International Journal of Emerging Technology and Advanced Engineering
Website: www.ijetae.com (ISSN 2250-2459, ISO 9001:2008 Certified Journal, Volume 4, Issue 1, January 2014)
663
TEST DATA COMPRESSION FOR LOW POWER TESTING
OF VLSI CIRCUITS
Robert Theivadas J
1, Ranganathan Vijayaraghavan
2 1 Anand Institute of Higher Technology: Chennai 6031032
Dr. Mahalingam College of Engineering and Technology: Pollachi 642003
Abstract— The two major areas of concern in the testing of
VLSI circuits are Test data volume and excessive test power. Among the many different compression coding schemes proposed till now, the CCSDS (Consultative Committee for Space Data Systems) lossless data compression scheme is one of the best. This paper discusses the techniques that test data compression scheme based on lossless data compression Rice Algorithm as recommended by the CCSDS for the reduction of required test data amount to be stored on the tester, which will be transferred during manufacturing testing to each core in a system-on-a-chip (SOC). In the proposed scheme, the test vectors for the SOC are compressed by using Rice Algorithm, and by applying various binary encoding techniques. Experimental results show that the test data compression ratio for the larger ISCAS 89 Benchmark Circuits is significantly improved in comparison with existing methods.
Keywords - CCSDS, Rice Algorithm, SOC, test data compression.
I. INTRODUCTION
It is really difficult to test digital circuits as a bulky amount of test data has to be delivered to the circuit under test (CUT). It is more difficult to test VLSI chips, because of their complicated functionality and size caused by increased integration levels of VLSI chips. Furthermore, testing of VLSI design is quite expensive. Therefore, VLSI producers aim at reducing the test cost of these circuits. The two important factors contributing to test cost are the test data volume and test power.
While testing SOCs, the hardest task is handling the huge amount of test data that has to be transferred between the tester and the chip. A set of test vectors are present in each core of a SOC that should be applied to the core. During modular testing, it is necessary to store these test vectors on a tester and then transfer them to the inputs of the core. Because of the placement of increased number of cores on a single chip, total amount of test data for the chip is highly increased. This causes a big problem because of the expensivenes demerits of automated test equipment (ATE). Testers have limited speed, memory & channel capacity.
Usually, the time taken to test a chip relies on the amount of test data that has to be transferred to the chip, and the speed at which the data is transferred. This in turn relies on the speed and channel capacity of the tester, and the organization and characteristics of the scan chains on the chip. Therefore, from a test economics point of view, test time and test storage are the two main areas of concern when it comes to SOCs [2].
In this paper, a lossless data compression scheme is presented, which reduces the amount of test data that is to be stored on the tester and then transferred to the chip. In this, a smaller amount of compressed data is transferred from the tester to the core in each test vector, instead of transferring the entire data. This also takes lesser time than the time taken to transfer the entire data. The approach discussed here has a significant reduction effect on the test storage needs and the overall test time.
For achieving test vector compression, many different techniques have been published. We have used a technique based on lossless data compression Rice Algorithm as
recommended by the CCSDS Recommendation
compression [1].
II. RELATED WORK
For a long time now, test data compression has been quite an issue. Several compression techniques have been proposed in the bygone years to reduce the test data volume. Some of them are statistical coding [2], run length coding [10], Golomb coding [11], selective Huffman coding [12], Tunstall coding [18], LZWcoding [20], heterogeneous compression technique [19], FDR coding [15], run length Huffman coding [13], multilevel Huffman
coding [14], Bitmask and Dictionary Selection
International Journal of Emerging Technology and Advanced Engineering
Website: www.ijetae.com (ISSN 2250-2459, ISO 9001:2008 Certified Journal, Volume 4, Issue 1, January 2014)
664 III. RICE ALGORITHM
Robert F. Rice from NASA developed the Rice Coding upon which the CCSDS [1] standard is based on. A lossless source coding technique conserves source data accuracy and eliminates redundancy in the data source. The lossless Rice coder has two different functional parts, viz., the preprocessor and the adaptive entropy coder its shown in figure1. The performance measure in the coding bit rate (bits per sample) of a lossless data compression technique depends on two important factors. They are the amount of
correlation eliminated among data samples the
preprocessing stage, and the coding efficiency of the entropy coder. The preprocessor functions in de-correlating data and reformatting them into non-negative integers with the preferred probability distribution. The coding option that performs the best on the current block of samples is selected by the Adaptive Entropy Coder (AEC). The code selection is based on the number of bits that the selected option will use to code the current block of samples. An ID bit sequence will specify the option used to encode the accompanying set of code words.
IV. COMPRESSION METHOD
Test vectors are compressed using Rice entropy coding [1]. The entropy coder first converts the number of input vectors xi into preprocessor samples δi using predictor. The preprocessing is done using a predictor, and then by a prediction error mapper. Based on the predicted
value, yi, the prediction error mapper converts each
prediction error value, Δi, to an n-bit nonnegative integer,
δi, which is suitable for processing by the entropy coder.
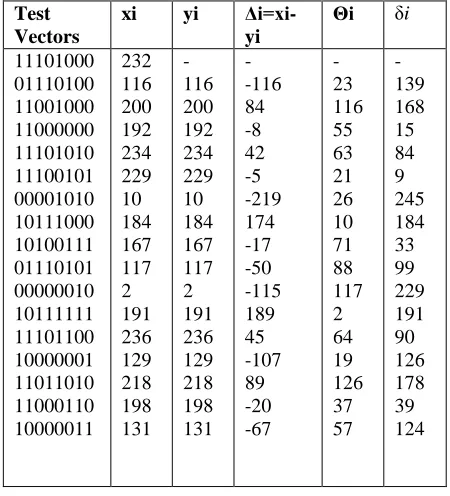
[image:2.612.317.542.443.691.2]For example, the benchmark circuit S298 MINTEST[6] Vectors are taken, and the predictor is applied to 8 bit data values from 0 to 255, as shown below.
Figure. 1: Block diagram of Rice algorithm architecture.
Test Vectors
xi yi
Δi=xi-yi
Θi δi
11101000 01110100 11001000 11000000 11101010 11100101 00001010 10111000 10100111 01110101 00000010 10111111 11101100 10000001 11011010 11000110 10000011
232 116 200 192 234 229 10 184 167 117 2 191 236 129 218 198 131
- 116 200 192 234 229 10 184 167 117 2 191 236 129 218 198 131
- -116 84 -8 42 -5 -219 174 -17 -50 -115 189 45 -107 89 -20 -67
- 23 116 55 63 21 26 10 71 88 117 2 64 19 126 37 57
- 139 168 15 84 9 245 184 33 99 229 191 90 126 178 39 124
International Journal of Emerging Technology and Advanced Engineering
Website: www.ijetae.com (ISSN 2250-2459, ISO 9001:2008 Certified Journal, Volume 4, Issue 1, January 2014)
665 If xmin and xmax respectively represent the minimum and
maximum values of any input sample xi, then, the predicted
value yi, obviously would lie within this range [that is, in
between xmin and xmax]. Consequently, the prediction
error value Δi would surely be one of the 2n values in the
range [xmin – yiand xmax – yi]. For a selected predictor, it
is more likely that there will be small values of |Δi| than
large values. Consequently, the prediction error mapping function will be as follows:
δi = 2Δi 0 ≤ Δi ≤ θi 2|Δi| –1 –θi ≤ Δi ≤ 0 θi + |Δi| otherwise .
where θi = minimum ( yi– xmin, xmax –yi),
The entropy coding module is a collection of
variable-length codes operating in parallel onblocks of J
preprocessed samples. The coding option making the highest compression is chosen for transmission, along with an ID code used to recognize the option to the decoder. As, a new compression option can be chosen for each block.
The zero block option is the first option. This is chosen when one or more preprocessed sample blocks are zeros. Here, the numbers of adjacent all zero preprocessed blocks are encoded by a Fundamental Sequence (FS).
The second option is called the second extension option. This is designed to generate compression data in the range of 0.5 bits per sample to 1.5 bits per sample. In this option, the encoding scheme initially pairs the consecutive preprocessed samples of the J-sample block, and then transforms the sample pairs into new values that are coded with an FS codeword. The FS codeword is represented for γ, where:
γ = (δi + δi+1) (δi + δi+1+1)/2 + δi+1
The third option is the Fundamental Sequence code. This is also called the “comma code”. Here, the codeword is comprised of a string of “0” digits which is equal to the decimal of the symbol which has to be coded. At the end of each current codeword, the digit “1’ is applied to signal its termination. This simple protocol permits one to decode the FS code words without going for lookup tables.
The Fourth option is the split-sample options. In the entropy coder, most of the options will be “split-sample options”. The kth split-sample option takes a block of J preprocessed data samples, splits the k least significant bits
(LSB) from each sample, and encodes the left-out higher order bits with a simple FS code before prefixing the split bits to the encoded FS data stream. Have a look at the example below.
Table 2: FS code word example
δi Binary K=5
5LSB+FS Code
K=6,
6 LSB+FS Code
139 168 15 84 9
10001011 10101000 00001111 01010100 00001001
01011 00001 01000 000001 01111 1 10100 01 01001 1
[image:3.612.326.520.191.321.2]001011 001 101000 001 001111 1 010100 01 001001 1
Table 3: Split Sample option
The final option is the no compression option. When none of the above given options provides any data compression on a block, this final option is selected. Under the no compression option. The preprocessed block of data is transmitted without any modification other than a prefixed identifier.
The entropy coder chooses the option that needs the fewest bits to encode the current block of symbols. An identifier bit sequence makes reference to the option selected. When the quantization is equal to or less than 8 bits, a 3 bit Id will be the output, while the larger quantization will have a 4 bit ID.
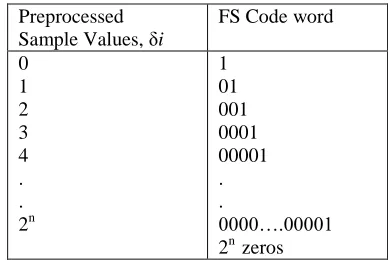
The test data is split into blocks of fixed length, and the variable length adaptive coding the following specifications is applied to the test data. The test vectors are divided into several blocks containing J samples (8, 16, 32, or 64 samples per block), with a maximum of 32 bits per sample.
Preprocessed
Sample Values, δi
FS Code word
0 1 2 3 4 . . 2n
1 01 001 0001 00001 . .
International Journal of Emerging Technology and Advanced Engineering
Website: www.ijetae.com (ISSN 2250-2459, ISO 9001:2008 Certified Journal, Volume 4, Issue 1, January 2014)
666 The output format for the coded data of the first block is ID, Reference value, J-1 FS data sample or default value, and K split data for J-1 samples. And the remaining blocks are coded in the format ID, and K split sample option for J samples or default value. For example, S298 MINTEST Vectors are divided into 8 sample blocks, with each sample containing 8 bits.
Input Data δi δi Output
11101000 01110100 11001000 11000000 11101010 11100101 00001010 10111000
- 139 168 15 84 9 245 184
11101000 10001011 10101000 00001111 01010100 00001001 11110101 10111000
{(111), 11101000, 10001011,10101000, 00001111,01010100, 00001001,11110101, 10111000}
10100111 01110101 00000010 10111111 11101100 10000001 11011010 11000110
33 99 229 191 90 126 178 39
00100001 01100011 11100101 10111111 01011010 01111110 10110010 00100111
{(110),100001,100011, 100101,111111, 011010,111110, 110010,100111,1,01,00 01,001,01,01,001,1
[image:4.612.42.295.216.483.2]K=6
Table 4: Output format of Rice Algorithm
V. EXPERIMENTAL RESULTS
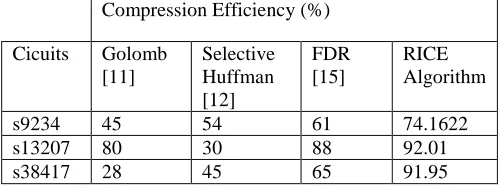
The experimental results for the various ISCAS89 benchmark circuits test vectors are compressed and presented in the following table. We have used the Mintest [6] test datas.We achieved the highest compression percentage for the different benchmark circuits. The comparison is also given in the table below.
Compression Efficiency (%)
Cicuits Golomb
[11]
Selective Huffman [12]
FDR [15]
RICE Algorithm
s9234 45 54 61 74.1622
s13207 80 30 88 92.01
s38417 28 45 65 91.95
Table 5: Comparison of different compression schemes using MINTEST test data
VI. CONCLUSION
Rice Algorithm coding is a great way to compress test data. It comes with dual benefits in that, it reduces both the amount of test data required to be stored on the tester and the time taken to transfer the test data from the tester to the CUT. In this paper, we have discussed of how we have applied our algorithm on different benchmark circuits, and have made comparison of our reults with existing test compression techniques. By applying our technique, we have achieved a significantly higher compression ratio.
REFERENCES
[1] Lossless Data Compression. Report Concerning Space Data System Standards,CCSDS 121.0-B-2. Blue Book. Issue 2. Washington, D.C.: CCSDS, May 2012.
[2] Abhijit Jas, Jayabrata Ghosh-Dastidar, Mom-Eng Ng, and Nur A. Touba, “An Efficient Test Vector Compression Scheme Using Selective Huffman Coding,” in IEEE Trans. Comput.-Aided Des. Integr. Circuits Syst., vol. 22, no. 6, pp.797–806, Jun. 2003.
[3] Y. Zorian, E. J. Marinissen, and S. Dey, “Testing embedded core based system chips,” in Proc. IEEE Int. Test Conf., 1998, pp. 130–143.
[4] A. Chandra, and K. Chakravarty, “Test Data Compression and Decompression for System-On- a-chip using Golomb codes”, VLSI Test Symposium, pp. 113-120, 2000.
[5] C.V. Krishna and N. A. Touba, “Reducing Test Data Volume Using LFSR Reseeding with Seed Compression”, in Proc. of the IEEE International Test Conference (ITC), 2002.
[6] F. F. Hsu, K. M. Butler, and J. H. Patel, “A case study on the implementation of Illinois scan architecture,” in Proceedings of IEEE International Test Conference, 2001,pp. 538-547.
[7] I. Hamzaoglu and J. H. Patel, “Reducing test application time for full scan embedded cores,” in Proceedings of International Symposium on Fault-Tolerant Computing,1999, pp. 260-267.
[8] B. Koenemann et al., “A SmartBIST Variant with Guaranteed Encoding,” Proc. 10th Asian Test Symp. (ATS 01),IEEE CS Press, 2001, pp. 325-330.
[9] M. Ishida, D.S Ha and T. Yamaguchi, “COMPACT: A Hybrid Method for Compressing Test Data”, VLSI Test Symposium, pp. 62-69, 1998.
[10] M. Tehranipoor, M. Nourani, and K. Chakrabarty, “Nine- coded compression technique for testing embedded cores in SoCs,” IEEE Trans.Very Large Scale Integr. Syst., vol. 13, no. 6, pp. 719–731, Jun. 2005.
[image:4.612.42.292.593.686.2]International Journal of Emerging Technology and Advanced Engineering
Website: www.ijetae.com (ISSN 2250-2459, ISO 9001:2008 Certified Journal, Volume 4, Issue 1, January 2014)
667 [12] X. Kavousianos, E. Kalligeros, and D. Nikolos, “Optimal selective
Huffman coding for test-data compression,” IEEE Trans.
Computers,vol. 56, no. 8, pp. 1146–1152, Aug. 2007.
[13]. M. Nourani and M. Tehranipour, “RL-Huffman encoding for test compression and power reduction in scan applications,” ACM Trans. Des. Autom. Electron. Syst., vol. 10, no. 1, pp. 91–115, 2005.
[14] X. Kavousianos, E. Kalligeros, and D. Nikolos, “Multilevel-Huffman test-data compression for IP cores with multiple scan chains,” IEEE Trans. Very Large Scale Integr. (VLSI) Syst., vol. 16, no. 7, pp. 926– 931,Jul. 2008.
[15] A. Chandra and K. Chakrabarty, “Test data compression and test resource partitioning for system-on-a-chip using frequency-directed run-length (FDR) codes,” IEEE Trans. Computers, vol. 52, no. 8, pp. 1076–1088, Aug. 2003
[16] X. Kavousianos, E. Kalligeros, and D. Nikolos, “Test data compression based on variable-to-variable Huffman encoding with codeword reusability,” IEEE Trans. Comput.-Aided Des. Integr. Circuits Syst.,vol. 27, no. 7, pp. 1333–1338, Jul. 2008.
[17] Kanad Basu, Prabhat Mishra, “Test Data Compression Using Efficient Bitmask and Dictionary Selection Methods,” IEEE Trans. Very Large Scale Integr. (VLSI) Syst., vol. 18, no.9, Sep.2010
[18] H. Hashempour, L. Schiano, and F. Lombardi, “Error-resilient test data compression using Tunstall codes,” in Proc. IEEE Int. Symp. Defect Fault Tolerance VLSI Syst., 2004, pp. 316–323.
[19] L. Lingappan, S. Ravi, A. Raghunathan, N. K. Jha, and S. T. Chakradhar, “Test-volume reduction in systems-on-a-chip using heterogeneous and multilevel compression techniques,” IEEE Trans. Comput.-Aided Des. Integr. Circuits Syst., vol. 25, no. 10, pp. 2193– 2206, Oct. 2006.