D1.1 – Architectural design of mOSAIC’s API and platform
Grant Agreement number: 256910
Project Title: mOSAIC - Open-Source API and Platform for
Multiple Clouds Project start date:
Duration
01/9/2010 30 months
Deliverable number: Deliverable title:
Due date of deliverable: Actual submission date:
D1.1 Arhitectural design of mOSAIC’s API and platform 28.02.2011 28.02.2011
Last update: 28.02.2011
Editors: Dana Petcu
Participants: SUN – IEAT – AITIA – TERRA2 - FTK
Workpackage: WP1
Deliverable Nature: Report
Dissemination Level: PU: Public
Version: 01
Total Number of Pages: 56
File name: FP7-256910-D1.1-1.0.doc
Abstract
The report presents the architecture of the mOSAIC API and platform and offers a general image of the developments that will be done in the frame of mOSAIC project in the next two years.
Keywords List
Executive Summary
The present document is the result of the T1.1 – API and Platform architectural details (part of Work-package 1 – Design) of the mOSAIC project.
The main concepts that are exposed are related to the set of unified APIs, Cloud components, platform services, Cloud agency, Cloud ontology, Semantic engine, Cloud usage patterns, or SLA management. These concepts are based on our beliefs in the need of Sky computing and open-source solutions, the need of semantics in order to express diversity and to focus on with data intensive applications, in Cloud APIs as solution to programme e-infrastructures and in patterns as way to attract new user communities. The technologies that are used for implementations in the next two years as well as positioning versus existing solutions are also exposed.
Document Versioning
Version Date Description/Change Made Authors
0.1 28 Oct 2010 Filling with existing materials from project proposal and results of the meetings
Dana Petcu
0.2 19 Jan 2011 First full version including materials available on technical wikis Dana Petcu Ciprian Craciun Salvatore Venticinque Iñigo Lazkanotegi 0.3 27 Jan 2011 State of the art from
submitted scientific papers
Dana Petcu Maximilian Rak Ciprian Craciun Salvatore Venticinque Iñigo Lazkanotegi Francesco Moscato 0.4 31 Jan 2011 First round of corrections Tamás Mahr 0.5 19 Feb 2011 Second round corrections Dana Petcu
Bogdan Caprarescu 0.6 20 Feb 2011 Third round of corrections Salvatore Venticinque
Rocco Aversa
1.0 28 Feb 2011 Final version Dana Petcu
Document Review
Reviewer Institution Data Result of Review
Tamás Mahr AITIA 31 Jan 2011 Major review
D. Petcu IEAT 19 Feb 2011 Minor review
R. Aversa SUN 20 Feb 2011 Minor review
D. Petcu IEAT 28 Feb 2011 Minor review
Contributors
First Name Last Name Company Email
Dana Petcu IeAT [email protected]
Ciprian Craciun IeAT [email protected]
Salvatore Venticinque SUN [email protected]
Massimiliano Rak SUN [email protected]
Francesco Moscato SUN [email protected]
Rocco Aversa SUN [email protected]
Iñigo Lazkanotegi Larrate TECNALIA [email protected]
Tamás Máhr AITIA [email protected]
Massimo Ficco SUN [email protected]
Acronyms
Acronym Meaning
API Application Programming Interface
CA Cloud Agency
VC Virtual Cluster
SLA Service Level Agreements
QoS Quality of Service
IaaS Infrastructure as a Service PaaS Platform as a Service SaaS Software as a Service
Table of Contents
1 Introduction ... 8
1.1 Context ... 8
1.1.1 Cloud hype ... 8
1.1.2 Current limitations of Cloud computing ... 8
1.1.3 Timing ... 8
1.2 Project objectives and deadlines ... 9
1.3 Organization of the material ... 9
2 Concept ... 10
2.1 Beliefs... 10
2.1.1 Programmable e-Infrastructures ... 10
2.1.2 How to attract new communities ... 10
2.1.3 The emergence of Sky computing ... 10
2.1.4 Open source ... 11
2.1.5 Cloud-based application profile ... 11
2.1.6 Use semantics to express diversity ... 11
2.1.7 SLA-oriented resource management ... 12
2.1.8 Data-intensive applications on the hype ... 12
2.2 Expected innovations ... 13
2.3 Expected positioning in the Cloud market... 13
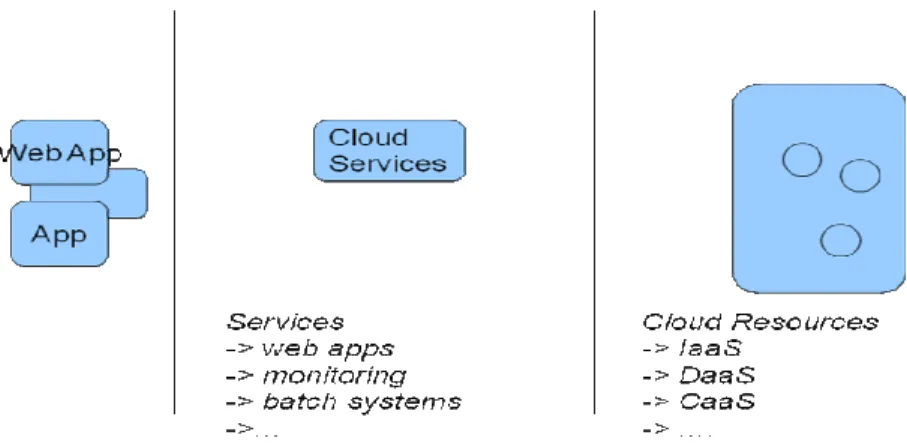
3 Cloud-based applications developed with mOSAIC ... 14
3.1 Characteristics of mOSAIC best-fitted applications ... 14
3.1.1 Application life cycle... 15
3.1.2 Logical view vs. Run-time view of an application ... 16
3.1.3 Actors ... 17 4 Architectural layers ... 18 4.1 Development support ... 18 4.1.1 API roles ... 18 4.1.2 Application tools ... 20 4.1.3 Cloud ontology ... 20 4.1.4 Patterns ... 21 4.1.5 Semantic engine ... 21 4.2 Deployment support ... 22
4.2.1 Application deployment descriptor ... 22
4.2.2 Cloud agency and provider agents ... 24
4.3 Execution support ... 25
4.3.1 Virtual Cluster as resource management facility ... 25
4.3.3 Role of the execution engine and platform services ... 26
5 Components and interactions ... 27
5.1 API components ... 27
5.1.1 Unified API ... 27
5.1.2 Building blocks: Cloud resources and Cloud components ... 28
5.1.3 API’s layers... 29
5.2 Platform components ... 30
5.2.1 Provisioning system ... 31
5.2.2 Cloud agency ... 32
5.2.3 Semantic engine ... 34
5.2.4 Platform services for deployment ... 35
5.2.5 Platform services for execution... 36
5.2.6 Service interactions ... 37
6 Technologies for implementation ... 38
7 Positioning vs. existing solutions ... 43
7.1 Cloud-related APIs ... 43
7.1.1 API requirements ... 43
7.1.2 Cloud providers’ vs. cross platform APIs ... 43
7.1.3 In-process vs. remote APIs ... 44
7.1.4 Building blocks and usage patterns ... 45
7.2 Cloud-based platforms... 46
7.3 SLA-oriented resource management and agents role ... 48
7.4 Cloud ontology ... 49
7.5 References ... 52
8 Relationship with other mOSAIC’s results ... 54
8.1 Deliverables and timeline ... 54
8.2 Publications ... 55
Figures
Figure 1: Different views of an application: Interface vs. Behaviour vs. Resources ... 16
Figure 2: Logical view vs. Infrastructure view... 17
Figure 3: Behind interface, behaviour and resources views ... 19
Figure 4: Main structure of mOSAIC Cloud Ontology ... 20
Figure 5: Cloud Agency ... 24
Figure 6: API layers ... 29
Figure 7: Interactions between Cloud Agency components ... 31
Figure 8: Agents interactions ... 32
Figure 9: Use case of Cloud Agency ... 33
Figure 10: Reasoning component ... 34
Figure 11: Components interactions at run-time ... 37
Tables
Table 1: mOSAIC components supporting the application in different moments of its life cycle ... 18Table 2: Minimal functionalities exposed by mOSAIC’s API ... 19
Table 3: Minimal list of mOSAIC’s application tools ... 20
Table 4: Jade agents ... 32
Table 5: mOSAIC agents ... 33
Table 6: External interfaces ... 33
Table 7: Services for deployment ... 35
Table 8: Services for execution ... 36
Table 9: Software tools ... 38
Table 10: Cloud-related products: Storage and Databases ... 39
Table 11: Cloud-related products: Map-Reduce, Message Queues and APIs ... 40
Table 12: Cloud-related products: Serialization and RPC ... 41
1
Introduction
1.1 Context
1.1.1 Cloud hype
Cloud computing is a recent model for enabling convenient, on-demand network access to a shared pool of configurable computing resources (e.g. networks, servers, storage, applications, and services) that can be rapidly provisioned and released with minimal management effort or service provider interaction.
Cloud computing is now at the peak of its hype cycle and there are a lot of expectations from this technology. Clouds are currently used mainly in commercial settings and address on-demand provision of IT infrastructure. They can play a significant role in a variety of areas including innovations, virtual worlds, e-business, social networks, or search engines.
1.1.2 Current limitations of Cloud computing
Cloud computing is still in its early stages of development, with consistent experimentation to come. Cloud computing solutions are currently used in settings where they have been developed without addressing a common programming model, open standard interfaces, adequate service level agreements or portability of applications. Neglecting these issues current Cloud computing offers force people to be stranded into locked, proprietary systems. Developers making an effort in cloudifying their applications cannot port them elsewhere. Moreover, users put in the hands of commercial providers applications and data without negotiable quality of service agreements. The R&D of mOSAIC ismotivated by the existing weaknesses of the current research and practice in Cloud computing. We mention here the ones that mOSAIC addresses directly:
Weakness 1. Lack of common programming model for Cloud-oriented applications.
Weakness 2. Lack of tools for easy deployment of scalable applications and multi-Cloud-based service compositions.
Weakness 3. Lack of standard interfaces for resource virtualisation.
Weakness 4. Lack of adequate service level agreements and their dynamic negotiation.
Weakness 5. Platform dependability and non-portability due to different APIs for different types of resources.
1.1.3 Timing
Europe is currently investing hardly to keep up with the domination of Cloud computing providers from over-see. The FP7 ICT programme currently promotes and supports the innovative R&D activities of key players in European industry and research. Combining the raise of new technological requests with the already recognized leadership by Europe, e.g. in intelligent techniques, it is the receipt for success.
1.2 Project objectives and deadlines
mOSAIC’s main objective is to create, promote and exploit an open-source Cloud API and platform targeted for designing and developing multi-Cloud-based applications. To achieve this main objective the following technical objectives were established: TO1 Design an API and a platform that are hardware and vendor agnostic
TO2 Design a Cloud ontology
TO3 Design a unified resource representation
TO4 Adapt agent-based negotiation mechanism for Cloud services
TO5 Establish Cloud-specific service level agreements and quality of service requirements TO6 Adapt tests and benchmarks for Cloud services and applications
TO7 Implement the API in well known programming environments TO8 Demonstrate the usefulness of semantics in Cloud service usage TO9 Implement an agent system for negotiation of Cloud services
TO10 Deliver a full platform for programming and deploying Cloud-based applications TO11 Identify Cloud usage patterns
TO12 Design realistic platform usage cases
TO13 Design and implement examples of Cloud-based applications using project developments The accomplishment of these objectives will be marked by results emerging at different points of the project:
February 2011 Architectural and implementation details established August 2011 API’s first prototype and platform use cases
February 2012 API’s second prototype and first version of the platform August 2012 Full platform available
February 2013 Feedback on platform performance and mOSAIC applications
1.3 Organization of the material
The next sections are organized as follows. Section 2 describes the main beliefs of the mOSAIC team that leads their R&D activities and which are derived from the analysis of the current Cloud computing market. Section 3 presents the vision related to the type of applications that will be supported by mOSAIC. Section 4 describes the main architectural layers of the mOSAIC technical solution, while Section 5 gives more details about its components. Details about the technologies that are used in the implementation are given in Section 6. We position our proposal versus existing ones in Section 7. The other deliverables dependence on the current one is stated in Section 8. The last section draws a few conclusions.
2
Concept
2.1 Beliefs
2.1.1 Programmable e-Infrastructures
The idea of computing as utility has taken several forms in implementation in the last decades. Cloud computing and storage is one of the latest incarnation of this idea. Closest relatives are Grid computing, Cluster computing, Data center management, Service oriented architectures, Utility computing, On-demand computing etc. We believe that the individuality of Cloud in its family is related to the fact that it focuses on the programmability of e-Infrastructures.
Most offers of Cloud providers are related to an Infrastructure as a Service (IaaS) layer where a trend is emerging in standardizing the interfaces for these offers to allow interoperability and portability. The virtualization techniques, which have been enhanced in order to be massively used in cloud computing, are also part of the IasS layer. However the users of IasS platforms are often required to develop custom solutions for the dynamic provisioning of cloud resources to their applications.
The aim of the Platform as a Service (PaaS) layer is to hide the infrastructure details and to provide the application developers with an API that allows them to focus on the business logic and to develop the software components that will be made available to the users under the Software as a Service (SaaS) paradigm.
A Cloud should be, and currently is not, able to support application-driven service management based on application profiles. Most of the current solutions are provider-driven. . We believe that only by enabling self-managing and auto-scaling applications cloud computing can massively penetrate into the industry.
2.1.2 How to attract new communities
The adoption of a technology is dependent on the degree of its simplicity in usage. Currently, most of the Cloud-related programming is done using proprietary interfaces and thus is limiting the ability to choose a Cloud provider or to swap one provider for another. Moreover, if there are many proprietary programming models, even an IT specialist is unlikely to know more than a few of them.
Having standard APIs for programming Clouds can simplify the development process of Cloud based applications and therefore can lead to an increase in adopting the new technologies. Moreover we believe that the use of standard interfaces allows the flexibility necessary to build new applications and to enable the interoperability of data and services regardless of a specific Cloud type.
As the power of examples is highly recognized, we investigate the current Cloud usage patterns and will enable them through the proposed API.
2.1.3 The emergence of Sky computing
The selection of Cloud providers for a particular application is an intricate issue due to the complex business model associated with Cloud computing. The cost depends on many factors, e.g. CPU usage, storage usage, communication, location, privacy requirements, to name just a few. A
powerful brokering mechanism is required to select the best Cloud offers (like the least less expensive solution or the most powerful solution), taken into account the characteristics of the applications. Moreover, complex applications are likely to require more than a single Cloud system, and thus offers of several Cloud providers must be combined to satisfy their needs.
For example, service consumers can require fast response time and distributing workload requests to multiple Clouds at the same time can be a solution for satisfying their requirements.
Moreover, Cloud providers usually deploy traditional system-centric resource management architecture. A market-oriented resource management is necessary instead in order to regulate the provision of Cloud resources.
These facts are expressions of the need for a computing environment for interconnecting and provisioning Clouds from multiple domains.
The new term that has emerged recently for such a solution is Sky computing. We consider that the differences between Sky computing and Cloud computing is similar with the differences between Grid computing and Cluster computing.
We consider that in order to tackle with the provider and client best representation as well as mediation of their interests, agent technologies are more appropriate to be used.
2.1.4 Open source
Beyond standardization efforts, in order to break down the vendor lock-in problem, we consider the open source to be the best solution. Already classical examples are PVM in parallel computing, Globus Toolkit in Grid computing and so on.
Therefore we consider that one of the main benefits of using our technical approach will be the fact that it will be open-source.
2.1.5 Cloud-based application profile
We consider that the killer applications in Cloud computing are the long-running scalable ones. By long-running scalable applications we envision the kind of applications that are composed of multiple components which communicate one with another to solve the given tasks. These applications, once submitted, should run for undefined period of times, but also scale (upward or downward) as the usage demands it.
Some examples of such applications are web-crawlers, forecasting systems (financial, meteorology), economical applications (ERP), etc.
2.1.6 Use semantics to express diversity
Services provided by current Cloud systems are different, e.g. from Linux machines with root access to turnkey virtual clusters vs. data storage or processing. Moreover, terms like virtualisation is understood differently in the context of different technologies such as storage, processing, networking.
To overcome this situation a unified resource representation is needed. In this context, we consider that a comprehensive Cloud ontology should be developed to support the needs of the Cloud providers, as well as of the application developers.
2.1.7 SLA-oriented resource management
Cloud providers need to support different parameters expressing the QoSs for each individual consumer and negotiate them in specific SLAs. Limited support is currently available for dynamic negotiation of SLAs and for automatic allocation of resources to multiple competing requests. Moreover, service requirements of users can change over time and thus may require amendments of original service requests.
In this context, new SLA-oriented resource management strategies are needed to be designed for Clouds that provide personalized support to the customers and their applications.
2.1.8 Data-intensive applications on the hype
Special attention will be given in mOSAIC to the validation of the API and platform in data-intensive applications. The motivation is to follow the recent vision of a new) paradigm of scientific and technological discovery, the one based on data-intensive science: a movement is registered from data scarcity towards a data excess, which is leading to a relative poverty of human attention to any individual datum and is necessitating machine-assisted winnowing (the availability of diverse data is shifting scientific approaches from the traditional, hypothesis-driven scientific method to science based on exploration).
In this context, the following Gray’ laws are applied [1]: (1) Scientific computing is becoming increasingly data intensive; (2) The solution is in a “scale-out” architecture; (3) Bring computations to the data, rather than data to the computations.
Clouds are promising to satisfy the requirements of the last two laws [1]:
• Latest technological evolution of computational science allowing groups to host, process, and analyse large volumes of multidisciplinary data.
• Consolidating computing and storage in very large data centers that creates economies of scale in facility design and construction, equipment acquisition, and operations and maintenance that are not possible when these elements are distributed.
• Consolidation and hosting mitigate many of the sociological and technical barriers that have limited multidisciplinary data sharing and collaboration.
• Offering hosting facilitates long-term data preservation, a task that is particularly challenging for universities and government agencies and is critical to our ability to conduct longitudinal experiments.
In what concerns the particular case of data services, data lock-in (lake of standardized APIs) is one of the multiple important issues to deal with. The solution that we propose is to use semantic ontologies and data processing to identify the application requirements in terms of Cloud services.
2.2 Expected innovations mOSAIC proposes the followings:
Tech. innovation i. Designing a language- and platform-agnostic application programming interface for using multi-Cloud resources and Cloud usage patterns.
Tech. innovation ii. Building an open-source and portable platform for using Cloud services based on the proposed API and Cloud usage patterns.
Tech. innovation iii. Designing a generic agent skeleton for representing various stakeholders, e.g. Cloud vendors and their resources, Cloud users of various types, and collection of modules that can be used to adapt agent skeleton to support needed functionalities.
Tech. innovation iv. Designing user-centric service level agreements, a Cloud ontology and mechanisms for dynamic negotiation of resources based on multi-agent technologies and semantic data processing.
Tech. innovation v. Building proof-of-concept applications using resources from multiple Clouds and with a special emphasis on data intensive applications.
2.3 Expected positioning in the Cloud market
mOSAIC is expected to offer the freedom of choice at programming level as well as at the resource level. The mOSAIC software package will offer a transparent and simple access to heterogeneous Cloud computing resources and the avoidance of lock-in proprietary solutions. In the current context of the Cloud-based exchange for computing resources, mOSAIC implementation would have a significant impact on the current oligopoly-structured market, where a few providers can offer computing resources at prices higher than those possible in a competitive market structure. The primary users of the mOSAIC solutions will be the developers of the Cloud based applications. Through their activities, other categories, like application users as well as Cloud providers will benefit from mOSAIC solutions.
mOSAIC intends to free the current Cloud users from the burden of the problems diagnosed during the early stage implementations of the Cloud concept:
For the end-users: mOSAIC will provide transparent and simple access to resources and avoidance of “lock-in” to particular proprietary solutions.
For users as developers: mOSAIC will provide a uniform, consistent, and lightweight API, independent of a particular development language and platform as well as implementations for important languages.
For users as administrators: mOSAIC will offer easily manageable (deploy, migrate, upgrade) applications, virtual appliances and virtualised resources and the usage of community accepted technologies.
For users as providers: mOSAIC will allow new providers to offer similar services as the existing ones and varied business models for both infrastructure and application levels.
3
Cloud-based applications developed with mOSAIC
The mOSAIC API and platform will be adequate especially for long-running scalable applications. Massive batch- or parallel-processing jobs – these data- or computational-intensive applications although are not the primary target of mOSAIC can still be easily and successfully deployed.
In what follows we describe the characteristics of the Cloud-based applications that is expected to be developed from scratch using mOSAIC’s concept and middleware.
3.1 Characteristics of mOSAIC best-fitted applications
The Cloud based-application code is expected to consist of:
1. Service-related software components: code written by developer which implements the service behavior (each component publish or consume/react to messages)
2. Deployment file: describe the components, their relationship and the resources involved Glue code (generated) which assembly all the components together.
The application that will reside on the Cloud(s) is supposed to be accessible via Internet protocols. We assume that the design of the application will follow the guide-lines provided by the API:
(a) split the application in components (modules) based on their purpose; (b) create clear (communication and data) dependencies between components; (c) use the recommended architectural paradigm (service oriented);
(d) use the recommended communication patterns: either synchronous or asynchronous remote calls, or message-queue oriented.
Furthermore, we assume also that in the development of the application by using the provided API: (i) all the communication and data exchange between components are done through the API; (ii)all communications to and from the exterior (i.e. Internet) are using the provided API; (iii) avoid using ad-hoc IPC mechanisms that have not been integrated in the environment (like
sockets).
In our design and programming methodology we consider that:
• no user module communicate directly with one-another; all the interaction is done through other mOSAIC components (e.g. distributed databases, message queues, distributed file systems, etc.)
• no user module has direct access to the Internet; all the interaction with external resources (e.g. other Web services, mail, raw TCP/IP communication) is done through mOSAIC components; endpoints (e.g. HTTP, SMTP, UDP endpoints).
The user doesn’t control (or use) the Cloud resources directly, but only through the abstraction that the mOSAIC components provide (thus the mOSAIC platform API).
In order to obtain scalable modules, these must respect some restrictions:
• they must be stateless i.e. the module must not store any state in global variables;
• they must be life-cycle controllable (paused, un-paused, terminated, upgradeable, etc.);
• an event-driven programming style is adopted;
• all the configuration is done through the platform;
• the stored or communicated data must be in a language-independent format.
3.1.1 Application life cycle
The Cloud-based application developers are invited to use the mOSAIC solution through the programming libraries implementing the abstract mOSAIC API in a common programming language (Java and Python). Moreover, part of the components needs to be present on the user side running as daemon process, e.g. part of the Cloud Agency and part of the platform responsible with the resource provisioning.
After the selection of the Cloud providers, at the deployment phase, parts of the platform components (e.g. the services at execution phase) are deployed on Cloud provider sites to ensure the application and resource monitoring. Implementation of mOSAIC API is present also to this level as input for the components that will translate the application requests into provider APIs requests. We make a series of assumptions related to the way in which the developer of a Cloud-based application will interact with mOSAIC API and platform.
First of all we underline the need of decoupling the development of the Cloud based application from its execution. The developer should focus on the development of the application components according to the proposed API and the platform should automate and assist the deployment and execution of the application.
Secondly, we consider that, in order to benefit from the advantages of the mOSAIC’s API, an application developer has to take the following steps:
(1) develop the application; (2) deploy the application:
a) specify the resource requirements;
b) submit the requirements to the Cloud Agency, that give back a resource contract committing to the requirements;
c) bootstrap the contracted resources by using a specialized tool; d) start the application;
(3) execute the application a) monitor the application;
b) scale or move according the needs; c) results’ gathering or real time interaction.
3.1.2 Logical view vs. Run-time view of an application
The main functional views of an application are: •
••
• Interface (left in Figure 1) •
••
• Service behaviour (middle in Figure 1) •
••
• Resource management (right in Figure 1).
Figure 1: Different views of an application: Interface vs. Behaviour vs. Resources
On another hand, the first two categories are logical ones, while the third is related to the execution platform. Therefore, we distinguish two views of the same application on different abstraction levels are:
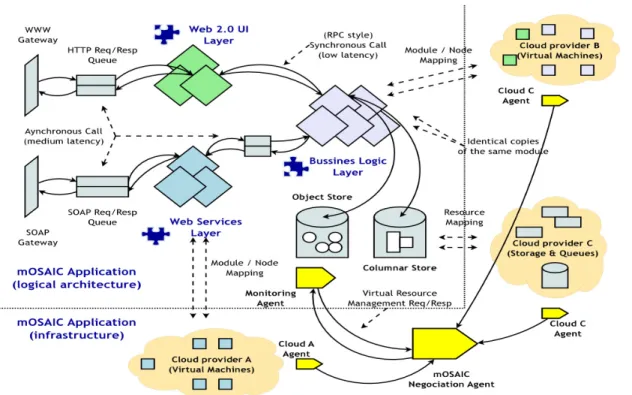
1. the logical one (left upper corner in Figure 2) – the developer view; 2. the infrastructure one (right and bottom in Figure 2) – the platform view.
The application is composed from several components (suggested by rhombuses in Fig. 2) representing different layers (e.g. business logic, services, user interface etc). They are communicating through asynchronous messages using queues (suggested by gray rectangles in Fig. 2). Even though the components are depicted as single boxes, these are logical components, and they could and should be embodied by multiple instances at run-time.
The deployment descriptor of the applications specifies the components as well as the needs in what concerns the types of resources (without specifying the Cloud provider). In the case depicted by Fig. 2 the business logic requires some objects to be stored and some data to be maintained in a columnar store as well as virtual machines to process the data, while the service layers requires only virtual machines to be launched depending on the overload on the application through the Web service interfaces.
The Cloud Agency assists in finding a collection of resources from one or multiple Cloud Providers that are matching the requirements of the application as specified in the deployment descriptor as well as in monitoring the behaviour of the Cloud resources at run-time (yellow components).
Figure 2: Logical view vs. Infrastructure view
3.1.3 Actors
The main actors in the life-cycle of the application are: • •• • Final user • •• • Service developer • ••
• Resource owner (Cloud provider)
Their entry points are depicted in Figure 1, while they roles can be:
• Scenario 1: Service developer as tool developer
The Service developer builds up a tool and sells the tool to User. The User exploits the tool and accesses the Cloud provider resources. The User pays for Cloud resources.
The Service developer acts just as a Software House.
• Scenario 2: Service developer as service owner
The Service developer builds up a tool and offers a SaaS to the User. The User exploits the SaaS and pays to the Service developer. The Service developer pays for Cloud resources.
• Scenario 3: Service developer as User The Service developer is the final User. Match with scenario 1.
• Scenario 4: Service developer as Provider
The Service developer is the Cloud Provider and adds value services. Match with scenario 2.
4
Architectural layers
Focusing on the Cloud based applications, mOSAIC supports all three stages of the pplications’ life cycle:
1. Development support 2. Deployment support 3. Execution support.
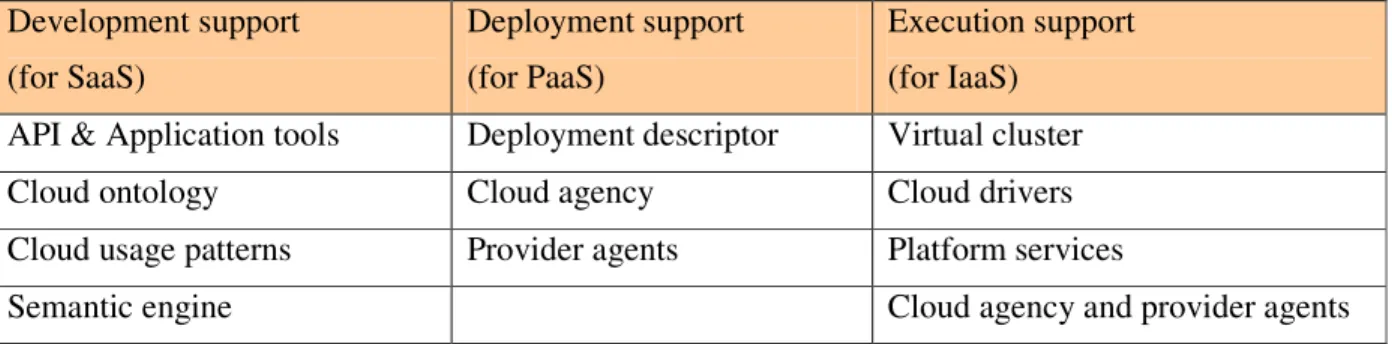
Table 1 exemplifies the split of different components depending on the stage that they serve. The split between different categories is done for the sake of material organization but in reality several components can have double of triple roles at all stages of the application support.
Table 1: mOSAIC components supporting the application in different moments of its life cycle
Development support (for SaaS) Deployment support (for PaaS) Execution support (for IaaS)
API & Application tools Deployment descriptor Virtual cluster
Cloud ontology Cloud agency Cloud drivers
Cloud usage patterns Provider agents Platform services
Semantic engine Cloud agency and provider agents
4.1 Development support
4.1.1 API roles
The APIs should help the developer such that the application:
• Let the user be independent from the Cloud Provider.
• Let the user use a large set of different technologies.
• Let the user be able to manage SLA aspects (optimization).
The APIs encountered in the application development, deployment and execution, are serving different roles:
• Cloud API which has the following characteristics:
o it is provided by the Cloud providers;
o it is directly used by the mOSAIC platform in order to control the Cloud on which
the deployment relies;
o it is expected to be standardized by already existing bodies (e.g. OCCI, OVF, etc.); • mOSAIC API with the following characteristics:
o it is directly used by users in order to deploy applications over the mOSAIC
platform;
o should by standardized: as semantics (i.e. what is the POSIX standard for the UNIX
world), either as protocol like AMQP or HTTP, or at least as a programmable API like JMS, JSP or WSGI.
Table 2: Minimal functionalities exposed by mOSAIC’s API
Level Solution Examples of models
Storage - File storage - Block storage - Column database
GoogleFS, HadoopFS, Amazon S3 DRBD
GoogleBigTable, SimpleDB, BerkeleyDB, HBase Communication - Message queues
- RPC
- Broadcast, multicast - Streams
- Synchronization primitives
AmazonSQS, AMQP Web Services, REST Ericsson TIPC HP SCTP
Semaphores, Mutexes Monitoring - Application status
- Resources
Ganglia framework Nagios monitoring
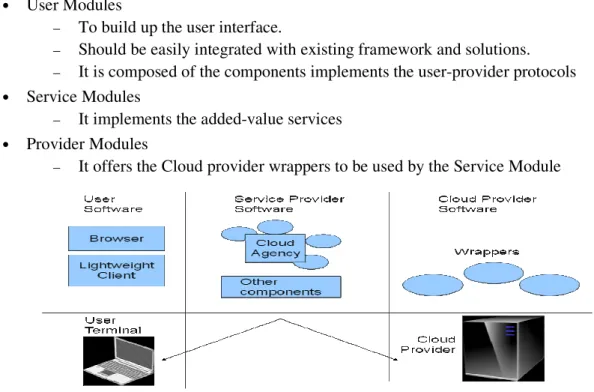
We focus on the development of mOSAIC’s API which must reflect the main functionalities necessary for the Cloud-based applications. The minimal functionalities are the ones from Table 2. API implementations will be done for Java until the Autumn of 2011 and Python until Spring 2012. The application development will be based on three sets of components for the different layers (Figure 3) following the functional views of the applications:
• User Modules
– To build up the user interface.
– Should be easily integrated with existing framework and solutions. – It is composed of the components implements the user-provider protocols
• Service Modules
– It implements the added-value services
• Provider Modules
– It offers the Cloud provider wrappers to be used by the Service Module
Figure 3: Behind interface, behaviour and resources views
The User Module implements the mOSAIC interactions and offer support for different kind of services. The Service module is the core of the mOSAIC API and here the programming paradigm is involved. The Provider Module is composed of wrappers to Cloud provider technologies e.g. vendor agents) and should solve the lock-in problem.
4.1.2 Application tools
The Application Tools developed as mOSAIC platform components will include (see Table 3): service discovery mechanism, service composer, workflow editor and workflow manager, all of these based on semantic descriptions of a Cloud ontology.
Table 3: Minimal list of mOSAIC’s application tools
Client tools Platform tools
Deployment specification assistant Workflow editor
Examples for client codes Eclipse plug-in
Service discover Meta-service creator (Local) Platform simulator Platform usage patterns
4.1.3 Cloud ontology
In order to better understand the different Cloud architectural layers (IaaS, SaaS, PaaS), the development of specific or overall ontologies for these layers is necessary. mOSAIC aims to develop ontologies that would offer the main building block to describe the services.
The Cloud resources are described using terms from the Cloud Ontology. The Cloud Ontology defines concepts from Cloud domains, as well as Cloud components like infrastructures, platforms and services.
In order to enable algorithms for matching different types of resources, functionalities and capabilities must be captured in the Ontology: a clear description and categorization of existing functionalities, capabilities and specificities of different resources (possibly existing in the Cloud) will ease rapid development of successful applications of the Cloud/over the Cloud.
OWL is used to describe the Cloud resources. This approach allows to easily take a Cloud resource model and adapt it within other ontology languages making it both platform and vendor agnostic.
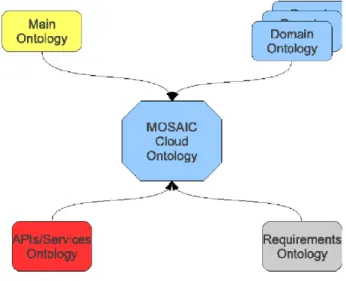
The mOSAIC Cloud Ontology is structured as in Fig.4. It is the result of the merge of four kinds of ontologies:main ontology, domain ontologies, APIs and services ontology, requirements ontology. The Main Ontologycontains the definition of general concepts and relationships related to Cloud systems. For example, the concept of Cloud Resource, of virtual machine, of service layer etc. are specified in this ontology. Depending on the domain of services and APIs, several Domain Ontolo-gies are created. Each domain has its own ontology. APIs and Services Ontology describes the model, the profile and the grounding for Cloud API and services Requirements Ontology has the main goal of modelling Service Level Agreements (SLA) between Clouds consumers and providers.
4.1.4 Patterns
Applications and architectures that can be refactored in order to make the most use of standard components are those that are expected to be successful in leveraging the benefits of Cloud computing.
A consequence of the self-service, pay-by-use model is that Cloud based applications are composed by assembling and configuring appliances and open-source software as much as they are programmed.
In this context, we assume that Cloud based applications are composed and are built to be composable. mOSAIC-based applications will be easy developed from tailored services, Cloud usage patterns, and simple examples of use cases.
The patterns will be specified for different levels of expertise of the end-users and developers identified through the study of use cases. The patterns to be designed in the frame of mOSAIC are intended to be transposed in design pattern for the API implementations. They are more programming oriented than use cases and should support the easy development of the Cloud based applications.
Two types of patterns are expected to be provided by mOSAIC: Cloud usage patterns and Platform usage patterns. Both types of patterns are intended to be designed as workflows of services that are implemented using mOSAIC API. Moreover they will be related to an ontological representation of the Cloud resources of interest.
The starting points for the pattern design are the SOA usage patterns, parallel computing patterns or utility computing patterns. Due to the importance of MapReduce for Cloud based applications it is expected that several other Cloud usage patterns will be related to a MapReduce pattern. Other types of Cloud specific usage patterns are related to the multi-tenancy concept and interaction pattern for the relationship client-providers. Higher level programming patterns, similarly in simplicity with MapReduce patterns, for writing distributed client-server applications and Web services are needed.
4.1.5 Semantic engine
All the requests and responses (SLA's, bid requests, and contracts) should be described according to the specific ontology that governs the brokering domain. Because each actor could natively have a
different ontology, the agents that sit behind the actor implement a semantic mapping between the native ontology and the brokering ontology – in the Semantic Engine, that will do also ontological validation and translation and will refine the application specification document into a correct and complete SLA on behalf of the user.
Matchmaking algorithms that would select the best service to be used based on its functionality and capabilities cannot be achieved without a clear description of the services.
Matching algorithms will equally apply at the different layers of the Cloud architecture: selecting best available hardware or firmware, based on specified capabilities; identifying best available infrastructures, based on specified functionalities related with IaaS and/or DaaS and/or CaaS; or even selecting best available Cloud application from a large base of available applications, based on matching customers needs with application specificities.
Matching among service descriptions will also be provided, together with functionality for “reverse” ontology synthesis, e.g. production of an OWL ontology from a WSDL description. Semantic matching is possible since service request and services descriptions are semantically annotated based on concepts from ontologies adopted for modelling the specific domain of application. Matching procedure will take as input two schemas and determine a mapping indicating which elements of the input schemas logically correspond to each other, together with a similarity measure indicating the plausibility of their equivalence.
The different input schema, service descriptions, ontologies, and other components, will be represented in a uniform way by means of directed rooted graphs, where nodes represent schema elements, connected by directed links of different types, e.g. for containment and referential relationships. Based on this uniform internal representation a number of matching algorithms will operate, including structure-based algorithms (Children Matcher, Leaves Matcher, Graph and Sub Graph Isomorphism).
One of the most challenging goals of the semantic engine is to design and develop semantic-based Cloud services discovery. A prototypical tool will be built based on syntactic and structural schema matching. The input will be an ontology describing a service request and services descriptions. This will be achieved on the syntactic level through a service description language (like WSDL), or on the semantic level, through service ontologies (like in OWL-S, WSMO, SWSF and WSDL-S).
4.2 Deployment support
4.2.1 Application deployment descriptor
We consider that all the components of the application are embodied in elements named modules in the deployment descriptor. Moreover, all the links between the user modules and the resources are explicitly expressed in the deployment descriptor in a certain resource section for each component. Roles (predefined by the platform) in usage of resources should also specified (e.g. consumer or producer of a queue).
We argue about the need of the above described approach in order to ensure the scalability of the resulting system. For example from the fact that by monitoring the queues length and knowing which are the producers and which are the consumers, the platform can automatically choose to instantiate another module.
Note that nowhere in the deployment descriptor is specified anything about the Cloud providers; instead the user requests explicit "capabilities" from each resource (e.g. persistence requirement of the queue system, the fact that we need range queries from the columnar store, etc.), that would guide the mOSAIC platform in weeding out and selecting the right set of possible Cloud providers. An application descriptor needs to be provided to the platform responsible for the deployment. Except the component descriptions, the infrastructure needs for the deployment (minimal, at running time can be modified) of the developed application are necessary to be specified. Such specification can include, beyond the type of resource, the amount of needed resources, the availability time-frame of the resources (some resources could be asked only for certain stages of the application life), the QoS needs (like: minimum processor speed or available memory in case of computing nodes), or minimum bandwidth (in case of message queues or Internet access), latency or average down-time, budget for each resource type, trade-offs between performance and costs. Note that there are several critical QoS parameters in a service request for Cloud computing, such as for instance: time, cost, computer power, storage size, reliability, trust and security. Other parameters should be added; e.g. enterprises have to be careful about where their data gets processed, and therefore, are not able to employ Cloud services from an open market – this could be mitigated through SLAs that specify strict constraints on the location of the resources.
We consider that the main types of resources that can be specified in the application descriptor can be classified as follows:
1. computing resources:
• computing nodes (virtual machines) – that the application (through the mOSAIC platform) can manage the way it wants; on these nodes the mOSAIC environment should deploy the needed libraries / services in order to allow the application to run;
• computing services -- specialized software that the application needs (like simulation software);
2. storage resources:
• storage targets (virtual disks);
• file systems;
• columnar databases;
• CDN (Content Delivery Network) services; 3. communication resources:
• message queue systems;
• computing-nodes inter-communication.
The resource requirements should specify for each type of resource at least the followings:
• the amount of needed resources;
• the availability timeframe of the resources – some resources could be asked only for certain stages of the application life;
• the QoS needs like: minimum processor speed or available memory (in case of computing nodes), or minimum bandwidth (in case of message queues or Internet access), latency, average down-time, etc.
• budget for each resource type;
This specification need not be written entirely by the user, but instead a dedicated tool will be available in mOSAIC Application tools suite which based on the developed application, and some feedback from the user, could generate a template specification that the user can tune.
4.2.2 Cloud agency and provider agents
The Cloud Agency is a multi agent system that is responsible for SLA management: negotiation, re-negotiation, monitoring. Starting from the MAGDA toolset,the agent layer will provide facilities to design, develop and deploy agents-based services. These services will be accessible through a repository and will be able to be access Cloud resources. While making services accessible by standard service technologies, the agent layer will be made “invisible” to the end-user.
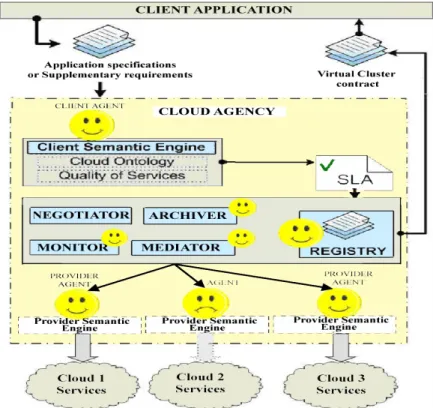
A core set of agents will implement the basic services provided by the Cloud Agency. Some agents will be in charge of interacting with users and providers in order to negotiate and to broker the needing resources (Figure 5).
Figure 5: Cloud Agency
Agents will communicate among them via standard ACL (Agent Communication Language) over http, or over other transport protocols if necessary. Services provided by agents are exposing a Web services interface that works as a Message Gateway: SOAP to ACL and ACL to SOAP.
The negotiation module will support dynamic negotiation of SLAs between participants and mechanisms for automatic allocation of resources to multiple competing requests.
We intend to combine SLA-based resource negotiations with virtualised resources in terms of on-demand service provision.
4.3 Execution support
The application execution components are in charge of application execution using the resources booked and stated in a resource contractdocument.These components can be classified as follows:
• Virtual Cluster, including the booked resources;
• Providers wrappers, agents as special connectors that ensure a uniform interface to the Clouds resources available in resource contract;
• Execution engine including the components for accessing the physical resources and platform services that ensures resource availability and management and includes a resource scheduler and a resource monitor and handles supplementary resources request.
4.3.1 Virtual Cluster as resource management facility
The platform will build up a Virtual cluster (VC) on the basis of a given SLA established within a certain application. The VC will be modularly configured by software agents in order to let the user setup his configuration of required services. A resource contract will be granted on the basis of the physical resources assigned to the VC machines.
It will be possible to dynamically change hardware resources assignment or to start, stop, suspend, migrate a virtual resource from a physical machine to another one within the same VC: the VC configuration can be carried on at the VC first startup, and "on-the-fly", i.e. when the VC is already running, adding or removing modules representing needed/no longer needed services (recontracted). Moreover the agency will enrich the VC and the platform with a set of services for monitoring and benchmarking the offered virtualised resources. Both at infrastructure level (i.e. collecting the information throughout the VC distributed among different users and of a given VC independently by its user) and at service level, i.e. executing a set of measures trough services deployed on the VC.
The agents of the selected resources during the negotiation will further represent the Cloud resources during the execution of an application, as they will understand the application requests and translate them into vendor specific requests (acts as wrappers). The agency will use or modify existing monitoring tools. Agents will be used as intelligent managers – autonomously adjusting the load in case when such operation will be necessary. The agents will have also a monitoring function. The objective is to estimate the amount of resources that is reserved and that is really used by a customer in order to support billing and optimize system utilization. Moreover, the agents’ logs will support the testing and benchmarking of the platform.
A set of features to be embedded in a VC will be provided to evaluate the Quality of Service (QoS) that is perceived by the customer. This is necessary to grant that SLA is met and to detect relevant working conditions such as resource saturations or under-utilization. Such information can be useful to customers, who could be interested in changing their SLA, or to providers, which can be interested in overbooking their physical resources or in optimizing their utilization. Distinctive parameters to be measured will be bandwidth, CPU usage and others, which will be identified during the design phase (and included in the Cloud ontology).
4.3.2 Reaching providers’ resources
Providers wrappers are a set of interfaces that allow a user to access Cloud resources. Each Cloud (Provider) has its own architecture for storage or communication therefore we must create some special connectors that know how to communicate with each provider apart but we must offer to the user a uniform access interface (or an API) to these heterogeneous resources. These wrappers will be created for each of the services offered by the providers that mOSAIC platform will support.
4.3.3 Role of the execution engine and platform services
The platform offers access to the Clouds resources, already booked, through the Execution engine. This engine gives the users access to the resources from the following points of view:
−storage view – offers methods for accessing storage facilities/repositories from the Clouds;
−communication view – describes methods used for implementing different types of communication inside the application running environment;
−computational view – offers the resources booked in the Virtual Cluster.
The resource allocator manages the resources available and schedules tasks (application components) to the processing resources. This component will act as a workload management service.
The resource consumption is an important aspect of monitoring because based on this information we can optimize the resources used for execution: for example if an user had requested more resources than he can consume then he can release the resources unused; this action will lead to a execution cost reduction; of course this process can be implemented without the user's interaction (automate this process).
The resource monitor is in charge of the resource consumption monitoring. It has the role of triggering new resource requesting processes. For example if a user underestimated the resource consumption of it's application then resource monitor can request more resources to be booked for current application. Another function of this component is the monitoring of application execution: users can retrieve information, in real time, about the status of application execution.
More than that, users can use a monitoring tool for retrieving information about their application running status and resource consumption. The users will be able to check the status of their application instance running; also these methods can be used for debugging purposes in case of failures and errors.
5
Components and interactions
5.1 API components
5.1.1 Unified API
Two main API categories are exposing exposing operations for a certain Cloud resource: in-process APIs and remote APIs.
By in-process API we depict what any developer uses on a daily basis, abstracting the resources in terms of memory usage, mutable or immutable, usually transparent, data-structures and usually opaque pieces of machine executable or interpreted code.
A remote APIs is abstracting the resources as reactive (request/reply) opaque agents that communicate based on fully transparent immutable data structures; interoperability is favored over efficiency.
Our platform is targeted mainly at Cloud-based application developers, so we intend to offer them mainly a unified in-process Cloud API, but also a remote one through so-called interoperability API. The first one should be based on the emerging Cloud remote API standards (OCCI, CDMI), but should go also one step further providing a feature-full unified API.
The unification aspect is threefold:
1. we try to unify both provisioning APIs (i.e. OCCI) and data access APIs (i.e. CDMI) under the same library with common concepts and a common programming patterns;
2. we intend to find a common ground between real cloud resources (like Amazon EC2 S3 SimpleDB, RackSpaceWebFiles, Google BigTable, etc.) and self-managed distributed data resources (like Riak, Cassandra, Hypertable, HBASE, etc.) thus exposing the same categories of data models and access patterns; and
3. by providing libraries for multiple programming languages (mostly object oriented like Java, Python, etc.) we achieve uniformity from one development platform to another.
Two goals that need to be met, and which are in conflict with the uniformity approach, are:
i. the minimization of the efficiency impact of the overall API calls (e.g. latency, throughput); ii. loosing as little as possible from the advanced features offered by each resource (the
versioning and ACL support of Amazon S3, or the super column families of Cassandra, and the vector clocks of Riak, just to name a few).
The implementation should follow also the principle that the users have different levels of knowledge and requirements, and thus granting them, if performance or other judicious reasons demands it, the possibility to jump over abstraction layers and gain access to the original API.
5.1.2 Building blocks: Cloud resources and Cloud components
Our approach is to offer a set of API as much as possible paradigm- and technology- independent. In order to face the challenges of this approach we model applications in terms of Cloud Building Blocks which are able to communicate each other. A Cloud Building Block is any identifiable entity inside the Cloud environment.
Cloud Building Blocks can be Cloud Resources or Cloud Components. Any Cloud application is split into Cloud Resources and Cloud Components.
mOSAIC aims at offering a way to develop Cloud Components which are:
• scalable, i.e. it should support multiple instances of the same component and scale well with respect to the increasing number of instances;
• fault tolerant, i.e. it should be able to handle in an as automated as possible way the fault of a component
• manageable, i.e. it should be easy to configure it by changing its working parameters;
• autonomous, i.e. it should be able to run in a Cloud environment, independently from other components.
A Cloud Resource is under Cloud provider control. A Cloud Component is a building block, controlled by user, configurable, exhibiting a well defined behavior, implementing functionalities and exposing them to other application components, and whose instances run in a cloud environment consuming cloud resources.
Simple examples of Components are: a Java application runnable in a platform as a service environment; or a virtual machine, configured with its own operating system, its web server, its application server and a configured and customized e-commerce application on it. Components can be developed following any programming language, paradigm or in-process API.
Communication between Cloud Components takes places through Cloud resources (like message queues – AMPQ, or Amazon SQS) or through non-Cloud resources (like socket-based applications). The same as component development, communication can use any paradigm and/or remote API. Many existing Cloud application can be described in terms of components and their communication respecting the definition above proposed, even if the concepts are not defined in a so explicit way.
A Component developed independently from the platform proposed here (a legacy-component) can interact without problems with Cloud components, even if it probably will not grant all the above described characteristics.
The high level description of a Cloud application in terms of inter-communicating components is not affected by the way in which components are developed (the programming language and the programming paradigm adopted) or communicate between them (like queues or sockets).
5.1.3 API’s layers
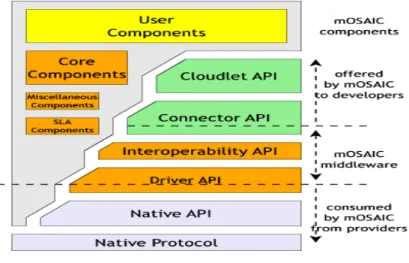
As resource interaction plays a very important role in building a cloud application, we invest an important part of our efforts to propose a unified resource API. Taking into account the goals mentioned in the previous section, achieving the aim of a unified API for multiple programming languages requires a specific architecture that we present in Fig. 6. The bare resource APIs are wrapped in a couple of layers, each one increasing the abstraction, until the developer sees a single consistent interface. The green components are developed for a certain programming language. The orange ones are the platform APIs. The gray components are the reusable ones.
Figure 6: API layers
At the lowest layer we have either the native resource protocol (Web service, RPC, etc.), or a native resource API provided as a library by the vendor for a certain programming language; at this level we have no uniformity (for example nothing between CDMI resources and a Cassandra Thrift API), but we have full access to all the features of the resource, and no performance penalty.
One layer upwards we have the driver API which wraps the native API, providing the first level of uniformity: all resources of the same type are exported with the same interface. Thus exchanging, for example, an Amazon S3 with a Riak key-value store is just a matter of configuration. Of course at this level we are incurring some performance penalties (as we have to trans-code from native a data model to our uniform one), and we are starting to loose some custom resource features (like the ACL from Amazon S3).
The RPC-like-interoperability API aims to provide programming language interoperability and protocol syntax and semantic enforcements. It is not a full API, but actually an RPC solution that abstracts addressing, and provides the driver API with stubs, and the connector API proxies.
The first layer that the developer is expected to touch is the connector API which, depending on the programming language, provides abstractions for the cloud resources, suitable for the programming paradigm. It can be roughly compared with the C’s ODBC, Java’s JDBC, or even Java’s JDO. In fact this is where we provide the second kind of uniformity for the programming paradigms, as all the implementations of the connector API in object oriented programming languages will have similar class hierarchies, method signatures, or patterns. On the performance only small impact is expected, and there is no feature loss due to the 1:1 mapping between what the driver and the connector API provide.
Even thought the developer already can access Cloud resources, he or she must restrict himself or herself to a cloud compliant programming methodology, which we provide (integrated with all the layers already mentioned) that we call Cloudlet, as similar with the existing Java Servlet technology that provides standard programming components in J2EE environments and which was adopted even by Google in their AppEngine PaaS solution. Again like in the layer above little performance and no features are lost.
The native and driver APIs live inside a driver daemon, meanwhile the connector, cloudlet APIs, and the user code lives in what we call a component. Both processes are usually on the same node, but the resource does not have a clearly defined process scope, and in almost all cases it is outside of the current node. The communication between these three scopes is done as follows: between the driver daemon and the actual resource we use the native networked resource protocol (accessed through the native API), and between the driver daemon and the component process we use our custom interoperability API (by providing stubs on the driver side, and proxies on component side).
5.2 Platform components
The mOSAIC platform is used by the developer to:
• develop the Cloud-application by providing the needed libraries, tools and documentation;
• deploy the Cloud-application into the Cloud(s) delegating the provisioning role to the mOSAIC Cloud Agency;
• run, monitor, and scale the Cloud-based application (again delegating the provisioning). In order for the platform to fulfil its goals it must cooperate / communicate with:
• the mOSAIC Cloud Agency (by using JADE specific XML/HTTP API's);
• the Cloud application itself (by providing homogeneous API's);
• the Cloud provider itself (by consuming heterogeneous Cloud API's);
• other middleware (by consuming middle-ware dependent API's); The components of the platform are:
• language dependent libraries that expose the mOSAIC API to the developer and providing:
o run-time operations:
module configuration;
module life-cycle management;
o resource mediation:
file system (e.g. wrapping HDFS, S3, etc.);
key-value store (e.g. wrapping Riak, S3, etc.);
columnar store (e.g. wrapping HBase);
message queues (e.g. wrapping RabbitMQ, SQS+SNS);
• supporting services for:
o deployment; o running; o monitoring; o scaling.
5.2.1 Provisioning system
It is in charge of providing a set of functionalities for resources negotiation and management. These facilities can be used by the mOSAIC runtime engine, if the developer uses the mOSAIC tools to implement his applications and wants to delegate the management, otherwise they can be invoked independently by the application.
The provisioning services will be available as a sub-set of mOSAIC API.
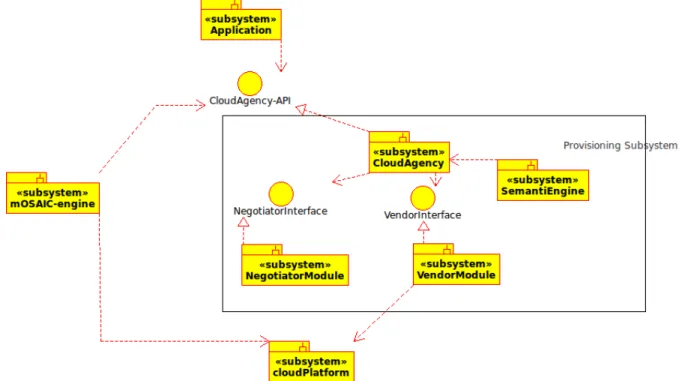
As it is shown in the Figure 7, the provisioning system is composed of several different sub-systems:
• The Cloud Agency is a multi agent system that is responsible for SLA management: negotiation, re-negotiation, monitoring
• The Negotiation Module that implements different policies for effectively composing the SLA according to the application requirements and the Vendors' proposals.
• The Vendor Module which can be implemented by different technologies to support the interaction with Cloud Platforms in order to acquire and to instantiate resources.
• The Semantic Engine that is able to discover new Cloud Services and Providers and to update the list of available ones if they are supported by mOSAIC.
5.2.2 Cloud agency
The Cloud Agency architecture is made of different components. In the Figure 8 we can see a component diagram composed of:
• The Jade Agents Platforms
• Agents
• A storage for statistics
• A Negotiator Interface to be extended by one or more external implementations
• A Vendor Interface to be extended by more external implementations
Figure 8: Agents interactions
The Jade Platform (Table 4) provides the environment for executing agents and the basic facilities to manage the agent life cycle. It also provides communication facilities which are used to implement agents interaction protocols.
Table 4: Jade agents
Agent Description
DF Agent belonging to the Jade implementation of the FIPA standard providing yellow pages. AMS Agent that manage agent names and agent addresses.
All the Cloud Agency functionalities are implemented by the cooperation of specialized agents, which interacts according to well defined Agents Interaction Protocols. The agents roles are described in the Table 5.
The Negotiator Interface and the Vendor Interface are abstraction of the Negotiation Module and the Vendor Module. They allow mOSAIC developers to implements different policies, without being aware about the Agents Technology and about the Cloud Agency Implementation.
The Cloud Agency APIshave been organized into 2 packages: Core and Utility
The core APIs provides the basic facilities to the mOSAIC software platform and to the applications for negotiation, checking each contract and configuring the Cloud Agency. They activate protocols which have been implemented into the Cloud Agency but are independent from the SLA. It means they are not aware of the semantic content of the SLATemplate, SLAProposal and Contract. On the other hand semantic is handled by the Negotiator Module. The set of facilities provided by the APIs includes (Figure 9):
• Call for SLA Proposal
• Accept/Refuse Proposal
• Cloud Agency Configuration
• Check for Contract status
The Utility provide a set of classes which can be used to get information about the Cloud Agency configuration and status.
Table 5: mOSAIC agents
Agent Description
Client Agent It is in charge to receive request from the user, from the application or from the mOSAIC runtime.
Negotiator Agent
The Negotiator Agent receives from the Client a SLA Template and splits the SLA Template in different requests which will be forwarded by the Mediator Agent. Mediator
Agent
The Mediator is a broker that, for each call for proposal coming from the Negotiator Agents, searches in the DF for the available vendors which can answer to that call.
Vendor Agent The Vendor Agent implements the Standard FIPA Contract Net interaction protocol at Provider Side
Archiver Agent
It maintains statistics about the mOSAIC system. Benchmarking
Agents
They will collect measures about the QOS parameters to be monitored by Monitoring Agent.
Monitoring Agent
It is responsible to use the statistics in order to check the compliance of the current performances with the Service Level defined in the SLA.
Table 6: External interfaces
Interface Description Negotiator
Interface
It is used to update the received proposal and combine them in order to generate the final SLA.
Vendor Interface
Will interact with a particular provider in order to ask for proposals, accept them and instantiate resources to get bindings to be used by application or by the mOSAIC runtime.