Traceability in Requirement Specifications
Using Natural Languages
Kroha, P., Hnetynka, P., Simko, V., Vinarek, J.
1
Traceability and Requirements
In software evolution and maintenance, traceability of requirements is very important [9]. When we move from analysis to design, we assign requirements to the design elements that will satisfy them. When we test and integrate code, our concern is to use traceability to determine which requirements led to each piece of code. Afterwards, when a change is planned we need to start impact analysis before the planned changes to identify how the system will be affected by a proposed change. Traceability tools help analysts understand the implications of a proposed change and ensure that no extraneous code exists.
1.1
Introduction
Originally, traceability of requirements was investigated. The intention was find whether all requirements are implemented and that for any change in a requirement all its im-pacts can be found.
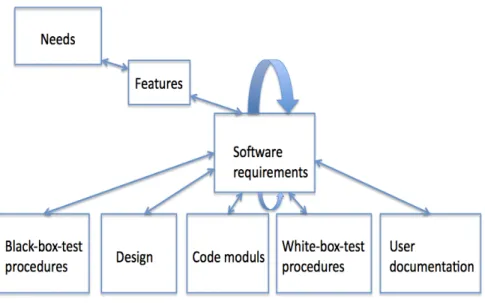
There are impacts Fig. 1 in other requirements, there are impacts in design, im-plementation, black-box and white-box test cases, and in user documentation [20]. A requirements traceability matrix was used as a prerequisite for this purpose.
A traceability matrix is a table that correlates any two documents that support soft-ware development. It represents a matching between high-level requirements and de-tailed, low-level requirements, e.g. detailed design, test plan, test cases. Usually, identi-fiers of high-level documents are column names and identiidenti-fiers of low-level documents are row names. A marked table element means that there is a relation between the corresponding documents.
The purpose of traceability matrix construction was to find whether all require-ments described in high-level docurequire-ments are implemented and tested in low-level-documents.
Lately, it was necessary to accept that developers do not build the requirements traceability matrix to the proper level of detail because its maintenance is time con-suming, even tough case tools such as DOORS [7], and Rational RequisitePro [18] support the process originally meant.
Currently, requirements traceability is defined as the ability to follow the life of a requirement in both a forward and backward direction” [11].
Figure 1: Traceability in requirements
Even though, we mention textual requirement specifications here, traceability con-cerns all free text documents expressed in natural language that have some relation to the program, e.g. user manuals, logs of errors, maintenance journals, design deci-sions, reports from inspection and review sesdeci-sions, and also annotations of individual programmers and teams.
In addition, free text documents often contain the available know-how knowledge of the application domain in form of explain notices. Additionally, diagrammatic rep-resentations, e.g. UML diagrams, are often supplemented with explanatory text as comments that help in communication between stakeholders.
The possibility to trace code to free text documents can also help to locate reuse-candidate components because it is usually difficult to specify which program unit should be design as reusable from the very beginning.
Briefly, we can say that traceability links between areas of code and related sections of free text documents that are important for program comprehension and program maintenance.
Traceability is very important in safety-critical systems because they producer are often legally required to demonstrate that all parts of the code trace back to valid re-quirements. There are laws such as the US Sarbanes-Oxley Act of 2002 requiring to implement change management processes with explicit traceability for software sys-tems that can impact the balance sheet [6].
1.2
Types of Traceability
The process of software development can be seen as using a chain of editors. Program-mers use these editors usually in a specific order, e.g. from analysis to coding. Any decision in a specific element of this chain has to be propagated to both ends of the chain to preserve the consistence of the documents.
In principle, changes of maintenance or/and evolution may initially have been made to any of the documents (free text, diagrams, source code), and have then to be propa-gated to other remaining documents.
More or less, we can distinguish two main types of traceability methods described in research papers:
• Updating requirements first and propagating the change to the code, i.e. creating traceability links top-down from free text documents of high-level to source code [19]. This means that links are propagated from high-level abstraction to low-level abstraction. This approach will be called a normative approach [14] or forward traceability. It is an ideal maintenance process.
• Creating traceability links bottom-up from source code to high-level free text documents, i.e. propagating links from low-level abstraction to high-level ab-straction, that is a sort of reverse engineering [4]. This approach will be called a trace generation approach [12] or backward traceability or after the fact require-ments tracing in [12].
As written above, traceability is necessary to provide maintenance and evolution of program systems. Ideally, both processes - maintenance and evolution - should follow the software development process phases. This means that requirements on program changes and program enhancements should be collected and than, at suitable time points, new analysis, design, implementation, test cases and other documents (we can denote them as free text documents even though they can contain coded diagrams) should be made as an impact of changes in requirements.
If this methodology is strictly followed it is recommended to generate specific no-tices or frames in documents of design, source code, and test cases that denote bor-ders and bidirectional links between parts of these documents (automatically generated or manually derived) from parts of requirements. This approach we used in our tool TESSI 2.3.
Actually, it happens often that, e.g. because of the urgent call of an unhappy cus-tomer, engineers (programmers) make changes directly in source code without running the whole software development process [16]. In this case, some high-level docu-ments become outdated and inconsistency between the high-level docudocu-ments (original requirement specification and design specification) and source code occurs very prob-ably.
In such a case, the only possibility to find the links between the high-level free text documents and the source code is to try some kind of back propagation of changes in the source code. This means that we first have changes in source code and than we are looking for their impact in parts of requirements and other free text documents that have to be changed. Traceability will be recovered in this case. This approach described
in 3.2 uses methods of information retrieval [2] that is based on the assumption that engineers use meaningful names for program items, such as functions, variables, types, classes, and methods.
Manual traces tend to be inconsistent and incomplete. This is the reason why tools are built to implement automatic tracing. Case tools support the forward tracing and special tools that we discuss later support backward tracing.
2
Traceability Top-Down
Traditionally, traceability links are stored in tables (spreadsheets, databases) or require-ments management tools such as Telelogics DOORS or IBMs Rational RequisitePro. Such links are build during the program development but they tend to deteriorate during a project as time-pressured team members fail to update them [6].
Available requirement management tools provide limited support for link creation and maintenance, offering features such as drag-and-drop techniques for creating links, visualization for traces, and denoting links to artifacts that were modified because they might have become outdated. This is referred to as in-place traceability in [6] where specialized tool Poirot is described.
To achieve traceability in this way in maintenance of legacy systems is practically unachievable task because legacy systems were not initially developed supporting the idea of traceability.
2.1
Traceability and Identified Static Model
In requirements, parts of UML model can be recognized and identified. It can be done partially automatically and partially manual. Class diagram (class hierarchy and associations), attributes, and methods (their existence) are parts of the UML model that describe the static structure.
Their identification can be done automatically with some necessary human inter-action because of the complexity of real world semantics. The often used method is based on the grammatical inspection [1]. This method offers a judgment saying that nouns in sentences of requirement specifications may have a link to classes in the cor-responding UML model, verbs may represent methods or relationships, and adjectives may represent a value of an attribute. Because of the natural language complexity, this method works satisfactorily only when using a human interaction.
2.2
Traceability in System RequisitePro
RequisitePro is a professional tool offered by IBM. Traceability links requirements to related requirements of same or different types. RequisitePros traceability feature makes it easy to track changes to a requirement throughout the development cycle. Without traceability, each change would require a review of your documents to deter-mine which, if any, elements need updating.
If either end-point of the connection is changed, the relationship becomes suspect. If you modify the text or selected attributes of a requirement that is traced to or traced
from another requirement, RequisitePro marks the relationship between the two re-quirements suspect.
Traceability relationships cannot have circular references. For instance, a traceabil-ity relationship cannot exist between a requirement and itself, nor can a relationship indirectly lead back to a previously traced from node. RequisitePro runs a check for circular references each time you establish a traceability relationship.
The trace to/trace from state represents a bidirectional dependency relationship be-tween two requirements. The trace to/trace from state is displayed in a Traceability Matrix or Traceability Tree when you create a relationship between two requirements. Traceability relationships may be either direct or indirect. In a direct traceability relationship, a requirement is physically traced to or from another requirement. For example, if Requirement A is traced to Requirement B, and Requirement B is traced to Requirement C, then the relationships between Requirements A and B and between Requirements B and C are direct relationships.The relationship between Requirements A and C is indirect. Indirect relationships are maintained by RequisitePro; you cannot modify them directly. Direct and indirect traceability relationships are depicted with arrows in traceability views. Direct relationships are presented as solid arrows, and indirect relationships are dotted and lighter in color.
A hierarchical relationship or a traceability relationship between requirements be-comes suspect if RequisitePro detects that a requirement has been modified. If a re-quirement is modified, all its immediate children and all direct relationships traced to and from it are suspect. When you make a change to a requirement, the suspect state is displayed in a Traceability Matrix or a Tree. Changes include modifications to the requirement name, requirement text, requirement type, or attributes.
2.3
Traceability in System TESSI
Some help can be done by applying of part-of-speech tagging analysis and searching for templates in the tree structure that represents the parsed sentence. We made some experiments based on grammatical templates taken from experience and described as trees in a domain-specific language using our system TESSI (the last version of TESSI in [15]).
When a template matched a part of requirement specification text then an entity of the corresponding UML-model was generated. Its representation was propagated through XMI-interface to the tool Rational Rose that makes possible to draw the cor-responding UML-model diagram and to generate the corcor-responding code-template.
The tool TESSI builds and maintains some important relationships between re-quirements and parts of the resulted system, e.g. bi-directional links between the iden-tified entities in sentences of textual requirements and the corresponding entities of the model. These links will be followed during an adaptive maintenance. This helps to hold requirements and programs consistent and supports the concept of software evo-lution in which every change in the software system should start with the change of the requirements specification and follow the life-cycle of development.
Requirements traceability paths:
The structure of requirement specification mirrors the abstraction levels of speci-fication, i.e. requirements build a tree structure in that some requirements explain specific cases of more abstract requirements.
There is an interesting problem how to find these relations between requirements that represent the relation of specialization.
• There are paths representing (tracing) semantic relationships among requirement specifications. The problem is that requirement specifications may have mutual influence, i.e. there are some semantic relationships between them and, in some cases, it is not possible to change them independently.
There is a next interesting problem how to find the mutual semantic dependencies between parts of requirement specifications.
• Usually, there is a trace from requirements into design. However, it is possible that requirements and design are independent.
• There is a trace from requirements into test procedures. First, we develop black-box test procedures based on requirements. We have to know how to change the black-box test procedures when changing requirements. White-box test proce-dures exist for all classes and their methods, i.e. changing the structure of classes and methods will impact the white-box test procedures.
• Trace requirements into user documentation plan means that the system func-tionality is completely described in User Manual and other documentation. New appended features in requirements have to be followed by newly appended chap-ters in User Manual.
3
Traceability Bottom-Up
As we mentioned above, engineers maintaining software systems are often forced by dead lines to change source code first and hope that they will change other documents some other time. In this way, document inconsistency occurs because requirements remain unchanged. So, it is necessary to change the corresponding documents of the higher abstract level, e.g. requirement specifications, to preserve consistency.
In principle, the process has two steps:
• to find keywords that specify the same concept in all documents,
• to build links between corresponding documents based on the keywords found We describe these both steps in subsections below in more details.
3.1
Identification of Requirements-related Changes in Source Code
The backward traceability is based on the following known phenomenon. When writ-ing the code programmers often use the mnemonics for identifiers of functions, vari-ables, types, classes, and methods. The analysis of these mnemonics, so called change-related keywords [14], can help to associate high-level concepts with program parts.
Requirements tracing of this kind consists of:
• document parsing,
• candidate link generation,
• candidate link evaluation, and
• traceability analysis.
In this context, it is necessary to identify a subset of changes in source code that have an impact on requirements, so called requirements-related changes, because there are some changes in source code that correspond to bug fixing or refactoring and do not have any impact on requirements.
In information retrieval, we can used a controlled vocabulary. This means that semantics of documents is represented by a set of keywords (descriptors) selected from a vocabulary given before. A query is than represented by a set of keywords specific for it and selected from the same vocabulary. In the past, authors were asked to describe the content of their papers using this technology.
Similary, the keywords can be chosen from an analyst-defined ontology, created in advance. A keyword-matching algorithm is then applied to build lists of low-level elements that may potentially satisfy a given high-level requirement. These are called candidate links [12].
There is another possibility how to do it. This process is called normalization. We can automatically select all unique words of a document and than :
• we eliminate such words that are too much common or too much specialized (Zipf law).
• we extract nouns because we believe that nouns are the most important compo-nents of semantical meaning,
• we apply algorithm of stemming to reduce the number of words to words stems
• we apply algorithms of lemmatization to reduce the influence of grammar
• we can assign weights to words calculated from their frequency in document and normalized by the document length
Keywords occurring in documents of both high-level and low-level are called can-didate links. They are used for traceability matrix construction.
In methods of top-down traceability, the analyst examines the text of the require-ments visually after candidate links are found, determines the meanings of the docu-ments in relation, compares the meanings, and decides whether the meanings are suffi-ciently close, i.e. whether candidate links are really links. The goal is to find high-level requirements that do not have children under low-level documents and the low-level documents or elements that do not have parents in higher level. This was originally called traceability analysis. Its goal was to find not implemented requirements or to find parts of code that became obsolete after requirements have been changed.
Currently, it has been found that maintenance top-down is too much time-consuming. Engineers being under time pressure make changes directly in source code, and because of that it is necessary to use bottom-up methods. So, it is necessary to find a matching between identifiers of source code elements that were changed during the last mainte-nance step and all documents on higher levels concerned.
We assume that traceability links existed before changes and therefor we are look-ing for links between changed elements in source code and other documents. This reduces the set of keywords that are denoted as keywords of requirements-related changes.
In [14], the following types of requirements-related changes caused by changes in source code have been identified:
• Changes in methods bodies are in most cases related to refactoring and/or bug fixes.
• Additions of new elements (classes, methods, package, fields) are usually related to the addition or extension of features.
• Additions and removals of elements having similar names are usually rename operations. This can be very misleading as addition of elements is likely to relate to feature extension while renames are simple refactorings.
• Changes in methods signature are usually related to refactoring.
• Changes in private elements can affect the external behaviour of the system.
• Additions of several methods having the same name (the same name but differ-ent parameters) are usually related to the same feature, i.e they have the same behavior.
In practice, programmers use compound identifiers, e.g. firstNameAbbreviation. The naming convention differs from one language to another. The keywords suitable for link search have to be extracted from identifiers. In paper [14], the camelCase convention is mentioned, which is used in several programming languages (e.g. Java and .NET). In this convention, the names are split according to the position of capital letters in the name.
The question of element granularity is discussed in [8]. They evaluated the eco-nomic value of tracing at lower levels of granularity measured by the effort needed to create the links versus value returned through tracing at various levels of precision. Their case study showed a tenfold increase in granularity returned only a twofold im-provement in precision.
To determine the set of candidates of keywords the processing of names of added or deleted elements were not enough. It is necessary to analyze the context of the change, i.e. we look at the call hierarchy of the element (a method or a class). By call hierarchy we mean all the methods/classes that are invoking the considered method or those invoking the a constructor of the considered class. The authors of [14] expect that going back by one, two or three levels in the call hierarchy should be enough to
gather relevant information about the context of the change. Additionally, keywords can be obtained from comments of classes, methods, and parent classes.
After the keywords extraction, there are many irrelevant keywords in the list of candidates such as keywords relating to implementation details (set, get, string, etc. ), very general keywords in the project (e.g. the name of the project), or stop words (as mentioned above 3.1 that might appear in the documentation of elements (a, the, that, etc.). It is important to filter out as many of these irrelevant keywords as possible. It can be done manually or automatically using their frequency of occurrence, i.e. Zipf law will be applied.
Finally, the remained keywords signalizing changes can be grouped together. One possible way to group changes is to consider all changes affecting a class as a single change, where the keywords extracted from all the changes in that class are grouped together.
3.2
Identification of Links between Code and Requirements
After keywords (called change-related elements) in source code (in general, keywords in a low-level document) have been identified that might cause changes in require-ments, methods of information retrieval [17] are used that are based on the idea that the name of an element in the source code usually reflects its intended function described in requirements and that programmers use the same words for the same entities during the whole software development process, i.e. a specific noun in requirements is used in the same sense as the class name in the corresponding UML diagram and as the class name in the corresponding Java program etc.
In paper [2], which can be seen as a representative of this approach, two models are used to generate links:
• A probabilistic model In the probabilistic model, we use a classifier, e.g. a Bayes classifier, to assign a probability to every word taken from a prescribed vocab-ulary (given by Zipf law) in each free text document. The free text documents are then classified, i.e. we created classes of documents that have similar prob-abilities of the same words. Then we use the same classification procedure (the same prescribed vocabulary) for source code documents to score the sequences of mnemonics extracted from each source code component. A high score in-dicates a high probability that a particular sequence of mnemonics be relevant to the free text document. So, we interpret it as an indication of the existence of a semantic link between the component from which the sequence had been extracted and the class of the free text documents.
• A vector space model In the vector space model, free text documents and source code documents are represented as vectors in an n-dimensional space, where n is the number of words in the prescribed vocabulary, i.e. each word of the prescribed vocabulary is represented by a space dimension.
Documents are ranked against each other by computing a similarity function between the corresponding vectors. Very often, the cosine similarity function
will be used, i.e. the similarity of two documents corresponds to the cosine of the angle between the vectors of these two documents.
In the paper [2], the authors showed that it is possible to retrieve traceability links from source code to textual manual (library LEDA - 95 KLOC, 208 classes, and 88 manual pages) with a recall of 100 % but with a precision of 13 %. They used their tool RETRO described in [13]. Goals for an effective requirements tracing tool and the corresponding tracing tool RETRO are described in [12].
3.3
Using the Bottom-Up Traceability Technology
Above, we described two phases of the reverse traceability. Now, we present their cooperation.
• First, the changes between the two versions of the source code have to be de-tected and the relevant changes have to be identified that are likely to affect the external behavior based on the rules given in 3.1 taken from [14]. The source code comparing strategy consists in focusing on only two types of change: ad-dition and removal of elements that are packages, classes, methods and fields. The comparing is done based on the name only. By detecting all added ele-ments, this approach is detecting the main code changes that relate to feature addition/extension as mentioned in 3.1. To filter out renames, the names and the call hierarchy (for classes and methods) of the added and the removed elements is compared. If the added and deleted elements belong to the same parent ele-ment (e.g. two fields belong to the same class) and if they have similar names, then the change is considered as a rename and is ignored by our approach. Us-ing the steps above, a list of program elements is obtained whose changes might have impact on requirements.
• Then, for each identified program element a list of keywords has to be extracted from the names of the changed elements, from their documentation, and from their call hierarchy.
• Finally, the extracted keywords have to be traced to the requirements specifica-tion in order to identify outdated ones.
The approach described above can either be used in a fully automated way, where the changes are directly traced to requirements or in a semi-automated way, where the user can filter out manually the changes that he thinks are not relevant before running the tracing [14].
3.4
Evaluation of Bottom-Up Traceability
In paper [14], there is an interesting evaluation of their method (described briefly above).
First, they evaluate the effectiveness of their approach for identifying requirements-related changes using the evaluation question:
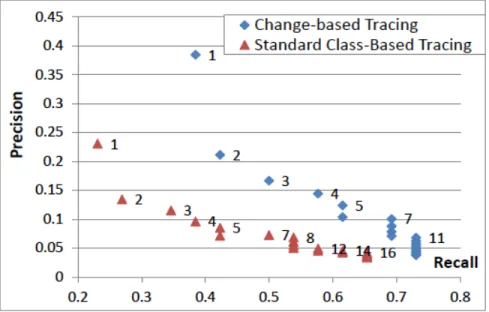
Figure 2: Evaluation of precision and recall of traced links
EQ1: How effective are the proposed heuristics for differentiating between changes which impact requirements and those which do not?
Results:
Using their comparing tool, 33 classes were identified, covering 12 of the 14 requirements-related changes. Among the 33 identified classes, 26 actually contained parts of the 14 changes. The other 7 classes were simple refactorings. Thus, the approach achieved a precision of 26 / 33 = 79 % and a recall of 12 / 14 = 85.7 %.
Second, they evaluate the effectiveness of using change-related keywords for trac-ing the changes to requirements instead of tractrac-ing classes directly, thus validattrac-ing the second and third step of their approach that we described in 3.3. The evaluation ques-tion is:
EQ2: Does the approach of change-based tracing give better results than the class-based tracing? If yes, how much?
Result is given in Fig. 2 and means that the enhancement of keywords from class names to other (discussed in 3.3 brings better precision and recall.
4
Conclusion
Concluded, information retrieval techniques can provide a way to recovering traceabil-ity links between the documentation of a system and its source code (between high-level documents and low-high-level documents) and reduce the manual effort required from
the engineer to maintain the software system.
Document matching is done automatically, and the analyst then inspects the can-didate links. Its full automation cannot be achieved because of uncertainty of natural language. The experiments have shown [2] that it is possible to achieve a very high recall (about 100 % ) but with the accompanying precision about 14 %.
Because of using natural language, problems caused by ambiguity can be expected. This means that different modules are programmed from different programmers (dif-ferent team from dif(dif-ferent countries) who can have dif(dif-ferent interpretation for words. In information retrieval, a large free text of a document provides a context of the used word but it is not the case of comments in source programs. Of course, it is necessary to avoid reusing the same term to describe different concepts in different domains.
Such a semantic gap can be resolved by defining domain-specific synonyms and by a tool that decides about their matching. The domain description is based on a well-constructed project glossary, defined during initial discovery meetings with stakehold-ers and used consistently throughout product development. It will generally increase consistency in term usage and subsequently improve traceability. Experiences are de-scribed in [21]. They weighted keywords from glossary more highly than other types of keywords and have got an advantage in precision and recall.
Acknowledgments
This work was partially supported by the Grant Agency of the Czech Republic project P103/11/1489.
References
[1] Abbott, R.J.: Program design by informal english descriptions. Communications of the ACM, 26(11), pp. 882894, 1983.
[2] Antoniol, G., Canfora, G., Casazza, G., De Lucia, A., Merlo, E.: Recovering Traceability Links between Code and Documentation. IEEE Transactions on Soft-ware Engineering, Vol. 28, No. 10, October 2002
[3] Charrada2012 Charrada, E.B., Koziolek, A., Glinz, M.: Identifying Outdated Re-quirements Based on Source Code Changes. In: Proceedings Requirement Engi-neering 2012, Chicago, IEEE 2012.
[4] Charrada, E.B., and Glinz, M.: An automated hint generation approach for support-ing the evolution of requirements specifications. In: Proc. Joint ERCIM Workshop Software Evolution (EVOL) and Int. Workshop Principles of Software Evolution (IWPSE), pp. 5862, 2010.
[5] Cleland-Huang, J., Chang, C.K., and Christensen, M.: Eventbased traceability for managing evolutionary change. IEEE Trans. Softw. Eng., Vol. 29, No. 9, pp. 796810, 2003.
[6] Cleland-Huang, J., Settimi, R., Romanova, E., Berenbach, B., and Clark, S.: Best Practices for Automated Traceability. IEEE, June 2007.
[7] Telelogic product DOORS, http://www.telelogic.com/products/ doorsers/doors/index.cfm, 2005.
[8] Egyed ,A. et al.: A Value-Based Approach for Understanding Cost-Benefit Trade-Offs During Automated Software Traceability. In: Proceedings of the 3rd Interna-tional Workshop Traceability in Emerging Forms of Software Engineering, ACM Press, pp. 2-7, 2005.
[9] Ernst, N., Borgida, A., and Mylopoulos, J.: Requirements evolution drives soft-ware evolution. In: Proc. Joint ERCIM Workshop Softsoft-ware Evolution (EVOL) and Int. Workshop Principles of Software Evolution (IWPSE), pp. 1620, 2011. [10] Gemeinhardt, L.: Connecting TESSI and Rational Rose by means of XML.
Project Report, TU Chemnitz, 2000. (In German)
[11] Gotel, O.C.Z., and Finkelstein, A.C.W.: An Analysis of the Requirements Trace-ability Problem. Proceedings of the 1st IEEE International Conference Require-ments Engineering, IEEE CS Press, pp. 94-101, 1994.
[12] Hayes, J., Dekhtyar, A., and Sundaram, S.: Advancing candidate link generation for requirements tracing: the study of methods. IEEE Trans. Softw. Eng., vol. 32, no. 1, pp. 419, Jan. 2006.
[13] Hayes, J., Dekhtyar, A., Sundaram, S., Holbrook, E., S. Vadlamudi, S., and April, A.: REquirements TRacing On target (RETRO): improving software maintenance through traceability recovery. Innovations in Systems and Software Engineering, Vol. 3, No. 3, pp. 193202, 2007.
[14] Herrmann, A., Wallnofer, A., and B. Paech, B.: Specifying changes only a case study on delta requirements. In: Requirements Engineering: Foundation for Soft-ware Quality, pp. 4558, 2009.
[15] Kroha, P., Janetzko, R., Labra, J. E.: Ontologies in Checking for Inconsistency of Requirements Specification. In: Dokoohaki, N., Zavoral, F., Noll, J.(Eds.): Pro-ceedings of the 3rd International Conference on Advances in Semantic Processing SEMAPRO 2009, IEEE Computer Society, Sliema, Malta, October 2009.
[16] Lethbridge, T.C., Singer, J., and Forward, A.: How software engineers use docu-mentation: The state of the practice. IEEE Softw., vol. 20, no. 6, pp. 3539, 2003. [17] Oliveto, R., Gethers, M., Poshyvanyk, D., and De Lucia, A.: On the equivalence
of information retrieval methods for automated traceability link recovery. In: Pro-ceedings of International Conference Program Comprehension, pp. 6871, 2010. [18] Rational RequisitePro, http://www-306.ibm.com/software/awd tools/reqpro/,
[19] de Souza, S.C.B., Anquetil, N., and de Oliveira, K.M.: A study of the documen-tation essential to software maintenance. In: Proceedings of International Confer-ence Design of communication: documenting and designing for pervasive infor-mation, SIGDOC05, pp. 6875, 2005.
[20] Spence, I., Probasco, L.: Traceability Strategies for Managing Requirements with Use Cases. Rational Software White Paper, 2000
[21] Zou, X., Settimi, R., and Cleland-Huang, J.: Phrasing in Dynamic Requirements Trace Retrieval. In: Proc. 30th Ann. Intl Computer Software and Applications Conf., IEEE CS Press, pp. 265-272, 2006.