2017 2nd International Conference on Software, Multimedia and Communication Engineering (SMCE 2017) ISBN: 978-1-60595-458-5
Parametric Dropout in RNN
Di WU, Yuan-ping NIE
and Jiu-ming HUANG
College of Computer, National University of Defense Technology, Chang Sha, China
Keywords: Dropout, Parametric, RNN.
Abstract. Deep learning has become a very important tool in the field of natural language processing (NLP), especially RNN, in processing sequential data. Dropout as a method of regularization, excellent solved the “overfitting” problem in neural network training. However, dropout in RNN always just implement in the feed-forward connection, less for recurrent connection, because dropout may damage the temporal dependencies of RNN. In this paper, we proposed a parametric dropout algorithm for RNN, used in recurrent connection and can capture the dependence and semantic information between words in sentences. We experiment our algorithm in two datasets and composed with original uniform dropout. The result shows that our algorithm performs better than the previous one.
Introduction
Recently, deep learning methods have become very popular in natural language processing (NLP), especially recurrent neural network (RNNs). RNNs have outstanding performances in processing sequential models. Because when processing sequential data, such as text, neural networks need not only the current information, but also the previous data. The “memory” ability of RNN can help to store previous information and transmit it for subsequent nodes, which is very important for sequential data analyzing. Now, RNNs have achieved the state-of-art performances in some tasks in NLP, such as speech recognition, neural language modeling, machine translation and image description. RNNs will be applied more widely in the future.
Dropout is one of regularization methods, originally proposed by Hinton in 2012[1]. When training neural networks, if the training set is small, the result tends to be well in the training set, but unsatisfactory in the test set. This problem is called “overfitting”. Dropout is proposed to solve this overfitting problem. The dropout procedure is that discard some nodes from the network temporarily according to some certain probability when modeling deep learning networks. After injecting dropout, the neural network can obtain a thinner network from the original one, this to some extent, increases the number of training data.
The original dropout discards nodes randomly, the dropout probability always obeys uniform distribution or normal distribution. But words in sentence are not random. There are some relationships and dependence between them. The original dropout does not consider the dependence between words in sentences, which may discard some important words. Parametric dropout assigns proper dropout probability to each words according to the importance and dependence of the word, which makes the discard more accuracy.
Dropout injected in feed-forward neural networks, such as Convolutional Neural Networks (CNN), has achieved excellent performances. But dropout in RNNs is somewhat limited. Dropout in RNN can be implemented in feed-forward architectures like CNN. But when injected in the recurrent connection, the preceding information will be cut off and it will severely damage the temporal dependencies of RNNs, which will cause a memory loss.
Related Work
Dropout is originally proposed by Hinton in 2012 in his paper [1]. He explained the theory and implement of dropout in his paper, and that raised extensive attention and research in recent years. In [2,3,4], they demonstrated that dropout used in feed-forward networks such as convolutional neural networks(CNNs) is effective through experiments. Srivastava et al.[5] extended dropout by showing that dropout can be effectively applied in the hidden layers as well and interpret the model as a form of model averaging. Their experiment results declared that neural networks with dropout had achieved state-of-the-art performances in several benchmark datasets. Wan et al.[6] proposed a generalization of dropout, DropConnect, which set a randomly selected subset of weights instead of activations to zero, for regularizing large fully-connected layers in neural networks. Goodfellow et al.[7] proposed a new activation function called maxout, which can facilitate optimization by dropout and improve the accuracy of dropout’s fast approximate model averaging technique. Steven et al.[8] explained that annealed the probability of dropout from a high original value to zero can improve the quality of the model. Wang et al.[9] proposed a fast dropout training method which approximately regards the input as obeying Gaussian distribution. With this method, all data can be used completely.
Considering dropout in RNN, Bayer et al.[10] proposed a deterministic approximation of dropout (fast dropout) for RNN. They thought that dropout should be used in the connection from the hidden layer to the output layer which is the “non-dynamic” parts of the model, because dropout may cause the dynamics change of RNN dramatically. Pham et al.[11] assessed dropout with handwriting recognition tasks. They indicated that dropout in RNN should only be applied to the feed-forward connection, not the recurrent connection. Théodore et al.[12] made several experiments on LSTM to explore where was the best place to apply dropout. Taesup et al. [13] suggested a new variant of dropout in RNN in the speech recognition community, which randomly dropped unit in the LSTM’s cell and used the same mask at every time step. Gal et al.[14] proposed a similar model as Moon’s, they regarded the weight of RNN as a matrix based on the Bayesian neural network and variational, dropping out a row of the matrix randomly as dropout and used this dropout operation at every time step. Dropout can be used in many areas in NLP, such as QA. Nie Y. et al. [18] proposed an attention-based encoder-decoder model for answer selection in question answering, which used dropout in the model.
Parametric Dropout in RNN
Dropout in LSTM
LSTM is a popular variant of RNN. It can prevent RNN from vanishing gradient problem though special gate system, which will strengthen the memory ability of RNN after a larger number of time steps during both forward and backward passes. The Core formula of LSTM are as follows:
𝑓𝑡 = 𝜎(𝑊𝑓∙ [ℎ𝑡−1, 𝑥𝑡] + 𝑏𝑓). (1)
𝑖𝑡 = 𝜎(𝑊𝑖 ∙ [ℎ𝑡−1, 𝑥𝑡] + 𝑏𝑖). (2)
𝐶̃𝑡 = 𝑡𝑎𝑛ℎ(𝑊𝐶∙ [ℎ𝑡−1, 𝑥𝑡] + 𝑏𝐶). (3)
𝐶𝑡 = 𝑓𝑡∗ 𝐶𝑡−1+ 𝑖𝑡∗ 𝐶̃𝑡. (4)
𝑜𝑡 = 𝜎(𝑊𝑜∙ [ℎ𝑡−1, 𝑥𝑡] + 𝑏𝑜). (5)
(1) Apply dropout on the hidden state vector in each gate computing and updating. The specifically formulas in each sequence are as follows:
𝑖𝑡 = 𝜎(𝑊𝑖 ∙ [𝑑(ℎ𝑡−1), 𝑥𝑡] + 𝑏𝑖). (7)
𝑓𝑡 = 𝜎(𝑊𝑓∙ [𝑑(ℎ𝑡−1), 𝑥𝑡] + 𝑏𝑓). (8)
𝑜𝑡 = 𝜎(𝑊𝑜∙ [𝑑(ℎ𝑡−1), 𝑥𝑡] + 𝑏𝑜). (9)
𝐶̃𝑡 = 𝑡𝑎𝑛ℎ(𝑊𝐶∙ [𝑑(ℎ𝑡−1), 𝑥𝑡] + 𝑏𝐶). (10)
(2) Apply dropout on the cell directly in each sequence, the specifically form is: 𝐶𝑡 = 𝑑(𝑓𝑡∗ 𝐶𝑡−1+ 𝑖𝑡∗ 𝐶̃𝑡). (11)
(3) Apply dropout to the cell update vector, the specifically formula is as follows: 𝐶𝑡 = 𝑓𝑡∗ 𝐶𝑡−1+ 𝑖𝑡∗ 𝑑(𝐶̃𝑡). (12)
Regarding the intuitive idea to drop previous hidden states directly like method (1), considering the hidden state update rule of an LSTM network, assume every gate to be equal to 1, and then: ℎ𝑡 = (ℎ𝑡−1+ 𝐶̃𝑡)𝑝. (13)
𝐶̃𝑡 are update vectors and 𝑝 is the probability that not drop a neuron. And ℎ𝑡−1 can be computed by the same rule, recursively so ℎ𝑡 can be rewrite as: ℎ𝑡 = ((((ℎ0+ 𝑔0)𝑝 + 𝑔1)𝑝 + ⋯ ) 𝑝 + 𝑔𝑡) 𝑝 (14)
Collate the formula form as: ℎ𝑡 = 𝑝𝑡+1ℎ 0+ ∑𝑡𝑖=0𝑝𝑡−𝑖+1𝑔𝑖. (15)
𝑝 is a value between 0 and 1. So when 𝑖 is small and then 𝑝𝑡−𝑖+1 will be little and approach to 0. Small 𝑖 means that 𝑔𝑖 is far away from 𝑡 step. As a result the 𝑔𝑖 far away from 𝑡 step will have little contribution to the summation and even can be removed. This will make a memory loss, especially the initial information. As for method (3), this problem can be relieved. Only dropping the update vectors g will not scale the hidden state directly. The formula will rewrite as: ℎ𝑡 = pℎ0 + ∑𝑡𝑖=0𝑝 𝑔𝑖 = pℎ0+ 𝑝 ∑𝑡𝑖=0𝑔𝑖. (16) Method (3) allows us to apply dropout to per-step mask sampling, and still keep long-term dependencies. From [16] we know that method (3) has the best performance and less memory loss. So in our experiments, we choose method (3), applying dropout to the cell update vector.
Parametric Dropout for RNN
The probability of dropout proposed previously basically obeys uniform distribution or normal distribution. However, as we all know, words in sentences are not simply obeying normal distribution or uniform distribution; they may have some additional and more complicated associations. The parametric dropout for RNN we proposed premeditates the dependence between words. In general, the probability of dropout for a word should be related to its importance in the sentence. The higher the importance of the word, the smaller the corresponding dropout probability should be. We don’t want to drop out the meaningful word, otherwise the feature of the sentence will incomplete.
Particularly, let 𝐒 represents a sentence, 𝐒 = {𝑥1, 𝑥2, ⋯ , 𝑥𝑛}, 𝑥𝑖 indicates the word in sentence.
N represents the number of words in the sentence. For each word 𝑥𝑖 ∈ 𝐒, we can compute the conditional probability P(𝑥𝑖|𝑥𝑖−1), which represents the probability of 𝑥𝑖’s appearance on the condition of 𝑥𝑖−1’s appearance. We can regard it as the importance of 𝑥𝑖. So the dropout probability of 𝑥𝑖 should be the unimportant degree of 𝑥𝑖, which equals to 1 − P(𝑥𝑖|𝑥𝑖−1). The
detailed formulas are as follows:
1 − P(𝑥𝑖|𝑥𝑖−1) = 1 −P(𝑥𝑖,𝑥𝑖−1)
𝑃(𝑥𝑖−1) = P(𝑥̃ |𝑥𝑖 𝑖−1). (17)
dp(𝑥𝑖) = 1 − P(𝑥𝑖|𝑥𝑖−1). (18)
E(dp) =dp(𝑥1)+𝑑𝑝(𝑥2)+⋯+dp(𝑥𝑛)
𝑛 . (19)
dp(𝑥𝑖) is the dropout probability of 𝑥𝑖. P(𝑥̃ |𝑥𝑖 𝑖−1) is the absence probability of the word on the condition of the last one’s appearance probability. A word has such a big probability to be discarded, then it has such a big probability does not appear. This also verifies the rationality of the algorithm from another point of view. So the dropout rule is that:
𝑑𝑝(𝑥𝑖) > 𝑘, 𝑑(𝑥𝑖) = 0.
𝑑𝑝(𝑥𝑖) ≤ 𝑘, 𝑑(𝑥𝑖) = 1. (20)
k = 𝐎𝐫[N × (1 − p)]. (21) k is the threshold of global dropout which controls the whole dropout probability of the pending data. To compute k, first we sort the dropout probability of 𝑥𝑖, dp(𝑥𝑖), in ascending order, expressed in Or. Assume the global dropout probability is p, that means we want to discard p × N
data in total. N is the number of the whole data. So 𝑥𝑖 corresponding to larger dp(𝑥𝑖) that larger
than k should be discarded. We can control the dropout by adjusting the threshold.
In practice, in this paper we use LSTM for experiment, so dropout applies to the cell update vector in the recurrent layer as mentioned in section 3.1. At test time, the dropout probability is set to zero, and the weights of the network are re-scaled according to the average of the probability.
Experiment
We evaluate our algorithms with two real world datasets, IMDB[18] and MR[19]. Both experiments are based on tensor flow[20], which is one of the most popular deep learning frameworks. The structure of our neural networks is a Recurrent Neural Network with LSTM cell. We compare our algorithm with original dropout algorithm as baseline. The details and results of two experiments are shown below:
IMDB
Dataset: The IMDB dataset has 50,000 movie reviews with one sentence per review. IMDB is a dataset for binary sentiment classification. It contains a set of 25,000 highly polar movie reviews for training, and 25,000 for testing.
Setup: The recurrent neural network used in this experiment has 128 neurons. We set the number of words as 20,000. The max length of sentences is 80 words. After the recurrent neural network there is a full-connected layer with tanh activation. We use Adam optimizer. The learning rate is set to 0.001 and training iters are 100,000. The loss function is categorical crossentropy and batch size is 32. We employ LSTM cell in neural network.
Table 1. On different dropout probability, the average accuracy of two methods on IMDB dataset.
0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9
LSTM + Uniform distribution dropout 0.78714 4 0.79139 2 0.78883 2 0.78848
8 0.78012
0.78782 4 0.78120 8 0.77748 8 0.77872 8 LSTM + Parametric dropout
0.81516 0.81034
6667
0.80322
9583 0.79516
0.79706 6667
0.80359
0769 0.78421 0.78128 0.75224
We computed each dropout probability 10 times and got the average value in table 1. The results show that our algorithm performs better than the original dropout in accuracy expect the global dropout probability is 0.9. The highest improvement is reach 2.8% when the global dropout probability is 0.1. When the dropout probability is 0.2 to 0.6 and 0.7, the improvement of our dropout method is 1%-2%. When the global dropout probability is 0.7, the two algorithms have similar performances. The best result of our algorithm is 0.81516 when the global dropout probability is 0.1, and the best result of the original one is 0.791392 when the dropout probability is 0.2. The best accuracy of our algorithm is higher than the original one 2.4%.
From the results we can find that the algorithm we proposed generally performs better than the original one. It means that our algorithm indeed exploits the dependence between words and captures more semantics, so that the model can get more accuracy and proper features of the sentence. The original dropout deleted neurons randomly. In natural language processing task, each word has different contribution to the semantic. So randomly dropout may lead the performance unstable and poorly interpretable. The best dropout probability of our algorithm is related to the content sentence composition. And our algorithm makes less important words have higher drop probability. So the interpretability of our algorithm is better than the random one. And the results show our algorithm is more effective in this task.
MR
Dataset: MR dataset has 10,662 movie reviews with one sentence per review. We separated 9,662 for training, and the remaining 1000 used for testing. It is also a binary classification problem (Pang and Lee, 2005).
Setup and results: The configuration of the neural network was the same as IMDB. We also took the accuracy as the evaluation criteria. And for each average dropout probability, we ran 10 times and took the average accuracy. The result is in table 2.
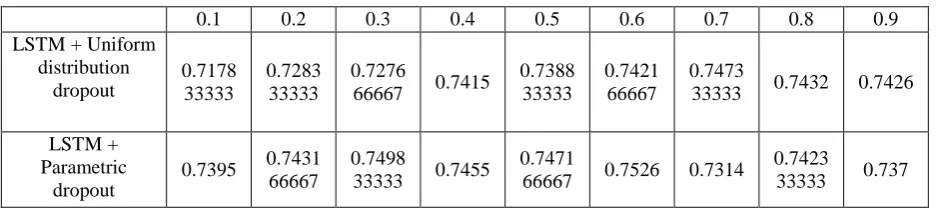
Table 2. On different dropout probability, the average accuracy of two methods on MR dataset.
0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9
LSTM + Uniform distribution dropout 0.7178 33333 0.7283 33333 0.7276
66667 0.7415
0.7388 33333
0.7421 66667
0.7473
33333 0.7432 0.7426
LSTM + Parametric
dropout
0.7395 0.7431
66667
0.7498
33333 0.7455
0.7471
66667 0.7526 0.7314
0.7423
33333 0.737
The result shows that the algorithm we proposed is better when the global dropout probability is less than 0.7. When the global dropout probability is 0.3, the gap is the biggest, about 2.22%. When the global dropout probability is more than 0.6, our algorithm become worse than the original one. The best result of our algorithm is 75.26% when the global dropout probability is 0.6 and the best result of the original algorithm is 74.73% when the dropout probability is 0.7.
[image:5.595.65.534.559.664.2]algorithm captures some dependence between words and semantic information. Maybe the MR dataset is small, so the effect is not obvious.
Conclusion
In this paper we proposed a parametric dropout algorithm in RNNs. Though we only make experiments in LSTM, it can also be used on other RNN networks like GRU. The original dropout using the uniform distribution may discard some important words, which will reduce the accuracy. The algorithm we proposed exploits the dependence between words in sentences, and combines the relationship with dropout operations. It can not only solve the overfitting problem, but also make the discard more appropriate, and prevent the important word from dropout. The result shows that the algorithm can enhance the performance of RNN and improve the accuracy rate. And our algorithm has better interpretability. In the future work, we will find other more complex input data distribution that may further optimize the dropout.
Acknowledgement
This research was financially supported by State Key Development Program of Basic Research of China (No.2013CB329604), the research was sponsored by NSFC (Grant No. 61502517, 61672020, 61662069), Project funded by China Postdoctoral Science Foundation: (2013M542560, 2015T81129).
References
[1] GE Hinton, N Srivastava, A Krizhevsky, I Sutskever, RR Salakhutdinov, Improving neural networks by preventing co-adaptation of feature detectors, Computer Science, 2012.
[2] A Krizhevsky, I Sutskever, GE Hinton, Imagenet classification with deep convolutional neural networks, International Conference on Neural Information Processing Systems, 2012.
[3] Li Deng, Abdel-Hamid, O , Dong Yu, A deep convolutional neural network using heterogeneous pooling for trading acoustic invariance with phonetic confusion, IEEE International
Conference on Acoustics, 2013.
[4] Jie Li, Xiaorui Wang, Bo Xu, Understanding the dropout strategy and analyzing its effectiveness on lvcsr, IEEE International Conference on Acoustics, 2013.
[5] Srivastava, Nitish, Hinton, Geoffrey, Krizhevsky, Alex, Dropout: A Simple Way to Prevent Neural Networks from Overfitting, Journal of Machine Learning Research, 2014.
[6] L. Wan, M. Zeiler, S. Zhang, Regularization of Neural Networks using DropConnect,
International Conference on Machine Learning, 2013.
[7] Ian J. Goodfellow, David Warde-Farley, Mehdi Mirza, Aaron Courville, Yoshua Bengio, Maxout networks, 2013.
[8] Steven J. Rennie, Vaibhava Goel, Samuel Thomas, Annealed Dropout Training Of Deep Networks, Spoken Language Technology Workshop, 2014
[9] Sida Wang, Christopher Manning, Fast dropout training, JMLR W&CP 28 (2):118–126, 2013
[10] Justin Bayer , Christian Osendorfer, Daniela Korhammer, On fast dropout and its applicability to recurrent networks, Computer Science, 2013
[12] Theodore Bluche, Christopher Kermorvant, Jerome Louradour, Where to apply dropout in recurrent neural networks for handwriting recognition?, International Conference on Document
Analysis & Recognition, 2015.
[13] Taesup Moon, Heeyoul Choi, Hoshik Lee, RnnDrop: A Novel Dropout for RNNs in ASR,
Automatic Speech Recognition & Understanding, 2015.
[14] Yarin Gal, A Theoretically Grounded Application of Dropout in Recurrent Neural Networks,
Statistics, 2015.
[15] Yarin Gal, A theoretically grounded application of dropout in recurrent neural networks.
arXiv:1512.05287, 2015.
[16] S Semeniuta, A Severyn, E Barth, Recurrent Dropout without Memory Loss, ACL, 2016.
[17] Yoshua Bengio, Patrice Simard, and Paolo Frasconi. Learning long-term dependencies with gradient descent is difficult. IEEE Transactions on Neural Networks, 5(2):157-166. 1994.
[18]Nie Y, Han Y, Huang J, et al. Attention-based encoder-decoder model for answer selection in question answering[J]. Frontiers, 18: 535-544.
[19] https://s3.amazonaws.com/text-datasets/imdb_full.pkl
[20] https://www.cs.cornell.edu/people/pabo/movie-review-data/