An Actor-Based Middleware for Crowd-Sourced
Services
Ahmed
Abdel
Moamen
1,
Nadeem
Jamali
21Department of Computer Science, Prairie View A&M University, Prairie View, TX, USA
2Department of Computer Science, University of Saskatchewan, Saskatoon, SK, Canada
Abstract
The growing ubiquity and variety of personal connected computational devices – each with a number of sensors – has created the opportunity for a wide range of crowd-sourced services. A busy professional could find a restaurant to go to for a quick lunch based on information available from smartphones of other people already there. Sensors on diners’ smartphones could detect whether their owners are eating, waiting to be seated, or even heading to a restaurant.
Although the programming required for offering a new service of this sort is significant if done from scratch, we identify core communication mechanisms underlying such services, and implement them as part of a middleware, CSSWare. Service designers can then launch novel services over CSSWare by plugging in small pieces of service-specific code.
This paper describes the multi-origin communication mechanism which we believe to underlie many crowd-sourced services. It presents our design and prototype Actor-based implementation of CSSWare, a middleware for crowd-sourced services. We present source code for two realistic crowd-sourced services to illustrate the ease with which new services can be specified and launched. Finally, we present our experimental results demonstrating scalability, performance and data-contributor side energy efficiency of the approach.
Receivedon 21 December 2016;acceptedon 06 July 2017;publishedon13 September 2017
Keywords: CSSWare, middleware, crowd-sourced services, programmability, Actors
Copyright© 2017 Ahmed Abdel Moamen and Nadeem Jamali, licensedto EAI. Thisisanopen access articledistributed under the terms of the Creative Commons Attribution license (http://creativecommons.org/licenses/by/3.0/), whichpermitsunlimiteduse,distributionandreproductioninanymediumsolongastheoriginalworkisproperlycited. doi:10.4108/eai.13-9-2017.153070
1. Introduction
With the growing ubiquity of personal computational devices, such as smartphones and wearable devices, has come the ubiquity of sensors on these devices, as well as the potential for triggering actions virtually anywhere. This opens up an opportunity to offer a variety of services which rely on the state of the context in which devices are located, such as a person or a group of people carrying the devices, their geographical location, etc. We broadly refer to these as crowd-sourced services. Consider a restaurant recommendation service which samples data collected about experiences of clients at a number of restaurants in a neighborhood and ranks them according to the service experienced
∗
Corresponding author. Email:jamali@cs.usask.ca
by these clients. The source of the data could be sensor feeds on clients’ smartphones, used to guess whether they are waiting, seated, enjoying their meals, paying or leaving. Consider other services, such as one for recommending hospital emergency services to people. Such applications have a pattern of communication in which contextual data offered by a number of contributors becomes the basis for a service. Another class of applications with a similar pattern of communication is social media applications, such as Twitter, where crowds contribute to collective messages by contributing free-form short messages, which are then available to others in a digestible form.
We refer to this pattern of communication as
multi-origin communication. This is the type of communication
where a group of senders contribute to a group message, without any of them necessarilytaking the lead. Contrast
1
on
Mobile Communications and Applications
Research Article
this with a single-origin (multi-sender) communication [1], which is initiated by a single party which solicits interest from other parties to join together in sending a particular message. An example of the latter would be a workplace petition drafted by an individual and presented to others to sign. In multi-origin (implicitly also multi-sender) communication, there is no single party which needs to takes the lead. In other words, multiple parties may autonomously launch messages which are then aggregated in order to create a group message.
It turns out that unlike single-origin multi-sender messages, multi-origin messages require a setup in advance. Consider a public square where a number of citizens spontaneously begin to gather to party or protest. In this context, the physical space of the square serves as part of a setup which allows mutual observation, an opportunity to join in or leave, to endorse, reject or refine the collective message or experience over time. The closest electronic equivalent of such a physical space would be social media services such as Twitter, which allow people to observe others’ tweets in an aggregate form (which is quite natural in physical space, but requires filtering and counting mechanisms in electronic space), endorse them by adopting hashtags, improve upon the message, and so on. In general, for a crowd (or mass) -conceived communication to happen, there is a need for a mechanism to be in place to coordinate the generation of the group message by soliciting (or more generally instigating) individual messages, receiving them, and then aggregating them into a group message. The solicitation lays out the rules to be followed for selection of the potential senders, receiving their messages, and aggregating them. For example, imagine a multi-stage communication with the first solicitation being to invite nominations for topics to have the message on, followed by a vote to select the topic, followed by a solicitation of messages, followed by a final vote to agree on an aggregate message. The communication could be one-time, periodic, or continual. There may or may not be a time-out for responding to the solicitation. All these aspects would be laid out in the original solicitation.
Multi-origin communication serves as the core mech-anism underlying many such crowd-sourced services [2]. In other words, key coordination mechanisms can be provided in a platform over which a class of crowd-sourced services could be implemented relatively easily. Here, we present our efforts in realizing that potential by implementing CSSWare, a middleware for crowd-sourced services. Having CSSWare as a platform, all that a service designer needs to do to launch a new service is to identify a constituency of potential con-tributors, and to provide a few lines of service-specific code for specifying the nature of contributions and for aggregating them when they arrive. Additionally, we
try to (opportunistically) optimize the data contributor side energy consumption of crowd-sourced services for the situation where a number of services are being contributed to simultaneously. An optimizing sampling scheduler schedules the sampling of sensors based on the sensing requirements received from services run-ning concurrently. The scheduler looks for opportuni-ties for different services to share sensor samples, and lowers the effective sampling rate for each sensor when possible.
The rest of paper is organized as follows: Section 2 presents the related work. Section 3 describes our general approach to supporting crowd-sourced services using multi-origin communication. Section 4 and 5 present our design and prototype implementation respectively. Section 6 evaluates the approach in two ways. First, it illustrates the ease with which new services can be implemented over our platform. Second, it presents experimental results showing scalability, performance and energy efficiency of the approach. Finally, Section7concludes the paper.
2. Related Work
There have been a number of projects – both in academia and industry – involving crowd-sourced services. The term crowd-sourced can refer to two types of services: participatory sensing services and crowdsensing services. Participatory sensing involves explicit participation of human beings in possession of mobile devices, whereas crowdsensing relies on sensor feeds automatically flowing from devices to servers. We first present some representative examples of both these types of crowd-sourced services, and then discuss some existing frameworks for enabling such services.
2.1. Crowd-Sourced Services
Some of the best examples of participatory sensing services can be found in services aimed at assisting automobile drivers. Waze [3] is one of the largest community-orientated mobile travel applications with users volunteering information about their driving experience in real time, by reporting on congestions, delays, and gasoline prices. These reports then become the basis for information displayed on other drivers’ maps (on their mobile devices), to help them make routing decisions.
Similarly, TrafficPulse [4] combines sensor data from mobile devices with real-time traveler reports from frequent travelers, and then offers this information to other drivers in an aggregate form.
to overcome challenges created by both the inadequacy of maps and the change in landscape because of the devastation.
CrowdHelp [6] uses smartphones to collect direct feedback from mobile users about their medical condition, in combination with data coming from sensors in smartphones. This information is used to enable swift response to emergencies. For example, when CrowdHelp is used for emergency reporting, mobile users submit information relevant to an event (such as the number of injured people and their state) to a central server. This information is collected and sent to the nearest health care facility capable of treating the injured.
Among crowdsensing services, the real-time traffic information displayed on Google Maps is arguably the most widely used one. The service relies on location data voluntarily made available by users of Google’s services, which is then aggregated and then visualized on Google’s Maps to show traffic flow. Since Google’s acquisition of Waze in 2012, Waze’s participatory sensing service has now been combined with Google’s crowdsensing service for providing real-time traffic flow information.
Crowdsensing has also been used by Uga et al. [7] in an earthquake warning system, which uses data from accelerometers present in many modern mobile devices to detect seismic vibrations. Devices send reports of likely seismic activity to a server which then aggregates the reports received to send out warnings.
2.2. Mobile Crowd-Sourced Frameworks
Our work is more closely related to research focused on supporting crowd-sourced applications. Existing efforts have taken different approaches to supporting such applications, focusing on concerns from programmabil-ity (e.g., Medusa [8] and AutoMan [9]), to privacy (e.g., AnonySense [10]), to participatory crowd-sensing (e.g., CDAS [11]), and efficient sensor data collection (e.g., MECA [12]). We discuss these frameworks below.
Medusa [8] is a programming framework for crowd-sourced applications. A task (such as video documentation or citizen journalism) is launched by a requester, andworkersare solicited through Amazon’s Mechanical Turk (AMT) service.1 These workers – volunteering smartphone users – then provide raw or processed data to be used as part of a social or technical experiment. An XML-based programming language, MedScript, is used to specify the required task as a series of several stages, from the initial recruitment
1Mechanical Turk is an online human hiring system which acts
as an intermediary between employers (requesters) and employees (workers or turkers) to perform short-term computational tasks. https://www.mturk.com/mturk/
of volunteer workers, to the workers’ (say, for a video documentation task) recording videos on their smartphones, summarizing them, and then sending them back. The stages can involve actions selectable from a library of executables, which are downloaded to mobile devices from a cloud server. Because Medusa requires that tasks pick from a limited set of activities, it suffers from limited programmability and generality, and is not applicable to a large class of crowd-sourced services.
AutoMan [9] is a programming platform for enabling a function-call like mechanism for requesting human-beings to carry out tasks involving vision, motion, natural language understanding, etc. The platform supports scheduling, pricing and quality control. A programmer’s interface to AutoMan is a set of function calls, implemented as an embedded domain-specific language for the Scala programming language. The platform also uses Amazon’s Mechanical Turk for hiring workers to perform these short-term human-based assignments. Although the way AutoMan supports interactions with people is interesting, its scope is limited to that function. For instance, a similar approach could be used along with our middleware for applications requiring deliberate human input.
AnonySense [10] is another framework for collecting and processing sensor data, which pays particular attention to privacy concerns. AnonySense allows a requester to launch one of a selected group of applications with their parameters. The application then distributes sensing tasks across anonymous participating mobile devices (referred to as carriers), and finally aggregates the reports received from the carriers. Achieving anonymity relies on separating sensor data from identifying features (such as homes or workplaces in GPS traces) to obscure individual identities. Similarly to Medusa, AnonySense has limitations in programmability and generality because of its limited focus on collection of sensor data and in-network processing.
CDAS [11] is an example of participatory crowd-sensing frameworks. It enables deployment of various crowd-sensing applications which require human involvement for simple verification tasks to deliver high accuracy services. Similar to CDAS, MOSDEN [13] is a collaborative mobile sensing framework that operates on smartphones to capture and share sensed data between multiple distributed applications and users.
The MECA (Mobile Edge Capture and Analysis) middleware for social sensing applications [12] focuses on efficient data collection from mobile devices. It uses a multi-layer architecture to take advantage of similarities in the data required for different applications to lower the demand on devices on which data is being collected. MECA’s focus is limited to a narrow class of applications, and
3 Mobile Communications and ApplicationsEAI Endorsed Transactions on
n
coordinator
destination
aggr
a
1a
2
a
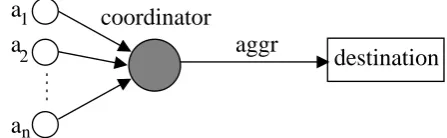
Figure 1. Multi-Origin Communication
does not address wider programmability challenges. Furthermore, MECA – like other similar frameworks – uses the smartphone as a dumb data generator, offloading all processing to the server layer. This increases communication cost and does not allow applications to take advantage of data collected while the mobile device is not connected.
In summary, existing frameworks for crowd-sourced applications focus on narrow application areas or specific concerns, making it difficult to utilize them for a wider class of services. Also, none of them support concurrent execution of multiple services from within one service platform, which precludes taking advantage of opportunities to optimize for shared sensing requirements.
3. Supporting Crowd-Sourced Services
It turns out that a large class of crowd-sourced services exhibit a similar pattern of interaction, where members
of a crowd contribute bits of information from their
respective contexts, which are then aggregated to create useful information for clients. We have identified this pattern of interaction as multi-origin (multi-sender)
communication, which involves aggregation of the
messages received from a group of senders (referred here to as the constituency) into a group messageto be sent on behalf of the group to one or more intended recipients. This is illustrated in Figure1, where senders
a1 through an autonomously send messages with the intention of them being sent to a destination in aggregate form.
Most examples of crowd-sourced services fit the
continual type of multi-origin communication, where
members of the constituency send messages on a continual basis rather than just once; this would be useful for a service provided over the web or through a mobile application where site visitors or application users seek up-to-date information (say) on restaurant waiting times in a neighborhood. The one-off type of interaction soliciting only one message from each member of the constituency is a special case of this general case; this would be the type of communication used to serve one-time requests, such as to hold a census or an election, or to satisfy a one-off request to recommend a restaurant with a short waiting time. For some services, such as the one for restaurant
recommendations, the choice between the continual and the one-offtype of communication would depend on the frequency of requests, the number of potential senders of messages, etc. For instance, it would not be useful to be maintaining up-to-date information about all restaurants when there are very few requests for recommendations; however, it would be wasteful to solicit one-off communications if there were frequent requests.
From here on, we will refer to continual multi-origin communication as simply multi-origin communication.
3.1. Multi-Origin Communication
To be precise in our presentation of multi-origin com-munication, we specify it in terms of the Actor model [14]. Actors are autonomous concurrently executing primitive agents (i.e., active objects) which communi-cate using asynchronous messages.2 We represent the different parties involved in a multi-origin tion using actors, and define the required communica-tion in terms of asynchronous actor messages.
The requester of a multi-origin communication makes a function call in order to launch the communication. The call passes two parameters, the first specifying the potential contributors – the constituency – to be invited to participate in the communication, and the second specifying an aggregation method. As illustrated in Figure 2, an invocation of this function results in the creation of a new coordinator actor capable of coordinating the communication, which is next told to invite the constituency to participate. The coordinator then sends invitations to the members of the constituency (the contributors) to send their messages; when applicable, it also sends them parameters advising on how to construct their contributions (such as by tapping into a set of sensors, or soliciting input from the user), how often to send them (once or periodically, how frequently), etc.
As the contributors send their messages, the messages are aggregated by the coordinator as specified in its own behavior, to generate group messages on behalf of the contributors. When a contributor’s message arrives at the coordinator, it checks whether the message warrants an update, or whether the interval for which it was to collect messages has passed. In both cases, it forwards an aggregate of messages received since the beginning of the interval to the requester. For example, a restaurant recommendation service available over the web would collect periodically sent updates from
2Actors are emerging as the model of choice for large-scale
requester
messages aggr
create
coordinator
constituency invite
CommSetup()
Figure 2. Multi-Origin Communication Setup
various restaurants and offer up-to-date information to site visitors.
Figure 3 illustrates the execution of a multi-origin communication using an actor event diagram [14].
A communication is initiated by the requester by calling the function
Comm-Setup(coordClass,constit,updateCond,interval),
where coordClass is the desired behavior of the coordinator, constit is the list of prospective contributors, updateCond specifies the condition in which the requester should be immediately updated,3
and interval specifies the intervals at which the
coordinator would be notified by the clock.
Once the coordinator has been created, it broadcasts an announcement to contributors contrib1 through
contribnand then waits to receive messages from them.
Contributors either send updates periodically or when they observe an interesting event (such as a change in the level of activity in a restaurant, for example).
Also, the clock actor periodically (i.e., after every
intervalperiod of time) notifies the coordinator of the
passage of an interval, at which time the coordinator computes a new aggregate.
4. CSSWare Design
Our design of the CSSWare middleware builds on the mechanism for multi-origin communication described in the previous section. As illustrated in Figure 4, the sensing crowd becomes the constituency whose input is solicited. The service continually aggregates the feeds arriving from the crowd to create up-to-date custom views for various types of clients. For example, if the service were for recommending restaurants, one interface could be for prospective diners, another for the restaurant managers making real-time staffing plans, yet another could be for a vehicular routing system interested in improving downtown traffic flow at lunch time.
Figure 5 illustrates how the distributed run-time system for the middleware is organized with parts executing on the service platform, on devices of members of the constituency, as well as client devices.
3This should also lead to resetting of the interval with the clock; this
is not shown in the event diagram to avoid making it too crowded.
interval
aggr
event
event cond
yes
yes
no
aggr
aggr no
msg
cond
no
aggr yes aggr
requester clock
interval
P1
P2
create
coordinator
cond
contrib contrib
msg
msg
event
. . . . contrib ...
interval
2
1 n
CommSetup
invite
Figure 3. Continual Multi-Origin Communication
...
service
. . . . .
sensing crowd
....
interface
interface
clients
clients
...
Figure 4. Crowd-Sourced Service
In the rest of this section, we discuss these three parts separately.
4.1. Service Platform Side
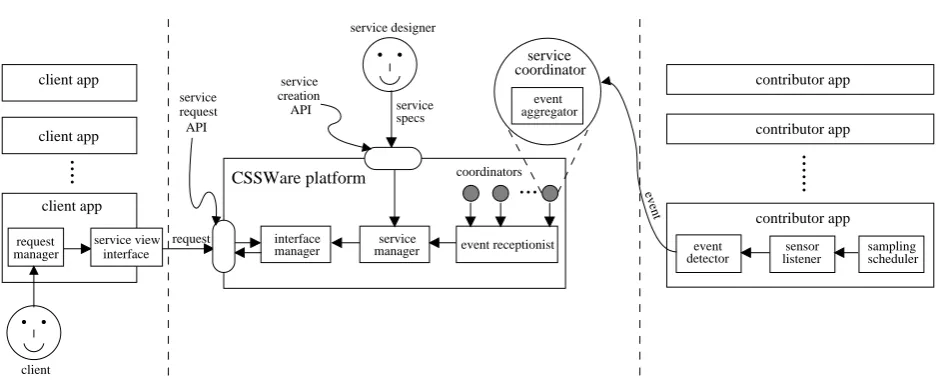
The service designer uses the service creation API to create and launch a new crowd-sourced service. A set of parameters stating service specifications is passed through the API. These specifications identify the contributors to be invited to participate in the service, the aggregation method to be used, as well as a description of the feeds solicited from the contributors in terms of specific events of interest, such as arrival at a restaurant, being seated at the table, etc.
To launch a new service, the service manager (see server in Figure 5) creates a new service coordinator to coordinate the communication between the contributors and the CSSWare platform, which is capable of coordinating the communication between
5 Mobile Communications and ApplicationsEAI Endorsed Transactions on
CSSWare platform
...
event receptionist service
specs
managerservice
request
client app
....
coordinatorsinterface service view request
manager
aggregatorevent
coordinatorservice
client app client app
interface manager creation API service
API request service
service designer
client
detector
contributor app
...
contributor app contributor app
event sensor sampling
listener scheduler
event
Figure 5. System Architecture
the contributors and the CSSWare platform. Next, it sends invitations to the contributors to send their events – when one is detected – to the coordinator. It also sends them parameters advising on how to detect events, construct their messages, and how often to send them (once or periodically, how frequently, etc.).
Contributor events received by a service coordinator are handled by its event aggregator, which in turn reports the events in aggregate form to the CSSWare platform’s event receptionist. The aggregated events are then passed on to the service manager, which processes them to update the service’s state, which is forwarded to the service interface manager to deliver appropriate views requested by clients through custom interfaces.
4.2. Contributor Side
To launch a service, the platform’s service manager sends invitations to contributors to participate in the service. It also sends them parameters advising on how to detect events and construct their messages (i.e., sensing parameters). Event detection is carried out by dedicated event detection actors, who generate event feeds using relevant sensor feeds, which are then sent to the service coordinator.
An optimizing sampling scheduler schedules the sampling of each sensor based on the sensing requirements received from the service coordinator for each service being served at the time.
Sampling Scheduler
The scheduler attempts to optimize the sampling rate of each sensor exploiting opportunities for different services to share sensor samples when possible.
On receiving a new request, the scheduler checks if the current sampling rate – sufficient for serving all currently served requests – can also satisfy the new sampling rate being requested. To ensure that the data
samples are equidistant in time, the scheduler needs to compute theleast common multiple(LCM) of the sensor’s current sampling rate and the rate being requested, to determine a rate that would serve both existing requests and the new request. This, however, presents a challenge.
Because of the way LCM is defined,4 it is only in special circumstances that LCM(x, y) is lower than the sum of x and y, meaning that using the LCM of two requested sampling rates would rarely be better than serving them independently. Particularly, the LCM of two numbers is lower than their sum when the numbers are equal or one is the multiple of the other. For this reason, finding a covering sampling rate is most beneficial when the sampling rates requested by applications are in such a relationship among themselves. It turns out that this is possible to achieve by setting up preferred sampling rates for applications to pick from – as the Android Sensor API already does by offering 5Hz, 16Hz, 50Hz, 100Hz with designated purposes of UI, normal, game, highest, respectively – so that they are of the formx∗2n, making the LCM of any two requested sampling rates simply the larger of the two. In our prototype, we use 10Hz, 20Hz, 40Hz, 80Hz; however, we can easily add a lower rate of 5Hz, or change the scheme to begin with 12.5Hzso that 100Hz
can be served.
The sensor listener is responsible for sampling sensor data according to the sampling rate received from the sampling scheduler. However, because sensor samples are for all apps, there is afilterto extract the required samples to be sent to the different apps.
Algorithm1shows the steps taken by the scheduler to find the optimal sampling rate for sensing requests
4LCM(x, y) = (x∗y)/GCD(x, y); and LCM(x, y, z) =
being served at the time. Each sensing request specifies the sensor s to be sampled and the rate r at which it should be sampled. When a new request is received, the scheduler checks if the sensor is already scheduled to serve other requests. If not, it sets it up to be schedule from then on. If the sensor is already being scheduled to serve existing requests, the scheduler determines the rate of sampling which will be sufficient for also serving the new request. Assuming that requests are limited to the preferred sampling rates, this simply requires comparing the new request with the existing sampling rate, and picking the larger of the two. In general, it would require a more complex process computing LCMs of different numbers of requests to be served, and checking if serving them independently would be more efficient than serving them from a covering rate. Because of the computational complexity of this method, as well as the low likelihood that the LCM of requests would be lower than their sum – let alone the LCM of all requests – our implementation and experiments assume that requests pick from the preferred sampling rates of 10Hz, 20Hz, 40Hz and 80Hz.
4.3. Client Side
A service can have various types of clients subscribed to different views of the service’s state, each provided by a custom interface. When a client requests subscription to a particular type of view, the request manager inside the client app constructs a custom view subscription request. This request is passed on to the service view interface, which is transmitted through the service request API of the CSSWare platform (see Figure5). The platform adds the client to a list of subscribers to that view of the service, and begins sending it all updates.
5. CSSWare Implementation
We have prototyped CSSWare as an actor system. The implementation has two parts: a server implementing a crowd-sourced service platform (about 7,500 lines of code), and a mobile app supporting both client and contributor functionalities (about 4,600 lines of code).
As shown in Figure 6, our implementation is built using the CyberOrgs [16] extension of Actor Architecture (AA) [17], a Java library and runtime system for distributed actor systems. Crowd-sourced services run over the CSSWare platform, which runs over the CyberOrgs runtime system.
For the client and contributor side, we have ported AA to Android OS for supporting the mobile app.
5.1. Service Platform Side
To launch a new service, first, the requested service’s meta data (i.e., its title and description) is added
Services
....
Operating System
CyberOrgs Platform
CSSWare Platform
Figure 6. System Design
to the list of published services, which lists active services visible to contributors. Next, the service manager creates a service actor which invites potential contributors to send their events to the service’s coordinator. It also sends them parameters advising on how to construct their contribution messages. After inviting the contributors, a new service view is created in the service request API in order to serve clients’ requests.
As contributors to a service detect and send events, the events are aggregated by the coordinator and reported to the service manager through the event receptionist (see Figure5). The service manager collects aggregated events until a sufficient number of them have been received (as determined by a sufficiency condition provided by the service designer in the form of a function) and then updates the service state, revising the custom service views available to the clients.
5.2. Contributor Side
For the contributor (and client) side, we have ported CyberOrgs to Android OS, and implemented a self-contained application over it which runs on the Android OS (ver. 5.1). The current implementation supports contributions based on feeds from the GPS, accelerometer, microphone, magnetometer, gyroscope, pressure, humidity, temperature and light sensors. A set of high-level sensor events has been pre-implemented in terms of these (low-level) sensor events – as executable specifications – which a service designer can draw from and customize by providing parameters. These high-level events form the basis for service events. For each high-level sensor event feed, the list of required low-level feeds is provided in the form of a list, where each entry identifies a sensor and specifies the rate at which it should be sampled. These specifications are typically only a few lines of code, varying between 7 and 18 lines of code for the triggers used in the example service prototypes. The code for using high-level sensor events to generate the service events is
7 Mobile Communications and ApplicationsEAI Endorsed Transactions on
Algorithm 1Sampling Rate Request Handling Algorithm
1: procedureSensor Scheduling(s, r) .sensor name (s) and sampling rate (r)
2: if¬SamplingScheduler.isSensorFound(s)then
3: SamplingScheduler.add(s, r); .addsto the scheduler
4: SamplingScheduler.createSensorListener(s); .create a new sensor listener actor fors
5: SamplingScheduler.createSensorFilter(s); .setup a sensor filter actor fors
6: else .sis already scheduled
7: if(r > SamplingScheduler.currentRate)then
8: SamplingSchedule.adoptSamplingRate(s, r); .adopt the sampling rate tor
9: end if
10: end if
11: end procedure
typically even shorter. The current prototype does not have a way for a service designer to add completely new high-level sensor or service event types; ongoing work is developing a way to allow that.
As shown in Figure7, the runtime system executing on the Android device has two components: the sampling scheduler and the event detector.
Sampling Scheduler. As described in Section 4.2, the
sampling scheduler sets a sampling rate for each sensor based on the received sensing parameters. The sched-uler optimizes sensor sampling feeds by opportunis-tically sharing them between different service feeds. It then sends these requirements to individual sensor listeners, which then sample sensor data at the required sampling rate.
In [18], we describe further details of this process and introduce the ShareSens API we have developed through which the sampling scheduler can be accessed by any mobile application.
Event Detector.Because the data sampled from a sensor
can be for multiple event feeds, the data is filtered to extract the sub-feed pertinent to each event feed being served, and only that sub-feed is forwarded to the relevant event detection actor. An event detection actor monitors the sensor feed it receives for event triggers; when it sees one, it fires the event off to its service coordinator.
An event detector does not maintain a local record of the triggered events itself; all events are sent to the service coordinator.
Because the contributor side of the system will likely execute on battery-operated mobile devices, it is important that contributors have the ability to either develop or adopt simple resource consumption policies to avoid undesired battery drain. We hope to utilize the fine-grained resource management features already present in the CyberOrgs [16] extension of Actor Architecture which we have used in our prototype. For now, we have implemented a feature allowing a service
detector
...
....
rate
filter service
listener
samples
sampling scheduler platform
mobile app
samples
event
sensor
coordinator
sensing params
event sampling requirements
rate
event
event actors
event
Figure 7. Contributor Side
designer to specify resource limits after reaching which the contributor device would stop contributing feeds.
5.3. Client Side
Client side of the platform is implemented as part of the Android application implementing the contributor side. When a new service is launched, each client receives a notification about the launch. Multiple views are supported through custom interfaces installed by the service designer. A client interested in subscribing to a service can examine available views using the
service view interface (see Figure 5), and then use the
Table 1. Lines of Code Comparison
Service Standalone CSSWare
Restaurant
Recommendation 6,142 41
Twitter-like Messaging 4,768 46
about 100 and the smallest at 75 lines).5 Although these interfaces are sufficient for the examples we have implemented, and for services with similar client side requirements, additional interfaces would need to implemented for different types of services. In our current prototype, there is no way for service designers to program these interfaces themselves; however, we plan to provide a way for new (general purpose or custom) interfaces developed by service designers or other parties to be installed or added to a repository from which they could be installed.
6. Evaluation
In this section, we present our evaluation of CSSWare for both the programmability of new services, as well as our experimental evaluation for performance, scalability and energy efficiency.
6.1. Programmability
The main programmability advantage of using CSS-Ware is in the orders of magnitude lower number of lines of code required for launching a new service. As shown in Table1, the prototype restaurant recom-mendation service presented in this section required 41 lines of code for the server and contributor side combined; in comparison, an equivalent standalone service we implemented required 6,142 lines of code. A twitter-like messaging service we implemented, sim-ilarly required 46 lines of code instead of 4,768 lines for an equivalent standalone service. For reference, the server and contributor end of the CSSWare platform required 7,473 and 4,622 lines of code respectively.
Below, we present prototype implementations of these two qualitatively different services to illustrate the ease with which new services can be programmed.
Restaurant Recommendation Service. Consider the type of restaurant recommendation service previously described in Section1, where mobile devices of people visiting restaurants in a neighborhood automatically send real-time updates about the service they are
5These 350 lines of code are included in the previously mentioned
roughly 4600 lines of code for the Android application’s implementa-tion.
. . . .
mobile devices mobile devices
Restaurant 1 Restaurant n
service
coordinator coordinator
client
create aggr
create aggr
Figure 8. Restaurant Recommendation Service
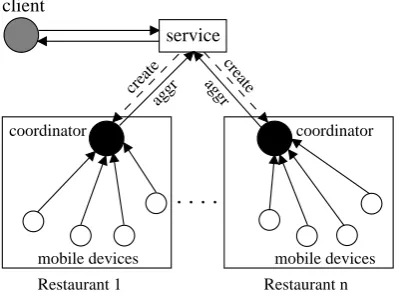
receiving to a service provider, which then aggregates this information for people searching for restaurants. We assume that information required for generating these feeds can be gathered automatically by the devices by tapping into various sensors to determine when someone arrives at a restaurant, when they are waiting to be seated, when they sit down, when they are served, when they finish eating, and when they leave. The information could be coarser or finer grained depending on the device, usage habits, quality of the behavior detecting software, etc. These updates from personal mobile devices could then be aggregated by a service provider to rank restaurants according to criteria such as the amount of wait time before being seated, the length of time taken dining (shorter or longer, as preferred), the total amount of time that the user could expect to travel to the restaurant, dine, and be back at work. The ranking could also consider the server’s meta-knowledge about the number of people being sent to various restaurants by the service.
Figure8shows the service graphically, and Figure9 presents our code implementing such a service as a
createSensorService() method. First, a number of
service variables are initialized: the list of restaurants (i.e., their names and coordinates), restaurantList, a method to be used by the coordinator to aggregate contributions, aggrMethod, and the default sampling rate to be used for sensor feeds when a rate is not explicitly specified, Default_SamplingRate.
aggrMethod is initialized here to a general purpose
method for computing the average; it is to be used by the coordinator to compute average waiting time. Other services could use other available aggregation methods; our prototype provides a selection of them. There is currently no way for a service designer to add a new aggregation method, but we plan to provide that functionality in the future. Although here we hardcode the restaurants, functionality can be easily added to the mobile app to allow contributors to add previously unknown restaurants.
9
1 void c r e a t e S e n s o r S e r v i c e ( )
2 {
3 /* i n i t i a l i z e s e r v i c e v a r i a b l e s */ 4 S t r i n g p l a c e L i s t =
5 " Restaurant1 , 5 2 . 1 2 6 9 ,−1 0 6 . 7 6 1 8 ; 6 Restaurant2 , 5 2 . 1 1 5 6 ,−1 0 6 . 5 9 9 7 ; . . . " ; 7 i n t aggrMethod = SvcEnum . a v e r a g e ; 8 i n t d e f a u l t S a m p l i n g R a t e =
9 SensorManager . SENSOR_DELAY_NORMAL ; 10
11 /* d e f i n i n g s e n s o r s */
12 Sensor GPS = new Sensor ( SvcEnum . GPS ,
13 d e f a u l t S a m p l i n g R a t e ) ; 14 Sensor a c c e l = new Sensor (
15 SvcEnum . a c c e l , d e f a u l t S a m p l i n g R a t e ) ; 16 Sensor gyroscope = new Sensor (
17 SvcEnum . gyroscope , d e f a u l t S a m p l i n g R a t e ) ; 18
19 /* d e f i n e a s e r v i c e e v e n t */
20 S e r v i c e E v e n t l o c a t i o n E v e n t = new S e r v i c e E v e n t 21 ( SvcEnum . sensorEvent , new L i s t <Sensor > ( ) { GPS } , 22 new L i s t <EventParam > ( ) {
23 createParam ( " t r i g g e r " , SvcEnum . e n t e r P l a c e ) , 24 createParam ( " t r i g g e r " , SvcEnum . d e p a r t P l a c e ) , 25 createParam ( " p l a c e L i s t " , p l a c e L i s t ) ,
26 createParam ( " u p d a t e I n t e r v a l " , 30) ,
27 createParam ( " output " , SvcEnum . v i s i t T i m e ) } ) ; 28
29 /* d e f i n e a s e r v i c e e v e n t */ 30 S e r v i c e E v e n t a c t i v i t y E v e n t =
31 new S e r v i c e E v e n t ( SvcEnum . sensorEvent , 32 new L i s t <Sensor > ( ) { a c c e l , gyroscope } , 33 new L i s t <EventParam > ( ) {
34 createParam ( " t r i g g e r " , SvcEnum . sitDown ) , 35 createParam ( " t r i g g e r " , SvcEnum . s t i l l ) , 36 createParam ( " s t i l l T i m e " , 1 ) ,
37 createParam ( " output " , SvcEnum . waitTime ) } ) ; 38
39 /* c r e a t e and l a u n c h t h e s e r v i c e */
40 CrowdService s e r v i c e = new CrowdService ( t i t l e , 41 d e s c r i p t i o n , new L i s t <S e r v i c e E v e n t > ( ) 42 { l o c a t i o n E v e n t , a c t i v i t y E v e n t } , aggrMethod ) ; 43 s e r v i c e . launch ( ) ;
44 }
Figure 9. Restaurant Recommendation Service
A sensor is set up for each of the sensor feeds required for any of the service feeds, following which the two types of service events are defined. The first,
locationEvent, is defined to require the GPS sensor
feed and is defined in terms of a number of parameters. The “trigger” parameters identify high-level sensor events, which become the basis for service events. For exampleenterPlace recognizes entering a location (a restaurant in this service). The “output” parameters identify the service events to be sent to the coordinator; here, visitTime computes the difference between
enterPlace and departPlace. Additional parameter
types are parameters that are available to the various methods; for example,updateIntervalis available to
visitTime as a parameter to decide the frequency of
feeds to send to the coordinator.
. . . .
coordinator coordinator
constituency constituency
service
client
aggr
aggr
create
create
Discussion 1 Discussion n
Figure 10. Twitter-like Messaging Service
Similarly,activityEventspecified a different sensor feed related to observations of the restaurant client’s activity. It uses various sensor feeds. The triggers detect activities of “sitting down” or “being still,” the latter using thestillTimeparameter, which are then used as the basis for awaitTimeservice event to be sent to the coordinator.
Finally, the service is created as an instance of the
CrowdService class, and launched. The constructor
for CrowdService takes as parameters a title, a
description, the list of events (i.e., locationEvent
and activityEvent) and the aggregation method
aggrMethod. Once the service has been created,launch
is called to launch the service, which creates the coordinator actor to coordinate the communication between the contributors and the service, which then invites the contributors to begin sending their event feeds.
Twitter-like Messaging Service. A service like Twitter serves a number of purposes, which include trans-mission of personal, organizational and news updates, social networking, coordination of collective action, and sharing or propagation of opinions. Increasingly, it has also served as a source of information for journalists, opinion makers, politicians, etc. to acquire a sense of public sentiment. There are a handful of specific mes-sage formatting devices (particularly hashtags) which are created and subsequently adopted by contributors to indicate relationship with existing messages and con-versations, and which enable some degree of analysis of sentiment. Here we show how the mechanisms pre-sented in this paper can be used to implement a service which allows users to both contribute their opinions, and obtain aggregate information helpful in assessing contributor sentiment.
1 void c r e a t e M e s s a g e S e r v i c e ( )
2 {
3 /* i n i t i a l i z e s e r v i c e v a r i a b l e s */ 4 i n t d e f a u l t S a m p l i n g R a t e =
5 SensorManager . SENSOR_DELAY_NORMAL ; 6 i n t aggrMethod = SvcEnum . msgRanking ; 7
8 /* d e f i n i n g s e n s o r s */ 9 Sensor keyboard = new Sensor
10 ( SvcEnum . keyboard , d e f a u l t S a m p l i n g R a t e ) ; 11
12 /* d e f i n e a s e r v i c e e v e n t */ 13 S e r v i c e E v e n t c r e a t e D i s c E v e n t = 14 new S e r v i c e E v e n t ( SvcEnum . msgEvent , 15 new L i s t <Sensor > ( ) { keyboard } , 16 new L i s t <EventParam > ( ) {
17 createParam ( " t r i g g e r " , SvcEnum . rcvReq ) , 18 createParam ( " c o n s t i t u e n c y " , d i s c C o n s t i t ) , 19 createParam ( " u p d a t e I n t e r v a l " , 1 ) ,
20 createParam ( " output " , SvcEnum . i n v i t e C o n s t i t )
} ) ;
21
22 /* d e f i n e a s e r v i c e e v e n t */ 23 S e r v i c e E v e n t addMsgEvent =
24 new S e r v i c e E v e n t ( SvcEnum . msgEvent , 25 new L i s t <Sensor > ( ) { keyboard } , 26 new L i s t <EventParam > ( ) {
27 createParam ( " t r i g g e r " , SvcEnum . rcvMsg ) , 28 createParam ( " message " , msg ) ,
29 createParam ( " output " , SvcEnum . u p d a t e L i s t ) } ) ; 30
31 /* d e f i n e a s e r v i c e e v e n t */ 32 S e r v i c e E v e n t voteEvent =
33 new S e r v i c e E v e n t ( SvcEnum . msgEvent , 34 new L i s t <Sensor > ( ) { keyboard } , 35 new L i s t <EventParam > ( ) {
36 createParam ( " t r i g g e r " , SvcEnum . sendVote ) , 37 createParam ( " output " , SvcEnum . msgText ) , 38 createParam ( " output " , SvcEnum . msgWeight ) } ) ; 39
40 /* c r e a t e and l a u n c h t h e s e r v i c e */
41 CrowdService s e r v i c e = new CrowdService ( t i t l e , 42 d e s c r i p t i o n , new L i s t <S e r v i c e E v e n t > ( ) 43 { voteEvent , c r e a t e D i s c E v e n t , addMsgEvent } , 44 aggrMethod ) ;
45 s e r v i c e . launch ( ) ; 46 }
Figure 11. Twitter-like Messaging Service
this service, a contributor of a message is also simul-taneously a client who gets to see other messages. On proposing a message, the service shows the contributor (now also a client) a list of existing messages in the discussion which contain keywords from the proposed message (or are similar in a more meaningful way). At this point, the contributor decides whether to proceed with contributing their message as a new message to the discussion or to add support to one of the existing messages. This decision is made by the contributor by voting for either their own message or one or more existing messages, or both, by distribution their 1.0 vote among them.
Figure10shows the service graphically and Figure11 presents our code implementing it. To define events, we abstract the observation of a user’s contribution as an event sensed by the keyboard sensor. We use three events – msgSentEvent, createDiscEvent and
addMsgEvent – corresponding to the three types of
activities a user can engage in.
Next, the set of events to be reported to the coordinator is defined. AcreateDiscEventfires when a contributor sends a request to create a new discussion with the identified constituency discConstit. When the service receives this request, it assigns a new discussion ID to identify the discussion topic by, and creates a dedicated discussion coordinator for that discussion, and sets up an updateInterval
specifying the lengths of the intervals after which the service would receive updates from the coordinator. The coordinator in turn announces the discussion to contributors (SvcEnum.inviteConstit). Once invited, the contributors are free to send messages to the discussion coordinator in the form of asynchronous messages. An addMsgEvent fires when the service receives a (msg) from a contributor. Thismsgis either a new message drafted by the contributor, or an existing message previously sent to the service. On receiving a
msg, the discussion coordinator first updates the ranked message list (SvcEnum.updateList) to reflect the new message received, and then checks to see if it is time to aggregate received messages and report back to the service. When it is time to aggregate,6it aggregates the updates and reports them to the server using an update message, which invokes the corresponding method in the server. The server’s update method updates the state of the discussion, and then for every entry in the list of service subscribers, sends them the view that they are subscribed to. A voteEvent is reported to the coordinator when a new message is drafted by the contributor. A message contains some text (msgText) as well as the proportion of the contributor’s vote for the message,msgWeight. Each contributor has a total of 1.0 vote for any discussion, which they are free to distribute between various messages under that discussion.
Service creation takes as parameters a title,
description, a list of events (i.e., voteEvent,
cre-ateDiscEvent and addMsgEvent) and the selected
aggrMethod.
6.2. Experimental Evaluation
We experimentally evaluated CSSWare in terms of performance, scalability and energy efficiency. Our experiments were conducted on a prototype Actor-based implementation of CSSWare. On the contributor
6If messages are infrequent, a clock is used by the service to interrupt
the coordinator at the end of each interval.
11
side, we used a Samsung Galaxy Note II phone with a 1.6GHz quad-core processor and 2GB of RAM running Android OS ver 5.1. The server ran on a Windows 7 laptop equipped with a 2.6GHz quad-core Intel i7 processor and 8GB of RAM.
We installed instrumentation in the server and mobile application (i.e., contributor and client) parts of our prototype restaurant recommendation service to measure the processor time taken to perform various tasks. Instrumentation was also added to the contributor side to measure energy consumption of sensing.
Performance and Scalability.
Service Platform Processing Demand. To evaluate the
scalability of the server, we measured the resources required to host a service.
We created and launched a set of instances of the previously described restaurant recommendation service with their required frequencies of event feeds distributed over a normal distribution function. Specifically, we picked 150 random values with an average of 6.7, which added up to 1,000. We created 150 services with the randomly chosen feed frequency requirements, adding up to a cumulative feed frequency of 1,000 feeds per second. Each service received feeds from 10 restaurants. Note that the event feeds here are feeds of higher level events detected at the contributor end; these are not the raw data received at a high frequency from the sensors. In other words, the average frequency of 6.7 events per second per service would mean that something interesting is observed at some contributor device related to the service at the rate of 6.7 per second. Furthermore, we used a window size of 20 for recently received feeds for any window, this is the number of recent feeds which were used to compute a score for the restaurant. For this local aggregation, we simply maintained the average wait time for the restaurant, which required O(1) amount of time to maintain. These local aggregates for restaurants fed into the creation of a global aggregate in the form of a ranked list of the restaurants based on their scores, which amounted to a single step of insertion sort to maintain a sorted list, with an O(n) cost.7
Table 2 separately shows the one-time processing costs involved in creation of a new service as well as on-going processing costs as each event feed is received and processed. Creating service and coordinator actors – the former also including parsing the service’s meta data (i.e., title and description) and adding the new service to the published service list – took 13.04ms
7Although this performs well for the small number of restaurants, it
would be more efficient to use a binary search tree to keep a large number of restaurants sorted.
and 11.67ms on average, respectively. Initializing the global view for the service required 7.84ms. In terms of on-going costs, receiving and parsing an incoming event feed required 7.35ms on average. The cost of local aggregation to keep track of the average of the last 20 waiting times for a restaurant was 0.024ms on average. This aggregation has O(1) complexity. We also measured costs forO(logn),O(n) andO(n2) complexity
local aggregation functions as shown in the table. The global aggregation for ranking the 10 restaurants incurred an average processing cost of 0.95ms.
To put these numbers in some context, given the 8.325ms required per feed on an on-going basis, about 120 event feeds could be processed by a server of our configuration per second. This could support a single service where 120 events are being collectively detected by the contributors every second, or 10 services which are each receiving about 12 feeds per second on average, and so on. In a broader context still, assuming 40% of the population dines out at a meal time,8, assuming the diners are distributed somewhat evenly over a period of two hours, and each diner’s device is sending 3 events over the course of their meal (indicating arrival, seating, departure) a server of our modest configuration could process 288,288 diners’ data, equivalently data for a city of about 720,720 people. In practice, data from a small fraction of the diners could be used, allowing service for an order of magnitude higher population.
That said, our global aggregation function assumed only 10 restaurants. Although this may be reasonable because individuals requiring restaurant recommenda-tions are not likely to be close to hundreds of restau-rants, narrowing down the selection before aggregation would mean custom global aggregations, each costing the 0.95ms. However, this custom aggregation could happen on the client’s own device, without impacting the server’s scalability. Alternatively, for a truly global aggregate for a city with (say) 10,000 restaurants, an
O(logn) binary search tree could be used to keep the restaurants sorted; only the top few would ever need to be fetched, limiting the fetching cost.
Contributor Processing Demand. On the contributor
side, again, we separately measured the initial cost of handling a new service’s request for contribution, as well as the on-going cost of serving the service.
The average total of measured one-time cost was 53.35ms (SD 3.41). The on-going costs measured were per sensor feed: every time a piece of raw data was received from a server, its average total processing cost
8Zagat 2014 restaurant survey reported that an average American ate
Table 2. Average Processing Time at the Server Side in ms
One-Time Per-Service Costs Mean SD
Create a service actor 13.04 2.63 Create a coordinator actor 11.67 1.74 Create a service view 7.84 0.98 Total processing time 32.55 5.35
Per-Event-Feed Costs Mean SD
Process an event feed 7.35 1.11 Local aggregation (O(1) cost) 0.024 0.0021 Local aggregation (O(logn)
cost) 0.078 0.0083
Local aggregation (O(n) cost) 0.280 0.0349 Local aggregation (O(n2) cost) 0.680 0.0987 Global aggregation (10
Restaurants) 0.95 0.17
Total processing time (O(1)
local aggregation) 8.325 1.28
Table 3. Average Processing Time at the Contributor Side in ms
One-Time Per-Service Costs Mean SD
Process a service invitation 32.51 2.32 Initiate service 20.84 1.09 Total processing time 53.35 3.41
Per-Sensor-Feed Costs Mean SD
Schedule samples 2.81 0.45 Filter a sensor feed 4.16 0.49 Detect a service’s event 1.71 0.08 Total processing time 8.68 1.02
amounted to 8.68ms (SD 1.02). A finer breakdown of this total is presented in in Table3.
To put this on-going cost in perspective, about 115 sensor feeds per second could be handled on a device of our configuration (assuming no other computations executing). If an average service requires as many as 10 data samples per second (from a variety of sensors), 11.5 of such services could be supported; if an average of 1 data sample per second is required per service, a more likely scenario, 115 services could be simultaneously contributed to.
Client Processing Demand.For the client side as well, we
measured the one-time processing costs of accessing a new service, as well as the on-going costs of receiving updates.
As shown in Table4, the average total of measured one-time costs was 35.53ms. The total of measured per-refresh on-going costs amounted to 60.9ms on average, with 28.7ms (SD 3.9) for processing the update, and 32.2ms (SD 6.4) for display. In other words, a client
Table 4. Average Processing Time at the Client Side in ms
One-Time Per-Service Costs Mean SD
Parse a service notification 21.32 2.21 Subscribe to a custom view 14.21 1.84 Total processing time 35.53 4.05
Per-View-Update Costs Mean SD
Parse a service update 28.7 3.9 Display a service view 32.2 6.4 Total processing time 60.9 10.3
Table 5. Energy Consumed using ShareSens vs. Standalone Services in mJ
Sensor Standalone CSSWare
Mean SD Mean SD
Accelerometer 2,646 132.3 1,995 102.6 Gyroscope 14,653 761.4 10,751 645
could be simultaneously subscribed to and receive updates from 16 services every second. This is not very meaningful considering that more than half of the processing cost is for graphically displaying the update, which is not likely to happen simultaneously for more than only a few services. If we assume that only one service’s updates are actually displayed at a time, more than 30 services could be supported in the background where interesting updates could lead to notifications, invitations to display, etc.
Energy Consumption of CSSWare vs. Standalone Services.
Finally, a set of experiments was carried out to measure the overall improvement achieved in energy consumption by using CSSWare’s sampling scheduler on the contributor device. We used the PowerTutor software [19] for our energy measurements.
To measure the overall improvement in energy consumption, we made measurements of energy used by CSSWare and identical standalone services implemented without using CSSWare. Table 5 shows the total amount of energy used by each sensor for the entire experiment duration. As shown in Table 5, the sampling scheduler improved energy consumption of accelerometer and gyroscope sensors by up to 24.60% and 26.63%, respectively. However, the percentage savings depend entirely on the number of requests being served, because although the energy used is roughly linear in the cumulative sampling rate of all requests for the standalone services, for CSSWare, it depends almost entirely on the highest frequency being requested at the time, from which other requests are also served.
13
Overhead Analysis. In order to determine the non-sensing overhead of CSSWare, we measured the energy consumed by the contributor device side of the framework, albeit without the actual sensing. The average energy consumed was measured to be 70.4 mJ for the accelerometer, and a similar 79.6 mJ for the gyroscope sensor. In percentage terms, this was roughly 4% of the total energy consumed in the accelerometer experiments, and 0.8% for the gyroscope sensor, the difference explained by the order-of-magnitude larger overall energy demand of the gyroscope sensor itself.
7. Conclusions
With the growing ubiquity of sensors and mobile devices, it is more possible than ever to offer innovative services based on both what the millions of sensors on people’s devices are sensing, as well as what individuals are willing to actively contribute. However, the barriers to offering such services continue to be prohibitive for most: not only must these services be implemented, they would inevitably compete for resources on people’s devices.
We have argued in this paper that many crowd-sourced services, including prominent social media services (if we consider their role of helping evolve collective messages), require similar communication mechanisms. We focus on one such mechanism – multi-origin communication – which allows a number of autonomous participants to contribute messages which can then be aggregated to create group messages on behalf of all. We introduced an approach to supporting crowd-sourced services using multi-origin communication, and presented our design and implementation of an Actor-based middleware for crowd-sourced services as a platform for launching such services. We illustrate the ease with which new services can be launched by presenting source code for prototype implementations for two qualitatively different types of services, each requiring less than 50 lines of main service specification code, with less than 100 lines of additional relevant code from available libraries of aggregation functions, feed specifications and service view interface. Finally, we experimentally evaluated the scalability of the approach. Most notably, even our modestly configured server could potentially provide a restaurant recommender service to a population of millions; contributor devices could contribute to tens if not hundreds of services simultaneously; client devices could monitor tens of services.
We have additionally addressed the challenge of satisfying the energy needs of a potentially large number of services requiring sensor data continuously. Use of the sampling scheduler takes advantage of the overlap in sensing requirements of various applications
to achieve significant energy savings when there are overlapping requirements, with minimal overhead.
In on-going work, we are developing mechanisms for service designers and third parties to add new service feed specifications, custom service view interfaces, and aggregation functions. This will allow a larger variety of services to be implemented. We are also working on further simplifying programmability of services through web-based graphical interfaces. Finally, we would like to apply our approach for fine-grained resource coordination to refining the sensor sampling scheduler, and more generally to manage the resource demands that a larger number of services may place on resource-constrained mobile devices.
Acknowledgements. Support from the Natural Science and Engineering Research Council of Canada (NSERC), the Cana-dian Foundation for Innovation (CFI) and the Government of Saskatchewan is gratefully acknowledged.
References
[1] Geng H, Jamali N. Supporting Many-to-many Communication. In: Proceedings of AGERE!@SPLASH. Indiana, USA; 2013. p. 81–86.
[2] Abdel Moamen A, Jamali N. Coordinating Crowd-Sourced Services. In: Proceedings of IEEE Mobile Services. Alaska; 2014. p. 92–99.
[3] Levine U, Shinar A, Shabtai E, Shmuelevitz Y. Condition-based activation, shut-down and management of appli-cations of mobile devices. United States Patents, US 8,271,057. 2009;.
[4] Li RY, Liang S, Lee DW, Byon YJ. TrafficPulse: A Mobile GISystem for Transportation. In: Proceedings of MobiGIS. California, US; 2012. p. 9–16.
[5] Zook M, Graham M, Shelton T, Gorman S. Volunteered Geographic Information and Crowdsourcing Disaster Relief: A Case Study of the Haitian Earthquake. World Medical and Health Policy. 2010;2(2):7–33.
[6] Besaleva L, Weaver A. CrowdHelp: A crowdsourcing application for improving disaster management. In: Proceedings of GHTC. California, USA; 2013. p. 185– 190.
[7] Uga T, Nagaosa T, Kawashima D. An emergency earthquake warning system using mobile terminals with a built-in accelerometer. In: Proceedings of the 2012 IEEE Conference on ITS Telecommunications;. .
[8] Ra MR, Liu B, La-Porta T, Govindan R. Medusa: A Pro-gramming Framework for Crowd-sensing Applications. In: Proceedings of MobiSys; 2012. p. 337–350.
[9] Barowy DW, Curtsinger C, Berger ED, McGregor A. AutoMan: A Platform for Integrating Human-based and Digital Computation. In: Proceedings of the ACM International Conference on Object Oriented Programming Systems Languages and Applications. OOPSLA ’12; 2012. p. 639–654.
[11] Liu X, Lu M, Ooi C, Shen Y, Wu S, Zhang M. CDAS: A Crowdsourcing Data Analytics System. The Journal of PVLDB. 2012;5(10):1040–1051.
[12] Ye F, Ganti R, Dimaghani R, Grueneberg K, Calo S. MECA: Mobile Edge Capture and Analysis Middleware for Social Sensing Applications. In: Proceedings of the Conference Companion on WWW. Lyon, France: ACM; 2012. p. 699–702.
[13] Jayaraman P, Perera C, Georgakopoulos D, Zaslavsky A. Efficient opportunistic sensing using mobile collabora-tive platform MOSDEN. In: Proceedings of the 2013 International Conference on Collaborative Computing: Networking, Applications and Worksharing;. .
[14] Agha G. Actors: A Model of Concurrent Computation in Distributed Systems. MIT Press, Cambridge, MA, USA. 1986;.
[15] Agha G. Actors Programming for the Mobile Cloud. In: Proceedings of ISPDC; 2014. p. 3–9.
[16] Jamali N, Zhao X. Hierarchical resource usage coordination for large-scale multi-agent systems. In: Massively Multi-Agent Systems I. Springer Berlin Heidelberg; 2005. p. 40–54.
[17] Jang M, Momen A, Agha G. Efficient Agent Communication in Multi-agent Systems. In: Proceedings of SELMAS; 2004. p. 236–253.
[18] Abdel Moamen A, Jamali N. ShareSens: An Approach to Optimizing Energy Consumption of Continuous Mobile Sensing Workloads. In: Proceedings of IEEE Mobile Services. NY, USA; 2015. p. 89–96.
[19] Zhang L, Tiwana B, Qian Z, Wang Z, Dick RP, Mao ZM, et al. Accurate Online Power Estimation and Automatic Battery Behavior Based Power Model Generation for Smartphones. In: Proceedings of CODES+ISSS. Arizona, USA; 2010. p. 105–114.
15 EAI Endorsed Transactions