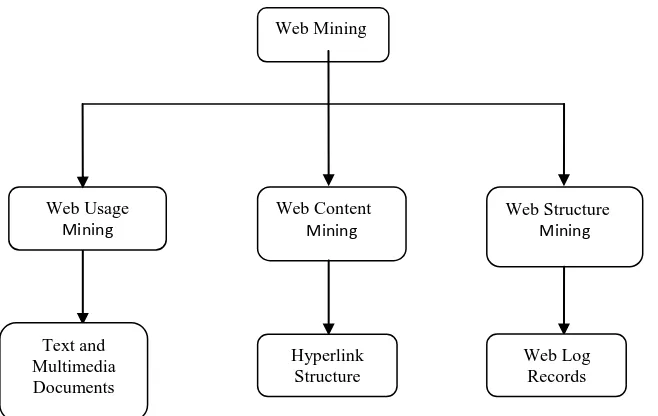
A Survey: Techniques of an Efficient Search Annotation based on Web Content Mining
Full text
Figure
Related documents
Product range Axially split case pumps Vertical turbine pumps Multi-pump pressure boosting systems with speed controlled pumps or base-load pump. Series Wilo-SCP Series VMF, CNE,
Student Academic Advisement and Admission with WebAdvisor Registration, Same Day Payment, November 30 - January 18, Student Services
Multiculturalisme Language - talk about factors facilitating integration; discuss which culture immigrants should show loyalty to Grammar - use conjunctions Skills -
Aggressive interactions and competition for shelter between a recently introduced and an established invasive crayfish: Orconectes immunis vs... First evidence for an
Informed by their castles of due process, institutions have historically implemented remedies
Different astronomical practices from Antarctica are studied like infrared astronomy, Sub millimeter wave astronomy, Neutrino detection etc.. In this review work the
We compared our results with those obtained from four different scheduling techniques commonly used in high-level synthesis, namely, the GA scheduling , ALAP scheduling
