Available online: https://edupediapublications.org/journals/index.php/IJR/ P a g e | 698
A Personalized Search Engine with Secure Data Storage in
Cloud
Nambi Vikramaditya & P.Sanjeeva
PG Scholar, Dept of CSE, Associate Professor, Dept of CSE,
[email protected]
,
[email protected]
,
Malla Reddy Engineering College (Autonomous),
Secundrabad, Telangana, India.
Abstract:
A personalized search engine has been playing an increasingly vital role in today’s web search engines. Many systems are already using these services. However, these proposed paper deals with the personalized web systems.User profiles supported philosophy thus manufacturing linguistics applications with made to order services.The primary step of the approach is to extract the selections from internet documents and constructing relevant concepts. The planned approach integrates linguistics info into internet usage mining personalization process.
Index Terms:
Web page recommendation, Web Mining, a semantic network, domain Ontology.
Introduction:
Domain information of the web application at the interval type of philosophy can play a vital role in giving smarter and require information to systems. Both net Usage Mining and linguistics net have combined and introduced a fresh and fast rising analysis area - linguistics net Mining. The linguistics net relies on a vision of Tim Berners-Lee, the creator of the online. The linguistics net enriches the online by machine methodology, prepared information that supports the user in accomplishing his tasks further merely [6]. The observation of a linguistics net has recently drawn vital attention every from the tutorial and industrial circles. As a result of the upper than issues, there is Associate in the Nursing high effort in method websites, objects regarding of linguistics
information to practice philosophy. This web service provides a completely distinctive methodology to give more net page recommendation supported internet usage and domain info, that's supported by three new info illustration models and a bunch of Web-page recommendation ways: 1 ) Associate in the Nursing ontology-based model that provides the domain info of an online website. The event of this model is semi-automated so as that the event efforts from developers are going to low. 2) The second model could also be linguistics network that shows domain info, whose construction is going to be completely automatic. It’s going to be merely incorporated into web-page methodology due to it automatic feature. 3) This model could also be an abstract prediction model, this will be a map network of domain terms supported the off times viewed internet-pages. The recommendation ways build domain uses info and additionally the prediction model through a set of the 3 models to predict consecutive pages with potentialities for a given net user supported his or her current Web-page position state. An honest extent, this methodology is automatic the content erection and eased the new-page downside as provided above. Some models, like ordered modeling, have shown their vital effectiveness on recommendation generation. Some research, have displayed that tree-based algorithms, notably Pre-Order coupled WAP-Tree Mining area unit excellent in supporting Web-page recommendation, compared with various sequence mining algorithms. Moreover, blending of PLWAP Mine and therefore the increasing-order Andre Mark off model can considerably value of mining performance
Available online: https://edupediapublications.org/journals/index.php/IJR/ P a g e | 699 • The data discovery from net usage data and data
illustration for strongly recommended web pages have square measure troublesome.
• It provides efficient and the higher internet-page recommendation through the linguistics is sweetening to group by the action of a domain and net usage data of a website.
•The first model uses philosophy to illustrate the domain data. The second model uses one automatically produce linguistics network to explain domain terms, Web-pages and thus connection between them. Another new model, as an abstract of estimate model to planned in an automatically produce a linguistics network of the linguistics net usage data, that's that the mixing of domain data and net usage data.
• The variety of queries are developed to question regarding these databases. Supported these queries, as a gaggle of recommendation ways that are planned to be urged by the Web-page persons. The recommendation results should be compared with a sophisticated previous netusage Mining technique.
Disadvantages:
• The Existing system performance depends on the sizes of the coaching job datasets. The larger is predicted as unit page restricted within the discovered web access sequences.
• The domain philosophy is created manually by specialists, or automatically learned by the models which are compelled to vogue to implement the coaching models which are done by professionals at the beginning.
Proposed system:
In planned system gifted by a personalized system makes use of representation of things user-profiles supported metaphysics thus produce linguistics applications with personalized services.
The linguistics technique achieved by victimization utterly two different methods. A domain-based skill which makes inferences concerning about user interests and a taxonomy-based same skill has utilized to clear the user matching rule increase overall the results. The recommended user planned to be domain-independent, which is implemented as a web service.
The projected recommended system supported the philosophy and net Usage Mining. The first step of
the approach is extracting choices from net documents and constructing relevant ideas. Then build it for internet web site use the concepts and main terms take out from documents. Per linguistics similarity of net documents to cluster them into varied them simply different preferences.
Advantages:
• Integration domain information with net usage enhances the performance of recommended systems exploitation based on ontology mining techniques. • The development of this model is semi-automation, therefore the developer efforts could also be reduced. • The user-profile learning rule, accountable for increasing and maintaining date-to-date for the long user interests and employs a domain-based reasoning technique for conjunction in various connection feedback methods to populate lots of faster the user profile.
• The filtering rule follows a stemming approach that makes use a linguistics same as technique supported by the information structure of philosophy to clear the calculation of item-user matching score.
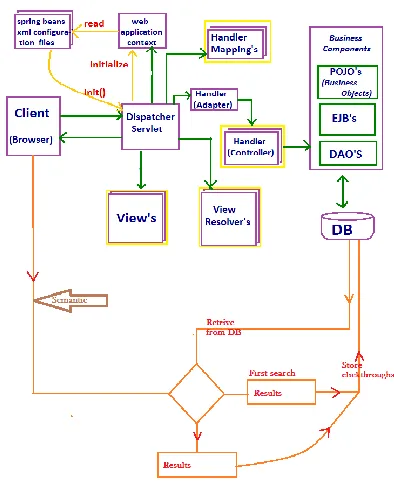
System design:
figure : Proposed method
Available online: https://edupediapublications.org/journals/index.php/IJR/ P a g e | 700 Bringing Order to Web: mechanically Classified Search
Results:
The model was accustomed classify new websites came from search engines on-the-fly. This model has the advantage of investment far-famed.
User goals are automatically identified in internet search:
In this method,the automatic goal-identification methodology was reviewed. First our results from a person's subject study that powerfully indicates the practicability of automatic query-goal identification. The Query Recommendation victimization question Logs in Search Engines:
The paper suggested that, when the given content is submitted with a bug, suggests a listing of connected queries. The linked queries are unit primarily based in previously issued queries and will be given by the user to the pc program to tune or art the search methodology.
Varying Approaches to Topical internet question Classification:
I have a tendency to discover that employment expressly from categorized queries outputs unite for document taxonomy from the employment of the high quantity.
The Context-Awareness question Suggested by the Mining Click-Through the Session Data:
The proposed paper contains bent a distinctive context-aware question suggestion approach that's in a pair of steps. At intervals of the online model-learning method, to handle data poorness, queries area unit summarized into concepts by the bunch a click-through bipartite.
Modules:
1. Build Search history 2. Query congregate 3. Query Explicate 4. Grouping
Build search history:
The User profile provides personal documents like browsing history and emails on user’s laptop. These concentrate constant terms with limits the property of document set that additionally gives the full information of users’ interest. The module permits pc program to be raise understands by a user session.
Once question group area of a unit far-famed, from the search engines can have a good illustration for search context behind this question victimization queries and click inside corresponding question cluster.
Query congregate:
The user queries are categorized into utterly different question clusters. The Concept-based on user profile as a unit of measurement which would be used in the cluster techniques to a better result. The foremost similar attempt of conception node and then merge foremost same as the previous node. Every individual question submitted by user treated as a personal question with a user image. Later,inclined to perform the grouping throughout the same dynamic fashion, whereby an inclination to the first place of a current question then clicks an issue cluster.
Query Explicate:
Available online: https://edupediapublications.org/journals/index.php/IJR/ P a g e | 701 click on same URLs. The Question Explicate graph
and thus question click graph from search and also thanks to using them to figure out the connection between queries and question groups at the history of user’s.
Grouping:
Query groups treat every question in associate passing user’s history as an issue cluster then combine these question groups in associate repetitive mode. This could be unrealistic in the state of affairs for two reasons:
1) It's attending to have the unpleasant impact of fixing a user’s existing question group, most likely conquest the user’s own manual efforts in organizing history.
2) It involves a high-estimation value, suppose need to recap associate big varying question cluster same as estimated for every question.
Conclusion:
A singular approach has projected to infer user search goals for an issue by a bunch its feedback sessions portrayed by pseudo-documents. Firstly, an inclination was carried out display feedback sessions to analyze the user search goals rather than using search bars or URLs. Since feedback sessions can replicate using user information require plenty of efficiently. Secondly,an inclination was carried out for map feedback sessions to the pseudo-documents have appropriate texts in user minds. The pseudo-documents can enrich their URLs with more content
in conjunction with titles and snippets. Finally, the main Stemming was replaced to develop the analysis of user performance. To enrich the quality low standard and to approach utilized merely. The fundamental measurement depends on the number of feedback sessions. Since the fundamental measure is low. The approaches can be discovered in user search goals, a couple of common places the queries may disappear at the start. User commits one of each queries, the program may result into a different groups.
References:
[1] B. Liu, B. Mobasher, and O. Nasraoui, "Web Usage Mining," in Web Data Mining: Exploring Hyperlinks, Contents, and Usage Data, B. Liu, Ed.: Springer-Verlag Berlin Heidelberg, 2011, pp. 527-603.
[2] B. Mobasher, "Data Mining for Web Personalization," in The Adaptive Web. vol. 4321, P. Brusilovsky, A. Kobsa, and W. Nejdl, Eds.: Springer-Verlag Berlin, Heidelberg, 2007, pp. 90-135.
[3] G. Stumme, A. Hotho, and B. Berendt, "Usage Mining for and on the Semantic Web," AAAI/MIT Press, 2004, pp. 461-480.
[4] H. Dai and B. Mobasher, "Integrating Semantic Knowledge with Web Usage Mining for Personalization," in Web Mining: Applications and Techniques, A. Scime, Ed. Hershey, PA, USA: IGI Global, 2005, pp. 276 - 306.
[5] S. A. Rios and J. D. Velasquez, "Semantic Web Usage Mining by a Concept-Based Approach for Off-line Web Site Enhancements," in Web Intelligence and Intelligent Agent
Technology, 2008. WI-IAT '08.
IEEE/WIC/ACM International Conference on, 2008, pp. 234-241.
[6] S. Salin and P. Senkul, "Using Semantic Information for Web Usage Mining based Recommendation," in 24th International Symposium on Computer and Information Sciences, 2009., 2009,
Available online: https://edupediapublications.org/journals/index.php/IJR/ P a g e | 702
[7] A. Bose, K. Beemanapalli, J. Srivastava, and S. Sahar, "Incorporating Concept Hierarchies into Usage Mining Based Recommendations," in Proceedings of the 8th Knowledge discovery on the web international conference on Advances in
web mining and web usage analysis
Philadelphia, PA, USA: Springer-Verlag, 2007, pp. 110-126.
[8] N. R. Mabroukeh and C. I. Ezeife, "Semantic-Rich Markov Models for Web Prefetching," in 2009 IEEE International Conference on Data Mining Workshops Miami, Florida, USA, 2009, pp. 465-470.
[9] M. O'Mahony, N. Hurley, N. Kushmerick,
and G. Silvestre, "Collaborative
recommendation: A robustness analysis," ACM Transactions on Internet Technology, vol. 4, pp. 344-377, 2004.
[10] G. Stumme, A. Hotho, and B. Berendt, "Semantic Web Mining: State of the art and future directions," Web Semantics: Science, Services and Agents on the World Wide Web,