2019 International Conference on Computer Science, Communications and Big Data (CSCBD 2019) ISBN: 978-1-60595-626-8
Dynamic and Multi-Match Answer Selection Model for Automobile
Question Answering
Jia-kun ZHAO, Lu-hui LIU
*, Xi ZHANG and Zhen LIU
School of Software, Xi’an Jiaotong University, Shanxi, 710049, China
*Corresponding author
Keywords: Automobile question answering, Dynamic word embedding, Multi-match.
Abstract. Automobile question answering is mainly integrated into the vehicle system to provide users with some common query functions about vehicle questions or instructions. One of the key sub-tasks in automobile question answering system is answer selection. In this paper, we build different neural network QA models with automobile related QA dataset, and improve the basic convolutional neural network answer selection model and the recurrent neural network answer selection model. Finally, we propose to use dynamic word embedding and multiple matching model to build the dynamic and multi-match answer selection model for automobile question answering.
Introduction
With the development of artificial intelligence in recent years, more voice assistant products are produced, such as Siri, Google Assistant, DuerOS, etc. At the same time, more and more car manufacturers have integrated voice assistants into the car navigation entertainment system of the car. At present, the car voice system only provides a simple command control function, it is very important to integrate the common questions such as automobile instruction manual and maintenance manual into the car question answering system, and to provide users with a question answering assistant function. In the process of vehicle question answering system, first of all, the user's voice is used to ask questions, and the voice is converted to text as a question, according to the question, some answers are retrieved by the search engine as a list of answers, such as Lucene. Then the questions are semantically analyzed and the answer list is matched, and the answers are ranked and the answers are scored to return the answers with the highest scores. This paper mainly studies the module of scoring and sorting the answer list, which is called the Answer Selection. It is a key research task in the field of automatic question answering.
Answer selection is given a question and a list of candidate answers, and selects one or more answers through the semantic analysis of questions and answers. At present, the main challenge of answer selection is the problem of semantic mining: on the one hand, the words that appear in the questions do not appear in the answers, and the answer cannot be completed only by matching method; on the other hand, the answers may contain other information, thus affecting the judgment of important information. Using traditional feature engineering to solve semantic problems is often poor to match the sentences, but using neural networks can learn deep features and mine more semantic information. Therefore, this paper mainly studies the ranking of answer selection based on deep learning. Firstly, sentences are expressed in the form of vectors. Distributed vector representation uses unsupervised learning to pre-train a large number of unsupervised tag data, which makes up for the problem of insufficient tag data and learns more abundant semantic information. Then we use neural networks to learn more deep features from tagged data, extract more semantic information and complete the task of answer selection. The main purpose of this paper is to study the feasibility of vehicle Question Answering Based on neural network by constructing different neural network models on the collected dataset such as automobile instructions manuals.
Related Work
Automatic question and answer as a key research content in natural language processing, involving a lot of technology, such as language model, sentence representation, similarity calculation, L2R, neural network and so on. Natural language related technologies and question and answer systems have also received extensive attention in recent years. Hui Yang [1] et al. solve questions that do not contain the same vocabulary in questions and answers by extracting additional features. Suzuki [2] uses the SVM model to solve the question-answer pair matching problem by extracting some vocabulary features and named entity features from the word level. Yu [3] et al. applied convolutional neural networks to the field of natural language processing. Convolutional neural networks are used to encode sentences into vectors of equal length. Meanwhile, translation invariance and combination invariance of convolutional neural networks are used to combine word or word granularity levels, and pooling layer is used to capture longer-distance dependencies to solve the matching problem of answer selection in question answering system. Mikolov [4] et al. proposed word vector coding, which uses unsupervised learning method to learn the information between words in unmarked data of large corpus, and then express it as a fixed vector, which contains all the information of sentences between words. Considering that the word embedding of Word2vec is static and polysemous words are ignored, Peters M E [5] et al. put forward the dynamic word embedding, which largely solves the polysemous phenomenon of words in different contexts. Convolutional neural network ignores the problem of sentence sequence. Ming Tan [6] et al. used the LSTM network that considered the sequence problem to learn the characteristics between sentence pairs to solve the problem matching problem of the non-factual question answering system by modeling the sentence. Dzmitry Bahdanau [7]
et al. improved the machine learning translation model and introduced the ATTENTION mechanism to the NLP field for the first time. In order to solve the problem of machine translation, Vaswani, Ashish [8] et al. a Transformer network structure based on attention mechanism, which solved the problem of slow computation and no parallel in RNN. Jacob Devlin [9] et al. built Pre-training of Deep Bidirectional Transformers for Language Understanding on the basis of ELMO and Transformer, and proposed Masked LM and Next Sentence Prediction to improve the performance of the model, and the model performed best on many NLP tasks.
Relevant Technologies and Approaches
In this part, first of all, I will introduce some related frameworks and technologies as well as commonly used neural networks, then build answer selection models based on CNN, BILSTM, BERT and BIMPMrespectively.
WORD2VEC: Word2vec is a tool developed by Google to convert words into word vectors in the field of NLP. The proposal of Google Word2vec has attracted the attention of academia and industry. Word2vec uses shallow neural network to learn the distributed vector representation of words on a large number of unlabeled data, which makes up for the problem of data shortage. Word2vec uses CBoW model and Skip-gram model to calculate word vector, and use Hierarchical Softmax (Hierarchical Softmax) and Negative Sampling (Negative Sampling) to optimize the speed. In this paper, we use Word2vec to train Chinese Wikipedia, and get the vector representation of words. We use skip-gram to train 300-dimensional word vectors and use them as embedding layer.
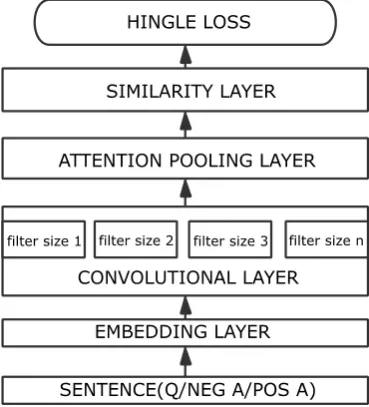
CNN: Convolutional neural network has been widely used in the field of image processing. The characteristics of convolution network are Location Invariance and Compositionality. Similarly, in NLP field, we can define different filters to achieve more distant word information and extract more features. At the same time, we can use the characteristics of convolution pooling to complete the convolution layer mining. In this way, dimensionality reduction is realized and important information is not lost. At the same time, the size of output matrix is fixed, which is beneficial to the processing of upstream tasks. This experiment constructs a question-answer selection model based on multi-layer convolution neural network, which consists of Embedding layer, convolution layer, pooling layer and similarity calculation layer. Embedding layer uses pre-trained word2vec model to convert words into word vectors, essentially converting word vectors represented by one-hot into word vectors with fixed length at low latitudes. The multi-layer convolution network is also used to embedding the questions and answers, which solves the problem that the questions and answers interact on the same level of convolution to a certain extent. Convolutional layer is mainly used to extract features, similar to n-gram, which can extract features between multiple words. Various convolution kernels are also used in this experiment, which is helpful to extract more features between words. Pooling layer: Because of the redundancy of features extracted by convolution layer, these redundancies can be removed by pooling layer, key features can be extracted, dimensionality reduction can be completed and sentences can be expressed as equal-length dimensions. This experiment draws lessons from attention pooling in ABCNN [10], and introduces attention mechanism, which is more conducive to the context interaction at the level of sentence paragraph, and is conducive to extracting deeper features. In similarity computing layer, cosine similarity is used:
1
cos( ) 2 2
1 1
1 2
[image:3.595.204.389.538.742.2]1 2
|| 1||| | 2 || ( 1 ) ( 2 )
n
i i i
n n
i i i i
s s
S S sim
S S s s
(1)S1 and S2 are two sentence vectors, respectively. And hinge loss is defined loss function to train positive and negative sample data of multilayer convolution network, computed as follows:
0, ( , ) ( , )
LOSSMAX MSIM Q A SIM Q A
(2) Where M is margin, Q is the question, A+ is positive answer and A- is negative answer from candidate Answer list. The purpose of this function is to maximize the interval between positive and negative samples. The convolution-based QA model is shown as follows:
BILSTM: CNN focuses on the extraction of extracted features, and has good effects in some natural language processing tasks such as text classification. Circulating neural network (RNN) takes into account the interaction of input at different times and is suitable for processing serialized samples. RNN can better understand the semantic information of the whole sentence as a whole, and has achieved great success in many tasks of natural language processing. As a variant of RNN, LSTM introduces a gate mechanism to selectively save and output historical information, which solves the problem that RNN cannot handle long-distance dependence. However, there is a problem in modeling sentences using LSTM: the information from the back to the front cannot be encoded. BILSTM [10] is composed of forward LSTM and backward LSTM, which can capture the information of the sentence from the back to the front. This paper constructs an answer selection model based on traditional BILSTM, and introduces the Attention mechanism at the sentence level, which extracts more semantic information through the interaction between questions and answers.
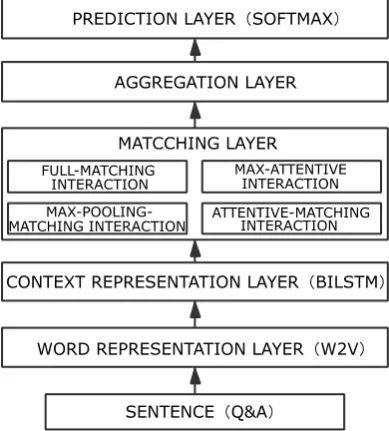
[image:4.595.199.394.542.758.2]BIMPM: There are two types of commonly used deep learning-based sentence similarity judgment schemes. One is based on the SIMAESE network. Usually, two sentence vectors, such as CNN or LSTM, are obtained through a shared weight neural network, and then matched. This method has relatively few parameters and is more efficient to train, but there are some problems, such as fewer interactions between questions and answer sentences. The second one is based on bilateral multi-perspective matching. Firstly, the units between questions and answers are matched. The matching results are transformed into vectors through a neural network and then matched again. To some extent, this way can capture the features of sentence interaction. This paper matches the model from multiple angles to solve the problem of insufficient matching of previous interaction models. This experiment is based on BIMPM's Question Answer Selection Model, which is mainly divided into five steps. The first step is the Word Representation layer, which uses pre-trained word vectors to transform a pair of questions and answers into corresponding word vector representations and serves as the output layer of the model. In the second step, the text representation layer generates the corresponding hidden state sequences for the input question and answer sentences based on BILSTM. The third step is the interactive information layer, which mainly matches the hidden state sequence from the text representation layer and generates the interactive vector sequence. There are four main types of interactive matching: full-matching interaction, max-pooling-matching interaction, attentive-matching interaction and max-attentive-matching interaction. The fourth step is the aggregation layer, which uses BI-LSTM model for two matching sequences through an aggregation layer, and then connects the last time-step vectors (4) of Bi-LSTM to get a fixed length matching vector. Step 5: Prediction layer uses full-connected network to achieve classification prediction.
Experiments
Dataset
The experimental models are evaluated in the automotive question-and-answer dataset. The characteristics of the data set are as follows:
Table 1. Dataset of automobile question answering.
Dataset QA pairs Question Pos Answers Neg Answers
Train 137682 7137 7468 130214
DEV 54815 2915 2979 51836
TEST 33765 1898 2088 31677
ALL 226262 11950 12535 213727
The car Q&A data set mainly consists of a Q&A pair formed by the car instruction manual and the maintenance manual, as well as some other related public question and answer pairs. The data set also contains a series of non-factual questions. Each question corresponds to a list of candidate answers, which is retrieved by a search engine. The list of candidate answers contains or does not contain the corresponding questions, and is organized into a standard format: [Question, Answer, Label].
Evaluation Method
The quality of our QA system is same as ranking, and is evaluated by mean reciprocal rank (MRR), mean average precision (MAP) and Accuracy@1, defined as below:
Accuracy@1: Acc@1 is the ratio of the most correct answer that can be matched to the total number of questions.
| |
i 1
1
@1 ( , )
| |
Q
i i
Acc C A
Q
(3)Where |Q| is the total number of questions, Ci is the correct answer corresponding to question Qi and Ai is the list of candidate answers corresponding to the Qi. (C Ai, i) equals to 1 when Ci has the highest score in the list of candidate answers Ai, and 0 otherwise.
Mean Reciprocal Rank: MRR takes the reciprocal of the order value of the standard answers in the results given by the evaluation system as its accuracy, and then averages all reciprocals.
Mean Average Precision: MAP is a single-valued indicator that reflects the performance of the system on all relevant documents. The higher the relevant documents retrieved by the system (the higher the rank), the higher the MAP may be. If the system does not return related documents, the accuracy defaults to 0.
Performance on the Dataset
[image:5.595.92.507.644.719.2]We use a single-layer CNN as the baseline to build a multi-convolution (M_CNN) answer selection model, a BIMPM answer selection model based on the attention mechanism, a BIMPM answer model and a BERT+BIMPM model. The experimental results on the verification set are show in the following table:
Table 2. The experimental results on the validation dataset.
DEV_DATASET MRR MAP ACC@1
CNN 0.645381 0.648570 0.587416
M_CNN 0.694789 0.691461 0.602113
A_BILSTM 0.715341 0.711355 0.627233
BIMPM 0.828832 0.828412 0.746648
BERT+BIMPM 0.899141 0.899030 0.844742
Results
account the bidirectional sequence and introduces the ATTENTION mechanism, which increases the interaction between the question and the answer and the model MRR has been improved by 8% compared with the CNN model. Compared with M_CNN, the MRR of BIMPM model based on multi-matching is improved by more than about 9%. The performance of the model has been greatly improved, and the MRR has been improved by 11% with combining BERT model and BIMPM model.
Table 3. The experimental results on the test dataset.
TEST_DATASET MRR MAP ACC@1
CNN 0.493609 0.490048 0.401224
M_CNN 0.564730 0.561409 0.482145
A_BILSTM 0.577713 0.572316 0.496213
BIMPM 0.656356 0.652036 0.515551
BERT+BIMPM 0.766594 0.762864 0.650501
Conclusion
In this paper, we build answer selection models based on improved convolutional neural network, answer selection models with attention mechanism based on bidirectional long-term and short-term memory network, BIMPM-based answer selection model and dynamic and multi-match answer selection model on the Chinese car Q&A dataset respectively. Through experiments, it is found that adding more interactive matching information is more conducive to mining deep semantic information between more questions and answer sentences. At the same time, the use of Bert model to introduce dynamic embedding, to a certain extent, makes up for the inadequacy of static embedding, and improves the effect of answer selection model.
Next Step Plan
This paper mainly builds a vehicle question-and-answer model based on in-depth learning through the recently popular neural network model. The next step is: 1. Research and collect more data to train a general question-and-answer model for different types of vehicles. 2. Combine more traditional feature engineering to study the application of feature-based and deep learning combined with supervised and unsupervised learning in the field of question and answer. 3. Through the study of Bert model, the next research work of deep model in NLP is explored.
References
[1] Yang H , Chua T S , Wang S , et al. Structured Use of External Knowledge for Event-based Open Domain Question Answering[J]. 2003.
[2] Suzuki J, Sasaki Y, Maeda E. SVM answer selection for open-domain question answering[C]// Proceedings of the 19th international conference on Computational linguistics-Volume 1. Association for Computational Linguistics, 2002: 1-7.
[3] Yu L, Hermann K M, Blunsom P, et al. Deep learning for answer sentence selection[J]. arXiv preprint arXiv:1412.1632, 2014.
[4] Mikolov T, Sutskever I, Chen K, et al. Distributed Representations of Words and Phrases and their Compositionality[J]. Advances in Neural Information Processing Systems, 2013, 26:3111-3119.
[5] Peters M E, Neumann M, Iyyer M, et al. Deep contextualized word representations[J]. 2018.
[6] Tan M, Santos C D, Xiang B, et al. LSTM-based Deep Learning Models for Non-factoid Answer Selection[J]. Computer Science, 2016.
[8] Vaswani A, Shazeer N, Parmar N , et al. Attention Is All You Need[J]. 2017.
[9] Devlin J, Chang M W, Lee K, et al. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding[J]. 2018.