3721
ReCoSa: Detecting the Relevant Contexts with Self-Attention for
Multi-turn Dialogue Generation
Hainan Zhang, Yanyan Lan, Liang Pang, Jiafeng Guo and Xueqi Cheng CAS Key Lab of Network Data Science and Technology,
Institute of Computing Technology, Chinese Academy of Sciences University of Chinese Academy of Sciences, Beijing, China {zhanghainan,lanyanyan, pangliang, guojiafeng, cxq}@ict.ac.cn
Abstract
In multi-turn dialogue generation, response is usually related with only a few contexts. Therefore, an ideal model should be able to detect these relevant contexts and produce a suitable response accordingly. However, the widely used hierarchical recurrent encoder-decoder models just treat all the contexts indis-criminately, which may hurt the following re-sponse generation process. Some researchers try to use the cosine similarity or the tradi-tional attention mechanism to find the rele-vant contexts, but they suffer from either insuf-ficient relevance assumption or position bias problem. In this paper, we propose a new model, named ReCoSa, to tackle this problem. Firstly, a word level LSTM encoder is con-ducted to obtain the initial representation of each context. Then, the self-attention mecha-nism is utilized to update both the context and masked response representation. Finally, the attention weights between each context and re-sponse representations are computed and used in the further decoding process. Experimen-tal results on both Chinese customer services dataset and English Ubuntu dialogue dataset show that ReCoSa significantly outperforms baseline models, in terms of both metric-based and human evaluations. Further analysis on at-tention shows that the detected relevant con-texts by ReCoSa are highly coherent with hu-man’s understanding, validating the correct-ness and interpretability of ReCoSa.
1 Introduction
This paper is concerned with the multi-turn dia-logue generation task, which is critical in many natural language processing (NLP) applications, such as customer services, intelligent assistant and chatbot. Recently, the hierarchical recurrent encoder-decoder (HRED) models (Serban et al.,
2016;Sordoni et al.,2015) have been widely used in this area. In the encoding phase of these HRED
The fitst example context1 你好,在吗?(Hello)
context2 有什么问题我可以帮您呢?(What can I do for you?) context3 保真吗?(Is this product fidelity?)
response 我们的商品都是海外采购的 绝对保证是正品的
(Our products are all purchased overseas Absolutely guaranteed to be genuine)
The fitst example
context1 我有个交易纠纷,麻烦你看看有进度吗
(I have a trading dispute. Could you please tell me whether it is progressing? )
context2 您好,请问是这个订单吗?(Hello, is this order?) context3 对(Yes)
[image:1.595.313.522.223.355.2]response 等待纠纷处理(Waiting for dispute resolution)
Table 1: The two examples from the customer services dataset, and the red sentence indicates the relevant con-text to the response.
models, a recurrent neural network (RNN) based encoder is first utilized to encode each input a con-text to a vector, and then a hierarchical RNN is conducted to encode these vectors to one vector. In the decoding phase, another RNN decoder is used to generate the response based on the above vec-tor. The parameters of both encoder and decoder are learned by maximizing the averaged likelihood of the training data.
However, for this task, it is clear that the re-sponse is usually dependent on some relevant con-texts, rather than all the context information. Here we give two examples, as shown in Table 1. In the first example, the response is clearly related to the closest context, i.e. post, in the first exam-ple. While in the second example, the response is related to context1. In these cases, if we use all contexts indiscriminately, as in HRED, it is likely that many noises will be introduced to the model, and the generation performance will be hurt sig-nificantly. Therefore, it is critical to detect and use the relevant contexts for multi-turn dialogue gen-eration.
sim-ilarity measure, such as the cosine simsim-ilarity in Tian et al. (Tian et al.,2017). However, the cosine similarity is conducted between each context and the post, with the assumption that the relevance be-tween a context and a response is equivalent to the relevance between the context and the correspond-ing post, which is clearly insufficient in many cases, e.g. example 2 in Figure??. Some other re-searchers, e.g. Xing et al. (Xing et al.,2018) make an attempt by introducing the traditional attention mechanism to HRED. However, some related con-texts are far from the response in the multi-turn di-alogue generation task, and the RNN-based atten-tion model may not perform well because it usu-ally biases to the close contexts (Hochreiter et al.,
2001), namely position bias problem. Therefore, how to effectively detect and use the relevant con-texts remains a challenging problem in multi-turn dialogue generation.
In this paper, we propose a new model, namely ReCoSa, to tackle this problem. The core idea is to use the self-attention mechanism to measure the relevance between the response and each con-text. The motivation comes from the fact that self-attention is superior in capturing long dis-tant dependency, as shown in (Vaswani et al.,
2017). Specifically, we first use a word-level LSTM encoder to obtain the fixed-dimensional representation of each context. Then, we use the self-attention mechanism to get the context and masked response representations. Finally, we cal-culate the attention weight between the context and response representations as the relevant score, and conduct a decoder based on the related con-texts to generate the corresponding response.
In our experiments, we use two public datasets to evaluate our proposed models, i.e. Chinese cus-tomer services and English Ubuntu dialogue cor-pus. The results show that ReCoSa has the abil-ity to produce more diverse and suitable responses than traditional HRED models and its attention variants. Besides, we conduct an analysis on atten-tion, and the results show that the ReCoSa obtains higher coherence with the human labels, which in-dicate that the detected relevant contexts by our model are reasonable.
2 Related Work
Despite many existing research works on single-turn dialogue generation (Li et al., 2017; Mou et al.,2017;Zhang et al.,2018a,b), multi-turn
di-alogue generation has gain increasing attention. One reason is that it is more accordant with the real application scenario, such as chatbot and cus-tomer services. More importantly, the generation process is more difficult since there are more con-text information and constrains to consider (Chen et al.,2018;Zhang et al.,2018c,d;Wu et al.,2017;
Zhou et al., 2016), which poses great challenges
for researchers in this area.
Serban et al. (Serban et al., 2016) proposed HRED which uses the hierarchical encoder-decoder framework to model all the context sen-tences. Since then, the HRED based models have been widely used in different multi-turn di-alogue generation tasks, and many invariants have been proposed. For example, Serban et al. (
Ser-ban et al., 2017b,a) proposed Variable HRED
(VHRED) and MrRNN which introduce the latent variables into the middle state to improve the di-versity of generated responses.
con-texts (Hochreiter et al.,2001). Shen et al. (Chen
et al.,2018) introduced the memory network into
the VHRED model, so that the model can re-member the context information. Theoretically, it can retrieve some relevant information from the memory in the decoding phase, however, it is not clearly whether and how the system accurately ex-tracts the relevant contexts.
The motivation of this paper is how to effec-tively extract and use the relevant contexts for multi-turn dialogue generation. Different from previous studies, our proposed model can focus on the relevant contexts, with both long and short distant dependency relations, by using the self-attention mechanism.
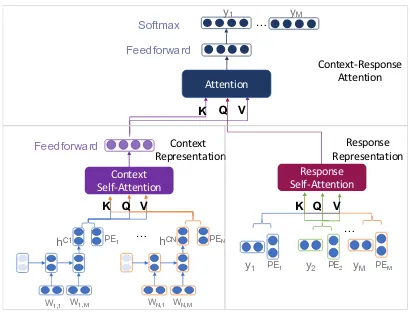
3 Relevant Context Self-Attention Model
In this section, we will describe our relevant con-text with self-attention (ReCoSa) model in de-tail, with architecture shown in Figure 1. Re-CoSa consists of a context representation encoder, a response representation encoder and a context-response attention decoder. For each part, we use the multi-head self-attention module to ob-tain the context representation, response represen-tation and the context-response attention weights. Firstly, the word-level encoder encodes each con-text as a low-dimension representation. And then, a multi-head self-attention component transforms these representations and position embeddings to the context attention representation. Secondly, an-other multi-head self-attention component trans-forms the masked response’s word embedding and position embedding to the response attention rep-resentation. Thirdly, the third multi-head atten-tion component feeds the context representaatten-tion as key and value, and the response representation as query in the context-response attention module. Finally, a softmax layer uses the output of the third multi-head attention component to obtain the word probability for the generation process.
3.1 Context Representation Encoder
We will introduce the main components of the context representation encoder in this section. The word-level encoder first encodes each context as a fixed vector. And then the context self-attention module transforms each sentence vector to a con-text representation.
Context Self-Attention
Attention
Response Self-Attention Context
Representation
…
Feedforward
Feedforward
Softmax y1 … yM
PE1 PEN
PE1 PE2 PEM
y1 y2 yM …
hC1 hCN
W1,1 W1,M WN,1 WN,M
K Q V K Q V K Q V
Response Representation Context-Response
[image:3.595.313.518.63.219.2]Attention
Figure 1: The architecture of ReCoSa model
3.1.1 Word-level Encoder
We first introduce the LSTM-based word level en-coder (Bahdanau et al.,2015) used in our model. Given the context set C = {s1, . . . , sN}, each sentence in C is defined as si = {x1, . . . , xM}. Please note that in our paper the post is treated as the last context sentencesN. Given a sentencesi
as the input, a standard LSTM first encodes each input context to a fixed-dimension vector hM as
follows.
ik=σ(Wi[hk−1, wk]), fk =σ(Wf[hk−1, wk]),
ok=σ(Wo[hk−1, wk]), lk= tanh(Wl[hk−1, wk]),
ck=fkck−1+iklk, hi =oktanh(ck),
whereik, fkandokare the input, memory and
out-put gate, respectively. wkis the word embedding
forxk, andhk stands for the vector computed by
LSTM at time kby combiningwk andhk−1. ck
is the cell at time k, and σ denotes the sigmoid function.Wi, Wf, WoandWlare parameters. We
use the vectorhM as the sentence representation. Therefore, we obtain the sentence representations
{hs1, . . . , hsN}.
It has been widely accepted that the self-attention mechanism itself cannot distinguish be-tween different positions. So it is crucial to encode each position information. Actually, there are var-ious ways to encode positions, and the simplest one is to use an additional position embedding. In our work, we parameterized position embed-dings Pi ∈ Rd, i = 1, . . . , N. The position
em-beddings are simply concatenated to the sentence representations. Finally, we obtain the sentences representation{(hs1, P
3.1.2 Context Self-Attention
Self-attention is a special attention mechanism to compute a sequence’s representation using only the sequence itself, which has been successfully applied to many tasks, such as machine transla-tion, reading comprehension, summarizatransla-tion, and language understanding (Vaswani et al., 2017;
Cheng et al., 2016; Parikh et al., 2016; Paulus et al., 2017; Shen et al., 2018). One critical ad-vantage of self-attention is that it has the ability to well capture the long distant dependency informa-tion (Vaswani et al.,2017). That’s why we use this mechanism in our work.
In this paper, we adopt the multi-head atten-tion (Vaswani et al., 2017) mechanism. Given a matrix of n query vectors Q ∈ Rn×d, keys
K ∈Rn×dand valuesV ∈
Rn×d, the scaled
dot-product attention computes the attention scores based on the following equation:
Attention(Q, K, V) =sof tmax(QK
T √
d )V,
wheredis the number of the hidden units in our network.
The H parallel heads are used to focus on dif-ferent parts of channels of the value vectors. For-mally, for the i-th head, we denote the learned linear maps by WiQ ∈ Rn×d/H,WiK ∈ Rn×d/H
andWiV ∈Rn×d/H, which correspond to queries,
keys, and values, respectively. Then the scaled dot-product attention is used to calculate the rel-evance score between queries and keys, to output mixed representations. The mathematical formu-lation is:
Mi=Attention(QWiQ, KW K
i , V WiV).
Finally, all the vectors produced by parallel heads are concatenated together to form a single vector. Again, a linear map is used to mix different chan-nels from different heads:
M =Concat(M1, . . . , MH),
O =M W, (1)
whereM ∈Rn×dandW ∈ Rd×d.
To obtain the context representation, the multi-head attention mechanism first feeds the matrix of sentences representation vectors
{(hs1, P
1), . . . ,(hsN, PN)}. as queries, keys
and values matrices by using different linear projections. Then the context representation is
computed as Os in equation 1. We use a
feed-forward network to output the context attention representationOsf.
3.2 Response Representation Encoder
Given the responseY ={y1,· · ·, yM}as the
in-put, another multi-head self-attention component transforms each word embedding and its posi-tion embedding to obtain the response representa-tion. For each wordyt, this multi-head attention
component feeds the matrix of response vectors
{(w1 +P1),· · ·,(wt−1, Pt−1)} as queries, keys and values matrices by using different linear pro-jections. Then the response’s hidden representa-tion is computed asOrin equation1.
After that, we use the mask operator on the re-sponse for the training. For each wordyt, we mask
{yt+1,· · · , yM}and only see{y1,· · · , yt−1}. For
inference, we use the loop function on the gener-ated responseG. Take thetthgeneration as an ex-ample. Given the contextC ={s1, . . . , sN}and
the generated response {g1,· · · , gt−1}, we feed {g1,· · · , gt−1} as the response representation to obtain the tth word distribution in the generation response.
3.3 Context-Response Attention Decoder
The third multi-head attention component feeds the context attention representationOsf as key and
value, and the response hidden representationOr
as query. The output is denoted as Od. We also
use a new feedforward network to obtain the hid-den vectorOfd, as conducted in section 3.1.2.
Finally, a softmax layer is utilized to obtain the word probability for the generation process. Formally, given an input context sequences C =
{s1, . . . , sN}, the log-likelihood of the
corre-sponding response sequence Y = {y1,· · · , yM}
is:
logP(Y|C;θ) =
M
X
t=1
logP(yt|C, y1,· · · , yt−1;θ).
Our model predicts the wordytbased on the hid-den representation Odf produced by the topmost softmax layer:
P(yt|C, y1,· · · , yt−1;θ) =P(yt|Ofs;θ)
=sof tmax(WoOsf),
ground-truth words given the input contexts over the entire training set. Adam is used for optimiza-tion in our experiments.
4 Experiments
In this section, we conduct experiments on both Chinese customer service and English Ubuntu di-alogue datasets to evaluate our proposed method.
4.1 Experimental Settings
We first introduce some empirical settings, includ-ing datasets, baseline methods, parameter settinclud-ings, and evaluation measures.
4.1.1 Datasets
We use two public multi-turn dialogue datasets in our experiments. The Chinese customer ser-vice dataset, named JDC, consists of 515,686 con-versational context-response pairs published by the JD contest1. We randomly split the data to training, validation, and testing sets, which contains 500,000, 7,843 and 7,843 pairs, respec-tively. The English Ubuntu dialogue corpus2 is extracted from the Ubuntu question-answering fo-rum, named Ubuntu (Lowe et al.,2015). The orig-inal training data consists of 7 million conversa-tions from 2004 to April 27,2012. The validation data are conversational pairs from April 27,2012 to August 7,2012, and the test data are from Au-gust 7,2012 to December 1,2012. We use the of-ficial script to tokenize, stem and lemmatize, and the duplicates and sentences with length less than 5 or longer than 50 are removed. Finally, we ob-tain 3,980,000, 10,000 and 10,000 pairs for train-ing, validation and testtrain-ing, respectively.
4.1.2 Baselines and Parameters Setting
Six baseline methods are used for comparison, including traditional Seq2Seq (Sutskever et al.,
2014), HRED (Serban et al.,2016), VHRED (
Ser-ban et al.,2017b), Weighted Sequence with
Con-cat (WSeq) (Tian et al., 2017), Hierarchical Re-current Attention Network (HRAN) (Xing et al.,
2018) and Hierarchical Variational Memory Net-work (HVMN) (Chen et al.,2018).
For JDC, we utilize the Chinese word as input. Specifically, we use the Jieba tool for word seg-mentation, and set the vocabulary size as 69,644. For Ubuntu, the word vocabulary size is set as
1
https://www.jddc.jd.com
2
https://github.com/rkadlec/ubuntu-ranking-dataset-creator
JDC Dataset
model PPL BLEU distinct-1 distinct-2 SEQ2SEQ 20.287 11.458 1.069 3.587 HRED 21.264 12.087 1.101 3.809 VHRED 22.287 11.501 1.174 3.695 WSeq 21.824 12.529 1.042 3.917 HRAN 20.573 12.278 1.313 5.753 HVMN 22.242 13.125 0.878 3.993 ReCoSa 17.282 13.797 1.135 6.590
Ubuntu Dataset
[image:5.595.321.513.66.221.2]model PPL BLEU distinct-1 disttinct-2 SEQ2SEQ 104.899 0.4245 0.808 1.120 HRED 115.008 0.6051 1.045 2.724 VHRED 186.793 0.5229 1.342 2.887 WSeq 141.599 0.9074 1.024 2.878 HRAN 110.278 0.6117 1.399 3.075 HVMN 164.022 0.7549 1.607 3.245 ReCoSa 96.057 1.6485 1.718 3.768
Table 2: The metric-based evaluation results (%).
15,000. For a fair comparison among all the base-line methods and our methods, the numbers of hid-den nodes are all set to 512, and batch sizes are set to 32. The max length of dialogue turns is 15 and the max sentence length is 50. The head number of ReCoSa model is set as 6. Adam is utilized for op-timization, and the learning rate is set to be 0.0001. We run all the models on a Tesla K80 GPU card with Tensorflow3.
4.1.3 Evaluation Measures
We use both quantitative metrics and human judgements for evaluation in our experiment. Specifically, we use two kinds of metrics for quan-titative comparisons. One kind is traditional met-rics, such as PPL and BLEU score (Xing et al.,
2017), to evaluate the quality of generated re-sponses. They are both widely used in NLP and multi-turn dialogue generation (Chen et al.,2018;
Tian et al.,2017;Xing et al.,2018). The other kind is the recently proposeddistinct(Li et al.,2016b), to evaluate the degree of diversity of the generated responses by calculating the number of distinct un-igrams and bun-igrams in the generated responses.
For human evaluation, given 300 randomly sampled context and their generated responses, three annotators (all CS majored students) are re-quired to give the comparison between ReCoSa model and baselines, e.g. win, loss and tie, based on the coherence of the generated response with respect to the contexts. For example, the win la-bel means that the generated response of ReCoSa is more proper than the baseline model.
JDC Dataset
model P@1 R@1 F1@1 P@3 R@3 F1@3 P@5 R@5 F1@5 P@10 R@10 F1@10 WSeq 35.20 29.73 16.12 24.27 51.49 16.50 21.61 71.76 16.61 17.45 97.17 14.79 HRAN 22.88 15.56 9.26 24.13 46.22 15.85 22.78 66.22 16.95 21.05 91.11 17.10 ReCoSa-head1 25.98 19.19 11.04 25.35 52.33 17.08 23.92 73.84 18.07 22.55 97.67 18.32
ReCoSa-head2 17.32 12.79 7.36 24.23 50.00 16.32 24.29 75.00 18.35 22.15 95.93 17.99 ReCoSa-head3 27.56 20.35 11.71 26.20 54.07 17.65 23.92 73.84 18.07 22.01 95.35 17.88 ReCoSa-head4 20.47 15.12 8.70 25.92 53.49 17.46 23.92 73.84 18.07 22.55 97.67 18.32
ReCoSa-head5 29.92 22.09 12.71 25.92 53.49 17.46 24.67 76.16 18.63 22.15 95.93 17.99 ReCoSa-head6 25.20 18.60 10.70 25.35 52.33 17.08 24.29 75.00 18.35 22.15 95.93 17.99
Table 3: The attention analysis results (%).
JDC Dataset
model ReCoSa vs. kappa win (%) loss (%) tie (%)
SEQ2SEQ 53.45 3.45 43.10 0.398 HRED 44.83 10.34 44.83 0.373 VHRED 50.00 6.90 43.10 0.369 WSeq 34.48 8.62 56.90 0.379 HRAN 24.14 13.79 62.07 0.384 HVMN 27.59 13.79 58.62 0.383
Ubuntu Dataset
model ReCoSa vs. kappa win (%) loss (%) tie (%)
SEQ2SEQ 55.32 2.13 42.55 0.445 HRED 44.68 8.51 46.81 0.429 VHRED 48.94 8.51 42.55 0.421 WSeq 25.53 14.89 59.57 0.440 HRAN 34.04 10.64 55.32 0.437 HVMN 27.66 12.77 59.57 0.434
Table 4: The human evaluation on JDC and Ubuntu.
4.2 Experimental Results
Now we demonstrate our experimental results on the two public datasets.
4.2.1 Metric-based Evaluation
The quantitative evaluation results are shown in Table 2. From the results, we can see that the attention-based models, such as WSeq, HRAN and HVMN, outperform the traditional HRED baselines in terms of BLEU and distinct-2 mea-sures. That’s because all these models further con-sider the relevance of the contexts in the optimiza-tion process. HRAN uses a tradioptimiza-tional attenoptimiza-tion mechanism to learn the importance of the con-text sentences. HVMN uses a memory network to remember the relevant context. But their ef-fects are both quite limited. Our proposed Re-CoSa performs the best. Take the BLEU score on JDC dataset for example, the BLEU score of Re-CoSa model is 13.797, which is significantly bet-ter than that of HRAN and HVMN, i.e., 12.278 and 13.125. The distinct scores of our model are also higher than baseline models, which in-dicate that our model can generate more diverse
responses. We have conducted the significant test, and the result shows that the improvements of our model are significant on both Chinese and En-glish datasets, i.e., p-value < 0.01. In summary, our ReCoSa model has the ability to produce high quality and diverse responses, as compared with baseline methods.
4.2.2 Human Evaluation
The human evaluation results are shown in Ta-ble 4. The percentage of win, loss and tie, as compared with the baselines, are given to evalu-ate the quality of generevalu-ated responses by ReCoSa. From the results, we can see that the percentage of win is always larger than that of loss, which shows that our ReCoSa model significantly out-performs baselines. Take JDC as an example. Compared with HRAN, WSeq and HVMN, the ReCoSa achieves preference gains (win subtracts loss) 10.35%, 25.86% and 13.8%, respectively. Kappa (Fleiss,1971) value is presented to demon-strate the consistency of different annotators. We also conducted the significant test, and the result shows that the improvements of our model are sig-nificant on both two datasets, i.e., p-value<0.01.
4.3 Analysis on Relevant Contexts
To verify whether the performance improvements are owing to the detected relevant contexts, we conduct a further data analysis, including both quantitative evaluation and case study. Specifi-cally, we randomly sample 500 context-response pairs from the JDC dataset, denoted as JDC-RCD4. Three annotators are employed (all CS PhD students) to label each context with respect to the human’s judgements. If a contextual sentence is related with the response, then it is labeled as 1. Otherwise it is labeled as 0. The kappa value of this labeled dataset is 0.514, indicting the consis-tance among different annotators.
Example1
context1 货物没有收到但是申请了退货 The goods were not received, but the return was applied
context2 请您稍等,马上为您查询 Please wait, I will check for you right away.
context3 这个申请什么时候能通过? When will this application pass?
response 这个订单已经发货了,需要到了站点之后处理 This order has been shipped and should be processed after shipping to the site. Seq2Seq 您好,请问有什么问题可以帮您? What can I do for you?
HRED 亲爱的客户,还麻烦您提供下订单号,妹子这边给您查询哦 Please give me your order ID. I will check for you now VHRED 您好,很高兴为您服务 I am very happy to serve you.
WSeq 申请中 Applying
HRAN 是已经完成了哦,系统无法拦截站点 It’s already done, and the system can’t intercept the site.
HVMN 建议等待呢 Please wait
[image:7.595.75.526.67.170.2]ReCoSa 亲爱的,查看到您的服务单还没有更新,请您耐心等待一下 Dear, check that your service order has not been updated yet. Please wait.
Table 5: The generated response Example1 from different models on JDC. The red contexts indicate the relevant context to the response.
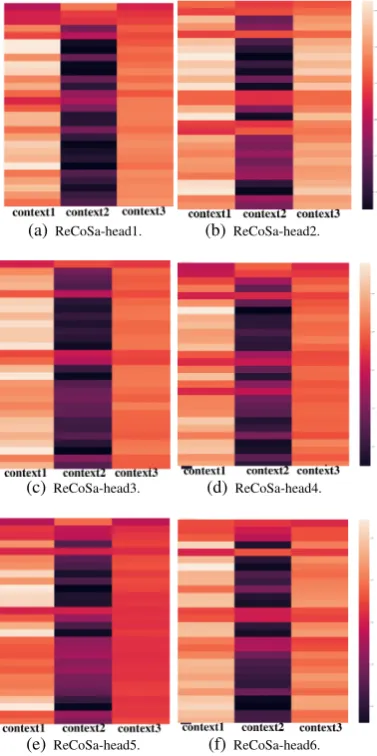
(a)ReCoSa-head1. (b)ReCoSa-head2.
(c)ReCoSa-head3. (d)ReCoSa-head4.
(e)ReCoSa-head5. (f) ReCoSa-head6.
Figure 2: ReCoSa multi-head attention for example1 in Table5. The x-coordinate shows the context sentences and the y-coordinate shows the generated words.
4.3.1 Quantitative Evaluation
Since HRED considers all the context as relevant context, we calculate the error rate for evaluation. That is, one minus the proportion of all-context-relevant in the JDC-RCD data, i.e. 98.4%. There-fore, using all contexts indiscriminately is highly
inappropriate for multi-turn dialogue generation. Other models, such as WSeq, HRAN and HVMN, will output the relevance score based on the attention weight for each context. Therefore we can treat it as a ranking problem. Ranking evaluation measures, such as the precision, re-call and F1 score, are used for quantitative eval-uations5. Then we calculate the precision, recall and F1 score of the top 1,3,5,10 for WSeq model, HRAN model and our ReCoSa model.6 The re-sults are shown in Table 3. We can see that the WSeq obtains the best score for P@1, R@1 and F1@1. That’s because there are 80% cases that the post is labeled as 1, and the cosine similarity can rank the explicitly similar context sentence as top 1. Though the WSeq has the best score for F1@1, it doesn’t work well for F1@3, F1@5 and F1@10. That’s because the WSeq may lose some relevant contexts which are not explicitly similar to the post but are related with the response. Compared with the HRAN and WSeq, ReCoSa performs better in most cases. Take P@3 for example, the P@3 score of ReCoSa-head3 is 26.2, which is significantly better than that of HRAN and WSeq, i.e., 24.13 and 24.27. These results indicate that the relevant contexts detected by our ReCoSa model are highly coherent with human’s judgments. Furthermore, we calculate the averaged attention distance to the response, defined as:
dis2resp=
N
X
i=1
N −i+ 1
N + 1 wi,
where i is the index of the context sentence si
andwi is the attention weight of theith context.
The dis2resp in human label is 0.399, indicting
5To clearly analyze the attention location, we only pay
attention to the context without the post. The reason is that the WSeq always rank the post as top1.
6The HVMN model doesn’t have the explicit attention
[image:7.595.94.283.229.608.2]Example2
context1 请稍等,正在为您确认此前咨询内容 Please wait, I am checking the previous requirement. context2 先直接退货再买吗? Should I return the goods firstly and buy it again? context3 是.收到了吧? Yes. Do you receive the goods?
context4 对,昨晚收到的 Yes, I received them last night.
response 那就只能无理由退了再买 You should return them and buy them again Seq2Seq 好的,亲爱滴请您稍等下哦 Ok, dear Please wait
HRED 可以的 Ok
VHRED 京东客服很高兴为您服务! JD customer services are happy to serve you. WSeq 请问还有其他的问题需要处理呢? Do you have any other questions?
HRAN 好.您可以换售后退货了哦 Ok, you can return the goods.
[image:8.595.326.519.263.660.2]HVMN 好的,正在查询!回复不够及时请见谅! Ok, Searching! Replying to you is not timely enough, sorry! ReCoSa 您申请售后,商品退回,重新下单购买 You can apply for sale, return the goods and place an order again
Table 6: The generated response Example2 from different models on JDC. The red contexts indicate the relevant context to the response.
that the distribution of human attention is approx-imately uniform, containing both long and short distant dependencies. The dis2resp in ReCoSa is 0.477, which is closer to human than the dis-tance in HRAN, e.g. 0.291. That is to say, our ReCoSa model can well capture the long distant dependency as compared with traditional attention on HRED, validating the correctness of our ideas.
4.3.2 Case Study
To facilitate a better understanding of our model, we give some cases as in Table5and6, and draw the heatmap of our ReCoSa model, including the six heads, to analyze the attention weights in Fig-ure2and3.
From the result, we can first see that the attention-based model performs better than the model using all contexts indiscriminately. Take example1 of Table 5 as an example. The base-lines of using all contexts are easy to generate some common responses, such as ‘What can I do for you?’ and ‘I am very happy to serve you. ’. The attention-based models, i.e. HRAN, WSeq, ReCoSa, can generate relevant response, such as ‘Applying’ and ‘It’ s already done, and the sys-tem can’ t intercept the site.’. The response gener-ated by our ReCoSa is more specific and relevant, i.e. ‘Your servers order has not been updated yet, please wait.’. The reason is that ReCoSA consid-ers the difference of contexts and it will focus on the relevant contexts, i.e. context1 and context3. Figure 2 shows the heatmap of example1 in Ta-ble 5. The x-coordinate indicates the context1, context2 and context3. And the y-coordinate in-dicates the generated words. The lighter the color is, the larger the attention weight is. We can see that the ReCoSa pays more attention to the
rele-(a) ReCoSa-head1. (b)ReCoSa-head2.
(c) ReCoSa-head3. (d)ReCoSa-head4.
(e) ReCoSa-head5. (f) ReCoSa-head6.
Figure 3: ReCoSa multi-head attention for example2 in Table6. The x-coordinate shows the context sentences and the y-coordinate shows the generated words.
Our model also performs well in the case where the post (i.e. the closest context) and the ground-truth response are not in the same topic. From the example2 in Table6, the baselines all produce ir-relevant or common responses, such as ‘Do you have any other questions?’ and ‘Ok, I am look-ing for you! Replylook-ing to you is not timely enough, sorry!’. The reason is that the baseline models are weak in detecting long distant dependency rela-tions. However, our model gives more relevant responses with specific meanings‘You could ap-ply for sale, return the goods and place an or-der again’, by using the self-attention mechanism. Figure 3 shows the heatmap of example2 in Ta-ble6. For example2, the context2 is the most sig-nificant context and the context1 is the most use-less one. We can see that the ReCoSa ignores the context1 and pays more attention to the context2. In a word, our ReCoSa model can detect both the long and short distant dependencies, even for the difficult case when the response is not related with the post.
5 Conclusion
In this paper, we propose a new multi-turn dia-logue generation model, namely ReCoSa. The motivation comes from the fact that the widely used HRED based models simply treat all contexts indiscriminately, which violate the important char-acteristic of multi-turn dialogue generation, i.e., the response is usually related to only a few con-texts. Though some researchers have considered using the similarity measure such as cosine or tra-ditional attention mechanism to tackle this prob-lem, the detected relevant contexts are not accu-rate, due to either insufficient relevance assump-tion or posiassump-tion bias problem. Our core idea is to utilize the self-attention mechanism to effectively capture the long distant dependency relations. We conduct extensive experiments on both Chinese customer services dataset and English Ubuntu di-alogue dataset. The experimental results show that our model significantly outperforms existing HRED models and its attention variants. Further-more, our further analysis show that the relevant contexts detected by our model are significantly coherent with humans’ judgements. Therefore, we obtain the conclusion that the relevant contexts can be useful for improving the quality of multi-turn dialogue generation, by using proper detec-tion methods, such as self-attendetec-tion.
In future work, we plan to further investigate the proposed ReCoSa model. For example, some topical information can be introduced to make the detected relevant contexts more accurate. In addi-tion, the detailed content information can be con-sidered in the relevant contexts to further improve the quality of generated response.
Acknowledgments
This work was funded by the National Natural Sci-ence Foundation of China (NSFC) under Grants No. 61773362, 61425016, 61472401, 61722211, and 61872338, the Youth Innovation Promotion Association CAS under Grants No.20144310, and 2016102, and the National Key R&D Program of China under Grants No. 2016QY02D0405. —
References
Dzmitry Bahdanau, Kyunghyun Cho, and Yoshua Ben-gio. 2015. Neural machine translation by jointly learning to align and translate. The International Conference on Learning Representations.
Hongshen Chen, Zhaochun Ren, Jiliang Tang, Yi-hong Eric Zhao, and Dawei Yin. 2018. Hierarchi-cal variational memory network for dialogue gener-ation. InProceedings of the 2018 World Wide Web Conference on World Wide Web, pages 1653–1662. International World Wide Web Conferences Steering Committee.
Jianpeng Cheng, Li Dong, and Mirella Lapata. 2016. Long short-term memory-networks for machine reading. InProceedings of the 2016 Conference on Empirical Methods in Natural Language Process-ing, pages 551–561.
Joseph L Fleiss. 1971. Measuring nominal scale agree-ment among many raters. American Psychological Association.
Sepp Hochreiter, Yoshua Bengio, Paolo Frasconi, J¨urgen Schmidhuber, et al. 2001. Gradient flow in recurrent nets: the difficulty of learning long-term dependencies.
Jiwei Li, Michel Galley, Chris Brockett, Jianfeng Gao, and Bill Dolan. 2016a. A diversity-promoting ob-jective function for neural conversation models. The North American Chapter of the Association for Computational Linguistics.
Jiwei Li, Will Monroe, Tianlin Shi, Alan Ritter, and Dan Jurafsky. 2017. Adversarial learning for neural dialogue generation. The Conference on Empirical Methods in Natural Language Processing.
Ryan Lowe, Nissan Pow, Iulian Serban, and Joelle Pineau. 2015. The ubuntu dialogue corpus: A large dataset for research in unstructured multi-turn dia-logue systems. Computer Science.
Lili Mou, Yiping Song, Rui Yan, Ge Li, Lu Zhang, and Zhi Jin. 2017. Sequence to backward and forward sequences: A content-introducing approach to gen-erative short-text conversation.The Annual Meeting of the Association for Computational Linguistics.
Ankur Parikh, Oscar T¨ackstr¨om, Dipanjan Das, and Jakob Uszkoreit. 2016. A decomposable attention model for natural language inference. In Proceed-ings of the 2016 Conference on Empirical Methods in Natural Language Processing, pages 2249–2255.
Romain Paulus, Caiming Xiong, and Richard Socher. 2017. A deep reinforced model for abstractive sum-marization.arXiv preprint arXiv:1705.04304.
Iulian V Serban, Alessandro Sordoni, Yoshua Bengio, Aaron Courville, and Joelle Pineau. 2016. Building end-to-end dialogue systems using generative hier-archical neural network models. InThirtieth AAAI Conference on Artificial Intelligence.
Iulian Vlad Serban, Tim Klinger, Gerald Tesauro, Kar-tik Talamadupula, Bowen Zhou, Yoshua Bengio, and Aaron Courville. 2017a. Multiresolution recur-rent neural networks: An application to dialogue re-sponse generation. InThirty-First AAAI Conference on Artificial Intelligence.
Iulian Vlad Serban, Alessandro Sordoni, Ryan Lowe, Laurent Charlin, Joelle Pineau, Aaron Courville, and Yoshua Bengio. 2017b. A hierarchical latent variable encoder-decoder model for generating di-alogues. InThirty-First AAAI Conference on Artifi-cial Intelligence.
Tao Shen, Tianyi Zhou, Guodong Long, Jing Jiang, Shirui Pan, and Chengqi Zhang. 2018. Disan: Di-rectional self-attention network for rnn/cnn-free lan-guage understanding. InThirty-Second AAAI Con-ference on Artificial Intelligence.
Alessandro Sordoni, Yoshua Bengio, Hossein Vahabi, Christina Lioma, Jakob Grue Simonsen, and Jian-Yun Nie. 2015. A hierarchical recurrent encoder-decoder for generative context-aware query sugges-tion. InProceedings of the 24th ACM International on Conference on Information and Knowledge Man-agement, pages 553–562. ACM.
Ilya Sutskever, Oriol Vinyals, and Quoc V Le. 2014. Sequence to sequence learning with neural net-works. InThe Annual Conference on Neural Infor-mation Processing Systems, pages 3104–3112.
Zhiliang Tian, Rui Yan, Lili Mou, Yiping Song, Yan-song Feng, and Dongyan Zhao. 2017. How to make context more useful? an empirical study on context-aware neural conversational models. In Proceed-ings of the 55th Annual Meeting of the Association for Computational Linguistics (Volume 2: Short Pa-pers), volume 2, pages 231–236.
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Łukasz Kaiser, and Illia Polosukhin. 2017. Attention is all you need. InAdvances in Neural Information Pro-cessing Systems, pages 5998–6008.
Yu Wu, Wei Wu, Chen Xing, Ming Zhou, and Zhou-jun Li. 2017. Sequential matching network: A new architecture for multi-turn response selection in retrieval-based chatbots. Proceedings of the 55th Annual Meeting of the Association for Computa-tional Linguistics.
Chen Xing, Wei Wu, Yu Wu, Jie Liu, Yalou Huang, Ming Zhou, and Wei-Ying Ma. 2017. Topic aware neural response generation. InThe Association for the Advancement of Artificial Intelligence, pages 3351–3357.
Chen Xing, Yu Wu, Wei Wu, Yalou Huang, and Ming Zhou. 2018. Hierarchical recurrent attention net-work for response generation. In Thirty-Second AAAI Conference on Artificial Intelligence.
Hainan Zhang, Yanyan Lan, Jiafeng Guo, Jun Xu, and Xueqi Cheng. 2018a. Reinforcing coherence for se-quence to sese-quence model in dialogue generation. InInternational Joint Conference on Artificial Intel-ligence, pages 4567–4573.
Hainan Zhang, Yanyan Lan, Jiafeng Guo, Jun Xu, and Xueqi Cheng. 2018b. Tailored sequence to sequence models to different conversation scenarios. In Pro-ceedings of the 56th Annual Meeting of the Associa-tion for ComputaAssocia-tional Linguistics (Volume 1: Long Papers), volume 1, pages 1479–1488.
Weinan Zhang, Yiming Cui, Yifa Wang, Qingfu Zhu, Lingzhi Li, Lianqiang Zhou, and Ting Liu. 2018c. Context-sensitive generation of open-domain con-versational responses. InProceedings of the 27th In-ternational Conference on Computational Linguis-tics, pages 2437–2447.
Zhuosheng Zhang, Jiangtong Li, Pengfei Zhu, Hai Zhao, and Gongshen Liu. 2018d. Modeling multi-turn conversation with deep utterance aggregation.
Proceedings of the 56th Annual Meeting of the As-sociation for Computational Linguistics.
Xiangyang Zhou, Daxiang Dong, Hua Wu, Shiqi Zhao, Dianhai Yu, Hao Tian, Xuan Liu, and Rui Yan. 2016. Multi-view response selection for human-computer conversation. In Proceedings of the 2016 Confer-ence on Empirical Methods in Natural Language Processing, pages 372–381.