2018 International Conference on Communication, Network and Artificial Intelligence (CNAI 2018) ISBN: 978-1-60595-065-5
Intrusion Response Decision-making Method Based on Reinforcement Learning
Jun-nan YANG*, Hong-qi ZHANG and Chuan-fu ZHANG
Zhengzhou Information Science and Technology Institute, Zhengzhou Henan 450004, China *Corresponding author
Keywords: Reinforcement learning, Response, Adaptive, Multiple purposes, Decision-making.
Abstract. Aimed at the poor adaptability of intrusion response decision nowadays, this paper proposes an adaptive intrusion response decision method based on reinforcement learning. Based on reinforcement learning, propose an attack pattern matching layer to optimize the learning effect. Based on Softmax, the defense strategies selection method is designed to solve the exploration-utilization problem. Based on the voting mechanism, a multi-response purpose strategy evaluation method is designed. Based on the above, an adaptive intrusion response decision-making algorithm based on reinforcement learning is proposed. The simulation results show that the algorithm has good adaptability, and can make targeted responses to different abilities attackers.
Introduction
The degree of damage to network attacks has reached a new level[1]. The issue of network
security has received more and more attention. Intrusion detection and response technology has also become one of the research hotspots. Compared with intrusion detection technology widely used and achieving good results, intrusion response is not a new technology, but its development is lagging behind[2]. The purpose of the detection is to respond. The detection can only find the attack.
Only the correct response can effectively protect the security of the system. In recent years, attacks have become more and more automated and complex. Artificial responses have failed to meet the security requirements of timeliness and effectiveness. Automatic response has become an inevitable trend[3]. The most critical automatic response is to automatically respond to decision-making issues,
that is, to establish a mapping between intrusion alerts and response actions. According to the literature [5,6,7], the automatic response decision-making method is mainly divided into three categories: Static mapping method[8,9], Dynamic mapping method[4] [11] and Cost sensitive mapping
method[2, 10, 12,13, 14, 15].Although the automatic response decision-making has achieved certain
results, there are still the following deficiencies:
(1) The dynamic nature of the network requires intrusion response decisions-making to be adaptive. At present, many models reflect their adaptability by selecting and responding to the network's real-time evaluation. However, due to the complexity of the network, this method involves more known and unknown factors and has poor accuracy.
(2) Most of the intrusion response decision-making models have a single response purpose and cannot be adjusted based on the user's security needs. The real response decision-making is determined by a variety of response goals.
(3) The decision-making of defender is actually playing with the attacker. Defender should take different defensive measures against different types of attackers. At present, the decision-making model does not achieve a good response to different types of attackers.
decision-making algorithm based on reinforcement learning is designed to achieve timely and effective response.
Intrusion Response Decision-making Method
State and Action
Reinforcement learning is a set of mapping from the environment state to the action, so that the agent's actions can get the maximum cumulative return from the environment. An intrusion response is a set of mappings that establish an intrusion alert to a response. This paper uses the attack graph to describe the environment state formally. The environment state in the intrusion response consists of the network environment and the attackers. After the intrusion alarm is found, it is matched to the state node of the attack graph, and then the state node is mapped to a response measure to complete the response decision-making through reinforcement learning.
Definition 1 Attack Graph. Use a three tuple of AG= (S, V, E) to represent an attack graph.
i| 1, 2, ,
S S i …n is a collection of system state nodes. VV ii| 1, 2,…,mrepresents a set of system vulnerability nodes. E S VVSrepresents directed edge collection.
The essence of the intrusion response decision is to play against the attacker. If you can know the attacker's next attack path, attack intentions and other information, then you can make more effective response decisions. Currently, the commonly used methods for predicting information such as attack path and attack intention are game theory, causal knowledge network, and Bayesian inference. These methods can be summarized as yf x( ). x is known attacker information. f is the established model. y is the predicted attack path, attack intention and other information These methods believe that there is a causal relationship between A and B. The establishment of a model is to find out the causality. However, the current attempt to find such a causality method is not effective in automatic response decision-making. To this end, an attack pattern layer is introduced, where the attack pattern layer corresponds to known attacker information. Using the correlation between data to eliminate some of the uncertainty can optimize the learning effect.
Definition 2 Atomic Attack Pattern am v S( i j): Indicates that the attacker has used vulnerability
i
v to attack and the system has reached stateSj
Definition 3 Attack Pattern Matrix k
am : The attack mode is represented by a 0-1 matrix.
1
k ij
am indicates that the attacker has an atomic attack pattern am v S( i j). k 0
ij
am indicates that the attacker does not have atomic attack pattern am v S( i j). All the atomic attack patterns contained
in the attack pattern matrix together constitute the attacker's attack pattern.
Definition 4 Attack pattern degree N: indicate the number of atomic attack modes in the attacker's attack pattern. N can be obtained from the attack mode matrix through the following
operations.
1 1 1 2 1
2 1
1
( , ) ( , ) ( , ) 1
( , ) 1
1,1, ,1
( , ) ( , ) 1
n
m
m m n n
v S v S v S
v S N
v S v S
Definition 5 Defense Measures SetA S( )i
ak |k1, 2,…,m
: represent the selectable defense measures of Si.Definition 6 Attack pattern set AM S( )i
amk |k1, 2,…,z
: represent the attack pattern corresponding to Si.to the attack pattern. That is, if there are multiple attack patterns that match, the one with the highest attack pattern degree is preferentially selected for mapping. The mapping from the attack pattern to the response measures needs to be mapped through the response selection mechanism in Section 4.2, and then the adaptive optimization of the mapping is performed through the online learning method in Section 4.3.
1
S
2
S
4
S
3
S
5
S S6
4
a
1
a
2
a
i
S
3
a
k
a
1
am
3
am
2
am
5
am
4
am
1
S
2
S
4
S
3
S
5
S S6 4
a
1
a
2
a
i
S
3
a
5
[image:3.595.64.528.607.694.2]a
Figure 1. Layer 2 mapping Figure 2. Layer 3 mapping
Response Measures Selection Mechanism
This paper uses the Softmax method to determine the probability that an action is selected based on the level of the reward. If the return is higher, the probability of being selected is also higher. The
probability is based on the Boltzmann distribution: (a|s) exp(Q(s,a)/ ) exp(Q(s,a)/ ) a A
P
Online Learning Mechanism
Implementing responsive measures requires adaptive optimization of response decisions through online learning. Agents perform real-time assessments of the system after response actions are implemented for immediate rewards, using immediate rewards to update cumulative returns and expected cumulative returns to complete online learning. Whether evaluation methods for immediate returns and ways to update cumulative returns and expected returns reasonably determine the speed of learning and the effect of learning.
The purpose of response is the goal of action[6], and also the direction of Agent learning. The same strategy has different rewards for different purpose of response. Carver gives more comprehensive purposes of response. There are 8 kinds of: catch attackrd1, analyze attackrd2, mask attackrd3, maximize confidentiallyrd4, maximize data integrityrd5, minimize costrd6, recover gracefullyrd7 and sustain servicerd8. In order to make the decision-making method meet different security needs, this paper gives a quantitative method for each response based on the purpose of Carver's response.
Catch attack: The goal is to identify and catch the attacker so that future action can be taken against the attacker. The quantitative method is shown in table 1.
Table 1. Catch Attack Immediate Return Rsa1s'
1 '
a s s
R description evaluation
1 Can identify identity information and have sufficient evidence 1
2 Can identify identity information and have a small amount of evidence 0.7
3 Can identify identity information but do not have evidence 0.4
4 Only a small amount of information to guess identity 0.1
5 No identity information and evidence 0
Table 2. Analyze Attack Immediate Return Rsa2s'
2 '
a s s
R description evaluation
1 Fully understand attack methods, paths, and intentions 1
2 A certain degree of mastery of attack methods, paths, and intentions 0.7
3 Grasp some attack methods and paths 0.4
4 Just discovered that it was attacked, nothing else 0.1
Mask attack: The goal is mask the attack so that service is not disrupted and the attack is terminated as soon as possible. The quantitative method is shown in table 3.
Table 3. Mask Attack Immediate Return 3
' a s s R 3 ' a s s
R description evaluation
1 Terminate the attack completely 1
2 Make the attack within controllable range 0.7
3 Partially stop the attack but the service is destroyed 0.4
4 Small part of the attack is terminated and the service is severely damaged 0.1
5 No effect 0
Maximize confidentially: The goal is to prevent the disclosure of information. The definition of confidentiality is shown in Table 4..
Table 4. Confidentiality Definition Wkc
c k
W description evaluation
1 Information leakage can cause extremely serious damage 1
2 Information leakage hazards are within control 0.7
3 Information leakage causes some damage 0.4
4 Information can be leaked when needed 0.1
5 Information is not confidential 0
Immediate return 4 '
1
1 ( )/
n
a c c
s s k k
k
R A W n
, Where ck
A is 0 or 1.0 represents no leakage of information k,
1 represents leakage.
Maximize data integrity: The goal is to prevent the changing of files on the system so that their integrity is maintained. The definition of completeness is shown in Table 5..
Table 5. Integrity Definitions Wki
i k
W description evaluation
1 Assets tampered with can cause extremely serious damage 1
2 Assets tampered with harm are within control 0.7
3 Assets have been transformed into certain hazards 0.4
4 Assets are allowed to be tampered in part 0.1
5 Assets have been tampered with without any impact 0
Immediate return 5 '
1
1 ( )/
n
a i i
s s k k
k
R A W n
, Where ck
A is 0 or 1. 0 represents that asset k has not been
tampered, and 1 represents tampered.
Recover gracefully: The goal is not to stop the intrusion but to retain the capability to recover gracefully from any attack with minimal effort. Recovery system returns immediately
6 ' 1 ( )/ n a r
s s k k
k
R A W n
, Where rk
A is 0 or 1. 0 represents recovery failure, 1 represents successful
recovery.Wk is the value of the asset.
Sustain service: The goal is sustain service during any attack. Maintain service immediate return
7 ' 1 ( )/ m a s
s s k k
k
R A W m
, Where sk
A is 0 or 1. 0 indicates that the service cannot be used normally, and 1
the service.
[image:5.595.59.541.424.784.2]Minimize cost: The goal is to minimize the cost of implementing a response in terms of resources. The quantitative method is shown in table 6.
Table 6. Minimum Cost Immediate Return 8
'
a s s
R
8 '
a s s
R description evaluation
1 The response occupies more system resources during the effective time -1
2 The response takes up less system resources during the effective time -0.7
3 The operating cost is very small -0.4
4 No response, no cost 0
In order to be able to quickly learn after changing the purpose of the response, the cumulative return and the expected cumulative return are independently updated for each response purpose. The cumulative return update process is: '
'
( ', ')
max
i ai i
s s a
Q R Q s a
The expected cumulative return update process is: Q s ai( , )Q s ai( , )[QiQ s ai( , )]
When humans make decisions, they do not choose only one response goal. A suitable response measure is to consider the results of multiple goals. The agent adopts a voting mechanism when making response decisions. Each response purpose has a certain weight. This weight is set by the administrator and represents the right to speak when voting for each response purpose. The expected cumulative return for each response measure is voted by the expected cumulative return for each response purpose, then the expected cumulative return for each response measure is:
8 1
( , ) i i( , )
i
vote s a Q s a
Intrusion Response Decision-making Algorithm
The intrusion response system is in the receiving alarm state. After the alarm is received, the response measures are selected, and then the network system is notified of the response measures. After the response measures are implemented, use its responsiveness to conduct online learning to optimize response plans. The specific algorithm is as follows.
Algorithm 1 Response Decision Algorithm Based on Reinforcement Learning
Input: environment E; Attack graph; Reward discount ; Update step ; Attack pattern AM; Temperature
Output: Response action a
BEGIN
1.initialQ am a( , ) 2.when(1)
3. s pattern alert to state alert _ _ _ ( )
4. amkpattern state to am s_ _ _ ( )
5. 8
1
( k, ) i i( k, ), ( )
i
vote am a Q am a a A s
6. ( | ) exp( ( , )/ )/ exp( ( , )/ )
t
k k k
a A
P a am vote am a vote am a
7. am(amk)// Selection of actions based on the probability obtained by Softmax
8. Output a;// Inform the system of response measures
9. 's = State after execution of action a in E
10. Raiss'(i1,2,...,8)immediate returns produced by performing action a in E
11. amk'pattern state to am s_ _ _ ( ')
12. For i=1,2,…,8 do
13. ' '
'
( , ) max ( , ')
i k ai i k s s
a
Q am a R Q am a
14. Q am ai( k, )Q am ai( k, )[Q am ai( k, )Q am ai( k, )]
15. End for;
16. s s am ', kamk'
END
Experiment
Simulation Scene
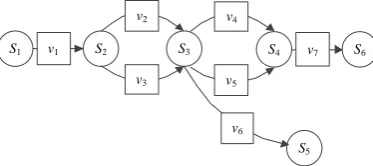
In order to verify the proposed decision method, a network scenario as shown in Figure 3 was deployed for simulation experiments. In this scenario, the access rules established by the firewall are shown in Table 7.
[image:6.595.185.413.186.280.2]Figure 3 Simulation scenario
Table 7. Firewall Configuration
Source host Destination host Access strategy
All Web server Allow
Web server Application server Allow
Application server Database server Allow
The vulnerability information of this experimental scenario design is shown in the Table 8.
According to system vulnerability information, using the method [18] to generate an attack graph is shown in Figure 4.
S2 S3
S1
v2
v3
v1 S4 S6
v4
v5
v7
v6
S5
Figure 4. Simulation scene attack graph
Table 8. Vulnerability information
Server number CVE description
Web v1 CVE-2016-3338 Get root privilege
Application
2
v CVE-2016-3387 Get user privilege
3
v CVE-2017-0893 Get user privilege
4
v CVE-2016-3343 Get root privilege
5
v CVE-2017-9758 Get root privilege
6
v CVE-2016-1261 DoS attacks
Database v7 CVE-2016-2555 Get root privilege
This experiment sets two types of attackers: high-capacity and low-capacity. High- capacity attackers can exploit all vulnerabilities in the network to initiate attacks. Because the attack cost of
3
v and v5 is small and destructive, a high-capacity attacker will preferentially select these two vulnerabilities, but a low-powered attacker can only use v1, v2, v4, v7 with the limitation of the ability.
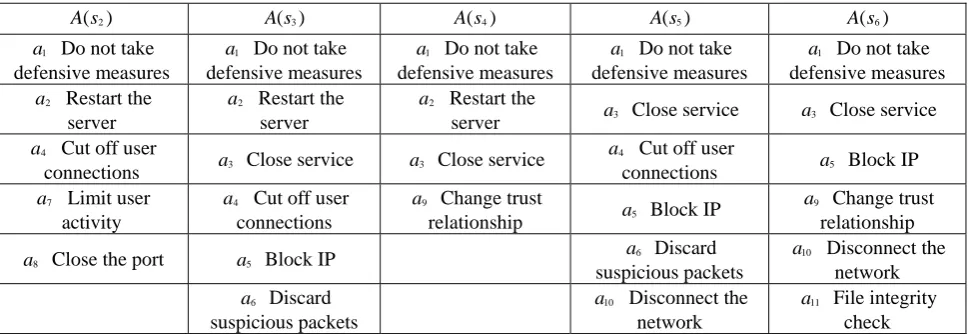
[image:6.595.203.390.447.530.2]Table 9. Defense measures
2
( )
A s A s( )3 A s( )4 A s( )5 A s( )6
1
a Do not take
defensive measures
1
a Do not take
defensive measures
1
a Do not take
defensive measures
1
a Do not take
defensive measures
1
a Do not take
defensive measures
2
a Restart the
server
2
a Restart the
server
2
a Restart the
server a3 Close service a3 Close service
4
a Cut off user
connections a3 Close service a3 Close service
4
a Cut off user
connections a5 Block IP
7
a Limit user
activity
4
a Cut off user
connections
9
a Change trust
relationship a5 Block IP
9
a Change trust
relationship
8
a Close the port a5 Block IP
6
a Discard
suspicious packets
10
a Disconnect the
network
6
a Discard
suspicious packets
10
a Disconnect the
network
11
a File integrity
check
Experimental Design
The experiment mainly tests three aspects: the effectiveness of the pattern matching layer, the impact of different response purposes on the decision, and the adaptability of the algorithm.
Experimental parameters are shown in Table 10.
Table 10. Experimental parameters
0.3 0.6 0.5 1.1 0.6 0.3
(1) Verify the effect of the pattern matching layer.
The effect of the pattern matching layer is verified by comparison. High-capacity and low-capacity attackers alternately launched 200 attacks on the system. The purpose of the attack is to obtain the root privileges of the database server. The number of memory attacks N is taken as 0 and the number of memory attacks N is taken as 1 to learn and respond respectively, and the actual response returns obtained by the system are compared. In the experiment, the voting weight of the response to the target is shown in Table 11.
Table 11. Voting weight
1
rd rd2 rd3 rd4 rd5 rd6 rd7 rd8
0 0 0 0.6 0 0.4 0 0
(2) Verification of the adaptability of the algorithm.
Use a high capacity attacker to launch 200 attacks. The purpose of the first 100 attacks is to get the database server information. The last 100 attacks aim to launch DoS attacks and paralyze network services. Statistical response measures verify whether the algorithm can adjust the attacker's change. The voting weight of the response target is shown in table 12.
Table 12. Voting weight
1
rd rd2 rd3 rd4 rd5 rd6 rd7 rd8
0.4 0 0 0 0 0.3 0 0.3
Experimental Results and Analysis
(1)The real average value of the Cumulative Return in the state s3 response is shown in Figure 5. From the figure, it can be seen that both N=0 and N=1 reach a stable state at the same time after a short period of learning. The difference is that the actual cumulative income of N=1 in the steady state is significantly higher than N=0. The pattern matching layer can effectively optimize the learning effect of the algorithm.
Figure 5. States3Response to Cumulative Return Average
Figure 6. Response to different ability attackers
From the figure, we can see that when N=0, the attack response measures for the high and low ability attackers are almost the same, indicating that they can not respond differently to different attackers, and the response measures to different attackers when N=1 are different, indicating that it has made different responses to different attack patterns.
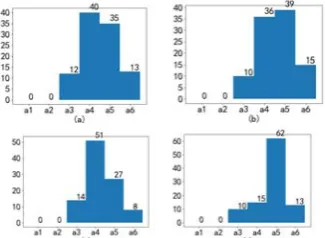
(2) From Figure 7(a), we can see the overall distribution of response corresponding to the different attack purposes. The purpose of response is to maintain services, track attacks and minimize costs. The first 100 attacks aim to obtain database ROOT permissions that do not pose a danger to system services. Combining tracking attacks and minimizing costs, it is reasonable to know that the system does not take defensive measures through learning choices. The last 100 attacks aim to launch a DoS attack. In order to avoid service paralysis, combined with tracing attack and minimizing cost, it is reasonable for the system to discard suspicious packets through learning.
Figure 7(b) is a selected area of Figure 7(a). From Figure 7(b), it can be seen that the system can respond in time when the attacker's attack purpose changes, and can select new effective response measures in a short time through learning. From Figure 7(c), it can be seen that when an attacker changes the target of an attack, although the average income has declined, the average return is quickly raised to a higher level by learning. It is known that the algorithm has good adaptability.
[image:8.595.82.512.601.711.2](a) (b) (c)
Figure 7. Response measures for different response purposes
Conclusions
pattern matching layer, reinforcement learning is changed from a traditional two-layer mapping to a three-layer mapping. Measure the attacker's pattern to determine the attacker's next attack and make a targeted response to optimize the learning effect. A multi-objective response strategy evaluation method is designed based on voting mechanism, so that decision making can satisfy different users' needs for different response purposes. Finally, a simulation experiment verifies the advanced nature of the algorithm.
References
[1] 2017 Iinternet SecurityThreat Report [EB/OL].[2017-11-12] http://ww w .symantec.com
[2] Iafarov R, Gad R, Kappes M. Improving Attack Mitigation with a Cost-sensitive and Adaptive Intrusion Response System[C]// ICN 2015 : The Fourteenth International Conference on Networks. 2015.
[3] Anwar S, Zain J M, Zolkipli M F, et al. From Intrusion Detection to an Intrusion Response System: Fundamentals, Requirements, and Future Directions[J]. Algorithms, 2017, 2017(10).
[4] Carver, Curtis A., Jr. Adaptive Agent-Based Intrusion Response[J]. 2001.
[5] Stakhanova N, Basu S, Wong J. A taxonomy of intrusion response systems[M]. Inderscience Publishers, 2007..
[6] Mu C, Huang H, Tian S, et al. A Survey of Intrusion Response Decision-Making Techniques of Automated Intrusion Response Systems[J]. Journal of Computer Research and Development, 2008, 45(8):1290-1298.
[7] Inayat Z, Gani A, Anuar N B, et al. Intrusion response systems[J]. Journal of Network & Computer Applications, 2016, 62(C):53-74.
[8] Yang W. Automated Response Using System-Call Delay[J]. Computer Engineering & Applications, 2003.
[9] Uppuluri P, Sekar R. Experiences with Specification-Based Intrusion Detection[C]// International Symposium on Recent Advances in Intrusion Detection. Springer-Verlag, 2001:172-189.
[10] Shi J, Lu Y, Xie L. Dynamic Intrusion Response Based on Game Theory[J]. Journal of Computer Research and Development, 2008, 45(5):747-757.
[11] Dan S, Holliday H, Smith R, et al. Cooperative Intrusion Traceback and Response Architecture (CITRA)[C]// DARPA Information Survivability Conference & Exposition II, 2001. DISCEX '01. Proceedings. IEEE, 2001:56-68 vol.1.
[12] Nadeem A, Howarth MP. An intrusion detection & adaptive response mechan for MANETs. Ad Hoc Netw 2014;13:368–80.
[13] Sendi A S, Louafi H, He W, et al. Dynamic Optimal Countermeasure Selection for Intrusion Response System[J]. IEEE Transactions on Dependable & Secure Computing, 2016, PP(99):1-1
[14] Stakhanova N, Basu S, Wong J. A Cost-Sensitive Model for Preemptive Intrusion Response Systems[C]// International Conference on Advanced NETWORKING and Applications. IEEE Computer Society, 2007:428-435. 2007
[15] Mu C, Li Y. An intrusion response decision-making model based on hierarchical task network planning. Expert Syst Appl 2010;37:2465–72.