Towards Implicit Content-Introducing for Generative Short-Text
Conversation Systems
Lili Yao1, Yaoyuan Zhang1, Yansong Feng1, Dongyan Zhao1,2 and Rui Yan1,2 ∗
1Institute of Computer Science and Technology, Peking University, Beijing, China 2Beijing Institute of Big Data Research, Beijing, China
{yaolili,zhang yaoyuan,fengyansong,zhaody,ruiyan}@pku.edu.cn
Abstract
The study on human-computer conversa-tion systems is a hot research topic nowa-days. One of the prevailing method-s to build the method-symethod-stem imethod-s umethod-sing the gen-erative Sequence-to-Sequence (Seq2Seq) model through neural networks. Howev-er, the standard Seq2Seq model is prone to generate trivial responses. In this pa-per, we aim to generate a more meaning-ful and informative reply when answering a given question. We propose an implicit content-introducing method which incor-porates additional information into the Se-q2Seq model in a flexible way. Specifical-ly, we fuse the general decoding and the auxiliary cue word information through our proposed hierarchical gated fusion u-nit. Experiments on real-life data demon-strate that our model consistently outper-forms a set of competitive baselines in terms of BLEU scores and human evalu-ation.
1 Introduction
To establish a conversation system with adequate artificial intelligence is a long-cherished goal for researchers and practitioners. In particular, auto-matic conversation systems in open domains are attracting increasing attention due to its wide ap-plications, such as virtual assistants and chatbot-s. In open domains, researchers mainly focus on data-driven approaches, since the diversity and un-certainty make it impossible to prepare the inter-action logic and domain knowledge. Basically, there are two mainstream ways to build an open-domain conversation system: 1) to search pre-established database for candidate responses by
∗Corresponding author: [email protected]
query retrieval (Isbell et al., 2000; Wang et al., 2013;Yan et al.,2016;Song et al.,2016), and 2) to generate a new, tailored utterance given the user-issued query (Shang et al.,2015;Vinyals and Le, 2015;Serban et al.,2016;Mou et al.,2016;Song et al., 2016). In these studies, generation-based conversation systems have shown impressive po-tential. Especially, the Sequence-to-Sequence (Se-q2Seq) model (Sutskever et al., 2014) based on neural networks has been extensively used in prac-tice; the idea is to encode a query as a vector and to decode the vector into a reply. Inspired by (Mou et al., 2016), we mainly focus on the generative short-text conversation without context informa-tion.
Despite this, the performance of Seq2Seq generation-based conversation systems is far from satisfactory because its generation process is not controllable; it responses to a query according to the pattern learned from the training corpus. As a result, the system is likely to generate an un-expected reply even with little semantics, e.g, “I don’t know” and “Okay” due to the high frequency of these patterns in training data (Li et al.,2016a; Mou et al.,2016). To address this issue, Li et al. (2016a) proposed to increase diversity in the Se-q2Seq model so that more informative utterances have a chance to stand out. Mou et al. (2016) provided a content-introducing approach that gen-erates a reply based on a predicted word. The word is usually enlightening and drives the gen-erated response to be more meaningful. However, this method is to some extent rigid; it requires the predicted word to explicitly occur in the generat-ed utterance. As shown in Table1, sometimes, it is better to generate a semantic related sentence based on the cue word rather than including it in the reply directly.
As for such content-introducing method, there are two aspects that need to be taken into
Query 你不觉得好丑吗(Don’t you think it is ugly?) Cue Word 审美(Aesthetics)
Reply 好恶心啊! (It’s disgusting!)
Query 先放个大招(Let me use my ultimate power.)
Cue Word 技能(Skill)
Reply 新技能?(New skill?)
Table 1: The content-introducing conversation ex-amples.
eration. 1) How to add the additional cue words during the generation process? One of the pre-vailing methods is modifying the neural cell with various gating mechanisms (Wen et al., 2015a,b; Xu et al.,2016). However, we need careful oper-ation to ensure the neuron works as expected. 2) How to display the cue words in replies? As men-tioned above, the explicit content-introducing ap-proach in (Mou et al.,2016) does not fit well with all situations.
In this paper, we present an implicit content-introducing method for generative conversation systems, which incorporates cue words using our proposed hierarchical gated fusion unit (HGFU) in a flexible way. Our main contributions are as fol-lows:
• We propose the cue word GRU, another neu-ral cell, to deal with the auxiliary informa-tion. Compared with other gating methods, our cue word GRU is more flexible.
• We focus on the implicit content-introducing method during generation: the information of the cue word will be fused into the gen-eration process but not necessarily occur ex-plicitly. In this way, we change the “hard” content-introducing method into a new “soft” schema.
The rest of paper is organized as follows. We s-tart by introducing the technical background. In Section 3, we describe our proposed method. In Section 4, we illustrate the experimental setup and evaluations against a variety of baselines. Section 5 briefly reviews related work. Finally, we con-clude our paper in Section 6.
2 Technical Background
2.1 Seq2Seq Model and Attention Mechanism
Seq2Seq model was first introduced in statistical machine translation; the idea is to encode a source
sentence as a vector by a recurrent neural network (RNN) and to decode the vector to a target sen-tence by another RNN. Now, the conversational generation is treated as a monolingual translation task (Ritter et al.,2011;Shang et al.,2015). Given a queryQ= (x1, ..., xn), the encoder represents it as a context vectorCand then the decoder gener-ates a responseR= (y1, ..., ym)word by word by maximizing the generation probability ofR con-ditioned onQ. The objective function of Seq2Seq can be written as:
p(y1, ..., ym|x1, ..., xn)
=p(y1|C) T
Y
t=2
p(yt|C, y1, ..., yt−1) (1)
To be specific, the encoder RNN calculates the context vector by:
ht=f(xt, ht−1);C =hT (2) where ht is the hidden state of encoder RNN at time t and f is a non-linear transformation which can be a long-short term memory unit (L-STM) (Hochreiter and Schmidhuber, 1997) or a gated recurrent unit (GRU) (Cho et al.,2014). In this work, we implementfusing GRU.
The decoder RNN generates each reply word conditioned on the context vector C. The prob-ability distributionptof candidate words at every time steptis calculated as:
st=f(yt−1, st−1, C);pt=softmax(st, yt−1) (3) where st is the hidden state of decoder RNN at timetandyt−1 is the generated word in the reply at timet−1.
Attention mechanisms (Bahdanau et al.,2014) have been proved effective to improve the gener-ation quality. In Seq2Seq with attention, eachyi corresponds to a context vectorCi; it is weighted average of all hidden states of the encoder. For-mally, Ci is defined asCi = PTj=1αijhj, where
αij is given by:
αij = PTexp(eij)
𝑪𝒕(𝛼𝑡) 𝒉𝟏 𝒚𝟏 𝒉𝒎 𝒚𝒎 … … 𝒔𝒏 𝒙𝒏 … … 𝒔𝟏 𝒙𝟏 𝑪𝒕(𝛼𝑡) 𝒔𝟏 𝒙𝟏 𝒔𝒏 𝒙𝒏 … … 𝒉𝟏 𝒚𝟏 𝒉𝒎 𝒚𝒎 … … Online process 𝒊𝒏𝒇𝒐: 𝑪𝒘
Pre-process Trained model User’s query
Cue word prediction Implicit content introducing
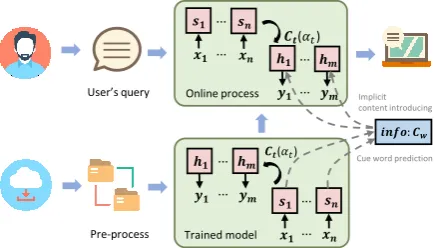
Figure 1: The architecture of our system. Based on the constructed corpus, we train our implicit content-introducing conversation system. Given a user-issued query, we first predict the cue word. Then, we incorporate the cue word into decoding process to generate a meaningful response.
2.2 Pointwise Mutual Information
Pointwise mutual information (PMI) (Church and Hanks, 1990) is a measure of association ratio based on the information theoretic concept of mu-tual information. Given a pair of outcomesxand
y belonging to discrete random variables X and
Y, the PMI quantifies the discrepancy between the probability of their coincidence based on their joint distribution and their individual distributions. Mathematically:
PMI(x, y) = log p(x, y)
p(x)p(y) = log
p(x|y)
p(x) (5)
This quantity is zero if xand y are independent, positive if they are positively correlated, and neg-ative if they are negneg-atively correlated.
3 Implicit Content-Introducing Conversation System
Figure1provides an overview of our system archi-tecture. We crawl conversational data from social media which are publicly available. After filtering and cleaning procedures, we establish the conver-sational parallel dataset, which consists of a large number of alignedhquery−replyi pairs. Based on the entire set, we first predict the cue word for the given query in Subsection3.1. Next, we pro-pose the new implicit content-introducing process, which explores when to incorporate the predicted cue word in Subsection3.2and how to apply such information in Subsection3.3.
Input: 𝑦𝑡−1
ℎ𝑡
Output: 𝑦𝑡
[image:3.595.313.524.61.138.2]Cue word = 𝑦0 ℎ1 𝑦1 𝑦1 ℎ2 𝑦2 𝑦2 ℎ3 𝑦3 𝑦𝑡−1 ℎ𝑡 𝑦𝑡 … Cue word
Figure 2: The information fusion patterns. The local information initialization is presented by the blue arrowhead and the global information incep-tion includes both the blue arrowhead and the green arrowhead.
3.1 Cue Word Prediction
In computational linguistics, PMI has been used for finding collocations and associations between words. As mentioned inMou et al. (2016), it is an appropriate statistic for cue words prediction, which is also adopted in this paper to predict a cue word Cw for the given query. Formally, given a query word wq and a reply word wr, the PMI is computed as:
PMI(wq, wr) = logp(pw(qw|wr)
q) (6) Then, we choose the cue word Cw with highest PMI score against the query words
wq1, ..., wqn during the prediction, i.e., Cw =
argmaxwrPMI(wq1, ..., wqn, wr), where PMI(wq1, ..., wqn, wr)≈log
Q
ip(wqi|wr)
Q
ip(wqi)
=X
i
logp(wqi|wr)
p(wqi) =
X
i
PMI(wqi, wr) (7) The approximation is based on the indepen-dence assumptions of both the prior distribu-tionp(wqi)and posterior distributionsp(wqi|wr). Even the two assumptions may not be true, we use them in a pragmatic way so that the word-level P-MI is additive for a whole utterance. PP-MI penal-izes a common word by dividing its prior proba-bility; hence, it prefers a word which is most “mu-tually informative” with the query.
3.2 Information Fusion Patterns
To implant the specific information in conversa-tion system, we consider two types of informaconversa-tion fusion patterns, namely 1) Local information ini-tialization 2) Global information inception.
[image:3.595.73.291.65.189.2]𝒉𝒕
1 − +
𝑡𝑎𝑛ℎ
𝜎
𝑪𝒘 𝑪𝒕
𝒚𝒕−𝟏
𝒉𝒘 𝒉𝒚
𝑡𝑎𝑛ℎ
𝒉t−1 𝒉t−1
𝒉𝒚 𝒉𝒘
𝒉𝒚′ 𝑘 𝒉𝒘′
Standard GRU
Cue Word GRU Fusion Unit
𝑟𝑦 𝑟𝑤
[image:4.595.105.257.66.266.2]𝑧𝑦 𝑧𝑤
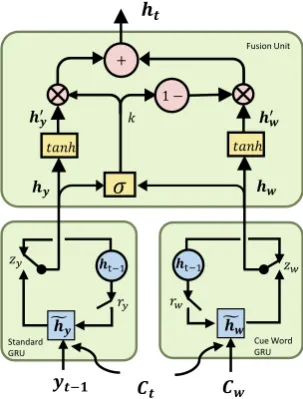
Figure 3: The structure of a HGFU. The bottom of two GRUs deal with corresponding input source, i.e., the last generated wordyt−1and the cue word
Cw. After that, fusion unit combines the output of two GRUs to compute current hidden stateht.
.
information only in the beginning of decoding. We describe this kind of pattern by the blue arrowhead in Figure 2. Recurrent neural networks(RNNs) such as gated recurrent units (GRUs) have the a-bility to keep the information from the beginning to the end to some extent. Therefore, the cue word added on the first step of the neural networks can still influence the generation of the later steps.
Global information inception. However, we observe that, although the network is capable of deciding what to keep in the cell state to affect the later generation, the influence of the added infor-mation in the beginning of decoding is becoming weaker and weaker over time. Therefore, to pro-vide the model a broader and more flexible space for learning, we propose a global information in-ception pattern, which fuses the cue wordCw as the auxiliary information at every step of decod-ing. This process is presented by both the blue arrowhead and the green arrowheads in Figure2.
3.3 Hierarchical Gated Fusion Unit
In this subsection, we propose our Hierarchical Gated Fusion Unit (HGFU), which incorporates cue words into the generation process and relaxes the constraint from the “hard” content-introducing method into a new “soft” schema. Figure3 pro-vides an overview of the structure of a HGFU. As
seen, the framework consists of three components: the standard GRU, the cue word GRU, and the fu-sion unit. Among them, standard GRU and cue word GRU take the last generated wordyt−1 and cue word Cw respectively as the decoder GRU’s input; the fusion unit combines the hidden states of both GRUs to predict the next wordyt. In the following, we will illustrate these components in detail.
3.3.1 Standard GRU
We adopt the standard gated recurrent unit (GRU) with the attention mechanism at the decoder part. Letht−1 be the last hidden state,yt−1 be the em-bedding of the last generated word, andCtbe the current attention-based context. The current hid-den state of the general decoding, hy, is defined as:
ry =σ(Wryt−1+Urht−1+UcrCt+br)
zy =σ(Wzyt−1+Uzht−1+UczCt+bz)
f
hy = tanh(Whyt−1+Uh(ry◦ht−1) +UchCt+bh)
hy = (1−zy)◦ht−1+zy◦hfy
(8) whereW’s ∈ Rdim×E andU’s ∈ Rdim×dim are weight matrices; b’s ∈ Rdim are bias terms; E denotes the word embedding dimensionality and
dim denotes the number of hidden state units. This general decoding process is presented by the “Standard GRU” in Figure3.
3.3.2 Cue word GRU
To generate more meaningful and informative replies, we introduce cue words as the additional information during generation. Naturally, the key point lies in how to incorporate such information. One of the prevailing methods is modifying the neural cell by various gating mechanisms. How-ever, these approaches are designed specially for a specific scenario, and not effective as expected when they are employed to other tasks. To tackle this issue, we propose the cue word GRU, another independent neural cell, to deal with the auxiliary information. Since this neural cell can be replaced easily by other units, it greatly improves the flexi-bility and reusaflexi-bility.
de-codinghwis computed by following equations:
rw =σ(WrCw+Urht−1+UcrCt+br)
zw =σ(WzCw+Uzht−1+UczCt+bz)
f
hw = tanh(WhCw+Uh(rw◦ht−1) +UchCt+bh)
hw = (1−zw)◦ht−1+zw◦hfw
(9) where W’s and U’s are weights andb’s are bias terms like those in the standard GRU. Note that the standard GRU does not share parameter matrixes with the cue word GRU. The “Cue word GRU” in Figure3describes the auxiliary decoding process.
3.3.3 Fusion unit
To combine both the general decoding information and the auxiliary decoding information, we apply the fusion unit (Arevalo et al., 2017) integrating the hidden states of both standard GRU, i.e., hy, and the cue word GRU, i.e., hw, to compute the current hidden stateht. The equations are as fol-lows:
h0y = tanh(W1hy)
h0w= tanh(W2hw)
k=σ(Wk[h0y, h0w])
ht=k◦hy+ (1−k)◦hw
θ={W1, W2, Wk}
(10)
withθ the parameters to be learned. From the e-quations above we can see that, the gate neuronk
controls the contribution of the information calcu-lated fromhy andhw to the overall output of the unit.
3.4 Model Training
When training on the aligned corpus, we random-ly sample a noun in the reprandom-ly as the cue word. The objective function was the cross entropy error be-tween the generated word distributionpt and the actual word distributionytin the training corpus. 4 Experiments
In this section, we compare our method with the-state-of-art response generation models based on a huge conversation resource. The objectives of our experiments are to 1) evaluate the effectiveness of our proposed HGFU model, and 2) explore how cue words affect the process of reply generation.
谢 谢 夸 奖 ! 么 么 哒 !
内 心 是 崩 溃 的 吧
递 纸 巾 !
说 过吗 ? 好 像 没 有 说过 啊 ! 内心
夸奖
纸巾
说过
Cor
re
lation
𝒌
op
en
n
ess
Figure 4: Heat map and thekgate openness. Bot-tom: The correlation between the generated reply words and the cue word. Top: The openness ofk
gate in fusion unit.
4.1 Experimental setup
We evaluated our model on a massive Chi-nese dataset of human conversation crawled from the Baidu Tieba1 forum. There are 500,000
hquery−replyipairs for training, 2,000 for val-idation, and another unseen 27,871 samples for testing. In total, we kept about 63,000 distinct words.
In our experiments, the encoder, the standard decoder and the cue word decoder have 1,000 hid-den units; the word embedding dimensionality is 610 which were initialized randomly and learned during training. We applied AdaDelta with a mini-batch size of 80 for optimization. These values were mostly chosen empirically. In order to pre-vent overfitting, early stopping was implemented using a held-out validation set.
4.2 Comparison Methods
In this paper, we conduct extensive experiments to compare our proposed method against sever-al representative baselines. All the methods ac-tually are implemented in two ways to utilize the cue word, which are local information initializa-tion and global informainitializa-tion incepinitializa-tion.
rGRU: Through a specially designed Recal-l gate (Xu et aRecal-l., 2016), domain knowledge was transformed into the extra global memory of a deep neural network.
SCGRU: In SCGRU (Wen et al.,2015b), an ad-ditional control cell was introduced to gate the
[image:5.595.322.504.60.223.2]Query 班主任还拍了我超级丑的照片已被笑死.(上上上镜镜镜)
Related Criterion Labels (Cue word) The teacher took a photo of me; it was really ugly
and people laughed at me. (Photogenic)
[image:6.595.308.527.269.379.2]Reply1 谁的照片?Whose photo? Logic Consistency Unsuitable Reply2 什么时候拍的?When did he took the photo? Implicit Relevance Neutral Reply3 抱抱。Give you a hug. Implicit Relevance Neutral Reply4 我拍照也都是巨丑的!My photos are also ugly! —— Suitable Table 2: An example query, corresponding cue word inboldand its candidate replies with human anno-tation. The query states that people laughed at the author’s photo, it is unsuitable to ask the ownership of this photo in Reply1. Generally, Reply2 and Reply3 apply to this scenario, but they do not reflec-t semanreflec-tic relevance wireflec-th reflec-the cue word. Reply4 reflec-talks aboureflec-t reflec-the respondenreflec-t’s sireflec-tuareflec-tion and relareflec-ted reflec-to “Photogenic”, thus it is a suitable response.
logue act (DA) features during the generation pro-cess.
SLGD: We implemented the Stochastic Language Generation in Dialogue (SLGD) method (Wen et al., 2015a), which added ad-ditional features in each gate of the neural cell.
FGRU: To explore more fusion strategies, intu-itively, we fused the cue word and hidden states by vector concatenation during the decoding process. Note that rGRU and SCGRU incorporate addi-tional information by gating mechanisms, while SLGD and FGRU fuse the information into each gate of the neural cell directly.
4.3 Experiment Evaluation
Objective metrics. To evaluate the performance of different methods for the conversation gener-ation task, we leverage BLEU (Papineni et al., 2002) as the automatic evaluation metric, which is originally designed for machine translation and evaluates the output by using n-gram matching between the output and the reference. Here, we use BLEU-1, BLEU-2 and BLEU-3 in our experi-ments.
Subjective metrics. Since automatic metric-s may not conmetric-simetric-stently agree with human percep-tion (Stent et al.,2005), human testing is essential to assess subjective quality. Hence, we randomly sampled 150 queries in the test set, then we invited five annotators to offer a judgment. For fairness, all of our human evaluation was conducted in a random, blind fashion, i.e., replies obtained from the five evaluated models are pooled and random-ly permuted for each annotator. Three levels are assigned to a reply with scores from 0 to 2: 0 =
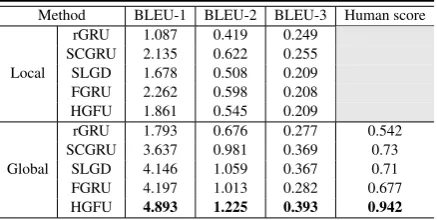
Method BLEU-1 BLEU-2 BLEU-3 Human score
Local
rGRU 1.087 0.419 0.249 SCGRU 2.135 0.622 0.255 SLGD 1.678 0.508 0.209 FGRU 2.262 0.598 0.208 HGFU 1.861 0.545 0.209
Global
rGRU 1.793 0.676 0.277 0.542 SCGRU 3.637 0.981 0.369 0.73
SLGD 4.146 1.059 0.367 0.71 FGRU 4.197 1.013 0.282 0.677 HGFU 4.893 1.225 0.393 0.942
Table 4: Performance of evaluated methods.
Unsuitable reply, 2 = Suitable reply, and 1 = Neu-tral reply.
To make the annotation task operable, the suit-ability of the generated reply is judged not only based on Grammar and Fluency, Logic Consis-tency and Semantic Relevance following (Shang et al.,2015), but alsoImplicit Relevance, i.e., the generated reply should be semantically relevant to the predicted cue word, no matter the cue word explicitly appears in the reply or not. If any of the first three criteria is contradicted, the reply should be labeled as “Unsuitable”. Only the replies con-forming to all requirements are labeled as “Suit-able”. Table2shows an example of the annotation results of a query and its replies. The first reply is labeled as “Unsuitable” because of the logic con-sistency. Reply2 and Reply3 are not semantically related to the cue word, and is therefore annotated as “Neutral”.
4.4 Overall Performance
Chinese Sentence English Tranlation
Query 写的真心棒!(夸夸夸奖奖奖) What a nice written! (Appreciation) Reply 谢谢夸奖!么么哒! Thanks for your appreciation! Love you! Query 还是无法淡定。(内内内心心心) Still cannot calm down. (Heart)
Reply 内心是崩溃的吧。 Your heart must be broken.
Query 我先去哭一会。(纸纸纸巾巾巾) I am going to cry for a while. (Tissue) Reply 递纸巾! Offer you a tissue!
[image:7.595.75.524.65.198.2]Query 当初你们不是说过他是诺维斯基吗?(说说说过过过) Didn’t you say that he wasNowitzki†? (Say) Reply 说过吗?好像没有说过啊!? Did I say it? I don’t seem to say it!?
Table 3: The explicit introducing-content cases of our HGFU model. The predicted cue word inbold
explicitly occurs in the generated reply.Nowitzki†is a NBA basketball player.
highest BLEU scores as well as the highest human score.
In terms of automatic evaluations, the global-based methods perform much better than a set of local-based methods, which demonstrates the ef-fectiveness of global information inception. As mentioned above, the global schema provides the model a broader and more flexible space for learn-ing, which is benefit for information fusion. When it comes to human scores (For the sake of con-venience, we only conducted human evaluation in global schema), there are similar conclusions to BLEU results.
From Table4, we can see that the performance of rGRU is not as good as the other systems, while SCGRU outperforms the others in the local pattern and shows comparative performance in the glob-al schema. These two methods both augment the standard neural network with specially designed gate to control the cue word, but the results vary greatly. It is the limitation of gating mechanism-s that imechanism-s lacking in adaptivenemechanism-smechanism-s. Bemechanism-sidemechanism-s, SLGD adding cue word term in each gate of the neural cell has the similar result as FGRU method, which concatenates cue word with hidden state. Basical-ly, our proposed HGFU has a significant improve-ment against the baseline systems. The most prob-able credits come from the cue word GRU: we ap-ply the extra GRU unit to control the auxiliary in-formation instead of fusion in the standard GRU, which is more flexible.
Till now, we have elaborated the overall per-formance of all methods. Next we will come to a closer look at some representative cases of our HGFU model for further analysis and discussions.
4.5 Analysis and Case Studies
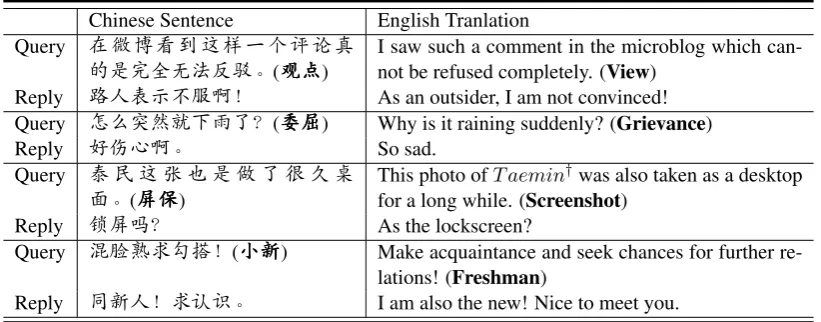
Given a query and the cue word, our HGFU model generates a meaningful and informative response. In Table 3, the predicted cue word occurs in the generated response and we treat this kind of gen-eration as the explicit introducing-content. How-ever, we do not strictly restrict tothis. As shown in Table5,our HGFUmodel also generates the replies without containing the cue word, while the re-sponsesare still somehow related to the cue word and the query. This reflects our expectation: the information of the cue word will be fused into the generation process but not necessarily occur ex-plicitly. It provesthe characteristics of our pro-posed new “soft” schema, whichare more flexible, extensible, and controllable.
We further analyze these explicit cases using a heat map as shown in Figure 4. We use various shades of blue to present the extent of correla-tion between the cue word and the generated re-ply. The darker the blue is, the higher correlation they have. For the added information in the reply (Here is exactly the cue word in darkblue), its po-sition and occurrence times are not fixed, which are autonomously controlled by our model.
Chinese Sentence English Tranlation Query 在微博看到这样一个评论真
的是完全无法反驳。(观观观点点点) I saw such a comment in the microblog which can-not be refused completely. (View)
Reply 路人表示不服啊! As an outsider, I am not convinced! Query 怎么突然就下雨了?(委委委屈屈屈) Why is it raining suddenly? (Grievance) Reply 好伤心啊。 So sad.
Query 泰 民这张也是做了很久桌
面。(屏屏屏保保保) This photo ofT aemin
†was also taken as a desktop
for a long while. (Screenshot) Reply 锁屏吗? As the lockscreen?
Query 混脸熟求勾搭!(小小小新新新) Make acquaintance and seek chances for further re-lations! (Freshman)
[image:8.595.93.504.63.224.2]Reply 同新人!求认识。 I am also the new! Nice to meet you.
Table 5: The implicit introducing-content cases of our HGFU model. The cue word in bold is not contained in the reply, while the response is still related to the cue word.T aemin†is a Korean singer.
5 Related work
5.1 Conversation Systems
Automatic human-computer conversation has at-tractedincreasing attention over the past few years. At the very beginning, people start the research using hand-crafted rules and templates (Walker et al.,2001;Misu and Kawahara,2007;Williams et al., 2013). These approaches require no da-ta or little dada-ta for trainingbuthuge manual ef-fort to build the model, which is very time-consuming. For now, buildinga conversation sys-temmainly falls into two categories: retrieval-based and generation-retrieval-based. As information re-trieval techniques are developing fast,Leuski et al. (2009) build systems to select the most suit-able response from the query-reply pairs using a statistical language model in cross-lingual in-formation retrieval. Yan et al. (2016) propose a retrieval-based conversation system with the deep learning-to-respond schema through a deep neural network framework driven by web data. Recently, generation-based conversation system-s have system-shownimpresystem-ssystem-sive potential. Shang et al. (2015) generate replies for short-text conversation by Seq2Seq-basedneural networks with local and global attentions.
5.2 Content Introducing
In vertical domains, Wen et al. (2015b) apply an additional control cell to gate the dialogue ac-t (DA) feaac-tures during ac-the generaac-tion process ac-to ensure the generated repliesexpressthe intended meaning. Also, the Stochastic Language Gener-ation in Dialogue method (Wen et al.,2015a) adds additional features in each gate of the neural
cel-l.Xu et al.(2016) introduce a new trainable gate to recall the global domain memory to enhance the ability of modeling the sequence semantics. Dif-ferent from the above work, our paper addresses the problem of content introducing in the open-domain generative conversation systems.
In open domains, Xing et al. (2016) incorpo-rate topic information into Seq2Seq framework to generate informative and interesting responses. To provide informative clues for content introducing, Li et al.(2016b) detect entities from previous ut-terances and search for more related entities in a large knowledge graph. A very recent study similar to ours is Mou et al. (2016), where the predicted word explicitly occurs in the generated utterance. Unlike the existing work, we explore an implicit content-introducing method for neural conversation systems, which utilizes the addition-al cue word in a “soft” manner to generate a more meaningful response given a user-issued query. 6 Conclusion
the current output word. The experimental results demonstrate the effectiveness of our approach. Acknowledgments
This work was supported by the National Hi-Tech R&D Program of China No. 2015AA015403; the National Science Foundation of China No. 61672058.
References
John Arevalo, Thamar Solorio, Manuel Montes-y G´omez, and Fabio A Gonz´alez. 2017. Gated mul-timodal units for information fusion. arXiv preprint arXiv:1702.01992.
Dzmitry Bahdanau, Kyunghyun Cho, and Yoshua Ben-gio. 2014. Neural machine translation by joint-ly learning to align and translate. CoRR, ab-s/1409.0473.
Kyunghyun Cho, Bart Van Merri¨enboer, Dzmitry Bah-danau, and Yoshua Bengio. 2014. On the properties of neural machine translation: Encoder-decoder ap-proaches. Eighth Workshop on Syntax, Semantics and Structure in Statistical Translation.
Kenneth Ward Church and Patrick Hanks. 1990. Word association norms, mutual information, and lexicog-raphy.Computational linguistics, 16(1):22–29. Sepp Hochreiter and J¨urgen Schmidhuber. 1997.
Long short-term memory. Neural computation, 9(8):1735–1780.
Charles Lee Isbell, Michael Kearns, Dave Kormann, Satinder Singh, and Peter Stone. 2000. Cobot in lambdamoo: A social statistics agent. In Proceed-ings of the Seventeenth National Conference on Ar-tificial Intelligence, pages 36–41. AAAI Press. Anton Leuski, Ronakkumar Patel, David Traum, and
Brandon Kennedy. 2009. Building effective ques-tion answering characters. In Proceedings of the 7th SIGdial Workshop on Discourse and Dialogue, pages 18–27. Association for Computational Lin-guistics.
Jiwei Li, Michel Galley, Chris Brockett, Jianfeng Gao, and Bill Dolan. 2016a. A diversity-promoting ob-jective function for neural conversation models. In
Proceedings of the 2016 Conference of the North American Chapter of the Association for Computa-tional Linguistics: Human Language Technologies, pages 110–119. Association for Computational Lin-guistics.
Xiang Li, Lili Mou, Rui Yan, and Ming Zhang. 2016b. Stalematebreaker: A proactive content-introducing approach to automatic human-computer conversa-tion. InProceedings of the Twenty-Fifth Internation-al Joint Conference on ArtificiInternation-al Intelligence, IJCAI
2016, New York, NY, USA, 9-15 July 2016, pages 2845–2851.
Teruhisa Misu and Tatsuya Kawahara. 2007. Speech-based interactive information guidance system using question-answering technique. InAcoustics, Speech and Signal Processing, 2007. ICASSP 2007. IEEE International Conference on, volume 4, pages IV– 145. IEEE.
Lili Mou, Yiping Song, Rui Yan, Ge Li, Lu Zhang, and Zhi Jin. 2016. Sequence to backward and for-ward sequences: A content-introducing approach to generative short-text conversation. In COLING 2016, 26th International Conference on Computa-tional Linguistics, Proceedings of the Conference: Technical Papers, December 11-16, 2016, Osaka, Japan, pages 3349–3358.
Kishore Papineni, Salim Roukos, Todd Ward, and Wei-Jing Zhu. 2002. Bleu: a method for automatic e-valuation of machine translation. InProceedings of the 40th annual meeting on association for compu-tational linguistics, pages 311–318. Association for Computational Linguistics.
Alan Ritter, Colin Cherry, and William B Dolan. 2011. Data-driven response generation in social media. In
Proceedings of the conference on empirical methods in natural language processing, pages 583–593. As-sociation for Computational Linguistics.
Iulian V. Serban, Alessandro Sordoni, Yoshua Bengio, Aaron Courville, and Joelle Pineau. 2016. Building end-to-end dialogue systems using generative hier-archical neural network models. InProceedings of the Thirtieth AAAI Conference on Artificial Intelli-gence, pages 3776–3783. AAAI Press.
Lifeng Shang, Zhengdong Lu, and Hang Li. 2015. Neural responding machine for short-text conver-sation. In Proceedings of the 53rd Annual Meet-ing of the Association for Computational LMeet-inguistics and the 7th International Joint Conference on Natu-ral Language Processing of the Asian Federation of Natural Language Processing, ACL 2015, July 26-31, 2015, Beijing, China, Volume 1: Long Papers, pages 1577–1586.
Yiping Song, Rui Yan, Xiang Li, Dongyan Zhao, and Ming Zhang. 2016. Two are better than one: An en-semble of retrieval-and generation-based dialog sys-tems. arXiv preprint arXiv:1610.07149.
Amanda Stent, Matthew Marge, and Mohit Singhai. 2005. Evaluating evaluation methods for generation in the presence of variation. In International Con-ference on Intelligent Text Processing and Compu-tational Linguistics, pages 341–351. Springer.
Oriol Vinyals and Quoc Le. 2015. A neural conversa-tional model. Deep Learning Workshop of the 32nd International Conference on Machine Learning. Marilyn A Walker, Rebecca Passonneau, and Julie E
Boland. 2001. Quantitative and qualitative evalu-ation of darpa communicator spoken dialogue sys-tems. In Proceedings of the 39th Annual Meeting on Association for Computational Linguistics, pages 515–522.
Hao Wang, Zhengdong Lu, Hang Li, and Enhong Chen. 2013. A dataset for research on short-text conversations. InProceedings of the 2013 Confer-ence on Empirical Methods in Natural Language Processing, pages 935–945. Association for Com-putational Linguistics.
Tsung-Hsien Wen, Milica Gasic, Dongho Kim, Nikola Mrksic, Pei-Hao Su, David Vandyke, and Steve Y-oung. 2015a. Stochastic language generation in di-alogue using recurrent neural networks with convo-lutional sentence reranking. In Proceedings of the 16th Annual Meeting of the Special Interest Group on Discourse and Dialogue, pages 275–284. Tsung-Hsien Wen, Milica Gasic, Nikola Mrksic,
Pei-Hao Su, David Vandyke, and Steve Young. 2015b. Semantically conditioned lstm-based natural lan-guage generation for spoken dialogue systems. In
Proceedings of the 2015 Conference on Empirical Methods in Natural Language Processing, pages 1711–1721.
Jason Williams, Antoine Raux, Deepak Ramachan-dran, and Alan Black. 2013. The dialog state track-ing challenge. InProceedings of the SIGDIAL 2013 Conference, pages 404–413.
Chen Xing, Wei Wu, Yu Wu, Jie Liu, Yalou Huang, Ming Zhou, and Wei-Ying Ma. 2016. Top-ic augmented neural response generation with a joint attention mechanism. arXiv preprint arX-iv:1606.08340.
Zhen Xu, Bingquan Liu, Baoxun Wang, Chengjie Sun, and Xiaolong Wang. 2016. Incorporating loose-structured knowledge into lstm with recall gate for conversation modeling. CoRR, abs/1605.05110. Rui Yan, Yiping Song, and Hua Wu. 2016. Learning
to respond with deep neural networks for retrieval-based human-computer conversation system. In