5
IV
April 2017
Technology (IJRASET)
IJRASET: All Rights are Reserved
1545
A Survey on Data Mining
Ishaan Kumar1, Sandhya Tarwani2 1,2
HMR Institute of Technology and Management Hamidpur, New Delhi, India
Abstract: Information mining is the figuring procedure of finding examples in expansive informational collections including techniques at the convergence of counterfeit consciousness, machine learning, measurements, and database frameworks. It is an interdisciplinary subfield of software engineering. The general objective of the information mining procedure is to concentrate data from an informational index and change it into a justifiable structure for further utilize. In this paper, the basic concept of data mining is being discussed along with the various types of techniques exist. The data mining tools are also described in this study to help researchers in using them foe enhancing and collecting various patterns and relationships from huge data.
Keywords: Mining; genetic; weka; neural; tools;
I. INTRODUCTION
The measure of information being created and put away in expanding by a quick speed because of progression of new innovations .With heaps of information comes awesome obligations of taking care of it so it can be utilized when required .In our exploration paper we will talk about on how information mining helps us in dealing with this information and removing data when required. Information mining is the way toward separating data from an informational index and changes it according to our requirements. Around 1960's another procedure was developed named as information angling or information digging. Notwithstanding, it was considered as an awful practice since it investigated information with no earlier theory. In late 1980's, this term database mining was advanced from information angling by HNC, a san diego based organization. Information mining term appeared after the global meeting on information mining and learning revelation (KDD-95) held in Montreal under AAAI sponsorship. At long last in 1996, Usama Fayyad propelled information mining and learning revelation.
There are different strides for information mining. The initial three stages include organizing or sorting the data and taking out the one we require from the entire part of information. At that point, the information must be changed into an appropriate way to such an extent that all the essential calculations can be connected to this. For instance information change is given by Cortes and Pregibon (1998). In the event that every information record depicts one telephone call however the objective is to foresee whether a telephone number has a place with a business or private client in light of its calling designs, then all records related with each telephone number must be accumulated, which will involve making ascribes comparing to the normal number of calls every day, normal call span, and so on. Each one of those inspired by this point ought to peruse the book Pyle 1999. The fourth step principally concentrates on the change of this information into information into trees by means of calculations to discover the examples. The term Knowledge Discovery in Databases, or KDD for short, alludes to the expansive procedure of discovering information in information, and accentuates the "abnormal state" utilization of specific information mining strategies. It is important to analysts in machine learning, design acknowledgment, databases, insights, computerized reasoning, information securing for master frameworks, and information perception. The binding together objective of the KDD procedure is to concentrate learning from information with regards to substantial databases. It does this by utilizing information mining techniques (calculations) to separate (recognize) what is esteemed learning, as per the determinations of measures and edges, utilizing a database alongside any required preprocessing, subsampling, and changes of that database. A few people don't separate information mining from learning revelation while others see information mining as a basic stride during the time spent information disclosure. Here is the rundown of steps required in the information revelation prepare −
Information Cleaning: In this progression, the commotion and conflicting information is expelled. Information Integration: In this progression, different information sources are consolidated.
Information Selection: In this progression, information applicable to the investigation errand are recovered from the database. Information Transformation: In this progression, information is changed or solidified into structures suitable for mining by performing outline or total operations.
Information Mining: In this progression, canny techniques are connected keeping in mind the end goal to concentrate information designs.
Technology (IJRASET)
IJRASET: All Rights are Reserved
1546
Information Presentation: In this progression, learning is spoken to.
[image:3.612.84.525.147.290.2]You must know that data mining in also defined as a process of finding patterns from a vast amount of data through algorithms. Thus, the fourth step covers all the techniques of data mining.
Figure 1 KDD process
A. Artificial Networks
[image:3.612.138.474.413.511.2]These are non-linear productive models that learn through training. They resemble biological neuron structures in real life. Each neural unit is connected with many others, and links can enhance or inhibit the activation state of adjoining neural units. The goal of the neural network is to solve problems in the same way that the human brain would, although several neural networks are more abstract. Neural networks have been used to solve a wide variety of tasks, like computer vision and speech recognition, that are hard to solve using ordinary rule-based programming. Its theoretical properties include its capacity, convergence, generalisation and statistics.
Figure 2 Artificial Network
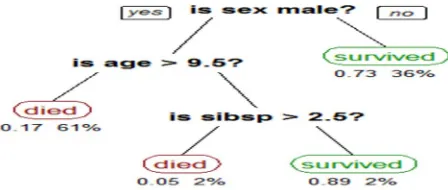
B. Decision Trees
These are tree-shaped structures that represent sets of decisions. These decisions generate rules for the classification of a dataset. Specific decision tree methods include Classification and Regression tree
[image:3.612.188.412.592.687.2]Technology (IJRASET)
IJRASET: All Rights are Reserved
1547
C. Classification Trees
When the predicted outcome is the class to which the data belongs.
D. Regression Tress
When the predicted output can be considered a real number.
E. Genetic Algorithms
Streamlining systems that utilization procedure, for example, hereditary blend, change, and characteristic choice in a plan in view of the ideas of advancement. Transformative calculations work by attempting to imitate regular evolution. [1] First, irregular arrangements of “standards” are determined to the preparation dataset, which attempt to sum up the information into formulas. The tenets are checked, and the ones that fit the information best are kept, the guidelines that don't fit the information are discarded. [3] The principles that were kept are then changed, and duplicated to make new rules. This procedure repeats as essential with a specific end goal to deliver decide that matches the dataset as nearly as possible. When this manages is gotten, it is then checked against the test dataset. If the administer still matches the information, then the lead is legitimate and is kept. If it doesn't coordinate the information, then it is disposed of and the procedure starts by choosing irregular guidelines again [2]
F. Nearest Neighbour Method
A procedure that orders each record in a dataset in light of a mix of the classes of the k record(s) most like it in a chronicled dataset (where k ³ 1). Once in a while it is known as the k-closest neighbor procedure. In example acknowledgment, the k-closest neighbors calculation (k-NN) is a non-parametric technique utilized for order and relapse. In both cases, the info comprises of the k nearest preparing cases in the component space [3]. The yield relies on upon whether k-NN is utilized for arrangement or relapse:
G. K-NN Arrangement
In k-NN arrangement the yield is class participation. A question is grouped by a larger part vote of its neighbors, with the protest being appointed to the class most normal among its k closest neighbors (k is a positive whole number, regularly little). On the off chance that k = 1, then the question is basically allocated to the class of that solitary closest neighbor.
H. K-NN Relapse
In k-NN Relapse, the yield is the property estimation for the protest. This esteem is the normal of the estimations of its k closest neighbors.5) Rule induction: The extraction of useful if-then rules from data based on statistical significance.
Once you start the process of mining you have to complete because you never know when the data may change. Some major rule paradigms are as follows:-
1) Association rule learning algorithms (e.g., Aggrawal)
2) Decision rule algorithms (e.g., Quinlan 1987)
3) Hypothesis testing algorithms (e.g., RULEX)
4) Horn clause induction
5) Version spaces
6) Rough set rules
7) Inductive Logic Programming
8) Boolean decomposition (Feldman)
II. APPLICATIONS
Technology (IJRASET)
IJRASET: All Rights are Reserved
1548
A. Some Fruitful Application Territories include
1) A pharmaceutical organization can break down its current deals drive movement and their outcomes to enhance focusing of high-esteem doctors and figure out which advertising exercises will have the best effect in the following couple of months. The information needs to incorporate contender advertise movement and additionally data about the neighbourhood human services frameworks. The outcomes can be disseminated to the business drive by means of a wide-territory arrange that empowers the agents to audit the proposals from the point of view of the key traits in the choice procedure. The continuous, dynamic investigation of the information stockroom permits best practices from all through the association to be connected in particular deals circumstances.
2) A Visa organization can use its incomprehensible distribution centre of client exchange information to recognize clients destined to be keen on another credit item. Utilizing a little test mailing, the traits of clients with a liking for the item can be distinguished. Late activities have shown more than a 20-overlay diminishes in expenses for focused mailing efforts over customary methodologies.
3) An enhanced transportation organization with a huge direct deals drive can apply information mining to recognize the best prospects for its administrations. Utilizing information mining to dissect its own client encounter, this organization can assemble a one of a kind division recognizing the characteristics of high-esteem prospects. Applying this division to a general business database, for example, those gave by Dun and Bradstreet can yield an organized rundown of prospects by district.
4) An extensive purchaser bundle merchandise organization can apply information mining to enhance its business procedure to retailers. Information from buyer boards, shipments, and contender movement can be connected to comprehend the explanations behind brand and store exchanging. Through this examination, the maker can choose limited time techniques that best achieve their objective client portions.
Each of these illustrations has a reasonable shared conviction. They use the information about clients verifiable in an information distribution centre to lessen costs and enhance the estimation of client connections. These associations can now concentrate their endeavors on the most essential (productive) clients and prospects, and configuration focused on showcasing procedures to best contact them.
III. TOOLSOFDATAMINING
A. WEKA
Weka is an accumulation of machine learning calculations for information mining errands. The calculations can either be connected straightforwardly to a dataset or called from your own particular Java code. Weka contains apparatuses for information pre-preparing, arrangement, relapse, bunching, affiliation guidelines, and representation. It is additionally appropriate for growing new machine learning plans. Weka bolsters a few standard information mining errands, all the more particularly, information pre-processing, and grouping, characterization, and relapse, perception, and highlight choice. The greater part of Weka's procedures are predicated on the suspicion that the information is accessible as one level record or connection, where every information point is portrayed by a settled number of characteristics (ordinarily, numeric or ostensible traits, yet some other quality sorts are likewise upheld). Weka gives access to SQL databases utilizing Java Database Connectivity and can handle the outcome returned by a database inquiry.
1) R-Programming Tool: This is written in C and FORTRAN, and allows the data miners to write scripts just like a programming language/platform. Hence, it is used to make statistical and analytical software for data mining. It supports graphical analysis, both linear and nonlinear modeling, classification, clustering and time-based data analysis.
2) Python based Orange and NTLK: Python is very popular due to ease of use and its powerful features. Orange is an open source tool that is written in Python with useful data analytic s, text analysis, and machine-learning features embedded in a visual programming interface. NTLK, also composed in Python, is a powerful language processing data mining tool, which consists of data mining, machine learning, and data scraping features that can easily be built up for customized needs.
Technology (IJRASET)
IJRASET: All Rights are Reserved
1549
more information you have about your gathering of people and industry, the better possibility of achievement you have. Utilizing supposition investigation devices permits you to assess the demeanours of your objective shoppers—states of mind that can represent the deciding moment your image's notoriety.
4) DTReg: The execution of the machine learning calculations has been contrasted and the execution of GMDH system utilizing
DTReg device. DTREG (https://www.dtreg.com/download) constructs arrangement and relapse choice trees, neural systems, bolster vector machine (SVM), GMDH polynomial systems, quality expression programs, K-Means grouping, discriminant investigation and calculated relapse models that depict information connections and can be utilized to foresee values for future perceptions. DTREG likewise has full support for time arrangement investigation. DTREG acknowledges a dataset containing of number of lines with a segment for every variable. One of the factors is the "objective variable" whose esteem is to be demonstrated and anticipated as an element of the "indicator factors". DTREG investigates the information and creates a model demonstrating how best to anticipate the estimations of the objective variable in light of estimations of the indicator variables.
IV. MOTIVATIONANDCHALLENGES
Data mining is the need of the hour for knowledge discovery process. Data Mining has benefited the market and retail industry. Marketing people can keep a track all the products whose sale was maximum and of the ones whose were minimum. It also helped them in campaigns. Moreover, retailers too had a record of their goods and thus can give discount on correct time to gain better profits. Not only the private sector, even the public sector has made good use of data mining. All the banks are using this process. It is because of this that they are able to keep track of the loans given and the percent by which it should be increased. Moreover, it has helped all the MNC’s in building up their databases. No matter it has been to great help to everyone, but it has had its backlogs. User is sometimes has no privacy with his data. Moreover, this brings doubt in our minds about the security of our data. Data mining no matter is a very successful technique but it is time consuming because finding out the required data from a bulk needs patience and time. This gives birth to a big fear in our hearts. What will we do if our data gets misused? What will you do if your database gets hacked? However, hacking data in data mining is not so easy but still there have been a few exceptions and the companies are working on these demerits. However, if you will not keep any loose ends, you can never be cheated or caught cheating. Every coin has two sides. But you have the right to choose your one.
REFERENCES
[1] Freitas, Alex A. "A Survey of Evolutionary Algorithms for Data Mining and Knowledge Discovery", Pontifícia Universidade Católica do Paraná, Retrieved on 2008-12-4.
[2] Jiawei Han, Micheline Kamber Data Mining: Concepts and Techniques (2006), Morgan Kaufmann, ISBN1-55860-901-6
[3] Altman, N. S. (1992). "An introduction to kernel and nearest-neighbor nonparametric regression". The American Statistician. 46 (3): 175– 185. doi:10.1080/00031305.1992.10475879.
[4] Brunk, C., Kelly, J., and Kohavi, R. MineSet: An Integrated System for Data Mining. In Proceedings of the The Third International Conference on Knowledge Discovery and Data Mining, August 1997. (Can be retrieved from http://robotics.stanford.edu/users/ronnyk/ronnyk-bib.html)
[5] Waikato ML Group. User Manual Weka: The Waikato Environment for Knowledge Analysis. Department of Computer Science, University of Waikato (New Zealand), June 1997. [4] Thearling, K. Data Mining and Database Marketing WWW Pages. http://www.santafe.edu/~kurt/dmvendors.shtml, 1998.
[6] Fayyad, U. Data Mining and Knowledge Discovery: Making Sense Out of Data. IEEE Expert, v. 11, no. 5, pp. 20-25, October 1996.
[7] Survey of classification techniques in data mining in Proceedings of the International Multi Conference of Engineers and Computer Scientists 2009 Vol I IMECS 2009, March 18 - 20, 2009, Hong Kong-classification