All Rights Reserved © 2015 IJARCSEE
167
Feature Extraction of Image Using Gray-level and KNN based
Genetic Algorithm
Kriti Joshi Mtech Scholar
CSE, LNCTS Bhopal, India
Amrit Suman Assistant Professor
CSE, LNCTS Bhopal, India
Dr. Sadhna Mishra Head of Department
CSE, LNCTS Bhopal, India
Abstract -
The feature extraction of image becomes much essentialnowadays from big image database which reduces the cost of storage as well as provide good quality of image. In this work, we propose an approach which extract feature of image on the basis of color, texture and shape. The color feature extraction is done using the probability, entropy and information gain while for texture uses gray level co-occurrence matrices and for shape uses Fourier descriptor (FD). Before extract these characteristic of image we relate KNNGA algorithm to optimize the extracted result from the big database. The experimental analysis of the proposed approach is simulated on MATLAB2012a toolbox which comprises the various functions to simulate it. Analysis of our work is performing on well known performance metric accuracy and false alarm rate (FAR) etc. After simulation it is analyze that our proposed system performs well than the some other approaches.Keywords
Words:-Content based image retrieval (CBIR), Gain, GLCM, Fourier descriptors, Similarity matching, MATLAB2012a, KNN-Genetic algorithm, FAR.
1.
INTRODUCTION
Nowadays the use of Image information systems is greatly increases with the advancements in broadband networks, high-powered workstations etc. huge collection of images be attractive available to the public, from photo collection to web pages, otherwise smooth video database. While illustration medium require amounts of memory and computing power for processing and storage space, here is a require to competently directory as well as retrieve visual information on or after image record. During current time, image categorization have expand into an attractive investigate field in application. Efficient indexing and retrieval of huge amount of color images, categorization plays a significant and challenging role [1]. In image processing, a color histogram is a demonstration of the allocation of colors in an image. For digital images, it is basically the number of pixels that have color in a piece of a fixed list of color ranges that span the image color space, the set of all possible colors. Color histogram method be a very easy as well as low level technique and in practice it has shown good results [2] specially designed for image indexing as well as retrieval tasks, wherever similar (not necessary identical) images are to
be retrieved along with simple feature extraction. This and ensure complete conversion and revolution invariance into the color descriptions below categorization job.
A color is representing in a three dimensional vector equivalent in the direction of a position in a color space. This leaves us to choose the color breathing space and the quantization steps in this color space. Instead of color some other features of images is texture and shape extraction which is also essential to extract this to reduce the cost of storage and generate a good quality of image. In this paper we perform the extraction of all features of image means color, texture and shape. The entropy, probability and information gain appearance be use designed for color feature extraction of image whereas intended for texture extraction of image we perform gray level co-occurrence matrices. And for shape of image uses Fourier descriptor (FD) after the feature extraction on feature is it essential to reduce or optimize the image from the classification which uses KNN-GA (K-nearest neighbor and Genetic Algorithm). The classification of extracted feature is performed on the basis of similarity factor.
CBIR is the learning of browsing digital images starting great database set. This is a rising research region having a large amount purpose in the field of image processing, pattern reorganization, medical fields etc. the two main steps in a CBIR techniques are, features extraction and similarity measurements[3].In content based image retrieval (CBIR) system derivative features consist of primitive features like color, texture and shape [4]. Content based image retrieval (CBIR) aim to extend techniques use for extracting parallel images from an images database on the base of mechanically resulting image features. Specified an input query image, we extract its features and calculate the similarity (distances) of features stuck between the query image and images in the database. The system precedes similar images according to the similarity ranking [5].
All Rights Reserved © 2015 IJARCSEE
168
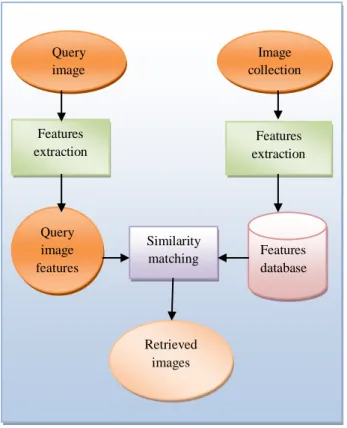
Fig.1 Content-Based Image Retrieval System
Fig: 1 Content based image retrieval system
The remaining section of paper is organized in such a way: Section 2 discusses about the related work which is previously done in section 3.
2.
RELATED WORK
Feature extraction from the set of huge database is wide area of research and lots of work also has been done. In this section of the paper we presents some literature survey of the previous work perform in the field of feature extraction in content based image retrieval system on the basis of texture, color and shape.
In this paper [6] author proposed projected a biased maximum margin analysis and a semi-supervised BMMA (Semi-BMMA) for integrating the unusual properties of feedbacks and developing the information of unlabeled models for SVM-based RF methods. The BMMA discriminates optimistic feedbacks as of negative ones base resting on local investigation, while the Semi-BMMA can efficiently fit in information of unlabeled samples by commencing a Laplacian regularizer to the BMMA. They properly formulate this predicament into a general subspace learning task and subsequently proposed an automatic approach for influencing the dimensionality of the embedded sub-space for RF. Widespread experiments on a outsized real-world image database reveals that the proposed method combined with the SVM RF can significantly advances the performance of CBIR systems.
In this paper [7] author proposed presented a new-fangled relevance feedback (RF) method for content-based image retrieval (CBIR) which utilizes Gaussian mixture (GM) modeled as image representations. The GM of every
image is acquired as an alteration of a worldwide GM which models the probability distribution of the aspects of the image database. In each RF round, the positive and negative examples presented by the user until the current round are used to train a support vector machine (SVM) to discriminate among the appropriate and irrelevant images according to the preferences of the user. In order to enumerate the resemblance among two images represented as GMs, Kullback-Leibler (KL) approximations are employed, the computation of which can be support accelerated taking benefit from the reality that the GMs of the images are all refined from a common model. The appropriate kernel function, based on this distance between GMs, is used to make probable the incorporation of GMs in the SVM framework. Lastly, comparative numerical experiments that showed the merits of the proposed RF system and the benefits presented.
In this paper author proposed [8] an original structure for join in adding up to weighting each of three i.e. color, shape and texture features to get elevated retrieval efficiency. The color feature is extract via count the YUV color space as well as the color attributes parallel to the mean value, the standard deviation, and the image bitmap of YUV color space is represent. The texture features are obtained by the entropy base on the gray level co occurrence matrix and the edge histogram descriptor of an image. The shape feature descriptor is resulting starting Fourier descriptors (FDs) and the FDs derived as of dissimilar signature. While calculate the similarity fixed between the query image and objective image in the database, normalization in series distance is as well used for regulate distance values into the similar level. And following that the linear mixture has used to merge the normalized distance of the color, shape and texture features to get the similarity as the indexing of image. Still, a new outcome point to, a weight variation to get important retrieval ineffectiveness and the designed technique positively outperforms additional system in situation of the accuracy as well as effectiveness.
In this paper [9] author proposed a Modified K-Nearest Neighbor (MKNN) can be considered a kind of weighted KNN thus to facilitate the inquiry label be approximated through weighting the neighbors of the inquiry. The procedure calculates the fraction of the identical label neighbors toward the whole quantity of neighbors. MKNN classification is based on validated neighbors who include extra information within evaluation through easy group labels. This paper also contemplated identifying the unlabeled images with help of M-KNN algorithm. Experiments show the validity takes into accounts the value of stability and robustness of the several guide sample concerning by means of its neighbors and excellent improvement in the performance of KNN method. This scheme allows give label toward unlabeled image as user input.
In this paper [10] author proposed presented well-designed and successful method for content-based image indexing and retrieval. The system utilizes the global and local features of the images for indexing and fractional Query
image
Image collection
Features extraction
Features extraction
Query image features
Similarity
matching Features
database
All Rights Reserved © 2015 IJARCSEE
169 distance measure as resemblance measure for retrieval.
The images are quantized prior to extracting the global features. They had also presented a novel method for image segmentation to mine the region features effectively. R*-Tree data structure is used in indexing the region features. The experimental outcomes showed that the proposed system can advance the retrieval precision as well as diminish the time for retrieval.
3.
FEATURES OF IMAGES
The preliminary step of CBIR system is to correspond to color component and shape regions into features vector. There are diverse ways to symbolize feature of digital images. In this paper following color and shape feature extraction techniques are proposed.
3.1 Color Feature
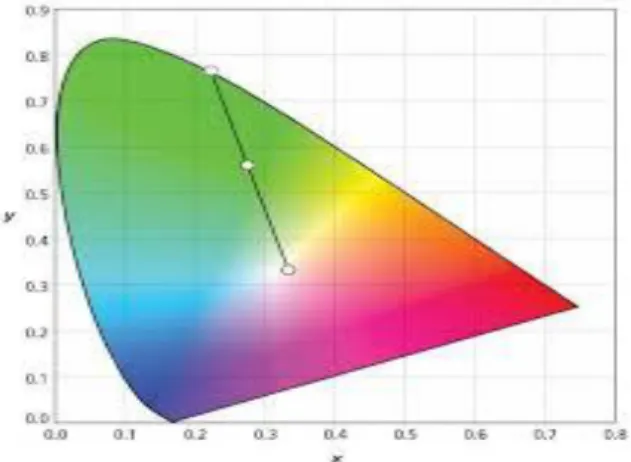
Designed for the preliminary progression of histogram similar, we utilize the HSV color space.
The HSV color space be chosen designed used for exploitation of color and saturation (to shift colors or adjust the amount of color) because it yield a larger active variety of diffusion [11]. Figure 2 illustrates the single hex cone HSV color reproduction. The top of the hex cone-shaped tool correspond toward V = 1, or the maximum intensity of colors. The point at the base of the hex cone-shaped tool be black as well as here V = 0. Corresponding colors are 180° opposite one another as measured by H, the angle about the vertical alliance V, among red at 0°. The cost of S is a ratio, ranging from 0 on the center line vertical alliance V to 1 resting on the side of the hex cone-shaped tool. Several cost of S between 0 and 1 may be associated through the position V = 0. The position S = 0, V = 1 be white. In-between values of V designed for S = 0 be the grays. Make a note of that at what time S = 0, the value of H be relevant. as of an artist’s point of view, several color through V = 1, S = 1 is a clean coloring whose color exist specific through H. addition white and black correspond to decreasing S without changing V and correspond toward declining V with no change S correspondingly .Tones be formed by decreasing both S and V.
Fig: 2 Color feature of image dataset
3.2 Shape Feature
Shape is an imperative illustration feature and it is single of the necessary features used to describe image content. However, shape illustration and explanation is a complicated task. This is because when a 3-D real world object is projected on top of a 2-D image plane, single dimension of object information is missing. As a result, the shape extracted from the image simply incompletely represents the projected object. To make the problem even more complex, shape is often corrupted through noise, defects, arbitrary distortion and occlusion. Further it is not known what is important in shape. Present approach has together positive and negative attributes; computer graphics or mathematics use effective shape demonstration which is unfeasible inside shape recognition with vice versa. Inspire of this, it is possible to find features common to the majority shape description approach. Essentially, shape-based image retrieval consists of measuring the similarity between shapes represent by their features. A quantity of easy geometric features can be used to describe shapes. Usually, the simple geometric features are capable of simply discriminate shapes by way of huge differences; for that reason, they be regularly use as filters to remove false hits or else collective with additional shape descriptors to differentiate shapes. They are not suitable to location simply shape descriptors. A shape can be described by different aspects [12]. These shape parameters are Mass, Center of gravity (Centroid) [13], Mean, Variance, Dispersion, Axis of least inertia, Digital bending energy, Eccentricity, Circularity ratio, Elliptic variance, Rectangularity, Convexity, Solidity, Euler number, Profiles, Hole area ratio, etc.
Fig: 3 Shape features of Image dataset
3.3 Texture Feature
All Rights Reserved © 2015 IJARCSEE
170 Fig 4: Texture feature of image dataset
4. PROPOSED WORK
The CBIR seem to be extremely useful technique not simply for the management of large numbers of image data, excluding also helpful to a multiplicity of field such as research, clinical medication, education and visual knowledge. CBIR is aimed to retrieve preferred images based on the similarity measurements. The individuality of these similarity measurements includes intensity, color, texture, size, location and so on.
4.1 Feature Extraction Module
The input images, including the instruction and query phase, are everyone process in this section. It is also the most important in image retrieval. While color is the majority admired and instinctive feature base on human visualization, it is applied in the system. In order to get extra dominant features, the CCH method as well as useful for extracting the imperative feature point. In this module two types of features are describe below:
I. Color Feature Extraction
Input images determination be separated into F*S grids ahead of this stage. Every grid is input to take out the color feature. Initial, the element calculate the average RGB value of the F*F grids. Second, the inside S*S grids in each F*S grids will in addition be input to analyze the average RGB value. The S*S grids’ detail RGB information is add on after the F*S grids’ color feature information. Everyone those are ready for first K-means clustering. Figure 2 demonstrate the color feature extractions of this segment.
II. CCH feature extraction
The system utilizes CCH (Conventional color histogram) to find out the important feature points. All the points are detected for preparing the input data of the neighborhood module and K-means clustering or KNN classifying. The information of CCH feature points, including the 64 dimensions data, combines with the neighborhood module result. Taking it as the input for the second round K-means clustering, the K-K-means clustering results in a fragment-based database, call the Code book. As the same implementation in query step, K-means is replaced by KNN algorithm. Query data imputed will be classified to improve the training code book, also correct classified result helps for quickly retrieval.
4.2 Grey-level co-occurrence matrix for texture Grey-Level Co-occurrence Matrix texture dimensions have been the workhorse of image texture as they were anticipated by Haralick. So many image analyst, they are a button you thrust in the software that capitulates a band whose use progresses classification – or not. The foremost works are essentially condensed and mathematical, making the procedure intricate to understand for the student or front-line image analyst. Determine the selected Feature. This computation uses only the values in the GLCM. See:
I. Contrast II. Correlation III. Energy IV. Homogeneity
These features are planned by distance 1 and angle 0, 45 and 90 degrees.
4.3 Fourier descriptors (FDs)
In general, Fourier descriptors (FDs) are obtained by applying Fourier transform on a shape signature, the normalized Fourier transformed coefficients are called the Fourier descriptors of the shape. The shape signature is
any one-dimensional function representing
two-dimensional areas. Tree shape signatures are considered in our case, these are centroid distance, complex coordinates, and curvature signature which is derived from shape boundary coordinates.
4.4 K-Means Clustering
K-means clustering is an approach to classify or to group objects based on aspects/features into K number of group [8]. K is positive integer number. The grouping is executed by minimizing the sum of squares of distances among data and the corresponding cluster centroid. Therefore the intention of K-mean clustering is to classify the data.
A cluster is a group of data objects that are comparable to single one more within the same cluster and are dissimilar to the objects in the additional clusters. It is the greatest suitable for data mining because of its efficiency in processing big data sets. It is definite as follow:
The k-means algorithm is built upon four basic operations:
I. Selection of the preliminary k-means for k-clusters. II. Computation of the difference between an object and the mean of a cluster.
III. Allotment of an object of the cluster whose mean is neighboring to the object.
IV. Re-calculation of the mean of a cluster from the object allocated to it so that the intra cluster difference is minimize.
The advantage of K-means algorithm is that it works glowing when clusters are not glowing separated from each other, which is frequently encountered in images.
4.5 K- Nearest Neighbors Algorithm
All Rights Reserved © 2015 IJARCSEE
171 and training samples. The classifiers do not employ any
model to fit and only based on memory. Specified a query point, we discover K digit of objects (training points) neighboring to the query point. The classification is using majority vote amongst the classification of the K objects. Whichever ties can be broken at random. K Nearest neighbor algorithm used neighborhood classification as the prediction value of the novel query instance.
4.6 Genetic Algorithm
GAs inside the pasture of evolutionary computation, be robust, computational, and stochastic search procedures modeled on the mechanics of natural genetic systems. In general, a GA contains a fixed-size population of possible solution over the search space. These possible solutions of the search space are encoded as binary or floating-point strings, call chromosomes. The preliminary population can be formed randomly or based on the problem- specific knowledge. GA is a branch of evolutionary computation. The main difference between IGA and GA is the construction of the fitness function, i.e., the fitness is resolute by the user’s evaluation and not through the predefined mathematical formula. A client can interactively find out which member of the population will reproduce, and IGA mechanically generate the subsequently production of content based on the user’s input. Through repetitive round of content generation and fitness assignment, IGA enable exclusive content to develop that suit the user’s preference. Base on this explanation, IGA can be used to resolve harms that are not easy or not possible to create a computational fitness function, for example, evolving images, music, a variety of artistic designs, and forms to fit a user’s aesthetic preference.
4.7 Algorithm for proposed method
Step 1- Verify image database. Step 2- Read all images from database. Step 3- Extract image RGB features.
Step 4- Stored all extracted features in a separate single file each.
Step 5- Now read query images.
Step 6- Now applying features extraction for color, texture and shape.
Step 7- Color feature extraction use probability, entropy and gain to find out Majority of color features.
Probability = no. of occurrences of a target event divided by no. of occurrences + the no. of fail occurs.
Entropy = measures of uncertainly of a random variable (statistical measure of randomness) and disorder of an image and it achieves its target value.
H(X) = 𝑚𝑘=1P X . log p(x)
Gain = gain find out the maximum color value and majority of the color.
Step 8 - Texture feature extraction used gray level co-occurrences matrix (GLCM) and edge histogram.
Step 9 - Shape feature extraction, extract by Fourier descriptor (FD).
extractions are described as below:
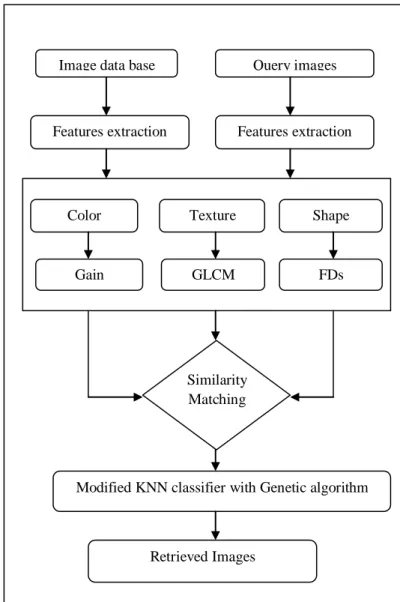
Fig 5: Block diagrams for proposed method
Step 10 - After extract all the features of color, texture and shape. Now we will apply similarity matching. Step 11 - Now applying modified KNN classifier with GA. For classification of images, for best optimized retrieval results.
Step 12- Now used Euclidean’s distances formula to calculate the distances between the query images and database.
Euclidean’s distances = root 𝑘 𝑥𝑖 − 𝑦𝑖
𝑖=1 ^2
Step 13 – Display the result in term of retrieved images.
4.
EXPERIMENTAL RESULTS
To examine the efficiency of the proposed method of content based image retrieval here we used MATLAB 2012A for simulation purpose and done experiment into most popular dataset.
Image Data Set
The coral image data set is very famous image data set for research purpose especially for image retrieval systems. And there are huge amount of images with 10 classes available into that set, but here we used approx 150 images.
Image data base Query images
Features extraction Features extraction
Shape Texture
Color
Gain GLCM FDs
Similarity Matching
Modified KNN classifier with Genetic algorithm
All Rights Reserved © 2015 IJARCSEE
172 Now we are going to explain the obtained result while
testing it. Here we have cross verified result with an existing method with our proposed method and found that our implemented method gives the better result to maximum set of images.
Fig. 6: Compared result of existing method with proposed method for horse
Fig. 7: Compared result of existing method with Proposed method for rose
Here we have selected only 9 categories of images, and in table 6.1 shows an individual accuracy of each image in and its compared graph is shown in fig.8. The overall accuracy is shown in table 6.2.and the compare graph in shown in fig.9.The comparison between existing and proposed method in which the proposed method gives the
97.00% while existing method gives overall accuracy 87.00%.
Table 6.1: Class wise accuracy of different image classes between Existing & Proposed
Individual accuracy
Method/Class Existing Proposed
C1 100 100
C2 70 90
C3 100 100
C4 100 100
C5 100 100
C6 60 90
C7 80 100
C8 80 90
C9 90 100
Fig. 8: Comparison of class wise accuracy
Table 6.2: Overall accuracy
Total accuracy
Method Existing Proposed
Accuracy% 87.00% 97.00%
0 20 40 60 80 100
C1 C2 C3 C4
C5 C6 C7 C8 C9
C
10
A c c u r a c y
% classes
Individual Accuracy
All Rights Reserved © 2015 IJARCSEE
173 Fig.9: Comparison graph
6. CONCLUSION
Digital image processing is widely used are area for research for the feature extraction of image, text etc. In this dissertation we proposed content based image retrieval using KNN (K-nearest neighbor) and (Genetic Algorithm) GA. The majority of color feature is measured using entropy, probability and information gain while for feature extraction of texture is perform by gray level co-occurrence matrix and edge histogram method which effectively increased the quality of text and shape of image is estimated using Fourier descriptor methodology. After reducing the feature of image on the basis of color, texture and shape we apply hybrid method KNN and GA for similarity matching and optimize the extracted result to augment the quality of the image. The dissertation uses MATLAB 2012a simulation toolbox to simulate proposed approach. The experimental result of proposed approach gives most effective outcomes than existing system. For analyzing the performance of the proposed approach we use performance metric accuracy and false alarm rate (FAR) in which our proposed approach outperforms. In future work, we need to perform the analysis of our proposed approach is for another performance metrics.
REFERENCES
[1].Saurabh Agrawal, Nishchal K Verma, Prateek Tamrakar, Pradip Sircar, “Content Based Color Image Classification using SVM”, In International Conference on Information Technology: New Generations-2011, proceeding of IEEE, 978-0-7695-4367.
[2].M. Swain and D. Ballard “Indexing via color histograms,” International Journal of Computer Vision, Vol. 7, pp. 11– 32, 1991.
[3].Jiska.K.P, Thusnavis Bella Mary.I, Dr.A.Vasuki “An image retrieval techniques based on texture features using
semantic properties”. International conferences on signal processing, image processing and pattern recognition [ICSIRP] 2013.
[4]. Wasim Khan, Shuv kumar.Neetesh gupta, Nilofar Khan, “A proposed method for image retrieval using histogram values and texture descriptor analysis”. International journal of soft computing and engineering (IJSCE), Volume-I Issue-II, May 2011.
[5].Guan-Lin Shen,Xiao-jun Wn,“Content based image retrieval by combining color, texture and Centrist”.School of IoT engineering jiangnam university,Wuxi,China,214122. [6].Lining Zhang, Lipo Wang ; Weisi Lin, “Semi-supervised
Biased Maximum Margin Analysis for Interactive Image Retrieval”, Image Processing, IEEE Transactions on (Volume:21 , Issue: 4 ), Page(s):2294 - 2308 ISSN :1057-7149.
[7].Marakakis, A., Siolas, G. ; Galatsanos, N. ; Likas, A. ; Stafylopatis, A., “Relevance feedback approach for image retrieval combining support vector machines and adapted gaussian mixture models”, Image Processing, IET (Volume:5 , Issue: 6 ), Page(s):531 - 540 ISSN :1751-9659.
[8].N. Suguna, and Dr. K. Thanushkodi, “An improved k-nearest neighbor classification using genetic algorithm”. IJCSI International Journal of Computer Science Issues, Vol. 7, Issue 4, No 2, July 2010.
[9].T. Dharani, I. Laurence Aroquiaraj, “Content Based Image Retrieval System using Feature Classification with Modified KNN Algorithm”.
[10].Suresh Pabboju, .Venu Gopal Reddy, “A Novel Approach for Content-Based Image Indexing and Retrieval System using Global and Region Features”, IJCSNS International Journal of Computer Science and Network Security, VOL.9 No.2, February 2009.
[11].Rafel C. Gonzalez and Richard E. Woods, “Digital Image Processing”, Second Edition, Pearson Education Asia, 2005”.
[12].Dengsheng Zhang and Guojun Lu, “Review of shape representation and description techniques”, Pattern Recognition Society. Published by Elsevier Ltd, Vol.37, pp. 1-19, 2004
[13].A. J. M. Traina, A. G. R. Balan, L. M. Bortolotti, and C. Traina Jr., “Content-based Image Retrieval Using Approximate Shape of Objects”, Proceedings of the 17th IEEE Symposium on Computer-Based Medical Systems, pp. 91-96, 2004.
[14].Aruna Verma, Deepti Sharma, “Content Based Image Retrieval Using Color, Texture and Shape Features”, International Journal of Advanced Research in Computer Science and Software Engineering, Volume 4, Issue 5,May 2014 ISSN: 2277 128X.
82 84 86 88 90 92 94 96 98
Existing Proposed