Programming Models for Reconfigurable Application Accelerators
Full text
Figure
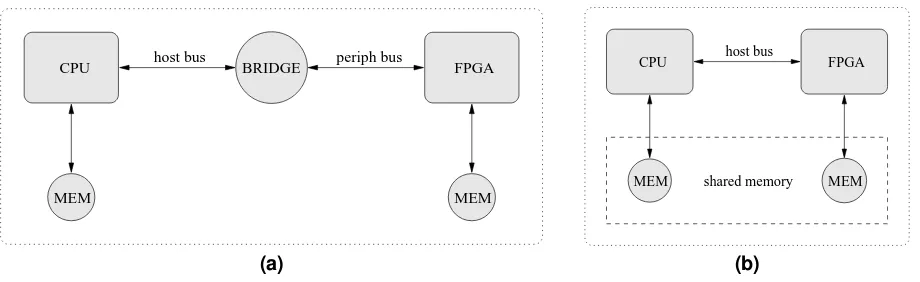
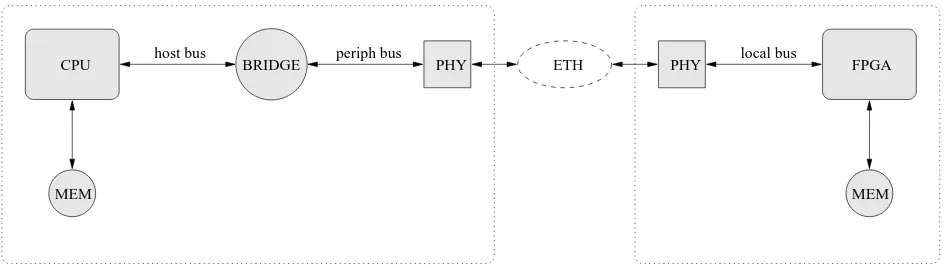
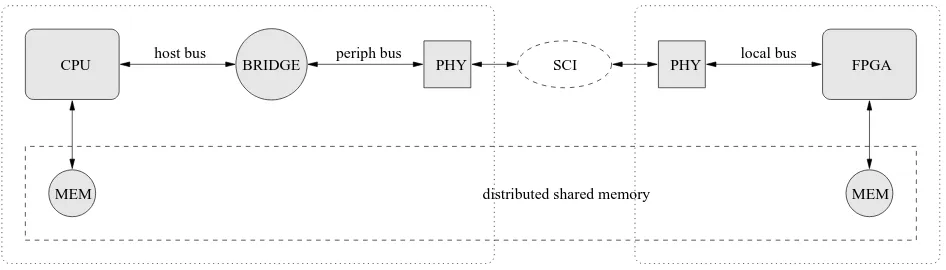
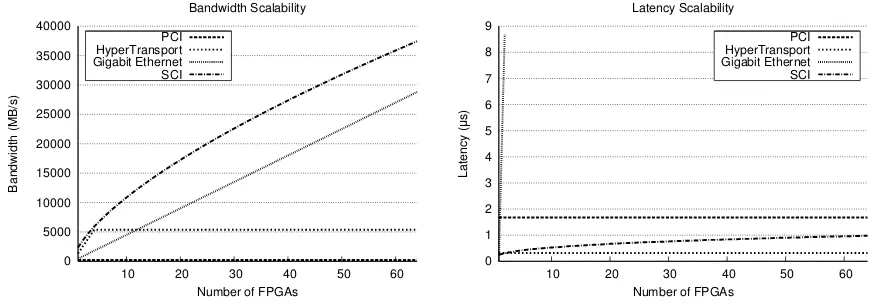
Related documents
Pre-treatment and filtration of the water source are mandatory initial steps (i.e. before installing a Class A UV device) on any surface water supply, ground water under the
deprivation for locally advanced and metastatic prostate cancer: results from a randomised phase 3 study of the South European Uroncological Group.. The role of intermittent
In any case, it is the customer's responsibility to test finished products intended to come into contact with food to ensure compliance with the
Type Description /Purpose Responsib le Attendee /Audience Media Timing Meetings Phase 2 Project Team Meeting Scheduled meetings to discuss project activities, progress
This proposed definition was developed by taking into account the existing literature in the field of political engagement as well as the perceptions concerning political
In the chapters that follow, we position the failure of the market to resolve external effects (inefficiencies) and equitable distributional outcomes as risks to
We measured knee joint laxity, joint kinesthesia, lower extremity balance, the amount of time required to generate peak torque of the knee flexor and extensor musculature,
[remove encryption from a container / CD] linux: (all open source). loop-AES, Cryptoloop, PPDD (Practical Privacy Disc Driver) windows:
