘Are there duplicate tuples?’ or ‘Are the data distributions in their respective domains similar?’
– Structure-based matching
• Abstracting from the actual labels, only the structure of the schema is evaluated, e.g., regarding element types, depths in hierarchies, number and type of relationships, etc.
•
If integration is
query-driven
only Schema
Mapping is needed
– Mapping from one or more source schemas to a target schema
7.2 Schema Integration
Data Source schema S Correspondence Target schema T Correspondence Mapping compiler Low-level mapping High-level mapping•
Schema Mapping
– Abstracting from the actual labels, regarding element types, depths in hierarchies, number and type of
relationships, etc.
7.2 Schema Integration
Product ProdID: Decimal Product: VARCHAR(50) Group: VARCHAR(50) Categ: VARCHAR(50) Product ID: Decimal Product: VARCHAR(50) GroupID:Decimal•
Schema integration in pratice
– BEA AquaLogic Data Services
• Special Feature: easy-to-use modeling: “Mappings and
transformations can be designed in an easy-to-use GUI
tool using a library of over 200 functions. For complex mappings and
transformations, architects and developers can bypass the GUI tool and use an Xquery source code editor to define or edit services. “
7.2 Schema Integration
•
What tools are actually given to support
integration?
– Data Translation Tool
• Transforms binary data into XML
• Transforms XML to binary data
– Data Transformation Tool
• Transforms an XML to another XML
– Base Idea
• Transform data to application specific XML → Transform to
XML specific to other application / general schema →
Transform back to binary
• Note: the integration work still has to be done manually
•
“I can’t afford expensive BEA consultants and the
AquaLogic Integration Suite, what now??”
– Do it completely yourself
• Most used technologies can be found as Open Source
projects (data mappers, XSL engines, XSL editors, etc)
– Do it yourself with specialized tools
• Many companies and open source projects are specialized in
developing data integration and transformation tools
– CloverETL
– Altova MapForce
– BusinessObjects Data Integrator
– Informatica Powerhouse, etc…
•
Altova MapForce
– Same idea as the BEA Integrator
• Also based on XSLT and a data description language
– Editors for binary/DB to XML mapping
– Editor for XSL transformation
– Automatic generation of data sources, web- services, and
transformation modules in Java, C#, C++
•
Google Refine
•
The
loading
process can be broken down into 2
different types:
– Initial load
– Continuous load (loading over time)
•
Issues
– Huge volumes of data to be loaded
– Small time window available when warehouse can be taken off line (usually nights)
– When to build index and aggregated tables
– Allow system administrators to monitor, cancel, resume, change load rates
– Recover gracefully - restart after failure from where you were and without loss of data integrity
•
Initial Load
– Deliver dimensions tables
• Create and assign surrogate keys, each time a new cleaned and conformed dimension record has to be loaded
• Write dimensions to disk as physical tables, in the proper dimensional format
– Deliver fact tables
• Utilize bulk-load utilities
• Load in parallel
– Tools
• DTS – Data Transformation Services (set of tools)
• bcp utility – batch copy
• SQL* Loader
•
Continuous load
(loading over time)
– Must be scheduled and processed in a specific order to maintain integrity, completeness, and a satisfactory level of trust (if done once a year… the data is
obsolete)
– Should be the most carefully planned step in data warehousing or can lead to:
• Error duplication
• Exaggeration of inconsistencies in data
•
Continuous load of
facts
– Separate updates from inserts
– Drop any indexes not required to support updates
– Load updates
– Drop all remaining indexes
– Load inserts through bulk loaders
– Rebuild indexes
•
Metadata
- data about data
– In DW, metadata describe the contents of a data warehouse and how to use it
• What information exists in a data warehouse, what the
information means, how it was derived, from what source systems it comes, when it was created, what pre-built
reports and analyses exist for manipulating the information, etc.
•
Types
of metadata in DW
– Source system metadata
– Data staging metadata
– DBMS metadata
•
Source system
metadata
– Source specifications
• E.g., repositories, and source logical schemas
– Source descriptive information
• E.g., ownership descriptions, update frequencies and access
methods
– Process information
• E.g., job schedules and extraction code
•
Data staging
metadata
– Data acquisition information, such as data
transmission scheduling and results, and file usage
– Dimension table management, such as definitions of dimensions, and surrogate key assignments
– Transformation and aggregation, such as data
enhancement and mapping, DBMS load scripts, and aggregate definitions
– Audit, job logs and documentation, such as data lineage records, data transform logs
•
DW schema: e.g., Cube description metadata
•
How to build a DW
– The DW Project: usual tasks, hardware, software, timeline (phases)
– Data Extract/Transform/Load (ETL):
• Data storage structures, extraction strategies (e.g., scraping, sniffing)
• Transformation: data quality, integration
• Loading: issues, and strategies, (bulk loading for fact data is a must)
– Metadata:
• Describes the contents of a DW, comprises all the intermediate products of ETL,
• Helps for understanding how to use the DW
•
Real-Time Data Warehouses
– Real-Time Requirements
– Real-Time ETL
– In-Memory Data Warehouses