`
93
Image Re-Ranking Based Image Retrieval Using Visual Highlights
And Snap Highlights Methods
Dr.J.Lekha
1Assistant Professor
Department of Computer Science and Applications Sri Krishna Arts and Science College
N.Sathyapriya
2, A.Abarna
3, CK.Vigneswaran
4*
Student Department of Computer Science and Applications
Sri Krishna Arts and Science College
Abstract: The irregularity between printed highlights and visual substance can cause poor picture as a result of image queries. To handle this issue, click highlights, which are more dependable than printed data in legitimizing the significance between an inquiry and clicked pictures, are received in picture positioning model. The current positioning model cannot incorporate visual highlights, which are effective in refining the snap based query items. In this paper, we propose a novel positioning model dependent on the figuring out how to rank structure. Visual highlights and snap highlights are the significant methods used to get the positioning model.The proposed methodology depends on substantial edge organized yield learning and the visual consistency which is incorporated with the snap includes through a hyper graph regularized term. As per the quick rotating linearization strategy, we plan a novel calculation to enhance the picture quality. This calculation also limits two distinct approximations of the first target work by keeping one capacity unaltered and linearizing the other. The proposed method uses a substantial scale dataset gathered from the Microsoft Bing picture web index, and the outcomes show that the proposed method figureout how to rank models depending on visual highlights and client clicks which beats best in class calculations.
Parameters: time, performance, re-rank
Keywords: Image search, Re-ranking, Novel positioning model, Picture positioning model, Visual highlights
1. INTRODUCTION
Despite the fact that people will be generally connect pictures with abnormal state ideas, the present PC vision systems extricate from pictures for the most part low-level highlights and the connection between low-level highlights and abnormal state semantics of picture content is lost. Neither a solitary low-level component nor a mix of different low-level highlights has express semantic importance all together. The comparability measures between visual highlights do not really coordinate human discernment, along with that, recovery after effects of low-level methodologies are commonly unacceptable and regularly flighty. This is what is known as the semantic hole: the absence of unexpected event amid the data that one can eliminate from the visual information and the translation that similar information have for a client in a given situation. Nonetheless, the recovery procedure bombs additionally because of the tactile hole: the hole between the item on the planet and
`
94
increasingly solid idea affiliation. Notwithstanding, thedimension of accomplishment in these endeavors is faulty; a purpose behind this lies in the sparsity of the per-picture watchword explanation gives information in contrast with the quantity of catchphrases that are generally relegated to records. We present the Markovian Semantic Indexing (MSI), another strategy for programmed explanation and comment based picture recovery.
2. RELATED WORK
Development in substance based recovery has been undeniably fast. In the ongoing years, in excess of 200 substance based recovery frameworks have been produced [5], most of which depend on low dimension highlights. Specifically, they can be arranged into two fundamental classes: 1) those that perform semantics mining dependent on the investigation of printed data related to pictures, for example, comments, relegated watchwords, subtitles, elective (alt) message in html pages or encompassing content, and 2) those that depend on the extraction of low-level visual highlights, for example, shading, surface so as to perform arrangement, characterization, perusing, looking, rundown, and so forth in picture accumulations. Techniques for the principal class rely upon difficult explanation, while the last strategies mostly cannot successfully catch semantics. Moreover, some different systems utilize both low-level highlights as visual catchphrases [6] and content explanation to perform content-based tasks. Yet for the most part of they request the unequivocal association of clients for phonetic comment of pictures [7], [8]. Explanation Based Image Retrieval frameworks join progressively proficient semantic
substance into both content based inquiries and picture subtitles. An immediate outcome is that, strategies at first produced for archive recovery might be appropriate for ABIR frameworks, also. Inactive Semantic Indexing [9] was at first created for record recovery. Hofmann, in view of the Aspect Model [10] presented the probabilistic Latent Semantic Indexing (pLSI) [11] as an option in contrast to projection (LSI) or grouping strategies for report recovery. Latent Dirichlet Allocation (LDA) was proposed by Blei et al [12] to address the restrictions of pLSI with respect to speculation and overfitting while Griffiths and Steyvers consolidated a Markov tie Monte Carlo system to LDA [13]. Steyvers presented another probabilistic model speaking to the two creators and subjects in archive recovery, and consolidating Gibbs inspecting to defeat overfitting issues [14].
3. OUR SYSTEM MODEL
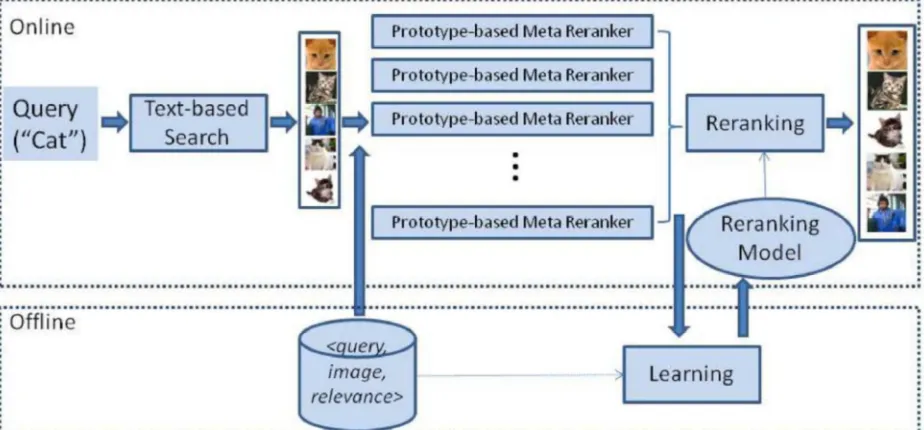
Our proposed methodology is the blend of both Circular re-ranking and Time-based re-re-ranking to enhance the picture recovery accuracy. The thorough framework design of the proposed framework is shown as a square graph in Figure 1. Right off the bat, we have a picture Dataset on which the picture recovery and re-ranking is performed. The list items of Bing and Google web crawlers and contains in excess of 10,000 pictures of 51 inquiries that cover discrete visual ideas as recorded in Figure 2. In the investigation led, the best 40 pictures are re-ranked, since practically speaking not many significant pictures could be discovered while going further into the rundown. We play out the accompanying capacities on the Dataset: Retrieving pictures from dataset, Circular ranking and Time-Based Re-ranking.
[image:2.612.74.536.472.687.2]
`
95
3.1 Roundabout Re-rankingRoundabout re-ranking [1], underlines the shared trade of data over numerous modalities for enhancing look execution, underwriting the rationality that solid performing methodology can gain from more fragile ones, while feeble methodology benefits from communicating with more grounded ones. In fact, roundabout re-ranking conducts various running of arbitrary strolls [17], through trading the positioning scores among various highlights in a cyclic way. Roundabout Re-ranking calculation continues with the accompanying three stages recorded.
3.2 Random strolls:
In the actualized framework, irregular walk signifies the underlying indexed lists showed on the landing page. Here, the underlying list items are acquired utilizing content inquiry, for example single question or watchword (record name) is sought and every one of those pictures relating to the catchphrase is recovered from the dataset of pictures.
3.3 Mutual fortification:
This progression trades methodology spaces in a pairwise way for irregular strolls. Here, literary portrayal of pictures in the dataset are utilized and is joined with the underlying question for looking. As a conclusion, multiple watchword look ends up possibly in the round re-ranking technique for social event enhanced and increasingly exact picture list items.
3.4 Roundabout re-ranking:
The last advance in roundabout re-ranking iteratively refreshes the picture positions by roundabout common fortification. Here, three modalities are joined for acquiring exact outcomes in picture look. Notwithstanding, the inquiry and content space referenced before, shading space is likewise consolidated for acquiring last re-ranked result. In contrast to the literary modalities, shading highlight is a powerless performing methodology.
3.5 Time sensitive Re-ranking
The Time-based re-ranking is utilized to re-rank the pictures dependent on • Time tally • Visit check • Download tally When the picture is opened it begins to tally the absolute time taken till the picture is shut and furthermore tally the number of perspectives and downloads of a specific picture. The re-ranking is emerged dependent on all out time taken, which picture has higher time is shown best of the query items. In the event that in excess of a picture have same time check, the visit tally is considered and re-ranking is appeared. Besides, when both the time and visit check are identical for more than one picture at that point, download tally is drawn and re-ranking is finished. Subsequently, we get the applicable query items on the best rundown. Presently, we think about the proposed framework from a client's point of view. Client
performs catchphrase seek so as to get to the picture from dataset. When the client has entered an information inquiry for picture seek, the relating pictures from the dataset will be recovered and showed on the website page. Since the underlying query items have been gotten, the re-ranking calculation can be actuated with client click. Initially, the Circular ranking calculation will be performed and the ranked rundown will be shown. Furthermore, Time-Based re-ranking will be performed on the round re-ranked list for further enhancing the recovery accuracy.
4. RESULTS AND DISCUSSION
[image:3.612.319.581.386.452.2]The motivation behind why the mastered re-ranking model depicted above can be summed up crosswise over inquiries past those utilized for the preparation is that the model loads are not identified with explicit pictures but rather to their rank positions in the content based query item. The partition of the model loads from explicit pictures is the way to guarantee that the re-ranking model just should be adapted once and would then be able to be connected to any self-assertive inquiry.
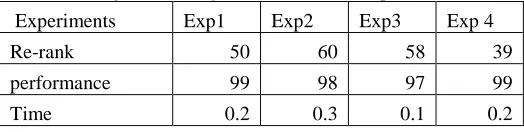
Table 1: Image re-ranking with the various Experiments
Experiments Exp1 Exp2 Exp3 Exp 4
Re-rank 50 60 58 39
performance 99 98 97 99
Time 0.2 0.3 0.1 0.2
`
96
Fig 2: Image Re-ranking Chart for the different level forsearching and experiments
Referring to the Fig 2, the chart shows the result of re-ranking through the experiments by using time performance.
Contrasted with them, the model based figuring out how to re-rank technique figures out how likely the pictures at every one of the positioned position in the content based outcome are to be important to the inquiry. At the end of the day, the technique straightforwardly learns the qualities of the hidden content based picture web search tool and requires less master contribution to terms of the re-ranking highlight plan and a progressively loosened up suspicion on the basiccontent based hunt than, for example, [4] and [15]. Thus, the model based re-ranking strategy can be required to sum up far superior over a wide arrangement of questions and perform well for any basic content based internet searcher.
5. CONCLUSION AND FUTURE ENHANCEMENT
We proposed a proficient collection approach for building minimized yet amazing picture portrayals by using the warmth condition in this original copy. We used the hypothesis of anisotropic dissemination, and expected that diagram characterized by a lot of profound highlights comprises a warmth exchange framework. By considering every profound component as a warmth source, our methodology maintained a strategic distance from over-portrayal that includes by upholding the framework temperatures got from all highlights be a consistent. We gave a commonsense answer for determine picture vectors, and showed the adequacy of our strategy on the assignment of occurrence level recovery. Propelled by our accumulation technique, we additionally
exhibited a warmth condition based picture re-ranking strategy to additionally expand recovery execution. Both of highlight total and picture re-positioning techniques are unsupervised, and can be good with various image positions, including pre-prepared and adjusted systems. Trial results demonstrated that we have set up new condition of the art results on open picture recovery benchmarks utilizing 512-dimensional vector portrayals.
REFERENCES
[1] S. Santini and R. Jain, “Similarity Measures,” IEEE Trans. PatternAnalysis and Machine Intelligence, vol. 21, no. 9, pp. 871-883, Sept.1999.
[2] K. Stevenson and C. Leung, “Comparative Evaluation of WebImage Search Engines for Multimedia Applications,” Proc. IEEEInt’l Conf. Multimedia and Expo, July 2005. [3] comScore’s Report Article, “Comscore’sQsearch 2.0
Service,”comScore’s Report Article, www.comscore.com, 2007.
[4] B.J. Jansen, A. Spink, and T. Saracevic, “Real Life, Real Users, andReal Needs: A Study and Analysis of User Queries on the Web,”Information Processing and Management, vol. 36, no. 2, pp. 207-227,2000.
[5] R. Datta, D. Joshi, J. Li, and J.Z. Wang, “Image Retrieval: Ideas,Influences, and Trends of the New Age,” ACM Computing Surveys,vol. 40, no. 2, pp. 1-60, 2008.
[6] A. Bhattacharya, V. Ljosa, J.-Y. Pan, M.R. Verardo, H. Yang, C.Faloutsos, and A.K. Singh, “Vivo: Visual Vocabulary Constructionfor Mining Biomedical Images,” Proc. IEEE Fifth Int’l Conf. DataMining, Nov. 2005. [7] J. Li and J. Wang, “Real-Time Computerized Annotation
ofPictures,” Proc. ACM 14th Ann. Int’l Conf. Multimedia, 2006.
[8] D. Joshi, J.Z. Wang, and J. Li, “The Story Picturing Engine - ASystem for Automatic Text Illustration,” ACM Trans. MultimediaComputing, Comm. and Applications, vol. 2, no. 1, pp. 68-89, 2006.
[9] M.W. Berry, S.T. Dumais, and G.W. O’Brien, “Using LinearAlgebra for Intelligent Information Retrieval,” SIAM Rev., vol. 37,no. 4, pp. 573-595, 1995.
[10] T. Hofmann, “Probabilistic Latent Semantic Indexing,” Proc. 22ndInt’l Conf. Research and Development in Information Retrieval (SIGIR’99), 1999.
[11] T. Hofmann, “Unsupervised Learning by Probabilistic LatentSemantic Analysis,” Machine Learning, vol. 42, no. 1/2, pp. 177-196, 2001.
[12] D.M. Blei and A.Y. Ng, and M.I. Jordan, “Latent DirichletAllocation,” J. Machine Learning Research, vol. 3, pp. 993-1022, 2003.
[13] T.L. Griffiths and M. Steyvers, “Finding Scientific Topics,” Proc.Nat’l Academy of Sciences USA, vol. 101, no. suppl. 1, pp. 5228-5235,2004.
0 20 40 60 80 100 120 140 160 180
Exp1 Exp2 Exp3 Exp 4
Image Reranking
time
performanc e
[image:4.612.37.273.91.312.2]`
97
[14] M. Steyvers, P. Smyth, M. Rosen-Zvi, and T.Griffiths,“Probabilistic Author-Topic Models for Information Discovery,”Proc. 10th ACM SIGKDD Conf. Knowledge Discovery and DataMining, 2004.
[15] Z. Guo, S. Zhu, Y. Chi, Z. Zhang, and Y. Gong, “A Latent TopicModel for Linked Documents,” Proc. 32nd Int’l ACM SIGIR Conf.Research and Development in Information Retrieval (SIGIR), 2009.
[16] T.-T. Pham, N.E. Maillot, J.-H. Lim, and J.-P. Chevallet, “LatentSemantic Fusion Model for Image Retrieval and Annotation,”Proc. 16th ACM Conf. Information and Knowledge Management(CIKM), 2007.
[17] R. Datta, D. Joshi, J. Li, and J.Z. Wang, “Image Retrieval: Ideas,Influences, and Trends of the New Age,” ACM Computing Surveys,vol. 40, no. 2, article 5, pp. 1-60, 2008.
[18] F. Monay and D. Gatica-Perez, “On Image Auto-Annotation withLatent Space Models,” Proc. ACM Int’l Conf. Multimedia (MM),2003.