2017 3rd International Conference on Computer Science and Mechanical Automation (CSMA 2017) ISBN: 978-1-60595-506-3
Interval-valued Fuzzy Support Vector Machine
Hong-Mei JU
1,a, Qiu-Ling HOU
2,band Ling JING
3,c,*1
College of Science, China Agriculture University, Beijing, China
1
Beijing Wuzi University, Beijing, China
2
School of Management, Qufu Normal University, Rizhao, Shandong, China
3
College of Science, China Agriculture University, Beijing, China
a
[email protected], [email protected], [email protected]
*Corresponding author
Keywords: Classification, Fuzzy membership, Interval-valued fuzzy support vector machine.
Abstract. Since the traditional fuzzy support vector machine (FSVM) hardly distinguishes between the sparse sample points and the dense ones with the same membership, it may further reduce the classification accuracy. In order to solve this problem, by using the fuzzy support vector machine and interval-valued fuzzy set, the interval-valued fuzzy support vector machine is constructed. We call it interval-valued fuzzy SVM (IVFSVM).The simulation experiment shows that the classification result by using the IVFSVM is more accurate than the traditional SVM and the FSVM.
Introduction
The theory of support vector machine (SVM) is a new classification technique and has drawn much attention on this topic in recent years [1–5]. The theory of SVM is based on the idea of structural risk minimization[3]. In many applications, SVM has been shown to provide higher performancethan traditional learning machines [1] and has been introduced as powerful tools for solving classification problems.
There are more and more applications using the SVM techniques. However, in many applications, some input points may not be exactly assigned to one of these two classes. Some are more important to be fully assigned to one class so that SVM can separate these points more correctly. Some data points corrupted by noises are less meaningful and the machine should better discard them. SVM lacks this kind of ability.
For this kind of situation, Lin [6-7] constructed fuzzy support vector machine (FSVM). The input samples are assigned to different membership according to the different contribution to the classification, thereby weakening the influence of noise or outliers on classification. How to determine the membership of the training sample is the key point of FSVM method. At present the commonly used method is using the sample's distance to the center of the cluster to determine the size of the membership [8], but the limitations of this approach is that without considering the close degree among samples. Given 2 kinds of sample points sparse and dense, then the former than the latter are more likely to be outliers. If both the distance from the points to the clustering centers is equal, both are endowed with the same membership, which is thus easy to cause large classification error.
Fuzzy set is the basis of constructing FSVM, which is produced by Zadeh [9] in 1965 and has been widely used in many fields of modern society [10]. However, fuzzy membership of each sample point is only a real number, which can only support or against in practical application in decision-making and so on. So there is certain limit in using only membership of fuzzy sets in some actual problems. Some fuzzy set theories, like intuitionistic fuzzy set theory introduced by Atanassov [11–12], are extensions of the classic fuzzy theory. Another well-known generalization is interval-valued fuzzy set. It was introduced by B. Gorzafczany [13–15].
the distribution of samples in high dimensional space, we determine the interval-valued membership of samples. At last we use SVM to classify the samples after they are processed in an interval-valued fuzzy way[16].
The rest of this paper is organized as follows. A brief review of the theory of FS and IVFS will be presented in Section 2. SVM and FSVM will be described in Section 3. Then the IVFSVM will be derived in Section 4. Experiments are presented in Section 5. Some concluding remarks are given in Section 6. And the acknowledgement will come last.
Fuzzy set (FS) and Interval-valued Fuzzy Set (IVFS)
Definition 1[9]LetXbe a non-empty set,A= <{ x A x, ( )> x∈X}is called a fuzzy set inX.
:X [0,1]
A → , A x( ) is the membership function of Awhich represents the membership of x
belonging toA, and0≤ A x( )≤1.
Definition 2[13]LetXbe a non-empty set,L={ [a,b] 0≤a ≤ b≤1}. A= <{ x A x A x,[ ( ), - +( )>x∈X] is called an interval-valued fuzzy set inX . A: X→L, A x-( )and A x+( )are the interval-valued membership functions ofAwhich represent the membership interval of x belonging toA , and
0≤ A x-( )≤ A x+( )≤1.
Support Vector Machine (SVM) and Fuzzy Support Vector Machine (FSVM) SVM
we briefly review the basis of the theory of SVM in classification problems [2, 3, 4]. Assume that a training set S is given as
1 1
{( , ), , ( l, l)}
S = x y x y (1)
wherexi∈Rn,and yi∈ −{ 1, 1}+ . The goal of SVM is to find an optimal separating hyperplane
0
T
w ⋅x + b = (2)
that classifies training samples correctly or basically correctly, wherew∈Rn, and the scalarb∈R. The separating margin or distance between two parallel planes should be as large as possible. Now to find the optimal separating hyperplane is to solve the following constrained optimization problem
1
1 m in
2
l T
i i
w w C ξ =
⋅ +
∑
s.t. (y wi T ⋅xi+b)≥1−ξi, i=1, 2,,l (3)
0, i 1, 2, ,l
ξ ≥ =
0
C> is a fixed penalty parameter of labeled samples.
With Wolfe theory the primal problem (3) can be transformed to its dual problem
1 1 1 1
1 m ax
2
. . 0
0 , 1, 2, ,
l l l
T i i j i j i j
i i j
l
i i i
i
y y x x
s t y
C i l
α
α α α
α
α
= = =
=
− ⋅
=
≤ ≤ =
∑
∑ ∑
∑
(4)
whereαis the vector of nonnegative Lagrange multipliers of problem (3). All the training vectors
corresponding to nonzeroαiare called support vectors. So
* *
,
condition of problem (4) with its solutionα*. Then any input
xcan be classified according to the
decision function
1
( ) sgn( ( ) )
l
T i i i i
f x α∗y x x b∗ =
=
∑
⋅ + .Sometimes it is unnecessary to askf x( )to be a linear function. In this case, one common strategy is to map the original input space into a high dimensional feature space to find an optimal separating hyperplane in this feature space. The optimization problem corresponding to the problem (4) is as follows
1 1 1
1
1
max ( , )
2
. . 0
0 , 1, 2, ,
l l l
i i j i j i j
i i j
l i i i
i
y y K x x
s t y
C i l
α
α α α
α α = = = = − = ≤ ≤ =
∑
∑∑
∑
(5)where ( , ) ( )T ( )
i j i j
K x x =ϕ x ⋅ϕ x denotes a kernel.
FSVM
In many real-world applications, the effects of the training points are different. It is often that some training points are more important than others in the classification problem. We would require that the meaningful training points must be classified correctly and would not care about some training points like noises whether or not they are misclassified.
That is, each training point no more exactly belongs to one of the two classes. In other words, there is a fuzzy membership associated with each training point. This fuzzy membership can be regarded as the attitude of the corresponding training point toward one class in the classification problem and the value can be regarded as the attitude of meaningless. So the concept of SVM is extended with fuzzy membership and becomes FSVM [6].
Suppose we are given a set of labeled training points with associated fuzzy membership
1 1, 1 ,
{( , m ), , ( ,l l m )}
l
S = x y x y (6) Each training point n
i
x ∈R is given a label { 1, 1} i
y ∈ − + and a fuzzy membership σ ≤mi ≤1with
1, 2, ,
i= l, and sufficient smallσ >0.
Since the fuzzy membership miis the attitude of the corresponding pointxi toward one class and the parameterξi is a measure of error in the SVM, the term miξiis a measure of error with different weighting. The optimal hyperplane problem is then regarded as the solution
1 1 m in 2 l T i i i
w w C mξ
=
⋅ +
∑
s.t. ( T ( ) ) 1 , 1, 2, ,
i i i
y w ⋅ϕ x +b ≥ −ξ i= l (7)
0, i 1, 2, ,l
ξ
≥ =
whereCis a constant. It is noted that a smallermireduces the effect of the parameterξiin problem (7) such that the corresponding point xiis treated as less important.
With Wolfe theory the primal problem (7) can be transformed to its dual problem
1 1 1
1
1
max ( , )
2
. . 0
l l l
i i j i j i j
i i j
l i i i
y y K x x
s t y
α
α α α
α = = = = − =
∑
∑∑
An important difference between SVM and FSVM is that the points with the same value ofαi may
indicate a different type of support vectors in FSVM due to the factormi .The only free parameterC in SVM controls the tradeoff between the maximization of margin and the amount of misclassifications. A largerCmakes the training of SVM less misclassifications and narrower margin. The decrease ofCmakes SVM ignore more training points and get wider margin. Then any
inputxcan be classified according to the decision function
1
( ) sgn( ( , ) )
l
i i i i
f x α∗y K x x b∗
=
=
∑
+ .Interval-valued Fuzzy Support Vector Machine (IVFSVM) Given training sample setS {( ,x y1 1,[µ1−,µ1+]), , ( ,x yl l,[µl−,µl+])}
= ,[ , ]
i i
µ− µ+
is the interval-valued
membership of
x
i, πi µi µi+ −
= − is the interval-valued fuzzy index, 0 1
i i
µ− µ+
≤ ≤ ≤ .
Determine the Center of Clustering We get the center of positive clustering
1 i i y C x l + + =
=
∑
, the center of positive clustering 1 i i y C x l − − =−=
∑
, l +andl−are the number of positive samples and negative samples respectively. Define the Sample Interval-Valued Membership
(1) The distance between the sample points 1,
( ,i j) i j ( 2, , ; 1, 2, , ) D x x = x −x i= l j= l
(2) The density of sample points, the same class sample points and the heterogeneous sample points
(x Ri ) Num x D x x{ j ( ,i j) R}
ρ , = ≤
(x Ri ) Num x D x x{ j ( ,i j) R, yi yj}
ρ+
= ≤ =
,
(x Ri ) Num x D x x{ j ( ,i j) R, yi yj}
ρ−
= ≤ ≠
,
Numrepresents the number of elements in the following set, R is the neighbourhood radius for sample point xiwhich can be adjusted. Obviously, ρ(x Ri ) ρ (x Ri ) ρ (x Ri )
+ −
= +
, , ,
(3) Define the sample interval-valued membership Assume the interval-valued membership of xiis [µi−,µi+]
, then
( , )
ma 1
x ( , )
i
k i
k D x C
D x C
µ−
+
+
= − , ( ) ( )
max ( ) ( ) (1 )
i i k i i i i k
x R x R
x R x R
µ µ ρ ρ µ
ρ ρ
+ +
+ − −
+
= + , ⋅ , −
, , (9)
k
x andxibelong to the same class.
Data Classification Algorithm
1
1
min ( )
2
l T
i i i
i
w w C µ− tµ+ ξ =
⋅ +
∑
+s.t. ( T ( ) ) 1 , 1, 2, ,
i i i
y w ⋅ϕ x +b ≥ −ξ i= l
(10)
0, i 1, 2, ,l
ξ ≥ =
whereCis a constant. It is noted that a smallerµi tµi
− +
+ reduces the effect of the parameter
i
ξin
problem (10) such that the corresponding pointxiis treated as less important.
1 1 1
1
max ( , )
2
l l l
i i j i j i j
i i j
y y K x x
α
α α α
= = =
−
∑
∑∑
1
. . 0
l
i i i
s t αy
=
=
∑
(11)0 αi (µi− tµi+) , C i 1, 2, ,l
≤ ≤ + =
Then any inputxcan be classified according to the decision function
1
( ) sgn( ( , ) )
l
i i i i
f x α∗y K x x b∗ =
=
∑
+ .Experiments
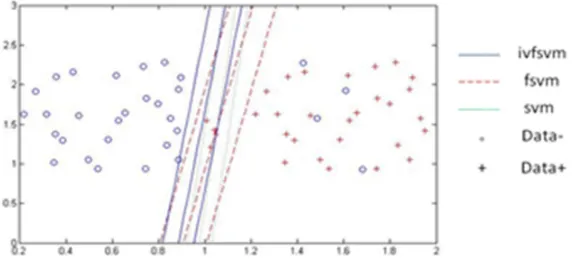
Experiments Using MATLAB Programming Conducted on Artificial Datasets in the PC As shown in fig.1, the experimental dataset is artificial which contains 60 samples with t = 0.7, R=1, C = 0.01. The positive class samples are showed with”+”, while the negative class with””, and the
kernel is linear function. The red line is for interval-valued fuzzy support vector machine, the blue line is for the fuzzy support vector machine and the pink line for support vector machine. We can see from Fig.1, although there are 4 negative samples scattered in class”+”, due to the distance between
[image:5.612.172.461.389.523.2]the other negative samples is larger, they are more likely to be outliers. While there are also 4 positive samples near class””, because they are more closely to each other, they are less likely to become the outliers. The SVM obvious put the 4 positive samples to the negative class; FSVM corrects 1 than SVM but still puts the other 3 to the negative, while IFSVM put the 4 samples totally to the positive, which is more in line with the habits of people's judgment.
Figure 1. Classification results of artificial dataset.
[image:5.612.79.536.612.752.2]Experiments Using MATLAB Programming Language Conducted on UCI Datasets in the PC
Table 1. Mean recognition rates (%), Standard deviations and Time on UCI data sets.
Datasets # Samples #Features svm fsvm ivfsvm
Parkinsons 195 22 84.6599 ±4.9851 84.6862±4.6263 85.7389±5.3354
0.2774 0.2662 0.303
Haberman 306 3 73.5325±0.4759 73.8604±0.9014 73.8551±0.1692
0.884 1.0073 1.3159
Vertebrallia nglei
310 6 79.7452±3.9508 80.6452±3.6780 81.6129±3.7619
1.2871 1.36 1.0142
Fertility 100 9 87.2752±1.9372 88.0752±1.9372 89.0276±1.6982
2.8649 2.8778 2.9205
WPBC 198 34 75.2627±1.0575 76.2692±1.0575 71.2692±10.6682
0.1668 0.1965 0.1766
Hepatitis 155 19 78.3654±1.3419 79.3669±1.3419 80.0121±2.2616
0.1494 0.1494 0.1938
ECH 131 10 86.4650±9.4751 84.8387±4.5500 89.3972±4.8212
0.1424 0.1481 0.168
Spect 267 44 78.3970±0.1883 79.3990±0.1883 80.5241±5.1124
0.4218 0.4559 0.6695
Sonar 208 60 85.0949±3.5589 86.0706±4.1233 85.5833±2.6116
0.6331 0.6989 0.7118
Conclusion
In order to better solve a kind of problem in FSVM, the IVFSVM is introduced in this paper. It comes from IVFS and FSVM which is also a kind of meaningful extension of SVM. Besides the distance from sample to the centre of the cluster, the close degree of the sample is proposed, and then the interval-valued membership of the sample is determined. Since the contribution degree of different samples with the same membership is considered, the effect of outliers is reduced and the accuracy of the SVM classification is improved. Simulation results verify the effectiveness of the proposed algorithm. The application of the algorithm to multi-class pattern recognition is the research direction in the future.
Acknowledgment
This paper was supported by Beijing Key Laboratory (NO: BZ0211) and Beijing Intelligent Logistics System Collaborative Innovation Centre.
References
[1] C. Burges, A tutorial on support vector machines for pattern recognition, Data Mining and Knowledge Discovery, vol. 2(2), 1998.
[2] C. Cortes and V. N. Vapnik, Support vector networks, Machine Learning, vol. 20, 273–297, 1995.
[3] V. N. Vapnik, The Nature of Statistical Learning Theory, New York: Springer-Verlag, 1995.
[4] V. N. Vapnik, Statistical Learning Theory, New York: Wiley, 1998.
[5] B. Schölkopf, C. Burges, and A. Smola, Advances in Kernel Methods: Support Vector Learning. Cambridge, MA: MIT Press, 1999.
[6] Lin C F, Wang S D, Fuzzy support vector machines [J], IEEE Transaction on Neural Networks, Vol.13, 464-471, 2002.
[7] Lin C F, Wang S D, Fuzzy support vector machines with automatic membership setting [J].Studies in Fuzziness and soft computing, Vol.177, 233-254, 2005.
[8] Xiang Zhang, Xiaoling Xiao, Guangyou Xu, Determination and analysis of membership degree in fuzzy support vector machine [J], Journal of image and graphics, 11(8), p1188-1192, 2006.
[9] Zadeh L A. Fuzzy sets [J], Information and Control, Vol.8, p338-353, 1965.
[11] K. Atanassov, Intuitionistic fuzzy sets, Fuzzy Sets and Systems, Vol. 20, pp. 87–96, 1986.
[12] K. Atanassov, Intuitionistic Fuzzy Sets: Theory and Applications, Physical-Verlag, Heidelberg, New York, 1999.
[13] B. Gorzafczany, Approximate Infererce with Interval-Valued Fuzzy sets-an Outline, in: Proc. Polish Symp. On Interval and Fuzzy Math. Poznan, 1983.
[14] Dziech A, Gorzafczany B. Decision Making in Signal Transmission Problems with Interval-valued Fuzzy Sets. Fuzzy Sets and Systems. 1987.
[15] Gorzafczany B. Interval-valued Fuzzy Controller Based on Verbal Model of Object, Fuzzy Sets and Systems, 1988.