Kent Academic Repository
Full text document (pdf)
Copyright & reuse
Content in the Kent Academic Repository is made available for research purposes. Unless otherwise stated all
content is protected by copyright and in the absence of an open licence (eg Creative Commons), permissions
for further reuse of content should be sought from the publisher, author or other copyright holder.
Versions of research
The version in the Kent Academic Repository may differ from the final published version.
Users are advised to check
http://kar.kent.ac.uk
for the status of the paper.
Users should always cite the
published version of record.
Enquiries
For any further enquiries regarding the licence status of this document, please contact:
[email protected]
If you believe this document infringes copyright then please contact the KAR admin team with the take-down
information provided at
http://kar.kent.ac.uk/contact.html
Citation for published version
Kanjo, Eiman and Younis, Eman and Ang, Chee Siang (2018) Deep Learning Analysis of Mobile
Physiological, Environmental and Location Sensor Data for Emotion Detection. Information
Fusion . ISSN 1566-2535.
DOI
https://doi.org/10.1016/j.inffus.2018.09.001
Link to record in KAR
https://kar.kent.ac.uk/68930/
Document Version
ContentslistsavailableatScienceDirect
Information
Fusion
journalhomepage:www.elsevier.com/locate/inffus
Full
Length
Article
Deep
learning
analysis
of
mobile
physiological,
environmental
and
location
sensor
data
for
emotion
detection
Eiman Kanjo
a ,∗, Eman M.G. Younis
b, Chee Siang Ang
caComputingandtechnologyDepartment,NottinghamTrentUniversity,Nottingham,UK bFacultyofComputersandInformation,MiniaUniversity,Minia,Egypt
cSchoolofEngineeringandDigitalArts,UniversityofKent,UK
a
r
t
i
c
l
e
i
n
f
o
Keywords:Deep learning Emotion recognition Convoltutional neural network Long short-term memory mobile sensing
a
b
s
t
r
a
c
t
The detection and monitoring of emotions are important in various applications, e.g., to enable naturalistic and personalised human-robot interaction. Emotion detection often require modelling of various data inputs from multiple modalities, including physiological signals (e.g., EEG and GSR), environmental data (e.g., audio and weather), videos (e.g., for capturing facial expressions and gestures) and more recently motion and location data. Many traditional machine learning algorithms have been utilised to capture the diversity of multimodal data at the sensors and features levels for human emotion classification. While the feature engineering processes often embedded in these algorithms are beneficial for emotion modelling, they inherit some critical limitations which may hinder the development of reliable and accurate models. In this work, we adopt a deep learning approach for emotion classification through an iterative process by adding and removing large number of sensor signals from different modalities. Our dataset was collected in a real-world study from smart-phones and wearable devices. It merges local interaction of three sensor modalities: on-body, environmental and location into global model that represents signal dynamics along with the temporal relationships of each modality. Our approach employs a series of learning algorithms including a hybrid approach using Convolutional Neural Network and Long Short-term Memory Recurrent Neural Network (CNN-LSTM) on the raw sensor data, eliminating the needs for manual feature extraction and engineering. The results show that the adoption of deep-learning approaches is effective in human emotion classification when large number of sensors input is utilised (average accuracy 95% and F-Measure =%95) and the hybrid models outperform traditional fully connected deep neural network (average accuracy 73% and F-Measure =73%). Furthermore, the hybrid models outperform previously developed Ensemble algorithms that utilise feature engineering to train the model average accuracy 83% and F-Measure =82%)
1. Introduction
Thegrowingpopularityofsensorsandlowpowerintegratedcircuits, togetherwiththeincreasinguseofwirelessnetworkshaveledtothe developmentofaffordable,robustandefficientwearabledeviceswhich cancaptureandtransmitdatainrealtimeforalongperiodoftime. Thesedatasourcesprovideauniqueopportunityforinnovativeways inrecognisinghumanactivitiesthroughhumanphysiologicalsensing whilealsotakingintoaccountothernaturalenvironmentalfactors,such asweather,noiselevels,etc.Thiscouldpotentiallycontributetobetter managementofchronicdiseasessuchasdiabetes,asthmaand cardio-vasculardiseases [1] .Forexample,extensiveresearchhasfocusedon automaticdetectionofphysicalexerciseswhicharelinkedtoarangeof healthrelatedissues [2] .Duetothesepotentialimpacts,researchwork isontherisewithmanyalgorithmsbeingdevelopedforarangeof
appli-∗Corresponding author.
E-mailaddress:[email protected](E. Kanjo).
cationareasinhealthcare(e.g.,symptomsmonitoring,home-based re-habilitation)andbeyond(e.g.,security,logisticssupports) [2,3] .Some of thesemachinelearningalgorithmsincludemultivariateregression, K-nearestNeighbour(KNN)classificationcombinedwithDynamicTime Warping(DTW),etc.Inaddition,giventheimportanceofmentalhealth anditsincreasingimpactonsocieties,researchersarenowfindingways toaccuratelydetecthumanemotionwiththehopetodevelop interven-tionstrategiesformentalhealthandtoprovidesrichcontextual infor-mation whichcan beused tobetterunderstand mentalhealth issues
[4] .Furthermore,therehavealsobeensignificantinterestsinemotion detectioninhuman-computerinteractions [5] duetoitspotentialuse, allowingustodesignintelligentcomputersystemswhichareadaptable accordingtousersemotionalstates,ensuringconvergenceand optimi-sationofhuman-computerinteraction.Therefore,therehavebeen nu-merousattemptstoexploitmachinelearningtechniquesutilisingsensor datasetsforautomaticemotiondetection [6–9] .Todate,asignificant amountofresearchinautomaticemotiondetectionhasbeencarriedout primarilyusingvisual,audioandmovementdata(e.g.,facialexpression, bodypostures,speeches) [3,6,8–10] .Withtheincreasedavailabilityof
https://doi.org/10.1016/j.inffus.2018.09.001
Received 15 January 2018; Received in revised form 14 August 2018; Accepted 1 September 2018 Available online 5 September 2018
low-costwearablesensors(e.g.,Fitbit,Microsoftwritsbands),thereis anemergencein researchinterestinusinghumanphysiologicaldata (e.g.,galvanicskinresponse(GSR),heartrate(HR), electroencephalog-raphy(EEG),etc.) foremotiondetection.Apartfromthese,giventhe intimatelinksbetweenemotionandenvironmentalfactors [6] ,studies arestartingtolookintousingenvironmentalsensorsdataandlocation patternstoinferhumanemotion [6] .Despitethepossibilityofsensing awiderangeofinformation(fromhumanphysiologytoenvironment), automatichumanemotionclassificationremainsverychallengingdue totheidiosyncrasyandvariabilityofhumanemotionalexpressions[11] . Therangeof modalitiesof emotionexpressioncouldbe very broad, withmanyofthesemodalitiesstillbeinginaccessibletocurrentsensor technology(e.g.,bloodchemistry).Manyaccessiblephysiological sig-nalsmaybenon-differentiableinemotiondetection [11] .Furthermore, studiesinautomaticemotiondetectionrelyoncontrolledsamplesinlab settings,wherespecificemotionsareartificiallytriggeredusing audio-visualstimuli(e.g.,presentingphotosorvideostoparticipants)orby askingparticipantstocarryoutcarefullydesignedtaskstoinduce emo-tionalstates [12] .Althoughthistypeofcontrolledstudiesisvaluable forcertainapplications(e.g.,clinicaldiagnosisinhealthcare),itsuse isratherlimitedtostrictlycontrolledenvironments.Foremotion de-tectiontechnologytobeusefulintheeverydaymanagementofmental healthandmobilehuman-computerinteractioninthewild,weare in-terestedintechniqueswhichallowustodetectemotionon-the-goandin real-lifesettings.Inthispaper,weexploreadeeplearningapproachfor multivariatetimeseriesclassification,combiningenvironmental, phys-iologicalandlocationsensordatausingsmartphonesandwristbands. Inspiredbythedeepfeaturelearninginimagesandspeechrecognition
[13–15] ,weexploreadeeplearningframeworkformultivariatetime seriesclassificationforemotionrecognitioninthewild,whereusersare walkinginaurbanarea.Deeplearningrelievestheburdenofmanually extractinghand-craftedfeaturesformachinelearningmodels.Instead,it canlearnahierarchicalfeaturerepresentationfromrawdata automat-ically.Weleveragethischaracteristicbybuildingmodelsusingarange ofdeeplearningmethodstotrainrawsensordata.Thiseliminatesthe needfordatapre-processingandfeaturespaceconstruction,and simpli-fiestheoverallmachinelearningprocess[16] .Duetoitssuccessin im-ageandspeechclassification,deeplearninghasbeenincreasinglyused fornon-image/speechdata,includinghumanactivityrecognitionusing timeseriesdatasuchasinthecaseofsmartphoneaccelerometerdata
[1,17–19] .Therehavealsobeenrecentattemptsusingdeeplearningfor emotiondetection,althoughmoststudieshaveonlylookedatlabbased emotiondata [9,20] .Specifically,weproposeaMulti-ChannelsDeep ConvolutionalNeuralNetwork(MC-DCNN)model.Wefollowahybrid approachbasedonConvolutionalNeuralNetworkandLongShort-term MemoryRecurrentNeuralNetwork(CNN-LSTM)inspiredbyprevious stateoftheart[19,21] whichhavebeenappliedtohumanactivityusing accelerometerdata.Themajorityofthestudiesemployingdeep learn-ingonactivityrecognitionarerestrictedtoahandfulofdatachannelsas opposedtothisstudy,whereweutilise20sensorchannelsfromthree differentmodalitiestoclassifyemotionagainstself-reportedemotion labels.Themaincontributionofourworkliesin:
1. Theuse ofmultimodalsensorfeeds(physiological,environmental andlocationdata)foremotiondetectionusing features automati-callyextractedwithdeeplearningapproach.Althoughdeep learn-inghasbeenusedinhumanactivity/emotiondetection,few stud-ieslookedintomultimodaldatasets.Specifically,tothebestofour knowledge,nootherworkhasapplieddeeplearningonthe combi-nationofphysiological,environmentalandlocationdataforemotion recognition.
2. Thecollectionofreal-worlddatafromparticipantswalkingina tran-sitedcitylocationwearingawristbandandsmartphone,while re-portingtheiremotionperiodicallyusingasmartphone.Thedata therefore better reflect the complexity of real life environments. Mostpreviousstudiesinautomaticemotiondetectionarecarriedout
incontrolledlabsettingsasopposedto“inthewild” (i.e.,in partic-ipants’naturalenvironments),thereforetheresultsarerestrictedto narrowapplicationdomains.
3. Variousexperimentscarriedouttocomparedifferentarchitectures of deep neural networks, including hybrid models using hybrid multi-channelsensordata(beyondhumanactivityrecognition). 4. Theanalysisandfusionofhumanphysiological,environmentaland
locationfeaturesindividuallyandcombinedtoexploreits signifi-canceinemotionclassification.
2. Relatedwork
Inrecentyears,smartphonesandmanywearabledevicessuchas smartwatchesandwristbands areequipped witharangeof sensors whichcancontinuouslymonitorhumanphysiologicalsignals(e.g.,heart rate, motions/movements,location data) andin somecases the am-bientenvironment data(e.g.,noise,brightness,etc.).Thisled tothe emergenceof largedatasets inawidevarietyofresearch areassuch ashealthcareandsmartcity.Thisburstofon-Bodyand environmen-taldatapresentsanunprecedentedopportunityforhealthcareresearch, butitrequiresthedevelopmentofnewtoolsandapproachestodeal withlargemultidimensionaldatasets.Inthepastdecades,researchers from variousfields,particularlyinubiquitous andmobile computing havebeenexploringthepossibilitiesharnessingthesedatatoinferor predicthumanbehaviour,withvaryinglevelsofsuccess [1,17–19,22– 25] .Giventherelativeeaseofcollectingtimeseriessensordatasets, re-searchershaveinvestigatedtherelationshipbetweenthesesensordata andhumanemotion.Themajorityemploytraditionalstatistical analy-sismethodsandmachinelearningtechniques.Often,anumberof hand-craftedfeaturesthatsummarisetherawsensordataareextractedfrom thelessstructureddata.Thesefeaturesarethenfilteredempiricallyor using structuredalgorithmsthrougha featureselectionprocess [16] . Featureswithlowlevelofcorrelationwithitscorrespondinglabelare excluded(throughdimensionalityreduction).Moreover,featuresare of-tenremovedtoavoid collinearity,whenexcessivecorrelationamong explanatoryvariables(features)existinthedataset.Giventhelistof se-lectedfeatures,computationalmodelsarebuiltwhichhelpclassifyor predicthumanactivity/emotionusingmachinelearningmodelssuchas logisticregressionbasedmodels [6] ,supportvectormachines(SVM), decisiontrees,artificialneuralnetworks(ANN),etc. [26,27] .Although hand-craftedfeatureshaveyieldedpromisingresults,theyare domain-specific,andoftenpoorlygeneralisetoothersimilarproblemdomains. Handcrafted-based approaches involvelaborious humanintervention forselectingthemost discriminatingfeaturesanddecision thresholds fromsensordata.Handcraftedfeatureshaveadecisiveimpacton mod-els [16] andoftenutilisestatisticalvariables,e.g.,mean,variance, kur-tosisandentropy,asdistinctiverepresentationfeatures.Moreover, tra-ditionalmachinelearningandfeatureengineeringalgorithmsmaynot beefficientenoughtoextractthecomplexandnon-linearpatterns gen-erallyobservedinmultimodaltimeseriesdatasets.Inaddition, tradi-tionalfeatureengineeringcouldalsoresultinalargeoutputfeaturesset
[28] .Thisisproblematicbecauseitisdifficulttoknowwithouttraining whichfeaturesarerelevanttoagiventask,andwhicharenoise.Asa result,theabilitytoselectfeaturesfromahugefeaturesetiscritical andwillrequireadditionaldimensionalreductiontechniquestoprocess thesefeatures.Furthermore,featureextractionandfeatureselectionare computationallyexpensive.Thecomputationalcostoffeatureselection mayincreasecombinatoriallyasthenumberoffeaturesincreases[28] . Ingeneral,searchalgorithmsmaynotbeabletoconvergetooptimal feature setsfor agivenmodel [16] .Giventhecomplexity of human emotiondetection,itisimportanttohaveabstractrepresentationsofthe sensordatawhichareinvarianttolocalchangesinthedata.Learning suchinvariantfeaturesisamajorchallengeinpatternrecognition(for examplelearningfeatureswhichareinvarianttothetimeofdata collec-tion).Traditionalshallowmethods,whichcontainonlyasmallnumber ofnon-linearoperations,donothavethecapacitytoaccuratelymodel
suchvariationoftimeseriesdata.Therefore,toovercomethedifficulties inobtainingeffectiveandrobustfeaturesfromtime-seriesdata,many re-searchershaveturnedtheirattentiontodeeplearningapproaches.One interestingpropertyofdeeplearningtechniquesisthattheycanwork onrawdataandautomatethefeatureextractionandselection.Noisy timeseriessamplesarefedintothenetworkasinputdata,andduring eachtransformation,ahiddenrepresentationofinputsfromtheprior layerisgeneratedtoformahigherhierarchicalarchitectureofdata rep-resentation(i.e.,features).Onecantrainthenetworkbyadjustingthe mappingparameters,inordertoobtainfinerabstractionlevels. Specif-ically,eachlayerinadeeplearningmodelcombinesoutputsfromthe previouslayerandtransformsthemviaanon-linearfunctiontoforma newfeatureset.Thisgivesadeeplearningmodeltheabilityto automat-icallylearnfeaturesdirectlyfromtheunderlyingsensordata,forminga hierarchy,wherebasicfeaturesaredetectedinthefirstlayers,andinthe deeperlayerstheabstractfeaturesfrompreviouslayersarecombinedto formcomplexfeaturemaps.Empiricalstudiesshowedthatdata repre-sentationsobtainedfromstackingupnon-linearfeatureextractinglayers asindeeplearningoftenyieldbetterresults,e.g.,improved classifica-tionmodelaccuracy [18] ,bettergenerativemodels(toproducebetter qualitysamples) [18] ,andtheinvariantcharacteristicsofdata repre-sentations[18] .Deeplearningtechniqueshavealreadymadesignificant impactsincomputervision [13,29,30] ,speechrecognition[31,32] and naturallanguageprocessing [20,33,34] ,whereitperformsbetterthan standardmachinelearningmethodsandtheperformanceis compara-bletohumanlevel.Whilesomeattemptsatdetectinghumanactivity andemotionhavebeenmadeusingdeeplearning[8,9,17,20,21] ,itis stillanewandgrowingareaofresearchwhichrequiresfurtherwork. Inrecentyears,deeplearninghasbeenincreasinglyusedinthefieldof humanactivityrecognition[17,21] .Whileprogresshasbeenmade, hu-manactivityrecognitionremainsachallengingtask.Thisispartlydue tothebroadrangeofhumanactivitiesaswellastherichvariationin howagivenactivitycanbeperformed.Sincedeeplearningiscapableof high-levelabstractionofdata,itcanbeusedtodevelopself-configurable frameworksforhumanactivityaswellasemotionrecognition.For in-stance,inanattempttoimproveperformanceaccuracyofactivity recog-nitionusingmobilephonetriaxialaccelerometerdata,Alsheikhetal.
[17] utilisedahybridapproachofdeeplearningandhiddenMarkov models(HMM).Thisapproachallowstomodeldeephierarchical rep-resentationsofspatialdatawithrestrictedBoltzmannmachines(RBM) andstochasticmodellingoftemporalsequencesin theHMMmodels. Theproposedapproachwasreportedtohaveperformedbetterthan tra-ditionalmethodsofusingshallownetworkswithhandcraftedfeatures. Otherdeeplearningarchitectures,includingConvolutionalNeural Net-work(CNN)andRecurrentNeuralNetwork(RNN)havebeen increas-inglyappliedinactivityrecognitionproblems.TheperformanceofCNN forsomeactivityrecognitiontaskswasexploredbyZengetal. [35–37] . BuildingonCNNssuccessesinimagerecognition,Hintonetal.[13] de-velopedamethodbasedonCNNandapplieditinactivityrecognition problemsinthreedifferent domains:assemblinglineactivities, activi-tiesinkitchenandjogging/walking.CNNwasutilisedtoautomatically extractfeaturesfromaccelerometerdatawithout anydomain knowl-edge.ItwasshownthatCNNcancapturelocaldependenciesand invari-antfeaturesinthedata.ExperimentalresultsshowedthatCNN outper-formedtraditionalmachinelearningapproaches.UsingaCNNmodel, Alsheikhetal.[17,21] demonstratedthatitcanmodelcomplex multi-variatesensorytimeseriesdata(consideringaccelerometerandgyro data) in recognition commonhumanactivities, e.g.walking, sitting, laying,etc.Specifically,CNNoutperformedSVMwhichhaspreviously achievedthebestperformanceinthisdataset [37] .showedthatCNN alsooutperformedotherconventionalmachinelearningmethods(e.g., KNNandSVM)intwootheractivityrecognitiondatasets:breakfast ac-tivityandgesturerecognition.ACNNisusedin [38] toextractfeatures forgaitpatternrecognitionsothatlabourintensivehand-craftedfeature extractionprocessisavoided.Furthermore,CNNshavebeenappliedfor detectionofstereotypicalmovementsinAutism[39] ,wherethey
signif-icantlyimproveduponthestate-of-the-art.Recurrentneuralnetwork (RNN)relyingonLongShort-TermMemory(LSTM)cellshavegained popularity duetoits abilitytoexploit thetemporaldependenciesin timeseriesdata.LSTMhaverecentlyachievedimpressiveperformance invarioustime-dependentapplications,suchasmachinetranslations, automaticvideosubtitling,andothers[40] .Abiometricsapplicationof LSTMhasbeenexploredbyNeverovaetal. [41] toidentifyindividual humansbasedontheirmotionpatternscapturedfromsmartphones,i.e., accelerometer,gyroscopeandmagnetometer.Thisisachallengingtask, astemporalmotionsignalsaregenerallyverynoisy.Theirworkusing LSTMdemonstratedthathumanmovementconveynecessary informa-tionaboutthepersonsidentityanditispossibletoachieverelativegood authenticationresults.Furthermore,thesameLSTMalgorithmcanalso be appliedtoothertimeseriesdataongesturedetectioninahuman conversation.In [21] ahybridapproachwasusedbasedonCNNand LSTMtoclassifyhumanactivitiesusingtwopublicdatasets(daily activ-itiesandassemblylineactivities).ThefundamentalideaistouseCNN toautomaticallyextractspatialfeaturesfromrawsensorsignals,and LSTMtocapturethetemporaldynamicsofthehumanmovement.Their resultsshowedthatCNN-LSTMhybridmodeloutperformedotherdeep modelswithoutusingLSTMtomodeltimedependencies.Importantly,it wasshownthatthemodelcanpotentiallybeusedinmultimodalsensor data.
2.1. ConvolutionalNeuralNetworks(CNN)
ConvolutionalNeuralNetworks(CNN)areawidelyuseddeep learn-ingalgorithmwhichperformsespeciallywellforimagesinputdata, al-thoughtheyarenowincreasinglyappliedintimeseriesdataincluding humanphysiologicaldataandfinancialdata [21,42] .Theinputsina convolutionallayerconnecttothesubregionsofthelayersinsteadof beingfully-connectedasintraditionalneuralnetworksmodels.These group of inputsin subregionsshare thesameweights, therefore the inputsofaCNNproducespatially-correlatedoutputs,whereas in tra-ditionalneuralnetworks(NN),eachinputhasindividualweightand henceproduceindependentoutputs.Inaneuralnetworkwithonly fully-connectedlayers,thenumberof weightscanincrease quicklyasthe dimensionoftheinputincreases.CNNsreducethenumberofweights compared withNN withthereducednumberof connectionsthrough weights sharing and downsampling.CNNs typically consist of three typesoflayers:convolutionallayers,pooling/downsamplinglayersand fully-connectedlayers.
• TheconvolutionallayeristhemainbuildingblockofaCNNwhich
determines theoutputof connectedinputs inwithin local subre-gions.Thisisdoneviaasetoflearnablefilters(kernels)whichare convolvedacrossthewidthandheightoftheinputdata, calculat-ingthescalarproductbetweenthevaluesofthefilterandtheinput, henceproducingatwo dimensionalactivationmapof thatfilter. Throughthis,CNNs areabletolearnfilterswhich activatewhen specifictypeoffeaturesatsomespatialpositionoftheinputare de-tected.
• Thepoolinglayerwillperformdownsamplingalongthespatial
di-mensionality of the giveninput, further reducing thenumber of weightswithinthatactivation.
• Thefully-connectedlayersarestandarddeepneuralnetworksand
attempttoproducepredictionsfromtheactivation,tobeusedfor classificationorregression.
ConvolutionisthekeyoperationinCNN.Byconvolutionofthe in-putsignalwithalinearfilter(orkernel),addingabiastermandthen applyinganon-linearfunction,a2Dmatrixnamedfeaturemapis ob-tained,representinglocalcorrelationacross theinput signal. Specifi-cally,foracertainconvolutionallayer,theunitsinitareconnectedto alocal subregionof unitsinthe(l-1)thlayer.Notethatalltheunits inonefeaturemapsharethesameweightvector(forkernel)andbias,
hence,thetotalnumberofparametersismuchlessthantraditional mul-tilayerfullyconnectedneuralnetworkswiththesamenumberof hid-denlayers.ThisindicatesthatCNNhasasparsenetworkconnectivity
[14] ,whichresultsinconsiderablyreducedcomputationalcomplexity comparedwiththefullyconnectedneuralnetwork.Foraricher repre-sentationoftheinput,eachconvolutionallayercanproducemultiple featuremaps.Thoughunitsinadjacentconvolutionallayersarelocally connected,varioussalientpatternsoftheinputsignalsatdifferentlevels canbeobtainedbystackingseveralconvolutionallayerstoforma hi-erarchyofprogressivelymoreabstractfeatures.Forthejthfeaturemap inthelthconvolutionallayerCl,j,theunitatthemthrowandthenth columnisdenotedasvm,nl,jandthevalueofvm,nl,jisdefinedby:
��, ��, � = �(��, � +∑� ∑�� =0� �, � 1∑�� =0� �, � −1���, ���, �, ��� +��, � +���1, � )
∀� =1, 2, � �, � =1, 2, � � , (1)
whereMlandNlareheightandwidthoffeaturemapCl,j.bl,jisthe biasofthisfeaturemap,kindexesoverthesetoffeaturemapinthe (l–1)thlayer,wpa,pbl,j,kisthevalueofconvolutionalkernelatposition (pa,pb),Pl,aandPl,barethesizeoftheconvolutionalkernel,and �() istheRectifiedLinearUnits(ReLU)nonlinearfunction.ReLUisdefined by:
�(� )=max(0, � ) (2)
Theproposedconvolutionoperationisperformedwithoutzeropadding (unliketheconventionalapproachesofimageprocessing).Thismeans eachdimensionoffeaturemapwillbereducedafteraconvolution op-eration.Thus:
� � =� � −1−� �, � +1� � =� � −1−� �, � +1, (3)
wherelistheindexofthelayerthatperformsconvolutionaloperation.
2.2. RecurrentNeuralNetworks(RNN)
Inatraditionalneuralnetwork(withonlyfullyconnectedlayers) weassumethatallinputsareindependentofeachother.InCNN,we haveseenthatinputscanbegroupedintosubregions,wherefeatures arespatiallydependentoneachotherandsharethesameweights.For someclassification/learningtasks,theinputsaretemporallydependent. Forinstance,ifwewanttopredictthenextwordinasentence,itis im-portanttoknowwhichwordscamebefore it.RNNscan performthe classificationtaskforeveryelementofatimesequence,withtheoutput beingdependedonthepreviouscomputations.Anotherwaytothink aboutRNNsisthattheyhave amemorywhich capturesinformation aboutwhathasbeencalculatedsofar.Inotherwords,RNNstakeas theirinputnotjustthecurrentinputdatatheysee,butalsowhatthey perceivedonestepbackintime.ThedecisionaRNNreachedattime step � −1affectsthedecisionitwillreachattimestept.Hence,RNNs
havetwosourcesofinput,thepresentandtherecentpast.Hereiswhat atypicalRNNlookslike:IntheoryRNNscanmakeuseofinformationin arbitrarilylongsequences,butinpracticetheyhavedifficultieslearning long-rangedependenciesduetothevanishinggradientproblem [43] . ThevanishinggradientproblemistheresultofRNNseekingto estab-lishconnectionsbetweenthefinaloutputandinputsfrommanytime stepsbefore asaRNNpassesthroughmanystagesof multiplication. Toaddressthis,weadoptLongShort-termMemory(LSTM)astheRNN memoryunit.LSTMshelppreservetheerrorthatcanbebackpropagated throughtimeandlayersbyusingagatedcellwhichdetermineswhat informationfromthepriorstepshouldbeforgottenandwhat informa-tionincurrenttimestepshouldberememberedintothenextstate,via gatesthatopenandclose(activateanddeactivate).ThisallowsaRNN tocontinuetolearnovermanytimesteps,therebyopeningachannel tolinkcausesandeffectsremotely(Fig. 1 ).
ThestructureofaLSTMcellisillustratedinFigureandthe mecha-nismofthegatesisdescribedasfollows:ThefirststepinaLSTMcellis
Fig.1. Long short term memory (LSTM) block [44].
todecidewhatinformationwewillforgetfromthecellstate.This deci-sionismadebyaSigmoidlayercalledtheforgetgatelayer.Itlooksat
ℎ � −1andxt,andoutputsanumberbetween0and1foreachnumberin
thecellstate � � −1.1representscompletelykeepthiswhile0represents
completelyremovethis.Theoutputftofthegateisformalisedas:
� � =�(� � ⋅[ℎ � −1, � � ]+��) (4)
Thenthecelldecideswhichnewinformationwillbestoredinthecell state.Thishastwoparts.First,asigmoidlayerknownastheinputgate layerdecideswhichvalueswillbeupdated.Then,atanhlayercreatesa vectorofnewcandidatevalues,� ̂
� ,whichcouldbeaddedtothestate.
Thesetwowillbecombinedtocreateanupdatetothestate,asfollow:
�� = �(� � ⋅[ℎ � −1, � � ]+� � ) (5)
̂
�� =tanh(� � ⋅[ℎ � −1, � � ]+� � ) (6)
Then,weupdatetheoldcellstate, � � −1, intothenewcellstateCtas
follow:
� � = � � −1∗� � +� � � ̂� (7)
Toproducetheoutput,aSigmoidlayerisfirstrun,whichdecideswhich partsofthecellstatewillbeoutput.Then,thecellstateisfedthrough tanh(topushthevaluestobebetween–1and1)andmultipliedbythe outputoftheSigmoidgate,asfollow:
�� =�(� � ⋅[ℎ � −1, � � ]+� � ) (8)
ℎ � =tanh(� � )∗ � � (9)
Aswe usedSoftmaxasour lastactivation,our lossfunction iscross entropyloss:
���� =−∑ �
log∑��� (� � � )
� ���(��� ) (10)
Finally,AdamOptimizercanbeusedtohaveabetternavigationthrough thelossfunction.
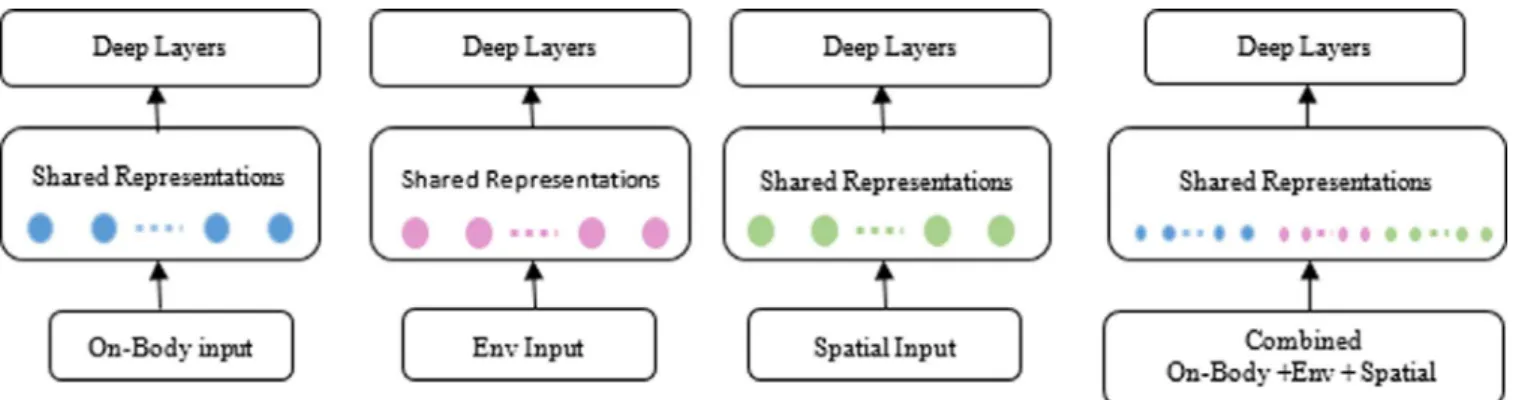
Fig.2. Learning Architectures, four models are trained, (a) for On-Body, (b) for Env , (c) for Location separately (d) and then fused using all the data input and feed it into the Deep Layers.
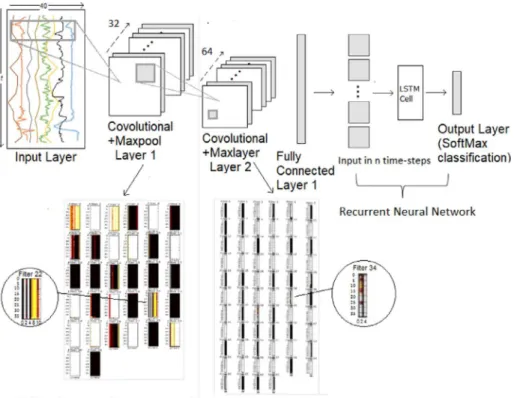
Fig.3. CNN architecture.
3. Methodology
Inthissection,weexplainindetailsthedatasetusedforemotion inthewildclassificationandthearchitecturesofdeeplearningmodels usedforexperimentation.
3.1. Theenvbodysensdataset
WeusetheEnvBodySensdataset [6] toevaluatethemodels,which consistsof40datafilescollectedfrom40femaleparticipants(average ageof28)walkingaroundthecitycentreinNottingham,UKon spe-cificroutes.Thedatasetiscomposedofon-bodydatasuchasheartrate (HR),galvanicskinresponse(SGR),bodytemperature,motiondata (ac-celerometerandgyro),environmentaldatasuchasnoiselevels,UV,air pressureandlocationdata,GPSlocationsassociatedwithtimestamp andselfreportemotionlevels(5-stepSelf-Assessment-Manikin(SAM) Scaleforvalence)loggedbytheEnvBodySensmobileapplication on Androidphones(Nexus),connectedwirelesslytoMicrosoftwristBand 2 [45] . Theparticipantswereaskedtospendno morethan45 min-uteswalkinginthecitycenter.Datawascollectedinsimilarweather conditions(average20° degrees),ataround11am.Duringthedata col-lectionprocess,550,432sensordataframeswerecollectedaswellas 5345self-reportresponses.Thestatisticaldataanalysisofthedatasetis reportedin[6] .Participantswereaskedtoperiodicallyreporthowthey feelbasedonpredefinedemotionscaleastheywalkedaroundthecity centre.Weadoptedthe5-stepSAMScaleforValencetakenfromBanzhaf etal.[46] tosimplifythecontinuouslabellingprocess.Onaverage,134 self-reportswereenteredperparticipants.Wedisabledthescreenauto sleepmodeonourmobiledevices,sothescreenwaskeptonduringthe datacollectionprocess. [6] .Datafromsixuserswereexcludeddueto loggingproblem.Forexample,oneuserwasunabletocollectdatadue tobatteryproblemwiththemobilephone,anotheruserswitchedthe
applicationoff accidentally.Thecorrelationmatrixin [6] showsalow levelofcorrelationbetweentheindependentvariables,suggestingthat ourmodelwillnotbeaffectedbythemulti-collinearityproblem.
4. Modelimplementation
WeuseTensorFlow [47] toimplementourmodelsandTensorboard forvisualisationonXeonE5-2640v4Processor(25MbCache,2.4GHz, 8 core).In thispaper, we firsttrain aMulti-layer Perceptron(MLP) foremotionclassificationbasedontwentyrawsensorinputfromthree modalities:(i)on-body(i.e.,physiologicalandmotion/movementdata), (ii)environmental,(iii)andlocationdata.Initially,wetraineach modal-ityindividuallyandthenwecombineallsensorinputmodalitiesina separatetrainingprocess,seeFig. 2 forthefourdifferentlearning archi-tectures.Thenweevaluatetheperformanceofeachmodalityagainst thecombinedmodel.Thisisthenfollowedbytrainingdeeplearning modelsinordertotesttheefficacyofthedeeplearningapproachfor accuratelyclassifyingmultimodaltimeseriesdata.
4.1. Datapre-processing
Afterthedatacollectionthesignalswerepre-processedandcleaned. Thefirstandthelast30swereremovedfromthestartofthedata col-lectionprocessforeachuserdata,thereasonforthisstepisthatusers neededafewsecondstofullyengageinthemovementandalsofew sec-ondstoterminatethedatacollectionprocess.Anon-overlappingsliding window strategyhasbeenadoptedtosegmentthetimeseriessignal. Fig. 12 showsthedifferencebetweenthetwosegmentationmethods.
4.2. MLPmodels
Our implementation of “Multi-Layer Perceptron” (MLP) network consistsoftwohiddenlayers.Thefirstlayerhas64 neuron,whereas
Fig.4. CNN-LSTM Model Architecture, we train 4 models separately, these are (a) On-Body, (b) Env , (c) for Location (d) and then we fused model using all the data input and feed it into the Deep Layers.
Fig.5. Comparison of average accuracy levels of all models.
thesecondhiddenlayerhas32neurons.Theinputlayeris20∗40
dimen-sionsperiteration.Theoutputlayerhas5neurons,eachcorrespondsto the5emotionalclasses.
4.3. CNNmodels
WestartwiththenotationsusedintheCNN.Aslidingwindow strat-egyisadoptedtosegmentthetimeseriessignalintoa(n,c,t)tensor, where � =numberofinstances, � =sensorchannels, � =timesteps. Af-terpreliminaryexperimentswithvariousdeeplearningtopologiesusing multiplemodalitiescombinations,wechoosetheCNNarchitectureas follows:Inputofnbatchx20channelsxtwindowsize,2convolutional layers(Conv1,Conv2),2maxpoolinglayers(Pooling1,Pooling2)and fully-connectedlayerasshownin3 .ThefirstlayerConv1has32filters (featuremaps)whilethesecondoneConv2has64filters.This proce-duremayhinderpartiallythegeneralityofthecreatedmodels,asthe averagecross-validationaccuracyisusedtoguidethefeatureselection search.However,thecomparisonbetweensingle,multiplemodalities,
andacrossfusionapproachesisfairbecauseallexperimentsfollowthe sameprocedure.Thewindowsize,r=40(i.e.,theheightofsliding
win-dow)ischosenexperimentally,bytryingdifferentsampleratesfrom10 to100asshownlaterin Table 2 .Theconvolutionkernelis2x2,stride is1x1,i.e.,strides=[1,1,1,1],Padding=1(whichdoesnotshrinkthe
matrix).
4.4. CNN-LSTMmodels
CNN-LSTMhasasimilarstructureasCNN,withanaddedLSTMlayer (see Fig. 3 ).Inparticular,thetemporaldimensionofthedatais pre-servedduringtheconvolutionoperation,andtheresulting fully con-nectedlayeris fedintoLSTM cell(see Fig. 4 ).Each LSTMcellkeeps trackofaninternalstatethatrepresentsitsmemory.Overtimethecells learntooutput,overwrite,orresettheirinternalmemorybasedontheir currentinputandthehistoryofpastinternalstates.TheMaxPool ker-nelis2x2,strideis1x2,i.e.,strides=[1,1,2,1],paddingis1.Sothat
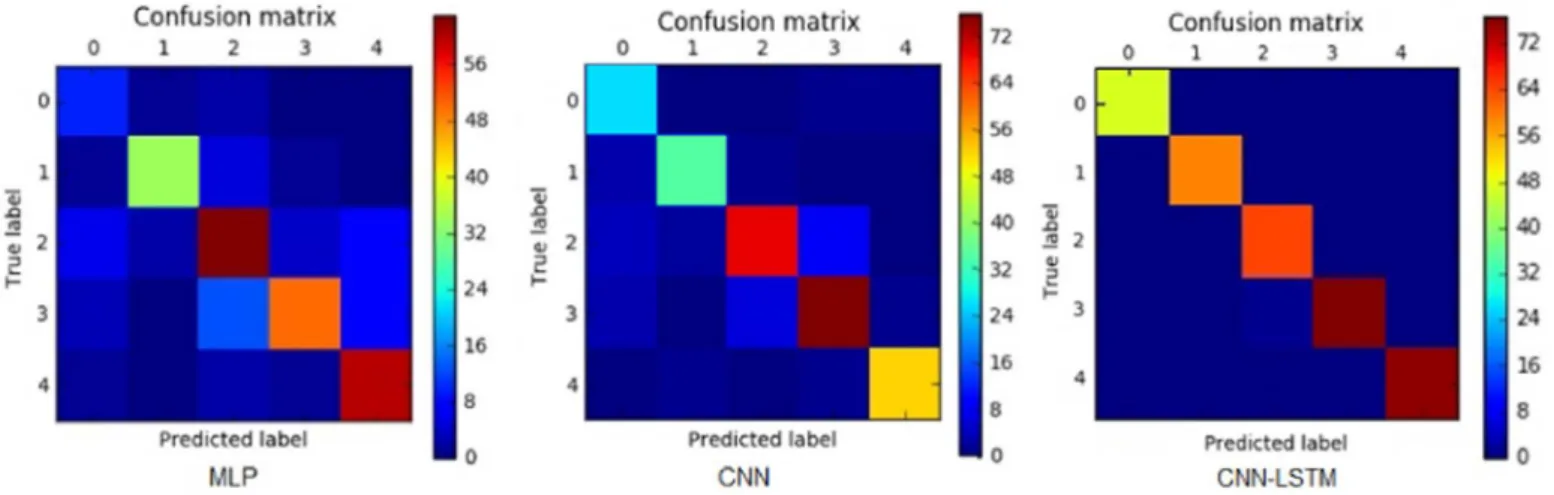
di-Fig.6. Confusion matrices of three models for one user data (fused data). Table1
Average performance metrics for all the models.
Average Precision Recall F-measure Accuracy RMSE
MLP All 0.734 0.728 0.729 72.9 0.95975 Body 0.654 0.621 0.63 62.2 1.264 Environment 0.424 0.428 0.424 42.6 1.54 Location 0.59 0.605 0.58 60.2 1.22 CNN All 0.818 0.79 0.787 78.6 0.788 Body 0.734 0.712 0.709 70.8 1.01 Environment 0.529 0.47 0.468 46.5 1.41 Location 0.79 0.761 0.769 78.7 0.99 CNN-LSTM All 0.927 0.95 0.949 94.7 0.291 Body 0.881 0.878 0.874 87.3 0.6 Environment 0.607 0.593 0.574 59.7 1.18 Location 0.655 5.586 0.621 64 1.03
mension.Thusoutputfiltersareof40x10dimensionafterfirstMaxPool layerand40x5afterthesecondMaxPoollayer.Similarly,32filtersare usedforthefirstConv1layerand64usedforthesecondConv2layer. Theoutputofthesefiltersarealsoshownin Fig. 4 .Wetrainallmodels mentionedaboveoneachsubjectdatasetusingfuseddatafromall sen-sorsmodalities.Wealsotrainthemodelsonthreesubsetsofthedata basedonthreemodalities:on-Body,EnvandLocation.Intotal,wetrain 12modelsoneachuserdataset(3x3modelsonsubsetsand3models onfuseddata).Here,n=40rawsamplesandc=20thenumberofthe at-tributesfromsensorinput.Similarly,c=2forthelocationmodels,c=3is forEnvmodels(Noise,Air-PressureandUV)andc=15fortheOn-body
models(therestoftheattributes).
4.5. Results
Alltheexperimentspresentedherearerunfordatafilesofeach in-dividualparticipantandthentheaverage(andstandarderror)ofthe re-sultingmodelspredictionaccuracyandotherperformancemetricsare reported.Theperformanceofthetrainedmodelisevaluatedby split-tingeachsubjectdatausingrandomsamplingtechniqueintotraining setof70%datainstancesandtestsetof30%.Evaluationresultsacross allexperimentsareillustratedinTable 1 ,basedonfivestandard perfor-manceevaluationmetrics:Precision,Recall,F-Measure,Accuracy, Er-rorrateandRMSE(rootmeansquarederror).Theaccuracylevelsof theresultsarealsocomparedbetweensinglemodalities(on-body, en-vironmentalandlocationmodality)andcombinedmodalitiesacrossall thethreemodels.WhenMLPwastrainedonlyon-Bodydatasubset,it achievedanaverageaccuracyof0.62(F-Measure:0.63±0.039).
Loca-tionmodelachievedanaverageaccuracyof0.60(F-Measure:0.580.032) whileMLPdidnotnotperformwellonEnvironmentdatawithan av-erageaccuracylowerthan0.50.MLPachievedanaverageaccuracyof 0.72(F-Measure:0.580.032)whenperformedonfusedmodalitiesdata
Table2
Average accuracy of CNN+LSTM models using different sliding window sizes. Bold numbers rep- resent the best performing window size.
Window size F-measure Accuracy RMSE
20 0.942 94 0.5 40 0.949 94.7 0.291 60 0.946 94.7 0.313 80 0.911 92.7 0.8 100 0.922 93.7 1.1 120 0.912 92.5 1.3
whichissignificantlyhigherthaneachsinglemodality(p< 0.01). More-over,theresultsshowthatCNNoutperformsMLPsignificantlyby6% (p < 0.01)withanaverageaccuracy0.79.(F-Measure:0.79 ± 0.034). Bothon-Body andLocationmodelswereimprovedwithCNN. CNN-LSTM model achieved anaverage accuracy of 0.95(F-Measure:0.95
± 0.022)withsignificant16%increasemarginin performance, com-paredtoCNNmodel(p < 0.01).Furthermore,theaccuracylevelofthe CNN-LSTMmodelincreasedconsiderablybasedon-Bodydataat0.87 (F-Measure:0.87 ±0.024,(p<0.01)),althoughthemodeldidnotdoas wellwithLocationdata.Theresultssuggestedthaton-Bodymodalityis themorerobustdatasourceforemotionclassification“inthewild”.The othertwomodalities,i.e.,EnvironmentandLocation,arenotaseffective ontheirownbuttogethertheyyieldimprovedperformancewhenfused withon-Bodydatabyapproximately7%inaccuracy.Thehighlevels ofaccuracyachievedwiththehybridCNN-LSTMmodelreinforcesthe effectivenessofdeeplearninginmultimodeltimeseriessensordatafor emotionrecognition.Duetolimitedspace,weonlyvisualisethe accu-racylevelsoftenparticipants.Radarchartin Fig. 5 showsthe differ-enceinaccuracylevelsof10usersexperimentswhichareselected
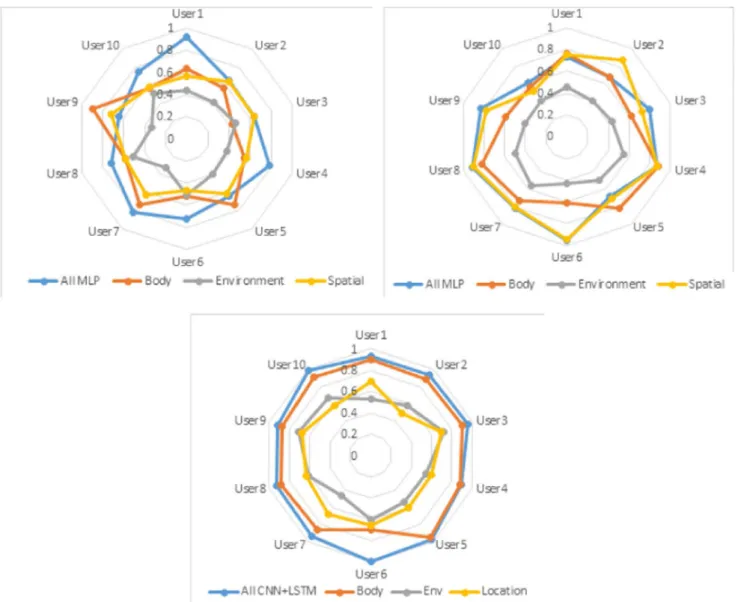
ran-Fig.7. Radar charts showing the accuracy levels of three models(a) MLP, (b) CNN , and CNN =LSTM, based on ten users data in ad-hoc and fused modes.
domly.WithCNN-LSTMaccuracylevelsrangingbetween0.89to0.996 (± 0.027).Similarly,Fig. 7 ,presents3radarchartsof10usersmodels
(figurepermodelMLP,CNNandCNN-LSTM).Itsclearfrom Fig. 7 that MLPmodelsresultedinthehighestvariationbetweenusers,andmodels basedonEnvironmentdataachievedthelowestaccuracylevels.While in 7 ,wecanseethatallthecombinedmodalitieshaveachievedhigh levelsofaccuracy. Fig. 7 ,illustratetheconfusionmatricesyieldedby thethreemodelsbasedfromoneuserdata.Thereisaslightconfusion betweenstate0and1(negativeemotions),whichisimprovedwhen LSTMisaddedtothearchitecture.Duringtheuserstudy,wehavemade agreatefforttoaskusersthemeaningofeachclassandthedifference betweentheverynegativelabel“0” andneutral“3”.Inaddition,we havecroppedthefirstfewminutesofthedatarecordingwhenusersare stationaryandusingdefaultrating(label)at3.Webelieveourdataset isreasonablybalancedwithsmallvariationfromoneusertoanother.
Moderndeep learningtechniques allowus totrain anetworkin batches by interleavingmultiple sequences together. Among others, batchingallowstofurtherexploit thepowerof matrixmultiplication ontheGPUandtoavoidloadingalldataintomemoryatonce.The batchsizehasimplicationsfortherobustnessoftheerrorthatis propa-gatedinthelearningphase [29] . Fig. 3 showsanexampleof3batches
thatencode3sequencesof5sampleseach.(Figs.6,8–10) Fig.8. The accuracy levels of 10 users across all the models in ad-hoc and fused
Fig.9. Cumulative distribution of recognition accuracy of 7 user.
Fig.10. Cumulative distribution of recognition loss of 7 users.
5. Discussion
Theobjectivesofourstudywereto(i)evaluatedeeplearningasa computationalmodelforemotionrecognition“inthewild” following state-of-the-artmethodologies,and(ii)toassesstheoverallpowerof deeplearningonmultmodalsensor dataincludingtimeseriessensor input(Physiological,EnvironmentalandLocationdata).Thisisoneof thefewstudieslookingintoemotionalrecognition of participantsin theirnaturalenvironmentusing multiplesourcesoftimeseriesdata. Ourresultshavedemonstratedthatrawfeaturescanperformwellwhen fusedutilisingdeeplearningmodels.Inparticular,CNNcombinedwith LSTMhasoutperformed traditionalMLPby morethan20%increase margin.Furthermore,applyingdeeplearningonmultimodelsensordata outperformedourearlierEnsemblealgorithmby6%margin [6] (see
Fig. 11 )whichisbasedonstakingvariouslearnersandrefinetheoutput byanothermetalearnerlayer.
Ourresults ingeneralhavesuggested thatdeeplearning method-ologiesareappropriateformodelingaffectivestatesand,more impor-tantly,indicatedthatad-hocfeatureextractionmaynotbenecessaryfor asdeeplearningmodelsareabletoidentifyhighlevelofdata abstrac-tionautomatically.Furthermore,insomeaffectivestatesexamined(e.g., relaxationmodelsbuiltonElectrodermalActivities(EDA);funand ex-citementmodelsbuiltonBloodVolumePulse(BVP);relaxationmodels builtonfusedEDAandBVP),deeplearningwithoutpriorfeature selec-tionmanagestoreachorevenoutperformtheperformancesofmodels builtonad-hocextractedfeatureswhichareboostedbyautomatic fea-tureselection.Thesefindingsshowcasedthepotentialofdeeplearning foraffectivemodelingbasedmultiplesensorsandmultiplemodalities input,asbothmanual featureextractionandautomaticfeature selec-tioncouldbeultimatelybypassed.Eventhoughtheresultsobtainedare morethanencouragingwithrespecttotheapplicabilityandefficacyof deeplearningforaffectivemodelling,thereareanumberoflimitations
Fig.11. Accuracy and F-Measure levels of the base learners and the stacking learner [6].
Fig.12. Illustration of sliding window steps and overlapping.
andresearch directionsthatshouldbe consideredinfutureresearch. Therearemanyparametersthatcanbetunedtoobtaintheoptimal per-formanceofthenetwork.e.g.wehavemanagedtotestvariousstepsizes oftheslidingwindowasshowninFig. 12 .Itdemonstratesthatbyonly analysingasmallchunckofdata(40samples,i.e.,160ms),thedeep learningmodelisabletoclassifyemotionsathighaccuracylevels.The testhasshownthatthemodelperformsatitsbestwhenthesliding win-dowstepsizeissetto40.However,thereareotherparameterswhich canbetunedbasedonsimilartestssuchasallowingwindowoverlapping andthewidthofwindowoverlapasshownin Fig. 12 .Whilethe Env-BodySensdatasetincludeskeycomponentsforemotionmodellingand isrepresentativeofatypicalaffectivemodellingscenario,ourapproach needstobetestedondiversedatasetswithlargernumberofparticipants andwithmoremodalitiesandaccounttootherfactorssuchaspollution levelsandcrowddensity,whichmayhavesignificantimpactonhuman emotions.Furthermore,weexpectthattheapplicationofdeeplearning tomodelaffectinlargephysiologicaldatasetswouldshow larger im-provementswithrespecttostatisticalfeaturesandprovidenewinsights ontherelationshipbetweenphysiologyandaffect.
Inaddition,we havedemonstrated thatouralgorithmscan work onthreeverydifferentmodalitiesincludingphysiological, enviromen-talandmovementactivities,webelieveourmodelscanalsoworkon almostanyothersensordata(beyondemotiondetectionandcity sens-ing).Alsoweareintheprocessofdeployingreal-timemobile applica-tionsthatcanrunthesemodelsonmobileandIoTplatformssuchas IntelEdisonmodule [48] .Wehaveattemptedtocombineall partici-pantsdataintoonesingledatasetforemotiondetection,howeverwe foundahighacross-subjectvariationinthedatasetwhichledtolow modelaccuracyoflessthan50%.Thisobservationisinagreementwith previousstudies [49] whichverifythatemotionrecognitionissubject dependentwhichmakesitdifficulttoobtainageneralisedmodelacross individuals.Othershavesuccessfullycreatedauniversaldeeplearning modelforgesturedataasgesturesperformedbydifferentindividuals aretypicallyquitesimilar.Foremotionhowever,thereishigherlevels ofvariationsbetweenindividuals.Ourresults,confirmthis,andverify
thattheemotionrecognitionissubjectdependentastheaccuracyvaries fromsubjecttosubjectandexhibitshighvarianceofaccuracy.
6. Conclusion
Mobile phones along with other wearable devices produce large numberofdataaspeoplearegoingabouttheirdailyactivities.Inthis study,wepresentedascenarioofemotiondetection“inthewild”,where peoplearemovingfromoneplacetoanotherinanurbanenvironment. Althoughthistypeoftimeseriesdatacanhelpusunderstandpeoples emotion,traditionalemotionrecognitiontechniquesrequiresfeatures engineering processtobe applied todata priortomodelling, which mightbechallengingespeciallyifthedatasetismultimodalandlarge. Deeplearningoffersanautomatedwayforfeaturesextraction embed-dedintheprocess.Thispaperhasdemonstratedtheadvantagesof em-ployingahybriddeeplearningapproachforrawmultimodaldata mod-ellingbasedonsmartdevicesensorsinputcollectedincityspace.Our resultshaveshownthatusingahybriddeeplearningapproach (CNN-LSTM)onlargenumberofrawsensordataincreasedtheaccuracy lev-els of emotionmodelsby morethan20% comparedtoa traditional MLPmodel.Furthermore,fusingvarioussensormodalitiesincluding on-Body,EnvironmentandLocationdatashowedasignificantincreasein accuracywhencomparedtomodellingsinglemodalitysuchas physio-logicalsensorsonly.Also,wehaveshownthatdeeplearningcanbea promisingapproachforthestudyofhumanbehaviourandemotiondata. Thepromisingresultsdemonstratedinthestudyholdsthepotentialfor novelapplicationsinemotionrecognitionandcanopennew opportu-nityinthestudyofmentalhealthandwell-beinginreal-lifesettings. Infuturework,wewillfurtherexplorethepossibilityofutilisingLSTM gatestoresetandforgetsomeofthestatesbasedontheemotionstates andtheirhistory.Finally,weareplanningtorunalargerscalestudies withothermodalitiesandsensorfeedsuchas(e.g.EEGdata,air qual-ity),andthenbuildanemotionmapusingourmodelonmobiledevices alongwiththesensors.
Supplementarymaterial
Supplementarymaterialassociatedwiththisarticlecanbefound,in theonlineversion,atdoi:10.1016/j.inffus.2018.09.001.
References
[1] G. Plasqui , K.R. Westerterp , Physical activity assessment with accelerometers: an evaluation against doubly labeled water, Obesity 15 (10) (2007) 2371–2379 . [2] O.D. Lara , M.A. Labrador , A survey on human activity recognition using wearable
sensors., IEEE Commun. Surv. Tutor. 15 (3) (2013) 1192–1209 .
[3] E.B. McClure , K. Pope , A.J. Hoberman , D.S. Pine , E. Leibenluft , Facial expression recognition in adolescents with mood and anxiety disorders, Am. J. Psychiatry 160 (6) (2003) 1172–1174 .
[4] T. Pham, T. Tran, D. Phung, S. Venkatesh, Deepcare: A deep dynamic memory model for predictive medicine, in: Proceedings of the Pacific-Asia Conference on Knowledge Discovery and Data Mining, Springer, 2016, pp. 30–41.
[5] R. Cowie , E. Douglas-Cowie , N. Tsapatsoulis , G. Votsis , S. Kollias , W. Fellenz , J.G. Taylor , Emotion recognition in human-computer interaction, IEEE Signal Pro- cess. Mag. 18 (1) (2001) 32–80 .
[6] E. Kanjo , E.M. Younis , N. Sherkat , Towards unravelling the relationship between on-body, environmental and emotion data using sensor information fusion approach, Inf. Fusion 40 (2018) 18–31 .
[7] E. Kanjo, D.J. Kuss, C.S. Ang, NotiMind: utilizing responses to smart phone notifica- tions as affective sensors, IEEE Access (2017), doi: 10.1109/ACCESS.2017.2755661 . [8] S. Jerritta, M. Murugappan, R. Nagarajan, K. Wan, Physiological signals based hu- man emotion recognition: a review, in: Proceedings of the IEEE Seventh Interna- tional Colloquium on Signal Processing and its Applications (CSPA), IEEE, 2011, pp. 410–415.
[9] C. Busso , Z. Deng , S. Yildirim , M. Bulut , C.M. Lee , A. Kazemzadeh , S. Lee , U. Neu- mann , S. Narayanan , Analysis of emotion recognition using facial expressions, speech and multimodal information, in: Proceedings of the Sixth International Con- ference on Multimodal Interfaces, ACM, 2004, pp. 205–211 .
[10] E. Kanjo , A. Chamberlain , Emotions in context: examining pervasive affective sens- ing systems, applications, and analyses, Pers. Ubiquitous Comput. (2015) 1–16 . [11] R.W. Picard , Affective computing: challenges, Int. J. Hum. Comput. Stud. 59 (1)
(2003) 55–64 .
[12] F. Agrafioti , D. Hatzinakos , A.K. Anderson , Ecg pattern analysis for emotion detec- tion, IEEE Trans. Affect. Comput. 3 (1) (2012) 102–115 .
[13] G.E. Hinton , S. Osindero , Y.-W. Teh , A fast learning algorithm for deep belief nets, Neural Comput. 18 (7) (2006) 1527–1554 .
[14] K. Simonyan, A. Zisserman, Very deep convolutional networks for large-scale image recognition, arXiv: 1409.1556 (2014).
[15] A. Graves , A.-r. Mohamed , G. Hinton , Speech recognition with deep recurrent neural networks, in: Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), IEEE, 2013, pp. 6645–6649 .
[16] A. Supratak , C. Wu , H. Dong , K. Sun , Y. Guo , Survey on feature extraction and appli- cations of biosignals, in: Machine Learning for Health Informatics, Springer, 2016, pp. 161–182 .
[17] M.A. Alsheikh , A. Selim , D. Niyato , L. Doyle , S. Lin , H.-P. Tan , Deep activity recog- nition models with triaxial accelerometers., in: Proceedings of the AAAI Workshop: Artificial Intelligence Applied to Assistive Technologies and Smart Environments, 2016 .
[18] C.A. Ronao , S.-B. Cho , Human activity recognition with smartphone sensors using deep learning neural networks, Expert Syst. Appl. 59 (2016) 235–244 .
[19] N.Y. Hammerla, S. Halloran, T. Ploetz, Deep, convolutional, and recurrent models for human activity recognition using wearables, arXiv: 1604.08880 (2016). [20] X. Zhou, J. Guo, R. Bie, Deep learning based affective model for speech emotion
recognition, in: Proceedings of the International IEEE Conferences on Ubiquitous Intelligence & Computing, Advanced and Trusted Computing, Scalable Computing and Communications, Cloud and Big Data Computing, Internet of People, and Smart World Congress (UIC/ATC/ScalCom/CBDCom/IoP/SmartWorld), IEEE, 2016, pp. 841–846.
[21] F.J. Ordóñez , D. Roggen , Deep convolutional and LSTM recurrent neural networks for multimodal wearable activity recognition, Sensors 16 (1) (2016) 115 . [22] N. Alajmi, E. Kanjo, N. El Mawass, A. Chamberlain, Shopmobia: an emotion-based
shop rating system, in: Proceedings of the Conference on Affective Computing and Intelligent Interaction, 2013, pp. 745–750, doi: 10.1109/ACII.2013.138 . [23] L. Al-barrak , E. Kanjo , E.M.G. Younis , Neuroplace: categorizing urban places accord-
ing to mental states, 2017, PLoS One 12 (2017) .
[24] W. Kieran , K. Eiman , Things of the internet (ToI): physicalization of notification, in: Proceedings of the ACM International Joint Conference on Pervasive and Ubiquitous Computing: Adjunct, ACM, 2018 .
[25] W. Kieran , K. Eiman , Emoecho: a tangible interface to convey and communicate emotions, in: Proceedings of the ACM International Joint Conference on Pervasive and Ubiquitous Computing: Adjunct, ACM, 2018 .
[26] M. Dumas , Emotional expression recognition using support vector machines, in: Pro- ceedings of International Conference on Multimodal Interfaces, 2001 .
[27] C.-C. Lee , E. Mower , C. Busso , S. Lee , S. Narayanan , Emotion recognition using a hier- archical binary decision tree approach, Speech Commun. 53 (9) (2011) 1162–1171 .
[28] J. Bins , B.A. Draper , Feature selection from huge feature sets, in: Proceedings of the Eighth IEEE International Conference on Computer Vision, ICCV, 2, IEEE, 2001, pp. 159–165 .
[29] Y. Bengio , P. Lamblin , D. Popovici , H. Larochelle , Greedy layer-wise training of deep networks, in: Proceedings of the Advances in Neural Information Processing Systems, 2007, pp. 153–160 .
[30] A. Krizhevsky , I. Sutskever , G.E. Hinton , Imagenet classification with deep convo- lutional neural networks, in: Proceedings of the Advances in Neural Information Processing Systems, 2012, pp. 1097–1105 .
[31] G. Dahl , A.-r. Mohamed , G.E. Hinton , et al. , Phone recognition with the mean-co- variance restricted Boltzmann machine, in: Proceedings of the Advances in Neural Information Processing Systems, 2010, pp. 469–477 .
[32] G.E. Dahl , D. Yu , L. Deng , A. Acero , Context-dependent pre-trained deep neural networks for large-vocabulary speech recognition, IEEE Trans. Audio Speech Lang. Process. 20 (1) (2012) 30–42 .
[33] R. Socher , E.H. Huang , J. Pennin , C.D. Manning , A.Y. Ng , Dynamic pooling and unfolding recursive autoencoders for paraphrase detection, in: Proceedings of the Advances in Neural Information Processing Systems, 2011, pp. 801–809 . [34] A. Bordes , X. Glorot , J. Weston , Y. Bengio , Joint learning of words and meaning
representations for open-text semantic parsing, in: Proceedings of the Artificial In- telligence and Statistics, 2012, pp. 127–135 .
[35] M. Zeng , L.T. Nguyen , B. Yu , O.J. Mengshoel , J. Zhu , P. Wu , J. Zhang , Convolutional neural networks for human activity recognition using mobile sensors, in: Proceed- ings of the Sixth International Conference on Mobile Computing, Applications and Services (MobiCASE), IEEE, 2014, pp. 197–205 .
[36] C.A. Ronao , S.-B. Cho , Deep convolutional neural networks for human activity recog- nition with smartphone sensors, in: Proceedings of the International Conference on Neural Information Processing, Springer, 2015, pp. 46–53 .
[37] J. Yang , M.N. Nguyen , P.P. San , X. Li , S. Krishnaswamy , Deep convolutional neural networks on multichannel time series for human activity recognition., in: Proceed- ings of the IJCAI, 2015, pp. 3995–4001 .
[38] M. Gadaleta, M. Rossi, IDnet: smartphone-based gait recognition with convolutional neural networks, arXiv: 1606.03238 (2016).
[39] N.M. Rad, A. Bizzego, S.M. Kia, G. Jurman, P. Venuti, C. Furlanello, Convo- lutional neural network for stereotypical motor movement detection in autism, arXiv: 1511.01865 (2015).
[40] F. Yan , K. Mikolajczyk , Deep correlation for matching images and text, in: Proceed- ings of the IEEE Conference on Computer Vision and Pattern Recognition, 2015, pp. 3441–3450 .
[41] N. Neverova , C. Wolf , G. Lacey , L. Fridman , D. Chandra , B. Barbello , G. Taylor , Learning human identity from motion patterns, IEEE Access 4 (2016) 1810–1820 . [42] M. Längkvist , L. Karlsson , A. Loutfi, A review of unsupervised feature learning and
deep learning for time-series modeling, Pattern Recognit. Lett. 42 (2014) 11–24 . [43] R. Jozefowicz , W. Zaremba , I. Sutskever , An empirical exploration of recurrent net-
work architectures, in: Proceedings of the Thirty-Second International Conference on Machine Learning (ICML-15), 2015, pp. 2342–2350 .
[44] K. Greff, R.K. Srivastava , J. Koutnk , B.R. Steunebrink , J. Schmidhuber , LSTM: a search space odyssey, IEEE Trans. Neural Netw. Learn. Syst. 28 (10) (2017) 2222–2232 .
[45] Microsoft Wrist Band kernel description, ( https://www.microsoft.com/microsoft- band/en-gb ).Accessed: 2017-09-04.
[46] E. Banzhaf, F. de la Barrera, A. Kindler, S. Reyes-Paecke, U. Schlink, J. Welz, S. Kabisch, A conceptual framework for integrated analysis of en- vironmental quality and quality of life, Ecol. Indic. 45 (2014) 664–668. https://doi.org/10.1016/j.ecolind.2014.06.002 .
[47] Abadi, Others, {TensorFlow}: large-scale machine learning on heterogeneous sys- tems, arXiv: 1603.04467 (2015).
[48] Intel Edison kernel description, ( https://software.intel.com/en-us/iot/hardware/ edison ).Accessed: 2017-09-04.
[49] Y. Gao , H.J. Lee , R.M. Mehmood , Deep learninig of eeg signals for emotion recog- nition, in: Proceedings of the IEEE International Conference on Multimedia & Expo Workshops (ICMEW), IEEE, 2015, pp. 1–5 .
![Fig. 1. Long short term memory (LSTM) block [44] .](https://thumb-us.123doks.com/thumbv2/123dok_us/525097.2561818/5.892.462.832.86.459/fig-long-short-term-memory-lstm-block.webp)

![Fig. 11. Accuracy and F-Measure levels of the base learners and the stacking learner [6] .](https://thumb-us.123doks.com/thumbv2/123dok_us/525097.2561818/11.892.188.712.81.299/fig-accuracy-measure-levels-base-learners-stacking-learner.webp)