U S I N G A T ~ X T M O D E L F O R A N A L Y S I S A N D G E N E R A T I O N E. F I M B E L , H. G R O S C O T , J . M . L A N C E L , N. S I M O N I N
C A P S O G E T I I N N O V A T ION 129, r u e de l ' U n i v e r s i t ~
7 5 0 0 7 P A R I S F R A N C E
ABSTRACT
The following paper concerns a general scheme for multilingual text generation, as opposed to just translation. Our system processes the text as a w h o l e , f r o m w h i c h it e x t r a c t s a representation of the meaning of the text. From this representation, a new text is generated, using a text modei and action ruies.
This process is done in six steps : word analysis, sentence analysis using a Functional Grammar, reference s o i v i n g and i n f e r e n c e , c o n s t r u c t i o n of the text pattern, sentence generation, and word generation. D i f f e r e n t kinds of information are used st each step of the p r o c e s s : t e x t o r g a n i z a t i o n , s y n t a x , semantic, etc.
A l l the knowledge, as w e l l as the text, is given in a d e c l a r a t i v e manner. It is expressed in a s i n g l e f o r m a l i s m n a m e d F u n c t i o n a l Oescriptions. It consists of lexical data, a Functional Grammar, a knowledge network, action r u l e s for r e f e r e n c e s o l v i n g and s e n t e n c e g e n e r a t i o n , m o d e l s of t e x t , r u l e s o f structuration, and sentence schema.
Text representation, included in the semantic network, is composed of different kinds of o b j e c t s (not n e c e s s a r i l y distinct) : text organization, syntactical information, objects introduced by the discourse, a f f i r m a t i o n s on t h e s e o b j e c t s , and l i n k s b e t w e e n t h e s e affirmations.
I TEXT VERSUS SENTENCES
the one hand rearrange a whole sentence in order to respect certain s t y l i s t i c rules and on the other hand modify the order of these sentences. Some of them may be d e l e t e d and others added. In any ease, in order to be a b l e to g e n e r a t e a coherent text by means of the i n f o r m a t i o n extracted from a source text, it seems most important to us to understand what the text is refering to.
We h a v e restricted our scope to economic geography texts, taken from a French r e v i e w named ATLASECO. These texts deaI with i n d u s t r y and agriculture, i n v o i v i n g reiated c o n c e p t s ( g r o w t h , d e c i i n e , p r o d u c t i o n , e c o n o m i c a I balance...). Our system parses a french text, integrates its i n f o r m a t i v e content into a k n o w l e d g e base, then generates a new text from information extracted from this base.
W e p r e s e n t in p a r t (2) t h e t e x t r e p r e s e n t a t i o n used throughout the process. We d e s c r i b e in p a r t (3) t h e k n o w l e d g e r e p r e s e n t a t i o n , b a s e d on the f u n c t i o n a l d e s c r i p t i o n s . In part (4), we b r i e f l y describe the different steps of the process.
2 TEXT REPRESENTATION
A text conveys information by various means. For example, the order of sentences, as well as their syntactic structure, may be significant.
The general text representation we use is the same for u n d e r s t a n d i n g and structuring. This representation includes the different kinds of information needed for these two processes.
Human translation is a complex process whose a c t i v i t i e s are not yet e n t i r e l y understood. Generation of text differs from generation of s i n g l e s e n t e n c e s : our w o r k s t r e s s e s the necessary processing of the text as a whole and restructuring of this text. A translator must on
The text is r e p r e s e n t e d by a set of interrelated objects (sentences, words, semantic objects...). There are five c l a s s e s of objects, not necessarily distinct : the visible objects, the syntactic components, the discursive objects (defined later), the affirmations and the links.
2.1 Visible Objects
V i s i b l e objects are chapters, paragraphs, sentences, words and word sequences . They are reiated by positionai iinks, describing the organization of the text, as shown by the foIiowing figure :
TEXT
SENTENCE 1 . . " r='~"J 5ENTEN~En / S
/
OB3 1 083 2 083 n OB3 1 083 n
fig. i
T h e s e l i n k s r e f l e c t the h i e r a r c h i c a l organization of the text (chapters ...) and the dependent relationship of statements (order of sentences ...).
2.2 Syntactic Components
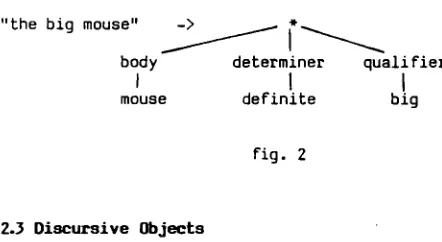
The sentences are represented by means of u n o r d e r e d " s y n t a c t i c c a s e s " ( s u b j e c t , determiner...), linking a component with its subcomponents. For example :
"the big mouse" ~ . ~ ~ ~
body determiner quail fier
J
I
i
[image:2.612.65.289.184.279.2]mouse definite big
fig. Z
2.3 D i s c u r s i v e O b j e c t s
Discursive objects represent the semantic objects o r entities introduced by the text. For example :
"The main crop i s wheat, whose p r o d u c t i o n has s t r o n g l y d e c r e a s e d . T h i s d e c l i n e has s t r o n g l y a f f e c t e d the commercial balance."
These two constructions correspond to a single discursive object, which could be c a l i e d : "decrease of the production of wheat"
The meaning of a sentence is represented by a network of discursive objects. The propositions, r e p r e s e n L i n g the d i s c u r s i v e o b j e c t s , are
normalized into an objscLive form. For example : 'Peter met 3ohn" -> "meeting of 3ohn by Peter" "Mary is ill" -> "illness of Mary".
This normalization is very usefui for co- reference soiving.
The text i t s e l f may be a discursive object. Hence, it is represented by an object which mentions topic, date and positional links b e t w e e n s e n t e n c e s of text. O u r i n g t h e Understanding Process, this object will be enlarged by new information, or modified (for instance topic may become more explicit).
2.4 Affirmations
Implicit within the text, as well as s i m p l y introducing objects, is the e v a l u a t i o n of certain objects. "The production is increasing" introduces "the production" and a f f i r m s "the increase of production".
There are various statement values ("stated p o s i t i v e l y in discourse", "dubious"...). These values may be given by the author, a figure, an economical organization, etc.
2.5 Links
The links are m a i n l y operators (and, or, because...) that correlate the affirmations, which are die c u r s i v e objects or links : "A b e c a u s e B" ; "A and B, b u t C".
They reflect internal structure of discourse. For example : "the production increases but the deficit remains important".
During Understanding phase, Lheir main role is to transmit statement values to the objects they link.
The structuring stage isolates argumentative effects of the discourse, and builds new links (possibly the same). The choice of these links is important because they have to be coherently acceptable from the reader point of view.
3 KNOM_EDGE REPRESENTATION
[image:2.612.65.286.438.559.2]The language of functional descriptions comes from the functional grammars (DIK 78), which is a linguistic formalism that can be reiated to case grammars (FILLMORE 68). Historically, Kay
( 8 1 ) used functional descriptions as a genecel tool to represent grammars, independently of any s p e c i f i c l i n g u i s t i c t h e o r y , a f t e r w h i c h Rousselot (84) then used functional d e s c r i p t i o n s
to represent any kind of knowledge (grammar, semantic rules, scripts..) in a system of story understanding.
We will use "DF" instead of "functional description".
A DF may represent any kind of knowledge. For example , "William cut himsel~' may be described by the following figure :
[action = cut tense = past
actor = [name = Wiiliam] obj_act <I actor>]
fig. )
A OF is an unorde~ed set of identifier-object pairs. The identifiers are not pre-defined : they may be added or removed in any way. This allows us to put various kinds of information in the same description : syntactic, semantic, etc. The objects may be other DFB or p a t h s .
A path is a notation whose aim is to point to objects that ace already defined . We h a v e two kinds of paths :
- A local path <I list-of-identifier> points to an object in the current OF, as defined by the list of identifiers. For example, in fig. 3, the path <I actor name> cefers to "William". - A g l o b a l path, <g starting-point list-of-
i d e n t i f i e r s > p o i n t s to an o b j e c t in the knowledge base. It is defined in the same way as the l o c a l path, except that the s t a r t i n g point i s the curcent DF.
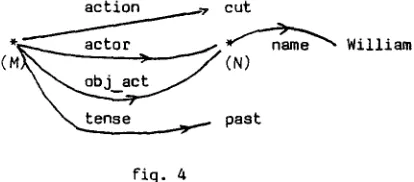
The internal representation of a DF is a labelled graph. For example, the representation of the DF in fig. ) is shown in fig. 4.
as input and converts it d i r e c t l y into the labelled graph as shown in fig. 4, which is then integrated into the knowiedge base.
A functional description network is the graph that represents a set of i n t e r l a c e d DFB, i.e. the knowledge base. This network is a labelled graph whose nodes correspond to OFs, and whose links to elementary object properties. These links are labelled with identifiers.
colour
table = ~ blue
object ( D F ) property object (OF)
f i g . 5
Each identifier (e.g. colour) may be given d i f f e r e n t p r o p e c t i e s (e.g. i n h e c i t a n c e properties). This is done through attaching a node to the identifier.
The graph may contain Dynamic Paths , which allow access to the objects. A dynamic path is a function <f starting-point list-of-identifiers> whose value is a node on the graph. Foc example, in fig. 4, the dynamic path <f (M) actor name> points to the node "William". Dynamic Paths ace very similar to substituable variables in formal systems.
The processing of a DF network can be done at two levels :
- e l e m e n t a r y l e v e l : insert or delete links
(i.e. propecties) or nodes (i.e. objects) ;
- f o r m l e v e l : each node of the netwock can
still be viewed as a description, which corresponds to a complex set of links. This a l l o w s us to w o r k on the f o r m of the objects (pattern matching and merging).
The main algorithms that operate at the form l e v e l are those of c o m p a t i b i l i t y (pattern matching) and m e r g i n g . "Compatilibity" is a b o o l e a n f u n c t i o n that decides whether two descriptions may correspond to the same object of the real world. For example, could the events described by "William speaks to himselP' also be described by "Somebody speaks to Ted" 7 :
7 cut William
t e n s e ~ past
Fig. 4
The system takes the DF, as shown in fig. 3,
~action = speak
actor ~name = William]
o b j - a c t = < I a c t o r > J
[action = speak
actor = ~ is-a = huma~ obJ-act = [ name Ted]J
fig. 6
[image:3.612.82.289.604.695.2]These two descriptions are n o t compatible, because the name of ,he "obj-act" is "William" on one hand and "Ted" on the other.
"William cut himself " action = cut tense = past
a c t o r = [ n a m e = o b j - a c t <1 a c t o r > ]
William]
"X cut Y"
[ a c t i o n = cut tense = past
a c t o r . = [ i s - a = human] . obj-act Estate changed]J
[ a c t i o n = cut tense = past
[image:4.612.340.477.179.307.2]actor = [ is-a = human name = William state = changed] o b j - a c t = <I actor>]
fig. 7
Two c o m p a t i b l e descriptions can be merged. The result is a new description, more c o m p l e t e than either of the originals. For example, the first two DFs of fig. 7 are compatible, and give the third one as the result of merging.
T h e s e two a l g o r i t h m s , i n s p i r e d by the functional unification introduced by Kay, are very powerfuI and are used at each step of text p r o c e s s i n g . T h e i r p r e c i s e d e f i n i t i o n s use mathematicaI transformations of iabeIIed graphs and are given in (GROSCOT, ROUSSELOT 85).
/4 TEXT PROCESSING
In this section, we describe the f o l l o w i n g different steps of the text processing :
- word anaiysis - sentence anaIysis - reference solving
- construction of the text pattern - sentence generation
- word generation
/4.1 Word Analysis
The word analyser uses a knowledge base about the standard inflexions of the initial language
and a dictionary of words and sequences of words. Each item in the dictionary contains a semantic definition, its syntactical category, and its type of infiexion with its roots.
We generate for each word a d e s c r i p t i o n of its syntactic features. A I I s o i u t i o n s are generated. For exampie, the analysis of the word "burns" gives at least these two DFs :
i ) [word = burn number = p l u r a l category = substantive
" ' " ]
2) [word = b u r n
category = verb
tense = present
person = 5 number = s i n g u l a r
o , , ]
fig. 8
/4.2 S e n t e n c e A n a l y s i s -
The a n a l y s e r is b a s e d on the w o r k of R o u s s e l o t (8/4). It works sentence by sentence and assumes three important functions :
- r e c o g n i t i o n and construction of syntactic components of a sentence
- c o n t r o I of semantic constraints
- generation of the semantic representation of the sentence, i.e. an affirmation or a link
The a n a l y s e r uses a d e c l a r a t i v e grammar, which does not depend upon the way in which the a n a i y s e r works. The grammar is a DF, in which each identifier-object pair represents a grammar ruIe. These rules aliow the analyser to s p i i t a syntactical category into constituents, to v e r i f y the c o n s t r a i n t s , and to b u i l d the associated semantic representation.
The analyser works in a top-down manner by means of an agenda which allows the separation of the controls. Also included in the anaIyser is a graph that contains the partiaI a n a i y s i s which minimizes processing time during the backtracks.
The starting point of this a n a l y s e r is the set of DFs which have been obtained and graphed after word analysis.
We show here, in an example, the result of the analysis of the sentence "Agriculture is a success" :
o b j e c t : success
e v a l u a t e d - o b j e c t : [ o b j e c t = a g r i c u l t u r e def-undef = d e f i n i t e ] statement-value = t r u e ]
4 . 3 R e f e r e n c e Solving
This stage determines what the pronouns and noun phrases point t o : known objects (already in the k n o w i e d g e base), or new o b j e c t s introduced (directly or indirectly) by the text.
The process uses action rules, written by means of OFs. The rules interpreter works in a "lazy" saturation mode : It l o c a l l y saturates the knowledge base regardless of whether or not all inferences have been made.
The process has three main features :
- i t is d i r e c t e d by the s y n t a x ( d e f i n i t e articles, pronouns..)
- i t identifies the objects at the semantic level, by testing the c o m p a t i b i l i t y of discursive objects
- i t uses p o s i t i o n a l l i n k s to d e f i n e the possible references in each case. For example, a demonstrative pronoun has to be found among
the preceding objects of the t e x t
It h a s two important effects :
- it constructs a coherent network of discursive objects (the "meaning" of the text)
- it integrates the text into the k n o w l e d g e base : each time that the text refers to a known object, links are created from this object to the text
W h e n t h i s is done, the p o s i t i o n of the information, may be inadequate for a coherent text. Therefore, the text structure is changed : some information is enhanced ; the paragraphs are b a l a n c e d ; the information is reordered a c c o r d i n g to c h r o n o l o g i c a l o r d e r and significance at the deepest l e v e l of the text
s t r u c t u r e .
At t h i s step, o u t p u t t e x t s t r u c t u r e is c l e a r l y apparent. But it is not sufficient because the text has now become a sequence of unrelated statements. Links are then created between the discursive objects introduced in the text (conjunctions, pronouns...) and e l l i p s e s are used to avoid repetitions.
4.5 Sentence G e n e r a t i o n
From each OF of the text describing output i n f o r m a t i o n , t h i s s t a g e g e n e r a t e s t h e description of a suitable sentence.
S y n t a c t i c p a t t e r n s are a s s o c i a t e d w i t h c o n c e p t s ( e v o l u t i o n s , a p p r e c i a t i o n s , numbers...). Action ruIes combine these patterns to create the description of a sentence, i.e. a iist of word descriptions.
4 . 4 C o n s t r u c t i o n o f the t e x t p a t t e r n
Once the initial text has been analysed, its i n f o r m a t i v e c o n t e n t is i n t e g r a t e d in the knowledge base, thereby making it p o s s i b l e to question this base and to reformulate the so- obtained information with the aim of generating
a new t e x t .
This s t a g e b u i l d s the text s t r u c t u r e (paragraphs, sub-paragraphs, sentences...) using two c o m p l e m e n t a r y approaches : the content of information and the e v o I u t i o n of the v i s i b l e
s t r u c t u r e of the text. Indeed, text generation
is a refIective process : generation of a singIe sentence of the text must take account the preceding and following text. All the processes used for structuring are written by means of rules.
The starting point of structuring is a set of i n f o r m a t i o n e x t r a c t e d from the k n o w l e d g e network.
First, all the information is inserted into a text model by means of their topics. Some obvious redundancies are eliminated : only one occurrence will be kept, in the most appropriate place.
A . 6 Word G e n e r a t i o n
Word generation uses the same organization of the knowledge base (about standard inflexions) as word anaiysis.
From a list of word descriptions, inciuding syntactic features, the system constructs the output word. For example :
word = burn
cat = verb tense = present
person = ) --> B U R N S
number = singula d fig. i0
.5 ANALYSING ECONOMIC GEOGRAPHY TEXTS
The texts we have analysed, taken from the F r e n c h r e v i e w A T L A S E C O , describe the main f e a t u r e s of the a g r i c u l t u r e in d i f f e r e n t c o u n t r i e s . They c o n t a i n an a v e r a g e of 20 sentences, which contain from i0 to 45 words.
The system used :
- 400 lexical items, which represent 2400 words
- 70 grammar ruies
- a semantic network containing 220 concepts, 80 of them being domain-dependant
- 80 semantic ruIes for inference and reference
solving
- i text model, containing 50 paragraphs and
subparagraphs
- lO0 rules for text structuring
- 30 sentence patterns for generation
O u r s y s t e m w a s a b l e to e x t r a c t t h e s i g n i f i c a n t i n f o r m a t i o n that s u c h a text conveys, and produce a new text from this information. As a matter of convenience, we used French as the target language for validation, however the process described here should also be able to work in a manner independant of the target language, by chaining certain parts of the knowledge base.
Now, we are in the process of adapting our system to generate French appliance operation manuals from the corresponding ones.
REFERENCES
ATLASECO
Atlas dconomique mondial Le Nouvel Observateur, 1982.
DIK Simon
"Functional Grammar"
Publications in Language Science.
Foris Publications, Oordrecht Holland, 1978.
FILLMORE Charles
"The c a s e for case" in " U n i v e r s a l s in Linguistics Theory", E. Bach and R. Harms (ede), p.i-90, 1968.
FIMBEL Eric
"Les reseaux miroirs : un mdcanisme d'infd- fence gdndraI ; a p p i i c a t i o n h u n syst~me d'aesimiiation de textes"
Th~se de l'universitd Paris 6, mars 1985.
GRIZE Jean-Blaise
"Introduction h la logique n a t u r e l l e et approche logique du dialogue"
Approches formelles de la sdmantique naturelle. Publication CNRS-UPS-UTM-ADI, 1982.
GROSCOT Herbert, ROUSSELOT Franqois
"Un l a n g a g e d d c l a r a t i f u n i f o r m e et un analyseur syntaxico-sdmantique"
Proceedings of Cognitiva, Paris, juin i985.
GROSS Maurice
"Mdthodes en syntaxe" Hermann, 1975.
KAY Martin
"Unification Grammars"
Xerox internal publication, 1981.
McKEOWN Kathleen R.
"Generating natural language text in response to questions about database structure"
PH.D of the university of PennsyIvania, 1982.
ROUSSELOT Francois
"Rdalisation d'un programme comprenant des textes en utiIisant un formaiisme ddclaratif pour reprdsenter toutes les connaissancee" Th~se d' dtat, Paris 6, 1984.
SIMONIN Nathalie
"Utilisation d'une expertise pour engendrer des textes structurds en fcan~ais"