BLOCK JACOBI-TYPE METHODS FOR LOG-LIKELIHOOD BASED
LINEAR INDEPENDENT SUBSPACE ANALYSIS
Hao Shen, Knut H¨uper
∗National ICT Australia, Australia,
and
The Australian National University, Australia
Martin Kleinsteuber
†Department of Mathematics,
University of W¨urzburg, Germany
ABSTRACT
Independent Subspace Analysis (ISA) is a natural generali-sation of Independent Component Analysis (ICA) incorpo-rated with invariant feature subspaces, where mutual statis-tical independence exists between subspaces, while mutual statistical dependence is still allowed between components within the same subspace. In this paper, we develop a gen-eral scheme of block Jacobi-type ISA methods which opti-mise a popular family of log-likelihood based ISA contrast functions. It turns out that block Jacobi-type ISA method is an efficient tool for both parametric and nonparametric approaches. Rigorous analysis regarding the local conver-gence properties is provided in a general sense. A concrete realisation of the block Jacobi-type ISA method, employ-ing a Newton step strategy, is proposed and demonstrates its local quadratic convergence properties to a correct sub-space separation. Performance of the proposed algorithms is investigated by numerical experiments.
1. INTRODUCTION
As a generalisation of the standard blind source separation (BSS), the so-called multidimensional blind source separa-tion (MBSS) studies the problem of extracting sources in terms of groups other than individual signals. Since the success of using Independent Component Analysis (ICA) to solve BSS, meanwhile, an analogous statistical tool to ICA has been proposed for solving MBSS as Multidimensional Independent Component Analysis (MICA) [1], which as-sumes that components from different groups are mutually statistically independent, while mutual statistical dependen-ce is still allowed between components in the same sub-space. Incorporated with invariant feature spaces, MICA is also referred to as Independent Subspace Analysis (ISA) ∗National ICT Australia is funded by the Australian Government’s Department of Communications, Information Technology and the Arts and the Australian Research Council throughBacking Australia’s Abil-ity and the ICT Research Centre of Excellence programs. Emails: [email protected], [email protected]
†Email: [email protected]
[2]. In this work, we study the problem of linear ISA from an optimisation point of view.
According to the pioneering work [1], it shows that, in general, any standard ICA algorithm can be adapted to solve MICA in two steps: (i) to utilise a standard ICA method to estimate all individual signals; (ii) to construct mutually statistically independent subspaces by grouping dependent signals together. The Jacobi-type method is an important tool for solving the standard linear ICA problem. It jointly diagonalises a given set of commuting symmetric matrices, which are constructed in accordance with certain ICA mod-els, such as JADE or MaxKurt, [3]. Apart from a full joint diagonalisation of a set of symmetric matrices, it has been shown that the problem of MICA can be solved by a joint
blockdiagonalisation with respect to a fixed block structure [4]. Recently, a class of MICA methods based on joint block diagonalisation has been developed in [4, 5] by performing a standard Jacobi-type method as in [6] followed by cer-tain permutations on the columns of the demixing matrix, to obtain block diagonalisation of a set of symmetric ma-trices. Although the efficiency of this approaches has been verified by numerical evidence, to our best knowledge, up to now there was no theory developed yet to guarantee that the efficiency and convergence properties of standard ICA algorithms hold for their MICA/ISA counterparts, as well.
It is well known that the Jacobi-type method is essen-tially an optimisation procedure. Instead of optimising over a single parameter at one time, the standard Jacobi-type method has been generalised to the so-called block Jacobi-type method [7], which optimises over several parameters simultaneously. It has also been shown that a convenient setting for doing linear ISA is indeed a flag manifold [8]. In this paper, we develop a general scheme of block Jacobi-type ISA methods on flag manifolds, in order to optimise a popular family of log-likelihood based ISA contrast func-tions.
The paper is organised as follows. Section 2 briefly introduces the linear ISA model with log-likelihood based ISA contrast functions and a block Jacobi-type method on a flag manifold. In Section 3, we give a critical point analysis of the log-likelihood based ISA contrast function followed
by a study of the Hessian, and propose a general scheme of block Jacobi-type ISA methods. Local convergence results of the proposed methods are presented without proof. By using a Newton step strategy, a concrete block Jacobi-type ISA method is formulated. It shares the same local conver-gence properties with the general cases. Analogous results on a similar nonparametric ISA approach, which is based on kernel density estimation, are also discussed. Finally, numerical experiments in Section 4 investigate the perfor-mance of the proposed algorithms.
2. PRELIMINARIES: LINEAR ISA MODEL AND BLOCK JACOBI-TYPE METHODS 2.1. Linear ISA Model and linear ISA Contrast
In this work, we study the standard noiseless linear instan-taneous ISA model as follows, refer to [2] for more details. Let
Z =AS, (1)
whereS = [s1, . . . , sn] ∈ Rm×n representsnsamples of
msources withm n, which consist of pmutually sta-tistically independent groups with the dimension of each subspace beingdi, fori = 1, . . . , p, and Pp
i=1di = m.
The matrixA∈Rm×mis the full rank mixing matrix, and
Z = [z1, . . . , zn] ∈ Rm×n represents the observed
mix-tures. It is important to notice that the mutual statistical independence is ensured only if the sample sizentends to infinity. Nevertheless, for our theoretical analysis in Sec-tion 3, we assume that the independence holds even if the sample size is finite.
The task of the linear ISA model is to recover the source signalsSin mutually statistically independent groups based only on the observationsZvia a linear transformation
Q=B>Z, (2)
whereB ∈ Rm×mis the full rank demixing matrix, and
Q∈Rm×nrepresentspindependent groups ofddependent
signals. LetB = [b1, . . . , bp] ∈Rm×mwithbi ∈ Rm×di andrkbi = di fori = 1, . . . , p. IfB∗ = [b∗1, . . . , b∗p] ∈
Rm×m is a correct demixing matrix and everyb∗i extracts
a statistically independent group of di dependent signals,
thenB withspanbi = spanb∗i, for alli = 1, . . . , p,
pro-vides a correct separation of independent groups as well. Let us define ri := Pi
j=1dj for all i = 1, . . . , p. It is
clear that 0 < r1 < . . . < rp = m is an increasing
sequence of integers. The solution set of the linear ISA problem can then be identified as the collection of ordered sets ofpvector subspacesVi ofRmwithdimVi = ri for
i= 1, . . . pandV1 ⊂. . . ⊂Vp =Rm, i.e., the flag
mani-foldF l(r1, . . . , rp). In this work, we only study the
sit-uation where all independent subspaces have the same di-mensiond. For the sake of simplicity, in the following, we
useF l(p, d)to denote the flag manifoldF l(r1, . . . , rp)with
ri=i·dfor alli= 1, . . . , p.
Similar to performing linear ICA, the so-called whiten-ing process of the mixtures can be applied to simplify the demixing ISA model (2) as follows
Y =X>W, (3)
whereW = [w1, . . . , wn] =V Z ∈Rm×nis the whitened
observation (V ∈ Rm×m is the whitening matrix),X ∈ Rm×mis an orthogonal matrix being the demixing matrix,
andY = [y1, . . . , yn]∈Rm×ncontains the reconstructedp
independent groups of signals.
Let us denote the special orthogonal group of orderm
bySO(m) :=X∈Rm×m|X>X=I,det(X) = 1 . Let
X= [x1, . . . , xp]∈SO(m)withxi∈Rm×d, i.e.,x>i xi= I. We define an equivalence relation∼onSO(m)by the following: for anyX,X¯ ∈ SO(m),X ∼ X¯ if and only ifspanxi = span ¯xi, for alli = 1, . . . , p. We denote the
equivalence class containingX ∈SO(m)under∼bybXc. Obviously, every equivalence classbXc, forX ∈ SO(m), identifies exactly one point inF l(p, d)andXis a represen-tative ofbXc ∈F l(p, d).
The key idea of linear ISA is to maximise the mutual sta-tistical independence between the norms of the projections of observations on a set of linear subspaces. Minimisation of the negtive log-likelihood between recovered signals is a widely used independence criterion in standard ICA. We adapt the same criterion to the linear ISA case as follows
F:F l(p, d)→R, F(bXc) := p X k=1 Ei h −logψw>ixkx>kwi 2 i , (4)
whereψ(·)is the differential probability density function (PDF) of the norm of the projection of the observations on a certain linear subspace andEi[·] is the empirical mean
over indexi. It is easily seen that the ISA contrast function (4) is independent of concrete representatives of an equiva-lence classbXc. The PDFψis usually chosen hypothetically based on applications. For the sake of simplicity, we use
G(a) :=−logψ(a). It can just be considered as a special parametric approach.
2.2. Block Jacobi-type Methods on Flag Manifolds
Block Jacobi-type procedures were developed as a general-isation of standard Jacobi method in terms of grouped vari-ables for solving symmetric eigenvalue problems or singu-lar value problems [9]. Recent work in [7] formulates the so-called block Jacobi-type method as an optimisation ap-proach on manifolds. We now adapt the general formulation as in [7] to the present setting, the flag manifoldF l(p, d).
Denote the vector space of allm×mskew-symmetric matrices by so(m) := {Ω ∈ Rm×m| Ω = −Ω>}. Let
m=p·d. We fix a subspaceB(p, d)⊂so(m)with fixed block structure as follows. AnyΩ∈ B(p, d)consists ofp2
blocks of dimensiond×d. The(d×d)-diagonal blocks
ωllofΩ = (ωkl) p
k,l=1 ∈ B(p, d)are all equal to zero. For
example, forp= 3,Ω∈ B(3, d)looks as Ω = 03×3 ω12 ω13 −ω> 12 03×3 ω23 −ω> 13−ω23> 03×3 , (5)
whereωkl = −ω>lk ∈ R3×3. By means of the matrix
ex-ponential map, a local parameterisation µbXc of F l(p, d)
aroundbXcis defined as
µbXc:B(p, d)→F l(p, d), µbXc(Ω) :=bXeΩc. (6)
The tangent space ofF l(p, d)atbXcis then
TbXcF l(p, d) =ddt µbXc(t· B(p, d))
t=0. (7)
Now let us decomposeB(p, d)as follows
B(p, d) = M
1≤k<l≤p
Bkl(p, d), (8)
where all blocks ofΩ∈ Bkl(p, d)∼=Rd×dare equal to zero
except for thekl-th andlk-th block. We then define
VbklXc:= ddtµbXc(t· Bkl(p, d))
t=0. (9)
It is clear that(Vkl
bXc)1≤k<l≤pgives a direct sum
decompo-sition of the tangent spaceTbXcF l(p, d)as well, i.e., TbXcF l(p, d) =
M
1≤k<l≤p
VbXklc. (10) The smooth maps
τkl:Bkl(p, d)×F l(p, d)→F l(p, d), τkl(Ω,bXc) :=µbXc(Ω),
(11) for all1≤k < l≤p, are referred to as thebasic transfor-mations.
Let f: F l(p, d) → Rbe a smooth cost function. A
block Jacobi-type method for minimising f can be sum-marised as follows
Algorithm 1Block Jacobi-type method onF l(p, d) Step 1: Given an initial guessbXc ∈F l(p, d)and a set
of basic transformationsτkl, for all1 ≤ k < l≤p, as defined in (11).
Step 2: (Sweep) LetbXoldc=bXc. For1≤k < l≤p
(i) Compute Ω∗:= arg min
Ω∈Bkl(p,d)
(f ◦τkl)(Ω,bXc),
(ii) UpdatebXc ←τkl(Ω∗,bXc).
Step 3: Ifδ(bXoldc,bXc)is small enough, Stop.
Otherwise, goto Step 2.
Here δ(bXoldc,bXc) represents a certain distance measure
between two points on F l(p, d). Following the result of Theorem 2.4 in [7], we state the following theorem without proof.
Theorem 1 Letf: F l(p, d) → Rbe a smooth cost
func-tion andbX∗c ∈F l(p, d)be a local minimum off. If the HessianHf(bX∗c) is nondegenerated and the vector
sub-spacesVbXklc, for all1≤k < l ≤p, as in(10)are mutually orthonormal with respect to the HessianHf(bX∗c), then the
block Jacobi-type method converges locally quadratically fast.
3. BLOCK JACOBI-TYPE ISA METHODS 3.1. Analysis of Linear ISA Contrasts
In this section, we will first show that the log-likelihood based linear ISA contrast function as in (4) fulfills the con-ditions stated in Theorem 1, i.e., one can develop a scheme of block Jacobi-type methods, which minimise the nega-tive log-likelihood based ISA contrasts, with local quadratic convergence properties.
By the chain rule, the first derivative of the contrastFis calculated as d dt(F◦µbXc)(tΩ) t=0= p X 1≤k<l≤p trω>kl(ukl(X)−ulk(X)), (12)
whereukl(X), ulk(X)∈Rd×dwith
ukl(X) =Ei h G0(w > ixlx>lwi 2 )x > kwiw > ixl i , and ulk(X) =Ei h G0(w > ixkx>kwi 2 )x > kwiw > ixl i (13)
It can be shown that ifbX∗c ∈F l(p, d)is a correct demix-ing point, by the whitendemix-ing properties of the sources, the termukl(X∗)is equal to0for allk 6= l. Thus it follows that the first derivative ofF vanishes atbX∗c. Therefore a correct demixing pointbX∗cis indeed a critical point of
F. Note that there exist more critical points than the correct separation points.
By a straightforward computation, the second derivative ofF at a correct separation pointbX∗cis calculated as fol-lows d2 dt2(F◦µbX∗c)(tΩ) t=0 = p X 1≤k<l≤p trωkl>(vkk(X∗) +vll(X∗))ωkl (14)
where vkk(X) = 2Ei h G00(w > ixkx>kwi 2 )x > kwiw > ixk i −Ei h G0(w > ixkx>kwi 2 )x > kwiw > ixk i + 2Ei h G0(w > ixkx>kwi 2 ) i Id. (15)
It is clear that the Hessian ofFevaluated atbX∗cis indeed block diagonal with the size of each diagonal block being
d×d. Note that the properties in (15) hold true only if the statistical independence can be ensured for the sources.
3.2. A Block Jacobi-type ISA method
According to the results in Section 3.1, we now develop a scheme of block Jacobi-type linear ISA method. For any 1≤k < l≤p, we denote
µklbXc:= µbXc
Bkl(p,d). (16) Each partial step in a Jacobi-type sweep (Step 2 in Algo-rithm 1) requires to solve an unconstrained optimisation pro-blem as
F◦µklbXc:Bkl(p, d)∼=Rd×d→ R. (17)
As stated in Algorithm 1, one will need to solve the above subproblem for a global optimum. Unfortunately, it seems not feasible to do so in the current case (17). Nevertheless we can still make a theoretical conclusion as the following.
Corollary 2 LetbX∗c ∈ F l(p, d)be a correct separation point of a linear ISA problem. Then the block Jacobi-type linear ISA method in the fashion of Algorithm 1is locally quadratically convergent tobX∗c.
It is well known that the performance of block Jacobi-type methods critically depends on the methods to solve the subproblems. In the rest of this section, we formulate a Newton step based realisation of the block Jacobi-type linear ISA method, i.e., other than seeking for a local or global minimum of the restricted subproblem (17), we apply a single Newton optimisation step on each basic transforma-tion. Similar techniques have already been used in [10, 11]. The resulting algorithm preserves the local quadratic con-vergence properties as Algorithm 1 does.
The first and second derivatives ofF◦µklbXcare computed as follows d dt(F◦µ kl bXc)(tΩ) t=0= trω > kl(ukl(X)−ulk(X)), d2 dt2(F◦µ kl bXc)(tΩ) t=0= trω > kl(h (X) kl(Ω)+h (X) lk(Ω)), (18) whereΩ∈ Bkl(p, d)and h(Xkl)(Ω) =Ei h G00(w > ixkx>kwi 2 )(x > kwiw > ixl)(w > ixkωklx > lwi) i −Ei h G0(w > ixkx>kwi 2 )(x > kwiw > ixkωkl) i +Ei h G0(w > ixkx>kwi 2 )(ωklx > lwiw > ixl) i . (19)
Thus, a single Newton step is computed by solving the fol-lowing linear system forΩ∈ Bkl(p, d)
h(klX)(Ω) +h(lkX)(Ω) =ukl(X)−ulk(X). (20) By recursively iterating the above Newton step approach on each basic transformation, it completes the corresponding Newton step based block Jacobi-type ISA method. The lo-cal convergence properties of the Newton step based block Jacobi-type ISA method is stated as follows. Due to the page limits, we omit the proof.
Proposition 3 LetbX∗c ∈F l(p, d)be a correct separation point of a linear ISA problem. Then the block Jacobi-type linear ISA method employing a single Newton step as(20)
on each basic transformationτklfor all1 ≤k < l≤pis
locally quadratically convergent tobX∗c.
3.3. ISA Contrast Using Kernel Density Estimation
Similar to ICA, the true distribution of the norm of projected observations is generally unknown. By employing the ker-nel density estimation technique, a popular nonparametric approach, an empirical negative log-likelihood between the norms of projected components can be formulated as fol-lows, see [12] for more details,
e F:F l(p, d)→R, e F(bXc) := p X k=1 −Ei log 1 hEj φ w>ijxkx>kwij 2h2 , (21)
wherewij :=wi−wj ∈Rmrepresents the difference
be-tween thei-th andj-th sample,φ:R→Ris an appropriate
kernel function, e.g., the Gaussian kernelφ(a) = exp (−a), andh∈R+is the kernel bandwidth.
Following more tedious but analogous computations as for the general contrast function (4), it shows that (i) a cor-rect separation pointbX∗cis a critical point of Fe, (ii) the
Hessian ofFeatbX∗cis also block diagonal with respect to
the fixed block structured×d. It then follows directly that block Jacobi-type method is indeed an efficient tool for min-imising the empirical ISA contrast function (21). A Block Jacobi-type ISA method for optimising the contrast func-tion (21) can be formulated directly in the similar fashion as in Section 3.2. The convergence properties for general settings stated in Corollary 2 and Proposition 3 will still ap-ply to the empirical situation here. Due to the page limits,
all descriptions of the algorithm and proves of correspond-ing convergence results will be omitted here. For further details, we refer to our forthcoming journal paper.
4. NUMERICAL EXPERIMENTS
In this section, we propose two experiments to illustrate the properties of the proposed ISA methods. Section 4.1 demonstrates the local quadratic convergence properties of the Newton step based block Jacobi-type ISA method by an ideal example. In Section 4.2, the Newton step based em-pirical block Jacobi-type ISA method proposed in Section 3.3 is compared with an ICA based ISA approach in terms of separation quality.
4.1. Experiment 1
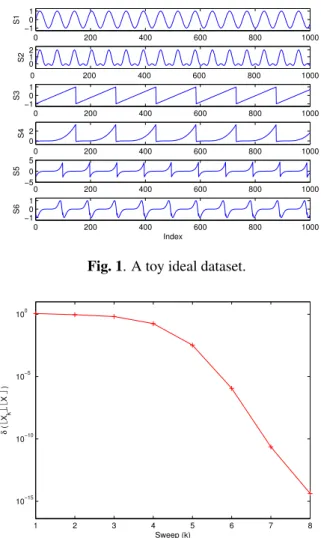
As pointed out before, in general, the statistical indepen-dence holds only if the sample size tends to infinity. It in-dicates that the theoretical results as shown in Corollary 2 and Proposition 3 could not generally be observed or veri-fied in real environment. Nevertheless, in this experiment, by constructing an ideal dataset where the statistical inde-pendence can be ensured, we will illustrate the theoretical convergence result of the Newton step based block Jacobi-type ISA method, i.e. the result in Proposition 3.
Let us first specify the ideal dataset, which consists of three statistically independent signal groups with two de-pendent signals per group, as shown in Fig. 1 and approxi-mate the PDF byψ(a) = cosh(a). The convergence proper-ties are measured by the distance of the accumulation point
bX∗cto the current iteratebXkc, which is defined as follows, forbXc,bX¯c ∈F l(p, d), δ(bXc,bX¯c) := p X i=1 kxix>i −x¯ix¯>i kF, (22)
wherek · kF is the Frobenius norm. The numerical results
in Fig. 2 evidently verify the local quadratic convergence properties of the Newton step based block Jacobi-type linear ISA method stated in Proposition 3.
4.2. Experiment 2
In this experiment, we investigate separation performance of the Newton step based empirical block Jacobi-type ISA method proposed in Section 3.3. It is compared with the popular approach of applying an ICA method followed by a regrouping process (referred to here as ICA-Group ISA). By fixing the dimension of each subspaced= 1, the block Jacobi-type ISA methods proposed in section 3 can be ada-pted easily to solve the standard linear ICA problem, i.e., a standard Jacobi-type ICA method. We refer to [13] for
0 200 400 600 800 1000 −10 1 S1 0 200 400 600 800 1000 0 1 2 S2 0 200 400 600 800 1000 −10 1 S3 0 200 400 600 800 1000 0 2 S4 0 200 400 600 800 1000 −5 0 5 S5 0 200 400 600 800 1000 −10 1 Index S6
Fig. 1. A toy ideal dataset.
1 2 3 4 5 6 7 8 10−15 10−10 10−5 100 Sweep (k) δ ( Xk , X * )
Fig. 2. Convergence properties of the Newton step based block Jacobi-type linear ISA method.
implementation details. For each test, both methods are ini-tialised by the same separation point which is close to an optimal solution.
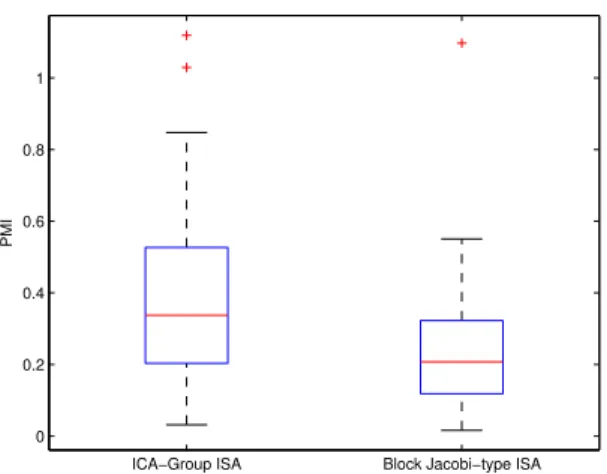
Our test data is generated as follows. Firstly we take three statistically independent signals randomly out of 200 sources, with a fixed sample size n = 2,000, from the benchmark speech dataset provided by the Brain Science In-stitute, RIKEN, see http://www.bsp.brain.riken.jp/data. By generating a distortion of each signal, we end up with test data having three statistically independent signal groups with two dependent signals per group. To measure the separation quality in ISA scenario, a so-calledmultidimensional per-formance index(MPI) has been proposed in [4] as a gener-alisation of the Amari error [14] by
d(C) := 1 p p X i=1 p P j=1 kcijk max j kcijk + p X j=1 p P i=1 kcijk max i kcijk −2, (23)
ICA−Group ISA Block Jacobi−type ISA 0 0.2 0.4 0.6 0.8 1 PMI
Fig. 3. Separation performance of the proposed method.
p·d. For a given separation pointbXc ∈F l(p, d), we define
C :=X>V A. Here the notationk · krepresents a certain matrix norm. As suggested in [4], for a givenc ∈ Rd×d,
kck gives the absolute value of the largest eigenvalue ofc. Generally, the smaller the index, the better the separation.
After a replication of 100 times of the test, we present the quartile based boxplots of the MPI score in Fig. 3. It shows that the Newton-step based empirical block Jacobi-type ISA method outperforms the ICA-Group approach in terms of separation quality consistently.
5. REFERENCES
[1] J.-F. Cardoso, “Multidimensional independent iompo-nent analysis,” inProceedings of the23rdIEEE Inter-national Conference on Acoustics, Speech, and Signal
Processing (ICASSP 1998), Seattle, WA, USA, 1998,
pp. 1941–1944.
[2] A. Hyv¨arinen and P. O. Hoyer, “Emergence of phase and shift invariant features by decomposition of natu-ral images into independent feature subspaces,” Neu-ral Computation, vol. 12, no. 7, pp. 1705–1720, 2000. [3] J.-F. Cardoso, “High-order contrasts for independent component analysis,” Neural Computation, vol. 11, no. 1, pp. 157–192, 1999.
[4] F. J. Theis, “Blind signal separation into groups of de-pendent signals using joint block diagonalization,” in
IEEE International Symposium on Circuits and
Sys-tems, 2005 (ISCAS 2005), Kobe, Japan, 2005, pp.
5878–5881.
[5] F. J. Theis, “Multidimensional independent compo-nent analysis using characteristic functions,” in Pro-ceedings of the13thEuropean Signal Processing Con-ference (EUSIPCO 2005), Antalya, Turkey, 2005.
[6] J.-F. Cardoso and A. Souloumiac, “Jacobi angles for simultaneous diagonalisation,” SIAM Journal of Ma-trix Analysis and Application, vol. 17, no. 1, pp. 161– 164, 1996.
[7] K. H¨uper,A Calculus Approach to Matrix Eigenvalue Algorithms, Habilitation Dissertation, Department of Mathematics, University of W¨urzburg, Germany, July 2002.
[8] Y. Nishimori, S. Akaho, and M. Plumbley, “Rie-mannian optimization method on the flag manifold for independent subspace analysis,” inLecture Notes
in Computer Science, Proceedings of the 6th
In-ternational Conference on Independent Component
Analysis and Blind Source Separation (ICA 2006),
Berlin/Heidelberg, 2006, vol. 3889, pp. 295–302, Springer-Verlag.
[9] G. Golub and C. F. van Loan, Matrix Computations, The Johns Hopkins University Press, Baltimore, 2nd edition, 1989.
[10] J. J. Modi and J. D. Pryce, “Efficient implementa-tion of Jacobi’s diagonalizaimplementa-tion method on the DAP,”
Numerische Mathematik, vol. 46, no. 3, pp. 443–454, 1985.
[11] J. G¨otze, S. Paul, and M. Sauer, “An efficient Jacobi-like algorithm for parallel eigenvalue computation,”
IEEE Transactions on Computers, vol. 42, no. 9, pp. 1058–1065, 1993.
[12] R. Boscolo, H. Pan, and V. P. Roychowdhury, “In-dependent component analysis based on nonparamet-ric density estimation,” IEEE Transactions on Neural Networks, vol. 15, no. 1, pp. 55–65, 2004.
[13] H. Shen, M. Kleinsteuber, and K. H¨uper, “Efficient ge-ometric methods for kernel density estimation based independent component analysis,” To appear at EU-SIPCO’07, Pozna´n, Poland, September 3-7, 2007. [14] S. Amari, A. Cichocki, and H. H. Yang, “A new
learn-ing algorithm for blind signal separation,” inAdvances in Neural Information Processing Systems, David S. Touretzky, Michael C. Mozer, and Michael E. Has-selmo, Eds. 1996, vol. 8, pp. 757–763, The MIT Press.