The BEA 2019 Shared Task on Grammatical Error Correction
Full text
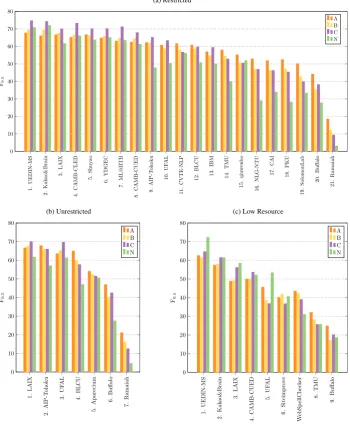
Figure




Related documents
In Proceedings of the 2019 Conference of the North American Chap- ter of the Association for Computational Linguistics: Human Language Technologies: Demo , pages 48– 53..
Therefore, we use BERT, pre-trained with large-scale raw corpora, and fine-tune it with learner corpora for re-ranking the hypotheses of our GEC model to utilize not only
We next created a dataset of 50 student essays, each corrected by 10 dif- ferent annotators for all error types, and in- vestigated how both human and GEC sys- tem scores vary
There is work that probes that there is an improvement using syntactic n-grams in (Sidorov and Ve- lasquez et al., 2014) where the author uses syn- tactic n-grams as machine
We correct the errors in the following order: Tokenizing → spelling error correction → punc- tuation error correction → N-gram Vector Ap- proach for Noun number (Nn) →
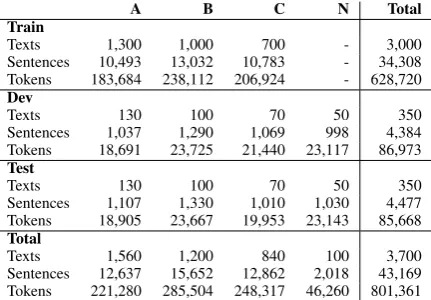
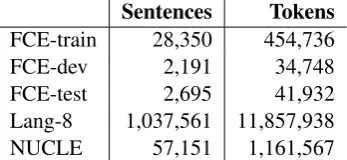
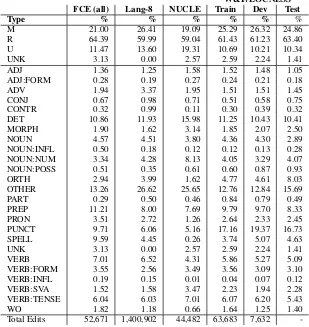
The shared task makes the NUCLE corpus (Dahlmeier et al., 2013) avail- able in the public domain and participants have been asked to correct grammatical errors belong- ing to
In this experiment, we have found out the set of good features for preposition and article error correction, and pro- posed a novel noun number error correction tech- nique based on
Similar to systems described in the literature, Arib utilizes language resources such as diction- aries and corpora as well as the application of different techniques
