On the construction of a RoboCup small size league team
14
0
0
Full text
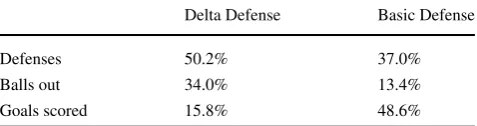
Figure
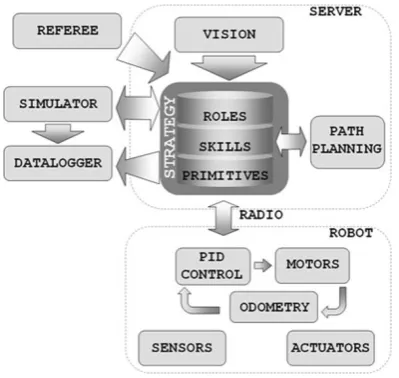
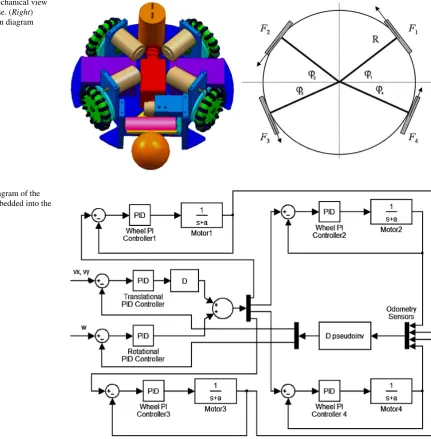
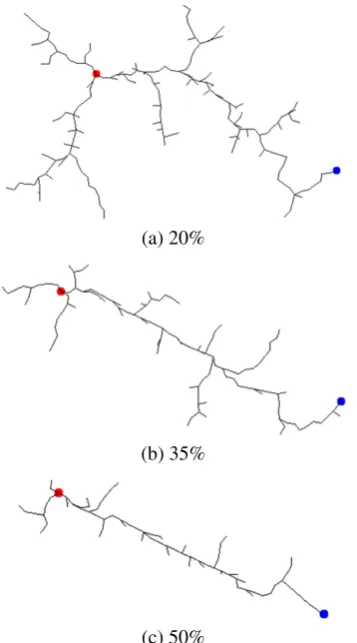

+4

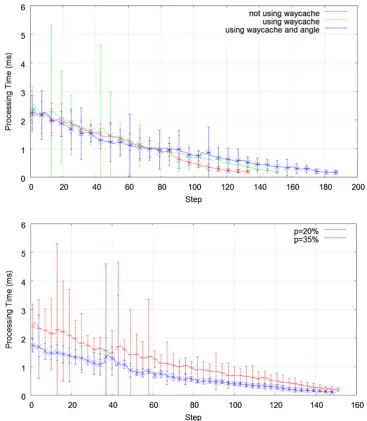
Related documents
