Numerical
Ocean
Modeling
and
Simulation
with
CUDA
Jason
Mak
Paul
Choboter
Chris
Lupo
Abstract—ROMS is software that models and simulates an ocean region using a finite difference grid and time stepping. ROMSsimulationscantakefromhourstodaystocompletedue tothecompute-intensivenatureofthesoftware.Asaresult,the sizeandresolutionofsimulationsare constrainedbytheperfor mance limitations of modern computing hardware. To address these issues, the existing ROMS code can be run in parallel witheitherOpenMPorMPI.Inthiswork,weimplementanew parallelization of ROMS on a graphics processing unit (GPU) usingCUDAFortran.Weexploitthemassiveparallelismoffered by modernGPUsto gainaperformancebenefitat alower cost andwithlesspower.Totestourimplementation,webenchmark with idealistic marine conditions as well as real data collected fromcoastalwatersnearcentralCalifornia.Ourimplementation yields a speedup of up to 8x over a serial implementation and2.5xoveranOpenMPimplementation,whiledemonstrating comparableperformancetoaMPIimplementation.
I. INTRODUCTION
The RegionalOcean Modeling System (ROMS)is a free-surface, primitive equation ocean model widely used by the scientific community for a diverse range of applications [1]. ROMSevolvesthecomponentsofvelocity,temperature,salin ity and sea surface height forward in time using a finite-difference discretization of the equations of motion, with curvilinearcoordinatesinthehorizontalandterrain-following coordinates in the vertical [2]. Sophisticatednumerical tech niques are employed,including asplit-explicit time-stepping schemethattreatsthefastbarotropic(2D)andslowbaroclinic (3D) modes separately for improved efficiency [3]. ROMS also containsa suiteof data assimilation toolsthat allow the usertoimprovetheaccuracyofasimulationbyincorporating observationaldata.Thesetoolsarebasedonfourdimensional variational methods [4], which have a solid mathematical foundationandgeneratereliableresultsinpractice,butrequire much more computational resources than a run without any assimilation of data.
The accuracyandperformanceof anyROMSsimulationis limited bythe resolutionof thefinitedifferencegrid.Increas ing the grid resolution increases the computational demands notonlybytheincreaseofthenumberofpointsinthedomain, but also because numerical stability requirements demand a smaller time step on afiner grid. The ability to increase the grid size to obtain a finer-grain resolution and therefore a moreaccuratemodelislimitedbythecomputingperformance of hardware. This is particularly true when performing data assimilation, where the run-time can beorders of magnitude
larger than non-assimilating runs, and where accuracy of a simulationisofparamountconcern.Inorderforthenumerical modeltogiveadesiredaccuracywithreasonableperformance, ROMSusesparallelcomputing totakeadvantageof its grid-basedmodel.AsharedmemorymodelusingOpenMPenables ROMStotakeadvantageofmodernmulti-coreprocessors,and adistributedmemorymodelusingMPIprovidesaccesstothe computingpowerof multi-nodeclusters.
Graphics processingunits havesteadily evolved from spe cialized rendering devices togeneral-purpose, massively par allel computing devices (GPGPU). Because of the relative low costand powerof GPUs, these devices havebecome an attractivealternativetolargeclustersforhigh-performancesci entificcomputing.Withsupportforalargeamountofthreads, an architectureoptimizedfor arithmeticoperations, andtheir inherentdata-parallelism, GPUsare naturallysuitable for the parallelization oflarge-scale scientificcomputingproblems.
ThesuccessofGPUsasgeneral-purposecomputingdevices owes not onlytotheir hardware capabilities butalso totheir improved programmability. NVIDIA’s Compute Unified De vice Architecture (CUDA) framework has been instrumental ingivingdevelopersaccesstotheresourcesavailableinGPUs [5].Untilrecently,thelanguageoftheCUDAAPIwaslimited to C/C++. In 2009, the Portland Group (PGI) worked with NVIDIA to develop a CUDAFortran compiler [6]. Because Fortranis popularinthe scientific community,the release of thiscompileropensupnewavenuesfor parallelizingexisting applications. Researchers have been successful in using the GPUtoachieve speedupin avarietyof Fortran applications, including grid-based models similar toROMS. The Weather ResearchandForecastingModel(WRF)isamesoscale open-sourceapplicationwritteninFortran[7]thathasbeensuccess fully coupled with ROMS [8]. Michalakes and Vachharajani rewroteamoduleinWRF asCUDACandobtained speedup [9]. Others have taken a step further and accelerated WRF in its original language using CUDA Fortran [10][11]. In Michalakes’andVachharajani’swork,theyexploreissuescon cerningtheuseofGPUsforweathersimulation,includingthe capabilitiesofGPUs,theeaseof re-engineeringexistingcode towork withCUDA, andthe possible improvements toease developmentandincreaseperformance[9].Theavailabilityof CUDAFortrancreates newavenuestoexploretheseideas.
Inthiswork,weuseaGPUtoimplementanewparalleliza tionof ROMS. UsingCUDAFortran,we exploittheexisting
grid partitioning routines andtile access schemesof ROMS’ OpenMPimplementationtomapportionsofasimulationonto a GPU. We target GPUs based on NVIDIA’s new Fermi architecture,whichfeaturesenhancedperformancefordouble precisioncalculations.Ourworkfocusesonthebarotropic2D steppingmodulethatoccupiesasignificantproportionoftime inasimulationofanon-linearmodel.Wediscusstheexisting parallelization optionsandtheir tradeoffs.WetestourCUDA implementationonbothidealizedandrealisticdataandassess its performance againstthat ofOpenMP andMPI.
II. ROMS
ROMS is open-source software that is actively developed by a large community of programmers and scientists. With over 400,000 lines of Fortran code, ROMS employs various equationsinitsnumericalmodel[1].ROMSmodelsanocean regionanditsconditionsasstaggered,finitedifferencegridsin the horizontalandvertical. To simulatechanging conditions, ROMSusessplit-explicittime-stepping inwhichalargetime step (baroclinic)computes 3D equations anditerates through a sequence of smaller time steps (barotropic) that compute depthintegrated2Dequations(step2D)[12].Usersdetermine the length and computational intensity of a simulation by setting the resolution of the grid, the number of large time steps(NTIMES),theamountofreal timeeachsteprepresents (DT),andtheamountofsmalldiscretetimesteps(NDTFAST) per large time step (with a minimum number to maintain numericalstability).Whentranslatedintosourcecode,ROMS begins a simulation by entering a loop that iterates through
NTIMES largetimesteps,wherethe largetimestepisrepre sentedbyafunctionnamedmain3D.Thisfunctionsolvesthe 3D equationsfor thefinitedifferencegridandcallsthe small timestepNDTFAST times.Becausethe3Dand2Dequations arebothappliedtotheentiregrid,theyserveasthetargetsof parallelization.
III. PARALLELIZATION
To runinparallel,ROMSpartitionsthe gridinto tiles[12]. Users enter the number of tiles in the I direction and the J
direction. For example, setting NtileI to 4 and NtileJ to 2 results in a partitioned grid of tiles that consists of 2 rows and 4 columns for a total of 8 tiles. The computations in ROMS appliestoeach gridpoint, so tilescanbe assignedto separate processors.ROMScanberuninparallelwitheither OpenMP or MPI, an option that is selected at compile time [12].Currently,ROMSdoesnotsupportusingbothoptionsat once. Eachparadigmis discussedinthenextsections.
A. OpenMP
OpenMP is a parallelization model designed for shared memory systems. For most modern hardware, this refers to multi-core processors on a single machine. In both its C and Fortranspecifications,OpenMP requiresprogrammersto insert directives around for loops (or do loops in Fortran). TheOpenMPlibraryautomaticallyassignsdifferentiterations of aloopto multiplethreads, whichare thendivided among
TABLEI
RUNTIMEPROFILINGDATAOFASHORTROMSSIMULATION
Function Runtime(s) Percentage
2Dstepping
GLSverticalmixingparameterization Harmonicmixingoftracers,geopotentials 3Dequationspredictorstep
Correctortime-stepfortracers Correctortime-stepfor3Dmomentum Pressuregradient
3Dequationsright-sideterms Equationofstateforseawater Other 614 261 43 41 38 36 35 34 25 26 53.3% 22.6% 3.7% 3.5% 3.3% 3.1% 3.0% 2.9% 2.2% 2.3%
multiple processors. In ROMS, the for loops of interest are located inmain3D,wherethe 3Dequations are solved.Each function is applied to the entire grid by looping over the partitionedtiles.Fig.1(a)showsOpenMPdirectivesappliedto aloop inROMS. Modern multi-core processors are fast and can perform computations over each tile quickly. However, the ideal minimum tile size in the OpenMP implementation is determined by the number of processor cores. Therefore, theparallelismofferedbyOpenMPiscoarse-grainedandmay havedifficulty scalingfor largerproblemsets.
B. MPI
MessagePassing Interface(MPI)isaparallelizationmodel used for distributed memory systems. This paradigm com monly targets multiple machines operating in a networked cluster. In ROMS, this paradigm enables a simulation to be parallelized with an arbitrarily large number of processors. As its name implies, MPIuses message passing tofacilitate memorymanagementacross severalmachines.The drawback of this distributed model occurs when different processes require data sharing during computation, andnetwork trans fers incur overhead. In ROMS, MPI differs from OpenMP because each partitioned tile is sent to a different machine andcomputed as itsown process [12].Computationsrequire tilestouseoverlappingboundary points,orhalopoints,from neighboringtiles[12].Inasharedmemorymodel,thesehalo points can be accessed in a straightforward manner. MPI, however,requiresmessagepassingtoretrievethehalopoints, whichaddsnetworktransfers tothecost ofcomputation.
C. CUDA
GPUs have evolved from graphics accelerators to general purpose compute units that provide massive parallelism with their large number of cores. GPUs are designed for data parallelism, where the same instructionsare executedsimul taneously on multiple data. In addition, the graphics legacy of GPUs enable them to be well optimized for arithmetic operations. Therefore, GPUs are well suited for performing mathematicalcomputationsonlargegrid-basedstructures.To provide high level access to the hardware resources of its GPUs,NVIDIAprovidestheCUDAframework,anAPIbased onC/C++[5].LikeOpenMP,theparallelizationabstractionsof CUDAtargetasharedmemoryarchitecture.However,CUDA differs from OpenMP in that it requires a large number of
1 DO my_iif=1,nfast(ng)+1 1 CALL step2d_host_to_device()
2 [...] 2 DO my_iif=1,nfast(ng)+1
3 !$OMP PARALLEL DO 3 [...]
4 DO thread=0,numthreads-1 4 CALL step2d_kernel<<<dim_grid, dim_block>>>
5 subs=numtiles/numthreads 5 (num_tiles,krhs(ng),kstp(ng),knew(ng),
6 DO tile=subs*thread,subs*(thread+1)-1,+1 6 nstp(ng), nnew(ng),PREDICTOR_2D_STEP(ng),
7 CALL step2d (ng, tile) 7 iif(ng), Lm(ng), Mm(ng), iic(ng),
8 END DO 8 nfast(ng),dtfast(ng), ntfirst(ng),
9 END DO 9 gamma2(ng), rho0, work_dev)
10 !$OMP END PARALLEL DO 10 [...]
11 [...] 11 END DO
12 END DO 12 CALL step2d_device_to_host()
(a)OpenMP (b)CUDA
Fig.1. OpenMPandCUDAparallelization
threads for optimal performance [5]. Unlike multi-threaded environmentsontheCPU,contextswitchingontheGPUbears littlecost.Therefore,GPUsfacilitatelargenumbersofthreads andhavebettersupportfor fine-grained parallelism.
Recently availabletechnologiesinbothhardware andsoft waremotivateustopursueaCUDAimplementationofROMS. In hardware,NVIDIA released anewgeneration of graphics cards in 2010 based on an architecture named Fermi. Fermi GPUsfeature greater numbers of coresthanprevious models and also have enhanced performance for double precision calculations [13]. As a result, these compute cards have the potential to enhance scientific computing applications like ROMS, which require numerical precision.In software, PGI ported the CUDA API into Fortran andreleased the CUDA Fortran compilerin2009.Thecompiler allowsustodevelop ourCUDAimplementationdirectlyinFortranandtointegrate our workwiththe existingROMScode.
1) Approach: InatypicalCUDAapplication,theprogram mer allocates memory on the GPU, copies the relevant data ontoGPUmemory,performsthecomputeintensivefunction(a CUDAkernel)onthedata,andcopiestheresultsbacktoCPU memory[5].WeisolateacomputeintensiveportionofROMS to rewrite as aCUDA kernel that will run on the GPU.We determinethatthedepthintegrated2Dequationsoccupyover 50% of the total runtime in a simulation. The 2D equations are computed as a function in the short time step, which is called many times in the large time step. Therefore, step2D
isoneof themostfrequently calledfunctionsinasimulation. TableIshowsvarioussimulationfunctionsandthepercentage of runtime theycontributetoashort,serialrunof ROMS.
In our approach, we rewrite the step2D function as a CUDA kernel that is launched in placeof the function call. First, we determine the variables that are used by step2D
and allocate appropriate space for them on the GPU. For
step2D, memory allocation needs to occur only once at the beginning of the program. This may change in future work when more functions are ported onto the GPU, because the GPU’s memorymay notbe largeenough tocontainthe data used by all functions. Array variables are stored in global memory,thelargestbutslowestmemoryontheGPU.Wepass scalarvariablesasargumentstotheCUDAkernelsothatthey
will be stored infaster memory locations including registers andcache. Sincemultiple iterationsof step2D are calledper largetimestep,copyingvariabledatabetween GPUmemory and CPU memory needs totake place onlybefore andafter theiterations.
Asakey stepinanyCUDAapplication,we mustpartition theproblemintosubdomainsthat canbeassignedtoseparate GPUthreads.Forthetaskofdividingthemodelgrid,wesave codingeffortbytakingadvantageof thetilepartitioningused in the existing parallel implementations of ROMS. Because bothOpenMPandCUDAtargetasharedmemorymodel,we deducethattheycanmanageandusethetilesinsimilarways. In ROMS, the tiling abstraction used by step2D and other functionsis implemented via tilenumbers that are passedas arguments. Within step2D, the tile number is mapped to a setof boundaries, whichdefinethe tile orsubset of the grid. To apply afunction toeverytile, the programloops through the tile numbers and calls the function for each tile number. Toparallelizetheloopsandprocessthetilesconcurrently,the OpenMPimplementationenclosestheloopswithdirectives.In ourGPUimplementation,weassigneachtiletoanindividual CUDA thread. Each CUDA thread has a self-identifying ID thatcanberetrievedfromwithinthekernel.Insteadofpassing atilenumberasanargument,weuseeachthread’suniqueID as the tile number. Fig.1 shows the OpenMP parallelization of step2Dandthe equivalentCUDAcode.
To test the correctness of our implementation, we use a small simulation to compare our output with that of the OpenMPimplementation. During asimulation,ROMS prints out diagnostics messages at each large timestep, which can be used for basic testing. For more extensive verification, we use the main simulation data that stores the values of grid variables at specific times. To output this large set of data,ROMSperiodicallywritestofilesintheNetCDFformat at a frequency specified by the user [12]. We dump the contents of these NetCDF files into ASCII files to use for comparison. The contents produced by our CUDA imple mentation matches that of the OpenMP implementation by approximately 82%. We found that the differences were due to the order in which OpenMP processes tiles, from higher numberedtolowered numberedtiles.When we switchedthe
loop orderingtoprocesstiles inascendingorder,the outputs fromCUDAandOpenMPwereidentical.Toaddressthisissue of threadordering,additionalworkisneededtoexploreGPU synchronization for ROMS.
BecausethedesignofROMSwasnotintendedfor CUDA, we foundthat porting afunction into CUDAandintegrating it into the code proved to be difficult tasks. The step2D
functionisover 2,000lines long,whichmeantthe equivalent CUDAkernelwouldberoughlythesamelength.Althoughthe majority of theoriginal code is directlyreusedinthe kernel, any changesto the code tomake the CUDAimplementation work(such asthe renamingof variables)mustbe propagated throughout thefunction.In addition,the step2D functionhas over 50 parameters, and the total size of these parameters are greater thanthe 256 KBlimit allowed for CUDA kernel arguments.Toworkaroundthislimitation,wetakeadvantage of a feature in the CUDA Fortran compiler that allows the GPU toaccessdevice variablesoutsidethe kernel butwithin the sameFortranmodule.Wechangemanyoftheparameters instep2Dtomodulevariables.Wealsoencounteredchallenges relating to encapsulation. Many module variables in ROMS are accessiblefromanyfilethatimportsthemodule.Because
step2D has a length of over 2,000 lines, the function uses module variables from a large number of files. Since GPU memory is separate from CPU memory, all variables used by the function (and therefore the CUDA kernel) must be identified and copied to GPU memory. These variables are often spread across various modules of the program. This lack of encapsulation may need to be considered in future applications of CUDAinROMS.
Another feature of the Fortran language that posed a challenge for our CUDA implementation is the ability for programmers to determine the way arrays are indexed. In the OpenMP parallelization of step2D, threads index local arrays differently depending on the tile they were assigned. For example, the following is apossible mapping of tilesto index rangesforanarrayof sizen:tile1 to[-2. . .n-3],tile 2
to[1. . .n],tile3to[4. . .n+3],andsoon.InFortran,theindex ranges of array variables must be specified at the beginning ofthefunctioninthevariables’declarationsaslocalvariables or dummyarguments.Onepossible solutionistodeclare the arrayswithacommonindexingandrewriteallarrayaccesses to assume this common indexing. To save time, we instead collapse all local arrays into one (to save kernel parameter space)andstoreitinglobalmemory.Wepassapointertothe arrayasasingleargumenttothekernel,sothatwecandeclare it as adummy argumentinside thekernel. In the declaration ofthedummyargument,weusethethreadID(tilenumber)to specifythearrayindices.Bydoingso,wemaintaintheexisting array accesses that expect different threads to use different indexing. Asthissolution indicates, manyof our approaches are designedtosaveeffortincoding.
IV. RESULTS
ToevaluatetheperformanceofourCUDAimplementation, we compare it to the existing serial, OpenMP, and MPI
im-TABLEII
THEUPWELLINGCASEISUSEDTOTESTSTEP2DWITHDIFFERENTGRID SIZES. THETOTALRUNTIMEINSECONDSISOF60STEP2DITERATIONS.
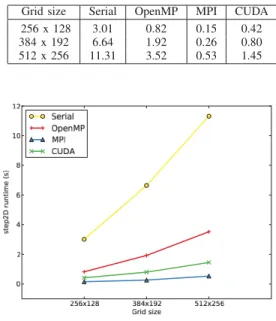
Gridsize Serial OpenMP MPI CUDA 256x128 384x192 512x256 3.01 6.64 11.31 0.82 1.92 3.52 0.15 0.26 0.53 0.42 0.80 1.45
Fig.2. Upwellingbenchmarkwithvariousgridsizes.
plementationsrunningonhighperformancehardware.Forthe serialruns,weuseanAthlonIIprocessorclockedat2.9GHz. ForOpenMP,weuse2IntelXeonE5504processors,pricedat approximately$450,foratotalof8cores.TorunROMSwith MPI,weuseaclusterofIntelXeon5130processorsthathave a total of 64 cores. The price of this cluster easily exceeds $10,000. To test our CUDA implementation, we target the GTX 470, acommodity GPU priced at approximately $300. Thiscard, basedontheFermiarchitecture,features1280MB ofmemoryand448coresclockedat1.22GHz[14].Intheory, theGTX470 requires21,504 threadsfor fullsaturation.
In addition to CUDA, we use PGI’s Fortran compiler to compile ROMS torun in serial and with OpenMP. Wealso apply the -O3, -fastsse, and -Mipa=fast optimization flags. TheMPIimplementationis compiledwithgfortran usingthe -O3, -frepack-arrays, and -ffast-math flags. When choosing tiling layouts, we use the same number of tiles as there are processors for the non-CUDA implementations. Because our CUDAimplementationmapseachtiletoaseparatethread,we setas many tilesas possible tosaturate the GPU.Therefore, the idealtile sizefor the GPUis 2 x 2, the smallest allowed inROMS.Inoursecondbenchmark,weareunabletousethe smallesttilesizeduetotheGPUrunning outofmemoryand instead,weuse 4 x 2tiles.Thislimitationsuggeststhatmore powerfulGPUsmaybeneeded forlargergridsizes.
A. Benchmarks
The upwelling ocean model, featuring a periodic channel with shelves on each side, is a basic example used to test ROMS [1]. The upwelling case uses internal, analytic func tionstocreateidealizedconditions,whichenablesustoeasily modifyitssimulationparameters.Wetakeadvantageofthisby
34.8 35 35.2 35.4 35.6 −121.5 −121 −120.5 Surface Temperature, 05−Nov−2010
15.5 15 14.5 14 13.5 13 12.5 12 Latitude Longitude
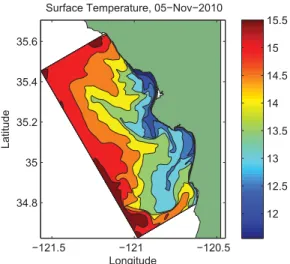
Fig.3. OceansurfacetemperatureofarealisticROMSsimulation.
usingthetestcasetobenchmarkthedifferentimplementations of step2D with increasing grid sizes. When testing CUDA, we includethetransfertimebetweenGPUandCPUmemory. Because not all functionshave been ported to the GPU, the functions on the CPU cannot proceed without the processed data from the GPU and vice versa, so the costs of these transfers are unavoidable. As Fig. 2 shows, the performance of the GTX470 fallsbetween the multi-core processors that run OpenMPandtheMPI-enabledcluster.Asthe gridsgrow in size, the performance gaps also increase. With the 512 x 256 grid, the CUDA implementation of step2D is nearly 8x faster thanthe serialimplementation and2.5xfaster thanthe OpenMP implementation.
In addition toanalytic functions, ROMS also allowsusers touseexternallycollecteddatatoestablishtheconditionsofa simulation, including initial conditions, boundary conditions, and wind forcing. To test CUDA on amore realistic bench mark, we use observational data collected by autonomous underwater vehicles from waters near California’s central coast. This data had been collected to simulate the state of an ocean region for the time periodof 1–7 November2010. Thesimulationisconfiguredtorepresentarectangulardomain 68 km wide and 170 km long, on a 256 x 512 grid, with approximately 250 mbetweengridpoints. Themodel isalso forced with NOAA/NCDC blended 6-hourly 0.25-degree sea surface wind stress [15]. Initial andboundary conditions are taken from the Hybrid Coordinate Ocean Model (HYCOM) 1/12 degree global hindcast reanalysis [16]. The simulation exhibits realistic features typically seen along the central California coastal ocean,including coldupwelled water next to thecoast. Fig. 3 showsagraphicaldepictionof the ocean region’s temperature properties. Although this benchmark is more realistic than upwelling, Fig. 4 indicates that the per formance characteristics are roughly the same. Once again, the CUDAimplementationdemonstratesa2.5xspeedupover OpenMP, and despite being a much less costly device, the GPU’s performanceremains closetothatof theMPIcluster.
Fig.4. Comparisonofstep2Druntimeinarealisticbenchmark.
V. FUTUREWORK
Ourworkleavesmanyopportunitiestoincreasetheperfor manceofROMSanddemonstratethepowerofGPUs.Because the step2D kernel is over 2,000 lines long, many possible optimizationsremain includingloopunrollinganddivergence removal. We have not attempted such optimizations in our work.Sharedmemoryisanotherpromisingoptimizationfound invariousCUDA applications.BecauseGPUs areoften lim itedbymemorylatency,andsharedmemoryactsasacachefor slower global memory,there is great potential for additional speedup[5].Inadditiontokernel-leveloptimizations,we can investigateotherparallelization models involvingCUDA. We can explore the use of multiple GPUs, which would enable us to further divide the grid and have each GPU process a smaller piece. We can also combine the use of CUDA with MPI by implementing a model that uses a cluster of GPUs. Integrating the two implementations would enable an MPI process to use a GPU to perform the heavy computations on the tile assigned to the process. Such a solution may be scalableforverylargegridsizes.Ourworkfocusesspecifically onthestep2Dfunctionthatoccupiesalargepercentageofthe runtime ina simulation.Although we succeeded inspeeding up thefunction, we canimprove overall performancefurther byrunningmorefunctionsontheGPU.Becausewereusedthe existing tilepartitioning inROMS toconvert OpenMPloops to CUDA code for step2D, all computations of ROMS that are parallelized with OpenMP can be rewritten in a similar fashion torun on the GPU. Therefore,it is possible to have themajorityof aROMSsimulation runentirelyon theGPU.
VI. CONCLUSION
We accelerate a compute intensive portion of the ocean modelingsoftware,ROMS, usingaGPUandCUDAFortran. Our work is motivated by the limitations on grid sizes and accuracycausedbytheincreased runtimesofsimulations.To showtheapplicabilityofourworkonreal-worldsimulations, webenchmark ourimplementationonobservationaldatacol lected from an ocean region. We discuss the approaches we took and challenges we faced in integrating CUDA into an
existingFortranproject.WedemonstratethattheuseofGPUs for massive fine grained parallelism in ocean modeling can yield comparable performance to that of multi-core systems and multi-node clusters. Furthermore, commodity GPUs can be found in the consumer market at a fraction of the cost of a cluster. These GPUs can run on a single machine, require relativelylittle maintenance, andconsume much less power. GPUs continue to evolvewith increasing numbers of cores,higherclockspeeds,largermemorysizes,andimproved programmability.Wehaveshownthepotentialofthesedevices inenhancingtheperformanceofROMSandsimilarlargescale oceanmodelingapplications.Webelievethesedevicescanaid scientists byremovingthe performancebottlenecksthat limit the accuracyandscaleof oceansimulations.
ACKNOWLEDGMENT
The authors would like to thank NVIDIA for equipment donations.
REFERENCES
[1] ROMS.[Online].Available:http://www.myroms.org
[2] D. B. Haidvogel, H. Arango, W. P. Budgell, B. D. Cornuelle, E. Curchitser, E. Di Lorenzo, K. Fennel, W. R. Geyer, A. J. Hermann, L. Lanerolle, J. Levin, J. C. McWilliams, A. J. Miller, A. M. Moore, T. M. Powell, A. F. Shchepetkin, C. R. Sherwood, R. P. Signell, J. C. Warner, and J. Wilkin, “Ocean forecasting in terrain-following coordinates: Formulation and skill assessment of the Regional Ocean Modeling System,” J. Comput. Phys., vol. 227, pp. 3595–3624, March 2008. [Online]. Available: http://portal.acm.org/citation.cfm?id=1347465.1347771
[3] A. F. Shchepetkin and J. C. McWilliams, “The Regional Oceanic Modeling System (ROMS): A split-explicit, free-surface, topography-following-coordinate oceanic model,” Ocean Modelling, vol. 9, no. 4, pp. 347 – 404, 2005. [Online]. Available: http://www.sciencedirect.com/science/article/pii/S1463500304000484
[4] E. D. Lorenzo, A. M. Moore, H. G. Arango, B. D. Cornuelle, A. J. Miller, B. Powell, B. S. Chua, and A. F. Bennett, “Weak and strong constraint data assimilation in the inverse Regional Ocean Modeling System (ROMS): Development and application for a baroclinic coastal upwelling system,” Ocean Modelling, vol. 16, no. 3-4, pp. 160 – 187, 2007. [Online]. Available: http://www.sciencedirect.com/science/article/pii/S1463500306000916 [5] “CUDAprogrammingguideversion3.0,”NVIDIA,2010.
[6] PGI CUDA Fortran compiler. [Online]. Available: http://www.pgroup.com/resources/cudafortran.htm
[7] Weather research and forecasting model. [Online]. Available: http://www.wrf-model.org/index.php
[8] M. Li, J. Hsieh, R. Saravanan, P. Chang, and H. Seidel, “Atlantic hurricanesusingacoupledregionalclimatemodel.”[Online].Available: http://sc.tamu.edu/research/chang/new/
[9] J. Michalakesand M. Vachharajani, “GPU accelerationof numerical weather prediction,” in Parallel and Distributed Processing, 2008. IPDPS 2008. IEEE International Symposium on, april2008, pp.1 – 7.
[10] G. Ruetsch, E. Phillips, and M. Fatica, “GPU accelera tion of the long-wave rapid radiative transfer model in WRF using CUDA Fortran,” NVIDIA. [Online]. Available: http://www.pgroup.com/lit/articles/nvidia paper rrtm.pdf
[11] M.WolfeandC.Toepfer,“PortingtheWRFWSM52dkerneltoGPUs usingPGIAcceleratorFortran,”ThePortlandGroup,Oct.2009.[On line].Available:http://www.pgroup.com/lit/articles/insider/v1n3a1.htm [12] K. S.Hedstr¨om, “Technical manual for a coupled sea-ice/ocean cir
culationmodel(version3),” U.S.DepartmentoftheInteriorMinerals ManagementService,2010.
[13] “NVIDIA’snextgenerationCUDAcomputearchitecture:Fermi,”White Paper,NVIDIA,2009.
[14] GeForce GTX 470. [Online]. Available: http://www.nvidia.com/object/product geforce gtx 470 us.html [15] Blended sea winds. [Online]. Available:
http://www.ncdc.noaa.gov/oa/rsad/air-sea/seawinds.html
[16] Hybrid coordinate ocean model. [Online]. Available: http://www.hycom.org