CSEIT183175 | Received : 05 Jan 2018 | Accepted : 19 Jan 2018 | January-February-2018 [(3) 1 : 254-260 ]
International Journal of Scientific Research in Computer Science, Engineering and Information Technology © 2018 IJSRCSEIT | Volume 3 | Issue 1 | ISSN : 2456-3307
254
A Proximity-Aware Interest-Clustered P2P File Sharing System
D. Mounika1, V. Sridhar Reddy2
1M.Tech Scholar, Department of CSE, Vignana Bharathi Institute of Technology Aushapur (V), Ghatkesar (M), R.R.,
Telangana, India
2Assistant Professor, Department of CSE, Vignana Bharathi Institute of Technology Aushapur (V), Ghatkesar (M), R.R.Dist, Telangana, India
ABSTRACT
Powerful archive question is basic to the general execution of distributed (P2P) record sharing systems. Gathering peers by their consistent favorable circumstances can basically enhance the capability of record request. Packing peers by their physical closeness can in like manner upgrade record question execution. Nevertheless, couple of current works can bunch peers in perspective of both friend interest and physical closeness. Yet sorted out P2Ps give higher archive request capability than unstructured P2Ps, it is difficult to recognize it in light of their totally portrayed topologies. In this work, we show a Proximity-Aware and Interest-clustered P2P record sharing System (PAIS) in perspective of a sorted out P2P, which shapes physically-close center points into a gathering and further social affairs physically-close and ordinary interest centers into a sub-assemble in light of a different leveled topology. PAIS uses a sharp archive replication figuring to moreover enhance record question viability. It makes duplicates of reports that are a great part of the time requested by a social occasion of physically close center points in their general vicinity. Furthermore, PAIS updates the intra-sub-bundle archive looking for through a couple of systems. To begin with, it moreover arranges the energy of a sub-pack to different sub-interests, and gatherings standard sub-interest center points into a social occasion for archive sharing. Second, PAIS develops an overlay for each get-together that interfaces cut down restrain centers as far as possible center points for flowed report addressing while in the meantime keeping up a key separation from center point over-load. Third, to reduce archive looking for delay, PAIS uses proactive record information amassing so a report requester can know whether its requested archive is in its near to center points. Fourth, to reduce the overhead of the record information collection, PAIS uses grow channel based report information assembling and looking at appropriated archive chasing. Fifth, to upgrade the record sharing viability, PAIS positions the grow channel achieves ask. sixth, taking a gander at that as a starting late passed by record tends to be gone to again, the bloom channel based approach is enhanced by simply checking the as of late added grow channel information to reduce archive looking for delay. Take after driven trial comes to fruition due to this present reality Planet Lab test bed display that PAIS definitely decreases overhead and updates the viability of record offering to and without mix. Further, the exploratory results show the high feasibility of the intra-sub-bundle report looking strategies in improving record looking for viability.
Keywords :P2P, File Sharing System, PAIS, DHT, Node Vicinity Portrayal
I.
INTRODUCTION
Appropriated preparing is a field of programming
building that audits spread structures. An
goal. There are various alternatives for the message passing part, including RPC-like connectors and message lines. Three basic characteristics of passed on structures are: synchronization of fragments, nonappearance of an overall clock, and free frustration of sections. A basic goal and trial of appropriated systems is zone straightforwardness. Instances of scattered structures vary from SOA-based systems to enormously multiplayer electronic diversions to circulated applications.
The condition is also snared by the traditional occupations of the terms parallel and scattered count that don't precisely facilitate the above implications of parallel and circled systems; see the region Theoretical foundations underneath for more clear exchange. Regardless, as a tried and true rule, predominant parallel estimation in a shared memory multiprocessor uses parallel computations while the coordination of a significant scale circled system uses passed on counts.
II.
LITERATURE SURVEY
Pastry: Scalable, decentralized object location and routing for large-scale peer-to-peer systems
Authors: A. Rowstron and P. Druschel
This paper demonstrates the blueprint and evaluation of Pastry, an adaptable, appropriated question zone and coordinating substrate for wide-domain conveyed applications. Prepared great performs application-level directing and question range in a conceivably tremendous overlay arrangement of centers related through the Internet. It can be used to help an arrangement of disseminated applications, including overall data storing, data sharing, accumulate correspondence and naming. Each center point in the Pastry orchestrate has a unique identifier (nodeId). Exactly when given a message and a key, a Pastry center point beneficially courses the message to the center point with a nodeId that is numerically closest to the key, among all at display live Pastry center points. Each Pastry center point screens its
speedy neighbors in the nodeId space, and tells usages of new center arrivals, center frustrations and recoveries. Prepared great considers orchestrate area; it tries to constrain the detachment messages go, as showed by a to scalar closeness metric like the amount of IP coordinating skips Pastry is completely decentralized, adaptable, and self-dealing with; it normally changes with the passage, departure and disillusionment of centers. Exploratory results got with a model execution on a duplicated arrangement of up to 100,000 center points certify Pastry's flexibility and adequacy, its ability to self-organize and change in accordance with center frustrations, and its incredible framework territory properties.
Semantic-mindful metadata association worldview in cutting edge record frameworks
Creators: Y. Hua, H. Jiang, Y. Zhu, D. Feng, and L. Tian
Existing information collecting frameworks in context of the diverse leveled list tree association don't meet the flexibility and esteem necessities for
exponentially making edifying records and
ceaselessly complex metadata ask for in colossal scale, Exabyte-level record structures with billions of
documents. This paper proposes a novel
flexibility and reduces request inaction over database approaches. To the best of our knowledge, this is the essential examination on the execution of complex inquiries in tremendous scale record systems.
Existing System
1. A key standard to judge a P2P record sharing system is its archive zone capability. To improve this viability, different systems have been proposed. One strategy uses a super partner topology which contains super hubs with speedy affiliations and standard center points with slower affiliations. A super hub interfaces with various super hubs and some predictable centers, and a standard center partners with a super hub. In this super-peer topology, the centers at the point of convergence of the framework are speedier and therefore make a more strong and stable spine. This empowers a bigger number of messages to be coordinated than a slower spine and, along these lines, allows more critical flexibility. Super-peer frameworks include the inside ground amongst
2. concentrated and absolutely symmetric P2P organizes, and can join the upsides of both consolidated and flowed looks.
3. Another class of systems to upgrade report range capability is through a closeness careful structure.
4. The inferior class of systems to upgrade report zone capability is to bundle centers with practically identical interests which decrease the record territory inaction.
Proposed System
1. This paper demonstrates a region careful and interest packed P2P record sharing System (PAIS) on a sorted out P2P structure. It outlines physically-close center points into a cluster and further social events physically-close and ordinary interest center points into a sub-gathering. It in like manner puts reports with comparative interests together
and make them accessible through the DHT Lookup() directing limit. More indispensably, it keeps every single point of convergence of DHTs over unstructured P2Ps. Contingent upon DHT question course of action as
opposed to broadcasting, the PAIS
improvement consumes impressively less cost in mapping centers to gatherings and mapping bundles to interest sub-gatherings. PAIS uses a clever archive replication count to also overhaul record inquiry efficiency. 2. It makes impersonations of reports that are a
significant part of the time requested by a social affair of physically close center points in their general vicinity. Likewise, PAIS enhances the intra sub-bunch record looking for through a couple of strategies
3. To start with, it also portrays the eagerness of a sub-group to different sub-interests, and clusters fundamental sub-interest centers into a social occasion for archive sharing. 4. Second, PAIS creates an overlay for each
get-together that interfaces cut down restrain center points as far as possible centers for coursed record addressing while in the meantime evading center over-trouble.
5. Third, to diminish archive looking
deferment, PAIS uses proactive record information gathering with the objective that a report requester can know whether its requested archive is in its adjoining center points.
6. Fourth, to diminish the overhead of the record information gathering, PAIS uses grow channel based archive information amassing and relating spread record chasing. 7. Fifth, to upgrade the archive sharing
information to diminish archive looking for
delay. System Design
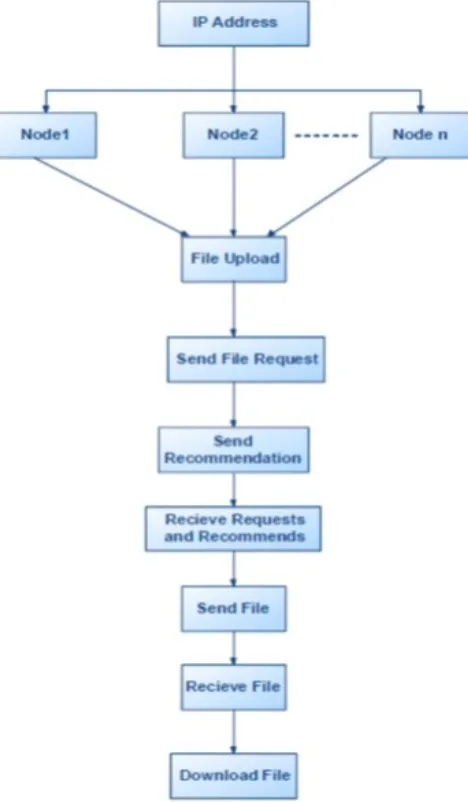
Figure 1. System Architecture
1. The DFD is also called as bubble chart. It is a simple graphical formalism that can be used to represent a system in terms of input data to the system, various processing carried out on this data, and the output data is generated by this system.
2. The data flow diagram (DFD) is one of the most important modeling tools. It is used to model the system components. These components are the system process, the data used by the process, an external entity that
interacts with the system and the
information flows in the system.
3. DFD shows how the information moves
through the system and how it is modified by a series of transformations. It is a graphical technique that depicts information flow and the transformations that are applied as data moves from input to output.
4. DFD is also known as bubble chart. A DFD may be used to represent a system at any level of abstraction. DFD may be partitioned into levels that represent increasing information flow and functional detail.
III.
IMPLEMENTATION
Modules:
1. PAIS Structure
2. Node vicinity portrayal 3. Node intrigue portrayal
4. Clustering physically close and normal intrigue hubs convenience of parts, sub social events, assemblages and also a finished thing It is the route toward working on programming with the arrangement of ensuring that the Software system satisfies its essentials and customer wants and does not bomb in an unsuitable way. There are diverse sorts of test. Each test sort watches out for a specific testing need.
Input design
The data setup is the association between the information structure and the customer. It contains the making subtle element and methodologies for data course of action and those methods are vital to put trade data in to a usable shape for planning can be expert by surveying the PC to examine data from a made or printed report or it can occur by having people entering the data clearly into the structure. The arrangement of data focuses on controlling the measure of data required, controlling the goofs, keeping up a vital separation from delay, sidestepping extra means and keeping the technique direct. The data is laid out in such a course thusly, to the point that it gives security and ease of use with holding the assurance. Data Design considered the going with things:
1. What information ought to be given as info? 2. How the information ought to be orchestrated
or coded?
3. The exchange to control the working staff in giving information.
4. Methods for getting ready information
approvals and ventures to take after when mistake happen.
Output Design
A quality yield is one, which meets the essentials of the end customer and presents the information fundamental and direct source information to the customer. Capable and astute yield arrangement upgrades the structure's relationship to help customer essential initiative.
1. Planning PC yield ought to continue in a sorted out, well thoroughly considered way; the correct yield must be produced while guaranteeing that each yield component is composed with the goal that individuals will discover the framework can utilize effortlessly
and adequately. At the point when
investigation outline PC yield, they should identify the particular yield that is expected to meet the prerequisites.
2. Select strategies for introducing data.
3. Make record, report, or different arrangements that contain data created by the framework.
The yield type of a data framework ought to finish at least one of the accompanying goals.
1. Convey data about past exercises, current status or projections of the Future.
2. Signal critical occasions, openings, issues, or notices.
V.
CONCLUSION
Starting late, to overhaul record zone efficiency in P2P structures, interest assembled super-peer
frameworks and region grouped super-peer
frameworks have been proposed. But the two procedures improve the execution of P2P structures; few works amass peers in perspective of both partner interest and physical proximity in the meantime. In addition, it is harder to recognize it in sorted out P2P systems as a result of their totally described topologies, regardless of the way that they have high viability of report region than unstructured P2Ps. In this paper, we show proximity careful and premium assembled P2P archive sharing system in light of a composed P2P. It groups peers in light of both interest and closeness by abusing a dynamic structure of a composed P2P. PAIS uses a sharp report replication estimation that emulates a record as frequently as conceivable requested by physically close center points near their physical region to overhaul the archive inquiry efficiency. Finally, PAIS enhances the archive looking viability among the region close and normal intrigue center points through different techniques. The take after driven trial comes to fruition on Planet Lab display the adequacy of PAIS in examination with other P2P archive sharing systems. It definitely diminishes the overhead and yields vital upgrades in record range.
VI.
REFERENCES
[1].BitTorrent. (2013) [Online]. Available:
http://www.bittorrent. com/
[2].Gnutella home page. (2003) [Online]. Available: http://www.gnutella.com
[3].I. Clarke, O. Sandberg, B. Wiley, and T. W. Hong, "Freenet: A distributed anonymous information storage and retrieval system," in Proc. Int. Workshop Des. Issues Anonymity Unobservability, 2001, pp. 46-66.
[4].I. Stoica, R. Morris, D. Liben-Nowell, D. R. Karger, M. F. Kaashoek, F. Dabek, and H.
Balakrishnan, "Chord: A scalable peer-topeer lookup protocol for internet applications," IEEE/ACM Trans. Netw., vol. 11, no. 1, pp. 17-32, Feb. 2003.