International Journal of Emerging Technology and Advanced Engineering
Website: www.ijetae.com (ISSN 2250-2459, ISO 9001:2008 Certified Journal, Volume 7, Issue 9, September 2017)
250
Review on Human Reference and Personal Genome Big Data
Analysis
Balamurugan Sivaprakasam
1, Jothi Ramalingam
21Department of Computer Science, Vel’s University, Pallavaram, Chennai – 600 117, Tamil Nadu, India
2Department of Advanced Zoology and Biotechnology, Government Arts College (Autonomous), Nandanam, Chennai – 600 035,
Tamil Nadu, India
Abstract— As we live in information society, data are enormously increasing in all the fields including health care with human related biological data. After the successful achievement of Human Genome Project (HGP) in 2003, the complete human genome sequence (reference genome set for any individual) was made available in NCBI (National Center for Biotechnology Information) and its size is about few GB. From 2005 – till now, one of the initiatives, the Personal Genome Project (PGP), generates 1000s of individual genome sequences of few terabytes in size and are making available in its own website. Both are freely available through Internet. If the sequencing is done for individuals of 7.4 billion world population, the genome size will exceed in Exabytes. Those data sets are so large and complex and traditional data processing applications are inadequate to handle such ―Big data‖. Through analyzing and comparing these huge amount of genomic sequences paves way to understand the complex diseases and find the personalized medicines. In the near future, the biological and computer science researchers will face a big challenge to store, manage and analyze this increasing size of data. Therefore, now and then, researchers are in position to store and manage these biological Big data in Cloud computing and do analysis or analytics by handling those data online (instead of storing it in hard drives). The present study reviews on Human Genome big data analytics with the above-mentioned services and methods will insight the bioinformaticians for human genetic variants analysis among individuals and that will pave the way to find
personalized medicine for our societal benefits.
Keywords— Big data; Human Genome Project; Personal Genome Project; R and Bioconductor; Cloud computing
I. INTRODUCTION
Human (Homo sapiens) is the culturally highly evolved species among all other animal categories. Research in all the scientific fields including computer science targeting on human health through Bioinformatics, Nanotechnology and Systems Biology [1]. The present high throughput technologies of biotechnology revolution paves way in analyzing human genome to conquer precise modeling of complex diseases and finding medicines [2,3].
International Journal of Emerging Technology and Advanced Engineering
Website: www.ijetae.com (ISSN 2250-2459, ISO 9001:2008 Certified Journal, Volume 7, Issue 9, September 2017)
251
The present study reviews on the human genomic data, generated through HGP and PG analyzed through various methods including Bioconductor packages using R programming language.II. HUMAN GENOME PROJECT
HGP was a 13 years’ project (1998-2003), 18 different countries were involved and founded by the United States Department of Energy (DoE) [10]. The Human Genome Project sequenced DNA of 24 chromosomes (22A+XY) from the volunteers which size is about few GB. Those are available in primary public database of NCBI (National Center for Biotechnology Information), which are considered as primary reference dataset [11]. In addition to Human Genome, cDNA (complementary DNA) and protein sequences are also available in NCBI [12]. The advancement in sequencing personal genomes is enormously increasing and are supportive in understanding human biology [10,13]. Since every genome of an individual is unique, it is important to sequence genomes of everyone to have their own genetic information and it is now possible to get genomes of all individuals due to the advancements in DNA sequencing technologies [14]. Therefore, the sequencing of individual genome has started coming up immediately after, the remarkable success of HGP is called personal genomics [14]. The first 20 individuals have had their personal genomes sequenced, for which each individual had paid $100,000 [15]. Craig Venter (founder of Celera Genomics), James Watson discoverer of the DNA double helix) and Steve Jobs (co-founder of Apple Inc.,) were the few among those 20 individuals. The latter DNA of cancer had also sequenced; it would provide information about more appropriate treatments for cancer and it helps to other people with the same treatment [16].
Though the facility to get our genomic information is very much possible, still it is in pilot phase. It is thought that one day it could play a crucial part of our everyday healthcare. Therefore, Personal genomics could allow us to optimize our health by our diet and taking medicines based on our genomic information [17]. Also in order to place the protection of individuals, HGP follows Ethical, Legal and Social Implications (ELSI) [18,19]. Nowadays the personal genome information is available in sources like Personal Genome Project.
III. PERSONAL GENOME PROJECT (PGP)
Personal genomics helps public that the individual genome sequences are made openly available and the service will continue to be accessible through personal genome databases such as 1000 genome project, personal genome project (PGP), PMI (Precision medicine Initiative), 23 and Me, etc. [20]. Among all the above said resources, PGP has been the first research project (pioneering initiative) to make public sharing of personal genomes data for research [21]. PGP was initiated by George Church at Harvard Medical School in 2005 and it is a large, long-term study looking to sequence and analyze the genomes of over 100,000 people across the world. Unlike other personal genomic studies, the Personal Genome Project publishes all its data online for the public and helps in the advancement of medical sciences [13].
In PGP, genome will be taken from the volunteer’s sample cells for sequencing. Along with their complete genome sequences, they also should provide information about theirphenotypesincluding medical records and various measurements such as height and weight. This allows the research to examine the relationship between phenotype, our genes and environment. These large-scale genomic data are one of the Big data among health sciences [22]. In PGP, each profile contains medical and genomic information including details about medications, procedures, diseases and demographic information [18].
By making all the data collected, publicly and freely available to all, the PGP hope that it will reach scientists, drug companies and research institutes across the world. This paired with information about health and physical characteristics could dramatically accelerate scientific research. It could help scientists learn more about how genetic and environmental factors interact to cause disease and drive new treatments for diseases like diabetes, cancer etc. (http://www.yourgenome.org/ stories/personal-genomics-the-future-of-healthcare).
A. Discrepancies in the Expenditure for Personal Genomics among Countries
International Journal of Emerging Technology and Advanced Engineering
Website: www.ijetae.com (ISSN 2250-2459, ISO 9001:2008 Certified Journal, Volume 7, Issue 9, September 2017)
252
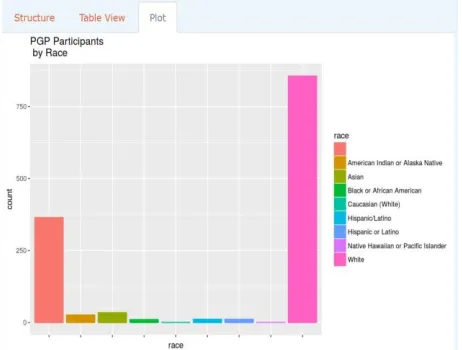
Several life-threatening but early preventable or treatable diseases like Malaria are still prevalent in developing countries. Figure 1 depicts that the white people are many in numbers in sequencing their genomes than other people. The data was retrieved from PGP database using R programming.Figure 1: Bar chart of Demographic data available in Personal Genome Project. White predominates other races(Bar Chart is taken
from one of the Author’s web App, https://SAFA-HG.shinyapps.io/home/).
[image:3.612.53.284.216.391.2]Previously the cost for sequencing genome through HGP was $100,000 but the present technology is sequencing personal genome to lower in price at $1000 [23]. Figure 2 shows that the Genome sequencing cost per raw Megabase (MB) is getting reduced from 2001 – 2015 (The data is taken from https://www.genome.gov/ sequencingcostsdata/ and the graph has been drawn using Excel). So, it is possible to have all our 7.4-billion World population on some future day. But, discrepancies exist in omics facilities such as personal genome sequencing and personalized medicine between the well-developed, developing and under developed countries [21]. In addition, the differences also exist in the ability to generate and analyze biological Big Data.
Figure 2: Genome sequencing cost from 2001 - 2015.
IV. HUMAN RELATED DATABASES AND HOW BIG THE BIOLOGICAL DATABASES ARE?
The scientific research projects such as HGP and PGP generates enormous amount of genomic, environmental, human trait data donated by volunteers. Many other human related data are also available in different number of biological databases that are widely used and currently accessible via the Internet. Considering the heterogeneity of those datatype, biological databases can be classified into various categories such as DNA, RNA, Protein, Expression, Pathway, disease, nomenclature, ontology, literature, histopathological and radiological images etc [21,24,25]. Figure 3 shows the searching result of ―Homo sapiens‖ in NCBI through Entrez, which exhibit how big the data resources for Human.
International Journal of Emerging Technology and Advanced Engineering
Website: www.ijetae.com (ISSN 2250-2459, ISO 9001:2008 Certified Journal, Volume 7, Issue 9, September 2017)
[image:4.612.52.289.140.344.2]253
Figure 3: Screenshot of the results obtained in NCBI using the keyword ―Homo sapiens‖ through Entrez to show the human related
data are big.
Consequently, in the era of Big data, human-related biological databases continue to grow not only in count but also in five distinct dimensions (5V’s) such as Variety, Velocity, Volume, Veracity and Value. These data are posing unprecedented challenges in data storage, processing, exchange, and curation [25]. With these challenges, decoding the human genome of each individual bears great significance to do research on personalized medicine against diverse diseases.
V. BIOLOGICAL BIG DATA STORAGE USING CLOUD COMPUTING
Cloud computing is being grown unparallelly for the past few years. It is composed of three components such as Infrastructure as a Service(IaaS), Platform as a Service(PaaS) and Software as a Service(SaaS). Using cloud services lots of companies do collect, store and analyze a huge amount of data. Nowadays, any analyst can make use of the genome information from cloud services provided by the commercial companies like Amazon, Google, Microsoft, Rackspace, GoGrid, Nimbus, Eucalyptus, BioCloud etc., those who also focus on genomic research [28]. Even the bioinformaticians can also make use of the cloud computing to access biological Big data, tools and its services [29,30,31,32]. Currently, lots of commercial companies those who provide cloud services are offering to store research data for free or at less price to encourage more researchers to use their services.
For example, Amazon Web services levies no charge for hosting the sequences released by the 1000 genome project. Since the cloud services can able to merge large data sets, it would allow scientists to link rare genetic variations to diseases, and such successes would encourage others to deposit more data sets and the development of yet more powerful software [33].
VI. TOOLS FOR BIOLOGICAL BIG DATA ANALYSIS
Nowadays many powerful statistical and graphical methods are available for the analysis of genomic Big data. Hadoop is anopen-sourcesoftware frameworkwritten in JAVA and developed by GOOGLE, used fordistributed storageand processing ofBig datasets using theMapReduceprogramming model [34]. It is used to easily write applications to process petabyte of data set. Many other tools like SOAP, MAQ, RMAP, Myrna and ZOOM are also used for biological Big data analytics. But the above tools have their own pros and cons. This kind of comparative study on bioinformatics analytic tools will certainly help and assist not only to biologist to conduct more concrete findings in the field of biology, but also to increase the researches from both the fields of computer science and biological sciences to guide their attention and consideration towards right computing on personalized medicine [26,35,36].
Like Hadoop framework, Bioconductor of R package is also found recently the most appropriate method to analyze biological data [37]. It is an open source and open development software project for the analysis of biomedical and genomic data. The project was started in 2001 and includes more than 25 core developers in the US, Europe, and Australia. Latest release contains 1296 packages. It provides access to powerful statistical and graphical methods for the analysis of genomic data. Bioconductor packages facilitate the integration of biological metadata such as GenBank, GO, Entrez, PubMed in order to analyze the available experimental data [38,39,40].
VII. DISCUSSION
International Journal of Emerging Technology and Advanced Engineering
Website: www.ijetae.com (ISSN 2250-2459, ISO 9001:2008 Certified Journal, Volume 7, Issue 9, September 2017)
254
Due to the invention of HGP and PG, for the past few years, the size of Human genome information in NCBI and PGP database has grown exponentially. In future, the collection of these data will exceed in volume of Exabytes but also in 5v’s (varieties, volume, veracity, value and velocities). These diversities of Omics information may take us to the Yottabyte data scale in the coming few years depends on the effort taken by the Global biomedical researchers and bioinformaticians to increase the quality of human life. Though the high throughput sequencing technology is increasing the possibility of sequencing whole genomes of many individuals in a short period with low cost, there is a challenge for researchers in handling, analyzing and interpreting the genomic information with moderate numbers of individuals. These challenges will become worsened when millions of individuals are sequenced. One thing to overcome this task is to develop a Big data system to store, manage and analyze using the services like Cloud [30].In this regard, this paper discusses about Big data analysis on human genomes in various aspects. With the invent of HGP and PG technologies, it is possible that, in future, all the individuals in the Globe may have their own genome information as their personal genetic card which will be the reference to the physician to have personalized medicine. This advancement should not be restricted only for people who are in well developed countries. It should be benefited all the individuals who are in developing as well as under developed countries. In future, this may happen invariably to all the countries.
Acknowledgement
We express our sincere thanks to all the authors, whose papers, in the area of biological Big data analytics on Human genome are published in various research journals.
REFERENCES
[1] Loscalzo, J. and Barabasi, A. 2011. Systems biology and the future of medicine Systems, WIREs Systems Biology and Medicine, Vol. 3 (6), pp.619-627.
[2] Niazi, G.A. and Riaz-ud-Din, S. 2006. Biotechnology and Genomics in Medicine - A Review, World Journal of Medical Sciences, Vol. 1 (2), pp. 72-81.
[3] Tripathi, R., Sharma, P., Chakraborty, P. and Varadwaj, P.K. 2016. Next-generation sequencing revolution through big data analytics, Frontiers in Life Science, Vol. 9 (2), pp 119–149.
[4] Makalowski, W. 2001. The human genome structure and organization‖, Acta Biochimica Polonica, Vol. 48 (3), pp.587-598. [5] Gonzaga-Jauregui, C., James, R., Lupski, J.R. and Gibbs, R.A. 2012.
Human Genome Sequencing in Health and Disease, Annual review of medicine, Vol. 63, pp. 35–61.
[6] Watson, J.D. and Crick, F.H.C. 1953. A structure for deoxyribose nucleic acid, Nature, Vol. 171, pp. 737–738.
[7] Travers, A. and Muskhelishvili, G. 2015. DNA structure and function, FEBS Journal, Vol. 282, pp. 2279–2295.
[8] Pećina-Šlaus, N. and Pećina, M. 2015. Only one health, and so many omics, Cancer Cell International, Vol. 15 (64).
[9] Merelli, I., Pérez-Sánchez, H., Gesing, S. and D'Agostino, D. 2014. Managing, analyzing, and integrating big data in medical bioinformatics: open problems and future perspectives, BioMed Research International. http://dx.doi.org/10.1155/2014/134023. [10] Hood, L. and Rowen, L. 2013. The Human Genome Project: Big
science, Genome Medicine, Vol. 5 (79).
[11] NCBI Resource Coordinators, 2016. Database resources of the National Center for Biotechnology Information, Nucleic Acids Research, Vol. 44, Database issue D7–D19.
[12] Sayers, E.W. et al. 2011. Database Resources of the National Center for Biotechnology Information, Nucleic Acids Res. Vol. 39, Database issue D38-D51.
[13] Alexov, E. 2014. Advances in Human Biology: Combining Genetics and Molecular Biophysics to Pave the Way for Personalized
Diagnostics and Medicine, Advances in Biology,
http://dx.doi.org/10.1155/2014/471836.
[14] Gurwitz, D.D. and Eschet, Y.B. 2009. Personal Genomics Services: Whose Genomes? European Journal of Human Genetics, Vol. 17, pp. 883 – 889.
[15] Ossola, A. 2015. Your Full Genome Can Be Sequenced and Analyzed for Just $1,000 It used to cost $100 million just a few years ago, Popular science, http://www.popsci.com/cost-full-genome-sequencing-drops-to-1000.
[16] Pai, A. 2009. Genomic medicine in health care – The tip of the iceberg, Electronic health care, Vol. 8 (1).
[17] Guttmacher, A.E. and Collins, V. 2003. Welcome to the Genomic Era, The New England Journal of Medicine, Vol. 349 (10). [18] Church, G.M. 2005. The Personal Genome Project, Molecular
Systems Biology, Vol. 1 (1), pp. 1-3.
[19] Charlebois, K., Palmour, K.N. and Knoppers, B.M. 2016. The Adoption of Cloud Computing in the Field of Genomics Research: The Influence of Ethical and Legal Issues, PLoS ONE Vol. 11 (10). https://doi.org/10.1371/journal.pone .0164347.
[20] The 1000 Genomes Project Consortium. 2012. An integrated map of genetic variation from 1,092 human genomes. Nature. Vol. 491 (7422), pp. 56–65. doi:10.1038/nature11632.
[21] Akram, A., Turcotte, M. and Meyre, D. 2015. From Big Data Analysis to Personalized Medicine for all: Challenges and Opportunities. BMC Medical Genomics. Vol. 8 (33). 10.1186/s12920-015-0108-y.
[22] Belle, A., Thiagarajan, R., Soroushmehr, S.M.R., Navidi, F., Beard, D.A. and Najarian, K. 2015. Big Data Analytics in Healthcare,
BioMed Research International, http://dx.doi.org/
10.1155/2015/370194.
[23] Hayden, E.C. 2014. Technology: The $1,000 genome, Nature, Vol. 507 (7492), 294-295.
International Journal of Emerging Technology and Advanced Engineering
Website: www.ijetae.com (ISSN 2250-2459, ISO 9001:2008 Certified Journal, Volume 7, Issue 9, September 2017)
255
[25] Baxevanis, D.M. and Bateman, A. 2015 The Importance ofBiological Databases in Biological Discovery‖, Curr Protoc Bioinformatics, Vol. 19 ;50:1.1.1-8.
[26] Marx, V. 2013 The Big Challenges of Big Data, Nature, 498, 255, 2013.
[27] Scruggs, S.B., Watson, K., Su, A., Hermjakob, H., Yates, J.R., Lindsey, M.L., and Ping, P. 2015 Harnessing the Heart of Big Data‖, Circ Res, Vol. 116, No. 7, pp. 1115–1119.
[28] Fusaro, V.A., Patil, P., Gafni, E., Wall, D.P. and Tonellato, P.J. 2011. Biomedical Cloud Computing with Amazon Web Services, PLoS Computational Biology, Vol 7 (8), pp. 1-6.
[29] Hsu, C,H., Lin, C.Y., Ouyang, M. and Guo, Y.K. 2013. Biocloud: Cloud Computing for Biological, Genomics, and Drug Design, BioMed Research International. Vol. 2013. http://dx.doi.org/ 10.1155/ 2013/909470.
[30] Nemade, P. and Kharche, H. 2013. Big Data in Bioinformatics & the Era of Cloud Computing, IOSR Journal of Computer Engineering, Vol. 14 (2), pp. 53-56.
[31] O’Driscoll, A., Daugelaite, J. and Sleator, R.D. 2013. Big data, Hadoop and cloud computing in genomics, Journal of Biomedical Informatics, Vol. 46, pp. 774–781.
[32] Kaur, S. and Kaur, S. 2015. Genomics with Cloud Computing, International Journal of Scientific & Technology Research, Vol. 4 (4). pp. 146-148.
[33] Stein, L.D., Knoppers, B.M., Campbell, P., Getz, G. and Korbel, J.O. 2015. Data analysis: Create a cloud commons, Nature, Vol. 523, pp. 149-151.
[34] Urmila, R.P. 2016. Big Data Analysis: Comparison of Hadoop MapReduce, Pig and Hive, International Journal of Innovative Research in Science, Engineering and Technology, Vol. 5 (6). [35] Lawrence, M., Huber, W., Pag`es, H., Aboyoun, P., Carlson, M.,
Gentleman, R., Morgan, M. and Carey, V. 2013. Software for Computing and Annotating Genomic Ranges. PLoS Computational Biology, Vol. 9, doi: 10.1371/journal.pcbi. 1003118.
[36] Gentleman, R. 2008. R Programming for Bioinformatics. Chapman & Hall/CRC. ISBN 1-4200-6367-7.
[37] Morgan, M., Carlsony, M., Obenchainz, V., Tenenbaumx, D. and Pages, H. 2011. High-throughput sequence analysis with R and Bioconductor, August 17.
[38] Gentleman, R., Vincent, J., Carey, V.J., Bates, D.M., Bolstad, B., Dettling, M., Dudoit, S., Ellis, B., Gautier, L., Ge, Y., Gentry, J., Hornik, K., Hothorn, T., Huber, W., Iacus, S., Irizarry, R., Leisch, F., Li, C., Maechler, M., Rossini, A.J., Sawitzki, G., Smith, C., Smyth, G., Tierney, L., Yang, J.Y. and Zqwhang, J. 2004. Bioconductor: open software development for computational biology and bioinformatics, Genome Biology, Vol. 5 (R80).
[39] Gentleman, R.V., Carey, V.W., Huber, R., Irizarry, S., Dudoit, eds. 2005. Bioinformatics and Computational Biology Solutions using R and Bioconductor, Springer.