Comparison of automatic summarisation methods for clinical free text notes
Full text
Figure

![Fig. 4. The Case-Based summarisation method illustrated as a ‘CBR cycle’, based on the CBR cycle introduced by Aamodt and Plaza [47]](https://thumb-us.123doks.com/thumbv2/123dok_us/9033257.2801151/7.918.209.726.100.538/case-based-summarisation-method-illustrated-introduced-aamodt-plaza.webp)
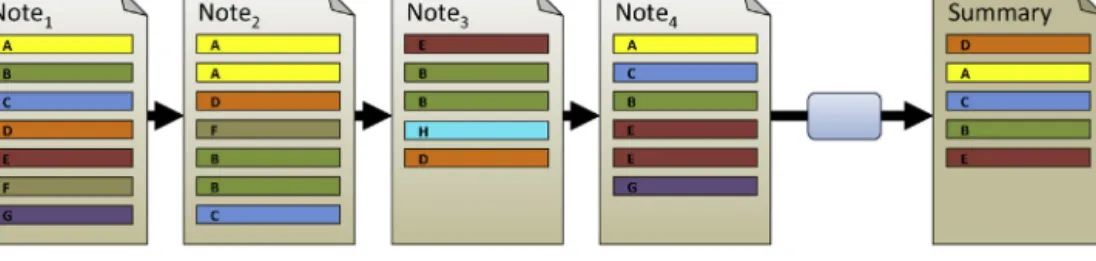
Related documents
Annual number of ED visits for AGI (ICD-9) per 1,000 people in each county. Percent of the population served by DWSs exposed to total coliform contamination.. Percent of the
Additionally, excess distance travelled per route over the minimum required would be related to vehicle performance efficiency index.The concept of vehicle administrative
document; 4) analysis of social media covering Benghazi; 5) documents relating to video-conferences in September 2012 pertaining to Libya; 6) documents/communications
• Market dynamics, including consolidation, the impact of Microsoft Windows SharePoint Services for collaborative document management, and increasing competition from
Staff members who will be on mission assignment for six months or more and who will not have eligible covered family members residing in the United States for the duration of
In verband met het verschil in duur van de gesprekken tijdens de voor- en nameting hebben we gebruik gemaakt van de procentuele verdeling van specifieke gedragen ten opzichte van
Finding a direct presence and direct communication with Japanese companies here in Japan is also having a ripple effect on the business we can get from Japanese companies
