CSEIT1723293| Received : 08 June 2017 | Accepted : 16 June 2017 | May-June-2017 [(2)3: 786-796]
International Journal of Scientific Research in Computer Science, Engineering and Information Technology © 2017 IJSRCSEIT | Volume 2 | Issue 3 | ISSN : 2456-3307
786
Mining the opinionative Web: Classification and Detection of
aspect Contexts for Aspect primarily based Sentiment Analysis
K. Anuradha
1, R. Meghamala
21
Assistant Professor, Department of Computer Science and Engineering, KMIT, Affiliated Jntu Hyderabad, Hyderabad, Andhra Pradesh, India
2
Assistant Professor, Department of Computer Science and Engineering, KMIT, Affiliated Jntu Hyderabad, Hyderabad, Andhra Pradesh, India
ABSTRACT
Aspect based mostly Sentiment Analysis (ABSA) provides additional insight into the analysis of social media. Understanding user opinion concerning very different aspects of product, services or policies are often used for up and innovating in a good approach. Thus, it is changing into a progressively necessary task within the natural language process (NLP) realm. The quality pipeline of aspect-based sentiment analysis consists of 3 phases: aspect class detection, Opinion Target Extraction (OTE) and sentiment polarity classification. During this article, we tend to propose another pipeline OTE, aspect classification, aspect context detection, and sentiment classification. Because it is often discovered, the narrow-minded words square measure initial detected then square measure classified into aspects. Additionally, the narrow-minded fragment of each aspect is delimited before playacting the sentiment analysis. This paper is concentrated on the aspect classification and aspect context detection phases and proposes a twofold contribution. First, we tend to propose a hybrid model consisting of a word embeddings model employed in conjunction with linguistics similarity measures so as to develop a facet classifier module. Second, we tend to extend the context detection algorithmic program by Mukherjee et al. to boost its performance. The system has been evaluated exploitation the SemEval2016 datasets. The analysis shows through many experiments that the employment of hybrid techniques that combination totally different sources of data improve the classification performance.
Keywords : OTE, ABSA, NLP, LCS, IC, MG-LDA, LDA, pLDA
I.
INTRODUCTION
An increasing variety of users utilizes websites and social media to share their experiences and degree of satisfaction with product, services or places, among others. On-line opinionative reviews are a very important supply of client feedback that firms will use to measure satisfaction and even improve their product and services. In addition, user-generated content in websites and social networks has experimented a very important growth [1]. This has contributed for the most part to the event of the Sentiment Analysis (SA) field. Additional concretely, facet-based mostly Sentiment Analysis (ABSA) is that the drawback of mining opinions from the text concerning specific entities and their associated aspects [1]. ABSA techniques need an
additional granular vision of the opinion mining drawback, as not only sentiment polarity is calculable, however additionally needs the aspects are known and analyzed. For instance, associate ABSA system that is conferred with the text “The food was lousy - too sweet or too salty and therefore the parts small.” ought to categorical that each aspect, food, and portion, art related to a negative polarity.
aspect. Secondly, the aspect classification module classifies the detected face into one in every of the many doable topics within the domain. Next, the context detection module determines the facet context boundary. Finally, the sentiment estimation module realizes a sentiment analysis of the opinion and its facet, yielding the calculable polarity.
The rest of this paper is organized as follows. In Sect. II, the connected work to our proposal is summarized. Sect. III presents the design of the system as an entire, shortly describing the aim of every module. Sect. IV describes our proposal for combining information and corpus sources for facet classification. Following, our proposal for context detection is conferred in Sect. V. Sect. VI presents the sentiment estimation module. To gauge the planned system, Sect. VII depicts the experimental results obtained. Finally, conclusions and future work are conferred in Sect. VIII.
II.
RELATED WORK
Many approaches aim to notice the worldwide sentiment polarity of a document or a sentence; however, efforts are created to research the sentiment at the facet level [2], [3]. During this context, our work presents a hybrid system that classifies each the facet and its opinion. As indicated by [4], aspect-based sentiment associatealysis has usually two steps: (i) identification and extraction of the aspects enclosed in an opinion sentence, and (ii) estimating the sentiment polarity of aforesaid aspects. This work deals with these two issues. During this section, the connected work of each issue is summarized.
A. ASPECT CLASSIFICATION
In the context of topic classification, Latent Dirichlet Allocation (LDA) driven models are often used [4]. LDA may be a generative probabilistic model that considers every document as a combination of topics. Supplementary to the present, several variations of this subject modeling technique are conferred, like pLDA [5]. In similar lines, [6] proposes a multi-grain approach to extract opinion aspects (MG-LDA), extending the LDA approaches. The MG-LDA methodology extracts the opinion aspects and it conjointly clusters them into topics.
Some further strategies for facet classification square measure the semantic-based approaches. These techniques use the idea of linguistics connectedness to assist in several linguistic communication process tasks. The matter is to see the relation between ideas or words.
That is, it is aimed to make some way of measure the space between the facet words and sure topics. During this context, some clergyman information sources (lexical databases) are often helpful, like WorldNet [7]. In addition, additional easy resources are used, because the network-based lexicon approach projected in [8].
B. Sentiment estimation
The dominant approaches to sentiment analysis square measure driven by machine learning strategies [3], [9]. The foremost common approach consists of the Bag of Word (BOW) model, wherever every document is remodeled into a feature vector that is then fed to a classification algorithmic program. alternative sorts of options square measure typically used, like a part of Speech (POS) tagging, that is associate elemental model of grammar analysis [10]. An applied mathematics approach for representing documents is understood as TF-IDF, wherever words square measure weighted depending on their frequency on the corpus [11]. Moreover, several sentiment analysis styles involve the employment of a sentiment lexicon as a supply of subjective info [12]. Even so, lexicon-based approaches have several drawbacks: the need of labeled knowledge that is reliable and consistent, the expression variations between domains and the indisputable fact that lexicons cannot be mechanically translated for bilingual use [13]. In addition, extracting non-simple options from text and determining which of them square measure relevant may be an elementary question within the machine learning driven techniques [14].
In addition to those approaches, ensemble strategies are often used for rising sentiment classifications performance. Ensembles strategies mix the predictions of varied classifiers (base classifiers) and apply some operate to them to yield a final prediction. The rule-based ensemble, like majority ballot, is often quite effective within the task of sentiment classification [20]. Besides, further subjective information is often supplementary with ensemble techniques, like POS employing a rule-based ensemble model [21]. In addition, a meta-classifier ensemble model is often used, as in [20]. Meta-learning models square measure supported the employment of base classifiers predictions as options fed to a further classifier that predicts the polarity.
III.
SYSTEM OVERVIEW
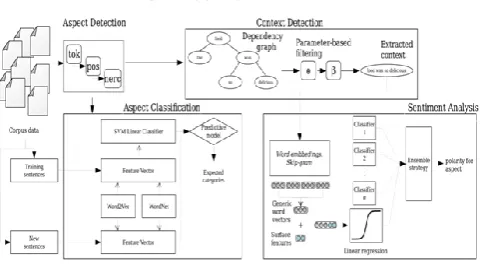
The projected system is divided into four modules, all addressing a different dimension of the ABSA problem: (i) the facet detection module that detects OTE in associate degree narrow-minded text; (ii) the fact classification module that classifies every detected target into one amongst many attainable categories within the studied domain; (iii) the context detection module that determines the boundaries of the opinion text for the detected aspect; and (iv) the sentiment analysis module is responsible for computing the sentiment polarity of the target supported the detected context.
Figure one illustrates the info flow of the system and its main elements. The method of facet primarily based Sentiment Analysis is as follows. Firstly, the text information is analysed by the aspect detection module. This module is that the one projected in [22], composed of many sub-modules known as pipes. Every pipe realizes a particular operate and, once combined, they yield the set of words that represent a side of the opinion text. That is, the mixture of those pipes permits the US to sight the aspects. The ix-pipe-to tokenizes and segments the text, six API pepos performs POS tagging and lemmatized, and 6 pipes ERC performs the Opinion Target Extraction (OTE). We have used the already trained models offered by the tools, as they are ready for the building reviews domain.
The detected facets area unit passed to the aspect classification (Sect. IV) and context detection (Sect. V)
modules. Finally, the context detection module requests analyses to the sentiment estimation (Sect. VI) module.
IV.
ASPECT CLASSIFICATION
Aspect class Detection could be a sub-task of ABSA; attending to establish each entity E and attribute a try, towards that, an opinion is expressed within the given text [23]. Specifically, given an input sentence like “The food was delicious”, the aspect class detection extracts the E and A try (e.g., category=FOOD#QUALITY) for the target word “food”. We have chosen English restaurant's domain of the ABSA of SemEval2016 [23]. Within the eating-house domain, SemEval predefines a collection of entity labels (SERVICE, RESTAURANT, FOOD, DRINKS, AMBIANCE, LOCATION) and a collection of attribute labels (GENERAL, PRICE, QUALITY, vogue choice, MISCELLANEOUS). The entities and labels compose twelve classes. Our task of aspect class classification consists in distribution an aspect class to the opinion target words.
distance between words. With such considerations, we have a tendency to aim at combining data (e.g.WordNet) and corpus (e.g. Yelp) sources to enhance aspect classification. Our main contribution is that the hybrid model that consists of a word embeddings model [24] and semantic similarity model exploitation WorldNet [25]. We have a tendency to propose to use similarity score because the weight of every vector dimension so that the linguistics similarity between words computed by word2vec and linguistics similarity measures square measure enclosed for training. Specifically, we have a tendency to expressly use then unigrams as a feature vector, within which the word similarity between target words and feature words square measure wont to represent every dimension of the feature vector. The thought is to coach a linguistics prophetic model for each class supported the feature words and similarity models exploitation SVM. Formally, let F = ff1; f2;: : :; fng be the set of feature words, a feature vector is diagrammatic as V2 [0; 1] N.
For a collection of target words T = fw1; wmg, the value of a dimension fi is computed from maxwj 2T sim (wj; fi), where the sim perform denotes the word similarity between two words. The calculation of similarity scores is additional computationally intensive than tally the incidence of words. Since the target words square measure within the sort of short text (several words), and the feature vector will be composed by a most representative words (small vector dimensions), the intensive computation the problem will be mitigated exploitation word similarity matrix. The sim perform is enforced by word2vec [24] for training Yelp knowledge and the linguistics similarity measures primarily based on WorldNet [25]. For word2vec, we have been obtained a nonstop illustration of words, wherever words that co-occur frequently square measure mapped to vectors go on vector area. Based on the spatial arrangement linguistics hypothesis, the words co-occur in a same close context square measure treated as relevant therefore that they need high similarity. Consequently, the sim(wj; fi) the perform is enforced as cos similarity between two-word vectors. exploitation this word2vec similarity model, a primary feature vector Vword2vec 2 [0; 1]N is obtained. The word2vec model considers the co-occurrence info of an equivalent close context, which might create would challenge the word2vec model once discriminating wordsfrom completely different classes that square measure often collocated (e.g.food and
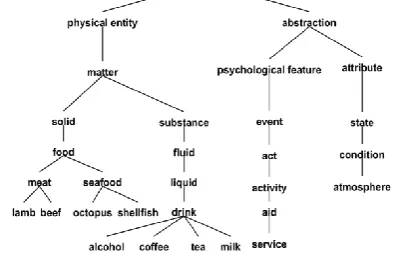
drink). as an example, in eating house domain, that wide range of words to be thought-about as connected. This w target words like fish and wine would seem in same surrounding contexts (e.g. “the fish is delicious and also the wine is great”). If a word2vec model is trained from such corpus simply supported conniving co-occurrences of words, many words happiness to completely different classes would have similar similarity. so as to resolve this drawback, linguistics similarity methods exploitation WordNet [25] square measure helpful to enrich the word2vec model by together with the structural data from the taxonomy. As illustrated in a very fragment of WordNet in Fig. 2, lamb, beef, and food square measure sub-concepts of FOOD class, while low, tea, and milk square measure sub-concepts of DRINKS category. though WordNet primarily based similarity model will retain taxonomical info from WordNet, it will solely address limited words that square measure contained in WordNet. Combining
word2vec and WordNet similarity models will change the facet classification model to own sensible ability in addressing massive vocabularies and encryption class-conscious data of common words from WordNet. In consequence, except for Word2Vec, we have a tendency to conjointly consider the linguistics similarity ways exploitation WordNet.
amount of nodes or edges (shortest path) connecting 2 words in WordNet taxonomy. Let path(wi; wj) be the shortest path between Wisconsin and wj, thePath [26] technique defines linguistics similarity as:
Simp ath (wi;wj) = 1/1+path(wi;wj) ---(1) The Leacock-Chod [27] method measures the semantic simi-larity between words based on their shortest path length using a non-linear function illustrated in Eq.(2): simLeacock Chod(wi; wj) = log ( length(wi; wj) ) (2)
where D is that the most depth of the taxonomy. the concept of exploitation depth information lies within the property of taxonomies that the superior words during a taxonomy ar imagined to be a lot of general. for instance in Fig. 2, the word combine lamb and beef ar additional similar than the word combine meat and food. The wu & linksman methodology measures the depth of 2 words in a very taxonomy with the smallest amount Common Subsumer (LCS), that is that the most specific word that's a shared root of the 2 words. for instance, the LCS of word beef and word octopus is that the word food. Let wlcs be the LCS of words American state and wj, then the wu & linksman [28] methodology measures linguistics similarity of given words exploitation the subsequent formula
sim wu&p almer (wi;wj)
=2depth(wlcs)/depth(wi)+depth(wj) ---(3) The above information based semantic likeness techniques consider the structure of a scientific classification which has a typical disadvantage of uniform separation between words in the scientific classification. Some different methodologies consider the Information Content (IC) to explain the uniform separation downside. The IC of a word is given by the likelihood of experiencing the word in a corpus. Take note of that we utilize Brown Corpus [29] for WordNet to process IC. The Resnik [30] technique depends on the IC of LCS hub of two words.
simResnik(ci; cj) = ICcorpus(clcs) (4) The consequent works by Lin [31] and Jiang & Conrad [32] extend the IC-based method by including the IC of words.
simLin(wi; wj) =
2IC(wlcs)
(5) IC(wi) + IC(wj)
sim
Jiang&Conrad(wi; wj) =1/1 + IC(wi) + IC(wj) 2IC(wlcs (6) The IC-based strategies lack necessary information of path and depth. so as to settle on the simplest WordNet-based linguistics similarity technique for the facet class classification, we'll experiment with all the linguistics similarity delineate higher than in analysis.
As illustrated in Fig. 1, a listing of feature words area unit extracted from coaching information. with the exception of the word2vec primarily based feature vector Vword2vec mentioned antecedently, another feature vector Vwordnet a pair of [0; 1]N consists of computing the linguistics similarity between target words and have words victimization the WordNet-based linguistics similarity strategies. Consequently, a 2N dimension vector consists for coaching and classifying new sentences by considering each word2vec similarity model and WordNet similarity model. The analysis of this module is given in Sect. VII-B. the most results show that combining word embedding and linguistics similarity measures will improve the performance of aspect class classification.
V.
ASPECT CONTEXT DETECTION
Aspect Context Detection is that the task of detection the text fragment within the original text that corresponds to the opinion about associate attribute associate of associate entity E. For the side context detection, we've changed the algorithmic rule planned by Mukherjee et al. [33] so as to boost its performance. the first algorithmic rule relies on computing the gap between words through dependency parsing. during this means, these distances are often painted in an exceeding graph, permitting the computation of the side context. This context detection technique relies on the belief that a lot of closely associated words move to a specific associate opinion concerning an exact side. If n aspects (a1; a2;:::; associate) are detected in an opinion, thealgorithm for extracting the set of words American state that specific any opinion regarding the target side at the return as represented in algorithmic rule one.
2) Make each ai 2 A the clusterhead of Ci. The target aspect at is the clusterhead of Ct. Initially, each cluster only consists of the clusterhead.
3) Assign each word wj to cluster Ck s.t. k = arg mini2nd(wj; ai)
4) Merge any cluster Ci with Ct if d(ai; at) < , where is some threshold distance.
5) The set of words wi 2 Ct expresses the opinion regarding the target aspect at.
6) If 6= 0, add to (or remove from) Ct the words wp so that
if > 0:
max d(wi; at) < d(wp; at) d(wp; at) max d(wi; at) + if < 0:
max d(wi; at) + d(wp; at) d(wp; at) < max d(wi; at)
The original formulation of this formula includes a threshold parameter ( ) that controls the association of comparable opinion contexts. more to the current, we've got generalized this formula by adding an extra parameter ( ) that modifies the behavior of the formula. This generalization intends to enhance the sentiment analysis performance of the system by increasing or reducing the amount of words that area unit enclosed in facet contexts. once the context is detected, this extra parameter controls the obtained context, adding or removing context words. concerning this, we have a tendency to do such getting to the distances within the computed dependency graph. It consists of the worth obtained once the generation of the dependency graph, the live of the space in it.
This parameter controls the amount of words that area unit either more ( > 0) or removed ( < 0) from the facet context considering the distances on the dependency graph. formula one shows the changed technique with this kind of distance. The associated parameter differs from the first formulation of the formula [33] once its price isn't zero. That is, when = 0, our proposal is clone of that of the first.
VI.
ASPECT BASED SENTIMENT ANALYSIS
In this module, the distinguished setting (Sec. V) is utilized for the notion estimation of the angle. That is, we consider that the content that is contained in the recognized setting alludes to the dissected viewpoint, and along these lines that is the thing that the feeling estimation modules usesThe notion grouping has been tended to with the utilization of beforehand proposed models. This feeling investigation
models expect to exploit distinctive sorts of components, accepting that a conclusion classifier can yield a superior execution in the feeling investigation errand when it is given a higher amount and assortment of data. For this end, two diverse mix systems are utilized: an outfit of classifiers and troupe of elements. On one hand, the outfit of classifiers joins the forecasts of the classifiers that shape the troupe (base classifiers). Along these lines, the enlarged data is given through every classifier's estimation forecast. Then again, the gathering of components joins the word vectors or elements that have been separated in an unexpected way. With this, distinctive wellsprings of data are embedded into a solitary classifier.
The elements utilized as a part of this work are non specific word vectors, portrayals gotten through a word embeddings calculation; and surface components, for example, slant vocabularies and Part-of-Speech labeling. The models we use in this work are depicted next.
Non specific word vectors display (MG). This model joins the vectors from each expression of the dissected report and totals them into a solitary vector. The conglomeration capacities that are utilized are the normal, max, and min. The non specific word vectors are gotten utilizing the skip-gram demonstrate [24]. Once the accumulated vectors have been formed, they are encouraged to a direct relapse calculation, that yields the conclusion extremity. Not at all like the accompanying models, MG does not join diverse wellsprings of data.
where the extremity class is chosen by the voting consequences of the base classifier. On account of a tie, the positive extremity is chosen. Second, a meta-learning procedure, where the expectations of the base classifiers are utilized as components for a meta-learner that yields the last assumption forecast. In this work, the meta classifier is actualized utilizing the Random Forest calculation. The base classifiers of the troupe are the same as in [34].
The group of elements (MSG), an outfit of elements model. In this model, the endeavor to enhance the MG proposition is handled by consolidating the beforehand utilized nonexclusive word vectors and an arrangement of surface components. Both sorts of components are consolidated by connection, getting an extended vector. This vector, as in MG model, is then nourished to a direct relapse classifier, that predicts the opinion extremity. The surface elements utilized as a part of this work are: Wordnet-Affect vocabulary esteems [35], number of outcry and cross examination marks, number of positive, nonpartisan and negative words, number of words that are in tops and number of prolonged words.
VII.
EVALUATION
In order to evaluate the aspect classification, context detec-tion and sentiment analysis sub-modules, we have performed several experiments. In these experiments, we aim to evaluate.
STATISTICS OF THE USED DATASETS.
The effectiveness of the projected system and, also, optimize a number of the delineated parameters. The metric used is that the F-score.
A. Datasets
For this analysis, we've got extracted a dataset that's aligned with the eating place reviews domain from the Yelp Challenge dataset one. This dataset provides with a high amount of information which will be used for the word embeddings coaching. Also, we tend to labelled this dataset employing a distant supervising strategy for the sentiment polarity. That is, we've got taken advantage of the Yelp start-based rating, considering one or two stars as negative sentiment, and four or five starts as positive polarity. during this work,
we tend to don't think about the role of the neutral polarity.
Also, we've got used as development informationset (learning of hyper-parameters) the SemEval16 coaching data, and as take a look at dataset (final validation of the sentiment performance) the SemEval16 take a look at set. These 2 datasets, also because the one extracted from Yelp, ar summarized in Table I.
.B. side class Classification analysis
We use the SemEval16 dataset of English eating place domain dataset. The coaching dataset consists of 1880 tuples and also the take a look at dataset consists of 650 tuples. we tend to extracted most typical ten words of every class and composed into seventy six feature words by removing duplicates. the little feature variety isn't a tangle since the vocabularies ar contained in word2ve and WordNet. yet, the standard of feature words ought to be thought of as a result of we tend to use the word similarity scores because the worth of feature vectors. we tend to use the foremost frequent words for simplicity during this article. The word2vec similarity model andWordNet similarity model ar accustomed reason word similarity between target words and have words. we tend to trained the side classification model exploitation the linear kernel of SVM exploitation the sklearn2 package. The classification metrics accuracy, precision, recall, and F-score ar used because the performance metrics to judge the various models.
We have experimented with the classification model in numerous settings: straightforward feature, knowledge-based feature, dense vector feature, and combined options. The experimental results ar shown in Table II. within the straightforward feature, we tend to use the straightforward glossary options Vwordlist two f0; 1gN, wherever the glossary is that the seventy six feature words. during this setting, we tend to use the unigram prevalence feature to coach a classification module Dataset #Positive #Negative
Yelp-extracted 1,492,558 450,540
SemEval16
train 1,696 773
exploitation SVM and use this model as a baseline. Note that the
TABLE II. ACCURACY, PRECISION, RECALL AND F-MEASURE OF ASPECT
CATEGORY CLASSIFICATION USING DIFFERENT METHODS.
Diverse learning programming and settings would impact the trial comes about with the goal that we executed a straightforward standard after the depiction of SemEval. With a specific end goal to demonstrate that the comparability based component is more viable than the straightforward word event highlight, we extended the basic element model to the learning based model and thick vector show. In the learning based setting, we have prepared and assessed the grouping model utilizing the WordNet-based similitude measures separately. Table II demonstrates that the Path [26] similitude measure is the best metric for viewpoint grouping, and the majority of the comparability measures are more powerful than the benchmark aside from the Resnik [30] strategy. In the thick vector setting, we have utilized word2vec implanting to take in the word vectors from Yelp remarks information and prepared the viewpoint grouping model just with the word2vec similitude demonstrate. The exploratory outcome demonstrates that the word2vec closeness model is more powerful than information based techniques and benchmark. By taking a gander at every classification, we found that the information based elements are more successful for nourishment and drink classes while word2vec performs better in different classifications. Since word2vec highlight is prepared from a space corpus (Yelp remarks), it has better scope in vocabularies and the classes, for example, AMBIENCE, LOCATION is more worried with pertinent components as opposed to a various leveled include. In the joined setting, we utilize both word2vec comparability model and WordNet likeness model to prepare and assess keeping in mind the end goal to choose the best mix between word implanting and semantic similitude techniques. Table II demonstrates that both Path [26] and Jiang and Conrad [32] are the best in consolidating with word2vec, as far as F-measure (.79).
since it has accomplished the best execution in our investigations, and it can join the word cooccurrence data together with various leveled learning from WordNet.
C. Context detection validation
In these context detection experiments, we have taken as performance metric the sentiment F-score on the development set with the MG sentiment classification model. In this way, the different contexts that vary from the variation of several pa-rameters are fed to this sentiment model. As for the training of the sentiment classifier, it is explained further in Sect. VII-D. The parameter validated in the context detector module is the value, that controls the words that added or removed to the context. As can be seen in Figure 3, the sentiment performance increases when > 0. The improvement between = 0 (original formulation) and = 6 (maximum improvement of our proposal) is of 3.04% oftheF-score.
A. Sentiment training and validation
Firstly, the skip-gram model has been trained with the Yelp-extracted dataset, setting the dimension of the ensuing vectors to four hundred, and a minimum count of five. As this can be unsupervised training, polarity labels haven't been used.
After the coaching of the word embeddings model, the MG model needs that a linear regression rule is trained. For this, we used the mass vectors for every document of the Yelp-extracted dataset, and also the corresponding distant sentiment labels. Also, the set of potential aggregation functions on the MG model has been evaluated on the SemEval16 train knowledge, getting the most effective performance with the common function a ninety-one.79 capitalize on F-score. succeeding high performance during this sense is that the combination max+avg, with an 87.94 %.
The ensemble of classifiers model doesn't like a coaching method because it consists of already trained classifiers. notwithstanding, the meta-learning strategy will like coaching because it learns from the predictions of its base classifiers. For this finish, the meta classifier is trained with the event knowledge.
Finally, Table III shows the F-scores for the various sentiment models within the SemEval16 check dataset. CEMVoSG is that the ensemble of the classifier with the majority option theme, and CEMMeLSG with the meta-learning strategy. The BOW baselines
are tested and compared with the planned models. It is often seen that the TF-IDF doesn't improve the sentiment performance in these experiments. Also, the most effective playacting model is that the MSG model. The experiment result indicates that connexion generic word vectors and surface options through a feature ensemble strategy improves the sentiment performance. notwithstanding, the 2 classifier ensemble ways don't end in a classification improvement, however a performance decrease.
To the extent of our information, there's no public disaggregation of F-score for the anticipated categories on the 3 best systems. notwithstanding, we will compare to the proposal represented in [36], that claim their F-score for positive and negative categories area unit eighty eight.26 and 76.21%, severally. Our systems perform higher in reference to the positive category, with a 91.00%, however it doesn't perform higher in the negative category, yielding seventy-three.91%. For each system, the F-score metric for the neutral category is zero.
VIII.
CONCLUSIONS
dependency tree categorical an opinion of the constant side. A generalization parameter is introduced into the formula and evaluated on the information, finding that this addition on the detected context strategies improves the sentiment classification performance.The sentiment estimation module consists of a hybrid system that uses a configurable combination of word embeddings, ancient sentiment options And an ensemble of classifiers. the mixture of ancient sentiment options (e.g., sentiment lexicon values) and skip-gram word embeddings is shown to boost the sentiment performance of the system.All in all, we've addressed during this paper, however, the mixture of data and corpus sources will improve each side classification and polarity detection, being complemented by similarity metrics inside classification. Moreover, we've explored however modifying the scope of the side contextaffects context detection, and have projected a generalization of Mukherjee et al. formula that may be used for its improvement in alternative datasets.
IX.
REFERENCES
[1]. B. Liu, Sentiment analysis: Mining opinions, sentiments, and emotions. Cambridge University Press, 2015.
[2]. S. Poria, E. Cambria, and A. Gelbukh, "Aspect extraction for opinion mining with a deep convolutional neural network," Knowledge-Based Systems, vol. 108, pp. 42-49, 2016. [3]. S. Poria, E. Cambria, L.-W. Ku, C. Gui, and A.
Gelbukh, "A rule-based approach to aspect extraction from product reviews," in Proceedings of the second workshop on natural language processing for social media (SocialNLP), 2014, pp. 28-37.
[4]. M. Cataldi, A. Ballatore, I. Tiddi, and M.-A. Aufaure, "Good location, terrible food: detecting feature sentiment in user-generated reviews," Social Network Analysis and Mining, vol. 3, no. 4, pp. 1149-1163, 2013.
[5]. Y. Wang, H. Bai, M. Stanton, W.-Y. Chen, and E. Y. Chang, "Plda: Parallel latent dirichlet allocation for large-scale applications," in In-ternational Conference on Algorithmic Applications in Management. Springer, 2009, pp. 301-314.
[6]. I. Titov and R. McDonald, "Modeling online reviews with multi-grain topic models," in Proceedings of the 17th international conference on World Wide Web. ACM, 2008, pp. 111-120. [7]. A. Budanitsky and G. Hirst, "Evaluating
wordnet-based measures of lexical semantic relatedness," Computational Linguistics, vol. 32, no. 1, pp. 13-47, 2006.
[8]. H. Kozima and T. Furugori, "Similarity between words computed by spreading activation on an english dictionary," in Proceedings of the sixth conference on European chapter of the Association for Computational Linguistics, 1993, pp. 232-239.
[9]. S. Wang and C. D. Manning, "Baselines and bigrams: Simple, good sentiment and topic classification," in Proceedings of the 50th Annual Meeting of the Association for Computational Linguistics: Short Papers-Volume 2, 2012, pp. 90-94.
[10]. K. Gimpel, N. Schneider, B. O’Connor, D. Das, D. Mills, J. Eisenstein, M. Heilman, D. Yogatama, J. Flanigan, and N. A. Smith, "Part-of-speech tagging for twitter: Annotation, features, and experiments," in Proceed-ings of the 49th Annual Meeting of the Association for Computational Linguistics: Human Language Technologies: Short Papers - Volume 2, ser. HLT ’11. Stroudsburg, PA, USA: Association for Computational Linguistics, 2011, pp. 42-47. [11]. J. Martineau and T. Finin, "Delta tfidf: An
improved feature space for sentiment analysis." ICWSM, vol. 9, p. 106, 2009.
[12]. P. Melville, W. Gryc, and R. D. Lawrence, "Sentiment analysis of blogs by combining lexical knowledge with text classification," in Proceedings of the 15th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, ser. KDD ’09. New York, NY, USA: ACM, 2009, pp. 1275-1284. [13]. M. Taboada, J. Brooke, M. Tofiloski, K. Voll,
and M. Stede, "Lexicon-based methods for sentiment analysis," Computational linguistics, vol. 37, no. 2, pp. 267-307, 2011.
[15]. R. Collobert, J. Weston, L. Bottou, M. Karlen, K. Kavukcuoglu, and P. Kuksa, "Natural language processing (almost) from scratch," The Journal of Machine Learning Research, vol. 12, pp. 2493-2537, 2011.
[16]. Y. Bengio, "Learning deep architectures for ai," Foundations and trends R in Machine Learning, vol. 2, no. 1, pp. 1-127, 2009.
[17]. D. Tang, F. Wei, N. Yang, M. Zhou, T. Liu, and B. Qin, "Learning sentiment-specific word embedding for twitter sentiment classification." in ACL (1), 2014, pp. 1555-1565.
[18]. D. Tang, F. Wei, B. Qin, T. Liu, and M. Zhou, "Coooolll: A deep learning system for twitter sentiment classification," in Proceedings of the 8th International Workshop on Semantic Evaluation (SemEval 2014), 2014, pp. 208-212. [19]. Z. Su, H. Xu, D. Zhang, and Y. Xu, "Chinese
sentiment classification using a neural network tool word2vec," in Multisensor Fusion and In-formation Integration for Intelligent Systems (MFI), 2014 International Conference on, Sept 2014, pp. 1-6.
[20]. R. Xia, C. Zong, and S. Li, "Ensemble of feature sets and classification algorithms for sentiment classification," Information Sciences, vol. 181, no. 6, pp. 1138 - 1152, 2011. Online]. Available:http://www.sciencedirect.com/science/ article/pii/S0020025510005682
[21]. R. Xia and C. Zong, "A pos-based ensemble model for cross-domain sentiment classification." in IJCNLP. Citeseer, 2011, pp. 614-622.
[22]. R. Agerri, J. Bermudez, and G. Rigau, "Ixa pipeline: Efficient and ready to use multilingual nlp tools." in LREC, vol. 2014, 2014, pp. 3823-3828.
[23]. M. Pontiki, D. Galanis, J. Pavlopoulos, H. Papageorgiou, I. Androut-sopoulos, and S. Manandhar, "Semeval-2016 task 5: Aspect based sentiment analysis," in Proceedings of the 8th international workshop on semantic evaluation (SemEval 2014). Citeseer, 2016, pp. 27-35. [24]. T. Mikolov, K. Chen, G. Corrado, and J. Dean,
"Efficient estimation of word representations in vector space," arXiv preprint arXiv:1301.3781, 2013.
[25]. R. Mihalcea, C. Corley, and C. Strapparava, "Corpus-based and knowledge-based measures of text semantic similarity," in AAAI, vol. 6, 2006, pp. 775-780.
[26]. R. Rada, H. Mili, E. Bicknell, and M. Blettner, "Development and application of a metric on semantic nets," IEEE Transactions on Systems, Man, and Cybernetics, vol. 19, no. 1, pp. 17-30, 1989.
[27]. C. Leacock and M. Chodorow, "Combining local context and wordnet similarity for word sense identification," WordNet: An electronic lexical database, vol. 49, no. 2, pp. 265-283, 1998. [28]. Z. Wu and M. Palmer, "Verbs semantics and
lexical selection," in Pro-ceedings of the 32nd annual meeting on Association for Computational Linguistics, ser. ACL ’94. Stroudsburg, PA, USA: Association for Computational Linguistics, 1994, pp. 133-138. [29]. W. N. Francis and H. Kucera, "Brown corpus
manual," Brown Univer-sity, 1979.
[30]. P. Resnik, "Using information content to evaluate semantic similarity in a taxonomy," in Proceedings of the 14th International Joint Conference on Artificial Intelligence - Volume 1, ser. IJCAI’95. San Francisco, CA, USA: Morgan Kaufmann Publishers Inc., 1995, pp. 448-453. [31]. D. Lin, "An information-theoretic definition of
similarity," in Proceed-ings of the Fifteenth International Conference on Machine Learning, ser. ICML ’98. San Francisco, CA, USA: Morgan Kaufmann Publishers Inc., 1998, pp. 296-304.
[32]. J. J. Jiang and D. W. Conrath, "Semantic similarity based on corpus statistics and lexical taxonomy," Computational Linguistics, vol. cmp-lg/970, no. Rocling X, p. 15, 1997.
[33]. S. Mukherjee and P. Bhattacharyya, "Feature specific sentiment analysis for product reviews," in International Conference on Intelligent Text Processing and Computational Linguistics. Springer, 2012, pp. 475- 487.
[34]. O. Araque, "Prototype of a Sentiment Analysis System Based on En-semble Algorithms for Combining Deep and Surface Machine Learning Techniques," Master’s thesis, ETSI Telecomunicacion,´ June 2016.
[35]. C. Strapparava, A. Valitutti et al., "WordNet Affect: an affective exten-sion of wordnet." in LREC, vol. 4, 2004, pp. 1083-1086.