Learning from Parenthetical Sentences for Term Translation in Machine
Translation
Guoping Huang and Jiajun Zhang and Yu Zhou and Chengqing Zong National Laboratory of Pattern Recognition,
Institute of Automation, Chinese Academy of Sciences, Beijing, China
{guoping.huang, jjzhang, yzhou, cqzong}@nlpr.ia.ac.cn
Abstract
Terms extensively exist in specific do-mains, and term translation plays a criti-cal role in domain-specific machine trans-lation (MT) tasks. However, it’s a chal-lenging task to translate them correctly for the huge number of pre-existing terms and the endless new terms. To achieve better term translation quality, it is nec-essary to inject external term knowledge into the underlying MT system. Fortu-nately, there are plenty of term transla-tion knowledge in parenthetical sentences on the Internet. In this paper, we pro-pose a simple, straightforward and effec-tive framework to improve term transla-tion by learning from parenthetical sen-tences. This framework includes: (1) a fo-cused web crawler; (2) a parenthetical tence filter, acquiring parenthetical sen-tences including bilingual term pairs; (3) a term translation knowledge extractor, ex-tracting bilingual term translation candi-dates; (4) a probability learner, generating the term translation table for MT decoders. The extensive experiments demonstrate that our proposed framework significantly improves the translation quality of terms and sentences.
1 Introduction
Terms, the linguistic representation of concepts, a noun or compound word used in a specific con-text, deliver essential context and meaning in hu-man languages, such as “interprocess communi-cation” or abbreviated as “IPC”. In this paper, we do not consider named entities (e.g., person names, location names, organization names, time and numbers). Terms extensively exist in
spe-cific domains. For example, in Microsoft Trans-lation Memory, there are 8 terms out of every 100 words, whereas names entities are nearly nonexis-tent. What’s more, new terms are being created all the time, such as in areas of computer science and medicine. Thus, term translation plays a critical role in domain-specific tasks of machine tions (MT), especially statistical machine transla-tion (SMT).
However, unlike person names or other named entities having obvious characteristics and bound-ary clues, it’s a challenging task to translate terms correctly for the huge number of pre-existing terms and the endless new terms. In practice, to achieve better term translation quality, it is neces-sary to inject external term knowledge into the un-derlying MT system. The best way is to import a bilingual technical term dictionary, such as such as Microsoft Terminology1. But the high cost makes it impossible to construct such bilingual dictio-nary by human experts for various domains. Thus how to learning bilingual term knowledge auto-matically becomes the key of term translation in domain-specific MT tasks.
The state-of-art term translation knowledge ex-traction methods tend to take the Internet as a big corpus (Ren et al.,2010). The most important as-sumption behind these methods is that the corre-sponding translation for every source term must exist somewhere on the web. Then, the term trans-lation pair extraction problem is converted to the task of finding these translations from the web and extract them correctly. As a result, except terms, the other various fragments, including multi-word expressions , will be extracted for the lack of term recognization. Not surprisingly, it has increased system workloads and directly reduces the quality of term translation.
1https://www.microsoft.com/Language/en-us/default.aspx
Example 1:A parenthetical sentence
不过各个进程有 自己 的内存空间、 数据 栈等 ,所以只能使用进进进程程程 间间间 通通通讯讯讯 ( interprocess
communication , IPC ),而不能直接共享信息。
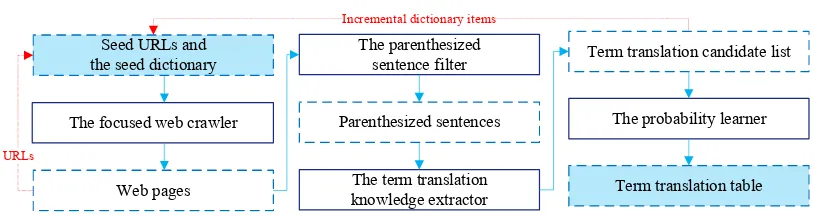
The focused web crawler Seed URLs and the seed dictionary
Web pages
The parenthesized sentence filter
The term translation knowledge extractor
The probability learner
Term translation table URLs
Parenthesized sentences
[image:2.595.95.502.113.221.2]Term translation candidate list Incremental dictionary items
Figure 1: An overview of learning from parenthetical sentences for term translation.
For the extraction of term translation knowl-edge, we should put quality before quantity. Thus, in this paper, we turn to parenthetical sentences in mix-language web pages for acquiring term trans-lation knowledge. In this work, a sentence will be calledparenthetical sentencewhen the following conditions are true: (1) the sentence contains one or more parentheses; (2) the phrase immediately to the left of the parenthesis is a term; (3) the cor-responding translation of the term is included in the parenthesis. The parenthetical sentence can be denoted ass=c1c2. . . cn(e1e2. . . em), where
c1c2. . . cn is a Chinese term and e1e2. . . em is its corresponding English translation. In this paper, the term included in the parenthesis and out of parentheses are referred to source term
(e1e2. . . em) andtarget term(c1c2. . . cn), respec-tively. A typical parenthetical sentence is shown as following Example 1.
In Example 1, the Chinese sentence contains one parenthesis, the phrase “进程 间 通讯” im-mediately to the left of the parenthesis is a target term, and the corresponding source term is “inter-process communication” or abbreviated as “IPC”. Therefore, it is a parenthetical sentence.
There are plenty of term translation knowledge in parenthetical sentences. Compared with paral-lel/comparable sentences, parenthetical sentences have fewer limits, update quickly and are easy to obtain. As we can see in Example 1, the main task for extracting the correct bilingual term pairs is to find the left boundary of the target term. Most im-portantly, the bilingual term pairs in parenthetical sentences have greater quality compared to other text in various web pages.
In this paper, in order to achieve high accuracy,
we propose a simple and effective framework to improve term translation by learning from paren-thetical sentences. The proposed framework in-cludes: (1) a focused web crawler, fetching and parsing relevant pages selectively; (2) a parenthet-ical sentence filter, acquiring parenthetparenthet-ical sen-tences including bilingual term pairs; (3) a term translation knowledge extractor, extracting bilin-gual term translation candidates; (4) a probability learner, generating the term translation table for MT decoders.
An overview of the proposed framework is shown in Figure 1. The input includes seed URLs and the seed dictionary. The final result is the term translation table with probabilities, being similar to phrase translation table in MT. In the processing flow, the intermediate results include the crawled web pages, extracted URLs, the filtered paren-thetical sentences, the extracted incremental dic-tionary items and the extracted term translation candidate list. The key steps include identifying the left boundaries of target terms by employing a maximal entropy classifier, and generating the probabilities of items as shown in Example 2, in the term translation table in cooperating with SMT system. In this paper, we regard the term transla-tion table as a feature of MT decoders.
During decoding in the sentence translation tasks, translation hypotheses are searched both in the phrase translation table and in the generated term translation table. The underlying MT de-coder gets the scores of hypotheses from both ta-bles, and selects the n-best list among translation hypotheses.
Example 2:The term translation table based on Example 1
communication|||通信|||0.387201 0.358436 0.623309 0.668845|||0-0 interprocess|||间|||0.00358423 0.0028275 0.333333 0.6|||0-0
interprocess|||进程间|||0.333333 0.00160575 0.666667 0.24|||0-0 0-1
interprocess communication|||间通信|||0.333333 0.000101348 0.333333 0.401307|||0-0 1-1
interprocess communication|||进程间通信|||0.4 0.000575558 0.666667 0.160523|||0-0 0-1 1-2
IPC|||间通信|||0.333333 0.416858 0.0454545 0.352726|||0-0 0-1 IPC|||进程间通信|||0.65625 0.731707 0.5 0.120435|||0-0 0-1 0-2
of terms and sentences. In summary, this paper makes the following contributions:
(1) The proposed simple and straightforward framework gets more reliable and accurate term translation knowledge by learning from parenthetical sentences. It substantially im-proves the translation quality of terms and sen-tences.
(2) The proposed framework regards the term translation table as a feature of MT decoders. It allows term translation knowledge to be more fully utilized compared with traditional bilingual term dictionaries.
(3) The well designed term translation knowledge extractor continuously extracts term transla-tion candidates from parenthetical sentences. Some of the extracted candidates will be added into the seed dictionary as incremental dictionary items, so as to improve the accuracy of parenthetical sentences.
2 The Proposed Framework
In this section, we first introduce the whole frame-work, then give a detailed description of this framework in the following subsections.
The primary insight of the proposed framework is that authors of many mix-language web pages, especially non-English pages (such as Chinese, Japanese), usually annotate terms with their origi-nal English translations insides of a pair of paren-theses. Thus we can extract some term transla-tion pairs follow parenthesis pattern, especially for technical terms.
To achieve better term translation quality, our proposed framework includes four parts as shown in Figure 1:
(1) A focused web crawler, collecting relevant web pages. Different from general purpose crawlers, the crawler employed by this pa-per is a focused crawler, collecting web pages that contain parenthetical sentences. The pro-posed focused crawler will predict the prob-ability that an unvisited page contains paren-thetical sentences before actually download-ing the page.
(2) A parenthetical sentence filter, acquiring par-enthetical sentences including bilingual term pairs. There are various proposes of parenthe-sis patterns, such as term translation, explana-tion, supplement, examples. The proposed fil-ter picks out sentences that contain only fil-term translation and match the parenthesis pattern. Then parenthetical sentences will be acquired.
(3) A term translation knowledge extractor, ex-tracting bilingual term translation candidates. The extractor identifies the left boundaries of target terms by employing a maximal entropy classifier. Then, the term translation candidate list for the parenthesized source term is ex-tracted depending on the left anchor, namely the given left boundary. The classifier was trained by naturally annotated resources (e.g., Wikipedia) and the seed dictionary.
2.1 Focused Crawler
Crawlers used by general purpose search engines retrieve massive numbers of web pages regardless of their content. However, there are various kinds of web pages on the Internet, and only a small fraction of pages happens to contain parentheti-cal sentences. So, the focused crawler (Pal et al., 2009) is employed in this paper to collect targeted pages, by carefully prioritizing the crawl frontier and managing the hyperlink exploration process.
The proposed focused crawler in this paper will predict the probability that an unvisited page contains parenthetical sentences before actually downloading this page. The larger the probabil-ity, the higher the visiting priority will be assigned to the URL in the task queue.
A URL consists of the domain, the path
and other parts. For instance, given the URL “https://en.wikipedia.org/wiki/Memory”, the do-main is “en.wikipedia.org” and the path is “/wiki/Memory”. We assume that a page may contain more parenthetical sentences if: (1) other pages in the same domain have more parentheti-cal sentences; (2) the parent page from which the URL is extracted contains many parenthetical sen-tences. Therefore, the probability that a URL con-tains parenthetical sentences is calculated by:
logp(url) = 0.5×logcounttotal((url.domainurl.domain))
+0.5×logcount(url.parent)
total(url.parent)
(1) where count refers to the number of parentheti-cal sentences, and total refers to the number of sentences. The value of count is given by the parenthetical sentence filter introduced in the next subsection. The focused crawler reorders the task queue by the probability according to Equation1.
A Bloom filter is employed for filtering dupli-cate URLs, and the controlled Chromium browser is adopted to simulate keyboard and mouse actions for downloading pages which cannot be accessed in the general way.
2.2 Parenthetical Sentence Filter
There are various proposes of parenthesis patterns, such as term translation, explanation, supplement, and demonstration. Several typical parenthesis patterns are shown in Example 3. Only the pat-terns for term translation are focused in this paper, and other patterns should be eliminated.
In order to acquire parenthetical sentences for learning term translation, we design a parentheti-cal sentence filter to identify whether a sentence matching the parenthesis pattern should be re-tained or not. For a parenthetical sentence s =
c1c2. . . cn(e1e2. . . em), the proposed filter
com-bines the seed dictionary, co-occurrence and pre-defined rules to score the parenthetical sentence candidate according to the following equation:
logp(s) =λ1logp(domain) +λ2logp(page) +λ3logr(s) +λ4logco(s)
(2) In Equation2,r(s)refers to the ratio of source words that correspond to target words according to the dictionary can be matched before the left parenthesis and can be calculated by the following equations:
r(s) = m1 × m X
j=1
sign(ej) (3)
sign(ej) =
0 ∀t0 ∈dict(ej), t0 ∈ {c/ n} 1 ∃t0 ∈dict(ej), t0 ∈ {cn}
(4)
wheredict(ej)refers to the target word set of the source wordej according to the seed dictionary.
In Equation 2, co(s) denotes the average co-frequency of source words and target words and can be calculated by the following equation:
co(s) = m1× m
X
j=1
max 1≤i≤n,ej∈s,ci∈s
2×count(ej, ci) count(ej) +count(ci)
(5)
After analysis, there are some typical websites and pages containing an especially great num-ber of bilingual pairs. Such prior information is very helpful to recognize parenthetical sentences. Thus, in Equation2,s(domain)denotes the prob-ability of one sentence included in domain con-tains parenthetical term translation and can be de-rived as the following equation:
s(domain) = |domain|1
X
s0∈domain
λ3×r(s0)
λ3+λ4 +
λ4×co(s0)
λ3+λ4
(6)
Example 3:Several typical parenthesis patterns Term translation:
软件开发中的焦焦焦油油油坑(the tar pit)可以通坑坑 过尽责、专业的过程得以避免。
岩石里有种构造叫夫夫夫妻妻妻节节节理理理(英文:coupled joints)
Explanation:
蓟北:泛指蓟州、幽州一带(现在河北省北部地区),是安、史叛军盘踞的地方。
Supplement: 艾
艾艾米米米莉莉莉·狄狄狄金金金森森森(1830-1886)是美国文学史上一个伟大的诗人。
斯
斯斯巴巴巴达达达克克克(杀开一条血路,大喊)不愿做奴隶的人们!起来!
Demonstration:
从图中两组节理面的锐锐锐角角角(beta)可计算出该岩石的内摩擦 转载请注意说明来来来源源源(www.qq.com)
没有被收录在词表中的词,包括各类专专专有有有名名名词词词(人名、地名、企业名等)
sentence included in page contains parenthetical term translation, s(page), can be derived as the following equation:
s(page) = 1
|page| X
s0∈page
λ3×r(s0)
λ3+λ4 +
λ4×co(s0)
λ3+λ4
(7)
where|page|refers to the number of sentences in this page.
In this paper, the default values of λare set to the following weights:λ1 =λ2= 0.2,λ3=λ4 = 0.3.
2.3 Term Translation Knowledge Extractor In order to extract bilingual term translation can-didates, the key task is to identify the left bound-ary of a target term. However, traditional term recognition methods employing statistical mea-sures to rand the candidates terms (n-gram se-quences), such as log likelihood (Cohen, 1995; Lefever et al.,2009), TF-IDF (Evans and Lefferts, 1995;Medelyan and Witten,2006), C-value/NC-value (Frantzi et al.,2000) and many others ( Ah-mad et al.,2000;Park et al.,2002;Kozakov et al., 2004;Sclano and Velardi,2007;Zhou et al.,2008; Zhang et al.,2008;Kostoff et al.,2009), leads to very low recall for some domains. What’s worse, some approaches apply frequency threshold to re-duce the algorithm’s search space by filtering out low frequency term candidates. Such methods have not taken into account Zipf’s law, again lead-ing to the reduced recall.
In this paper, to achieve a higher recall, we adopt naturally annotated resources for term
recognition and focus on supervised machine learning approaches based recognition approaches for MT with a wide range of fields. Thus, we train a maximal entropy based term recognition model using Wikipedia sentences to detect the left boundary candidate of a given target term.
There are plenty of naturally annotated re-sources with parenthetical sentences that can be used to train the term recognizer as shown in Fig-ure 2, especially Wikipedia. In Figure 2, the phrases with red rectangles are terms. As we can see, this terms are naturally annotated with bold fonts or hyperlinks. And such natural annotations clearly provide the important boundary informa-tion of terms and can be adopted as training data of term recognizers.
In this paper, we design following features for the term recognizer: the four words immedi-ately to the left of the term, Ws−4, . . . , Ws−1,
and their parts of speech,P OSs−4, . . . , P OSs−1;
the four words immediately to the right of the termWs+1, . . . , Ws+4, and their parts of speech,
P OSs+1, . . . , P OSs+4; the first word of the
phrase W L and the part of speech P OSL; the last word of the phraseW Rand the part of speech P OSR; the ratio of target words, D, that match parenthetical source words according to the seed dictionary.
Figure 2: Naturally annotated resources.
To expand the seed dictionary, the items with high confidence in the term translation candi-date list will be selected as incremental dictionary items. By doing this, we can make up for the seed dictionary as the growth of term pairs.
2.4 Probability Learner
In order to substantially improve the quality of term and sentence translation, in this paper, we design a probability learner to generate the term translation table with probabilities in cooperating with SMT decoders. The probability learner com-bines word alignment model with the detected boundary candidates to generate the final term translation table. And the process of searching for the best boundary,ci, can be formulated as the joint model:
i= argmax 1≤i≤n p(ci)
λ5 ×p(c
i. . . cn|e)λ6
×p(e|ci. . . cn)λ7 (8)
where p(ci. . . cn|e) and p(e|ci. . . cn) are word alignment probabilities of the source term and the target term, ande=e1. . . em.
In Example 1,s=“所以只能使用进程间通 讯( interprocess communication , IPC )”. For the source term “interprocess communication”, c1 =
“所以”,c2 =“只能”,c3 =“使用”,c4 =“进程”, c5 = “间”, c6 = “通讯”, e1 = “interprocess”,
e2 = “communication”. And the left boundary
is incorrectly recognized by our baseline system as c5, namely, the target term is c5c6 =“间 通
讯”. In order to correct the detection error, we en-large or shrink the anchor from the left boundary to re-generate target terms, including the correct target termc4c5c6 =“进程 间 通讯”. Then, we
select a best regenerated term which maximizes the joint probability according to Equation 8. In this work, the HMM-based word alignment model (Vogel et al.,1996) is employed to align words.
Next, we can extract term translation rules us-ing the selected term above, and generate the term translation table as shown in Example 2. In Ex-ample 2, fields of the line “communication|||通 信|||0.387201 0.358436 0.623309 0.668845||| 0-0” includes 7 properties: source term, target term, phrase translation probability, lexical weights, in-verse phrase translation probability, inin-verse lexical weights, word alignment.
In this paper, the default values ofλ5,λ6andλ7
are set to 0.4, 0.3 and 0.3, respectively.
3 Experiments
We conduct the experiments to test the perfor-mance of our proposed framework on improving the quality of term and sentence translation. We will check how much improvement the proposed framework can achieve on the final MT results. The performance of term pair extraction is eval-uated by precision (P); the quality of term transla-tion and sentence translatransla-tion are evaluated by pre-cision (P) and BLEU, respectively.
3.1 Experimental Setup
All the experiments are conducted on our in-house developed MT toolkit which has a typical phrase-based decoder (Xiong et al.,2006) and a series of tools, including word alignment and phrase table extraction.
We test our method on English-to-Chinese translation in the field of software localization. The training data (1,199,589 sentences) and an-notated test data (1,100 sentences) are taken from Microsoft Translation Memory, which is a domain-specific dataset. And additional data em-ployed by this paper includes: the seed dictionary (102,308 source words2, 24,094 terms from
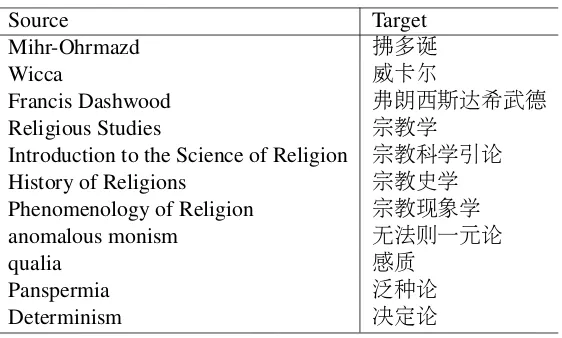
Source Target
Mihr-Ohrmazd 拂多诞
Wicca 威卡尔
Francis Dashwood 弗朗西斯达希武德
Religious Studies 宗教学
Introduction to the Science of Religion 宗教科学引论
History of Religions 宗教史学
Phenomenology of Religion 宗教现象学
anomalous monism 无法则一元论
qualia 感质
Panspermia 泛种论
[image:7.595.160.441.59.228.2]Determinism 决定论
Table 1: Extracted English-Chinese term translation candidates
crosoft Terminology Collection), Chinese Pinyin table (7,809 Chinese characters3). The gold stdard of term translation of test data are human an-notated.
All the MT systems are tuned by the develop-ment set (1,000 sentences) using ZMERT (Zaidan, 2009) with the objective to optimize BLEU ( Pap-ineni et al., 2002). The higher the BLEU score, the better the translation is. And the statistical sig-nificance test is performed by the re-sampling ap-proach (Koehn,2004).
3.2 Results and Analysis (1) The Term Extraction Tests
Firstly, we will evaluate the extraction perfor-mance of term translation candidates. In our ex-periments, the focused crawler has downloaded 162,543,832 web pages. And there are 12,673,286 pages that contain 49,976,931 parenthesized sen-tences selected by the parenthesized sentence filter in total.
The baseline term extraction system is denoted as “Baseline” which is implemented according to the work introduced by (Cao et al., 2007). The baseline system has extracted 10,823,132 terms from above web pages. And our system, being denoted as “TermExt”, outputs 12,048,310 terms. As we can see, therecall has been increased by 11.32% using our proposed framework.
Then, We sample the extracted terms 10 times on the baseline system and the proposed frame-work, respectively. And each sample includes 1,000 terms. And we report the average precision in Table 2.
3http://www.51windows.net/pages/gb2312.htm
In contrast to the baseline approach, the fig-ures in Table 2 show that theprecisionof Chinese terms has been increased by 2.9 points, and the precisionof term pairs has been increased by 4.1 points. Thus, according to the bold figures in Ta-ble 2, we can draw a conclusion that term extrac-tion can be substantially increased by the proposed framework.
(2) The SMT Translation Tests
Secondly, we test whether the proposed frame-work can further improve the performance of term and sentence translation, compared with the baseline system. The strong baseline sys-tem, e.g., well tuned Moses, is denoted as “Moses”. And our SMT system is denoted as “MaxEntSMT”. The translation results based on the extracted term dictionary are labeled with “MaxEntSMT+BaselineDict” and “Max-EntSMT+TermExtDict”, respectively. Corre-spondingly, the translation results based on the term translation table are labeled with “Max-EntSMT+TermExtTable”. The word alignment was conducted bidirectionally and then sym-metrized for extracting phrases as Moses (Koehn et al., 2007) does. The test set includes 1,100 sentences with 1,208 bilingual term pairs alto-gether. In order to highlight the performance of term translation, we count the number of terms that are translated exactly correctly, and the cor-responding term translation results are denoted as “Term (P/%)” (exactly matching). Meanwhile, the sentence translation results are labeled “Sentence (BLEU/%)”. We report all the results in Table 3.
Number of Terms Chinese Terms (P/%) Term Pairs (P%)
Baseline 10,823,132 94.30 88.20
TermExt 12,048,310 97.20** 92.30**
[image:8.595.148.451.153.238.2]“**” means the scores are significantly better than previous lines withp <0.01.
Table 2: The performance of term extraction
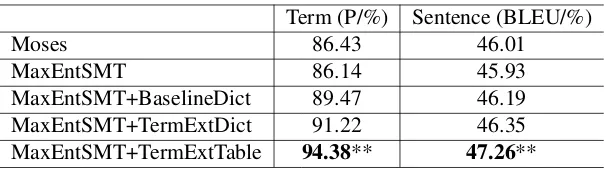
Term (P/%) Sentence (BLEU/%)
Moses 86.43 46.01
MaxEntSMT 86.14 45.93
MaxEntSMT+BaselineDict 89.47 46.19 MaxEntSMT+TermExtDict 91.22 46.35 MaxEntSMT+TermExtTable 94.38** 47.26**
“**” means the scores are significantly better than previous lines withp <0.01.
Table 3: The performance of translation
However, with the help of the proposed frame-work, the term translation quality is significantly improved by more than 7.95% accuracy. Non-term words are also strongly improved by the framework, because that the accuracy ratio of term words translation has been much improved and fewer non-term words are translated incorrectly. In sentence translation, the bold figures in Table 3 demonstrate that it improves the translation quality by 1.25 absolute BLEU points, compared with the well tuned Moses. Considering one term on aver-age in a single sentence in the test set, the BLEU scores are very promising actually, and our goals on term translation have been achieved.
In summary, we can draw the conclusion that the proposed term extraction framework signifi-cantly improves the performance of term extrac-tion from web pages, and further substantially im-proves the performance of MT in term of term translation and sentence translation.
4 Related Work
For term translation pairs extraction from paren-thetical sentences, Caoet al.(Cao et al.,2007) and Lin et al., like us, proposed two different meth-ods to mine bilingual dictionaries. Caoet al. used a 300GB collection of web documents as input. They extracted candidate translations using pre-defined templates, and used supervised learning to build models that deal with phonetic translitera-tions and semantic translatranslitera-tions separately. Lin et al. used a word alignment algorithm, not to make a distinction between translations and translitera-tions, to identify the terms being translated relying
on unsupervised learning.
Our work depends on supervised learning with naturally annotated resources (e.g., Wikipedia) to train a term recognization model and detect left boundary candidates of a term. In addition, our method combines word alignment model with the detected boundary candidates to generate the final term translation table with probabilities for MT, rather than the extracted bilingual term dictionary. We make no distinction between translations and transliterations.
5 Conclusion
In this paper, we have presented an simple, straightforward and effective framework to learn from parenthetical sentences for term translation in MT. The proposed framework continuously ex-tracts term translation candidates from parentheti-cal sentences from web pages, generates the term translation table, then regards the term translation table as a feature of MT decoders, finally substan-tially boosts term translation and sentence transla-tion. The experimental results are promising.
References
Khurshid Ahmad, Lee Gillam, and Lena Tostevin. 2000. Weirdness indexing for logical document extrapolation and retrieval. In Proceedings of the Eighth Text Retrieval Conference (TREC-8).
Jonathan D. Cohen. 1995. Highlights: Language- and domain-independent automatic indexing terms for abstracting. Journal of the American Society for In-formation Science, 46(3):162–174.
David A. Evans and Robert G. Lefferts. 1995. Clarit-trec experiments.Information Processing and Man-agement, 31(3):385–395.
Katerina Frantzi, Sophia Ananiadou, and Hideki Mima. 2000. Automatic recognition of multi-word terms: the c-value/nc-value method. International Journal on Digital Libraries, 3(2):115–130.
Philipp Koehn. 2004. Statistical significance tests for machine translation evaluation. In Proceedings of EMNLP 2004.
Philipp Koehn, Hieu Hoang, Alexandra Birch, Chris Callison-Burch, Marcello Federico, Nicola Bertoldi, Brooke Cowan, Wade Shen, Christine Moran, and Richard Zens. 2007. Moses: open source toolkit for statistical machine translation. In Proceedings of ACL 2007.
Ronald N. Kostoff, Joel A. Block, Jeffrey L. Solka, Michael B. Briggs, Robert L. Rushenberg, Jesse A. Stump, Dustin Johnson, Terence J. Lyons, and Jef-frey R. Wyatt. 2009. Literature-related discovery. Annual Review of Information Science and Technol-ogy, 43(1):171.
L Kozakov, Y. Park, T. H. Fin, Y. Drissi, Y N Doganata, and T. Cofino. 2004. Glossary extraction and knowl-edge in large organisations via semantic web tech-nologies. InProceedings of the 6th International Se-mantic Web Conference and the 2nd Asian SeSe-mantic Web Conference.
Els Lefever, Lieve Macken, and Veronique Hoste. 2009. Language-independent bilingual terminology extraction from a multilingual parallel corpus. In Proceedings of EACL 2009.
Olena Medelyan and Ian H. Witten. 2006. Thesaurus based automatic keyphrase indexing. In Proceed-ings of the ACM/IEEE-CS Joint Conference on Dig-ital Libraries.
Anshika Pal, Deepak Singh Tomar, and SC Shrivas-tava. 2009. Effective focused crawling based on content and link structure analysis. arXiv preprint arXiv:0906.5034.
Kishore Papineni, Salim Roukos, Todd Ward, and Wei-jing Zhu. 2002. Bleu: a method for automatic evalu-ation of machine translevalu-ation. InProceedings of ACL 2002.
Youngia Park, Roy J Byrd, and Branimir K Boguraev. 2002. Automatic glossary extraction: beyond termi-nology identification. In Proceedings of COLING 2002.
Feiliang Ren, Jingbo Zhu, and Huizhen Wang. 2010. Web-based technical term translation pairs min-ing for patent document translation. In Proceed-ings of the 6th International Conference on Natural Language Processing and Knowledge Engineering (NLP-KE 2010).
F. Sclano and P. Velardi. 2007. Termextractor: a web application to learn the shared terminology of emer-gent web communities. In Proceedings of the 3rd International Conference on Interoperability for En-terprise Software and Applications (I-ESA 2007). Stephan Vogel, Hermann Ney, and Christoph Tillmann.
1996. Hmm-based word alignment in statistical translation. In Proceedings of the 16th conference on Computational linguistics, volume 2, pages 836– 841.
Deyi Xiong, Qun Liu, and Shouxun Lin. 2006. Max-imum entropy based phrase reordering model for statistical machine translation. In proceedings of COLING-ACL 2006.
Omar F. Zaidan. 2009. Z-mert: A fully configurable open source tool for minimum error rate training of machine translation systems. The Prague Bulletin of Mathematical Linguistics, 91:79–88.
Ziqi Zhang, J. Iria, and Christopher Brewster. 2008. A comparative evaluation of term recognition algo-rithms. InLREC 2008.