Class Based n gram Models of Natural Language
14
0
0
Full text
Figure
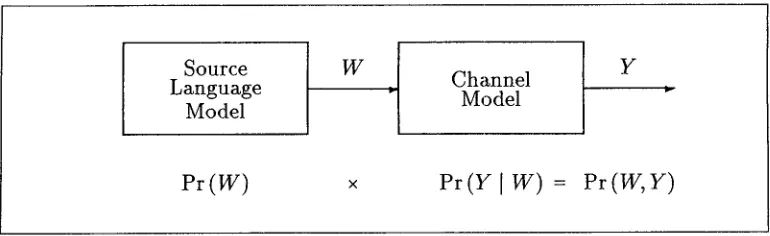

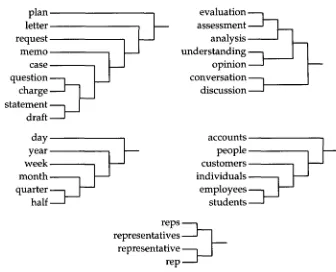

+2
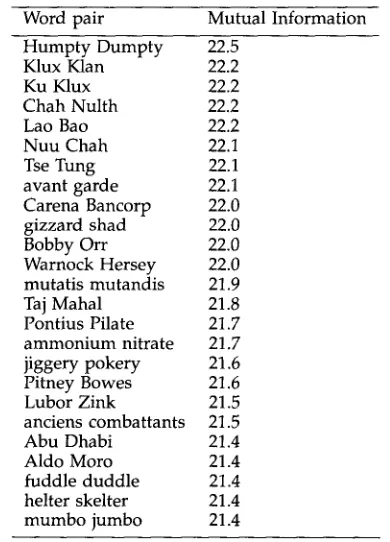
Related documents