DOI : https://doi.org/10.32628/CSEIT183894
An Adaptive Data Distribution Through Tree Rules in Frequent
Pattern Mining
Avinash Sharma1, Dr. Sarvottam Dixit2, Dr. N. K. Tiwari3
1Research Scholar Computer Science Engineering, Mewar University Chittorgarh Rajasthan India 2Computer Science Engineering Professor Mewar University Chittorgarh Rajasthan India
3Director Patel Group of Institution Bhopal, Madhya Pradesh. India
ABSTRACT
Information sharing among the associations is a general development in a couple of zones like business headway and exhibiting. As bit of the touchy principles that ought to be kept private may be uncovered and such disclosure of delicate examples may impacts the advantages of the association that have the data. Subsequently the standards which are delicate must be secured before sharing the data. In this paper to give secure information sharing delicate guidelines are bothered first which was found by incessant example tree. Here touchy arrangement of principles are bothered by substitution. This kind of substitution diminishes the hazard and increment the utility of the dataset when contrasted with different techniques. Examination is done on certifiable dataset. Results shows that proposed work is better as appear differently in relation to various past strategies on the introduce of evaluation parameters.
Keywords : Distributed Data, Data Mining, Encryption, Effective Pruning, Substitution.
I. INTRODUCTION
The prerequisite for data mining with security protection has created as an enthusiasm for exchanging touchy information already releasing data over the framework. Also, the suspicious techniques, and refusal of the data suppliers towards the confirmation of information. Web Phishing is a half-baked way to deal with gain private information, for instance, usernames, passwords, and charge card focal points by camouflaging as a reliable substance in an electronic correspondence. As such, extended online affirmation against phishing assaults is a district of epic interest. As these assaults are progressed in nature, they speak to a couple of challenges similar to avoiding strategies. Web phishing incited a couple of security and money related strikes on the customers
and endeavors far and wide. Web installment entryways of web managing an account have endured and incited liberal cash related setback [1, 2]. Thusly, upgraded data mining procedures with security are the need of extraordinary significance for secure information exchange over the framework. Nowadays, securing customers' information has a commitment with the ultimate objective that their security isn't harmed. Among a couple of existing estimation, the Data Mining with insurance produces exceptional results related to within view of protection saving with data mining. The security ought to be combined onto all mining parts including grouping, affiliation control, and request [1, 3].
everything being equal. This has incited assemble customers' individual data and sustained into data mining designs which should ensure that there is no loss of assurance. Moreover, the components like utilization, request of insurance with respect to its advantages and negative imprints are not been inspected authentically. A couple of insurance defending plans in data mining exists which join K-mystery, cryptography, development, L-assorted variety, randomization, procedures [8, 9]. The PPDM methodologies secure the data by hiding some remarkable information with the objective that private information isn't revealed. The structure is to modify a trade off among mystery and efficiency. The use cryptographic techniques constantly have computational costs to keep away from information spillage [4, 6].
II. RELATED WORK
N. Muthu Lakshmi and K. Sandhya Rani [9] proposed a model to find affiliation rules for vertically isolated databases considering the insurance goals with 'n' number of locales nearby data information digger. This model bargains assorted cryptography procedures, for instance, encryption, deciphering and scalar thing framework to find affiliation runs profitably and securely for vertically allocated.
F. Giannotti et al. [10] proposed an answer which relies upon k-namelessness recurrence. To counter recurrence examination interloper, the data proprietor implants counterfeit trades in the database to lessen the protest recurrence. Protests in the database are encoded with the 1-1 substitution words. In the wake of embeddings the phony trades, any question in the annoyed database will have a comparative recurrence with in any occasion k − 1
unique items. By then dada proprietors redistribute their database to the server for the mining task. The server runs visit itemset mining figuring and returns the happened ordinary itemsets and their
sponsorships to the data proprietor. The data proprietor changes these itemsets' sponsorships by subtracting them with itemsets' relating occasion check in the phony trades independently. By then, the data proprietor unravels the got itemsets with the revised sponsorships higher than as far as possible and produces affiliation manages in perspective of the ceaseless itemsets. In these setting, data proprietor requires including itemset occasions counterfeit trades to balance counterfeit trades. Using this system for the vertically distributed, data proprietors can't perform such calculations.
J. Lai et al. [11] proposed an insurance sparing re-appropriated affiliation design mining game plan. This plan is weak against recurrence examination assaults. Applying this response for vertically allotted databases will realize the spillage of the right sponsorships to data proprietors.
T. Tassa [12] proposed for secure mining of affiliation keeps running in on a dimension plane spread databases. The proposed tradition relies upon the brisk passed on count, which is an unbound scattered variation of Apriori computation. The tradition enlists the association (or intersection point) of private subsets that every one of the charming site hold. In like manner, the tradition tests the fuse of a part hold by one site in subset held by another. Regardless, this plan is suitable for level isolating, not for vertical allotting.
conviction which ensures the security of the data and mining result additionally.
III. PROPOSED WORK
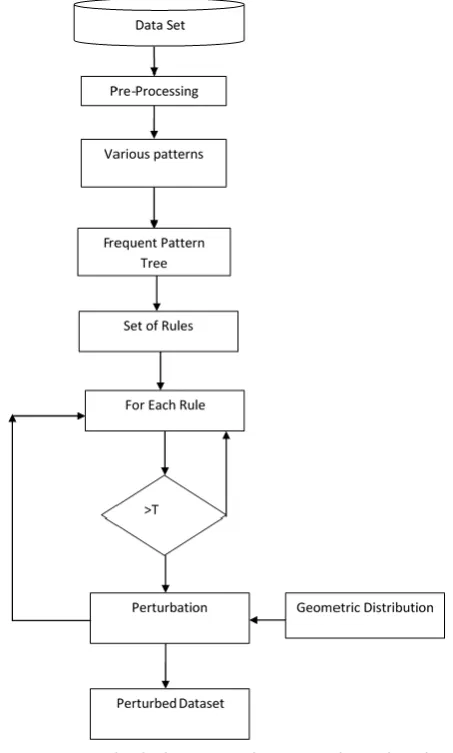
Entire work is a mix of two stages where initially incorporate site creation while second incorporate conveyance of segments on different locales. While exchanging entire column emcryption was performed on the them to save money on the destinations. Clarification of entire work is appeared in fig. 1.
Pre-Processing
Pre-Processing: As the dataset is acquire from the above advances contain numerous pointless data which one should be expelled for making appropriate task. Here information should be perused according to the calculation, for example, the game plan of the information in type of framework is required.
Change Frequent Pattern Tree
In this progression exchange comes in the dataset are go in the tree with the end goal that different mix of the things in the exchange are tally in this pass. Here opposite grouping is go in the tree where things present in this exchange are include by different parent the tree. This can be comprehend as:
A, B, D
A, C, D
C, B B, D, A
Table 1. Represent transaction set of elements. Let number of various things in the exchange sets are four, than tree has four tyke. Discover number of various mix of the thing set according to the set cardinality like cardinality 2 = {AB, AC, AD, BC, BD, CD}, cardinality 3 = {ABC, ACD, BCD}, cardinality 4 = {ABCD}. Build tree other dimension according to the cardinality hub appeared in fig. 2.
Channel Sensitive Rule
Presently from the created guideline one can get cluster of standards then it is required to isolate those tenets from the accumulation into delicate and non-touchy principle set. Those standards which cross touchy limit are distinguished as the delicate principles while those not containing are circuitous guidelines. This can be comprehended as the Let A, B C where this example cross least edge esteem so this standard is touchy principle. On the off chance that D, B C is a standard and not cross delicate or least edge then this standard isn't touchy guideline.
Figure 1. Block diagram of proposed work rule generation.
Where q = 1 – p, x is a lattice of numbers while p is a plausible incentive for the age of arrangement.
In this methodology unique dataset is change in arbitrary part where measure of progress is rely upon the base limit. The first qualities yet not in indistinguishable request from was in the first dataset. In [10] commotion is create by a Gaussian capacity that deliver a grouping of number at that point include those arrangement in the first position, so a sort of variety is create here for the security of the first one, however that was restricted to the numeric as it were.
Touchy Pattern Hiding:
So as to conceal design, {X, Y), this work can diminish its help to be lesser than client given least help exchange (MST). So as to diminish the help esteem the methodology is to decrease the help of the thing set {X, Y}.
((Rule_support – Minimum_support) * Total_transaction)/100
Info: A source database D, A base help in Transaction (MST).
Yield: The sterilized database D, where rules
containing X on Left Hand Side (LHS) or Right Hand Side (RHS) will be covered up.
4. New_transaction Find_transaction(P[I], MST) 5. While (T isn't vacant OR check =
New_treansaction)
6. On the off chance that t T have XUY rul
7. Remove Y from this transaction 8. End While
9. EndIf 10. End Loop
IV. EXPERIMENT AND RESULT
Dataset
In order to analyze proposed algorithm, it is in need of the dataset. So college admission dataset is use that has following attribute {branch, course, gender, pincode, etc.}. Here student information are pincode, gender, branch while sensitive items are important for the admission dataset owner. So for the privacy preservation both things need hide. So in order to provide protection against the private data of the customer one concept substitution has been included.
Evaluation Parameters
Risk:
utility of sharing information vary as per value pass in the perturbed dataset.
j
j
i
U
U
=
log
(
,
)
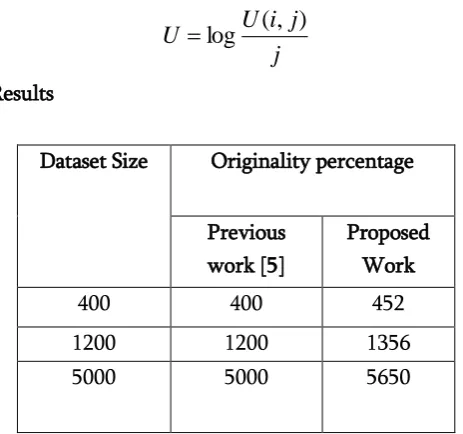
Results
Dataset Size Originality percentage
Previous work [5]
Proposed Work
400 400 452
1200 1200 1356
5000 5000 5650
Table 5.1 Comparison of proposed and previous work on the basis of dataset size.
From the above figure and table it is obtained that proposed work has maintain the same dataset size after applying the perturbation algorithm. Here by change in the dataset value dataset size of the previous work is increase than proposed work.
Dataset Percentage
Risk Value
Robfrugal [5] Proposed Work
400 6800 7203
1200 20400 21469
5000 85000 88879
Table 2. Comparison of proposed and previous work on the basis of Risk values.
From table 2 it is obtained that the risk value of the dataset is reduced after applying the proposed work. In other words previous work has reduced the risk
value but to less extent. It was obtained that session addition have reduce risk as compare to previous but not that much as done by substitution algorithm proposed in this work. Here proposed work replace less informative data so risk of the outsourced dataset was quit less.
Dataset Percentage
Utility Value
Robfrugal [5] Proposed Work
400 205.5197 117.9165
1200 631.9918 347.7699
5000 2.7110e+03 1.4598e+03
Table 3. Comparison of proposed and previous work [5] on Utility Value basis.
Figure 3. Comparison of dataset variation with utility value obtained from various approaches.
proposed work supplant less instructive information so danger of the re-appropriated dataset was stopped less. In any case, bother done by phony exchange or evacuating thing has decrease the utility to huge qualities.
V. Conclusion
As researchers are wearing down different field out of which finding an amazing vertical precedents is measure issue with this getting to be propelled world. This paper has proposed a data conveyance calculation for different servers. Here authentic vertical sections are create with the help of incessant example tree. By the usage of substitution security of the data at server side get overhaul as well. Results exhibits that proposed work chance esteem get decline. While utility was high as contrast with past work. By the usage of customized same session space cost is moreover kept up. As research is never end handle so in future one can grasp other precedent time technique for upgrading the server execution.
V.
REFERENCES
[1]. L. Li, R. Lu, S. Member, K. R. Choo, and S. Member, "PrivacyPreserving-Outsourced Association Rule Mining on Vertically Partitioned Databases," IEEE Trans. Info. Foren. Secur., vol. 11, no. 8, pp. 1847–1861, Aug. 2016. [2]. Lichun Li, Rongxing Lu, Kim-Kwang Raymond
Choo, Anwitaman Datta, and Jun Shao. "Privacy-Preserving-Outsourced Association Rule Mining on Vertically Partitioned Databases". IEEE Transactions On Information Forensics And Security, Vol. 11, No. 8, August 2016 1847 [3]. J. Lai, Y. Li, R. H. Deng, J. Weng, C. Guan, and
Q. Yan, "Towards Semantically Secure Outsourcing of Association Rule Mining on Categorical Data," Inf. Sci.., vol. 267, pp. 267-286, May 2014.
[4]. T. Tassa, "Secure Mining of Association Rules in Horizontally Distributed Databases Scalable Algorithms for Association Mining," IEEE
Trans.Knowl. Data Eng., vol. 26, no. 4, Apr. 2014.
[5]. F. Giannotti, L. V. S.Lakshmanan, A. Monreale, D. Pedreschi, and H. Wang, "Privacy-Preserving Mining of Association Rules from Outsourced Transaction Databases," IEEE Syst. J., vol. 7, no. 3, pp. 385- 395, Sep. 2013.
[6]. N. V. Muthu Lakshmi1 & K. Sandhya Rani, "Privacy Preserving Association Rule Mining in Vertically Partitioned Databases," In IJCSA, vol. 39, no. 13, pp. 29-35, Feb. 2012.
[7]. T. Calders and S. Verwer, "Three Naive Bayes Approaches for Discrimination-Free Classification," Data Mining and Knowledge Discovery, vol. 21, no. 2, pp. 277-292, 2010. [8]. F. Kamiran and T. Calders, "Classification with
no Discrimination by Preferential Sampling," Proc. 19th Machine Learning Conf.Belgium and The Netherlands, pp 1-6, 2010.
[9]. Yao, H., Hamilton, H., and Butz, C., FD_Mine: Discovering Functional dependencies in a Database Using Equivalences, Canada, IEEE ICDM 2002.
[10]. Wyss. C., Giannella, C., and Robertson, E. (2001), FastFDs: A Heuristic-Driven, Depth-First Algorithm for Mining Functional Dependencies from Relation Instances, Springer Berlin Heidelberg 2001.
[11]. R. Agrawal and R..Srikant, "Fast Algorithms for Mining Association Rules in Large Databases," Proc. 20th Int'l Conf. Very Large Data Bases, pp. 487-499, 1994.
[12]. Huhtala, Y., Karkkainen, J., Porkka, P., and Toivonen, H., (1999), TANE: An Efficient Algorithm for discovering Functional and Approximate Dependencies, The Computer Journal, V.42, No.20, pp.100-107.