Dense and Sparse Reconstruction Error Based Saliency
Descriptor
Tejavath Sivaprasad
1, Mr.K.Anjaneyulu
2, Mr.Sk Subhan
3[1]
M tech
PGScholar,
Department of Electronics and Communication Engineering, Madhira Institute of
Technology & Sciences–Jntuh, KODAD. Email id:-
[email protected]
[2](assistant professor & HOD), Department of Electronics and Communication Engineering, Madhira
Institute of Technology & Sciences–Jntuh, KODAD. Email id:-
[email protected]
[3]
(assistant professor), Department of Electronics and Communication Engineering, Vidya Vikas
Institute of Technology-Jntuh. Email id:[email protected]
ABSTRACT
In this paper, we propose a visual saliency location calculation from the point of view of recreation blunder. The picture limits are first extricated by means of super pixels as likely signs for foundation layouts, from which thick and scanty appearance models are developed. To start with, we figure thick and scanty recreation mistakes on the foundation formats for each picture district. Second, the reproduction blunders are proliferated in light of the settings acquired from K-implies bunching. Third, the pixel-level remaking blunder is registered by the incorporation of multi-scale recreation mistakes. Both the pixel level thick and scanty reproduction blunders are then weighted by picture conservativeness, which could all the more precisely recognize saliency. What's more, we present a novel Bayesian mix technique to join saliency maps, which is connected to coordinate the two saliency measures in light of thick and scanty recreation mistakes. Trial comes about demonstrate that the proposed calculation performs positively against 24 cutting edge techniques as far as accuracy, review, and F-measure on three open standard remarkable question discovery databases.
List terms — Saliency discovery, thick/meager recreation blunder, inadequate portrayal, setting based proliferation, locale conservativeness, Bayesian coordination.
1. INTRODUCTION
Current life has overpowering sum visual information and data accessible and made each moment. This development in picture information has prompted new difficulties of handling them quick and removing right data, in order to encourage distinctive errands from picture pursuit to picture pressure and transmission over system. One particular issue of PC
vision calculations utilized for extricating data from pictures, is to end objects of enthusiasm for a picture. Human visual framework has a colossal capacity to remove critical data from a scene. This capacity empowers people to center their restricted perceptual and subjective assets on the most appropriate subset of the accessible visual information, encouraging learning and survival in regular day to day existence. This astonishing capacity is known as visual saliency (Nitti et al. (1998)). Consequently for a PC vision framework, it is imperative to recognize saliency with the goal that the assets can be used appropriately to process critical data. Applications go from protest discovery or Content Based Image Retrieval (CBIR), face or human re-distinguishing proof and video following.
The top row shows an example of saliency map generated from the image (left) and the bottom row depicts an ideal segmentation of the object in
the image (left)
Subsequently, a notable boost will regularly fly out to the spectator, for example, a red spot in a red of green dabs, a sideways bar among an arrangement of vertical bars, a message pointer of a voice-mail, or a quick moving article in a scene with for the most part static or moderate moving items. An essential direct impact of the saliency component is that it pushes the visual perceptual framework to rapidly later and sort out valuable visual data, vital for protest acknowledgment and additionally scene understanding.
GOAL AND SCOPE:-The goal of the postulation is to gadget an effective notable question location strategy that can encourage as a pre-preparing advance for a significant number of the beforehand said undertakings. Further, the technique must be unsupervised with the goal that it can recognize any non specific protest. In addition, it must be computationally effective to guarantee quick preparing, thinking about the gigantic measure of accessible information. As of now talked about base up saliency can be described by the capacity to fly out in a scene. Subsequently, most saliency identification techniques in writing (Ashanti et al. (2009); Gofer roman et al. (2010); Cheng et al. (2011); Peruzzi et al. (2012); Li et al. (2013); Yang et al. (2013); Jiang et al. (2013)) propose a model by misusing uncommonness of highlights. Be that as it may, as additionally specified by Wei et al. (2012); Zhu et al. (2014) just component irregularity based approach isn't sufficient to separate striking areas from common pictures of shifting scene conditions. We recognize this inadequacy in the uncommonness of highlight based approach and endeavor limit earlier as a sign to actualize our rest strategy for saliency discovery. Component is that it pushes the visual perceptual framework to rapidly later and arrange helpful visual data, essential for protest acknowledgment and additionally scene
understanding. This astonishing capacity is known as visual saliency (Itti et al. (1998)).
Different challenges in saliency detection, illustrated using samples from saliency dataset.
Problems definition and challenges:-The issue we address in the proposition can be de require putting it plainly, as: Given a characteristic scene, recognize at least one districts of intrigue (ROI) which contain the remarkable protests in a scene. The strategy must be unsupervised with no preparation test for classes of items accessible. Parameters of any advancement capacity might be gotten the hang of utilizing a piece of another dataset, or confirmation subset of the same. In spite of the fact that the issue is like unsupervised frontal area division, it contrasts with regards to highlights which is generally roused by natural inspiration. A few cases of discovering objects of intrigue are displayed in Figure 1.1.
. Different challenges in saliency detection illustrated with images (left) and respective ground truths (right), from PASCAL dataset.
the scope of 0 to 1, portraying their likelihood of being notable. Henceforth, it can be effectively fragmented by basic system, to get the critical or notable question. In the work portrayed here, saliency is de require immeasurably as far as spatial uncommonness of picture highlight, essentially shading. Also, objectiveness is utilized as a part of a graphical model for remarkable protest division. This can change the ordinary method for extricating highlights from the entire picture or seeking objects in colossal 4-dimensional (position, scale and angle proportion) sliding window look space. Accompanying sub-areas, we depict the strategies proposed in the postulation in a nutshell.
Illustration of the sequence of stages of our proposed algorithm (PARAM) for saliency
estimation.
Then again, spatial smallness considers that shading having a place with a notable question would be assembled at a spatial area and in this way the spatial change of the shading would be low. Though, foundation hues are by and large dispersed over the entire picture and score low on spatial minimization.
2. LITERATURE SURVEY
The writing on nearby component recognition is huge and backpedals similar to 1954, when it was first seen by Alternative that data on shape is gathered at overwhelming focuses having high bend. It is difficult to depict every single commitment to more than 50 years of research in detail. Rather, we give pointers to the writing where the intrigued peruse can discover more. The primary objective of this segment is to make the peruse mindful of the different incredible thoughts that have been proposed, particularly in the pre-web period. Very frequently, these are neglected and afterward re-developed. We might want to give appropriate credit to every one of those scientists who added to the present cutting edge. Form convergences and intersections frequently result in bi-directional flag changes. In this way, a great methodology to identify highlights comprises of extricating focuses along the form with high shape. Bend of a simple bend is characterized as
the rate at which the unit digression vector changes as for circular segment length. Shapes are frequently encoded in chains of focuses or spoke to in a parametric frame utilizing spines.
Force Based Method:-Techniques in light of picture power have just feeble suspicions and are normally relevant to an extensive variety of pictures. A large number of these methodologies depend on first-and second-arrange dark esteem subsidiaries, while others utilize heuristics to discover districts of high fluctuation. Super pixels are spatially associated among themselves, yet not with frontal area ones can't ready to done all together information of pictures in saliency information.
Radiant-based approach:-Nearby element discovery in view of first request subordinates is additionally utilized as a part of different applications. A corner identifier which returns focuses at the neighborhood maxima of a directional difference measure was first presented with regards to versatile robot route. It was a heuristic execution of the auto-relationship work likewise investigated in the proposed corner locator explores a neighborhood window in the picture and decides the normal difference in force which comes about because of moving the window by a couple of pixels in different ways. This thought is taken further and formalized by utilizing first-arrange subordinates in a purported second minute framework to investigate nearby measurements of directional picture force varieties. The technique isolates corner hopeful location and confinement to enhance the exactness to sub pixel accuracy, at the cost of higher computational many-sided quality. Harris and Stephens enhanced the approach by Morava by performing systematic extension of the normal power change. These outcomes in a moment minute framework figured with Sob el subsidiaries and a Gaussian window. A capacity in light of the determinant and hint of that framework was brought which considered both eighteen estimations of the network.
been proposed, particularly in the pre-web period. Very frequently, these are neglected and afterward re-developed. We might want to give appropriate credit to every one of those scientists who added to the present cutting edge.
3. BACKGROUND
Image processing:-In electrical building and software engineering, picture preparing is any type of flag handling for which the info is a picture, for example, photography or video outline the yield of picture handling might be either a picture or, an arrangement of attributes or parameters identified with the picture. Most picture preparing systems include regarding the picture as a two-dimensional flag and applying standard flag handling strategies to it.
• Euclidean geometry changes, for example, amplification, lessening, and revolution
• Color remedies, for example, splendor and complexity alterations, shading mapping, shading adjusting, quantization, or shading interpretation to an alternate shading space
• Digital compositing or optical compositing (mix of at least two pictures), which is utilized as a part of film-production to make a "matte"
• Interpolation, and recuperation of a full picture from a crude picture arrange utilizing a Bayer channel design
• Image enlistment, the arrangement of at least two pictures
• Image differencing and transforming
• Image acknowledgment, for instance, may remove the content from the picture utilizing optical character acknowledgment or checkbox and bubble esteems utilizing optical stamp acknowledgment
• Image division
• High dynamic range imaging by joining different pictures
• Geometric hashing for 2-D question acknowledgment with relative invariance
ADVANCED IMAGE PROCESSING:-Advanced picture preparing is the utilization of PC calculations to perform picture handling on computerized pictures. As a subcategory or field of computerized flag preparing, advanced picture handling has numerous favorable circumstances over simple picture handling. It permits a considerably more extensive scope of calculations to be connected to the information and can keep away from issues, for example, the development of clamor and flag contortion amid preparing. Since pictures are characterized more than two measurements (maybe more) advanced picture preparing might be demonstrated as Multidimensional Systems.
APPLICATIONS:-Digital camera images Picture Processing and Analysis Computerized Data
Picture Resolution:-Determination can be characterized as "the capacity of an imaging framework to record fine points of interest in a discernable way". Working information of determination is fundamental for understanding both commonsense and reasonable subtle elements of remote detecting. Alongside the genuine situating of unearthly groups, they are of foremost significance in deciding the appropriateness of remotely detected information for a given applications. The significant qualities of imaging remote detecting instrument working in the unmistakable and infrared ghostly locale are depicted in wording as take after:
• Spectral determination
• Radiometric determination • Spatial determination • Temporal determination
Digital image
Cascading approach of bits in an pixel:-In the figure 3.2, the cascading approach of bits with respect to most significant bits and least significant bits are shown and how all the respective 8 bits intensity is combined to form the final intensity value in the final most significant bit and how the final intensity falls on human visual system to make the feel of object in an digital image and technically it is termed as human perception of digital image. These bits are logically present while the least element visualized by the human visual system is the pixel and in order to form the pixel we need to compose all
the 8 respective bits value to visualize the digitalized content in a pleasant approach. These bits play a crucial role in security related applications such as watermarking, stenography etc.
4. ROPOSED METHOD
We utilize both thick and scanty reproduction mistakes to gauge the saliency of each picture district. We take note of that a thick appearance display renders more expressive and nonexclusive portrayals of foundation layouts, though a scanty appearance show creates novel and minimized portrayals. It is outstanding that thick appearance models are more delicate to clamor. For jumbled scenes, thick appearance models might be less powerful in estimating remarkable items through remaking blunders. Then again, arrangements (i.e., coefficients) by inadequate portrayal are less steady (e.g., comparable areas may have diverse scanty coefficients), which may prompt broken saliency discovery come about. In this work, we utilize the two portrayals to display locales and measure saliency in view of reproduction mistakes.
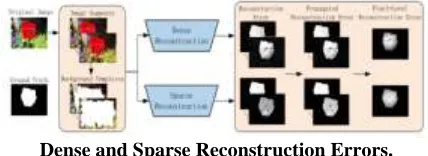
Dense and Sparse Reconstruction Errors.
The dense and sparse reconstruction errors are obtained as shown in Figure 2. First, we extract the image boundary segments as the background templates for saliency detection. Second, we reconstruct all the image regions based on the background templates and normalize the reconstruction errors to the range of [0,1]. Third, a propagation mechanism is proposed to exploit local contexts obtained from K-means clustering. Forth, pixel-level reconstruction error is computed by integrating multi-scale reconstruction errors. Background Templates:-To better catch auxiliary data, we initially produce super pixels utilizing the basic direct iterative grouping (SLIC) calculation to section an information picture into different uniform and conservative locales (i.e., fragments). We utilize the mean Lab and RGB shading highlights and facilitates of pixels to portray each fragment by x={L,a,b,R,G,B,x,y} .The whole picture is then spoken to as X=[x1,x2,...,xN]∈ R D×N ,where Nis
X-AXIS
YA X I S
f(x,
y)
BIT
1
BIT
2
BIT
3
BIT
4
BIT
5
BIT 6
BIT
7
BIT
8
M
SB’
s
LS
the quantity of sections and D is the element measurement. Spurred by the portrayal capacity of picture limit, we extricate the D-dimensional component of every limit fragment as band build the foundation format set as B=[b1,b2,...,bM],where M is the quantity of picture limit sections Figure 2 demonstrates some foundation layouts removed at various scales. Given the foundation layouts, we process two recreation mistakes by thick and meager portrayal for each picture district, individually.
Thick Reconstruction Error:-A fragment with bigger recreation mistake in light of the foundation formats will probably be the frontal area. In light of this worry, the reproductions blunder of every locale
Saliency maps based on dense and sparse reconstruction errors.
Brighter pixels show higher saliency esteems.
(an) Original pictures. (b) Saliency maps from thick remaking. (c) Saliency maps from meager recreation. (d) Ground truth. the remaking coefficient of section (I ∈[1,N]).]
β_i=U_B^T(X_i-X ̅) (1) what's more, the thick recreation mistake of fragment
is
ε_i^d=‖X_i-(U_Bβ_i+X ̅)‖_2^2 (2) Where x is the mean component of X. The saliency
measure is relative to the standardized recreation blunder (inside the scope of [0,1]).
α_i^*=arg min┬(α_i)‖X_i-Bα_i ‖_2^2 +λ‖α_i ‖ (3)
Furthermore, the meager recreation mistake is
ε_i^s=‖X_i-Bα_i^*‖_2^2 (4)
We initially apply the K-implies calculation to group picture fragments into bunches through their D-dimensional highlights and introduce the spread reproduction blunder of section I as ˜ εi =εi. Every one of the fragments are arranged in diving request
by their reproduction mistakes and considered as various theories. They are handled successively by spreading the remaking blunders in each bunch. The proliferated recreation mistake of section I having a place with bunch k (k=1,2,...,K), is changed by considering its appearance based setting comprising of alternate fragments in group as takes after:
Saliency maps with the context-based error propagation.
(a) And (b) are unique pictures and ground truth. (c) and (d) are unique and proliferated thick reproduction blunders. (e) and (f)are unique and proliferated meager recreation mistakes.
ε ̃_i=τ∑_(j=1)^(N_c)〖W_(ik_j ) ε ̃_(k_j )+(1-τ) ε_i 〗 (5)
W_(ik_j )=exp(- ‖X_i-X_(k_j ) ‖^2/(2σ_x^2 ))(1-δ(K_j-I) )/(∑_(j=1)^(N_c) exp (- ‖X_i-X_(k_j )
‖^2/(2σ_x^2))) (6)
Saliency maps with the multi-scale integration of propagated reconstruction errors.
What’s more, inadequate reproduction mistakes for each scale. We coordinate multi-scale recreation blunders and register the pixel-level remaking mistake by E(z)= N
¯E (z)=(∑_(s=1)^(N_s) 〖ω_zn (s) ε ̃_n (s) 〗 )/(∑_(s=1)^(N_s)〖ω_zn (s) 〗),ω_zn
Where dz is a D-dimensional component of pixel z and n (s) indicates the name of the section containing pixel z at scales. Thus to we use the likeness between pixel z and its relating fragment n (s) as the weight to normal the multi-scale recreation blunders.
Smallness Weighted Reconstruction Error :-thinking about the shading conservativeness or circulation in spatial space. Subsequently
E(z)=w^C(z)*¯E(z) (8)
Saliency Assignment Refined By Object Biased Gaussian:-There is an inside predisposition in some saliency identification datasets as of late focus earlier has been utilized as a part of and typically planned as a Gaussian model,
G(z)=exp[((x_zμ_x)^2/(2σ_x^2)+(y_zμ_y)^2/(2σ_y^ 2 )) ] (9)
Where μ_x=x_cand μ_y=y_c mean the directions of the picture focus and x_zand y_(z )are the directions of pixel z. Since notable items don't generally show up at the picture focus as Figure 7 appears, the middle one-sided Gaussian model isn't viable and may incorporate foundation pixels or miss the frontal area locales. We utilize a protest one-sided Gaussian model Go with μ_x= x_0and μ_y=y_c,wherexo andyo signify the question focus got from the pixel blunder in Eq. 7:
x_0=∑_j〖(E(i))/(∑_j〖E(j)〗) x_i 〗,x_0=∑_i〖 (E(i))/(∑_j〖E(j)〗) y_i 〗 (10)
We set σ x = 0.25 × H and σy = 0.25 × W, where W and H separately signify the width and stature of a picture. With the question one-sided Gaussian model, the saliency of pixel z is processed by
S(z)=G_0(z)*E(z) (11)
Comparison of center-biased (Gc) and object-biased (Go) Gaussian refinement. Ed and Es are
the multi-scale integrated dense and sparse reconstruction error maps.
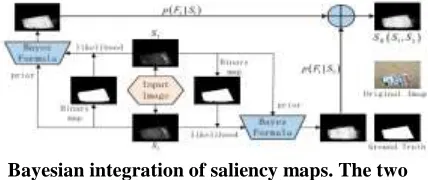
Bayesian Integration of Saliency Maps:
Bayes Formula:
p(F├|H(z)┤)=(p(F)(pH(z)├|F┤))/(p(F)pH(z)├|F┤+(1 -p(F))(pH(z)├|F┤ ) (12)
(pH(z)├|F┤ )=∏_(r∈{L,a,b}) (N_bF (r(z) ))/N_F ,(pH(z)├|B┤ )=∏_(r∈{L,a,b})〖(N_bB (r(z)))/N_B]
(13)
where NF signifies the quantity of pixels in the frontal area and NbF(r(z))(r ∈ {L, a, b}) is the quantity of pixels whose shading highlights fall into the closer view receptacle bF(r(z)) which contains include r(z), while the shading conveyance histogram of the foundation is indicated similarly by NB and NbB(r(z)). Be that as it may, the clamor in shading space might be presented once more
Bayesian integration of saliency maps. The two saliency measures via dense and sparse reconstruction are respectively denoted by S1 and
S2.
Bayesian Integration Formula:
p(S_j (z)├|F_i ┤ )=(N_(bF_i ) (S_j (z) ))/N_(F_i ) ,p(S_j (z)├|B_i ┤ )=(N_(bB_i ) (S_j (z) ))/N_(B_i )
(14) Thus the back likelihood is registered with Si as the
earlier by
p(F_i ├|S_j (z) ┤ )=(S_i (z)p(S_j (z)├|F_i ┤ ))/(S_i
(z)p(S_j (z)├|F_i ┤ )+(1-S_i (z) )p(S_j (z)├|B_i ┤ ) (15)
So also, the back saliency with Sj as the earlier is registered. We utilize these two back probabilities to figure an incorporated saliency delineate), S2(z)), in light of Bayesian joining:
Algorithm 1 Saliency Detection through Dense and Sparse Reconstruction: Given An information picture 〖{X_s}〗_(s=1)^(N_s ) got from SLIC division at N_(8 ) diverse scales, where X={X_i}}_(i=1)^N for one scale.
1: For s=1,2,… … N do
2: acquire the foundation format set B. 3: For i=1,2,… .,N do
4: Calculate the thick reproduction mistake ∑_i^d〖 by 〗Eq. 1-2.
5: Calculate the inadequate reproduction mistake ∑_i^sby Eq. 3-4.
6: ascertain the locale conservativeness c_i by Eq. 8-9.
7: Calculate the proliferated reproduction mistake {∑_i^(- d),∑_i^(- 8)} and area smallness e_i^~ by Eq. 5-6.
8: End 9: End
10: Integrate the multi scale result and get the pixel level remaking mistake 〖{e〗^(- d) (Z),E^(- 8) (Z)} and conservativeness c^z by Eq 7.
11: Obtain the weighted remaking blunder {E^d (z) ,E^8 (z)} by Eq 10.
12: Calculate the thick and meager saliency s^(d ),s^8 By eq. 11-13.
13: Obtain the Bayesian incorporated saliency s_b 〖 (s〗^d s^8) by EQ.16-18.
Yield:
The last saliency delineate 〖(s〗^d s^8).
5. EXPERIMENTAL RESULTS
6. CONCLUSION
better quantify saliency. A setting based spread component is intended to proliferate the remaking blunders through nearby setting acquired by K-implies grouping. The pixel-level saliency is at long last processed by a mix of multi-scale remaking mistakes took after by a protest one-sided Gaussian refinement. To consolidate the two saliency maps by means of thick and scanty recreation, we present a Bayesian reconciliation technique which performs superior to the traditional incorporation system. Test comes about demonstrate the execution change of the proposed technique contrasted with twenty-four best in class models. Our saliency guide can well smother the foundation while consistently feature the closer view objects.
7
.
REFERENCES
1. L. Itti and C. Koch, "Computational demonstrating of visual consideration," Nature Rev. Neurosci., vol. 2, no. 3, pp. 194– 201, 2001.
2. J. M. Wolfe and T. S. Horowitz, "What characteristics direct the arrangement of visual consideration and how would they do it?" Nature Rev. Neurosci., vol. 5, no. 6, pp. 495– 501, 2004.
3. C. Siagian and L. Itti, "Fast naturally propelled scene grouping utilizing highlights imparted to visual consideration," IEEE Trans. Example Anal. Mach. Intell., vol. 29, no. 2, pp. 300– 312, Feb. 2007.
4. C. M. Privitera and L. W. Stark, "Calculations for characterizing visual regionsof-intrigue: Comparison with eye obsessions," IEEE Trans. Example Anal. Mach. Intell., vol. 22, no. 9, pp. 970– 982, Sep. 2000.
5. D. Gao, S. Han, and N. Vasconcelos, "Discriminant saliency, the discovery of suspicious happenstances, and applications to visual acknowledgment," IEEE Trans. Example Anal. Mach. Intell., vol. 31, no. 6, pp. 989– 1005, Jun. 2009.
6. U. Rutishauser, D. Walther, C. Koch, and P. Perona, "Is bottomup consideration valuable for question acknowledgment?" in Proc. CVPR, 2004, pp. 37– 44.
7. L. Marchesotti, C. Cifarelli, and G. Csurka, "A system for visual saliency discovery with applications to picture thumbnailing," in Proc. ICCV, 2009, pp. 2232– 2239.
8. C. Guo and L. Zhang, "A novel multiresolution spatiotemporal saliency location model and its applications in picture and video pressure," IEEE Trans. Picture Process., vol. 19, no. 1, pp. 185– 198, Jan. 2010.
9. L. Itti, "Programmed foveation for video pressure utilizing a neurobiological model of visual consideration," IEEE Trans. Picture Process., vol. 13, no. 10, pp. 1304– 1318, Oct. 2004. [11] L. Itti, C. Koch, and E. Niebur, "A model of saliency-based visual consideration for fast scene examination," IEEE Trans. Example Anal. Mach. Intell., vol. 20, no. 11, pp. 1254– 1259, Nov. 1998.
10. D. A. Klein and S. Frintrop, "Center-encompass disparity of highlight insights for striking article location," in Proc. ICCV, 2011, pp. 2214– 2219.
11. S. Goferman, L. Zelnik-Manor, and A. Tal, "Setting mindful saliency identification," in Proc. CVPR, 2010, pp. 2376– 2383. question division in view of setting and shape earlier," in Proc. BMVC, 2011, pp. 1– 12.
12. A. Borji and L. Itti, "Abusing neighborhood and worldwide fix rarities for saliency recognition," in Proc. CVPR, 2012, pp. 478– 485.
13. R. Achanta, S. Hemami, F. Estrada, and S. Susstrunk, "Recurrence tuned remarkable district identification," in Proc. CVPR, 2009, pp. 1597– 1604.
14. M.- M. Cheng, G.- X. Zhang, N. J. Mitra, X. Huang, and S.- M. Hu, "Worldwide differentiation based remarkable area identification," in Proc. CVPR, 2011, pp. 409– 416.
15. L. Duan, C. Wu, J. Miao, L. Qing, and Y. Fu, "Visual saliency recognition by spatially weighted difference," in Proc. CVPR, 2011, pp. 473– 480.
16. F. Perazzi, P. Krahenbuhl, Y. Pritch, and A. Hornung, "Saliency channels: Contrast based separating for remarkable area identification," in Proc. CVPR, 2012, pp. 733– 740.
17. S. Lu, V. Mahadevan, and N. Vasconcelos, "Learning ideal seeds for dispersion based notable protest identification," in Proc. CVPR, 2014, pp. 2790– 2797.
saliency identification," in Proc. CVPR, 2014, pp. 3866– 3873.
19. R. Zhao, W. Ouyang, H. Li, and X. Wang, "Saliency identification by multicontext profound learning," in Proc. CVPR, 2015, pp. 1265– 1274.
20. G. Li and Y. Yu, "Visual saliency in light of multiscale profound highlights," in Proc. CVPR, 2015, pp. 5455– 5463.
21. L. Zhang, M. H. Tong, T. K. Imprints, H. Shan, and G. W. Cottrell, "SUN: A Bayesian structure for saliency utilizing common insights," J. Vis., vol. 8, no. 7, p. 32, 2008.
22. Y. Wei, F. Wen, W. Zhu, and J. Sun, "Geodesic saliency utilizing foundation priors," in Proc. ECCV, 2012, pp. 29– 42.
23. A. Borji, D. N. Sihite, and L. Itti, "Striking item location: A benchmark," in Proc. ECCV, 2012, pp. 414– 429.
24. X. Hou and L. Zhang, "Dynamic visual consideration: Searching for coding length increases," in Proc. NIPS, vol. 21. 2008, pp. 681– 688.
25. W. Wang, Y. Wang, Q. Huang, and W. Gao, "Estimating visual saliency by site entropy rate," in Proc. CVPR, 2010, pp. 2368– 2375.
AUTHOR’S PROFILE
Mr.K.ANJANEYULU, received the Master Of Technology degree in ECE from the MADHIRA INSTITUTE OF TECHNOLOGY & SCIENCES - JNTUH, he received the Bachelor Of Technology degree from SRR-Karepally, JNTUH. He is currently working as assistant professor & HOD of the ECE with Madhira Institute Of Technology And Sciences,kodad. His interest subjects are Signals and Systems, EDC,Analog Electronics, PTSP & Etc
Mr.SK SUBHAN, received the Master Of Technology degree in embedded systems
from the VIDYA VIKAS INSTITUTE OF
TECHNOLOGY-JNTUH, he received the Bachelor Of Technology degree from VNR-VJIET, JNTUH. He is currently working as assistant professor in the Department of ECE with Madhira Institute Of Technology And Sciences, kodad. His interest subjects are Embedded Systems, Microprocessors, measurement and instrumentation Systems.