Word Sense Disambiguation Improves Information Retrieval
Zhi Zhong and Hwee Tou Ng
Department of Computer Science National University of Singapore 13 Computing Drive, Singapore 117417 {zhongzhi, nght}@comp.nus.edu.sg
Abstract
Previous research has conflicting conclu-sions on whether word sense disambiguation (WSD) systems can improve information re-trieval (IR) performance. In this paper, we propose a method to estimate sense distribu-tions for short queries. Together with the senses predicted for words in documents, we propose a novel approach to incorporate word senses into the language modeling approach to IR and also exploit the integration of syn-onym relations. Our experimental results on standardTRECcollections show that using the word senses tagged by a supervised WSD sys-tem, we obtain significant improvements over a state-of-the-art IR system.
1 Introduction
Word sense disambiguation (WSD) is the task of identifying the correct meaning of a word in context. As a basic semantic understanding task at the lexi-cal level, WSD is a fundamental problem in natural language processing. It can be potentially used as a component in many applications, such as machine translation (MT) and information retrieval (IR).
In recent years, driven by Senseval/Semeval workshops, WSD systems achieve promising perfor-mance. In the application of WSD to MT, research has shown that integrating WSD in appropriate ways significantly improves the performance of MT sys-tems (Chan et al., 2007; Carpuat and Wu, 2007).
In the application to IR, WSD can bring two kinds of benefits. First, queries may contain ambiguous words (terms), which have multiple meanings. The
ambiguities of these query words can hurt retrieval precision. Identifying the correct meaning of the ambiguous words in both queries and documents can help improve retrieval precision. Second, query words may have tightly related meanings with other words not in the query. Making use of these relations between words can improve retrieval recall.
Overall, IR systems can potentially benefit from the correct meanings of words provided by WSD systems. However, in previous investigations of the usage of WSD in IR, different researchers arrived at conflicting observations and conclusions. Some of the early research showed a drop in retrieval per-formance by using word senses (Krovetz and Croft, 1992; Voorhees, 1993). Some other experiments ob-served improvements by integrating word senses in IR systems (Sch¨utze and Pedersen, 1995; Gonzalo et al., 1998; Stokoe et al., 2003; Kim et al., 2004).
This paper proposes the use of word senses to improve the performance of IR. We propose an ap-proach to annotate the senses for short queries. We incorporate word senses into the language modeling (LM) approach to IR (Ponte and Croft, 1998), and utilize sense synonym relations to further improve the performance. Our evaluation on standardTREC1
data sets shows that supervised WSD outperforms two other WSD baselines and significantly improves IR.
The rest of this paper is organized as follows. In Section 2, we first review previous work using WSD in IR. Section 3 introduces the LM approach to IR, including the pseudo relevance feedback method. We describe our WSD system and the method of
1http://trec.nist.gov/
generating word senses for query terms in Section 4, followed by presenting our novel method of in-corporating word senses and their synonyms into the LM approach in Section 5. We present experiments and analyze the results in Section 6. Finally, we con-clude in Section 7.
2 Related Work
Many previous studies have analyzed the benefits and the problems of applying WSD to IR. Krovetz and Croft (1992) studied the sense matches between terms in query and the document collection. They concluded that the benefits of WSD in IR are not as expected because query words have skewed sense distribution and the collocation effect from other query terms already performs some disambiguation. Sanderson (1994; 2000) used pseudowords to intro-duce artificial word ambiguity in order to study the impact of sense ambiguity on IR. He concluded that because the effectiveness of WSD can be negated by inaccurate WSD performance, high accuracy of WSD is an essential requirement to achieve im-provement. In another work, Gonzaloet al.(1998) used a manually sense annotated corpus, SemCor, to study the effects of incorrect disambiguation. They obtained significant improvements by representing documents and queries with accurate senses as well as synsets (synonym sets). Their experiment also showed that with the synset representation, which included synonym information, WSD with an error rate of 40%–50% can still improve IR performance. Their later work (Gonzalo et al., 1999) verified that part of speech (POS) information is discriminatory for IR purposes.
Several works attempted to disambiguate terms in both queries and documents with the senses pre-defined in hand-crafted sense inventories, and then used the senses to perform indexing and retrieval. Voorhees (1993) used the hyponymy (“IS-A”) rela-tion in WordNet (Miller, 1990) to disambiguate the polysemous nouns in a text. In her experiments, the performance of sense-based retrieval is worse than stem-based retrieval on all test collections. Her anal-ysis showed that inaccurate WSD caused the poor results.
Stokoe et al. (2003) employed a fine-grained WSD system with an accuracy of 62.1% to
dis-ambiguate terms in both the text collections and the queries in their experiments. Their evalua-tion on TREC collecevalua-tions achieved significant im-provements over a standard term based vector space model. However, it is hard to judge the effect of word senses because of the overall poor perfor-mances of their baseline method and their system.
Instead of using fine-grained sense inventory, Kim
et al. (2004) tagged words with 25 root senses of nouns in WordNet. Their retrieval method main-tained the stem-based index and adjusted the term weight in a document according to its sense match-ing result with the query. They attributed the im-provement achieved on TREC collections to their coarse-grained, consistent, and flexible sense tag-ging method. The integration of senses into the tra-ditional stem-based index overcomes some of the negative impact of disambiguation errors.
Different from using predefined sense inventories, Sch¨utze and Pedersen (1995) induced the sense in-ventory directly from the text retrieval collection. For each word, its occurrences were clustered into senses based on the similarities of their contexts. Their experiments showed that using senses im-proved retrieval performance, and the combination of word-based ranking and sense-based ranking can further improve performance. However, the cluster-ing process of each word is a time consumcluster-ing task. Because the sense inventory is collection dependent, it is also hard to expand the text collection without re-doing preprocessing.
Many studies investigated the expansion effects by using knowledge sources from thesauri. Some researchers achieved improvements by expanding the disambiguated query words with synonyms and some other information from WordNet (Voorhees, 1994; Liu et al., 2004; Liu et al., 2005; Fang, 2008). The usage of knowledge sources from WordNet in document expansion also showed improvements in IR systems (Cao et al., 2005; Agirre et al., 2010).
interest-ing to investigate the utilization of semantic relations among senses in IR.
3 The Language Modeling Approach to IR
This section describes the LM approach to IR and the pseudo relevance feedback approach.
3.1 The language modeling approach
In the language modeling approach to IR, language models are constructed for each query q and each documentdin a text collection C. The documents inC are ranked by the distance to a given queryq
according to the language models. The most com-monly used language model in IR is the unigram model, in which terms are assumed to be indepen-dent of each other. In the rest of this paper, language model will refer to the unigram language model.
One of the commonly used measures of the sim-ilarity between query model and document model is negative Kullback-Leibler (KL) divergence (Laf-ferty and Zhai, 2001). With unigram model, the neg-ative KL-divergence between model θq of query q and modelθdof documentdis calculated as follows:
−D(θq||θd) =−X
t∈V
p(t|θq) logp(t|θq) p(t|θd)
=X
t∈V
p(t|θq) logp(t|θd)−X
t∈V
p(t|θq) logp(t|θq)
=X
t∈V
p(t|θq) logp(t|θd) +E(θq), (1)
wherep(t|θq)andp(t|θd)are the generative proba-bilities of a termtfrom the modelsθq andθd,V is the vocabulary ofC, andE(θq)is the entropy ofq.
Definetf(t, d)andtf(t, q)as the frequencies oft
indandq, respectively. Normally,p(t|θq)is calcu-lated with maximum likelihood estimation (MLE):
p(t|θq) = P tf(t,q)
t0∈qtf(t0,q)
. (2)
In the calculation of p(t|θd), several smoothing methods have been proposed to overcome the data sparseness problem of a language model constructed from one document (Zhai and Lafferty, 2001b). For example,p(t|θd)with the Dirichlet-prior smoothing can be calculated as follows:
p(t|θd) =
tf(t, d) +µ p(t|θC) P
t0∈V tf(t0, d) +µ
, (3)
whereµis the prior parameter in the Dirichlet-prior smoothing method, andp(t|θC)is the probability of
tinC, which is often calculated with MLE:
p(t|θC) = P
d0∈Ctf(t,d
0)
P
d0∈C
P
t0∈V tf(t0,d0) .
3.2 Pseudo relevance feedback
Pseudo relevance feedback (PRF) is widely used in IR to achieve better performance. It is constructed with two retrieval steps. In the first step, ranked doc-uments are retrieved from C by a normal retrieval method with the original queryq. In the second step, a number of terms are selected from the topkranked documents Dq for query expansion, under the as-sumption that thesek documents are relevant to the query. Then, the expanded query is used to retrieve the documents fromC.
There are several methods to select expansion terms in the second step (Zhai and Lafferty, 2001a). For example, in Indri2, the terms are first ranked by the following score:
v(t, Dq) =P
d∈Dqlog(
tf(t,d)
|d| ×p(t|1θC)), as in Ponte (1998). Definep(q|θd)as the probability score assigned tod. The topmtermsTqare selected with weights calculated based on the relevance model described in Lavrenko and Croft (2001):
w(t, Dq) =Pd∈Dq htf(t,d)
|d| ×p(q|θd)×p(θd) i
,
which calculates the sum of weighted probabilities of t in each document. After normalization, the probability oftinθrqis calculated as follows:
p(t|θrq) = w(t,Dq)
P
t0∈Tqw(t0,Dq).
Finally, the relevance model is interpolated with the original query model:
p(t|θprfq ) =λ p(t|θqr) + (1−λ)p(t|θq), (4) where parameterλcontrols the amount of feedback. The new modelθqprf is used to replace the original oneθqin Equation 1.
Collection enrichment (CE) (Kwok and Chan, 1998) is a technique to improve the quality of the feedback documents by making use of an external target text collection X in addition to the original targetC in the first step of PRF. The usage ofX is supposed to provide more relevant feedback docu-ments and feedback query terms.
4 Word Sense Disambiguation
In this section, we first describe the construction of our WSD system. Then, we propose the method of assigning senses to query terms.
4.1 Word sense disambiguation system
Previous research shows that translations in another language can be used to disambiguate the meanings of words (Chan and Ng, 2005; Zhong and Ng, 2009). We construct our supervised WSD system directly from parallel corpora.
To generate the WSD training data, 7 parallel cor-pora were used, includingChinese Treebank,FBIS Corpus, Hong Kong Hansards, Hong Kong Laws, Hong Kong News, Sinorama News Magazine, and Xinhua Newswire. These corpora were already aligned at sentence level. We tokenized English texts withPenn Treebank Tokenizer, and performed word segmentation on Chinese texts. Then, word alignment was performed on the parallel corpora with theGIZA++software (Och and Ney, 2003).
For each English morphological root e, the En-glish sentences containing its occurrences were ex-tracted from the word aligned output of GIZA++, as well as the corresponding translations of these occurrences. To minimize noisy word alignment result, translations with no Chinese character were deleted, and we further removed a translation when it only appears once, or its frequency is less than 10 and also less than 1% of the frequency ofe. Finally, only the most frequent 10 translations were kept for efficiency consideration.
The English part of the remaining occurrences were used as training data. Because multiple En-glish words may have the same Chinese transla-tion, to differentiate them, each Chinese translation is concatenated with the English morphological root to form a word sense. We employed a supervised WSD system,IMS3, to train the WSD models. IMS (Zhong and Ng, 2010) integrates multiple knowl-edge sources as features. We used MaxEnt as the machine learning algorithm. Finally, the system can disambiguate the words by assigning probabilities to different senses.
3http://nlp.comp.nus.edu.sg/software/ims
4.2 Estimating sense distributions for query terms
In IR, both terms in queries and the text collection can be ambiguous. Hence, WSD is needed to disam-biguate these ambiguous terms. In most cases, doc-uments in a text collection are full articles. There-fore, a WSD system has sufficient context to dis-ambiguate the words in the document. In contrast, queries are usually short, often with only two or three terms in a query. Short queries pose a chal-lenge to WSD systems since there is insufficient context to disambiguate a term in a short query.
One possible solution to this problem is to find some text fragments that contain a query term. Sup-pose we already have a basic IR method which does not require any sense information, such as the stem-based LM approach. Similar to the PRF method, assuming that the topk documents retrieved by the basic method are relevant to the query, thesek docu-ments can be used to represent queryq(Broder et al., 2007; Bendersky et al., 2010; He and Wu, 2011). We propose a method to estimate the sense probabilities of each query term ofq from these top k retrieved documents.
Suppose the words in all documents of the text collection are disambiguated with a WSD system, and each word occurrencew in document d is as-signed a vector of senses,S(w). Define the proba-bility of assigning sensestowasp(w, s, d). Given a queryq, supposeDqis the set of topkdocuments retrieved by the basic method, with the probability scorep(q|θd)assigned tod∈Dq.
Given a query termt ∈q S(t, q) ={}
sum= 0
for each documentd∈Dq
for each word occurrencew∈d, whose stem form is identical to the stem form oft
for each senses∈S(w)
S(t, q) =S(t, q)∪ {s}
p(t, s, q) =p(t, s, q) +p(q|θd)p(w, s, d)
sum=sum+p(q|θd)p(w, s, d)
for each senses∈S(t, q)
p(t, s, q) =p(t, s, q)/sum
ReturnS(t, q), with probabilityp(t, s, q)fors∈S(t, q)
Figure 1: Process of generating senses for query terms
sense distribution for a query termtinq withDq, whereS(t, q) is the set of senses assigned totand
p(t, s, q) is the probability of taggingt as sense s. Basically, we utilized the sense distribution of the words with the same stem form inDq as a proxy to estimate the sense probabilities of a query term. The retrieval scores are used to weight the information from the corresponding retrieved documents inDq.
5 Incorporating Senses into Language Modeling Approaches
In this section, we propose to incorporate senses into the LM approach to IR. Then, we describe the inte-gration of sense synonym relations into our model.
5.1 Incorporating senses as smoothing
With the method described in Section 4.2, both the terms in queries and documents have been sense tagged. The next problem is to incorporate the sense information into the language modeling approach.
Supposep(t, s, q) is the probability of tagging a query term t ∈ q as sense s, and p(w, s, d) is the probability of tagging a word occurrencew ∈ d as senses. Given a queryq and a documentd in text collectionC, we want to re-estimate the language models by making use of the sense information as-signed to them.
Define the frequency ofsindas:
stf(s, d) =P
w∈dp(w, s, d), and the frequency ofsinCas:
stf(s, C) =P
d∈Cstf(s, d).
Define the frequencies of sense setSindandCas:
stf(S, d) =P
s∈Sstf(s, d),
stf(S, C) =P
s∈Sstf(s, C).
For a termt∈q, with sensesS(t, q):{s1, ..., sn}, suppose V:{p(t, s1, q), ..., p(t, sn, q)} is the vector of probabilities assigned to the senses of t and
W:{stf(s1, d), ...,stf(sn, d)} is the vector of fre-quencies of S(t, q) in d. The function cos(t, q, d)
calculates the cosine similarity between vector V
and vector W. Assume D is a set of documents inC which contain any sense inS(t, q), we define functioncos(t, q) = P
d∈Dcos(t, q, d)/|D|, which calculates the mean of the sense cosine similarities, and define function ∆cos(t, q, d) = cos(t, q, d)−
cos(t, q), which calculates the difference between
cos(t, q, d)and the corresponding mean value. Given a query q, we re-estimate the term fre-quency of query termtind with sense information integrated as smoothing:
tfsen(t, d) =tf(t, d) +sen(t, q, d), (5)
where functionsen(t, q, d)is a measure oft’s sense information ind, which is defined as follows:
sen(t, q, d) =α∆cos(t,q,d)stf(S(t, q), d). (6)
In sen(t, q, d), the last item stf(S(t, q), d) calcu-lates the sum of the sense frequencies oftsenses in
d, which represents the amount oft’s sense informa-tion ind. The first itemα∆cos(t,q,d)is a weight of the sense information concerning the relative sense sim-ilarity∆cos(t, q, d), whereα is a positive parame-ter to control the impact of sense similarity. When
∆cos(t, q, d)is larger than zero, such that the sense similarity ofdandq according totis above the av-erage, the weight for the sense information is larger than 1; otherwise, it is less than 1. The more similar they are, the larger the weight value. Fort /∈q, be-cause the sense setS(t, q) is empty, stf(S(t, q), d)
equals to zero andtfsen(t, d)is identical totf(t, d). With sense incorporated, the term frequency is in-fluenced by the sense information. Consequently, the estimation of probability oftindbecomes query specific:
p(t|θsend ) = tfsen(t, d) +µ p(t|θ
sen C ) P
t0∈V tfsen(t0, d) +µ
, (7)
where the probability oftinCis re-calculated as:
p(t|θCsen) = P
d0∈Ctfsen(t,d0) P
d0∈C
P
t0∈V tfsen(t0,d0).
5.2 Expanding with synonym relations
Words usually have some semantic relations with others. Synonym relation is one of the semantic re-lations commonly used to improve IR performance. In this part, we further integrate the synonym rela-tions of senses into the LM approach.
Suppose R(s) is the set of senses having syn-onym relation with senses. DefineS(q) as the set of senses of queryq,S(q) = S
t∈qS(t, q), and de-fineR(s, q)=R(s)−S(q). We update the frequency of a query termt ind by integrating the synonym relations as follows:
wheresyn(t, q, d)is a function measuring the syn-onym information ind:
syn(t, q, d) = X
s∈S(t)
β(s, q)p(t, s, q)stf(R(s, q), d).
The last item stf(R(s, q), d) in syn(t, q, d) is the sum of the sense frequencies ofR(s, q)ind. Notice that the synonym senses already appearing inS(q)
are not included in the calculation, because the infor-mation of these senses has been used in some other places in the retrieval function. The frequency of synonyms,stf(R(s, q), d), is weighted byp(t, s, q)
together with a scaling functionβ(s, q):
β(s, q) = min(1,stfstf(R((s,Cs,q)),C)).
Whenstf(s, C), the frequency of sense sin C, is less thanstf(R(s, q), C), the frequency of R(s, q)
inC, the function β(s, q) scales down the impact of synonyms according to the ratio of these two fre-quencies. The scaling function makes sure that the overall impact of the synonym senses is not greater than the original word senses.
Accordingly, we have the probability oftind up-dated to:
p(t|θdsyn) = tfsyn(t, d) +µ p(t|θ syn
C ) P
t0∈V tfsyn(t0, d) +µ
, (9)
and the probability oftinCis calculated as:
p(t|θsynC ) = P
d0∈Ctfsyn(t,d0) P
d0∈C
P
t0∈Vtfsyn(t0,d0).
With this language model, the probability of a query term in a document is enlarged by the synonyms of its senses; The more its synonym senses in a doc-ument, the higher the probability. Consequently, documents with more synonym senses of the query terms will get higher retrieval rankings.
6 Experiments
In this section, we evaluate and analyze the mod-els proposed in Section 5 on standard TREC collec-tions.
6.1 Experimental settings
We conduct experiments on the TREC collection. The text collectionC includes the documents from TREC disk 4 and 5, minus the CR (Congressional Record) corpus, with 528,155 documents in total. In
addition, the other documents in TREC disk 1 to 5 are used as the external text collectionX.
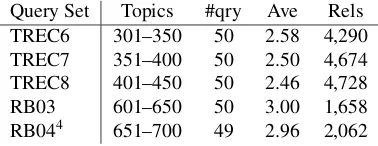
We use 50 queries from TREC6 Ad Hoc task as the development set, and evaluate on 50 queries from TREC7 Ad Hoc task, 50 queries from TREC8 Ad Hoc task, 50 queries from ROBUST 2003 (RB03), and 49 queries from ROBUST 2004 (RB04). In total, our test set includes 199 queries. We use the terms in the title field of TREC topics as queries. Table 1 shows the statistics of the five query sets. The first column lists the query topics, and the column#qryis the number of queries. The column
Avegives the average query length, and the column
Relsis the total number of relevant documents.
[image:6.612.331.520.267.340.2]Query Set Topics #qry Ave Rels TREC6 301–350 50 2.58 4,290 TREC7 351–400 50 2.50 4,674 TREC8 401–450 50 2.46 4,728 RB03 601–650 50 3.00 1,658 RB044 651–700 49 2.96 2,062
Table 1: Statistics of query sets
We use the Lemur toolkit (Ogilvie and Callan, 2001) version 4.11 as the basic retrieval tool, and se-lect the default unigram LM approach based on KL-divergence and Dirichlet-prior smoothing method in Lemur as our basic retrieval approach. Stop words are removed from queries and documents using the standard INQUERY stop words list (Allan et al., 2000), and then the Porter stemmer is applied to per-form stemming. The stem per-forms are finally used for indexing and retrieval.
We set the smoothing parameterµin Equation 3 to 400 by tuning on TREC6 query set in a range of
{100,400,700,1000,1500,2000,3000,4000,5000}. With this basic method, up to 10 top ranked docu-ments Dq are retrieved for each query q from the extended text collection C ∪X, for the usage of performing PRF and generating query senses.
For PRF, we follow the implementation of Indri’s PRF method and further apply the CE technique as described in Section 3.2. The number of terms se-lected from Dq for expansion is tuned from range
{20,25,30,35,40}and set to 25. The interpolation parameterλ in Equation 4 is set to 0.7 from range
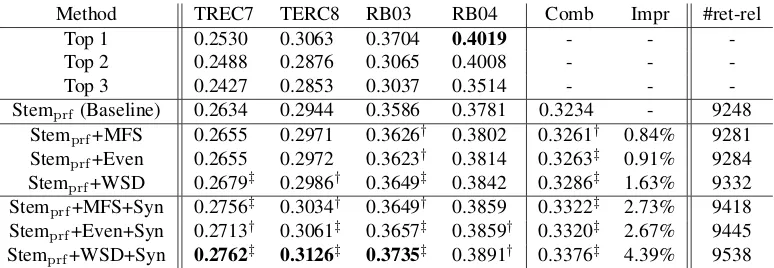
Method TREC7 TERC8 RB03 RB04 Comb Impr #ret-rel Top 1 0.2530 0.3063 0.3704 0.4019 - - -Top 2 0.2488 0.2876 0.3065 0.4008 - - -Top 3 0.2427 0.2853 0.3037 0.3514 - - -Stemprf(Baseline) 0.2634 0.2944 0.3586 0.3781 0.3234 - 9248
[image:7.612.114.501.65.199.2]Stemprf+MFS 0.2655 0.2971 0.3626† 0.3802 0.3261† 0.84% 9281 Stemprf+Even 0.2655 0.2972 0.3623† 0.3814 0.3263‡ 0.91% 9284 Stemprf+WSD 0.2679‡ 0.2986† 0.3649‡ 0.3842 0.3286‡ 1.63% 9332 Stemprf+MFS+Syn 0.2756‡ 0.3034† 0.3649† 0.3859 0.3322‡ 2.73% 9418 Stemprf+Even+Syn 0.2713† 0.3061‡ 0.3657‡ 0.3859† 0.3320‡ 2.67% 9445 Stemprf+WSD+Syn 0.2762‡ 0.3126‡ 0.3735‡ 0.3891† 0.3376‡ 4.39% 9538
Table 2: Results on test set in MAP score. The first three rows show the results of the top participating systems, the next row shows the performance of the baseline method, and the rest rows are the results of our method with different settings. Single dagger (†) and double dagger (‡) indicate statistically significant improvement overStemprf at the 95% and 99% confidence level with a two-tailed paired t-test, respectively. The best results are highlighted in bold.
{0.1,0.2, ...,0.9}. The CE-PRF method with this parameter setting is chosen as the baseline.
To estimate the sense distributions for terms in queryq, the method described in Section 4.2 is ap-plied withDq. To disambiguate the documents in the text collection, besides the usage of the super-vised WSD system described in Section 4.1, two WSD baseline methods,EvenandMFS, are applied for comparison. The method Even assigns equal probabilities to all senses for each word, and the methodMFS tags the words with their correspond-ing most frequent senses. The parameterαin Equa-tion 6 is tuned onTREC6from 1 to 10 in increment of 1 for each sense tagging method. It is set to 7, 6, and 9 for the supervised WSD method, the Even method, and the MFS method, respectively.
Notice that the sense in our WSD system is con-ducted with two parts, a morphological root and a Chinese translation. The Chinese parts not only dis-ambiguate senses, but also provide clues of connec-tions among different words. Assume that the senses with the same Chinese part are synonyms, there-fore, we can generate a set of synonyms for each sense, and then utilize these synonym relations in the method proposed in Section 5.2.
6.2 Experimental results
For evaluation, we use average precision (AP) as the metric to evaluate the performance on each queryq:
AP(q) = PR
r=1[p(r)rel(r)]
relevance(q) ,
whererelevance(q)is the number of documents rel-evant toq,Ris the number of retrieved documents,
r is the rank, p(r) is the precision of the topr re-trieved documents, andrel(r) equals to 1 if therth document is relevant, and 0 otherwise. Mean aver-age precision (MAP) is a metric to evaluate the per-formance on a set of queriesQ:
MAP(Q) = P
q∈QAP(q)
|Q| ,
where|Q|is the number of queries inQ.
We retrieve the top-ranked 1,000 documents for each query, and use the MAP score as the main com-paring metric. In Table 2, the first four columns are the MAP scores of various methods on the TREC7, TREC8, RB03, and RB04 query sets, respectively. The columnCombshows the results on the union of the four test query sets. The first three rows list the results of the top three systems that participated in the corresponding tasks. The rowStemprf shows the performance of our baseline method, the stem-based CE-PRF method. The columnImpr calculates the percentage improvement of each method over the baselineStemprf in columnComb. The last column
#ret-rellists the total numbers of relevant documents retrieved by different methods.
The rowsStemprf+{MFS,Even,WSD}are the re-sults ofStemprf incorporating with the senses gen-erated for the original query terms, by applying the approach proposed in Section 5.1, with the MFS
sta-tistically significant improvements overStemprf on TREC7, TREC8, and RB03.
The integration of senses into the baseline method has two aspects of impact. First, the morphologi-cal roots of senses conquer the irregular inflection problem. Thus, the documents containing the irreg-ular inflections are retrieved when senses are inte-grated. For example, in topic 326{ferry sinkings}, the stem form ofsinkingsissink. Assinkis an irreg-ular verb, the usage of senses improves the retrieval recall by retrieving the documents containing the in-flection formssunk,sank, andsunken.
Second, the senses output by supervised WSD system help identify the meanings of query terms. Take topic 357{territorial waters dispute}for ex-ample, the stem form ofwatersiswaterand its ap-propriate sense in this query should be water水域 (body of water) instead of the most frequent sense of water水(H2O). In Stemprf+WSD, we correctly identify the minority sense for this query term. In another example, topic 425{counterfeiting money}, the stem form of counterfeitingis counterfeit. Al-though the most frequent sense counterfeit冒牌 (not genuine) is not wrong, another sense counter-feit伪钞 (forged money) is more accurate for this query term. The Chinese translation in the latter sense represents the meaning of the phrase in orig-inal query. Thus, Stemprf+WSD outperforms the other two methods on this query by assigning the highest probability for this sense.
Overall, the performance ofStemprf+WSDis bet-ter thanStemprf+{MFS, Even}on 121 queries and 119 queries, respectively. The t-test at the confi-dence level of 99% indicates that the improvements are statistically significant.
The results of expanding with synonym relations in the above three methods are shown in the last three rows,Stemprf+{MFS,Even,WSD}+Syn. The integration of synonym relations further improves the performance no matter what kind of sense tag-ging method is applied. The improvement varies with different methods on different query sets. As shown in the last column of Table 2, the number of relevant documents retrieved is increased for each method. Stemprf+Even+Syn retrieves more rele-vant documents than Stemprf+MFS+Syn, because the former method expands more senses. Overall, the improvement achieved byStemprf+WSD+Synis
larger than the other two methods. It shows that the WSD technique can help choose the appropriate senses for synonym expansion.
Among the different settings,Stemprf+WSD+Syn achieves the best performance. Its improvement over the baseline method is statistically significant at the 95% confidence level on RB04 and at the 99% confidence level on the other three query sets, with an overall improvement of 4.39%. It beats the best participated systems on three out of four query sets5, includingTREC7, TREC8, and RB03.
7 Conclusion
This paper reports successful application of WSD to IR. We proposed a method for annotating senses to terms in short queries, and also described an ap-proach to integrate senses into an LM apap-proach for IR. In the experiment on four query sets of TREC collection, we compared the performance of a su-pervised WSD method and two WSD baseline meth-ods. Our experimental results showed that the incor-poration of senses improved a state-of-the-art base-line, a stem-based LM approach with PRF method. The performance of applying the supervised WSD method is better than the other two WSD base-line methods. We also proposed a method to fur-ther integrate the synonym relations to the LM ap-proaches. With the integration of synonym rela-tions, our best performance setting with the super-vised WSD achieved an improvement of 4.39% over the baseline method, and it outperformed the best participating systems on three out of four query sets.
Acknowledgments
This research is supported by the Singapore Na-tional Research Foundation under its InternaNa-tional Research Centre @ Singapore Funding Initiative and administered by the IDM Programme Office.
References
E. Agirre, X. Arregi, and A. Otegi. 2010. Document ex-pansion based on WordNet for robust IR. In Proceed-ings of the 23rd International Conference on Compu-tational Linguistics, pages 9–17.
5
J. Allan, M. E. Connell, W.B. Croft, F.F. Feng, D. Fisher, and X. Li. 2000. INQUERY and TREC-9. In Pro-ceedings of the 9th Text REtrieval Conference, pages 551–562.
M. Bendersky, W. B. Croft, and D. A. Smith. 2010. Structural annotation of search queries using pseudo-relevance feedback. InProceedings of the 19th ACM Conference on Information and Knowledge Manage-ment, pages 1537–1540.
A. Broder, M. Fontoura, E. Gabrilovich, A. Joshi, V. Josi-fovski, and T. Zhang. 2007. Robust classification of rare queries using web knowledge. In Proceedings of the 30th International ACM SIGIR Conference on Research and Development in Information Retrieval, pages 231–238.
G. Cao, J. Y. Nie, and J. Bai. 2005. Integrating word relationships into language models. In Proceedings of the 28th International ACM SIGIR Conference on Research and Development in Information Retrieval, pages 298–305.
M. Carpuat and D. Wu. 2007. Improving statisti-cal machine translation using word sense disambigua-tion. In Proceedings of the 2007 Joint Conference on Empirical Methods in Natural Language Process-ing and Computational Natural Language LearnProcess-ing, pages 61–72.
Y. S. Chan and H. T. Ng. 2005. Scaling up word sense disambiguation via parallel texts. In Proceed-ings of the 20th National Conference on Artificial In-telligence, pages 1037–1042.
Y. S. Chan, H. T. Ng, and D. Chiang. 2007. Word sense disambiguation improves statistical machine transla-tion. InProceedings of the 45th Annual Meeting of the Association for Computational Linguistics, pages 33–40.
H. Fang. 2008. A re-examination of query expansion us-ing lexical resources. InProceedings of the 46th An-nual Meeting of the Association of Computational Lin-guistics: Human Language Technologies, pages 139– 147.
J. Gonzalo, F. Verdejo, I. Chugur, and J. Cigarrin. 1998. Indexing with WordNet synsets can improve text re-trieval. InProceedings of the COLING-ACL Workshop on Usage of WordNet in Natural Language Processing Systems, pages 38–44.
J. Gonzalo, A. Penas, and F. Verdejo. 1999. Lexical ambiguity and information retrieval revisited. In Pro-ceedings of the 1999 Joint SIGDAT Conference on Em-pirical Methods in Natural Language Processing and Very Large Corpora, pages 195–202.
D. He and D. Wu. 2011. Enhancing query transla-tion with relevance feedback in translingual informa-tion retrieval.Information Processing & Management, 47(1):1–17.
S. B. Kim, H. C. Seo, and H. C. Rim. 2004. Informa-tion retrieval using word senses: root sense tagging ap-proach. InProceedings of the 27th International ACM SIGIR Conference on Research and Development in Information Retrieval, pages 258–265.
R. Krovetz and W. B. Croft. 1992. Lexical ambiguity and information retrieval. ACM Transactions on In-formation Systems, 10(2):115–141.
K. L. Kwok and M. Chan. 1998. Improving two-stage ad-hoc retrieval for short queries. In Proceedings of the 21st International ACM SIGIR Conference on Research and Development in Information Retrieval, pages 250–256.
J. Lafferty and C. Zhai. 2001. Document language mod-els, query modmod-els, and risk minimization for informa-tion retrieval. InProceedings of the 24th International ACM SIGIR Conference on Research and Develop-ment in Information Retrieval, pages 111–119. V. Lavrenko and W. B. Croft. 2001. Relevance based
language models. InProceedings of the 24th Interna-tional ACM SIGIR Conference on Research and De-velopment in Information Retrieval, pages 120–127. S. Liu, F. Liu, C. Yu, and W. Meng. 2004. An
ef-fective approach to document retrieval via utilizing WordNet and recognizing phrases. In Proceedings of the 27th International ACM SIGIR Conference on Research and Development in Information Retrieval, pages 266–272.
S. Liu, C. Yu, and W. Meng. 2005. Word sense disam-biguation in queries. InProceedings of the 14th ACM Conference on Information and Knowledge Manage-ment, pages 525–532.
G. A. Miller. 1990. WordNet: An on-line lexi-cal database. International Journal of Lexicography, 3(4):235–312.
F. J. Och and H. Ney. 2003. A systematic comparison of various statistical alignment models. Computational Linguistics, 29(1):19–51.
P. Ogilvie and J. Callan. 2001. Experiments using the Lemur toolkit. In Proceedings of the 10th Text RE-trieval Conference, pages 103–108.
J. M. Ponte and W. B. Croft. 1998. A language model-ing approach to information retrieval. InProceedings of the 21st International ACM SIGIR Conference on Research and Development in Information Retrieval, pages 275–281.
J. M. Ponte. 1998. A Language Modeling Approach to Information Retreival. Ph.D. thesis, Department of Computer Science, University of Massachusetts. M. Sanderson. 1994. Word sense disambiguation and
M. Sanderson. 2000. Retrieving with good sense. Infor-mation Retrieval, 2(1):49–69.
H. Sch¨utze and J. O. Pedersen. 1995. Information re-trieval based on word senses. InProceedings of the 4th Annual Symposium on Document Analysis and In-formation Retrieval, pages 161–175.
C. Stokoe, M. P. Oakes, and J. Tait. 2003. Word sense disambiguation in information retrieval revisited. In
Proceedings of the 26th International ACM SIGIR Conference on Research and Development in Informa-tion Retrieval, pages 159–166.
E. M. Voorhees. 1993. Using WordNet to disam-biguate word senses for text retrieval. InProceedings of the 16th International ACM SIGIR Conference on Research and Development in Information Retrieval, pages 171–180.
E. M. Voorhees. 1994. Query expansion using lexical-semantic relations. InProceedings of the 17th Inter-national ACM SIGIR Conference on Research and De-velopment in Information Retrieval, pages 61–69. C. Zhai and J. Lafferty. 2001a. Model-based feedback
in the language modeling approach to information re-trieval. InProceedings of the 10th ACM Conference on Information and Knowledge Management, pages 403–410.
C. Zhai and J. Lafferty. 2001b. A study of smoothing methods for language models applied to ad hoc infor-mation retrieval. InProceedings of the 24th Interna-tional ACM SIGIR Conference on Research and De-velopment in Information Retrieval, pages 334–342. Z. Zhong and H. T. Ng. 2009. Word sense
disambigua-tion for all words without hard labor. InProceedings of the 21st International Joint Conference on Artificial Intelligence, pages 1616–1621.