Machine Learning Methods for Reliable Resource
Provisioning in Edge-Cloud Computing: A Survey
THANG LE DUC,
Umeå University, SwedenRAFAEL GARCÍA LEIVA,
IMDEA Networks Institute, SpainPAOLO CASARI,
IMDEA Networks Institute, SpainPER-OLOV ÖSTBERG,
Umeå University, SwedenLarge-scale software systems are currently designed as distributed entities and deployed in cloud data centers. To overcome the limitations inherent to this type of deployments, applications are increasingly being supple-mented with components instantiated closer to the edges of networks – a paradigm known as edge computing. The problem of how to efficiently orchestrate combined edge-cloud applications is however incompletely understood, and a wide range of techniques for resource and application management are currently in use.
This paper investigates the problem of reliable resource provisioning in joint edge-cloud environments and surveys technologies, mechanisms, and methods that can be used to improve the reliability of distributed applications in diverse and heterogeneous network environments. Due to the complexity of the problem, special emphasis is placed on solutions to the characterization, management, and control of complex distributed applications using machine learning approaches. The survey is structured around a decomposition of the reliable resource provisioning problem into three categories of techniques: workload characterization and prediction, component placement and system consolidation, and application elasticity and remediation. Survey results are presented along with a problem-oriented discussion of the state of the art. Finally, a summary of identified challenges and an outline of future research directions are presented to conclude the paper. CCS Concepts: •Computer systems organization→Cloud computing;Reliability;Availability; • Computing methodologies→Model development and analysis;
Additional Key Words and Phrases: reliability; cloud computing; edge computing; distributed systems; placement; consolidation; autoscaling; remediation; machine learning; optimization
ACM Reference Format:
Thang Le Duc, Rafael García Leiva, Paolo Casari, and Per-Olov Östberg. 2019. Machine Learning Methods for Reliable Resource Provisioning in Edge-Cloud Computing: A Survey.ACM Comput. Surv.00, 0, Article 1 (June 2019),35pages.https://doi.org/0000001.0000001
1 INTRODUCTION
The past decades have witnessed the trend of moving computation, data storage and applications into cloud data centers (DCs), facilitating ubiquitous access to shared computing and storage resources on demand. The cloud computing model demonstrates numerous advantages, including high utilization of shared resources, low cost in service deployment and management, high scalability, accessibility, and availability [129]. Today, in the era of the Internet of Things (IoT), an unprecedented volume
Authors’ addresses: Thang Le Duc, Umeå University, Umeå, 90187, Sweden, [email protected]; Rafael García Leiva, IMDEA Networks Institute, Madrid, 28918, Spain, [email protected]; Paolo Casari, IMDEA Networks Institute, Madrid, 28918, Spain, [email protected]; Per-Olov Östberg, Umeå University, Umeå, 90187, Sweden, [email protected].
Permission to make digital or hard copies of all or part of this work for personal or classroom use is granted without fee provided that copies are not made or distributed for profit or commercial advantage and that copies bear this notice and the full citation on the first page. Copyrights for components of this work owned by others than the author(s) must be honored. Abstracting with credit is permitted. To copy otherwise, or republish, to post on servers or to redistribute to lists, requires prior specific permission and/or a fee. Request permissions from [email protected].
© 2019 Copyright held by the owner/author(s). Publication rights licensed to the Association for Computing Machinery. 0360-0300/2019/6-ART1 $15.00
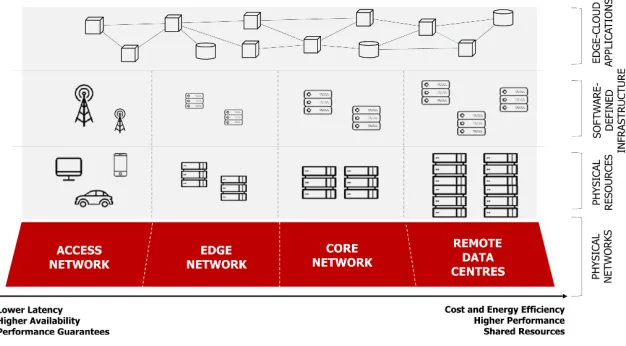
of data generated by the IoT devices needs to be collected and analyzed [17]. The collection of such volumes of data in cloud DCs incurs extremely high latency and network bandwidth usage. To address this issue, thefogoredge computingparadigm has been proposed, which pushes the data analysis closer to the systems or devices that data originates from [17,75]. It is however unclear how to orchestrate complex, large-scale software systems in heterogeneous network environments, and the topic of such orchestration, or how to automate computing platforms that integrate both edge and cloud computing capabilities, is the subject of significant research efforts. Fig.1illustrates hierarchical tiers of an (heterogeneous) edge-cloud network.
Fig. 1. A conceptual illustration of edge computing. To improve the application performance and the network bandwidth utilization, selected components are deployed closer to end-users in core and edge networks.
This paper targets techniques for reliable resource provisioning that can operate across different (and often multiple) distributed computing system domains, including cloud, edge and fog com-puting. In this respect, we do not limit our scope to a specific scenario, context or ecosystem, but rather focus on the techniques proposed to tackle provisioning, elasticity and remediation problems, and discuss how these techniques are shaping the next generation of edge/fog/cloud computing architectures. Such architectures are extremely heterogeneous and complex in many respects, to the point that a “fully engineered” approach to modeling and prediction/actuation may be exceedingly complex, if not plainly ineffective. For this reason, we explicitly target those techniques that employ some form of machine learning applied to modeling, prediction, classification and forecasting related to resource provisioning, applications/components placement, migration, and remediation in a continuum of distributed computing contexts. Accordingly, this paper first decomposes and structures the problem of reliable resource provisioning, and then puts a special emphasis on a survey of machine learning-based approaches to the solution of this problem or parts thereof.
studying the impact of Service Level Agreement (SLA) violations, dealing with different Quality of Service (QoS) parameters, and a need for evaluations of the proposed solutions in real cloud environments. Numerous architectures of edge-oriented computing systems are explored in [58], which proposes to clarify the edge/fog terminology, through related concepts. The main focus of the survey is on different architectures, management and optimization approaches tackling a number of issues in the architectures, including resource provisioning, placement, offloading, migration. A description of prior work based on pursued optimization objectives is also provided.
While very useful to put distributed edge/fog/cloud computing systems in perspective and to assess the progress of the recent research and engineering of these systems, none of the above surveys provides an analysis of the available literature from a machine learning perspective. Among other propositions, our paper aims at filling this gap (which has been only partially addressed by such works as [113]), and especially focuses on machine learning-based techniques, thus highlighting the opportunities that these techniques provide for the management of complex distributed systems. In more detail, the contributions of this paper include: (1) a problem formulation of reliable resource provisioning for distributed applications in edge-cloud environments; (2) a decomposition of the problem and a classification of sub-problems regarding resource provisioning and application remediation; (3) a comprehensive review of cutting-edge classic and machine learning-based schemes for workload modeling, load balancing, application placement and migration, computing offloading, system autoscaling and remediation; and (4) a problem-oriented discussion of a next generation of edge-cloud computing techniques needed for addressing the problem.
The remainder of this paper is organized as follows. Section2introduces terminology and describes enabling technologies to support the survey. Section3defines the problem of reliable resource provisioning in edge-cloud environments, and provides a classification of sub-problems that form the structure of the survey. Section4surveys classic and machine learning-based methods for addressing various aspects of resource provisioning and compares the schemes. Section5
presents a problem-oriented discussion about the state of the art, gives an overview of the surveyed solutions, identifies open issues and challenges, and discusses an optimization framework to fully address the problem. Finally, we draw concluding remarks in Section6.
2 BACKGROUND, TERMINOLOGY, AND ENABLING TECHNOLOGY
2.1 Cloud Computing
Cloud computing concerns the provisioning of resources, including computation, memory, storage, network, and applications/services, over the Internet. This computing paradigm basically adopts the client-server architecture and facilitates centralized deployment and computation offloading for applications. In this way, cloud computing is cost-efficient in application deployment and maintenance, and flexible in resource provisioning and in decoupling services from underlying technologies at both the client and server side. Cloud computing and its enabling technologies have been studied for decades, and numerous mature computing platforms have been delivered in the market, e.g., Amazon EC2, Google Cloud Platform, Microsoft Azure and IBM SmartCloud.
so as to boost the context awareness capability of both the devices and applications. The work also surveys numerous platforms that have been developed for this computing paradigm.
2.2 Edge and Fog Computing
A huge volume of data needs to be aggregated and consumed in order to generate intelligence and improve the context awareness of distributed applications. Fog and edge computing can meet this demand by leveraging distributed resources, up to the edge of a network. In the fog computing paradigm [78], the continuum of resources from the cloud to the edge is leveraged to provision computing and storage capacity to services and applications. Edge computing extends the concept further, so that potentially all computation and storage resources of edge network elements, e.g., access points, switches, routers, base stations and mobile devices, are utilized to provide a cloud-like computing environment to applications [94]. Besides an extension in the utilization of network infrastructure, this also provides optimizations in replicating information across networks to enhance local context awareness. Considering the convergence of information technology (IT) and telecommunications networks,mobile edge computing(MEC) is proposed as an instance of edge computing, in which the computational capabilities of Cloud and IT are integrated in Radio Access Networks (RANs) which are close to subscribers [44,101]. For standardization purposes, the European Telecommunications Standards Institute (ETSI) has established an industry standard for MEC as depicted in [41], which targets at an incorporation of the telco and IT cloud systems to form cloud-like environments within RANs.
Cloudlet computingis another architecture under the umbrella of edge computing [98]. A cloudlet is known as a small-scale DC bridging mobile/IoT devices and the central cloud. It is dedicated to quickly provision cloud services to the devices within its vicinity [99]. To support cloudlet deployment, OpenStack++ [114] (an extension of OpenStack [82]) has been developed by Carnegie Mellon University to provide a set of cloudlet-specific APIs. Moreover, commercial cloudlet-based applications have recently appeared in the market, e.g. Akamai’s cloudlet applications [47].
2.3 Application Architecture
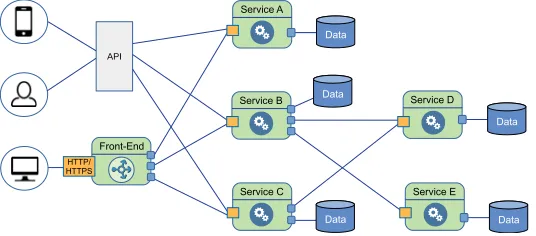
can be considered as an evolution of service-oriented architecture (SOA) to accommodate cloud and edge computing [104]. By employing microservices, a single cloud application can be distributedly deployed from cloud DCs down to the edges of the networks, and some components can be located even on the user devices. This architecture apparently delivers a high horizontal scaling flexibility in edge-cloud computing [68,104]. As pointed out in [27,68], Google, Netflix, Amazon, eBay, Twitter, and many other companies have evolved their applications toward microservices due to aforementioned benefits. Fig.2illustrates the architecture of a microservice-based application.
Fig. 2. An example of microservice-based application including one front-end service and five back-end services. The application can be accessed through a web (HTTP/HTTPS) interface or an API gateway.
2.4 Application Migration
Under the context of distributed edge-cloud application, application migration is defined as a relocation of one or multiple components within hosts or edge-/cloud-DCs. Since components are hosted and running in virtual machines (VMs) or containers, a component migration implies a VM/container migration. The execution of a migrated component needs to be resumed in the new host, thus the component’s data related to the current VM/container instance’s configuration, the component’s state and user sessions have to be transferred to the host for initializing the environment and resuming the component. Migration aims to provide workload balancing, fault tolerance, system stability, and energy efficiency. Based on relocation strategies, it can be categorized as either live migration with almost zero service downtime or non-live migration with some service suspension [66,81]. Non-live migration is the simplest and most naive technique [8], which first shuts down the source instance, transfers data of the instance image to the new host, and then reboot the instance. In contrast, live migration is more advanced and constitutes an attractive topic in both academia and industry. Numerous live migration schemes have been proposed [20,108,128], and various products currently support live migration [18], e.g. VMware ESX [116], Microsoft Hyper-V [71], Oracle VM Server [83], KVM [55], Google Cloud Platform.
2.5 Machine Learning
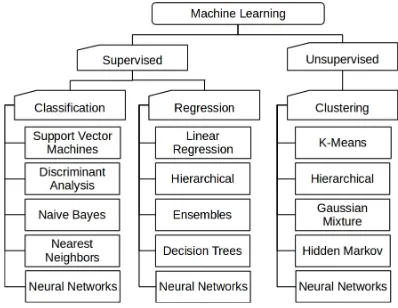
Machine learning algorithms can be classified into two main groups: supervised and non-supervised algorithms. Supervised learning refers to building models given a collection of training predictorsX1,X2, . . . ,Xp and the corresponding response variableY, whereas in unsupervised learning there exist only predictors, hence the algorithms have to learn the structure of the train-ing data (clustertrain-ing). When the goal is to predict a continuous or quantitative output value, the corresponding problem to be solved is called regression, whereas the prediction of a categorical or qualitative output is known as a classification problem. In Fig.3we provide a taxonomy of some of the most popular machine learning algorithms used in practice.
Fig. 3. Classification of the most common machine learning algorithms.
Machine learning methods can be parametric where certain assumptions are made about the functional form of the model and training data is then used to fit its parameters, e.g., as in polynomial regression, or non-parametric, e.g., neural networks. Machine learning can be used also for inference tasks, i.e., in order to understand how the response variable is affected when the predictors change.
3 RELIABLE RESOURCE PROVISIONING IN EDGE-CLOUD ENVIRONMENTS
As outlined in [84], reliable resource provisioning for edge-cloud applications is a complex problem, especially when it is examined in a multi-tenant edge-cloud environment where the infrastructure is utilized to host numerous applications/services owned by different service providers. Each ap-plication typically has its own set of requirements, and there is a high possibility that controlling operations or tuning the performance of one application will have some impact on the others. When dealing with user workloads, data analysis must be performed from two different angles, at both the application- and the infrastructure-level. Additionally, the problem also defines that the applications are deployed and operating in heterogeneous and geographically dispersed resource environments. In short, solving the problem completely and optimally is a challenging task which entails a mixture of multiple techniques to attain the predictability and controllability of the appli-cations’ performance in edge-cloud environments. This leads to the necessity of a comprehensive investigation of different aspects of the problem, so as to produce a holistic view on the challenges and issues when deriving a solution. For this purpose, in this section we outline and discuss aspects of resource management at the workload, application, and infrastructure levels.
3.1 Workload Analysis and Modeling
to distinct characteristics and based on different perspectives, it can be categorized into different types, including sequential or non-sequential/random workload, transactional or non-transactional workload, and computation-intensive, data-intensive, or memory-sensitive workload [12,33]. The demand of resources is different for each type of workload, in terms of both resource type and volume. The components of an edge-cloud application are designated to perform different tasks which highly likely deal with different kinds of workload. Moreover, because of the wide dispersion of the components over networks, workloads are distributed differently across locations from the cloud- to edge-DCs. These characteristics lead to a high complexity and challenges in workload analysis and modeling. Nevertheless, understanding the workload behavior is apparently beneficial for the performance and reliability improvement of an application, in the way that resources are sufficiently allocated for the application to serve any coming workloads. As a result, significant effort has been made to accomplish workload modeling recently, especially the work aiming at real workloads of Google [60,61], Facebook [122], Netflix [107], and Wikimedia [9].
Furthermore, most recently comes a demand of workload behavior prediction [54,61]. In the age of IoT, there emerges an increase of the number of mobile users/devices accessing cloud applications. This introduces sudden changes of workloads at certain locations within some periods of time. In other words, edge-cloud applications may experience variations of workloads in an unpredictable manner. Knowing about the spatio-temporal distribution of future workloads in advance brings benefits for application scaling, i.e., the system becomes capable of proactively scaling for an early resolution to meet the real-time resource needs of applications and services. In this way, resource utilization can be optimized while guaranteeing the SLA as well as the QoS, which in turn leverages the business of cloud service providers. For research and development, workload modeling and prediction enables the generation of proper models for constructing autonomous systems which are able to perform optimization in autoscaling and remediation (being discussed in the next sub-section) under diverse circumstances.
3.2 Application Optimization
Due to the nature of the computing platforms, the applications deployed in edge-cloud computing environments have to face numerous issues caused by the limited of bandwidth, the unreliability and heterogeneity of wireless communications, computation offloading, and security [24,49]. The performance of such edge-cloud applications is also affected by the fluctuation of the workload of different components at different locations in the network. In order to maintain QoS, elasticity and remediation should be taken into account as two key requirements of an application [77]. In fact, elasticity enables computational resources to be flexibly scaled to meet the demand of applications or the users, while remediation allows applications to be recovered in case of any failures. To equip an application with elasticity and remediation capabilities, multiple techniques have been introduced. Out of those, three techniques are widely applied in practice: load balancing, application scaling, and migration.
and typically more stable, they do not perform optimally in heterogeneous distributed applications subject to unpredictable workload fluctuations as well as to the variation of workload distribution over time [21,28,46].
Scaling (or autoscaling) is an essential technique for cloud computing because it advocates the key principle ofpay-as-you-goin resource usage on the computing platform. Scaling empowers resources to be allocated or released dynamically according to the demand of the applications, thereby reducing the resources cost due to over-provisioning while maintaining a given QoS. Scaling is now widely employed in the products of major cloud service providers such as Google Cloud Platform, Rackspace, Amazon Web Services and Microsoft Azure. Depending on the resource provisioning methods, scaling can be horizontal (scale out/in) or vertical (scale up/down). To horizontally scale an application means to add/remove a number of instances of a component, i.e., adding/removing VM/component instances on which components are hosted and running to/from the application. Typically, load balancing accompanies this type of scaling in order to fairly distribute the workload among different instances. Vertical scaling works by adjusting the amount of resources, such as computation and/or memory resources, allocated to a running instance. According to the characteristics and requirements of applications, scaling tasks can be performed in either a reactive or a predictive manner. Reactive scaling is triggered to react to the changes under current conditions of the application, whereas predictive scaling first analyzes historical workload data, creates a workload model, uses the model for future workload prediction, and finally generates early resolutions to proactively allocate resources needed by the application in the future. Although predictive scaling methods are more advanced, the reactive ones are widely adopted in commercial products due to the simplicity, accuracy, and high performance [7,76,79,96].
3.3 Infrastructure Optimization
As discussed above, a distributed application consists of multiple components which may come with different sets of requirements. Specifically, components designed to perform CPU-intensive tasks definitely demand a large amount of computational resources. Those dealing with large amounts of data require a high data throughput and a large storage capacity. Other components interacting with the end users are expected to be responsive in communication-intensive tasks. The problem of deploying such different types of component in edge-cloud environments becomes crucial and more challenging due to the diversity in capacities and locations of resources in the cloud, fog, and edge networks. Tackling this problem is apparently coupled with edge-cloud infrastructure optimization. A key technique often used in this context is to leverage the level of indirection offered by virtualization technologies to construct software-defined infrastructures (SDIs) based on VMs and lightweight containers, where components can be dynamically assigned to and migrated between physical resources.
Virtualization also facilitates and eases the placement of multiple VMs/containers in a single physical server, which is known asserver consolidation. Its primary target is to obtain an optimal placement where the optimality criterion depends on the service provider’s requirements (e.g., low power consumption) or on the application requirements (e.g., fast response time, redundancy, etc.). Server consolidation relies on application migration techniques which actually migrate VMs/container between physical servers in order to implement the optimal placement solutions. It is especially necessary in the cases that workloads arriving at components are unpredictable [26]. In fact, to maintain the QoS whenever workload variations are experienced, VMs/containers hosting the corresponding components need to be resized/reconfigured and migrated to proper physical servers. This causes workload redirections, which in turn result in consolidations of the workloads of co-hosted application components on specific physical servers. In this way, server consolidation can minimize the total number of physical servers required to host VMs/containers, thereby optimizing the utilization and efficiency of individual resources and clusters. Specifically, hardware costs, operation and administration costs are all minimized thanks to the use of a small number of physical servers.
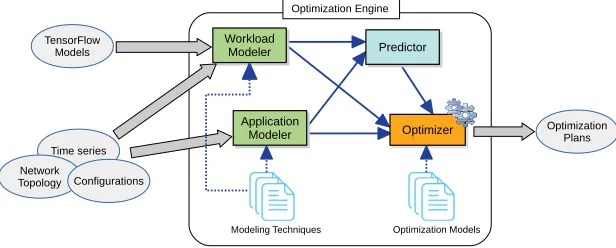
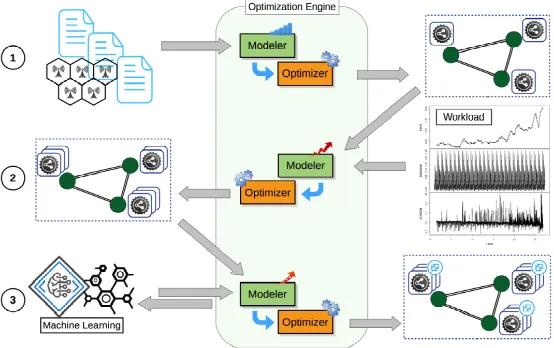
Fig. 4. An example of an optimization engine for VM/container placement. The optimizer is designated to produce the application and/or infrastructure optimization plans of VM/container placement.
3.4 Summary
This survey is motivated by the complexity of the problem of reliable resource provisioning for edge-cloud applications. To the best of our knowledge, there have been numerous studies surveying separately related sub-problems raised in each of the aforementioned topics, but none of them has investigated the problem as a whole to provide a complete technical reference to both academic and industrial research. By way of contrast, our survey sketches a full set of such sub-problems, and then carries out an exploration of the state of the art of machine learning-based techniques to solve them, before discussing how to address the problem as a whole.
4 LITERATURE REVIEW
Fig.5depicts a taxonomic classification of the literature surveyed by our paper. The studies have been classified in four main groups. Workload Analysis and Prediction deals with the task to mathematically model workloads and forecast future values given past behavior. Placement and Consolidation is about finding the optimal location of services and applications in large DCs. Elasticity and Remediation cover load balancing and how to properly scale applications. Finally, Network Function Placement studies similar issues in a network function virtualization context. We emphasize that, unless otherwise stated, the works surveyed in the following often cover techniques that can be applied to different virtualization technologies (e.g., VMs and containers) alike. For each paper, we still describe the context chosen in that specific work, and for techniques that can be applied only in a specific context (e.g., live VM migration) this is stressed upon the first occurrence.
Fig. 5. Taxonomic classification of the studies reviewed in the survey.
4.1 Workload Analysis and Prediction
Workload analysis and prediction has recently become an important research topic, as testified by the significant body of literature and by the presence of a few surveys covering aspects of this field. The recent work in [10] classifies workload traces collected from various types of applications (web, mobile, video streaming, etc.) as well as from the utilization of the underlying network infrastructure. The work discusses distinct workload features, characteristics, models and techniques to derive them. The models are applied in diverse contexts, in order to facilitate diverse resource planning and provisioning tasks, video content delivery, and system performance evaluation. Given a broad concept of workload and goals, the insufficiency of workload datasets for public use, and the fast evolution of cloud technology, the papers covered in [10] are shown to have different degrees of maturity (the highest being found in web applications and social networks).
threshold autoregressive moving average (SETARMA) models, as well as modern machine learning methods including advanced neural networks, support vector machines (SVM), decision trees, Bayesian networks, splines, and exponential smoothing. The selected studies in the survey cover data preparation, workload modeling and prediction methods. Notwithstanding this, most of them exclude up-to-date examples on how to use the methods to forecast future workload.
As the above surveys suggest, workload modeling and prediction in general was born mainly in the context of classical cloud computing scenarios. However, its great potential for the optimization and self-management of complex cloud/fog/edge scenarios makes it important to picture the most employed characterization techniques. This will be the focus of the next paragraphs and will be summarized in Section4.1.3.
4.1.1 Workload Analysis and Modeling.Jiaet al.propose to use principal component analysis to
find a set of crucial metrics out of a set of 45 metrics to characterize an array of 32 big data workload traces retrieved from BigDataBench [45]. The authors apply k-means clustering and a Bayesian information criterion both to study the affinity of the workloads, and to select a subset of represen-tative ones. The work considers two different software stacks: Hadoop and Spark. These stacks are shown to have a greater impact on the behavior of applications, from a microarchitecture point of view, than the employed algorithms. An alternative approach to characterize application workload is introduced in [50], which proposes to collect hardware performance data for modern processors, as this method is potentially less invasive than traditional monitoring tools. The methodology has been evaluated using two different ARM-based mobile phones, with three applications running in each device.
The authors of [4] develop a tool for low-level workload characterization using data collected from a hypervisor located in the virtualization tier and management operations of VMs. This makes it possible to characterize applications based on a set of typical CPU, memory, storage, and network utilization metrics. To do so, the authors apply a linear combination of various “canonical workloads”, which correspond to the set of above metrics, coupled with the least absolute shrinkage and selection operator (LASSO) method. The methodology is evaluated through a set of standard benchmarks such as MySQL and Apache web in a lab environment using synthetic datasets. The advantage of monitoring the hypervisor for workload data collection instead of each VM yields a lower footprint on machine performance.
The models provide predictions with root mean squared error (RMSE) at about 0.015. Aiming at container workload characterization, in [16] descriptive analytics is employed to analyze workload traces of Alibaba’s DCs so as to highlight the main issues faced by a data center hosting both production-scale long-running jobs as well as more dynamic non-containerized batch jobs. The study highlights typical resource overbooking patterns, and confirms a reliable prediction of resource usage over time is needed to avoid, e.g., straggling issues and co-location interference.
The authors of [119] carry out a comprehensive workload analysis and modeling for the workload data collected from three different private cloud production deployments: a large-scale software development system, a generic cloud, and a business process integration framework. They compare the capability of the hyperexponential, lognormal, and Pareto parametric models to answer “what-if” questions for load variation prediction, infrastructure capacity planning, and cost estimation. The workload of the VMs is characterized in terms of the interarrival time of the requests, VM lifetime, number of VMs requested, and the size of each VM. However, it remains unclear if physical system parameters (CPU, disk, and network usage) can be predicted from the features used for workload characterization, and if the considered three-phase hyperexponential distribution generalizes to all kinds of environments or remains specific to the studied dataset.
The use of system log analysis to automate workload characterization is proposed in [3]. With the results of the analysis, the authors derive sequences of interactions with the system (termed sessions) and propose a customer behavior graph model to reverse-engineer high-level application scenarios at the user interface level, typically in terms of usage patterns. The validity of the model is tested with artificially generated workload for a web server in a testbed. The proposed method is apt for e-commerce systems, which naturally employ a concept of user sessions. In [19], Cuzzocreaet al.propose to collect time series of references mapping a program to virtual memory at run time, and to apply spectral analysis to the collected data. The authors then model the time series using an ergodic continuous hidden Markov model in order to characterize application workload, classify applications (e.g., for benchmark construction), and generate synthetic workloads. Experimental validation is carried out using a collection of typical applications.
With the objective of extending CloudSim, [65] presents a workload modeling approach encom-passing data analysis, model parameter estimation, simulation and validation. Synthetic workload data used in the study is generated via RUBiS [13]. The collected workload metrics include the CPU, memory, and storage utilization, the system response time, and the total number of executed instructions. Once validated, the models are implemented in CloudSim for public use. The authors of [102] propose three different methods (linear, weighed, and exponential) to model the CPU workload of the control plane of a Software-Defined Network (SDN) hypervisor. The models are tested using an emulated data plane with the FlowVisor and OpenVirteX hypervisors. The study in [103] extends [102] by considering the fluctuation of resource availability, by including a better workload model based on SVM, and by testing the proposed method in a simulation environment.
4.1.2 Workload Prediction.A Bayesian approach is discussed in [22] to predict the future CPU
and memory workload of a given application. The authors propose a set of metrics that can be used as predictors (e.g., mean load, fairness index) and their combinations, and evaluate their results against other moving average and autoregressive models via the Google dataset [90]. Similarly [48] proposes to predict the CPU workload on VMs, by joining time series autocorrelation measurements and similarity clustering. The results are validated using a data captured from a real private cloud. A significant improvement in prediction accuracy is observed.
number of machines on the overall cloud performance. After observing that none of the considered prediction methods performs efficiently, the authors propose a weighed ensemble method, where weights are adjusted based on the error time series of the methods.
Huet al.propose a distributed system to monitor and predict the grid resource utilization [40], where prediction is delegated to neural networks and SVM, whose hyper-parameters are optimized through genetic and particle swarm algorithms. The models are tested using historical CPU and network bandwidth datasets, whose relatively small size constrains neural networks to small structures, and may not translate to big data learning on complex cloud architectures.
In [123], autocorrelation is used to identify relevant workload features to train neural networks and forecast future CPU, memory, storage, and network workload. The methodology is evaluated using a real dataset from an IBM production cloud. The work in [126] proposes to train multilayer perceptrons using application workload data clusterized by CPU usage. New tasks are classified based on proximity to one of the available clusters. The methodology is evaluated using the Google dataset. A method to predict power consumption in DCs over different time scales is proposed in [59]. First, the time series are de-noised using a de-trended fluctuation analysis, then power consumption is analyzed at the desired granularity using autoencoder neural networks. The model is validated by integrating real web server workload datasets in a simulated DC.
A combination of theoretical models, neural networks, SVM, and random forests is proposed in [23] to predict future workloads, with the goal of reducing the machine learning training time and increase the accuracy of theoretical models. The authors combine the models through kNN, hybrid boosting, and probing, and evaluate the results in a testbed with two open source applications. Given the small datasets, it remains unclear if the training would be an issue in modern machines. A joint feature selection, clustering, labeling and machine learning approach to resource scheduling is proposed in [124]. The main focus of the work is a set of algorithms leveraging multiple machine learning models to improve the classification and prediction of network nodes’ performance. The algorithms are evaluated in terms of performance classification and straggler mitigation using the OpenCloud dataset. The authors report an achievement of up to a 92.86% node performance prediction accuracy using the appropriate algorithm and hyperparameter choice.
In [130], the authors employ a Deep Belief Network (DBN) to make long-term (day scale) and short-term (hour scale) predictions of future CPU and memory requirements in a cloud environment. The results are validated using the Google dataset, and compared to an ARIMA model. The authors discardrecurrent neural networks(RNNs) due to the long training time. The error achieved by the DBN seems to indicate a risk of overfitting. A 3-layer neural network is trained using genetic algorithms and applied to workload predictions in cloud DCs in [54]. The proposed training method produces a model that predicts the NASA and Saskatchewan servers’ HTTP trace data with a higher accuracy then achieved with the backpropagation algorithm.
Workload management is addressed in [67] via decision trees re-trained using reinforcement learning, and applied to the best placement of new database queries. The authors implement and test a proof-of-concept implementation. In the context of automatically scaling computing resources in container-based cloud platforms, neural networks, Q-learning and a custom heuristic algorithm are compared in [97] using synthetic workloads. The authors conclude that Q-learning shows the fastest adaptation rate, and provides up to 22% resource saving.
4.1.3 Summary.Workload analysis presents different levels of maturity, mostly due to the lack
combination of the above [65]. For workload prediction, most of the machine learning alternatives have been evaluated, including Bayesian approaches [22], clustering [48], moving averages [60], SVM [40], decision trees [67], neural networks [54,123,126], and combinations thereof [23], without a clear winner [39]. However, neural networks seem to provide significantly good accuracy in several cases, provided that sufficient data is available for training.
4.2 Placement and Consolidation Optimization
4.2.1 Application placement. Application placement deals with the deployment of application
components in physical servers, VMs and/or containers, and encompasses different problems such as replica or content placement in CDNs, and placement of components in intra- or inter-DCs scenarios. Each problem is formulated with its own set of constraints on different Key Performance Indicators (KPIs), including resource utilization and the quality/availability of services. Due to the diversity and complexity of the application architecture, deploying applications on different computing platforms requires various placement schemes. In [106], the optimal placement if VM is achieved by solving a linear program, along with simpler heuristic algorithms from the bin-packaging domain. Additional requirements from a managerial point of view are also included. The approach is validated using datasets from an industrial environment and experimental results indicate an order-of 30% cost savings.
Wanget al.employ graph-to-graph mapping to solve the component placement problem in order to balance the workload of different components [117]. The authors model both the application and the physical computing infrastructure as graphs and find the optimal mapping between the two graphs. They then propose two different heuristic algorithms to solve the problem under different constraints, and theoretically prove them to achieve a polynomial-logarithmic approximation ratio. In [5], graph-to-graph mapping is used for multi-component application placement in order to minimize both the total mapping cost and the rate of mapping failure, constrained by the network capacity and service delay requirements. After solving the mapping through an integer linear programming, the authors deploy two heuristic algorithms. Through comprehensive simulations, the centralized algorithm is shown to yield a near-optimal result, although its extremely high complexity makes infeasible in large-scale cloud networks compared to the distributed one.
The placement of applications in mobile cloud networks is addressed in [111] via a multi-objective optimization accounting for resource utilization, service latency, and provisioning costs. Besides a globally optimum solution obtained via exhaustive search, the authors devise a local search algorithm based on depth-first search over a local subgraph. A method to optimally allocate of physical machines in cloud DCs is proposed in [6]. Jobs to be scheduled are characterized by required CPU and memory, and an optimal allocation is obtained via linear programming. An approximate solution is computed via a decision tree and linear regression. The proposal is validated experimentally in a testbed with web server jobs. k-means and density-based clustering are used in [125] to aggregate applications with complementary requirements on the same physical machines. The applications are classified as CPU-intensive or non-CPU intensive based on the CPU rate and utilization, and on the cycles per instruction, where non-CPU intensive application show higher disk I/O time and disk usage. The methods are applied to the open Google workload traces dataset.
4.2.2 Computation Offloading.A deeper investigation on component placement shows that
in a cloudlet, or in an edge- or cloud-DC. Because mobile devices are resource-constrained, placing the components on an edge-cloud server will release the devices from intensive computations, thereby improving the performance of applications and also the user experience [62]. However, offloading incurs communication costs and delays, and different locations may be more or less suitable for a certain target. Therefore, offloading may achieve different benefits due to different levels of server performance or reliability of servers and the communication medium.
Computation offloading is used for better energy efficiency in edge-cloud computing in [120]. The work considers both two-level offloading (where parts of a mobile device’s workload is shifted to the cloud) and three-level offloading (where the workload is initially shifted to a cloudlet, and only after that to the cloud). The authors solve the problem with a dynamic control algorithm employing Lyapunov optimization so as to optimally reduce the energy consumption while maintaining the responsiveness of applications. The authors of [34] consider hybrid fiber-wireless networks as a computing infrastructure where the cloud and MEC coexist, and provide offloading opportunities. Offloading is optimized to maximize the energy savings of mobile devices in this context, while satisfying communications and latency constraints. Different approaches include: an exhaustive search; a centralized greedy heuristic scheme; and a game-theoretic scheme that operates in a distributed manner. The work in [112] aims at optimizing computation offloading and resource allocation in MEC to minimize the energy consumption under bandwidth, compute resources, and latency constraints. The study covers offloading both to the cloud (assumed to have unlimited resources), and to resource-constrained mobile peers. The authors show that such problem is non-convex and NP-hard, and solve it iteratively using a successive non-convex approximation approach.
4.2.3 Server Consolidation.Both the optimization of application placement and the offloading
of computationally-intensive tasks bring benefits by reducing the ineffective allocation of resources and by improving the service performance. Still, effective optimization solutions need to also take into account the conditions of the underlying infrastructure, besides pure application-level requirements. Server consolidation with the help of VM migration techniques is a prerequisite to make truly optimal decisions. A survey of VM-specific migration schemes in cloud DCs is introduced in [1]. The work first identifies challenges entailed by the migration of VMs across Wide Area Network (WAN) links. Then, the surveyed schemes are characterized based on several qualitative variables. Next, the authors propose a novel taxonomy to categorize the analyzed schemes and frameworks, and finally list challenges and research trends.
A migration framework is presented in [25], which employs two levels of software agents to find the optimal VM migration time and placement. On each physical machine resides a first-level agent that is trained through Q-learning to detect overloading. A second-level agent decides where to migrate VMs. The framework is simulated using CloudSim and compared with classical migration algorithms. By observing that VMs share base images of common operating systems or software stacks that remain unchanged over time, the CBase migration framework is implemented in [128] using a central repository of common base images. With CBase, a VM migration job consists of a base image, user data and memory migration, where the former two take place concurrently, followed by the latter. The authors enhance the scheme with a multilayered VM structure [127] leveraging the reuse of base images. The consistency of user data migration is ensured via snapshotting.
consecutive migration tasks: the first one using the pre-copy procedure and the remaining ones using post-copy. Anm-mixed strategy is also proposed to pre-copymVMs in parallel before serially migrating the remaining VMs using post-copy. A theoretical analysis based on multi-server queues enables the evaluation of different metrics for each migration. The authors conclude that it is feasible to implement the proposed strategies using Xen or the KVM hypervisor. Considering the VM migration over WANs, the approach proposed in [2] employs predictive analytics to reduce the downtime of live migrations. A regression tree is trained to decide the resource utilization thresholds after which a migration should occur. A set of heuristics based on the cost of migration (in terms of the number of CPUs or network usage) combined with the prediction of the VM’s future behavior is used to finally decide whether to migrate. The system improves itself as new data becomes available, and is evaluated via a simulated testing environment.
In [110], the authors propose an architecture and algorithm for container migration focused on mobile services and fog computing in large-scale environments. Migration costs are measured via communication delay and power consumption. The algorithm is based on a Markov decision process enhanced with a four-layer neural network and trained with a reinforcement learning strategy. Experimental validation in a testbed shows a 48.5% save in power consumption, and 59.5% reduction in total migration cost with respect to Q-learning.
The survey in [115] introduces a hierarchical classification of server consolidation techniques in cloud DCs, and then discusses their problems and challenges. The surveyed work is organized according to the operational objectives and costs of DCs, and cover different types of optimization methods aimed at addressing server consolidation and energy efficiency. Furthermore, another survey presented in [43] covers resource reconfiguration, primarily focusing on the adaptation of resource assignment in cloud computing, and includes references to fuzzy logic methods. A novel definition ofcloud adaptationis proposed, which separates the decision making process from the enacting of the reconfiguration. A set of key features used to classify research directions are derived, identifying open challenges.
PRESS is presented in [30] as an approach to predict the CPU usage workload of VMs and to decide the optimal resource-saving VM reconfiguration that still maintains service-level objectives. The approach seeks repetitive patterns through Fourier analysis, and resorts to a discrete-time Markov chain model if no pattern is found. The results are obtained in a virtual lab using synthetic data from RUBiS and real traces from Google, and compared against simpler approaches. The scheme in [70] predicts the future CPU usage of VMs through Brown’s quadratic exponential smoothing, complemented with a genetic algorithm to find a VM configuration that can optimally manage the predicted workload. The performance of the proposed scheme is finally evaluated in a sizeable environment with more than 300 servers using artificially generated loads.
Recently, advanced machine learning techniques have been widely employed to tackle optimal VM migration. A two-level approach to manage the resource allocation of resources in a cloud environment is detailed in [63], with reinforcement learning by means of an autoencoder neural network at the global scale, along with a Long Short Term Memory (LSTM) neural network at the local level. The models are trained using Google data, and their validity is tested in simulations. In [74], SVM and Q-learning are used to automatically and dynamically select which resources of non-urgent virtual networks should be migrated, and where, with the objective to migrate VMs while satisfying QoS requirements. The method is evaluated through simulations showing improvements over a static resource migration approach and a dynamic one with random selections.
4.2.4 Summary.Optimal application placement is mostly modeled as a graph problem [5,111,
117] and solved using classical linear programming techniques [6,26,106]. It can also be combined with computation offloading in order to increase the application performance and the quality of the user’s experience [120] but at the expense of higher communication costs and delays. The problem has been extensively studied in case of mobile services [34] and mostly from the point of view of energy saving [112]. The models are typically based on queuing theory [108] and Q-learning [25,74], although alternative approaches have been investigated, including decision trees [2], time series analysis [42], genetic algorithms [70] and neural networks [63].
4.3 Elasticity and Remediation
4.3.1 Load Balancing.Load balancing in combination with migration techniques can be
consid-ered as one of the key methods to realize system/application elasticity and remediation. In fact, redirecting and redistributing workload can improve the application throughput, thereby reducing the service latency and maintaining the robustness of the application. Moreover, in case recovery and remediation are needed to solve problems with the infrastructure and/or the application, the workload directed to migrated applications or components should be redistributed and balanced.
The study presented in [64] formulates a geographical load balancing problem with a cost function that factors in energy consumption and service delay. The main goal is to identify routing paths conveying workloads to DCs and a number of active servers at each DC, so as to minimize the cost function. Three distributed algorithms are proposed to generate provable optimal solutions. The first algorithm is implemented using the Gauss-Seidel method, while the last two are gradient-based and shown to converge to an optimal solution faster. The performance of three algorithms is evaluated and compared to that of existing ones, showing that the proposed solutions outperform solutions considering only the energy consumption or the service delay. Targeting geographical balancing, the authors of [15] propose a two-timescale resource allocation scheme to minimize the overall network cost, defined to reflect energy consumption. The scheme is implemented as a distributed algorithm dealing with long-term and short-term time scales separately, and considering multiple constraints including the computation capacity of DCs, operational costs, power supply, consumption and storage. The performance of the scheme is compared to that of local load balancing and other geographical balancing schemes. Results show that the proposed scheme can decrease the average network cost up to about 46% using data from production systems.
Recently, many studies have targeted at load balancing on microservices deployed on container-based cloud platforms. The one in [35] proposes a container scheduling technique to address the problem. The technique takes into account the attributes of every single container (e.g., size and resource demand) and the interaction between containerized services when carrying out placement and migration. A particle swarm optimization algorithm is adopted to realize the scheduling technique. The performance of the proposed technique is verified and compared to MOPSO [109] and the spread scheduling strategy widely adopted in microservices, showing that the proposed technique outperforms both, improving the system performance by 20% and 25%, respectively. The work introduced in [80] revisits the problem towards the minimization of the system response time. The authors propose an algorithm named COLBA, which is based on game theory and convex optimization, to solve the problem. The performance of the algorithm is evaluated via simulations and the results show that the system response time improves by up to 41% and 13% against the existing instance-oriented and microservice-oriented balancing techniques, respectively.
4.3.2 Application Scaling.Besides load balancing, application autoscaling plays a crucial role
to completely achieve application elasticity and remediation. By flexibly adjusting the amount of resources allocated for applications and/or the number of application instances or components, it is possible to adapt to workload fluctuations, which helps prevent the application from becoming unresponsive or terminating. It is worth noting that after performing the application scaling, the load balancing task should balance the workload at every instance of each application.
Aiming at a proactive dynamic resource provisioning for cloud applications, the study in [9] proposes a system consisting of an application provisioner, a load predictor and performance modeler, and a workload analyzer. A workload model is constructed using historical workload data and is updated continuously at runtime by the workload analyzer using ARIMA model. It is used for future workload predictions, which are then exploited by the provisioner to proactively allocate resources and satisfy QoS requirements. The prediction accuracy is evaluated through real data from Wikimedia’s web servers. Liuet al.address the problem by an adaptive workload prediction scheme and an autoscaling framework presented in [61]. To deal with workload prediction, the authors first formulate the workload classification as an integer programming problem, and then optimally solve the problem through branch and bound. The obtained solution is used to select an appropriate prediction model which is based on either linear regression or SVM. The performance and accuracy of the scheme are evaluated using real trace data obtained from Google cloud.
the model, a set of algorithms are proposed, which are deployed and operated on both the leader and the member servers, to maintain the largest number of servers operating in their respective optimal regime, so as to achieve overall energy efficiency.
In [88], Persicoet al.propose an horizontal scaling control system for cloud applications en-compassing a monitor, a fitness component, a controller, and an actuator. The system employs a proportional-integral-derivative (PID) feedback control mechanism. The PID controller is enhanced by fuzzy logic to be more adaptive in the presence of the unpredictable and time-varying workloads and resources’ demands of cloud applications. In addition, the fitness function can deal with multiple metrics (computational and network capacities) so as to meet the applications’ demands for different types of resources. The robustness and the remediation capability of the system are demonstrated through experiments with multiple realistic workloads in an Amazon EC2 environment.
With different focus, the authors of [79] study the impact of database tier on horizontal autoscal-ing in 3-tier web applications in the cloud environment, and implement an autoscalautoscal-ing simulator using the Queuing Network Model (QNM) and Layered QNM. First, they model the cloud ap-plication as a network of queues and analyze the response time, throughput, and the maximum amount of workload which can be handled by the application. Analytical results are then used for autoscaling. Finally, a simulation system is constructed with cloud applications deployed on an IaaS infrastructure and an autoscaler deployed to react to workload variations. The system is used for experiments to prove how such a scaling task affects the scaling decisions of the business tier ad how often SLA violations occur.
Elasticity for containerized edge-cloud applications has recently drawn attention from the research community. One exemplary work is presented in [87] tackling the problem of dynamic resource allocation for deep learning jobs, aiming at minimizing their total execution time. The authors propose a job scheduler, called Optimus, based on an online learning technique to construct performance models for the predictions of the jobs’ execution time. The scheduler is implemented and integrated with Kubernetes so as to schedule containerized ‘workers’ serving the jobs. The results show that Optimus outperforms the fairness-based scheduler [29] and Tetris [32] by up to 63% and 139% in terms of makespan and job completion time, respectively.
The authors of [51] propose a heuristic approach to control the elasticity of containerized mi-croservices. The proposed approach is realized by a Custom AUtoScaler (CAUS) mainly performing two complementary tasks: reactive container instance autoscaling in accordance to the changes of workload, and proactive container instances provisioning based on workload predictions. The approach is validated using synthetic workload under two test scenarios (with increase-decrease and spike workload patterns). Results show that CAUS reduces the duration of resource overprovi-sioning (in terms of the number of containers) up to approximately 30% when comparing to the strategy of overprovisioning with a fix amount of extra containers.
4.3.3 Summary.Load balancing is formulated as optimization problems in most of the cases,
4.4 Network Function Placement
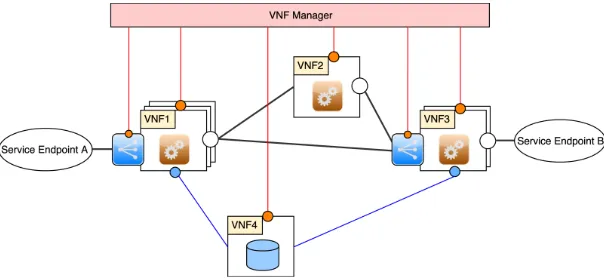
Network Function Virtualization (NFV) is known as a modern network architecture model based on the technology of server virtualization, that splits network functions into basic building blocks implemented as software components. The blocks are chained to create communication services. NFV differs from traditional architectures in that it runs on top of standard servers or cloud computing infrastructure, thus eliminating the demand for custom networking appliances. Thanks to virtualization technologies, NFV-based services, known as service function chains (SFCs), are easily entitled to scalability, elasticity, multi-tenancy support, fast deployment and configuration. The fast scalability and elasticity in turn enable service providers to efficiently maintain a certain degree of redundancy so as to support remediation for their services. Fig.6shows a simple architecture of an SFC with multiple virtualized network functions (VNFs) which can be deployed distributedly in edge-cloud environments.
Fig. 6. The architecture of an SFC implemented with three VNFs (VNF 1, 2, and 3), database service and load balancers. The VNF Manager manages and monitors the operations of all the VNFs. VNF1 and VNF3 are scaled with multiple instances independent of other VNFs.
An approach for VNF characterization based on CPU, memory, storage and network resources to be allotted for VNFs is proposed in [91]. The authors model the relationship between the amount of each resource and the achieved performance through a regression tree. The approach is validated through experiments using synthetic data in the context of a traffic classifier VNF which is deployed on top of OpenStack. Its performance is shown to highly depend on the specific characteristics of each network function.
from a university. The experimental results are compared to other policies (static and manual) and other machine learning techniques. A machine learning-based autoscaling engine which aims at scaling detection and decision-making tasks in NFV-based systems is proposed in [11]. For scaling detection, several machine learning techniques are applied to realize multiple classification models. The model training process relies on diverse historical data at both the (VNF) application-and infrastructure-level to achieve insight into the systems’ behaviors, thereby improving the detection accuracy. The relationship among VNF instances of SFCs is also exploited to compute a plan for flexible resource assignment based on outcomes of the scaling detection. The proposed methodology is evaluated using synthetic workloads for two VNFs: a Squid-based proxy and a Suricata-based intrusion detection. In both cases, the neural network model yields the best results. The work in [89] proposes a service chaining algorithm for VNFs. The applied method addresses main limitations of competing algorithms including the large convergence time and the constraint that the network configuration should remain static. The proposed algorithm employs genetic programming to generate a near-optimal solution two-order of magnitude faster than other linear programming algorithms. Additionally, the algorithm takes into account the changes in both computing resources and networking resources (given the latest advances in SDN). To show the effectiveness of the proposed algorithm, the obtained solution is evaluated using a custom testbed. The authors of [37] focus on simultaneously optimizing the cost and the latency of the placement of VNFs in SFCs. To this end, they propose an optimization framework employing a random selection of clouds and cloud resources combined with a predictive model based on support vector regression. The framework is evaluated using a combination of synthetic data generated using a queue-theoretic model and data gathered from a cloud testbed. The study in [52] proposes a reinforcement-learning based dynamic flow routing algorithm, which selects a path from a set of multiple paths for one SFC in an SDN/NFV environment. This is achieved by considering both the CPU usage of each node and the network bandwidth of the links between the nodes. The performance of the algorithm is evaluated in an artificial environment and compared with a classic greedy algorithm.
To cope with remediation, the problem of detecting and localizing network-related issues is investigated in [36]. The authors propose a predictive classification model to deal with the problem of NFV deployments within a multi-cloud environment. The model is developed based on a neural network model which adopts multiple machine learning techniques including typical “shallow” techniques (SVM, alternating decision tree, and random forest) and deep ones (the stacked autoen-coders). In this model, the detection checks if any issue occurs, and then determines the issue type using a shallow learning. Next, with deep learning, the localization locates the issue within the NFV-based system and estimates its impact on the system performance. The proposed model is validated using two different datasets: a real dataset of network faults from the Telstra network, and a synthetic dataset obtained by using a multivariate kernel density estimation technique enhanced with real live network issues.
The concept of Knowledge-Defined Network has been introduced recently in [69], which proposes to add aknowledge planeto the planes defined by a traditional SDN architecture. The knowledge plane is designated to exploit advantages of machine learning to address the most challenging problems of complex networks. The authors show four use cases illustrating the application of their proposal and provide solutions for two of them. The first one relates to routing on an overlay network, whereas the other revolves around NFV using real data from a university campus.
4.4.1 Summary. A wide range of problems regarding NFV is investigated, including VNF
5 DISCUSSION
5.1 Analysis and Categorization
Tackling the problem of reliable resource provisioning for edge-cloud applications requires address-ing an array of sub-problems includaddress-ing workload analysis and prediction, optimization in resource utilization at both the application and infrastructure levels. Numerous methods and schemes pro-posed for such purposes have been reviewed in the previous section. Most of them adopt one machine learning technique in their operational flow. Table1summarizes the techniques utilized in these methods and schemes. We remark that our paper has adopted a broad meaning for machine learning, which embraces both recent approaches using, e.g., deep neural networks (DNN) or complex graph analysis, as well as more classical approaches including Q-learning, reinforcement learning, Bayesian methods, and Markov models. In accordance with the definition provided in Section2.5, machine learning methods include all the models that can be trained using data in order to carry out supervised or unsupervised classification and regression tasks.
Table 1. Summary of techniques employed by the studies in the survey.
Applied Technique References
Regression (Logistic, LASSO, etc.) [4], [11], [50], [60], [61] Analytical models (Autocorrelation function (ACF), ARIMA, etc.) [9], [42], [56], [57], [123], [130]
Bayesian methods [22], [45], [100], [124]
Markov models [15], [19], [30], [48], [100], [110] Queuing theory-based models [14], [64], [79], [108], [120] Clustering (K-means, K-nearest neighbors, ...) [23], [45], [125]
Exponential ensembles [70], [102], [117], [119]
Artificial neural networks [11], [23], [36], [40], [53], [54], [59], [60], [63], [69], [72], [87], [97], [110], [123], [126], [130] Support vector machines [40], [23], [74], [102], [36], [37], [61], [124] Decision trees, Random forests [2], [6], [11], [23], [36], [67], [91], [124] Reinforcement Learning [25], [52], [63], [67], [74], [97], [110] Control theory, Game theory-based techniques [14], [34], [80], [88], [120] Linear programming, Geometric programming [5], [6], [26], [61], [106], [112] Genetic algorithms, Genetic programming [40], [54], [70], [88], [89]
Graph analysis [3], [5], [111], [117]
Distribution analysis [65], [107], [122]
Derivative-based and Gradient-based optimization [15], [64], [93] Agent-based and Heuristic-based methods [20], [25], [35], [51], [86], [97], [128]
From the present survey, it can be concluded that workload analysis and prediction is a critical task in large-scale cloud- and edge-based computing infrastructures, since high accurate predictions facilitate the dynamic reallocation of available resources to guarantee SLAs meanwhile saving energy and costs. However, workload prediction is in general a difficult endeavor, even more if the workload depends on unpredictable human activities (e.g. on web servers, CDNs, transportation system in smart cities). Classical approaches to workload prediction are based on autoregressive models, like ARIMA or GARCH. Recently, a new generation of data analysis models based on RNNs have been adopted, and extensive evaluations on them show promising results. Neural network models, e.g., LSTM, provide more accurate predictions on average than classical regressive models. Nevertheless, neural networks require an extremely large amount of training data and extensive computing time, and even the use of highly specialized hardware, like servers with GPUs.
of the fog and edge computing paradigms, where it is often critical to locate services near the user, so as to move computation capabilities instead of moving the data. Finding an optimal solution to the placement of VMs/containers on physical servers is a difficult problem that could become computationally intractable in case of large clusters, edge networks, or networks of IoT devices. Numerous algorithms have been evaluated to find approximate solutions, from the classical linear programming, to more advanced machine learning-based algorithms (decision trees, neural networks, and others). Multiple, and sometimes contradictory requirements can be used as part of the utility functions, and as input attributes to those functions. Making decisions on which parameters to use is a complex research problem by itself that can be addressed by means of applying machine learning techniques like principal component analysis.
Elasticity and remediation are two key functions to fully address the problem of reliable resource provisioning for edge-cloud applications, as they ensure the reliability and robustness of the ap-plications regardless the non-linear fluctuation of the workload over time. However, an optimal implementation of elasticity and remediation in heterogeneous distributed environments with resource virtualization using classic mathematical optimization techniques is computationally chal-lenging. This is because applications running in such an environment are dynamically distributed and highly unpredictable; and each application component may be subject to different workload. According to the reviews in Section4.3, all the proposed schemes require an understanding of workload characteristics in order to efficiently perform the autoscaling and remediation. Therefore, workload analysis and prediction based on time series analysis becomes the vital factor for the effi-ciency of the schemes, and especially so for the proactive schemes, as they require future workload forecasting to adjust the amount of resources allocated for applications beforehand. Our reviews also shows that many of studies apply queuing theory and graph theory to model the service latency, which is one of the KPIs that needs to be improved through autoscaling and remediation. Moreover, control theory combined with advanced machine learning optimization techniques has been used for constructing the autoscaling system or framework. As a result, it is worth considering an adoption of the machine learning techniques when deriving holistic solutions to the problem.
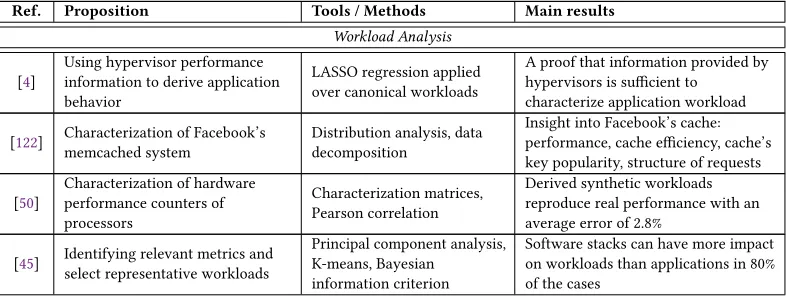
Table2provides a summary of problems studied by each of the reviewed papers, the tools and methods adopted, and a short quantitative summary of the achieved results. The works have been organized according to the subsections of Section4, and chronologically within each category. This clearly highlights that the use of complex machine learning and optimization techniques (e.g., deep learning, complex graph theory, and genetic algorithms) relates mainly to the most recent papers.
Table 2. Summary of the proposals, tools/methods, and main results of the studies in the survey.
Ref. Proposition Tools / Methods Main results
Workload Analysis
[4]
Using hypervisor performance information to derive application behavior
LASSO regression applied over canonical workloads
A proof that information provided by hypervisors is sufficient to
characterize application workload
[122] Characterization of Facebook’s memcached system
Distribution analysis, data decomposition
Insight into Facebook’s cache: performance, cache efficiency, cache’s key popularity, structure of requests
[50]
Characterization of hardware performance counters of processors
Characterization matrices, Pearson correlation
Derived synthetic workloads reproduce real performance with an average error of 2.8%
[45] Identifying relevant metrics and select representative workloads
Principal component analysis, K-means, Bayesian
information criterion