Journal of Computing and Security
April 2016, Volume 3, Number 2 (pp. 95–110)
http://www.jcomsec.org
A Hybrid Method based on Statistical Features and Packet Content
Analysis to Identify Major Network Tunneling Protocols
Keihan Kazemi
a, Ali Fanian
a,∗
aDepartment of Electrical and Computer Engineering, Isfahan University of Technology (IUT), Isfahan, Iran.
A R T I C L E I N F O.
Article history:
Received:20 April 2016
Revised:16 June 2017
Accepted:31 August 2017
Published Online:26 November 2017
Keywords:
Traffic Detection, Tunneling Protocols, Packet Payload Analysis, Semi-Supervised Clustering, Active Learning.
A B S T R A C T
Network traffic identification is an essential component for effective network analysis and management. Signature-based and machine learning techniques are the two most important methods in network traffic analysis. Due to the strengths and weaknesses of these two approaches, their combination can strengthen them and remove the weaknesses of each in detection process. In this article, a hybrid method is introduced, to identify major network tunneling protocols. This method can detect the well-known tunneling protocols by combining signature-based methods and statistical analysis techniques through a clustering algorithm. In this proposed method, the clustering process is refined by the feedback of signature-base method. Since, in semi-supervised clustering, it is important to gain most informative data to improve the clustering performance, in the proposed clustering method, a new active learning approach is introduced for selecting informative constraints. In this hybrid method, four tunneling protocols (L2TP, PPTP, IPsec and OpenVPN) are applied. The obtained results indicate that this proposed hybrid method significantly increases accuracy and cluster purity, and these protocols are identified with high accuracy and low processing cost.
c
2016 JComSec. All rights reserved.
1
Introduction
Security and privacy are the important issues in the computer networks. Tunneling protocols have a great contribution in maintaining anonymity and safe trans-action while working with the Internet [1]. These pro-tocols constitute the major means to securely trans-mit information between both ends of a given channel. These types of protocols are applied to establish a vate network over a public network named virtual pri-vate network (VPN). With the extensive use of VPN, a variety of tunneling protocols are on emergence. In
∗ Corresponding author.
Email addresses:keihan [email protected](K. Kazemi), [email protected](A. Fanian)
ISSN: 2322-4460 c2016 JComSec. All rights reserved.
this article, four popular tunneling protocols (L2TP, PPTP, IPsec and OpenVPN) are discussed, with each being appropriate for a different special tunneling tar-get [2].
man-agement.
Traffic identification techniques are divided into three main categories, including: port-based, signature-based and machine learning methods [4]. A port-based technique is the simplest method based on simple matching of ports with the well-known port list. Since, some applications select the ports randomly or some applications apply the well-known port numbers for their communication, this method is not appropri-ate [5]. A detailed analysis of the classification based on the port numbers was run by [6], where, 30-70% of the data were not classified properly. According to [7] the port-based analysis is unable to get accuracy higher than 70% in the network traffic detection.
Signature-based methods identify the applications by matching the traffic payload with the application signatures [8]. This technique is named Deep Packet Inspection (DPI). DPI techniques identify network ap-plications with high accuracy [9]. While this approach can be accurate, its drawback is the high cost of com-puting. In addition, access to the contents of the pack-ets is inconsistent with the legal issues related to the the users privacy. DPI is not practical for online anal-ysis in high rate links, because payload packet traces are too long to store and match in these networks [4]. Machine learning (ML) techniques apply statistical features of the traffic like maximum and minimum packet lengths in each direction, flow durations, inter-packet arrival times, etc. [10]. Machine learning tech-niques are divided into three categories: supervised learning, unsupervised learning and semi-supervised learning [11]. Supervised learning tries to find out a model from labeled training data. This model can be used for specifying the class label of new instances. In an unsupervised learning, training data are unlabeled and these algorithms try to learn a model that reflects the statistical structure and hidden patterns of un-labeled training data. In most domains, due to high cost in labeling, there exist a small amount of labeled data and many unlabeled data. Since, having labels for all samples is difficult, costly and time-consuming, in the recent years the focus of researchers is mostly on semi-supervised learning [12]. Semi-supervised learn-ing can go on with a large number of unlabeled data and small number of side information. Side informa-tion may take the form of labeled data or pairwise constraints between pairs of data objects. These algo-rithms are faster than supervised learning algoalgo-rithms. In addition, semi-supervised algorithms can identify new applications and detect changes in the behavior of applications that have already been identified.
Machine learning methods are light weight methods in traffic identification. Even if encryption is applied, statistical features are measurable, indicating that
these methods are applicable in encrypted traffic iden-tification. Although, machine learning techniques have high performance, they are not without their limita-tions in traffic detection. For example, the statistical features of traffics are not steady in every network and in all the time. When a test dataset is collected at the same point of a train dataset, the accuracy assessed, might not be comparable with the test dataset and train dataset collected at different time and place. In [13] by applying the same algorithm on two datasets captured from two different networks, different accu-racy was obtained. Therefore, better accuaccu-racy of an algorithm in one network, does not necessarily guar-antee the accuracy of this algorithm in other networks. Consequently, for having acceptable accuracy in ma-chine learning methods, training and testing traffic datasets should be captured from the same network segment, at the same time and from the same network geographic level [14].
Machine learning-based approach is unable to rec-ognize different applications that have similar statisti-cal features (e.g., different application based on P2P). These methods can be vulnerable to mistreatment of data exchange. For example, if the uniform sized pack-ets are sent at fixed time intervals, this mistreatment will reduce the accuracy of the traffic detection system. Recently, new methods are designed that change the statistical features, in a sense that one class of traffic appears as the other class. In [15], by using convex op-timization, features of one application are changed to become similar to another application. Moreover, the behavior of some applications like tunneling is com-plex. These applications can tunnel different protocols and the traffic behavior of tunneling applications is affected by the protocol inside the tunnel, so the statis-tical features cannot classify them accurately. These methods usually have lower accuracy for the special traffic classification and they cannot model all traffics.
April 2016, Volume 3, Number 2 (pp. 95–110) 97
based on active learning framework are selected and design query to be asked from LPI model. Finally, the obtained results of the clustering are refined based on the answer received from LPI method. In summary, the proposed method has the following properties.
(1) A hybrid method, which is a combination of machine learning and signature-based methods. (2) Fast and accurate DPI model, named LPI, to
assist the clustering process.
(3) An active learning framework proposed for se-lecting instances with the highest information rate. The objective is improving clustering per-formance with as little supervised data as possi-ble.
The results of these experiments indicate that the proposed approach is accurate and robust to encrypted traffic identification and overcome the problems caused by adopting signature-based or machine learning-based methods separately.
The remainder of this paper is organized as follows. Section 2 discusses related work. The proposed frame-work is introduced in Section 3 and the experimental evaluations are presented in Section4. Finally, Sec-tion 5 gives conclusion and future work.
2
Related Works
As mentioned above, the proposed method is a hybrid method includes clustering and LPI, and a new ap-proach in active learning introduced in its clustering process. Therefore, the most important related works in point of the author’s view that are based on ML or DPI methods will be discussed in this section. 2.1 Semi-Supervised Clustering
Traffic identification based on semi-supervised cluster-ing, includes two general approaches. Semi-supervised algorithms which use only a small amount of labeled data with a large amount of unlabeled data and semi-supervised algorithms which use constraints with un-labeled data. A semi-supervised approach was intro-duced in [13] that applied both labeled and unla-beled data. In [17], DBSCAN clustering was applied in semi-supervised algorithm based on composite fea-ture set. In this work, the feafea-tures were a combination of payload-based and statistical traffic features which were applied for measuring similarity between data in the clustering process. In recent work [18], a semi-supervised method was proposed based on data grav-itation theory [19] and the further division of recog-nition space [20]. Data gravitation-based clustering, use the concept of universal gravitation of Newton in clustering. Further division of recognition space
im-proves the classification accuracy by extending and further dividing the recognition space. In mentioned semi-supervised methods, labeled data were not in-volved in the clustering process. Labeled data were only applied to map the clusters to the application after clustering process
Another type of algorithms, apply constraints in-stead of labeled data and these constraints will assist the clustering process for improving clusters purity. Constraints include similar or dissimilar pairs. In this context of clustering, there are a few works in net-work traffic identification. A constrained clustering approach was proposed in [21]. This work provided a comparison of constrained clustering algorithms, in-cluding: MPCK-Means [22], COPK-Means [23] and LCVQE [24]. COPK-Means achieved best results in all experiments. In the similar work Set-Based Con-strained K-Means was introduced, which forced hard satisfaction of the constraints in K-Means [25]. In these works, active learning was not applied in constraints selection, while in some cases, if the constraints are not chosen properly, may cause to reduce the clustering accuracy.
2.2 Hybrid Methods
The proposed approach provided low overhead and achieved flow and byte accuracy of 97.10 and 97.06%. 2.3 Payload-Based Methods
DPI is the most used method in network traffic iden-tification. Although several payload and statistical based systems, including: snort [29], tie [30] and tstat [31] exist, but these methods cannot identify tunnel-ing traffic. These traffic detection systems inspect the content of IP packets independently of each other. However, these schemes can defrag the fragmented packet for inspection, but they cannot reconstruct the segment of UDP or TCP protocol for checking signatures of an application which split a segment to different IP packets. Since, to establish a tunneling protocol, different small IP packets must be transmit-ted in the negotiation phase, these schemes cannot detect them. Another, signature-based tool in traffic detection is nDPI, which is forked from OpenDPI [32]. This tool supports more than 100 protocols [33], but it does not provide the best performance and results even for plain flows; for example, in [34] it was shown that nDPI leaves SMTP-PLAIN flows unclassified. Although nDPI is able to recognize some well-known tunneling protocols (PPTP, IPsec, OpenVPN, except L2TP), it also gives a very significant number of mis-classifications. According to nDPI source code, this tool uses a combination of payload signatures, payload size and port numbers to determine the application protocol for a given traffic flow. For example, to detect OpenVPN flows, at first the port number of flows is checked. If these numbers are one of the 443 or 1194 numbers, the rest of signature are checked. So if flows use other port numbers, nDPI cannot detect Open-VPN flows. On the other hand, there is no TCP or IP payload re-assembly, so there is no possibility to de-tect a signature split into multiple TCP segments / IP packets [33]. In LPI method, data packets according to the state diagram of tunneling protocols are placed together effectively, so that if the specification of a tunneling protocol is found, LPI method can detect it [16].
3
The Proposed Hybrid Framework
for Tunneling Protocols
Identifica-tion
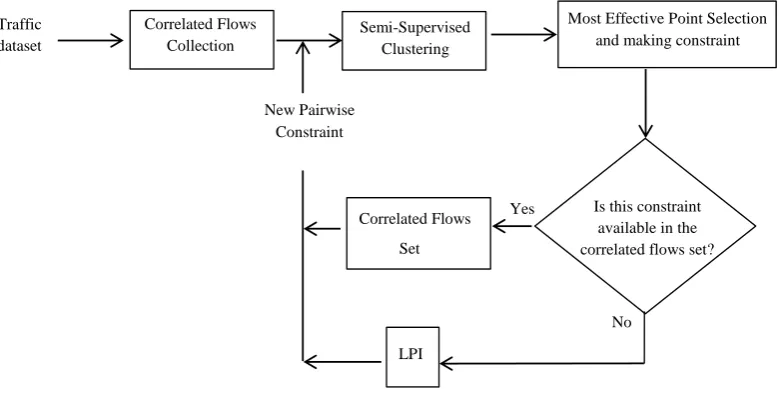
The flowchart of the hybrid framework is shown in Figure 1. As observed in Figure 1, both the signature and statistical analysis are utilized in the proposed model. The method is constructed in several phases. In the first phase, the correlated flows in the form of pairwise must-link constraints are collected without any manual inspection. In this phase, two types of
pairwise constraints, including: must-link and cannot-link constraints are considered. Must-cannot-link constraints specify that two instances must be placed in the same cluster and cannot-link constraints specify that two instances must not be placed in the same cluster. In the network traffic analysis, side information in the form of pairwise must-link constraints are more applicable than labeled data, that is, in the network, it is easier to specify whether the two flows belong to the same protocol or not, instead of specifying their labels. For example, given the two TCP flows with the same host address and the same port number in a specified time interval, it can be deduced that these two flows belong to the same protocol. These flows with their constraints make the correlated flows list. Therefore, before the clustering phase, a number of constraints are achieved without any inspection of flows; while, the number of these flows may be low.
In the second phase, the constrained clustering is performed. In constrained clustering, there is no information about data labels, and only must-link and cannot-link constraints between data are avail-able. These sets of constraints assist the constrained clustering algorithm to find the appropriate clusters, which meet the specified must-link and cannot-link constraints.
In the third phase, in order to improve clustering performance, some instances are selected to design query to be asked from the LPI model or from the correlated flows set. To accomplish this task, the set of correlated flows achieved before the clustering is checked. If none of these constraints exist in this set, the query is asked from LPI, that is, instead of asking the labels of the data, the asked question is formed as: Do instances x and y belong to the same proto-col or not? Information obtained from this query is the in{must-link, cannot-link}form. In LPI, by ex-amining the content of data packets, new constraint is designed and added to the pairwise constraint list. If the query is selected inappropriately or randomly, the return answer reduces the clustering algorithm performance [35]. To overcome this drawback, in this proposed method an active framework is presented to select those unlabeled examples that supply the most information to the learner.
relation-April 2016, Volume 3, Number 2 (pp. 95–110) 99
Is this constraint available in the correlated flows set? Correlated Flows
Correlated Flows Collection Traffic
dataset
Semi-Supervised Clustering
Most Effective Point Selection and making constraint
LPI New Pairwise
Constraint
No Yes
Set
Figure 1. The Framework of the Proposed Hybrid Method for Tunneling Protocols Identification
ship between the samples from the experts or other information sources. Since the samples are selected properly, a small number of samples are required to learn a concept. Through active learning, maximum information is gained by a number of questions.
Therefore, in each clustering process iteration, the most uncertain instance is selected, based on active learning criterion and current clustering. It will be shown that the most uncertain instance is the point with the highest information rate. The proposed active learning framework is named Most Effective Points (MEP). In the last phase, the clustering results are refined based on new pairwise set. This process contin-ues until an acceptable solution is reached or a certain number of questions are asked.
This proposed model consists of two stages named training and testing stage. All steps are run in the training stage. In the test stage, only the distance between the data and the center of the created clus-ters are measured and accordingly the test data are assigned to the clusters. Consequently, the proposed method can be applied in tunneling traffic identifica-tion for online usage in high-speed networks.
3.1 Semi-supervised encrypted traffic clus-tering with active learning
The improvement on semi-supervised clustering is mainly due to incorporation of the supervised data. As mentioned before, one of the most studied types of supervised data is pairwise constraints that include must-link and cannot-link constraints. If no cluster-ing solution exists which satisfies the specified con-straints, some constrained clustering algorithms like COPK-means abort. These algorithms try to satisfy
all constraints, indicating that, if there are noisy con-straints, these algorithms result are not reliable. An-other kind of constrained clustering algorithms like MPCK-means and PCK-means, try to minimize the constraint violation. In this proposed method, the LPI results assist the clustering process. So, the con-straints are not applied directly to identify the flows; they are a partial guide in clustering algorithms.
The proposed method uses Mmeans and PCK-means algorithms [22]. These algorithms are modified version of K-Means algorithm, which incorporate soft constraint satisfaction. They introduce an associated cost for violating each constraint. The algorithm min-imizes a combined objective function defined as the sum of the total squared distances between the data instances and their cluster centers and the penalty cost incurred by violating any pairwise constraints. It also performs a constraint-seeded initialization of cluster centers. These algorithms findK partitions
C={c1, . . . , ck}, whereok is the centroid ofck such
that objective function is minimized. These algorithms change the sum of squared errors function of K-means to include both sum of the total squared distances between the data and their cluster centers and any associated constraint violations.
Must-link (ML) and cannot-link (CL) constraints have the following properties:
• (xi, xj)∈M L\CL⇒(xj, xi)∈M L\CL
• (xi, xj)∈M L∧(xj, xr)∈M L⇒(xi, xr)∈M L
• (xi, xj)∈CL∧(xi, xr)∈M L⇒(xj, xr)∈CL
and all of them are connected by must-link constraint. The relationship between the different neighborhoods, belonged to the different protocols, is cannot-link con-straint. The neighborhood is interpreted into a set of labeled data, because data in different neighborhoods have different protocol labels.
In the most constrained clustering, pairwise con-straints already exist or two instances are randomly selected and their relationship (must-link or cannot-link) is asked, then according to these constraints, clus-tering algorithms separate the data. Random selection of the constraints may reduce the algorithm efficiency. Figure 2 shows a random selection of constraints.
In Figure 2, constrained clustering is run on diff-300 dataset [37]. Clustering Performance is represented by F1. In this figure, case (a) shows true labels of the data. In (b), simple K-means algorithm is run, without any constraints. In (c) and (d) constrained clustering is run with 100 random constraints. It is clear that, in (c), the K-means algorithm efficiency is increased. On the contrary, in (d), 100 random constraints reduce K-means algorithm performance. So, getting the most valuable information becomes an essential subject. It is not possible to study all network traffic and select the most effective ones. A solution to this problem is letting the clustering approach has an active contribution in the process and the points are chosen consciously. These actively selected points contain more information to assist the clustering process. Since, constraints selection is important, in the proposed hybrid method active learning is applied.
K-means is a greedy algorithm and selects the first centroid randomly, so different results are possible in different runs. To obtain the best result, k-means must be run several times. Selection of good initial centroids affects the k-means quality significantly [38]. In order to improve clustering performance, the same principle in the pairwise case is followed: In the initialization step of clustering, explorer algorithm introduced in [39] is applied in the proposed method. This algorithm uses farthest-first traversal properties [40]. In explore, the first point is selected randomly and placed in the first neighborhood. The point that is farthest away from all neighborhoods is selected and queried against the existing neighborhoods until a must-link is found. Then the point assigned to the correct cluster. If there exist a cannot-link constraint against all neighbor-hoods, a new neighborhood is created with this point. This work continues until queries are allowed or de-sired separate neighborhoods are found.
Election of the number of neighborhoods (clusters) is a crucial step. Experiments have shown that the number of clusters should be as close as possible to the
actual number of traffic types subjected to the anal-ysis [41]. The explore algorithm result are neighbor-hoods given to the clustering algorithm as the initial centroids.
The algorithm starts by building neighborhoods through the explore algorithm. The constraint list contains ML and CL, is updated with the neighbor-hood’s values. Constrained clustering algorithm by applying the constraint list generates solutionC. The found neighborhoods through explore algorithm may not be robust as it involves very few instances. In or-der to have bigger neighborhoods, in each iteration, one instance is added to the neighborhoods. For bet-ter data clusbet-tering, these instances are selected based on active learning algorithm and current clustering solution. To reduce the number of asked questions, the neighborhoods are sorted based on the possibil-ity ofx∗belonging to them, in descending order and are asked against thex∗. Instancex∗is added to the neighborhood must-linked to it. The neighborhood that includesx∗ and the constraint list is updated. This means that, a must-link constraints withx∗and all data that exist in this neighborhood and cannot-link constraints betweenx∗and all data exist in other neighborhoods are added to constraint list. In each iteration new neighborhood’s values are given to the algorithm as initial cluster centroid. This process con-tinues until the queries are finished.
Line 4 of the semi-supervised algorithm refers to the Most Effective Points algorithm (MEP). This algo-rithm selects the instance that knowing its neighbor-hood assists greatly in the clustering process. Selecting an inappropriate instance causes to have unnecessary or repeated constraints that may affect badly on tering results [42]. Through MEP algorithm, best clus-ters are found with minimum queries. So the subjec-tive in this section is finding the most effecsubjec-tive points. In the remaining part of this section, the proposed method for selecting these instances is described.
There exist the current clustering assignmentC=
{c1, c2, . . . , cn} with centroid O = {o1, o2, . . . , on},
and a set of neighborhoodsN. Data are bounded to the cluster that the distance between the data and the cluster centroids is minimized. For each instance
x, possibility of x belonging to the all clusters C
is computed as{p1, p2, . . . , pn}. The possibility ofx
belonging to the clusterci is computed as: p(x∈ci) = Pndist(x, oi)
j=1dist(x, oj)
(1)
In Equation (1),dist(x, oi) denotes the distance
be-tweenxandoi. The instance with close possibility is
April 2016, Volume 3, Number 2 (pp. 95–110) 101
Active Query Selection for Semi-supervised Clustering
Pavan Kumar Mallapragada, Rong Jin and Anil K. Jain
Department of Computer Science and Engineering
Michigan State University, East Lansing, MI 48823
{
pavanm,rongjin,jain
}
@cse.msu.edu
Abstract
Semi-supervised clustering allows a user to specify
available prior knowledge about the data to improve
the clustering performance. A common way to express
this information is in the form of pair-wise constraints.
A number of studies have shown that, in general, these
constraints improve the resulting data partition.
How-ever, the choice of constraints is critical since
improp-erly chosen constraints might actually degrade the
clus-tering performance. We focus on constraint (also known
as query) selection for improving the performance of
semi-supervised clustering algorithms. We present an
active query selection mechanism, where the queries
are selected using a min-max criterion. Experimental
results on a variety of datasets, using MPCK-means as
the underlying semi-clustering algorithm, demonstrate
the superior performance of the proposed query
selec-tion procedure.
1
Introduction
The goal of clustering or unsupervised learning is to
partition
n
objects represented as points in
d
dimen-sions. It is well-known that this problem is very
dif-ficult and considered to be ill-posed [7]. Any additional
user-specified information should help in guiding the
clustering algorithm towards a better solution.
Semi-supervised clustering allows incorporation of
“side-information” into the clustering algorithm, which is
usually specified as constraints
1
of the form: should the
u
-th and the
v
-th objects in the data be put in the same
cluster? The answer to this query can either be “yes” (a
must-link query) or “no” (a must-not link query). Fig. 1
shows how introducing 100 randomly selected pairwise
1
The constraints are referred to as the queries in active learning
terminology.
This research was partially
supported by ONR Grant No.
N000140710225
constraints improves the performance (Fig. 1(c)) of
K
-means clustering (Fig. 1(b)). Semi-supervised
cluster-−0.3 −0.2 −0.1 0 0.1 0.2 0.3 0.4 −0.4 −0.3 −0.2 −0.1 0 0.1 0.2 0.3 0.4 True Labels
−0.3 −0.2 −0.1 0 0.1 0.2 0.3 0.4 −0.4 −0.3 −0.2 −0.1 0 0.1 0.2 0.3 0.4
No Constraints 0.61365
(a) True Labels
(b)
F
1
= 0.56
−0.3 −0.2 −0.1 0 0.1 0.2 0.3 0.4 −0.4 −0.3 −0.2 −0.1 0 0.1 0.2 0.3 0.4
Random Constraints 0.67165
−0.3 −0.2 −0.1 0 0.1 0.2 0.3 0.4 −0.4 −0.3 −0.2 −0.1 0 0.1 0.2 0.3 0.4
Random Constraints 0.51218
(c)
F
1
= 0.67
(d)
F
1
= 0.51
Figure 1. Illustration of constraint-based
clustering. (a) 2-D projection of the
Diff-300 dataset [2] using PCA, with true
la-bels (b)
K
-means Clustering (
K
= 3
)
with-out any constraints, (c) & (d) two different
clusterings with 100 pairwise constraints
selected randomly.
F
1
statistic [1]
indi-cates the clustering quality.
ing algorithms focus on how to utilize the constraints
effectively to infer the cluster labels. However, the
con-straints may not be always available a priori, but an
or-acle (user) may be available to provide the constraints,
as needed by the algorithm. This scenario, where the
system queries the oracle to obtain information relevant
to learning is called active learning [5]. In an active
learning framework, one aims to obtain a better
parti-tion of the data with minimal number of queries.
David-son et al. [4] and Wagstaff [10] show that when queries
are not selected properly, the semi-supervised learning
1
(a) True Labels.
Active Query Selection for Semi-supervised Clustering
Pavan Kumar Mallapragada, Rong Jin and Anil K. Jain
Department of Computer Science and Engineering
Michigan State University, East Lansing, MI 48823
{
pavanm,rongjin,jain
}
@cse.msu.edu
Abstract
Semi-supervised clustering allows a user to specify
available prior knowledge about the data to improve
the clustering performance. A common way to express
this information is in the form of pair-wise constraints.
A number of studies have shown that, in general, these
constraints improve the resulting data partition.
How-ever, the choice of constraints is critical since
improp-erly chosen constraints might actually degrade the
clus-tering performance. We focus on constraint (also known
as query) selection for improving the performance of
semi-supervised clustering algorithms. We present an
active query selection mechanism, where the queries
are selected using a min-max criterion. Experimental
results on a variety of datasets, using MPCK-means as
the underlying semi-clustering algorithm, demonstrate
the superior performance of the proposed query
selec-tion procedure.
1
Introduction
The goal of clustering or unsupervised learning is to
partition
n
objects represented as points in
d
dimen-sions. It is well-known that this problem is very
dif-ficult and considered to be ill-posed [7]. Any additional
user-specified information should help in guiding the
clustering algorithm towards a better solution.
Semi-supervised clustering allows incorporation of
“side-information” into the clustering algorithm, which is
usually specified as constraints
1
of the form: should the
u
-th and the
v
-th objects in the data be put in the same
cluster? The answer to this query can either be “yes” (a
must-link query) or “no” (a must-not link query). Fig. 1
shows how introducing 100 randomly selected pairwise
1
The constraints are referred to as the queries in active learning
terminology.
This research was partially
supported by ONR Grant No.
N000140710225
constraints improves the performance (Fig. 1(c)) of
K
-means clustering (Fig. 1(b)). Semi-supervised
cluster-−0.3 −0.2 −0.1 0 0.1 0.2 0.3 0.4 −0.4 −0.3 −0.2 −0.1 0 0.1 0.2 0.3 0.4 True Labels
−0.3 −0.2 −0.1 0 0.1 0.2 0.3 0.4 −0.4 −0.3 −0.2 −0.1 0 0.1 0.2 0.3 0.4
No Constraints 0.61365
(a) True Labels
(b)
F
1
= 0.56
−0.3 −0.2 −0.1 0 0.1 0.2 0.3 0.4 −0.4 −0.3 −0.2 −0.1 0 0.1 0.2 0.3 0.4
Random Constraints 0.67165
−0.3 −0.2 −0.1 0 0.1 0.2 0.3 0.4 −0.4 −0.3 −0.2 −0.1 0 0.1 0.2 0.3 0.4
Random Constraints 0.51218
(c)
F
1
= 0.67
(d)
F
1
= 0.51
Figure 1. Illustration of constraint-based
clustering. (a) 2-D projection of the
Diff-300 dataset [2] using PCA, with true
la-bels (b)
K
-means Clustering (
K
= 3
)
with-out any constraints, (c) & (d) two different
clusterings with 100 pairwise constraints
selected randomly.
F
1
statistic [1]
indi-cates the clustering quality.
ing algorithms focus on how to utilize the constraints
effectively to infer the cluster labels. However, the
con-straints may not be always available a priori, but an
or-acle (user) may be available to provide the constraints,
as needed by the algorithm. This scenario, where the
system queries the oracle to obtain information relevant
to learning is called active learning [5]. In an active
learning framework, one aims to obtain a better
parti-tion of the data with minimal number of queries.
David-son et al. [4] and Wagstaff [10] show that when queries
are not selected properly, the semi-supervised learning
1
(b)F1= 0.56
Active Query Selection for Semi-supervised Clustering
Pavan Kumar Mallapragada, Rong Jin and Anil K. Jain
Department of Computer Science and Engineering
Michigan State University, East Lansing, MI 48823
{
pavanm,rongjin,jain
}
@cse.msu.edu
Abstract
Semi-supervised clustering allows a user to specify
available prior knowledge about the data to improve
the clustering performance. A common way to express
this information is in the form of pair-wise constraints.
A number of studies have shown that, in general, these
constraints improve the resulting data partition.
How-ever, the choice of constraints is critical since
improp-erly chosen constraints might actually degrade the
clus-tering performance. We focus on constraint (also known
as query) selection for improving the performance of
semi-supervised clustering algorithms. We present an
active query selection mechanism, where the queries
are selected using a min-max criterion. Experimental
results on a variety of datasets, using MPCK-means as
the underlying semi-clustering algorithm, demonstrate
the superior performance of the proposed query
selec-tion procedure.
1
Introduction
The goal of clustering or unsupervised learning is to
partition
n
objects represented as points in
d
dimen-sions. It is well-known that this problem is very
dif-ficult and considered to be ill-posed [7]. Any additional
user-specified information should help in guiding the
clustering algorithm towards a better solution.
Semi-supervised clustering allows incorporation of
“side-information” into the clustering algorithm, which is
usually specified as constraints
1
of the form: should the
u
-th and the
v
-th objects in the data be put in the same
cluster? The answer to this query can either be “yes” (a
must-link query) or “no” (a must-not link query). Fig. 1
shows how introducing 100 randomly selected pairwise
1
The constraints are referred to as the queries in active learning
terminology.
This research was partially
supported by ONR Grant No.
N000140710225
constraints improves the performance (Fig. 1(c)) of
K
-means clustering (Fig. 1(b)). Semi-supervised
cluster-−0.3 −0.2 −0.1 0 0.1 0.2 0.3 0.4 −0.4 −0.3 −0.2 −0.1 0 0.1 0.2 0.3 0.4 True Labels
−0.3 −0.2 −0.1 0 0.1 0.2 0.3 0.4 −0.4 −0.3 −0.2 −0.1 0 0.1 0.2 0.3 0.4
No Constraints 0.61365
(a) True Labels
(b)
F
1
= 0.56
−0.3 −0.2 −0.1 0 0.1 0.2 0.3 0.4 −0.4 −0.3 −0.2 −0.1 0 0.1 0.2 0.3 0.4
Random Constraints 0.67165
−0.3 −0.2 −0.1 0 0.1 0.2 0.3 0.4 −0.4 −0.3 −0.2 −0.1 0 0.1 0.2 0.3 0.4
Random Constraints 0.51218
(c)
F
1
= 0.67
(d)
F
1
= 0.51
Figure 1. Illustration of constraint-based
clustering. (a) 2-D projection of the
Diff-300 dataset [2] using PCA, with true
la-bels (b)
K
-means Clustering (
K
= 3
)
with-out any constraints, (c) & (d) two different
clusterings with 100 pairwise constraints
selected randomly.
F
1
statistic [1]
indi-cates the clustering quality.
ing algorithms focus on how to utilize the constraints
effectively to infer the cluster labels. However, the
con-straints may not be always available a priori, but an
or-acle (user) may be available to provide the constraints,
as needed by the algorithm. This scenario, where the
system queries the oracle to obtain information relevant
to learning is called active learning [5]. In an active
learning framework, one aims to obtain a better
parti-tion of the data with minimal number of queries.
David-son et al. [4] and Wagstaff [10] show that when queries
are not selected properly, the semi-supervised learning
1
(c)F1= 0.67
Active Query Selection for Semi-supervised Clustering
Pavan Kumar Mallapragada, Rong Jin and Anil K. Jain
Department of Computer Science and Engineering
Michigan State University, East Lansing, MI 48823
{
pavanm,rongjin,jain
}
@cse.msu.edu
Abstract
Semi-supervised clustering allows a user to specify
available prior knowledge about the data to improve
the clustering performance. A common way to express
this information is in the form of pair-wise constraints.
A number of studies have shown that, in general, these
constraints improve the resulting data partition.
How-ever, the choice of constraints is critical since
improp-erly chosen constraints might actually degrade the
clus-tering performance. We focus on constraint (also known
as query) selection for improving the performance of
semi-supervised clustering algorithms. We present an
active query selection mechanism, where the queries
are selected using a min-max criterion. Experimental
results on a variety of datasets, using MPCK-means as
the underlying semi-clustering algorithm, demonstrate
the superior performance of the proposed query
selec-tion procedure.
1
Introduction
The goal of clustering or unsupervised learning is to
partition
n
objects represented as points in
d
dimen-sions. It is well-known that this problem is very
dif-ficult and considered to be ill-posed [7]. Any additional
user-specified information should help in guiding the
clustering algorithm towards a better solution.
Semi-supervised clustering allows incorporation of
“side-information” into the clustering algorithm, which is
usually specified as constraints
1
of the form: should the
u
-th and the
v
-th objects in the data be put in the same
cluster? The answer to this query can either be “yes” (a
must-link query) or “no” (a must-not link query). Fig. 1
shows how introducing 100 randomly selected pairwise
1
The constraints are referred to as the queries in active learning
terminology.
This research was partially
supported by ONR Grant No.
N000140710225
constraints improves the performance (Fig. 1(c)) of
K
-means clustering (Fig. 1(b)). Semi-supervised
cluster-−0.3 −0.2 −0.1 0 0.1 0.2 0.3 0.4 −0.4 −0.3 −0.2 −0.1 0 0.1 0.2 0.3 0.4 True Labels
−0.3 −0.2 −0.1 0 0.1 0.2 0.3 0.4 −0.4 −0.3 −0.2 −0.1 0 0.1 0.2 0.3 0.4
No Constraints 0.61365
(a) True Labels
(b)
F
1
= 0.56
−0.3 −0.2 −0.1 0 0.1 0.2 0.3 0.4 −0.4 −0.3 −0.2 −0.1 0 0.1 0.2 0.3 0.4
Random Constraints 0.67165
−0.3 −0.2 −0.1 0 0.1 0.2 0.3 0.4 −0.4 −0.3 −0.2 −0.1 0 0.1 0.2 0.3 0.4
Random Constraints 0.51218
(c)
F
1
= 0.67
(d)
F
1
= 0.51
Figure 1. Illustration of constraint-based
clustering. (a) 2-D projection of the
Diff-300 dataset [2] using PCA, with true
la-bels (b)
K
-means Clustering (
K
= 3
)
with-out any constraints, (c) & (d) two different
clusterings with 100 pairwise constraints
selected randomly.
F
1
statistic [1]
indi-cates the clustering quality.
ing algorithms focus on how to utilize the constraints
effectively to infer the cluster labels. However, the
con-straints may not be always available a priori, but an
or-acle (user) may be available to provide the constraints,
as needed by the algorithm. This scenario, where the
system queries the oracle to obtain information relevant
to learning is called active learning [5]. In an active
learning framework, one aims to obtain a better
parti-tion of the data with minimal number of queries.
David-son et al. [4] and Wagstaff [10] show that when queries
are not selected properly, the semi-supervised learning
1
(d)F1= 0.51
Figure 2. Clustering With Random Selection of Constraints [35]
Algorithm 1Semi-Supervised Clustering Algorithm
Input: Set of dataX, set of Must-link constraints:M L, set of Cannot-link constraint:CL, number of clusters
K, and the total number of queriesQ. Output: Clustering DatasetX.
1: CreateKneighborhoodsN through explore algorithm and update the constraint list 2: whilequeries are alloweddo
3: C= constrained clustering algorithm (X,M L,CL) 4: x∗= Most Effective Point (C,X)
5: for eachNi∈N in decreasing order ofp(x∗∈Ni)do
6: Queryx∗about any (xi∈Ni) from correlated flow list or from LPI 7: if (x∗, xi)∈M Lthen
8: Addxi toNi
9: Update constraint list
10: Break
other, bounding the instance to the correct clusters is so difficult. The instance uncertainty is computed through a measure such as entropy. Entropy is an uncertainty measure. It is the expected amount of information gained, with having a probability distri-bution. In general,entropy(x) is maximized when all
piare equal and minimized when one of thepi’s is 1 and all others are zero. Entropy is computed by the Equation (2):
Entropy(x) =−
n
X
i=1
p(x∈ci)log2p(x∈ci) (2)
wherenis the total number of clusters. High entropy indicates that it is difficult to predict the cluster of instances. Such as when the possibility ofxbelonging to allnclusters is 1/n. Low entropy means that the cluster of the instance is obvious, for instance, when the possibility ofxbelonging to one cluster is 99.99%. Therefore, uncertainty has a direct relation with the entropy value.
Assuming that the points are ranked based on their entropy in decreasing order,i.e.,Entropy(x1)≥
Entropy(x2) ≥ · · · ≥ Entropy(xn). The instance
with the more entropy value is selected, however, it should also be considered that if there exist more point around the selected instance, selecting this instance would be more useful and reduce the probability of selection noisy instance. In the proposed selection cri-terion, this fact is considered. The number of data surrounding the selected point is considered as the density associated with each instance, so the instance that maximizes the following equation is selected:
x∗=arg max
x∈DEntropy(x)∗(1−e
−s(x)) (3)
Where D is the set of points that are not belong to any neighborhood and s(x) is the total number of data around thex. Our active selection method is summarized in Most Effective Points algorithm (Algorithm 2).
3.2 Signature-Based Method for Tunneling Protocols Identification
As mentioned before, payload-based methods have an important contribution in traffic identification, but the computational cost is its drawback. In this article, LPI approach is applied, which is a high-speed and memory efficient payload-based method in tunneling traffic identification [16]. Although, tunneling proto-cols use encryption, tunneling establishment consists of a negotiation phase in the form of non-encrypted traffic for exchanging connection parameters in the beginning of the connection. Messages exchanged in this phase are clear. LPI uses these clear messages to identify each flow. The LPI method consists of
heuris-tics and rules about the tunneling protocols achieved from the standard protocol specifications and some performed observation and analysis. If data packets are placed together, according to these heuristics and rules, then LPI detects the protocol.
LPI method is fast and need less memory and stor-age in comparison with existing DPI methods. The accuracy of LPI is comparable with other DPI ap-proaches. This method only requires initial packets of payload that refer to negotiation phase and first few bits of each packet. Indicating that, it reduces the privacy matter in DPI and it is effective and practical when probing of whole packets in high speed network is impossible. LPI has a few rules for packet matching. For example, for identifying IPsec, PPTP, L2TP and OpenVPN, it is required to consider only at most six first packets.
Due to the unique characteristics of LPI, in this paper, it is applied as a signature-based system. 3.3 Runtime Analysis
For analyzing the runtime of hybrid method, the active learning algorithm and LPI method are focused. LPI method uses a few packets for protocol identification, and it has a few rules. For identifying IPsec, PPTP, L2TP and OpenVPN, it is required to consider only at most six first packets [16]. So overhead and runtime of LPI is low. In MEP algorithm, there exist two for-loop. The outer for-loop is executed at mostO(N) times, thatN is the number of data instances. The runtime of inner for-loop isO(M) thatM is the number of the neighborhood or the number of application type in the dataset. In this work, the number of neighborhoods is limited to four, therefore, the total runtime is bounded byO(N).
4
Experiments
4.1 Dataset
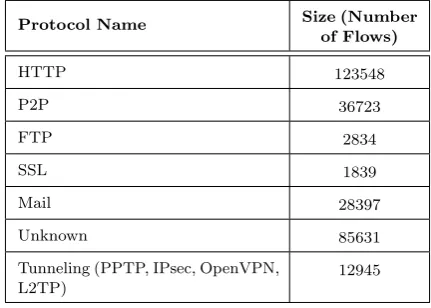
Unfortunately, there exist no appropriate dataset in tunneling traffic and none of the available datasets have suitable protocols. For example Moore dataset [43] and others, do not include tunneling traffic and therefore cannot be used to evaluate the accuracy of the proposed method. In this article, the IUT.F.D dataset is used that was produced at Isfahan Univer-sity of Technology in the summer of 2014 from the real traffic. Table 1 shows the traffic profile used as reference for evaluating our hybrid method accuracy.
April 2016, Volume 3, Number 2 (pp. 95–110) 103
Algorithm 2Most Effective Point Algorithm
Input: Set of dataX, The cluster solutionC=c1, c2, . . . , cn, Set of neighborhoodN
Output: The informative instancex∗.
1: for eachx∈X that is not a member of any neighborhooddo 2: fori= 1tondo
3: p(x∈ci) =
dist(x,oi) Pn
j=1dist(x,oj)
4: end for
5: Entropy(x) =−Pn
i=1p(x∈ci)Log2p(x∈ci)
6: end for
7: x∗=arg maxx∈DEntropy(x)∗(1−e−s(x))
Table 1. Protocol Distribution of Our Trace
Protocol Name Size (Number of Flows)
HTTP 123548
P2P 36723
FTP 2834
SSL 1839
Mail 28397
Unknown 85631
Tunneling (PPTP, IPsec, OpenVPN, L2TP)
12945
MEP algorithm, night UCI datasets [44] are used, including Digits-389, Tae1, Parkinsons, Ionosphe,
Ecoli, Letter, Seeds, Balance Scale and Data-banknote-authentication.
4.2 Evaluation
To evaluate the proposed hybrid approach, at first, the effectiveness of MEP algorithm is evaluated on UCI datasets and finally the performance of the com-bination of active constrained clustering and LPI is measured on tunneling dataset.
4.2.1 Active Constrained Clustering Perfor-mance Evaluation
In this section, regardless of the results on tunneling traffic dataset, the performance of the MEP algorithm is compared with a set of methods, including random selection [39], E&C [39] and Min-Max [35] on UCI dataset. In this comparison, MPCK-means algorithm is used.
In order to have proper comparison, two metrics are applied as the cluster evaluation, including: nor-malized mutual information (NMI) [45] and pairwise F-measure [39]. NMI metric considers the class label and the clustering assignment as random variables
1 Teaching Assistant Evaluation
and measures how the clustering algorithm could re-construct the underlying label distribution in the data. IfCis the random variable representing the cluster assignments of points, andKis the random variable representing the class labels of the points, then NMI is defined as follows:
N M I = I(C;K)
(H(C) +H(K))/2 (4) Where I(C;K) = H(C)−H(C|K) is the mutual information between the random variablesCandK
.H(C) is the Shannon entropy ofC, andH(C|K) is the conditional entropyCgivenK.
Another comparison metric is F-measure that eval-uates how well the model can predict the pairwise relationship between each pair of points in cluster as-signments in comparison to the relationship defined by the class labels. F-measure is defined as the har-monic mean of precision and recall, and is defined by the following equations:
P recision=#P airsCorrectlyP redictedInSameCluster #T otalP airsP redictedInSameCluster
(5)
Recall= #P airsCorrectlyP redictedInSameCluster #T otalP airsActuallyInSameCluster
(6)
F−M easure= 2×P recision×Recall
P recision+Recall (7)
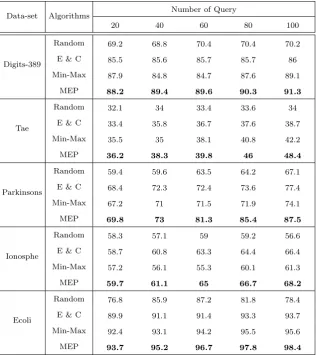
Table 2. The F-measure values on UCI datasets
Data-set Algorithms Number of Query
20 40 60 80 100
Digits-389
Random 69.2 68.8 70.4 70.4 70.2
E & C 85.5 85.6 85.7 85.7 86
Min-Max 87.9 84.8 84.7 87.6 89.1
MEP 88.2 89.4 89.6 90.3 91.3
Tae
Random 32.1 34 33.4 33.6 34
E & C 33.4 35.8 36.7 37.6 38.7
Min-Max 35.5 35 38.1 40.8 42.2
MEP 36.2 38.3 39.8 46 48.4
Parkinsons
Random 59.4 59.6 63.5 64.2 67.1
E & C 68.4 72.3 72.4 73.6 77.4
Min-Max 67.2 71 71.5 71.9 74.1
MEP 69.8 73 81.3 85.4 87.5
Ionosphe
Random 58.3 57.1 59 59.2 56.6
E & C 58.7 60.8 63.3 64.4 66.4
Min-Max 57.2 56.1 55.3 60.1 61.3
MEP 59.7 61.1 65 66.7 68.2
Ecoli
Random 76.8 85.9 87.2 81.8 78.4
E & C 89.9 91.1 91.4 93.3 93.7
Min-Max 92.4 93.1 94.2 95.5 95.6
MEP 93.7 95.2 96.7 97.8 98.4
next step, for getting bigger neighborhoods, data are selected randomly and placed in the correct neigh-borhood. These neighborhoods are the initial seeds in clustering. More recently, MMax approach is in-troduced that is an improvement to E&C. Min-Max approach changes the consolidate phase of E&C by se-lecting the most uncertain point and design the quires. In the second phase, Min-Max incrementally expands the neighborhoods with selecting a point to design a query through a distance-based Min-Max criterion.
In the mentioned three methods, constraints are selected before clustering and regardless of the clus-tering result, while in hybrid method presented in this article, constraints are selected in an iterative pro-cess according to the clustering results. The achieved results indicate that the proposed method can be ap-plied to non-network traffic data types.
In Table 2, the F-measure values are observed. Dif-ferent methods with 20, 40, 60, 80 and 100 query size are compared. The best results are highlighted in boldface. As it is obvious, the proposed method named MEP, has high accuracy in separating clusters
in comparison with other methods.
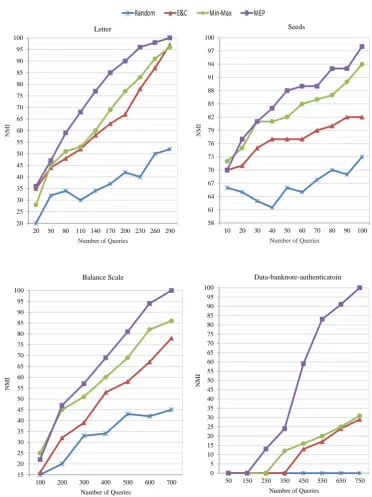
In addition, the NMI values of MEP and other methods on some other datasets with different query size are shown in Figure 3. The x-axis indicates the number of queries and the y-axis shows the clustering performance measured according to NMI values by running MPCK-means algorithm.
Seeds, Letter and Data-banknote-authentication are balanced datasets and Balance scale is unbalanced dataset. So the performance of the MEP method in balanced and unbalanced datasets is better than other proposed methods in this area.
4.2.2 Performance Evaluation of Combina-tion of MEP and LPI
April 2016, Volume 3, Number 2 (pp. 95–110) 105
20 25 30 35 40 45 50 55 60 65 70 75 80 85 90 95 100
20 50 80 110 140 170 200 230 260 290
NM
I
Number of Queries
58 61 64 67 70 73 76 79 82 85 88 91 94 97 100
10 20 30 40 50 60 70 80 90 100
N
M
I
Number of Queries
15 20 25 30 35 40 45 50 55 60 65 70 75 80 85 90 95 100
100 200 300 400 500 600 700
N
M
I
Number of Queries
Balance Scale Data-banknote-authenticatoin
Letter Seeds
0 5 10 15 20 25 30 35 40 45 50 55 60 65 70 75 80 85 90 95 100
50 150 250 350 450 550 650 750
N
M
I
Number of Queries
Figure 3. The NMI Values on UCI Datasets
methods is depicted in the following figures.
In Figure 4 the F-measure values of the proposed hybrid approach through various active learning meth-ods with different query size are depicted. As it is obvious, by increasing the number of queries, the ef-fectiveness of random selection is reduced or at least remains unchanged. This indicates the importance of constraints selection. The performance of the E&C and Min-Max method are improved by increasing the query size, but their F-measure values are lower than
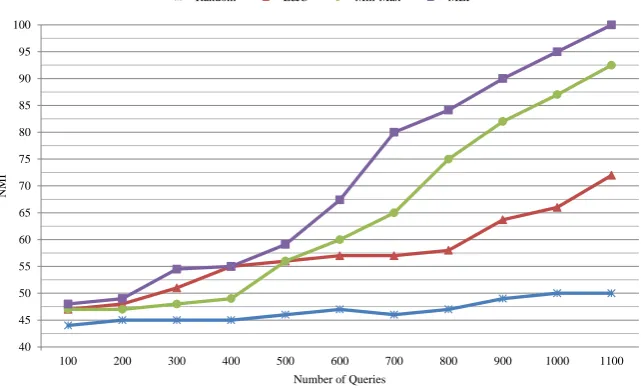
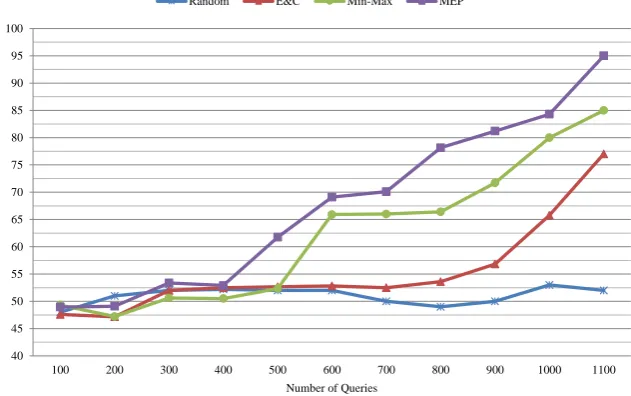
MEP in all points, so our hybrid approach, including proposed active clustering and LPI has a high ability to separate tunneling protocols. To evaluate the per-formance, the NMI criteria is used. The results of the comparison using NMI, is depicted in Figure 5.
The NMI of unconstrained clustering algorithms like K-means and EM, is about 48% that due to its fixed value, it is not shown in Figure 5.
40 45 50 55 60 65 70 75 80 85 90 95 100
100 200 300 400 500 600 700 800 900 1000 1100
F
-meas
u
re
Number of Queries
Random E&C Min-Max MEP
Figure 4. The F-Measure Values on IUT.F.D Dataset, Using MPCK-means
40 45 50 55 60 65 70 75 80 85 90 95 100
100 200 300 400 500 600 700 800 900 1000 1100
N
MI
Number of Queries
Random E&C Min-Max MEP
Figure 5. The NMI Values on IUT.F.D Dataset, Using MPCK-means
The performance of the proposed method using PCK-means algorithm is depicted in following figure.
As observed in Figures 6 and 7, at first, the perfor-mances of the algorithms are close together. By in-creasing the number of queries, the proposed method strength is more specified. This result was predictable because the proposed active learning method, in each stage of running, selects new constraints according to the clustering result, that is, by increasing the num-ber of questions the accuracy of clustering is getting better and better, whereas in the other three methods, constraint selection is done before the clustering and regardless of its results.
5
Conclusion and Future Work
ob-April 2016, Volume 3, Number 2 (pp. 95–110) 107
40 45 50 55 60 65 70 75 80 85 90 95 100
100 200 300 400 500 600 700 800 900 1000 1100
F
-meas
u
re
Number of Queries
Random E&C Min-Max MEP
Figure 6. The F-Measure Values on IUT.F.D Data-Set, Using PCK-means
40 45 50 55 60 65 70 75 80 85 90 95 100
100 200 300 400 500 600 700 800 900 1000 1100
N
MI
Number of Queries
Random E&C Min-Max MEP
Figure 7. The NMI Values on IUT.F.D Dataset, Using PCK-means
tained results indicate that the proposed hybrid ap-proach is effective in network traffic identification. For future work, our work can be extended in several di-rections: one direction is LPI development for other tunneling protocols. Another direction is considering the fact that each of protocols such as Http, DNS, Ftp, SSH, SSL, Mail, Chat, P2P, etc. can be encapsulated in tunneling protocols as the content, so identification the protocols inside the allowed and illegal tunnel is one of the most important recommendations for fur-ther work. Finally, in the hybrid approach, an unsu-pervised or semi-suunsu-pervised feature selection method can be applied, based on existing constraints.
References
[1] S. Narayan, C. J. Williams, D. K. Hart, and M. W. Qualtrough. Network performance comparison of VPN protocols on wired and wireless networks. In2015 International Conference on Computer Communication and Informatics (ICCCI), pages 1–7, Jan 2015.
[2] William Stallings. Cryptography and Network Security: Principles and Practice. Prentice Hall Press, 5th edition, 2010. ISBN 0136097049, 9780136097044.
[3] James Hoagland, Suresh Krishnan, and Dave Thaler. Security Concerns with IP Tunneling. RFC 6169, April 2011.
Is-sues and future directions in traffic classification. IEEE Network, 26(1):35–40, January 2012. ISSN 0890-8044. doi:10.1109/MNET.2012.6135854. [5] Tomasz Bujlow. Classification and Analysis of
Computer Network Traffic. PhD thesis, Aalborg University, 6 2014.
[6] A. Madhukar and C. Williamson. A Longitudinal Study of P2P Traffic Classification. In14th IEEE International Symposium on Modeling, Analy-sis, and Simulation, pages 179–188, Sept 2006. doi:10.1109/MASCOTS.2006.6.
[7] Andrew W. Moore and Konstantina Papagian-naki. Toward the Accurate Identification of Network Applications, pages 41–54. Springer Berlin Heidelberg, 2005. ISBN 978-3-540-31966-5. doi:10.1007/978-3-540-31966-5 4.
[8] Fang Yang and Zhi-qun Zhang. Research of Ap-plication Protocol Identification System Based DPI and DFI, pages 305–310. Springer Berlin Heidelberg, 2012. ISBN 978-3-642-25769-8. doi:10.1007/978-3-642-25769-8 44.
[9] T. Liu, Y. Sun, and L. Guo. Fast and Memory-Efficient Traffic Classification with Deep Packet Inspection in CMP Architecture. In2010 IEEE Fifth International Conference on Networking, Architecture, and Storage, pages 208–217, July 2010. doi:10.1109/NAS.2010.43.
[10] R. Alshammari and A. N. Zincir-Heywood. Unveiling Skype encrypted tunnels using
GP. In IEEE Congress on
Evolution-ary Computation, pages 1–8, July 2010.
doi:10.1109/CEC.2010.5586288.
[11] T. T. T. Nguyen and G. Armitage. A survey of techniques for internet traffic classification using machine learning. IEEE Communications Sur-veys Tutorials, 10(4):56–76, Fourth 2008. ISSN 1553-877X. doi:10.1109/SURV.2008.080406. [12] R. V. Kulkarni, S. H. Patil, and R. Subhashini.
An overview of learning in data streams with label scarcity. In 2016 International Con-ference on Inventive Computation Technolo-gies (ICICT), volume 2, pages 1–6, Aug 2016. doi:10.1109/INVENTIVE.2016.7824874.
[13] Jeffrey Erman, Martin Arlitt, and Anirban Ma-hanti. Traffic Classification Using Clustering Al-gorithms. InProceedings of the 2006 SIGCOMM Workshop on Mining Network Data, MineNet ’06, pages 281–286. ACM, 2006. ISBN 1-59593-569-X. doi:10.1145/1162678.1162679.
[14] H. A. H. Ibrahim, O. R. Aqeel Al Zuobi, M. A. Al-Namari, G. MohamedAli, and A. A. A. Ab-dalla. Internet traffic classification using machine learning approach: Datasets validation issues. In 2016 Conference of Basic Sciences and Engineer-ing Studies (SGCAC), pages 158–166, Feb 2016. doi:10.1109/SGCAC.2016.7458022.
[15] Charles V. Wright, Scott E. Coull, and Fabian Monrose. Traffic Morphing: An Efficient Defense Against Statistical Traffic Analysis. In Proceed-ings of the 16th Network and Distributed Security Symposium, pages 237–250. The Internet Society, 2009.
[16] K. Kazemi and A. Fanian. Tunneling protocols identification using light packet inspection. In 2015 12th International Iranian Society of Cryp-tology Conference on Information Security and Cryptology (ISCISC), pages 110–115, Sept 2015. doi:10.1109/ISCISC.2015.7387907.
[17] Huisheng Liu, Zhenxing Wang, and Yu Wang. Semi-supervised Encrypted Traffic Classification Using Composite Features Set. Journal of Net-works, 7(8):1195–1200, 2012.
[18] Zhenxiang Chen, Zhusong Liu, Lizhi Peng, Lin Wang, and Lei Zhang. A novel semi-supervised learning method for Internet application identi-fication. Soft Computing, 21(8):1963–1975, Apr 2017. ISSN 1433-7479. doi:10.1007/s00500-015-1892-1.
[19] Lizhi Peng, Bo Yang, Yuehui Chen, and Ajith Abraham. Data gravitation based classification. Information Sciences, 179 (6):809 – 819, 2009. ISSN 0020-0255. doi:https://doi.org/10.1016/j.ins.2008.11.007. [20] Zhenxiang Chen, Haiyang Wang, Ajith
Abra-ham, Crina Grosan, Bo Yang, Yuehui Chen, and Lin Wang. Improving neural network classifica-tion using further division of recogniclassifica-tion space. International Journal of Innovative Computing, Information and Control, 5(2):301 – 310, 2009. ISSN 349-4198. URLhttp://www.ijicic.org/
07-136-1.pdf.
[21] Y. Wang, Y. Xiang, J. Zhang, and S. Yu. A novel semi-supervised approach for network traffic clus-tering. In 2011 5th International Conference on Network and System Security, pages 169–175, Sept 2011. doi:10.1109/ICNSS.2011.6059997. [22] Mikhail Bilenko, Sugato Basu, and Raymond J.
Mooney. Integrating Constraints and Metric Learning in Semi-supervised Clustering. In Pro-ceedings of the Twenty-first International Con-ference on Machine Learning, ICML ’04, New York, NY, USA, 2004. ACM. ISBN 1-58113-838-5. doi:10.1145/1015330.1015360.
[23] Kiri Wagstaff, Claire Cardie, Seth Rogers, and Stefan Schr¨odl. Constrained K-means Cluster-ing with Background Knowledge. In Proceed-ings of the Eighteenth International Conference on Machine Learning, ICML ’01, pages 577– 584, San Francisco, CA, USA, 2001. Morgan Kaufmann Publishers Inc. ISBN
1-55860-778-1. URL http://dl.acm.org/citation.cfm?
April 2016, Volume 3, Number 2 (pp. 95–110) 109
[24] Dan Pelleg and Dorit Baras. K-Means with Large and Noisy Constraint Sets, pages 674–682. Springer Berlin Heidelberg, Berlin, Heidelberg, 2007. ISBN 978-3-540-74958-5. doi:10.1007/978-3-540-74958-5 67.
[25] Yu Wang, Yang Xiang, Jun Zhang, Wan-lei Zhou, and Bailin Xie. Internet traffic clustering with side information.
Jour-nal of Computer and System Sciences, 80
(5):1021 – 1036, 2014. ISSN 0022-0000. doi:https://doi.org/10.1016/j.jcss.2014.02.008. Special Issue on Dependable and Secure Com-puting.
[26] Ying Hou, Hai Huang, Wenchao Shao, and Heqing Huang. Traffic Classification Method by Com-bination of Host Behaviour and Statistical Ap-proach. Journal of Engineering Science & Tech-nology Review, 7(3):151–157, 2014.
[27] G. L. Sun, Y. Xue, Y. Dong, D. Wang, and C. Li. An Novel Hybrid Method for Effectively Classi-fying Encrypted Traffic. In2010 IEEE Global Telecommunications Conference GLOBECOM 2010, pages 1–5, Dec 2010.
[28] Wujian Ye and Kyungsan Cho. P2P and P2P botnet traffic classification in two stages. Soft Computing, 21(5):1315–1326, Mar 2017. ISSN 1433-7479. doi:10.1007/s00500-015-1863-6. [29] Snort - network intrusion detection &
preven-tion system. URLhttps://www.snort.org. Ac-cessed: June 26, 2017.
[30] TIE - Traffic Identification Engine. URLhttp://
tie.comics.unina.it. Accessed: June 26, 2017.
[31] Tstat - TCP STatistic and Analysis Tool. URL
http://tstat.tlc.polito.it. Accessed: June
26, 2017.
[32] L. Deri, M. Martinelli, T. Bujlow, and A. Cardigliano. nDPI: Open-source high-speed deep packet inspection. In2014 International Wireless Communications and Mobile Computing Conference (IWCMC), pages 617–622, Aug 2014.
doi:10.1109/IWCMC.2014.6906427.
[33] Daniele De Sensi. Dpi over commodity hardware: implementation of a scalable framework using fastflow. Master’s thesis, Universit`a di Pisa, Italy, 2012.
[34] Tomasz Bujlow, Valent´ın Carela-Espa˜nol, and Pere Barlet-Ros. Extended independent com-parison of popular deep packet inspection (DPI) Tools for Traffic Classification. Technical report, Universitat Polit`ecnica de Catalunya, 2014. [35] P. K. Mallapragada, R. Jin, and A. K. Jain.
Active query selection for semi-supervised clus-tering. In 2008 19th International Conference on Pattern Recognition, pages 1–4, Dec 2008. doi:10.1109/ICPR.2008.4761792.
[36] Burr Settles. Active Learning Literature
Survey. Technical Report 1648, University of Wisconsin–Madison, 2009. URL http: //axon.cs.byu.edu/~martinez/classes/
778/Papers/settles.activelearning.pdf.
[37] Sugato Basu, Mikhail Bilenko, and Raymond J. Mooney. A Probabilistic Framework for Semi-supervised Clustering. In Proceedings of the Tenth ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, KDD ’04, pages 59–68. ACM, 2004. ISBN
1-58113-888-1. doi:10.1145/1014052.1014062.
[38] Shalove Agarwal, Shashank Yadav, and Kan-chan Singh. K-means versus K-means++ Clus-tering Technique. In 2012 Students Con-ference on Engineering and Systems, 2012. doi:10.1109/SCES.2012.6199061.
[39] Sugato Basu, Arindam Banerjee, and Raymond J. Mooney. Active Semi-Supervision for Pair-wise Constrained Clustering, pages 333–344. doi:10.1137/1.9781611972740.31.
[40] Wikipedia. Farthest-first traversal, 2017.
URL https://en.wikipedia.org/wiki/
Farthest-first_traversal.
[41] Alina Vl˘adut¸u, Drago¸s Com˘aneci, and Ciprian Dobre. Internet traffic classification based on flows’ statistical properties with machine learn-ing. International Journal of Network Manage-ment, 27(3):e1929–n/a, 2017. ISSN 1099-1190. doi:10.1002/nem.1929.
[42] Kiri L. Wagstaff.Value, Cost, and Sharing: Open Issues in Constrained Clustering, pages 1–10. Springer Berlin Heidelberg, 2007. ISBN 978-3-540-75549-4. doi:10.1007/978-3-540-75549-4 1. [43] GRIDprobe / Nprobe. URL http://www.
cl.cam.ac.uk/research/srg/netos/nprobe/
data/papers/sigmetrics. Accessed: June 29,
2017.
[44] M. Lichman. UCI Machine Learning Repository, 2013. URLhttp://archive.ics.uci.edu/ml. [45] Alexander Strehl and Joydeep Ghosh.
Keihan Kazemi received her B.Sc. and M.Sc. in IT Engineering and Artificial Intel-ligence from University of Isfahan and Isfa-han University of Technology, Iran, in 2010 and 2014, respectively. Her research interests include Internet traffic identification using machine learning methods. Her research inter-ests focus on encrypted traffics identification using classification and clustering methods.
![Figure 2. Clustering With Random Selection of Constraints [35]](https://thumb-us.123doks.com/thumbv2/123dok_us/38875.2004407/7.595.100.500.101.450/figure-clustering-random-selection-constraints.webp)