Image Search Re ranking based on Topic Diversity Using K-NN Algorithm
.
Bachhav Ashwini V2
Prof. Dhande Mahesh T1 Dept of Computer Engg.
Shatabdi Institute of Engineering & Research Agaskhind,Nashik
Ghotekar Trunali S3 Dept of Computer Engg.
Shatabdi Institute of Engineering & Research Agaskhind,Nashik
Dept of Computer Engg.
Shatabdi Institute of Engineering & Research Agaskhind,Nashik
Shah Shivani S4 Shinde Ashwini B5
Dept of Computer Engg. Dept of Computer Engg.
Shatabdi Institute of Engineering & Research Shatabdi Institute of Engineering & Research
Agaskhind,Nashik Agaskhind,Nashik
[email protected] [email protected]
Abstract:-The developing measure of client labeled sight and sound has driven social picture examination and recovery gain significance which has helped individuals arrange and get to client labeled mixed media. Client labeling is uncontrolled, includes uncertainty and profoundly customized thus a crucial inquiry emerges how to decipher the importance of client contributed tag concerning the visual substance depicted by the tag. Picture’s significance and decent variety are considered and a social re-ranking framework for tag- based picture recovery. As per individual visual data, semantic data and social pieces of information the pictures are re-positioned. The underlying outcomes incorporate pictures contributed by various social clients. Every client may contribute a few pictures. Consequently, first, these pictures are arranged by between clients re-positioning. The clients that have a higher commitment to the given question are positioned higher. At that point, consecutive checking time stamp positioning is performed in which the ideal yield is acquired on the premise of title data and the ongoing time stamp which improves the decent variety execution of picture positioning framework. It additionally checks a number of perspectives used to enhance the importance execution of the picture recovery results. The last recovered outcomes are made out of the chose pictures. Catchphrase importance coordinates the information is recovered for the social picture dataset to quicken the seeking procedure.
Keywords— Social Media, Tag- based Image Retrieval,
Image Search, Ranking, Time-Stamp Re-Ranking, Diversity, KNN Algorithm
1.
INTRODUCTIONThe current web picture web crawlers, including Bing, Google, and Yahoo, recover and rank pictures generally dependent on the printed data related with the picture in the facilitating website pages, for example, the title and the encompassing content. While content-based picture positioning is frequently viable to scan for important pictures, the exactness of the query output is generally constrained by the bungle between the genuine pertinence of a picture and its significance derived from the related printed portrayals [4]. To
sources. Such intermittent pictures or recordings as often as possible show up in picture web indexes, (for example, Yahoo or Google) and photograph sharing locales, (for example, Flickr). In prior work, ten we broke down the recurrence of such repetitive examples (as far as visual copies) for cross- dialect theme following (a substantial level of global news recordings share regular video cuts, close copies, or abnormal state semantics). Grouping information dependent on a proportion of closeness is a basic advance in logical information investigation and in building frameworks. A typical methodology is to utilize information to take in a lot of focuses to such an extent that the total of squared mistakes between information focuses and their closest focuses is little. At the point when the focuses are chosen from genuine information focuses, they are designated "models." The well known k-focuses grouping method [1].
Starts with an underlying arrangement of haphazardly chosen models and iteratively refines this set in order to diminish the total of squared blunders. K-focuses bunching is very delicate to the underlying determination of models, so it is typically rerun ordinarily with various statements trying to locate a decent arrangement. Nonetheless, this functions admirably just when the quantity of groups is little and chances are great that no less than one arbitrary introduction is near a decent arrangement. There is no power over label connected by a number of clients on person to person communication locales, and the assorted variety of learning and data accessible to its clients. Albeit how important id the tag regarding the visual substance of the picture is emotional for an explicit client, a target paradigm is alluring for the universally useful hunt and visual substance understanding. We consider a tag is significant to a picture if the label connected to the picture splendidly depicts target parts of the visual substance, or at the end of the day, clients with basic information relate the tag to the visual substance effectively and reliably. As a rule, tag- based picture seek is more normally utilized in web-based life than substance based picture recovery and setting and- substance based picture recovery. Lately, the re-positioning issue in the tag-based picture recovery has picked up specialists' wide consideration.
2.
Literature review
In 2007,R. Cilibrasi and P. Vitanyi, “The Google Similarity Distance IEEE Transactions on Knowledge and Data Engineering”, proposes a hierarchical clustering method using visual, textual & link analysis. By using a vision based page segmentation algorithm, a web page is divided into blocks, and the textual and link information of an image can be accurately extracted from the block containing that image. By using block level link analysis method, an image graph can be constructed. We then used spectral method to find a Euclidean embedding of the images which respects the graph structure. Thus for every image, there are three kinds of modes, i.e.
visual feature based representation, textual feature based representation & graph based representation
In 2009, D. Liu, X. Hua, L. Yang, M. Wang, and H. Zhang “Tag ranking”,The author has projected a tag ranking technique to rank the tags of a given image, in which chance density estimation is employed to urge the initial connection scores and a random walk is projected to refine these scores over a tag similarity graph [5].
In 2010, M. Wang, K. Yang, X. Hua, and H. Zhang, “Towards relevant and diverse search of social images”, presents a numerous connection ranking theme that at the same time takes connection and diversity into account by exploring the content of pictures and their associated tags. First, it estimates the connection scores of pictures with respect to the question term primarily based on each visual info of pictures and semantic info of associated tags. Then linguistics similarities of social pictures are calculable based mostly on their tags. primarily based on the connection scores and the similarities, the ranking list is generated by a greedy ordering formula that optimizes Average numerous preciseness (ADP), a novel live that is extended from the typical Average preciseness (AP).
In 2012,Linjun Yang, Member, and Alan Hanjalic ,
walk is planned to refine these scores over a tag similarity graph.
In 2013, X. Qian, X. Liu, and C. Zheng, system drawback is user tagging is understood to be uncontrolled, ambiguous, and excessively personalized, a basic drawback is a way to interpret the connection of a user contributed tag with respect to the visual content the tag is describing. we have a tendency to propose answer to the system is a social re- ranking technique for tag based mostly image retrieval. It is a new approach of tag image re-ranking for social dataset. It will be used for retrieving pictures on the basis of tagging. This approach for Social image analysis and retrieval is very important for helping individuals organize and access the increasing amount of user-tagged transmission..
In 2014,X.Qian, X. Hua , Y.Tang , and T.Mei ,,” social image tagging with diverse semantics” ,author has implemented a retagging approach to hide a good vary of linguistics, within which each the connection of a tag to image further as its linguistics compensations to the already determined tags are united to see the final tag list of the given image
In2016,T.Chaitanya Reddy ,K Chaitanya “Ranking of Images Based on Tags”, Author presents a new theory of similarity between words and phrases based mostly on info distance and Kolmogorov complexness. To fix thoughts we have a tendency to use the world wide net as information, and Google as computer program. The technique is additionally applicable to different search engines and databases. This theory is then applied to construct a technique to mechanically extract similarity, the Google similarity distance, of words and phrases from the planet wide net exploitation Google page counts.
In 2016,Xueming Qian , Member, Dan Lu, Yaxiong Wang, Li Zhu,“ Image Re-ranking based on Topic Diversity”, proposed implemented Social media sharing websites allow users to annotate images with free tags, which significantly contribute to the development of the web image retrieval. Tag-based image search is a very important technique to search out pictures shared by users in social networks. However, the way to create the highest hierarchical result relevant and with diversity is difficult. In this system, we introduce a topic diverse ranking approach for tag-based image retrieval with the consideration of advance the topic coverage performance. First, we tend to construct a tag graph supported the similarity between every tag. Then community detection technique is conducted to mine the subject community of every tag. After that, inter-community and intra-community ranking square measure introduced to get the ultimate retrieved results. In the inter-community ranking process, an adaptive random walk model is employed to rank the community stand on the multi- information of every topic community. Besides, we tend to build associate inverted index structure for pictures to
accelerate the looking out method. Experimental results on Flickr dataset and NUS-Wide datasets show the effectiveness of the planned approach.
In 2017,Muyuan Fang and Yu-Jin Zhang,” Query Adaptive Fusion for Graph-Based Visual Re-ranking”, has planned a unique technique for graph primarily based visual re ranking, that addresses 2 major limitations in existing ways. First, within the section of graph construction, our technique introduces fine-grained measurements for image relations, by assignment the sting weights mistreatment normalized similarity. additional a lot of ,in the section of graph fusion, instead of summary all the graphs for various single options indiscriminately, they planned to estimate the responsibility of every feature through a applied math model, and by selection fuse the one graphs via query-adaptive fusion weights. Fusion ways with either labeled knowledge and unlabeled knowledge are projected and therefore the performance are evaluated and compared by experiments. This technique is evaluated on 5 public datasets, by fusing scale-invariant feature rework (SIFT), CNN ,and hue, saturation, hue (HSV), 3 complementary options. Experimental results demonstrate the effectiveness of the planned technique, that yields superior results than the competitive ways
3.
Problem Definition
To implement the system using K nearest neighbor algorithm to search the images from web using keywords based approach to make the searching more faster and efficient. This will make the ranking of images using the relevance of the keywords.
4.
System Architecture
In this system, we focus on the topic diversity. We first group all the tags in the initial retrieval image list to make the tags with similar semantic be the same cluster, and then assign images into different clusters. The images within the same cluster are viewed as the ones with similar semantics. After ranking the clusters and images in each cluster, we select one image from each cluster to achieving our semantic diversity. In this system, we propose to construct the tag graph and mine the topic community to diversify the semantic information of the retrieval results. The contributions of this system are summarized as follows:
vector of each tag based on the English Wikipedia corpus with the model word2vec. We rank each mined community according to their relevance level to the query. In the inter- community ranking process, an adaptive random walk model is employed to accomplish the ranking based on the relevance of each community with respect to the query, pair-wise similarity between each community, and the image number in each community.
Fig: System Architecture
We are used Net bean IDE 8.2,Wamp Server This software are used , Net bean IDE 8.2 Net Beans is a software development platform written in Java. The Net Beans Platform allows applications to be developed from a set of modular software components called modules. Applications based on the Net Beans Platform, including the Net Beans integrated development environment (IDE).
MySQL is released under an open-source license. So you have nothing to pay to use it. MySQL uses a standard form of the well-known SQL data language.
Algorithm:-
KNN Algorithm:- [input :Tag name output :Nearest neighbor]Step 1=A Positive integer K is specified
Step 2=We find the K entries in our database which are closest to the new sample.
Step 3=We find the most commons classification of these entries.
Step 4=This is the classification we give to find new sample.
5. Results
5.1Searching Time:- The searching time of the network is the total no. of data searched to a system at a time. The searching time of the system is calculated by the size of data per unit existing system as less searching time is required for the proposed system means larger efficiency.
Fig 5.1:-Comparison between existing system and propose system
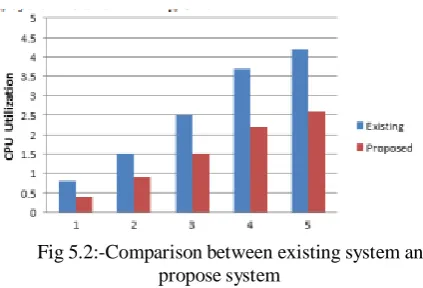
5.2 Energy Consumption:- As the proposed system is ad hoc network, it uses the limited source of energy. So we have to reduce the energy consumption of the system used for encryption of the messages. Less encryption time also means fewer CPU cycles, and less energy consumptions. The proposed system uses the simple substitution technique so the CPU utilization of the system is lower as comparedto the existing system. Less CPU utilization of the system consumes the less energy. The difference between the proposed system and existing system is shown in fig 5.2.
Fig 5.2:-Comparison between existing system and propose system
Show Above graph, Blue color indicate existing system and red color indicates proposed system. According to both graph. In first graph we enhance searching time as compare to existing system. An second graph we enhance less CPU utilization.
5.3Throughput:-
The throughput of the network is the total no. of messages transferred to a system at a time. The throughput of the system is calculated by the size of message per unit time i.e. seconds, minutes, hours. The throughput of system is always high. In proposed system the throughput is higher than the existing system as less searching time means larger throughput.
Conclusion
299 | P a g e
not powerful enough to retrieve images efficiently by it including semantic concepts. The work presents an approach to re-rank the web-based images by narrow down the semantic gap between query keywords. The query-specific semantic signatures extensively improve both the proper and efficiency of image re-ranking. Derived two algorithm which is best for image search for the web image re-ranking both text and images will be provided the best image search results as well tested the idea of re-ranking on the three text queries to a large-scale web image search engine and it will be reasonable or need the image are re-ranked using keyword expansion to provide better efficiency and effectiveness by using precise output.
References
[1] R. Cilibrasi and P. Vitanyi, \The Google Similarity Distance IEEE Transactions on Knowledge and Data Engineering, 19(3):1065 -1076, 2007.
[2] D. Liu, X. Hua, L. Yang, M. Wang, and H. Zhang, “Tag ranking”. WWW, 2009: 351-360.
[3] M. Wang, K. Yang, X. Hua, and H. Zhang, “Towards relevant and diverse search of social images”. IEEE Trans. Multimedia, 12(8):829-842, 2010.
[4] Linjun Yang, Member, IEEE, and Alan Hanjalic , Senior Member, IEEE, \Prototype Based Image Search Reranking IEEE TRANSACTIONS ON MULTIMEDIA, VOL.14, NO. 3, JUNE 2012.
[5] X. Qian, X. Liu, and C. Zheng, Tagging photos using users' vocabularies. Neuro-computing, 111(111), 144-153, 2013
.
[6] X. Qian, X. Hua, Y. Tang, and T. Mei, \social image tagging with diverse semantics IEEE Trans. Cybernetics, vol.44, no.12,2014, pp. 2493-2508.
[7] T. Chaitanya Reddy, K. Chaitanya, \Ranking of Images Based on Tags",2016.
[8] Image Re-ranking based on Topic Diversity" Xueming Qian , Member, IEEE, Dan Lu, Yaxiong Wang, Li Zhu, Yuan Yan Tang, Fellow, IEEE, and Meng Wang.
[9] Muyuan Fang and Yu-Jin Zhang, Senior Member, IEEE,\Query Adaptive Fusion for Graph-Based Visual Re-
ranking in IEEE Journal of Selected Topics in Signal Processing, vol. 11, no. 6, pp. 908-917, Sept. 2017.
[10] X. Qian, H. Wang, Y. Zhao, et al.,Image Location Inference by Multisaliency Enhancement. IEEE Trans. Multimedia 19(4): 813-821 (2017)
[11] X. Lu, X. Li and X. Zheng, Latent Semantic Minimal Hashing for Image Retrieval,IEEE Trans. Image processing, vol. 26, no. 1, pp. 355-368, 2017.
[12] A. Ksibi, A. Ammar, and C. Amar, “Adaptive diversification for tag based social image retrieval”. International Journal of Multimedia Information Retrieval, 2014, 3(1): 29-39.
[13] Y. Gao, M. Wang, H. Luan, J. Shen, S. Yan, and D. Tao, “Tag-based social image search with visual-text joint hypergraph learning”. ACM Multimedia information retrieval, 2011:1517-1520.
[14] X. Li, B. Zhao, and X. Lu, A General Framework for Edited Video and Raw Video Summarization," IEEE Transactions on Image Processing. Digital Object Identifier (DOI): 10.1109/TIP.2017.2695887.
[15] K. Song, Y. Tian, T. Huang, and W. Gao, “Diversifying the image retrieval results”, In Proc. ACM Multimedia Conf., 2006, pp. 707–710.
[16] R. Leuken, L. Garcia, X. Olivares, and R. Zwol, “Visual diversification of image search results”. In Proc. WWW Conf., 2009, pp.341–350.
[17] X. Qian, H. Wang, G. Liu, and X. Hou, “HWVP: Hierarchical Wavelet Packet Texture Descriptors and Their Applications in Scene Categorization and Semantic Concept Retrieval”. Multimedia Tools and Applications, May 2012. [18] X. Lu, Y. Yuan, X. Zheng, Jointly Dictionary Learning for Change Detection in Multispectral Imagery, IEEE Trans. Cybernetics, vol. 47, no. 4, pp. 884-897, 2017.
[19] J. Carbonell, and J. Goldstein, “The use of MMR, diversity based re ranking for reordering documents and producing summaries”. SIGIR 1998.
[20] Wu, J. Wu, and M. Lu, “A Two-Step Similarity Ranking Scheme for Image Retrieval. In Parallel Architectures”. Algorithms and Programming, pp. 191-196, IEEE, 2014.
Anther’s Profile
Ashwini Bachhav is a approved BE (computer Engineering) At Shatabdi Institute of engineering and research
collage Agaskhind. Savitribai phule pune university,pune (India).
Trunali Ghotekar is a approved BE (computer Engineering) At Shatabdi Institute of engineering and research collage Agashkind. Savitribai phule pune university,pune (India).
Shivani Shah is a approved BE (computer Engineering) At Shatabdi Institute of engineering and research collage Agaskhind. Savitribai phule pune university,pune (India).