P a g e | 986 B.Arathi
Assistant Professor, Dept of Computer Science and Engineering Kamala Institute of Technology and Science, karimnagar, Telangana, India.
ABSTRACT: Internet of Things is now an accelerating generation inside the international of devices. It allows us join allthe gadgets which we use in our daily chores thru the internet. Starting from home, office, enterpriseautomation to fitness care and clever towns internet of things has revolutionized the arena via interconnectingthem To many, the massive records generated or captured by means of IoT are taken into consideration having exceptionallyuseful and treasured data. Data mining will absolute confidence playa important position in making this kind of system smart sufficient toprovide greater convenient services and environments. This paperstarts offevolved with a dialogue of the IoT.
KEYWORDS-Data mining, Internet of things, Knowledge Data Discovery.
I. INTRODUCTION
The Internet of Things (IOT) and its relatedtechnology can seamlessly integrate classicalnetworks with network instruments and devices. Thedata inside the Internet of Things can be labeled intonumerous sorts like RFID statistics circulation, address identifiers,descriptive data, positional records, surroundings factsand sensor community records and so forth. [1]. Today, IOT bringsthe first-rate challenges for coping with, analysing andmining data. In IOT structures, records finemanagement is a critical era to provide highquality and trusted data to enterprise-level evaluation,optimization and choice making. In order toenhance excellent of data, anomaly detectiontechniques are widely used to eliminate noises andmisguided data. For anomaly detection, having greaterinformation manner it’s less difficult to stumble on an uncommon occasionagainst the historical past of everyday activities [3].Data Clustering refers to grouping of data basedon particular capabilities and its cost. In IOT, Dataclustering is an intermediate step for
identifyingstyles from the collected data. It’s most commonmethod in unsupervised gadget learning. Clusteringstrategies are divided into 4 primary categories includingpartitioning strategies, hierarchical techniques, densitybased techniques and grid based strategies. Otherclustering strategies also exist inclusive of fuzzyclustering, synthetic neural network and establishedalgorithms.
The hassle of Data category is said asgiven a hard and fast of education records factors at the side ofassociated label for an unlabelled check times.Classification set of rules incorporate 2 phases one is Trainingsegment and other is Testing phase. On the basis of education dataset, segmentation is done which encodes understandingabout the structure of the groups in form of goalvariable. Thus class problem is known assupervised learning.The function choice is the procedure used toidentified sample and allows us to perceiveattributes that have an effect on satisfactory index the most. Aftera few initial degree of test characteristic selection ismost efficient, identify what are attributes that influences aspecific trouble most and then carry out recordsclass, time series prediction or anomalydetection more without problems as it lessen the dimensionalityin mining the problem. Features choice is to discover afirst-rate feature subset from the candidate featureset, in order that to attain an ideal type accuracyand computing complexity manipulate.A time collection is series of temporal dataobjects, which incorporates traits consisting of: massivestatistics length, excessive dimensionality, and updatingcontinuously. Representation, similarity measuresand indexing are 3 additives of time collection missionis predicated on. Time collection representation reduces thedimension and it divides into three classes: modelprimarily based illustration, non-adaptive statisticsillustration and adaptive records representation. Thesimilarity degree is completed in right mannertogether with: studies directions consist of subsequencematching and full subsequence
Amended Data Mining for Various Internets of Things
P a g e | 987 matching. Theindexing of time series is linked with
representationand similar measure tools [2].
We live in a world where the speed with which thebusiness needs to move is much faster than the time ittakes to conceive and launch new solutions in theareas of big data, data mining, cloud, and IoT [3]. Tofind relatively small chunks of data in peta byte sizeddatabases generated from an IoT system is likelooking for a black cat in a coal cellar. To get in thegame, variety of data mining algorithms should bebuilt with various capabilities to get insights andreduce the risk of project failures. Till today there aremany studies which have been trying to solve theproblem of acquiring of big data on IoT systems.Most of the mining techniques are developed toexecute on a single system, so these KDD systemscannot be applied directly to process big data of theIoT system, whereas for a small system undoubtedlythese KDD processes can be applied directly.
To develop a high geared data mining structure ofKDD for an IoT system the following three points [5]are to be considered to elect the suitable miningtechnology, and they are –
• First and the foremost it is essential tounderstand the definition of the problem,their limitations and required informationand so forth.
• Secondly, the major concern would be tounderstand what kind of data is to berequired like the representation, size ofdata, processing of different data etc.,
• Thirdly on the basis of the abovementioned points, a suitable data miningalgorithm is to be chosen to bring outsensible and required information fromthe raw data.Further the types of data mining algorithms arebeing explained.
II. RELATED WORKS
Classification: It is a function of datamining that
delegates items intocategorical labels. It helps us to predict thecategory of a particular item in a dataset.
Let’s consider a scenario where amarketing manager of an automobilecompany wants to analyze the probabilityof a customer buying a type of car on thebasis of his/her profile. A classificationmodel can
be utilized to predict the typeof car; family, sports, truck or van, that acustomer is likely to buy on the basis ofhis/her age and family background.There are various classification modelssuch as decision tree, neural networks, IF -THEN rules depending upon their use.
• Clustering: Unlike classification,clustering is
typically defined ascategorizing the data into some sensible,meaningful groups or classes. This helpsto achieve an easy perceptive for the usersby grouping naturally. The best examplefor this could be a search engine which isbased on clustering, that can categorizeendless web pages into news, images,videos, reviews etc.,There are various clustering models suchas kMeans clustering, k-Medoidsclustering, Densitybased clustering andHierarchical clustering that can be useddepending upon their use.
• Association Analysis: Market basket is thebest
relatable module to association.Market basket analysis is observedroutinely in supermarket chains where theitems which are likely to be boughttogether with another set of items arealways placed together such as toothbrushand toothpaste are always in the samesection. This helps in decision making. Atfirst the data is processed incessantly, forfirst catalog of association analysis.
To discover inter transactional associationapriori algorithm has been used followedup with association discovery. Otheralgorithms used are pattern growth, eventoriented, event-based, partition based, FPGrowth, Fuzzy set and incrementalmining.
• Time Series Analysis: When data pointsare present
in consecutive time interval,time series analysis is applied to extractmeaningful related to specific patterns orstatistics. Stock market index value isanalyzed in a time series manner. Timeseries analysis is also used in forecasting,to analyze dependent events; that is topredict future values based on past events.
• Outlier Detection: Intermittently thereexists a data
P a g e | 988 of outliers.Outlier analysis can be used to
extrapolateoutliers, to calculate distance amongobjects, distribution of input space.The above mentioned data mining functionalities withthe listed algorithms are the most commonly usedalgorithms in any field to mine the data and extractthe required information
III. APPROACH
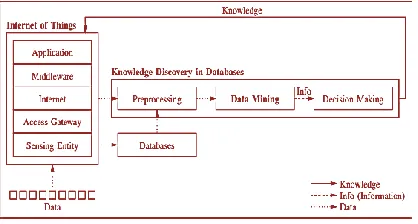
As depicted in Fig. 1, IoT collects data from different sources, which may contain data for the IoT itself. KDD, whenapplied to IoT, will convert the data collected by IoT intouseful information that can then be converted into knowledge.The data mining step is responsible for extracting patternsfrom the output of the data processing step and then feedingthem into the decision making step, which takes care oftransforming its input into useful knowledge. It is important tonote that all the steps of the KDD process may have a strongimpact on the final results of mining. For example, not all theattributes of the data are useful for mining; so, feature selectionis usually used to select the key attributes from each record inthe database for mining.
Fig. 1. The architecture of IoT with KDD The consequence is that data miningalgorithms may have a hard time to find useful information(e.g., putting patterns into appropriate groups) if the selectedattributes cannot fully represent the characteristics of the data.It is also important to note that the data fusion, large scaledata, data transmission, and decentralized computing issuesmay have a stronger impact on the system performance andservice quality of IoT than KDD or data mining algorithmsalone may have on the traditional applications.The relationships between big data, KDD, and data miningfor IoT will be discussed in this section. A simple model fordetermining the applicable mining technologies and a briefintroduction to the well-known data mining technologies forIoT will also be given in this section,
by using a unified datamining framework and a few simple examples. After that, adetailed analysis and summarization of mining technologiesfor the IoT will be given.
A. Basic Idea of Using Data Mining for IoT
It is much easier to create data than to analyze data. Theexplosion of data will certainly become a serious problemof IoT. Until now, a numerous studies [14], [15], [16], [17]have attempted to solve the problem of inquiring big dataon IoT. Without effective and efficient analysis tools, we,and all the systems, will definitely be submerged by thisunprecedented amount of data. When KDD is applied toIoT, from the perspective of hardware, cloud computing and relevant distributed technologies are the possible solutionsfor big data; nevertheless, from the perspective of software,most mining technologies are designed and developed to runon a single system. In the circumstances of big data, it isalmost certain that most KDD systems available today andmost traditional mining algorithms cannot be applied directlyto process the large amount of data of IoT. Generally speaking,either the preprocessing operator of KDD or the data miningtechnologies need to be redesigned for IoT that can produce alarge amount of data. Otherwise, the data mining technologiestoday can only be applied to small scale IoT system that canproduce nothing but a small amount of data.To develop a high-performance data mining module of KDDfor IoT, the three key considerations in choosing the applicablemining technologies for the problem to be solved by the KDDtechnology—the objective, characteristics of data, and miningalgorithm—are as given below.
• Objective (O): The assumptions, limitations, and
measurements of the problem need to be specified first so asto precisely define the problem to be solved. With thisinformation, the objective of the problem can be madecrystal clear.
• Data (D): Another important concern of data
P a g e | 989
• Mining algorithm (A): With needs (objective) and
dataclearly specified above, data mining algorithm can beeasily determined, as to be discussed.Whether or not to develop a new mining algorithm can beeasily justified by using these factors. For instance, from thecharacteristics of data, if the amount of data exceeds thecapability of a system and if there is no feasible solutionto reduce the complexity of the data, then a novel miningalgorithm is definitely needed; otherwise, the current miningalgorithm suffices. Another consideration is related to theproperty and objective of the problem itself. If a novel miningalgorithm can enhance the performance of a system, thenthe new mining algorithm is also needed. An example isthe clustering algorithm for a wireless sensor network, whichneeds to take into account the load of computation, but mosttraditional clustering algorithms simply ignore this issue.Now that the objective of the problem is decided, the characteristics of the input data are understood, and the particulargoals of mining and the mining algorithms are chosen, aunified framework is presented here and used throughout therest of the paper to describe all the mining algorithms presented in this paper to provide the audience a systematic wayto understand data mining algorithm.
As Algorithm 1 shows, the framework employsthe following operations: initialization, data input and output,data scan, rules construction, and rules update. Note that inAlgorithm 1, D represents the data; d the data read in bythe scan operator; r the rules selected by the rules updateoperator; o the predefined measurement for the objective ofthe problem; and v the candidate rules created by the rulesconstruction operator. To simplify the descriptions that follow,the core operators—data scan, rules construction, and rulesupdate—will be denoted by S, C, and U, respectively.
As shown inAlgorithm 2, first, a set of centroids c are created randomlyto represent how the input patterns are divided into differentgroups. Then, the
assignment operator will compute the distances between patterns and centroids to find out to which group each pattern belongs. Because this operator needs toscan all the input patterns so as to assign each pattern tothe group to which it belongs, it plays the role of scanningthe patterns and constructing the candidate rules. The updateoperator plays the role of updating the centroids after allthe patterns are assigned to the groups to which they belongby the assignment operator.
As shown in Algorithm 3,most of the traditional classification algorithms, ID3, C4.5,and C5.0, are widely used in constructing the decision treeof a classifier; that is, each branch representsa test or check for partitioning the patterns. This impliesthat the information (e.g., entropy and diversity) required for constructing the decision tree needs to be computed ateach iteration. This in turn implies that decision tree-basedalgorithms need the scan operator of Algorithm 3 to readthe information contents of input patterns. In the constructionphase (i.e., the split operator on line 5 of Algorithm 3), thedecision node of a classifier is created based on the labeledpatterns and the information contents. After the scan andconstruction operators finish their tasks, the decision tree willthen be updated.
IV. CONCLUSION
P a g e | 990 on the size of eachmining technology and of the
general included gadget areadditionally given.It is often the case that theattention is first at the improvement of green preprocessingmechanisms to make the IoT machine capable of managingmassive statistics and then at the improvement of effective miningtechnology to discover the policies to describe the records of IoT.
REFERENCES
[1] Shen Bin , Liu Yuan* , Wang Xiaoyi*,Ningbo Institute of Technology, ZhejiangUniversity Ningbo, China, College ofManagement, Zhejiang UniversityHangzhou, China on ―Research on DataMining Models for the Internet of Things‖in IEEE 2010.
[2] Joshua Cooper and Anne James on―Challenges for Database Management inthe Internet of Things‖ in IETETECHNICAL REVIEW, Researchgate.net SEPTEMBER 2009.
[3] Feng Chen , Pan Deng, Jiafu Wan, DaqiangZhang,Athanasios V. Vasilakos and XiaohuiRong on ―Data Mining for the Internet ofThings: Literature Review and Challenges‖.
[4] D. Miorandi, S. Sicari, F. De Pellegrini, and I. Chlamtac, ―Internetof things: Vision, applications and research challenges,‖ Ad HocNetworks, vol. 10, no. 7, pp. 1497–1516, 2012.
[5] M&M Research Group, ―Internet of Things (IoT) & M2M communication market - advanced technologies, future cities & adoptiontrends, roadmaps & worldwide forecasts 2012-2017,‖ Electronics.caPublications, Tech. Rep., 2012.
[6] D. Bandyopadhyay and J. Sen, ―Internet of things: Applicationsand challenges in technology and standardization,‖ Wireless PersonalCommunications, vol. 58, no. 1, pp. 49–69, 2011.
[7] M. C. Domingo, ―An overview of the internet of things for people withdisabilities,‖ Journal of Network and Computer Applications, vol. 35,no. 2, pp. 584–596, 2012.
[8] M. Palattella, N. Accettura, X. Vilajosana, T. Watteyne, L. Grieco,G. Boggia, and M. Dohler, ―Standardized protocol stack for the internetof
(important) things,‖ IEEE Commun. Surveys Tutorials, In Press,2013.
[9] R. Kulkarni, A. Forster, and G. Venayagamoorthy, ―Computationalintelligence in wireless sensor networks: A survey,‖ IEEE Commun.Surveys Tutorials, vol. 13, no. 1, pp. 68–96, 2011.
[10] T. S´ anchez L´ opez, D. C. Ranasinghe, M. Harrison, and D. Mcfarlane,―Adding sense to the internet of things,‖ Personal and UbiquitousComputing, vol. 16, no. 3, pp. 291–308, 2012.
[11] F. Siegemund, ―A Context-Aware communication platform for smartobjects,‖ in Proc. International Conference on Pervasive Computing,2004, pp. 69–86.
[12] G. Kortuem, F. Kawsar, V. Sundramoorthy, and D. Fitton, ―Smartobjects as building blocks for the internet of things,‖ IEEE InternetComputing, vol. 14, no. 1, pp. 44–51, 2010.
[13] T. S. L´ opez, D. C. Ranasinghe, B. Patkai, and D. C. McFarlane,―Taxonomy, technology and applications of smart objects,‖ InformationSystems Frontiers, vol. 13, no. 2, pp. 281–300, 2011.
[14] V. Cantoni, L. Lombardi, and P. Lombardi, ―Challenges for data miningin distributed sensor networks,‖ in Proc. International Conference onPattern Recognition, vol. 1, 2006, pp. 1000–1007.