2017 International Conference on Computer Science and Application Engineering (CSAE 2017) ISBN: 978-1-60595-505-6
Sentiment Analysis by Exploring Large Scale
Web-based Chinese Short Text
Ziyu Liu*, Yonggang Qi, Zhanyu Ma and Jie Yang
School of Information and Communication Engineering, Beijing University of Posts & Telecommunications. No.10 Xitucheng Rd, Haidian District, 100876 Beijing, China
ABSTRACT
Sentiment analysis has been a popular research topic these years. In this paper, we will pay attention to the sentimental state of college students and make corresponding sentiment analysis. In this paper, we purpose two short text sentiment analysis models based on student forum data, named hard mapping sentiment analysis model and soft mapping sentiment analysis model respectively. Hard mapping sentiment analysis obtains the polarity of each short text by Polarity Value Table of Chinese Sentimental Words. On this basis, soft mapping sentiment analysis model trains the word similarity model of Chinese words with a large amount of data from Chinese Wikipedia using word2vec and Gensim. It diminishes the judgment errors induced by the inadequate vocabulary size of the sentiment dictionary in the Hard mapping sentiment analysis. Our result shows the improvement in short text sentiment analysis of the model by using the soft mapping sentiment analysis model. The research has significant implications in the psychological guidance of college students.
INTRODUCTION
Sentiment analysis has been a popular research topic these years. Currently, the rapid growing texts on the Internet, whether product reviews or social network posts, provide large and valuable data to sentiment analysis research.
However, it is difficult to get valuable information in e-commerce and social websites. For human analysis of text is often misguided by their subjective preference. Therefore, we should apply automatic analysis to text information. While other researchers focus their work on customer review to improve the product, we apply sentiment analysis and text analysis to college forums. And thus we can analyze and monitor the sentimental state among undergraduate students [1].
College students in China, especially freshmen, are facing life and environmental changes, interpersonal relationship issues, and pressure from parents to succeed academically, socially, and professionally. This combination of stressors makes college students vulnerable to psychological and psychiatric problems. A survey conducted by the Chinese National Education Committee among 120,000 students showed that 20% of Chinese college students reported mental health problems [2]. College students are among the most active groups in a society. Their mental health status reflects, to a certain extent, the social development and health trends of the whole society. Therefore, it is critical to examine the mental health issues among college students in China [3].
make corresponding sentiment analysis. In the social network information for social sentiment analysis, the corpus and data set in academic research are mostly from micro-blog, Facebook and other public social platforms. According to a report released by Comsenz Inc., owner of Discuz!-the most widely used BBS system in China, pictures a particularly young, dynamic and devoted BBS culture with rich statistical data: 68.9% of the BBS users are aged 18-30; 79.7% are receiving or have completed higher education; 69.7% have been using BBS for over five years; 79.8% have ever published or replied to BBS posts. These data demonstrate to us the extreme popularity of BBS among Chinese netizens [4]. For the particular group of undergraduates, we choose to university student forums as our data sources. Undergraduates are relatively gathered in these forums, and the content is targeted. Besides, forum texts are mainly short texts and are well-suited for short text sentiment analysis.
In this paper, we use hard mapping sentiment analysis, a short text sentiment analysis model, based on student’s forum. The model uses the polarity value table of Chinese sentimental words, provided by Department of Chinese, Tsinghua University, to analyze sentence level sentiment directly. However, considering a word to be non-sentimental and scores 0 if its matching could not be found. We modify the Hard mapping sentiment analysis model to a ‘soft’ one. In modified model, the zero-score words would be graded according to their synonyms.
In the soft mapping sentiment analysis model, the concept of “Word Similarity” is added. We train Wikipedia Chinese corpus based on the word2vec model. We also use the Gensim software to form Chinese words semantic similarity model. For the words which do not exist in the sentimental lexicon, the word with the largest similarity of the sentimental maximum score is used instead. And the weight of similarity is added to reduce the error of sentence sentiment score review.
Compared to the existing short text analysis research. Our contribution is:
Our data of the study is the student forums, which have never been studied before.
We mainly study short texts in Chinese. The existing short text sentiment analysis is mostly English research.
We solved the deviation of sentiment words caused by the limited size of dictionaries.
The rest of this paper is organized as follows. The second section introduces related work. Then the third section describes our tools and methods: word2vec model, Gensim frameworks, and the hard mapping and soft mapping methods. There are also details of how to improve the model using semantic similarity. The fourth section describes the experiment, including the datasets and experiment result. Finally, our conclusion is presented.
RELATED WORK
analysis (LSA) to infer the semantic orientation of a word. Narayanan and et al. [9] studied sentiment analysis of conditional sentences with linguistic knowledge. Yuen and et al. [10] applied a method based on PMI presented by Turney [8] and morphemes in Chinese, which give high precision and recall in deciding semantic orientation of Chinese words.
And with polar lexical items found by Yuen [10], Tsou [11] brought out an algorithm exploring the spread, density and intensity of polar lexical items, and classified news articles regarding political figures with good performance. Ku and Chen [12] collected a Chinese sentiment words dictionary called NTUSD, which is widely used nowadays, and determined sentiment polarity of a sentence by identifying sentiment words, negation operators and opinion holders in it. Other research results [13, 14] were there based on HowNet, which is another famous Chinese sentiment words dictionary.
METHOD
In this section, we start by discussing methods for learning word vectors. We use Hard mapping sentiment analysis, a short text sentiment analysis model based on student forums, to analyze the data. Firstly, preprocess raw data. Secondly, do the segmentation procedure by Jieba segmenter. Then we map each word in dataset with sentimental words in Polarity Value Table of Chinese Sentimental Words to get the score of the word. The total sentimental score of sentence P is calculated by summing the score of each word.
To solve the deviation of sentiment words caused by the limited size of dictionaries, we proposed soft mapping sentiment analysis model. In the soft mapping sentiment analysis model, the concept of “Word Similarity” is added. We train Wikipedia Chinese corpus based on the word2vec model and the software of Gensim to form Chinese words semantic similarity model. For words which do not exist in the sentimental lexicon, the word with largest similarity of the sentimental maximum score is used instead. And the weight of similarity is added to reduce the error of sentence sentiment score review.
Word2vec: Find Relative Words
In our case, we first do the sentence segmentation to turn sentences into words. These words will be converted into vectors using word2vec program. The vectors will be used in Gensim model to compute similarity score. Each word will have a most similar word in the dictionary and has a corresponding similarity score. We will get a score of the word by multiplying the similarity score and sentiment score in the dictionary.
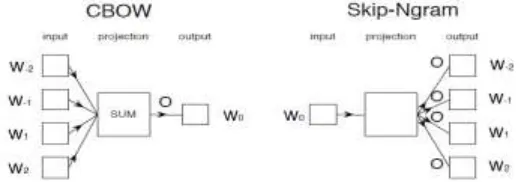
The CBOW model predicts the center word 𝜔𝑜 given a representation of the surrounding words 𝜔−𝑐, … , 𝜔−1, 𝜔1, 𝜔𝑐. Thus, the output vector 𝑂𝜔−𝑐,…,𝜔−1,𝜔1,𝜔𝑐 is obtained from the product of the matrix 𝑂 ∈ ℜ|𝑉|×𝑑𝜔 with the sum of the embeddings of the context words ∑−𝑐≤𝑗≤𝑐,𝑗≠0𝑟𝜔𝑗 .
Figure 1. Illustration of the Skip-gram and Continuous Bag-of-Word (CBOW) Models.
[image:4.612.167.428.134.225.2]Using above methods, we can compute similarity between the words. We can find relative words after computing and normalizing the distance. For example, input ‘trueness’, the related words and distances are listed in TABLE I (The original texts are Chinese. The results are translated into English in above TABLE I).
TABLE I. RELATIVE WORDS.
Word Distance
Rustic 0.780969
Innocent 0.757615
Simple 0.743768
Childhood 0.743078
Pure and Beautiful 0.739746
Quiet 0.734714
Deep 0.733255
From the list, we can see that the result is satisfying. So we can use word2vec to extend the sentiment dictionary to get more words that contain sentiment information.
Gensim
As we can see, after the words converted into vectors, we used in Gensim model to compute similarity score [18]. Each word will have a most similar word in the dictionary and has a corresponding similarity score. We will get a score of the word by multiplying the similarity score and sentiment score in the dictionary.
To get the correct semantic information of the word vector, preprocessing of the large text data is required. After segmenting and simplifying the traditional Chinese, we get raw data from Chinese Wikipedia data, which includes more than 230,000 Chinese articles. Then we build our word vector model using Gensim. Specifically, we use an unsupervised deep learning model in Gensim, to train the data set to get 400-dimensional vectors. We can compute the semantic distances using these vectors.
A Hard Mapping Sentiment Analysis Model
Firstly, comments data from the forums of University A and B (two universities in Beijing) are obtained by the crawler. Data from one of the forums are used for training parameters of the model. To further evaluate the accuracy, data from the other forum works as a testing set.
Raw data acquired some preprocessing procedures, starting by deleting sentiment icons and non-Chinese characters (e.g. English words) in the comments. The segmentation is done by Jieba segmenter [19]. Meanwhile, we introduce Polarity Value Table of Chinese Sentimental Words and define our data in the format of {word, value} for further mapping.
Supposing after segmentation, a sentence P expresses 𝑃 = {𝑎1, 𝑎2, 𝑎3, … , 𝑎𝑛} as where
𝑎𝑖is the ith segmentation result. Then we map each 𝑎𝑖with sentimental words in Polarity Value Table of Chinese Sentimental Words. If it finds its match, the sentimental polarity score of 𝑎𝑖 comes out; if not, which means 𝑎𝑖 is not in the dictionary, then it is considered as a non-sentimental word with a score of 0. The total sentimental score of sentence P is calculated by 𝑆𝑝= 𝑆𝑎1+ 𝑆𝑎2+ ⋯ + 𝑆𝑎𝑛
We divide the sentimental intendancy into five levels: 1) Positive 2) Negative 3) Neutral 4) Highly Negative 5) Highly Positive. Sentences are classified into the above levels based on the threshold value T of their sentimental scores. In this case, we test with the data from the BBS of University B to find the best T. T is initialized by 𝑇0= 0.7 and increased or decreased by 0.1, i.e. 𝑇𝑖= 𝑇0± 𝑖 ∗ 0.1. 𝑇𝑖 with the highest accuracy is taken as the final threshold T after comparing all 𝑇𝑖. The results are shown as Fig.3. It is evident that the accuracy is most desirable, when 𝑇 = 1.2, hence we use it for classifying sentences and analyzing a bulk of other forum data. The detailed value is illustrated in Figure 3. (The original texts are Chinese. The results are translated into English in above Figure 3)
the result of
segmentation Chinese Sentimental Words
Y Y Y N
Score:0
Score:+0.2
Score:-0.16
Score:The default is 0
+0.04
Positive sentiment
Total Score
output
You are
Today
A little
discourage
You are a little discourage
today
segemantation
Figure 2. Structure diagram of the hard mapping sentiment analysis model.
Figure 3. The accuracy of hard mapping model for t with different values.
43% 44% 44%
54% 56% 57% 58% 60% 61%
63% 68% 70% 73% 70%
65% 66% 63% 64% 60% 57% 53%
0.00% 20.00% 40.00% 60.00% 80.00%
0.0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1.0 1.1 1.2 1.3 1.4 1.5 1.6 1.7 1.8 1.9 2.0
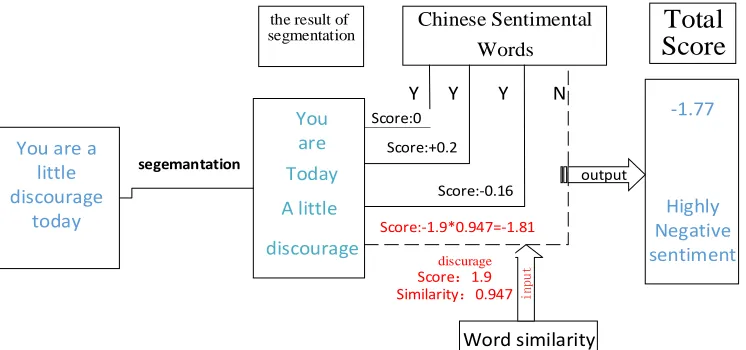
[image:5.612.113.489.413.553.2]Though straightforward and convenient, the error is not negligible after testing by 1000 pieces of manually labeled data. The main reason lies in the fact that we consider a word to be non-sentimental and scores 0 if its matching could not be found in Polarity Value Table of Chinese Sentimental Words. But in reality, sentimental words are countless given synonyms and so forth. Therefore, we modify the Hard mapping sentiment analysis to a ‘soft’ one.
the result of
segmentation Chinese Sentimental
Words
Y Y Y N
Score:0
Score:+0.2
Score:-0.16
Score:-1.9*0.947=-1.81
-1.77
Highly Negative sentiment
Total
Score
output
Word similarity
input
discurage
Score:1.9 Similarity:0.947
You are Today
A little
discourage segemantation
You are a little discourage
[image:6.612.116.489.148.323.2]today
Figure 4. Structure diagram of the softmapping sentiment analysis model.
A Soft Mapping Sentiment Analysis Model
To diminish the error induced by the inadequate vocabulary size of the sentiment dictionary in the Hard mapping sentiment analysis, we modify it by the concept of “Word Similarity” [20, 21]. Sentence P could be expressed as 𝑃 = {𝑎1, 𝑎2, 𝑎3, … , 𝑎𝑛} after preprocessing and segmentation. We run the same procedure as Hard mapping sentiment analysis if 𝑎𝑖 is within the dictionary. In contrast, its synonyms in the dictionary will be found according to word similarity and used alternatively later. The detailed method is illustrated in Fig.4. (The original texts are Chinese. The results are translated into English in above Fig.4)
We calculate the word similarity scores {𝑀𝑖1, 𝑀𝑖2, … , 𝑀𝑖𝑘}between a_i and each word in the dictionary 𝑑1, 𝑑2, 𝑑3, … , 𝑑𝑘 by word2vec Model and gensim.
Saying 𝑀𝑖𝑚𝑎𝑥= 𝑚𝑎𝑥{𝑀𝑖1, 𝑀𝑖2, … , 𝑀𝑖𝑘} represents the maximum of the comparison similarity between 𝑎𝑖 and words in the dictionary.
𝑀𝑖𝑚𝑎𝑥 corresponds to a word with a score 𝑆𝑖. New sentimental score equals to the product of 𝑀𝑖𝑚𝑎𝑥 and 𝑆𝑖, i.e. 𝑆𝑎𝑖 = 𝑆𝑖× 𝑀𝑖𝑚𝑎𝑥.
Then the total sentimental score of sentence 𝑃 is: 𝑆𝑝= 𝑆𝑎1+ 𝑆𝑎2+ ⋯ + 𝑆𝑎𝑛.
EXPERIMENTS
total sentimental score of a sentence can be calculated by summing the score of each word.
To diminish the error induced by the inadequate vocabulary size of the sentiment dictionary in the Hard mapping sentiment analysis model, we use the concept of “Word Similarity” to modify it. If the word can be found in the dictionary, we use Hard mapping sentiment analysis. If the there is no matching in the dictionary, the word with largest similarity score will be found and used alternatively. More details can be found in section 3.3 and 3.4.
At last, we present the experimental results of two models.
Dataset
Polarity Value Table of Chinese Sentimental Words: We can find a large number of authoritative sentimental dictionaries in English in modern sentimental analysis research, but concerning Chinese, there are very few. Among Chinese dictionaries, Polarity Value Table of Chinese Sentimental Words (Department of Chinese, Tsinghua University), Commendatory and Derogatory Meaning of Chinese Words Dictionary (Li-Jun, Tsinghua University), NTUSD Simplified Chinese Sentimental Words Dictionary (National Taiwan University) and Hownet Sentimental Words Dictionary (China National Knowledge Infrastructure) enjoy a high popularity at home [22,23]. In this paper, we use Polarity Value Table of Chinese Sentimental Words (Department of Chinese, Tsinghua University). It consists of 23419 sentimental Chinese words and their corresponding scores, which formats in “word\t Polarity value”. The sign of the Polarity value indicates whether it is a positive or negative emotion, while the absolute value of the Polarity value represents the intensity of sentimental tendency. For example, ‘’happy\t 1.17” is a positive feeling and ‘’sad\t -0.08” is a negative one.
College Forums Data: In this work, we obtained 3000 pieces of comments for the past month or more from the hottest modules of some college forums by a crawler software named Octopus. We set up our training set and testing set by manually labeling them with sentimental polarity for further analysis of undergraduates’ sentimental status.
Chinese Wikipedia data: Wikipedia official provides compression of about 1G of Chinese data, training word2vec model, used to calculate the semantic similarity between words.
Experimental Results
The above models are tested by manually labeled forum datasets of University B and University A, as training set and testing set respectively (see TABLE II).
TABLE II. THE ACCURACY OF TWO MODEL.
Hard Mapping Soft Mapping
Totally 62.4% 71.1%
Highly Positive Sentiment 60.6% 60.2%
Positive Sentiment 62.3% 65.5%
Neutral Sentiment 55.1% 55.7%
Negative Sentiment 63.4% 65.8%
Highly Negative Sentiment 62.1% 64.5%
For studying the undergraduates’ sentimental status behind the statistic, we look further into the result, which is not optimistic. Sentimentally-negatively comments are far more than positive ones in the last month in one of the surveyed forum. Sentimental topics, programming technical issues, employment issues are the most favorite topics, while they feel undesirable about political and marketing ads. Their attitude of economics is neutral relatively. It is of great significance to guide the undergraduates in sentiment.
Our result indicates that soft mapping model improves the accuracy of sentiment multi-level classification largely, therefore, it measures the sentimental tendency much better, leading to a far-raging use in reality. College students’ psychological condition is a serious and eye-catching problem recently, and clues of their pressure, characteristics, as well as thoughts, may be obtained from student forums. Therefore, we conduct fine-grained sentiment multi-level analysis on student forums and make further investigation.
Based on the soft mapping model, almost 4000 pieces of comment grabbed from the student forums of some universities in Beijing are in study. Comments unrelated (e.g. technical boards) are removed to ensure the data quality. We process the remaining 3000 comments, and the distribution result is as follow.
TABLE III. THE DISTRIBUTION OF SENTIMENT IN COMMENTS.
raw selected
Highly Positive Sentiment 8.8% 11.5%
Positive Sentiment 16.5% 19.2%
Neutral Sentiment 45.2% 32.2%
Negative Sentiment 18.4% 23.7%
Highly Negative Sentiment 11.1% 13.4%
As shown in TABLE III, after data selection, the number of neutral comment decreases and the negative ones increase (above 37.1%) in emotion-related boards.
More specifically, it could be found that 62.1% has commented in negative mood and 18.7% make more negative comments than positive comments.
The result is quite depressing and indicates universities should put more efforts on psychological education. Our research could locate the student groups overwhelmed by negative moods who need targeted guidance, which is of great significance.
CONCLUSIONS
analysis and soft mapping sentiment analysis model are proposed to analyze the sentimental features of the comment data. The experimental result shows the soft mapping sentiment analysis model can significantly induce Word Similarity to have higher accuracy. Some meaningful information, such as the students’ sentimental intendancy, their key focuses and their opinions about the social situation, will benefit our future work on sentimental and psychological guidance.
ACKNOWLEDGEMENT
This work is supported in part by the National Natural Science Foundation of China (61671078, 61402047, 61773071), Funds of Beijing Laboratory of Advanced Information Networks of BUPT, Fundamental Research Funds for the Central University under Grant No.2016RCGD09, and Funds of Beijing Key Laboratory of Network System Architecture and Convergence of BUPT, and 111 Project of China (B08004).
REFERENCES
1. B. Liu. 2012. “Sentiment Analysis and Opinion Mining,” Synthesis Lectures on Human Language Technologies, pp.188-190.
2. Q.Z. Qian. 2004. “Testing and cultivating of university female students’ mental health,” in Psychol. Sci. Jan 1, 2004.
3. G. Henriques. 2014. “The College Student Mental Health Crisis.” in Psychology Today.
4. L. W. Jin, S.M. 2008. "Chinese online BBS sphere: what BBS has brought to China," in Massachusetts Institute of Technology.
5. T. Nasukawa and J. Yi. 2003. “Sentiment analysis: Capturing favorability using natural language processing,” Proceedings of the 2nd international conference on Knowledge capture.
6. D. Kushal, S. Lawrence, and D. M. Pennock. 2003. “Mining the peanut gallery: Opinion extraction and semantic classification of product reviews,” Proceedings of the 12th international conference on World Wide Web.
7. S. Baccianella, A. Esuli, and F. Sebastiani. 2010. “Sentiwordnet 3.0: An enhanced lexical resource for sentiment analysis and opinion mining,” in LREC.
8. M. L. Littman. 2003. “Measuring praise and criticism: Inference of semantic orientation from association,” in ACM TOIS.
9. R. Narayanan, B. Liu, and A. Choudhary. 2009. “Sentiment analysis of conditional sentences,” in Conference on Empirical Methods in Natural Language Processing.
10. R. W. M. Yuen, T. Y. W. Chan, T. B. Y. Lai, O. Y. Kwong, and B. K. Y. T’Sou. 2004. “Morpheme-based derivation of bipolar semantic orientation of Chinese words,” in the 14th International Conference on Computational Linguistics.
11. B. K. Y. Tsou, R. W. M. Yuen, O. Y. Kwong, T. B. Y. Lai, and W. L. Wong. 2005. “Polarity classification of celebrity coverage in the Chinese press,” In International Conference on Intelligence Analysis.
12. L. W. Ku and H. H. Chen. 2007. “Mining opinions from the web: Beyond relevance retrieval,” Journal of the American Society for Information Science and Technology.
13. Y. L. Zhu, J. Min, Y. Q. Zhou, X. J. Huang, and W. U. Li-De. 2006. “Semantic orientation computing based on hownet,” Journal of Chinese Information Processing.
14. X. Fu, L. Guo, Y. Guo, and Z. Wang. 2013. “Multi-aspect sentiment analysis for Chinese online social reviews based on topic modeling and hownet lexicon,” In Knowledge-Based Systems. 15. W. Ling, C. Dyer, A. Black, I. Trancoso. 2015. “Two/Too Simple Adaptations of Word2Vec for
16. Mikolov, Tomas, Chen, Kai, Corrado, Greg, and Dean, Jeffrey. 2013a. “Efficient estimation of word representations in vector space,” arXiv preprint arXiv:1301.3781.
17. Mikolov, Tomas, Le, Quoc V., and Sutskever, Ilya. 2013b. “Exploiting similarities among languages for machine translation,” CoRR, abs/1309.4168.
18. Gensim , https://radimrehurek.com/gensim/tutorial.html. 19. Jieba , https://github.com/fxsjy/jieba
20. A. Islam and D. Inkpen. 2008. “Semantic text similarity using corpus-based word similarity and string similarity,” TKDD.
21. Y. Kim. 2014. “Convolutional neural networks for sentence classification,” in EMNLP.
22. T. Veale. 2005. “Analogy Generation with HowNet,” in International Joint Conference on Ijcai. 23. LW Ku , WF Chen . 2016. “Chinese Textual Sentiment Analysis: Datasets Resources and Tools,”