Volume 3, No. 4, July- August 2012
International Journal of Advanced Research in Computer Science
RESEARCH PAPER
Available Online at www.ijarcs.info
ISSN No. 0976-5697
Competent Data Collection and Authentication Protocol: Active Collector Assortment
Model (ACAM)
CH. Krishna Prasad*
Assoc Professor Anurag Engineering College,
Kodad,AP, India
G.Srinivasa Rao
Assoc Professor Anurag Engineering College,
Kodad,AP, India [email protected]
Abstract: In the case of comprehensive precautious networks there can arise situations where single entity nodes have to negotiate their safeties. Those kinds of nodes give the fake information, and when these nodes are not identified then finally they reach information gatherer i.e. a kind of key-store. These kinds of problems restrict the quantity of usage and also generate wrong indications. So in order to conquer the problem there is possibility of adapting the Usage competent, Information arranger and Validation approach depended Active Collector Assortment Model (ACAM) methodology that is considered in this article. This method utilizes the info validation rules, so called codes in order to find out and eliminate the fake information. The identification continues, and when the information travels from the node to the gatherer i.e. key store every node verifies the truth values produced by MAC and eliminates the info that gives wrong outputs at the starting stages. Finally the key-store sorts out the information which is falsified although they could not be identified by ACAM methodology of sorting. There is another phase in this ACAM which is recognized for the truth values. This other phase is methodology of combined assessment by several nodes in the structure. The total procedure is finished with a transparency of about 14bytes per info and has the capability to finish in 10 transitions between the nodes. With the help of this nearly 80 – 90% of the fake info can be identified. This method also minimizes the consumption of heavy usage nearly to 50%.
Keywords: Data aggregation, sensor networks, ACAM, DAA, Protocol
I. INTRODUCTION
The recent emerging world has shown the prominence of utilization of sensor networks in all the fields to identify and deliver the info. Some of the fields such as the battlefield endurance, sensing any occurrence of fire in the forest regions have the higher utilization of these networks. These kinds of sensors should provide info accurately including elimination of fake information which is produced and instilled in the network by any assailant. Due to this the worked out stress and the battery utilization is not properly done. The procedure of assailing the heavy network can be termed if an individual node is invaded or negotiated exteriorly. The total content available in the node can be easily opened by the invaders. Every node has a few private details and the result delivered by that node is a validated result. This validation info although it is wrong, there is chance to be advanced between the hops and ultimately arrive the key-store which is the main aim of the invader. The method of conjectural utilization of key depended validations to the sensor networks is not possible, which is a known fact,
II. RELATED WORK
Numerous associated exertions are facilitated in developing the protection for the sensor networks. A few exertions are listed below: Karlof et al. [1] learning the assaults of sensor network routing protocols. Wood et al.[2] learning DoS assaults. Sasha et al. [3] utters regarding the minimization of transparency and significance of records considering protection potency. Carmel et al. [4] examines the distinction among power usage of assorted open key algorithms on a wide range of sensor structure. Basagi et al.
[5] utilizes an individual key named mission key keeping presumptuous occurrence of fiddle network to each node devoid of maintaining the price in view.
III. ACTIVE COLLECTOR ASSORTMENT MODEL (ACAM)
This methodology of ACAM pertains a strategy called divide & rule strategy while impending to the huge networks. The functionality of ACAM is consistent and remarkable. As in general an individual node is utilized to validating the info, but in the case here of ACAM not just a single node is utilized but also the adjacent sensor nodes are utilized. The safety extra data given by the nodes are restricted, as a result there is no high affect even if negotiated. So in the process of producing the info, here in place of moving ahead by validation of individual node, the adjacent nodes produce a legal info in which the validation code is available. If the info has a insufficient amount of validation codes then it is eliminated from moving ahead to the upcoming nodes. Sometimes there arise a case of sufficient validation codes, but no proper true value of MAC. In these cases also the elimination is done. To the end if info has traversed every case, there is finest sorter that eliminates the info which are fake and that is key-store. There is couple of methods put forward in attaining the ACAM, they are as follows:
a. Handing over the key technique on the process of identifying the fake info due to negotiated nodes. b. A methodology for the combined info production,
between the nodes. With this there is a possibility of deducting the usage of power to 50%.
A. Active Collector assortment depending on in-order Collection and Corroboration:
Here there is a usage of ACAM methodology which is an expansion to the DAA [21] in huge networks through intense sensor nodes. When every node is arranged with the crash proof exterior then the fake info production can be eliminated and it is expensive. Coming to our model, every node has the adjacent nodes to identify the info together. As a reason of restricted safety details to each node in ACAM, the remaining nodes produce the legal info that includes validation codes and their respective keys. The remaining nodes combine and choose a solitary core node which is termed as Center- of-Stimulus (AcSen). The duty of this particular node is to gather the total validation codes produced by the nodes and move them ahead to key-store with the help of the hops present in the middle of the transitions. In this duration the fake ones are eliminated. The major work of the nodes present is that identification and production of validation codes to the unchanged stimulus.
B. Information Collection and validation:
The unique feature of DAA is to arrange a good safety of info and discretion. Along with this it also identifies the fake info by working on the information validation near the aggregators and the adjacent nodes and checking the info while it is moving ahead among the sequential aggregators. DAA Protocol (21)
Input: AWireless sensor network with densely deployed sensor nodes,some of which are designated as data aggregators.For a given value of T,data aggregators are already selected in such a way that (i) there exist at least T nodes between any two data aggregators, and (ii) each data aggregators has at least T neighboring nodes.
Output: Even though the network can have up to T compromised nodes, data are aggregated in data aggregators, data confidentiality is provided and the injected false data are detected and dropped.
Step 1: T neighboring nodes of each data aggregator are randomly selected as monitoring nodes to perform the additional data aggregation and to compute sub MACs of the aggregated data.
Step 2: The following 2T+1 pairs of nodes are formed by enabling the nodes of every pair to share a distinct symmetric key: (1) one pair is formed by the current and forward data aggregators, (2) T pairs are formed by the monitoring nodes of the current data aggregator and the neighboring nodes of the forward data aggregator, and (3) T pairs are formed by the monitoring and forwarding nodes of the current data aggregator. If two nodes want to form a pair but do not have a shared key, then they are assumed to establish a pair wise shared key using an existing key establishment algorithm.
Step 3: Each data aggregator and its selected T monitoring nodes aggregate data and then compute sub MACs. The aggregated data are encrypted by the current data aggregator. The data aggregator and its monitoring nodes compute two sub MACs: one sub MAC for the encrypted aggregated data and another sub MAC for the plain aggregated data. The current data is aggregator coaistrixts two FMACs to forwarding nodes. The integrity of the encrypted data is verified by forwarding pair mates of
the selected monitoring nodes of the current data aggregator. The integrity of the plain data is verified by some neighboring nodes of the forward data aggregator. If the integrity verification of the encrypted or plain data fails at any sensor node, the data are dropped immediately.
C. Threatful conditions:
The mentioned conditions defines the inclusion of an invader, by which the safety matter regarding to the single nodes can be leaked out due to the reason of radio transmission or due to the reason of directly incoming into the network. He might be having the possibility to triumph over the single node he occupied but he cannot get the chance triumph over the key-store due to reason as it is managed by the user. At this point the invader’s assaults can be restricted to a limit by node and information validation, but not on whole. In the design, not only wrong constructive assaults occur but also wrong destructive assaults occur. This means that although the instance has happened info is not produced, making the observers not knowing about the identification of problematic instance. In addition to this some more problems, such as restoring and reproducing of legal reports again and again can also occur and this results in time waste and also working of the sensor networks. On the whole, the aim of the ACAM model is as follows: a) Identifying and eliminating the info at the earliest stage: This process of identifying the fake info at the earliest saves the hard work and also the usage of power accurately. Utilizing the quantity without any instance is to no avail. b) Condensed usage and transparency:
The main focus of ACAM is to decrease transparency and usage of the reserves on whole.
ACAM has the feature of exertion on the lower side nodes and has an ability of effectively eliminating the info which is fake, which are not recognized in hashing methodologies used.
This methodology, ACAM focus on eliminating the fake info and on sorting the wrong messages by utilizing the below methods:
a) Every message id reached to the maximum neighboring nodes and the validation codes are produced by those nodes. This is makes us look that checking is very simple. These validation codes are changed to Bloom sorter type and are joined to the main document and then these are sent ahead.
b) While these are moving ahead among the hops, the mediator modes also process on these validation codes and eliminate the fake ones.
c) At the last after passing all the mediator nodes and some fake ones are unrecognized, those are eliminated near the key-store.
There is a much value in giving an overview on validation codes. Coming to the network, it consists of key-store that is like a reserve with all the keys which are available in all places of network. The interior nodes choose the keys arbitrarily from the reserve. By utilization of these keys the validation codes is produced that is unique for the equal stimulus. When the info is moving ahead, the neighboring nodes produce their respective validation codes that are gathered by the Center Of Stimulus (AcSen) in order to eliminate the fake info and move it ahead to key-store.
info considering the combined decision of the nodes not instead of considering a single node for the validation. Along with this, the keys from the key-store are distributed among the nodes with some division. The nodes in return give the validation codes to the equal stimulus and the validation codes are mapped and verified by utilization of this mapping technique.
The details about the ACAM methodology has been known and now let us know about the functionality. There are some questions regarding the details to be known. Some of the given questions are as below to have a better idea and view on the ACAM
a) What is the procedure of allocating the keys to nodes taking from key-store from which MAC generation and validation can be done appropriately?
b) In what way are the fake info identified?
c) Most of elimination and sorting of fake info is done prior to key-store and if any left are eliminated by key-store and how it identifies the fake ones? d) The validation codes are produced and combined
with Bloom sorter but in what way the areas combined with them are reduced?
D. Key production and info production:
Key-store is a huge storage of keys. These nodes choose the keys on their own in arbitrarily. For example consider
the whole quantity as ‘N’ keys are available 1
0
N i i
k −
=
, and these are again classified as ‘n’ non related separations, every separation has ‘m’ keys m⊂
N and every key has got a different identity. So at the final, a single node will have an index Ni=Kj where j
,
≥
im and j
≤ +
(
i
1)
m
−
1
The system of organizing the node is based on the end user, who chooses the selection set ‘n’ and selection key ‘m’. At that time the node sets its details and makes the arrangements to produce the validation codes for the info that is to be produced. At the time of reaching of the info and when it is recognized by the all adjacent nodes then they produce the validation codes and set their keys. And also they set the AcSen and produce the info that is in the type (site of instance, time of identification, kind of the instance). The identification of AcSen is the appealing one. The procedure applied here is: Every node that can identify stores its identification power and the contrast with the adjacent nodes provides the choice for picking up the AcSen. The node which has highest identification power is AcSen. This gathers the validation codes produced by other codes and them moves it ahead to the key-store by eliminating the fake info.
Then a procedure of developing a validation codes and posting them to key-store is initiated by the key-store. This AcSen involves only those nodes that have an exact wavelength that are mapped to it. The AcSen distributes the info to all the identification nodes. Every node verifies if the identified info is mapped to the produced info. If the condition is true, then the node chooses arbitrarily a key K and produces the MAC.
Mi=f(M)(Ki,Le||t||e),here || denotes concatenation and MAC recursively produces the MAC to message b utilizing key ‘a’.
The syntax followed by this is {i, Mi} and these are gathered by AcSen. AcSen separates the codes that are
being delivered by forming a set of one type considering the key separations. Considering all the types, AcSen chooses a single type T and joins it with the info which is the ultimate result of the AcSen. If the info available id not equal to that of the AcSen produced one then the node should re-involve in AcSen choosing. The concluding info is represented as {Le,t,e,i1,Mi1,i2,Mi2,…….,iT, MiT}.
E. Active Collector assortment:
The assortment procedure of the node is arbitrary and is expansion methodology to DAA. Hence it has a full feasibility of consisting the keys utilized in production of MAC i.e.(Kij,1<=j<=T). The procedure utilized in choosing the node is arbitrary ad is expansion methodology to DAA. It means that the feasibility of identifying keys by the nodes exists which is utilized for MAC production i.e.(Kij,1<=j<=T). Similar to each other node, the negotiated one even consists of T arbitrary keys. So in order to make the wrong info right by this node it has to have the capability of involving rest of T-1 keys to info, and that is practically not at all feasible.
The instant info is acknowledged, every node ensures to have the existence of T indicators and T validation Codes. Whichever info that has minimum count of those codes along with MAC s, or existence of couple of equal codes causes the elimination of info. The algorithmic code to process sorting is as given:
Every node identifies the MAC and checks if the info that it contains maps to that it receives. If there are none of the keys in T segments that map, then it is just the info is moved ahead to the consecutive node. The major issue of unrecognizing the wrong info begins at this point and if it is unrecognized by every mediator nodes, it is delivered to key-store which ultimately will be sorted, but the problem is that more load and usage has to be done.
F. Key-Store Confirmation:
Considering the total identification procedure, the key-store is the definitive reserve of keys available on the entire structure. The fake info that is missed on the process area is lastly found out at key-store. The validation codes acknowledged from all AcSen will be recomputed at the key-store to the every info and evaluates with the acknowledged. When evaluated if not mapped, it is a wrong info and will be eliminated. Due to the reason of huge acquaintance of every key, no fake data and info will be identified near to T-1 separations.
G. Validation code magnitude diminution:
In common the info holds the validation Codes for validating. Every node holds T validation codes and T key indicators that increments transparency. Although, the transparency is managed by arranging some limitations in utilizing hardware, commonly we utilize steady bloom sorting model to join validation codes to info in order to decrement transparency. Nevertheless the usage of identifying and eliminating the fake one does not change.
H. Steady bloom sorting in ACAM:
decrement the area occupied by it and the sorting can be better. The finishing info produced by AcSen is of type: {Le,t,e,i1,i2,…,it,F}.
The given below points are to be verified for authorize the info:
a) Confirm if info is with T key indicators and m-bit string F and minimum of KT ’1’s in F.
b) Confirm if each T key indicator are subset of dissimilar separations.
c) After the packet is delivered, calculates M=f(M)(K,Le||t||E), and involves procedure and
confirm if the relative bit is 1 at F, and if it is 0 eliminate it.
d) If there is a non equivalent key for thee node, it sends ahead the info to consequent hop making the wrong info miss out.
The key-store is the reserve for the keys available. In the due course, for the each info that is moving ahead inside the key-store verifies the availability of T indicator and m-bit F of minimum KT 1 is available in there. The bloom sorter will be produced utilizing the self keys and verifies with the info that moving in. If it is equivalent, it is correct info or else it is eliminated.
IV. ACAM FUNCTIONALITY
The current segment considers the enumeration of efficiency in the path of process and later calculating the bloom sorters wrong constructive feasibilities near the key-store and the moving ahead node (which means that the feasibility of wrong info being missed from identification). The previous outputs have been utilized to select the respective arguments in order to enhance the identification power of ACAM and minimize the wrong constructive. The amount of usage reserving attained by ACAM with elimination of fake info is verified (Section III-D), and replicated assessments are given (Section III-E).
I order to identify the info that has been fake, ACAM utilizes T that holds validation codes (that are available in type of Bloom, sorter). So an invader which negotiates keys in T and other dissimilar separations shall produce info lucratively. ACAM has no capability to identify or eliminate that fake info. The rest of the segment explains the situations in which invader will have keys in dissimilar separations is examined.
A. DAA efficiency:
The invader has no ability of creating the validation codes to the rest T - Nc types. To facilitate the construction of legal info, it needs T-Nc keys and the same amount of validation codes. To identify the wrong MAC and eliminate the info, the feasibility of moving ahead node that has the T-Nc keys is premeditated.
So now, we shall assume an invader selects T-Nc
different separations and one key in the every separation, now the feasibility for node comprising of T-Nc keys represented by p1 is as follows:
'' ( ')
1 ''/
'
ct k t
p t n
t
t
N
=
=
= −
Here k= amount of keys contained by every node
m=amount of keys in a separation n= amount of key separations
The portion of info that is fake and is to be identified and eliminated in h hops is as follows ph = 1− (1 − p1) h
The medium amount of hops for which a replica of info navigate is
1
1
1
(1
1)
i1
i
i
p
p
p
∞
− =
−
=
∑
From the above we can draw a result that if the amounts of hops increment then the identification portion also gets incremented. So for an illustration let us take a situation in which amount of key separations n=10, amount of keys in the separation m=100, amount of keys contained by every node k-500 and every packet holds T=50 validation codes. The Nc data is mentioned as 1, 3, 4 then the result that is received is p1=0.2, 0.1, 0.05 accordingly. The representation 6 mentioned before shows, if an invader contains keys in one separation, 90% of info that is fake will be eliminated in the early 0 hops. In the same way if an invader contains keys in couple of separations 80% of the wrong info will be eliminated in 15 hops. Considering a most terrible situation is at that time if MAC is wrong related to 80% of info are fake and eliminated in 32 hops and cover an area of 20 hops. The mentioned numbers indicate that ACAM changes the situation into an advantage in which if the info sending route is large then accrued usage o sorting is big.
B. Typical Bloom sorting construction to determine constructive fake info:
In this part wrong constructive feasibility if an info holds a bloom sorter in place of validation codes is examined. The examining is necessary in order to verify if the bloom sorter has the capability to minimize the volume occupied by the packet through damaging the safety.
a) Constructive fake ones near key-store: Now the possibility of invader receiving the erroneous packet is low. The kNc botching results for Nc true validation codes are kNc “1”s for a m-bit bloom sorter are recognized. As a result just the rest m-kNc nits in Bloom sorter have to be identified. The feasibility of assuming every bit correct is known by 1/2m−kNc.
The prototype of the bits can be assumed much intelligently at the invader side. Due to the reason that unchanged bit is only utilized to point the dissimilar hashing, the hash outputs k(T-Nc) of fake validation codes are pointed to minimum a single or near the highest k(T-Nc)
dissimilar bit areas. Intelligent assumption need not say that to select above the k(T-Nc) extra “1”s. The entire amount of bit prototypes of k(T-Nc) hash outputs is derived by usage of the given formula.
( )
1
( )
k T Nc m i i
B
−
=
=
∑
considering the below nodes of 20kbps proportion and 36 byte packet area. Preponderance of which is fake is even then identified and eliminated. Suitably assumed Bloom sorter never will be utilized to identify an additional wrong info which is of dissimilar substance as a reason of validation codes basing the substance of the info, it acquires 34 hours extra to construct a dissimilar wrong apprehension. Remember that previously denoted feasibilities will not provide feasibility of lucratively assuming the worth of the key, for which potency can be determined through the duration and autonomous nature of Bloom sorter.
b) Constructive fake ones at nodes moving ahead: So by knowing that it is very complicated to deceive the key-store, the negotiated node plans to deceive maximum mediator nodes in order to squander usage. This possibly will spot maximum bits it could, making an attempt to wrap every spotted bit with a true F. supposing that bits considered from the mediator nodes are previously spotted, the information is moved ahead. The given method reflects a modest change in tumbling the efficiency of on path sorting.
As a reason of available of T validation codes and everyone are blotched k counts and present are maximum kT
“1” bits of true F. If in excess of kT bits are“1”, a mediator node shall eliminate the info. Hence the approach of invader is that of spotting the (maximum) kNc bits among Nc true validation codes, and later spot rest k(T − Nc) bits as “1”. Now we determine the feasibility of moving ahead node A
along a single key T −Nc keys derives every bit spotted, crashing to identify that wrong info.
As a result of hash procedures point a MAC for every m
bits consistently, the feasibility of A’s k bits everyone come under kT “1”s spotted by the negotiated node, is as follows
(
kT
)
kc
m
p
=
Assuming the readings of m and T, probability trail of reduction in feasibility is made through selecting k. Through changing the primary arrangement derived one to zero it is changed as
ln
'
'
ln
1
' '
0;
kT k
m
c
e
e
kT
l
m
p
e l
k
=
=
+
∂
=
=
∂
Supplementary assessment derives that if k = m Te, pc
will have least amount e− mTe. Considering an illustration, say m = 64 and T = 5, results in pc ≈ 0.01. hence the feasibility of identifying the wrong info near anode moving ahead is derived with p1’= (1 − pc)p1,where p1 will be single-hop sorting feasibility in derivation 2.Selecting a better amount for k decreases the single-hop identifying the feasibility with 1%.
Regard as an illustration, here p1 = 0.2, that provides p1’ = 0.198. Which says 89% of which is fake is sorted among the early10 hops and medium hops of transport are 5.05. On contrast with the previous outputs in Section III-A, the changes are unidentifiable. It says, on the process sorting usage will not be exaggerated high through utilization of Bloom sorter. Lastly it utters about it saying Bloom sorter
significantly decreases the packet area to hold confirmation details and preserve the usage on the process sorting and key-store confirmation.
C. Choosing necessary constraints:
Every constraint has to be considered in order to make ACAM efficient. At the outset the readings of k,t,n and m are preferred.
a. Global key pool constraints: The foremost consequence of global key reserve construction and key allotment is on the process sorting. Derivation 2 explains k/N and T has to be bigger n order to increment the feasibility of identification single hop p1.In concurrent k is restricted with sensor accumulated space. If every key will be taken as 64 bit big accumulation 50 keys need 400 bytes. It quantifies to a limited part of below nodes’ accumulation. Though the proportion k/n has to not cross a limit, due to the reason of every negotiated node exposes a part of the global key reserve. To large K/N proportion a considerable part of key reserve shall be exposed.
T will be selected with the amount of bits a packet shall bear. Coming to the situation of few below node, packets shall not be large. The extent of T is depended with the area present later to the segregation of the area of the info matter etc. The usage considered in moving ahead also bases on selection of T. Bigger packets need high quantity of usage. T has to be selected in order to give adequate on process sorting usage and reserve it.
The separation count n impinges on the on process sorting feasibility. Minimum amount of n gives high amount of p1.Considerable increment of n results in complication to the invader in congregating keys from every separation. The feasibility of couple of nodes that has similar key is determined though the readings of k, m. Those situations have to be eliminated. The feasibility of those situations is as follows with k, m, and n as
1'
(1
c) 1
p
= −
p p
Bigger readings of k, m, due to the reason of the proportion k/m is measured the sorting feasibility p1 leftover similar. In performance some million keys has to be needed to make the p1 minimum.
b. Consumption density: The supplementary feature which has to be taken into view is the Consumption density ρ. As there is a requirement of T validation codes from unique types to produce the legal info, the identification nodes has to be bigger one in count for acquiring keys from T separations.
E[D|n_], the predictable count of nodes has to be combined and acquire keys from n_ unique separations, is determined in procedure given below.
' 1
0
1 [ | ']
' '[ | '] ln( ) 1 '
n i
E E D n
n i
n
E E D n n
n n
E E
+ =
= =
−
= =
− ≈
∑
guarantee adequate amount of identification nodes. In an illustration, if n = 10,it reads 7, 12 nodes to be combined and acquire keys from 5, 7 separations. Say T = 5, Nd and made to minimum of 7, or elevated (e.g., 12) in order to contain adequate density fro node.
c. Bloom sorter constraints: The bloom sorter constraints are chosen based on the key reserve constraints placed primarily. If a key has extent of
log2N, T key shows a m bloom sorter say Tlog2N +
m bits in view of every packet. The reading of m has to be big in order to decrease wrong constructive feasibilities. The hash procedure k in bloom sorter is made a selection depending on the derivation 5.
D. Usage optimization:
ACAM reduces the usage of nodes considering premature identification and elimination of wrong info. ACAM makes info to hold T key indicators along with Bloom sorter, besides the normal areas in info. These further areas take supplementary usage in transition and calculation. The subsequent replica enumerates the usage expenditure. Imagine the extent of the Bloom sorter and key indicator as Ls and Lk, correspondingly. The extent of a standard info is represented as Lr. The content of an ACAM info as follows Lr = TLk + Ls + Lr. standardizing the packet extents as Lr and making
'
' 1
' r r
k r r
L L
L L
T
L L
δ
α
α
α α =
= + +
≈
Say the quantity of hops transported in info be H, and quantity of legal interchange be 1and wrong inserted interchange be β. Exclusive of ACAM, every info (along with fakes) transport every hop of H. Considering ACAM, a wrong info with T −Nc fake validation codes has feasibility (1−p1)h−1p1 to transport accurately h hop stage nodes and here p1 = k(T−Nc)/N. Hence, the usage frenzied in order to transport all the interchange, represented by e exclusive ACAM and E considering ACAM, as follows:
(1
)
1 (1
1)
'(
)
1
He
H
p
E
H
p
β
α
β
=
+
− −
=
+
V. ACAM UNDERNEATH ADDITIONAL NETWORK FEATURES
ACAM takes a lead in all-encompassing networks due to the reason of utilization of crowded nodes available for perceiving the inward bound stimulus and substituting based on it to produce validation codes. The maximum amount of nodes and the hops maximizes the feasibility of eliminating the info that are fake. ACAM is proficient to as much as necessary in order to diminish usage expenditure and fake info elimination in case of decreased amount of nodes.
ACAM shall exert in all varieties of info and its penetration procedures such as Directed Diffusion, GRAB, TTDD [6].In order to satisfy the circumstances, it just accumulates few keys and capable of producing hash procedures for each inward bound info.
VI. ACAM’S IDENTIFICATION AUTHORITY:
The identification authority of ACAM is extremely towering. Fundamentally, the invader shall negotiate an individual node and will be acquainted with the separation currently nearby. In such situations it will be an uncomplicated job for ACAM to identify faulty ones. The competence of ACAM can be shown when an invader by mistake is familiar with every T-1 separation key, it has the capability to eliminate the info which is fake by greatly good organization. This every so often as well fights in opposition to assaults by T recognized separation keys except below n separations. By the n separations invader makes out each key in key-store that is extremely unattainable other than exertion if coincidentally recognizes. In a case if stimulus is delivered, a produced info consists of validation codes of a few separations. Nevertheless the info inserted by invader encloses every separation kind that obviously designates as a wrong info. ACAM is yet prevailing such that it shall identify fake info out of n-1 separations and here occurrence of n separations is intricate.
Node consumption density acts as an important part in approximation and the identification usage of ACAM. While everybody assumes, the relationship of ACAM identification usage depends a smaller amount with AcSen selection. The explanation assumed AcSen shall assault will be a negotiated node constantly attempts to take as an AcSen through dissemination of utmost indication potency. If a node has been preferred as AcSen, it shall have each right to just move ahead or eliminate info. Nevertheless this shall be avoided through enhancing the methods of selecting the node. The prospect to a node of fitting into the AcSen is supposed to be turned around between nodes in order to thwart the circumstances.
a. Diverse insider assaults: Thus far the conversation is all about just wrong constructive instances. Every so often, the node takes delivery of info. If a negotiated node individually endorses like AcSen, it shall not endorse the info by trouncing the genuine happening instance with no information. It’s a wrong destructive assault that shall not be recognized by ACAM. In an attempt to wrap up, ACAM is not available to identify and resolve every assault through negotiated node. It shall competently identify and eliminate fake info excluding identification of wrong destructive assaults, storing and again using legal info, inserting wrong organized packets in order to interrupt supplementary procedures.
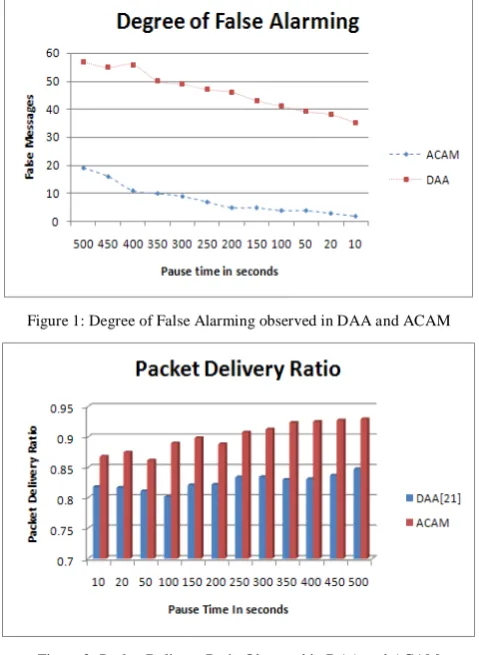
VII. PERFORMANCE ANALYSIS
Figure 1: Degree of False Alarming observed in DAA and ACAM
Figure 2: Packet Delivery Ratio Observed in DAA and ACAM
VIII. CONCLUSION
Earlier than ACAM, several procedures to sensor network safety were present excluding compact through insertion of info that is fake. Exceptionally, ACAM gave an initiative through the capability of identification and elimination of info that is fake. It composes the utilization of crowded availability of nodes of the network. It restricts the safety details for every node in order to create combined conclusion for validating the node. The central maxim of ACAM is that the evading of negotiated nodes, that decreases the assaults from the invader and consecutively decreasing the capability for the invader to insert fake info. ACAM is wellorganized sufficient which can eliminate 80 -90 % of info that is fake in early 10 hop moving ahead nodes, decreasing the usage expenditure with 50 % and further. In advance, learning has been conceded in enhancing the ACAM methodology and in next to no time it resolves and develops a foremost area by way of profitable outcomes
IX. REFERENCES
[1]. C. Karlof and D. Wagner, “Secure Routing in Wireless Sensor Networks: Attacks and Countermeasures,”, IEEE SPNA, 2002.
[2]. A. Wood and J. Stankovic, “Denial of Service in Sensor Networks,” IEEE Computer, October 2002.
[3]. S. Slijepsevic, M. Potkonjak, V. Tsiatsis, S. Zimbeck, and M. Srivastava, “On Communication Security in Wireless Ad-Hoc Sensor Networks,” IEEE International Workshops, 2002.
[4]. D. W. Carman, P. S. Kruus, and B. J. Matt, “Constraints and Approaches for Distributed Sensor Network Security,” NAI Labs, Tech. , September 2000.
[5]. S. Basagni, K. Herrin, E. Rosti, and D. Bruschi, “Secure Pebblenets,” in ACM MOBIHOC, 2001.
[6]. F. Ye, H. Luo, J. Cheng, S. Lu, and L. Zhang, “A Two-tier Data Dissemination Model for Large-scale Wireless Sensor Networks,” in ACM MOIBCOM, 2002.
[7]. Z.YuandY. Guan, “Adynamic en-route scheme for filtering false data in wireless sensor networks,” to appear in Proceedings of IEEE INFOCOM 2006, Barcelona, Spain, April 23–27, 2006.
[8]. W. Diffie and M. Hellman, “New directions in cryptography,” IEEE Trans. on Information Theory, 22(6):644–654, November 1976.
[9]. C. Karlof, N. Sastry, and D.Wagner, “TinySec: A link layer security architecture for wireless sensor networks,” Proc. of the Second ACM Conference on Embedded Networked Sensor Systems, November 3–5, Baltimore, MD, 2004.
[10]. W. Heinzelman, A. Chandrakasan, and H. Balakrishnan, “Energy-efficient protocol for wireless micro sensor networks,” Proc. of 33rd Hawaii International Conference on System Sciences, 2000.
[11]. S. Lindsey and C. S. Raghavendra, “PEGASIS: Power efficient gathering in sensor information systems,” Proc. of IEEE Aerospace Conference, 2002.
[12]. S. R. Madden, M. J. Franklin, J. M. Hellerstein, and W. Hong, “TAG: a tiny Collection service for ad-hoc sensor networks,” Proc. of the 5th Symposium on Operating Systems Design and Implementation, pp. 131–146, 2002.
[13]. C. Intanagonwiwat, R. Govindan, D. Estrin, J. Heidemann, F. Silva, “Directed diffusion for wireless sensor networking,” IEEE/ACM Transactions on Networking, vol. 11, no. 1, February 2003.
[14]. W. Heinzelman, J. Kulik, and H. Balakrishnan, “Adaptive protocols for information dissemination in wireless sensor networks,” Proc. of 5th ACM/IEEE Mobicom Conference, 1999.
[15]. L. Hu and D. Evans, “Secure Collection for wireless networks,” Proc. of Workshop on Security and Assurance in Ad hoc Networks, Jan. 28, Orlando, FL, [2003].
[16]. B. Przydatek, D. Song, and A. Perrig, “SIA: Secure information Collection in sensor networks,” Proc. of SenSys’03, Nov. 5–7, Los Angeles, 2003.
[17]. H. C¸ am, S. Ozdemir, P. Nair, D. Muthuavinashiappan, and H.O. Sanli, “Energy efficient and secure pattern-based data Collection for wireless sensor networks,” Special Issue of Computer Communications on Sensor Networks, pp. 446–455, Feb. 2006.
[18]. H. C¸ am, “Non blocking OVSF codes and enhancing network capacity for [3]G wireless and beyond systems,” Computer Communications, vol. 26, no. 17, pp. 1907– 1917, 1 Nov. 2003.
[20]. K. Wu, D. Dreef, B. Sun, and Y. Xiao, “Secure data Collection without persistent cryptographic operations in wireless sensor networks,” Proc. of 25th IEEE International Performance, Computing, and Communications Conference, (IPCCC) 2006, pp. 635–640, 2006.