Elicitation of Association Rules from Information on Customs Offences on the Basis of Frequent Motives
Full text
Figure
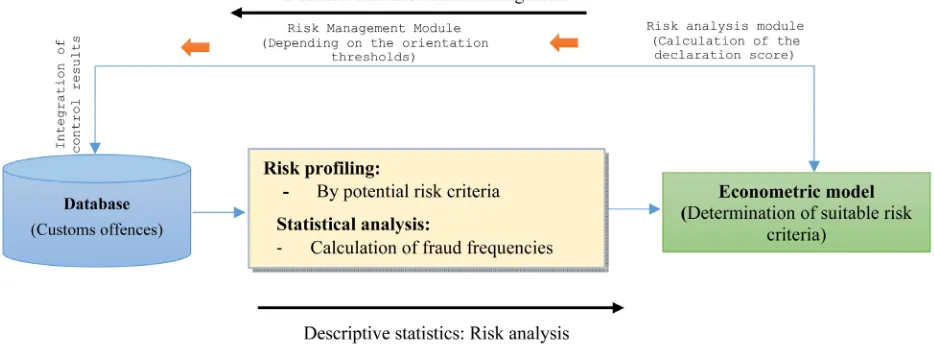
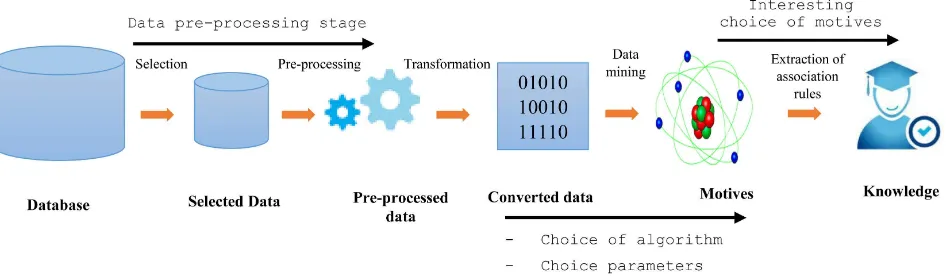
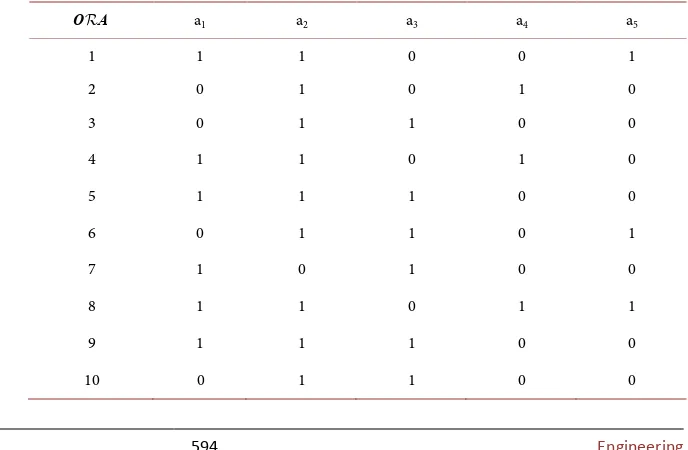



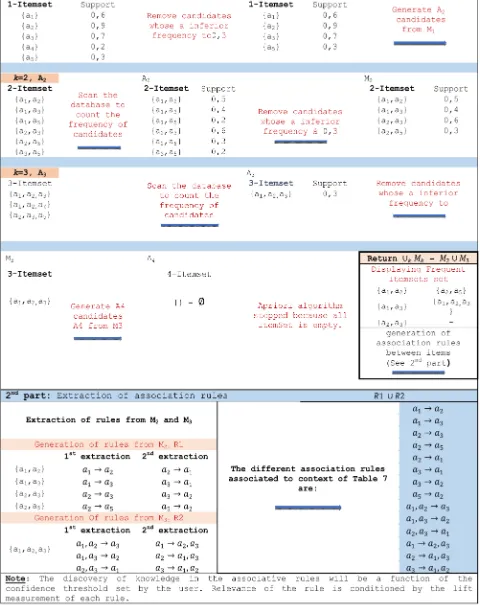


Related documents
Якщо після виконання вказівок «Посібника з усунення несправностей» і вимкнення та повторного ввімкнення приладу проблема не зникла і прилад не
– Education, licensure and/or professional work experience in a common law jurisdiction. – Typical assessment is
A new sizing method based on a numerical approach using the average meteorological data and the load demand of the Ngoundiane site along with both concepts of ALPSP and TLCC is
And he is certainly right to emphasize the gap between Carnap’s and Quine’s conceptions of the philosophical work of explication: whereas Carnap sought to dissolve metaphysical
The researcher concluded that agricultural Programmes identified by the respondents are not all implemented by government agencies, NGOs and Community especially:
There are infinitely many principles of justice (conclusion). 24 “These, Socrates, said Parmenides, are a few, and only a few of the difficulties in which we are involved if
If global citizenship is not a cultural value in the communities surrounding US schools and if education policy does not emphasize the importance of global
We recommend that you consider this independent information since Mercer is not responsible for, and does not evaluate or monitor, the solvency or ability of any insurance carrier
