2019 International Conference on Computer Science, Communications and Big Data (CSCBD 2019) ISBN: 978-1-60595-626-8
Human Action Recognition Using Spatio-Temporal Pyramid Model
Based Background Subtraction on Depth Maps
Emmanuel MUTABAZI, Jian-jun NI and Ye YANG
College of IOT Engineering, Hohai University, Changzhou, 213022, China
*Corresponding author
Keywords: Human Action Recognition, Background Subtraction in Regions, Improved Adaptive Region Decision Function, Histogram Oriented Gradient, Multi Class Support Vector Machine.
Abstract. In this paper, a background subtraction in region method is proposed to recognize actions and interactions in the video. Firstly, the video is taken and converted into frames. Preprocessing techniques are applied to sampled images for noise reduction. Next, a background subtraction method is used to extract the foreground objects in region units. The combination of the background model, color of the object and movement information are employed to get the region object likelihood. Then, an Improved Adaptive region decision function determines the object regions. Moreover, the human detection method produces a bounding box surrounding a person. Histogram Oriented Gradient (HOG) is used for feature extraction and representation. Finally, Multi class support vector machine (SVM) is the classifier used for classification.
Introduction
Human Action Recognition (HAR) is a new paradigm research area in computer vision. It has many applications in real-world such as intelligent surveillance systems, human-computer interaction and robotics [1]. Recognizing human actions in a moving background, non-stationary camera, scale variations and scenes with cluttered are still challenges for better recognition. Besides the difficulties related to recognition, a main challenge for detection in video is the size of the search space defined by spatio-temporal tubes formed by sequences of bounding boxes along the frames. Therefore, the appropriate background subtraction, features selection, feature extraction, and feature representation are the major tasks in the action recognition process [2]. Feature extraction is very important because it extracts a set of key parameters that describe the specific set of a human action so that the parameters can be used to distinguish among other actions. In this paper, we present a hierarchical graphical model for recognizing human actions and interactions in video. Our method includes the whole processing that spans the pixel level, blob level, object level and the event level computation of video. The rest of the paper is organized as follow. In section 2, Related works is given. In section 3, the proposed method is presented. In section 4, the Experiment and Results are presented. Finally, the Conclusion is given in section 5.
Related Works
concatenate the HOG features extracted from the spatial cuboid. Moreover, a Local Mean Spatio-temporal Feature (LMSF) was used [6] to improve the speed of action recognition in-depth images and introduced a motion capture method to capture valid frames in the depth sequences and finally applied the spatio-temporal pyramid to aggregate geometric and temporal cues.
Background Subtraction in Regions
In this section, A background subtraction method in region units is employed [7]. First, an image
must be divided into small similar regions. We define k
k ki i I
R
as the set of the regions at the
k-th frame. The information of the object and background colors and previous object positions are combined to determine the object region likelihood. Then, the object silhouette is obtained by the
region decision function
f
Dk defined on k .Region Object Likelihood
The region object likelihood L Rk
i of regionR
ik
kis calculated by
1
2
k k k k
i S i b i r i
L R L R
L R
L R (1) In the above equation, L Rks
i is the naïve object region likelihood given by the arithmetic mean ofthe pixel object likelihoods l s
, i.e. k
/ ki i
S l s nR
, here ki
R
n is the number of pixels in the
region
R
ik. The object color likelihoodL R
kc
i is given by k
/ ki i
S R l s nR
. The regularization termk k r i
L R
is the overlapping ratio of the regionR
ik and is given by k / ki i
r R R
n n , where k
i
r R
n is the number
of pixels in region
R
ikthat belongs to the previous object region.
2is a regularization parameter.Improved Adaptive Region Decision Function
We start by assigning each pixel to its label in L
0,1 , where 0 denotes a background and 1 denotes an object. The decision of the background subtraction in regions is performed in regionunits. Hence, the decision function
f
Dk of the k-th frame is defined on kR and takes its value L. The
decision function
f
Dk:
R
k
L
is defined as
1
0
otherwise
k i
k k k
i
k R
D i
if L
R
H
f
R
(2)Where region thresholds k
i
k R
H ’s are defined as an arithmetic mean of the thresholds
H
sk of pixels ink i
R
, and
is a constant to make sure there is enough lower bound. We determine the pixel thresholdk s
H
in the whole image from the previous frame by
2 1
/ 2
k k k
s s s
H H M (3)
In the above equation,
H
s0
H
1s
M
s0
H
minandM
sk1 stands for local minimum of the regionconsidering the weighted average of local region object likelihood
m
sk1 and the pixel objectlikelihood l s
i.e. wmsk1
1 w l s
where w is set to 0.8 in the experiments.m
ks1 is given by 1 1 1
1, \x R ,
1
min
min ,
otherwise
k k k
k x C s d L R O R R
k s
if d s O d m
H
(4)
Where C s d
, is a ball with radius dcentered at pixel s L, k1
R s, is the region likelihood of Rat the
k1
th frame and
1
, k
d s O is the nearest distance from pixel sto the previous object
region object k 1
O . Then we truncate
H
sk’s by a constantH
maxto prevent them from becoming too [image:3.595.61.535.113.351.2]high. The object segmentation process is shown in (Fig. 1).
Figure 1. Illustration of the jump action. From the left, extracted frame, human detection using bounding box, background subtraction, and colored Region of Interest (ROI).
Feature Extraction
HOG is a feature descriptor used in computer vision and image processing for the purpose of object detection [2]. To calculate a HOG descriptor, we need to first calculate the horizontal and vertical gradients; finally, we calculate the histogram of gradients.
Classification
Multi-class SVM has been used to solve multi-class problems [8]. The most important criterion for evaluating the performance of the multi-class SVM is their accuracy rate. The Gaussian RBF Kernel is used to train all the datasets as it can map non-linearly samples into a higher dimensional space.
Experiments and Results
To evaluate the performance of our proposed approach, we conduct experiments on publicly available Weizmann dataset [9], in the environment, MATLAB 2015b, Intel Pentium processor and Memory of 2GB. In this dataset, we considered 5 actions, namely: walking, bending, jumping, running and skipping. The validation performance is measured by training 70% of the training set and testing the other 30% of the training set. The accuracy of the proposed method is measured in terms of classification accuracy using Multi-class SVM classifier. As shown in table 1, the proposed approach is able to achieve 97.6%, 95.6%, 97.6%, 98%, and 95.6% of accuracy to detect bend, run, jump, walk and skip action respectively. In order to examine the performance of our method, we compared it to other two methods namely LMFS [6] and HOG_MBH [10].
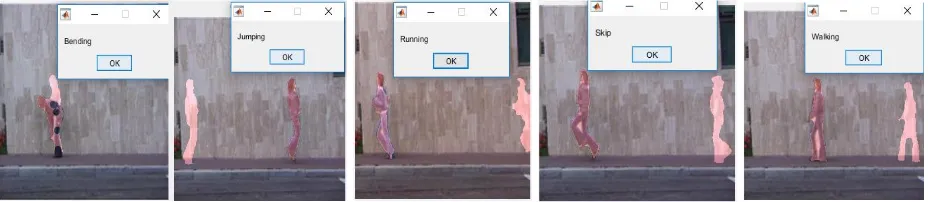
Figure 2. Results of actions recognition. From the left to the right, we have bend action, jump action, run action, skip action and walk action.
The results of the recognition accuracy for all the five actions, using our proposed approach are summarized in (Table 1) below.
Method Accuracy
LMFS [6] 93.82%
HOG_MBH [10] 95.4%
[image:4.595.238.358.309.386.2]Our Method 96.88%
Table 1. Summary of the Experimental Results.
Actions Accuracy
Bend 97.6%
Run 95.6%
Jump 97.6%
Walk 98%
[image:4.595.182.405.405.599.2]Skip 95.6%
Table 2. Comparison of our method with others.
Figure 3. Comparison of the performance of our method with others.
Our method was compared with the state-of-the art methods, and our results show that our method outperform other existing methods in terms of accuracy as shown in the (Table 2) and (Fig. 3) above.
Conclusion
improve the performance of the low-level processing, and representing the actions in 3 dimensions for better recognition accuracy.
Acknowledgement
This work was supported by the National Natural Science Foundation of China (61873086, 61573128), and the Fundamental Research Funds for the Central Universities (2018B23214).
References
[1] Liu, Li, et al. "Learning spatio-temporal representations for action recognition: A genetic
programming approach." IEEE transactions on cybernetics 46.1 (2016): 158-170.
[2] Lahiri, Dishani, Chhavi Dhiman, and Dinesh Kumar Vishwakarma. "Abnormal human action
recognition using average energy images." 2017 Conference on Information and Communication
Technology (CICT). IEEE, 2017.
[3] Xu, Haining, et al. "Spatio-temporal pyramid model based on depth maps for action
recognition." 2015 IEEE 17th International Workshop on Multimedia Signal Processing (MMSP).
IEEE, 2015.
[4] Silambarasi, R., Suraj Prakash Sahoo, and Samit Ari. "3D spatial-temporal view-based motion
tracing in human action recognition." 2017 International Conference on Communication and Signal
Processing (ICCSP). IEEE, 2017.
[5] Ji, Xiaopeng, Jun Cheng, and Wei Feng. "Spatio-temporal cuboid pyramid for action recognition
using depth motion sequences." 2016 Eighth International Conference on Advanced Computational
Intelligence (ICACI). IEEE, 2016.
[6] Ji, Xiaopeng, Jun Cheng, and Dapeng Tao. "Local mean spatio-temporal feature for depth
image-based speed-up action recognition." 2015 IEEE International Conference on Image
Processing (ICIP). IEEE, 2015.
[7] Ahn, Jung-Ho, and Hyeran Byun. "Human silhouette extraction method using region-based
background subtraction." International Conference on Computer Vision/Computer Graphics
Collaboration Techniques and Applications. Springer, Berlin, Heidelberg, 2007.
[8] Van Nguyen, Nang Hung, et al. "Human Activity Recognition Based on Weighted Sum Method
and Combination of Feature Extraction Methods." International Journal of Intelligent Information
Systems 7.1 (2018): 9.
[9] Blank, Moshe, et al. "Actions as space-time shapes." null. IEEE, 2005.
[10] Xing, Dong, Xianzhong Wang, and Hongtao Lu. "Action recognition using hybrid feature
descriptor and VLAD video encoding." Asian Conference on Computer Vision. Springer, Cham,