(will be inserted by the editor)
An SLA-based Broker for Cloud Infrastructures
Antonio Cuomo · Giuseppe Di Modica · Salvatore Distefano · Antonio Puliafito · Massimiliano Rak · Orazio Tomarchio · Salvatore Venticinque · Umberto Villano
Abstract The breakthrough of Cloud comes from its service oriented perspective where everything, including the infrastructure, is provided “as a service”. This model is really attractive and convenient for both providers and consumers, as a consequence the Cloud paradigm is quickly growing and widely spreading, also in non commercial contexts. In such a scenario, we propose to incorporate some elements of volunteer computing into the Cloud paradigm through the Cloud@Home solution, involving into the mix nodes and de-vices provided by potentially any owners or administrators, disclosing high computational resources to contributors and also allowing to maximize their utilization.
This paper presents and discusses the first step towards Cloud@Home: providing qual-ity of service and service level agreement facilities on top of unreliable, intermittent Cloud providers. Some of the main issues and challenges of Cloud@Home, such as the monitor-ing, management and brokering of resources according to service level requirements are addressed through the design of a framework core architecture. All the tasks committed to the architecture’s modules and components, as well as the most relevant component interac-tions, are identified and discussed from both the structural and the behavioural viewpoints. Some encouraging experiments on an early implementation prototype deployed in a real testing environment are also documented in the paper.
Keywords Cloud Computing, Cloud@Home, SLA, QoS, Resource Brokering.
Antonio Cuomo, Umberto Villano
Dipartimento di Ingegneria, Universit`a degli Studi del Sannio, Italy. E-mail: antonio.cuomo,[email protected]
Giuseppe Di Modica, Orazio Tomarchio
Dipartimento di Ingegneria Elettrica, Elettronica ed Informatica, Universit`a di Catania, Italy. E-mail: giuseppe.dimodica,[email protected]
Salvatore Distefano
Dipartimento di Elettronica e Informazione, Politecnico di Milano, Italy. E-mail: [email protected]
Antonio Puliafito
Dipartimento di Matematica, Universit`a di Messina, Italy. E-mail: [email protected]
Massimiliano Rak, Salvatore Venticinque
Dipartimento di Ingegneria dell’Informazione, Seconda Universit`a di Napoli, Italy. E-mail: massimiliano.rak,[email protected]
1 Introduction
Among the several definitions of “Cloud computing” available in literature, one of the most authoritative is that provided by NIST [32]: “Cloud computing is a model for enabling ubiq-uitous, convenient, on-demand network access to a shared pool of configurable computing resources (e.g., networks, servers, storage, applications, and services) that can be rapidly provisioned and released with minimal management effort or service provider interaction. This Cloud model promotesavailabilityand is composed of fiveessential characteristics, threeservice models, and fourdeployment models.” It is important to remark that such def-inition identifies the availability as a key concept of the Cloud paradigm. This concept has to be categorized into the broader class ofquality of service(QoS),service level agreement
(SLA) and related issues, topics of primary and strategic importance in Cloud.
In such context, the focus of this paper is on theInfrastructure as a Service(IaaS) pro-visioning model. IaaS Clouds are built up to provide infrastructures such as computing, storage and communication systems for free or by charge, with or without QoS/SLA guar-antees. There are multiple frameworks able to provide computing IaaS services: Eucalyptus [28], OpenNebula [20], Nimbus [29], PerfCloud [12], Clever [42], OpenStack [41] to name a few. All of them, as well as the existing proprietary solutions (i.e., Amazon EC2, Rackspace, etc.), aggregate and manage powerful and reliable underlying computing resources (usually single or multiple interconnected datacenters) to build up the Cloud IaaS infrastructure.
A different approach is instead proposed byCloud@Home, a project funded by Italian Ministry for Education and Research [15]. Cloud@Home (briefly,C@H) aims at building an IaaS Cloud Provider using computing, storage and sensing resources also acquired from volunteer contributors. The basic assumption on which C@H relies is that the resources offered on a volunteer basis are not reliable and can not provide levels of QoS comparable to those offered by commercial public Clouds.
We believe the C@Hvolunteerapproach can provide benefits in both business and open contexts. In business environments one of the main source of cost and complexity for com-panies is related to expanding, maintaining, tuning and optimizing the hardware resources in order to effectively satisfy the highly demanding, domain-specific software and to en-sure adequate productivity levels. The C@H technology will enable companies to organize their computing resources, which are sometimes distributed over several sites, in order to meet the demands of the mentioned software. Indeed, C@H allows a company to aggregate its sites into a federation, to which each site can contribute with its available and underex-ploited hardware resources to provide added value, guaranteed services. In open contexts a possible scenario that magnifies the C@H features and approach can be the academic one. Let us imagine that several universities or, in general, research institutions worldwide, need to collaborate on a scientific project that requires a huge amount of hardware resources. Moreover, let us assume that each institution owns a private datacenter, made up of het-erogeneous computing resources, each having a different level of utilization (depending on their geographic coordinates and time zones, some datacenters may result underexploited with respect to others). C@H will provide the institutions with tools to build up a federation of datacenters acting as aCloud broker, to which each partner can contribute with its own (i.e., not utilized or underexploited) resources according to its scheduled availability. Push-ing the approach to its limits, one can also imagine a scenario where private users aggregate into a federation and share their resources for each other’s needs.
In order to implement such ambitious idea, in the C@H project a three-phase roadmap was scheduled: i) development of quality of service (QoS) and service level agreement (SLA) brokering/federation mechanisms for private Cloud providers; ii) development of
billing and reward mechanism for merging both private and public Cloud; iii) development of tools for involving single-resource (desktop, laptop, cluster) volunteer contributors. The focus here is on the first step of the roadmap. The paper discusses the implementation of a framework for federating and brokering private Clouds, able to provideQoS guarantees on top of best effort providers.
The strength of the C@H proposal is that it offers a solution that is efficient from a cost perspective (when needed, resources can be “borrowed” from the system, thus avoiding to purchase them outside) and sufficiently reliable at the same time, as mechanisms for guar-anteeing QoS are also provided. If we take a look at the state of the art in this research field, the management of service quality of the leased resources is sometimes partially covered by commercial Clouds (availability, reliability and high level performance is natively sup-ported by very powerful and high-quality datacenters) and often neglected in actual Cloud frameworks.
The objectives of the C@H project and its rationale, limits and application contexts have been critically discussed in [5], which is a preliminary version of this work mainly focusing on concepts and ideas behind C@H. The present work tries to further develop and implement such ideas, more specifically by: i) identifying and characterizing the system actors; ii) detailing the architectural design and its modules and components; iii) providing details on the interactions among the components implementing the C@H functionalities; iv) reporting on the current prototype implementation and the testbed.
The remainder of the paper is organized as follows. A brief overview of the state of the art is first reported in Section 2. Then, Section 3 describes the C@H core architecture. Sections 4, 5, 6 and 7 delve into the details of the C@H architectural modules and compo-nents. Section 8 presents the system from a dynamic perspective, while Section 9 deals with a real testbed on which tests have been carried out. Conclusions and future developments are discussed in Section 10.
2 Related work
C@H aims at implementing a brokering-based Cloud Provider starting from resources shared by different providers, addressing QoS and SLA related issues, as well as resource manage-ment, federation and brokering problems. Since such issues and problems involve different topics, in the following we identified some of them providing an overview of the current state of the art.
Volunteer and Cloud Computing.The idea of volunteer Clouds recently emerges as one of the most interesting topic in Cloud computing. Some work is available in literature, also inspired by C@H that is one of the first attempt in such direction [16]. In [14] the au-thors present the idea of leveraging volunteer resources to build a form of dispersed Clouds, or “nebulas”, as they call them. Those nebulas are not intended to be general purpose, but to complement the offering of traditional homogeneous Clouds in some areas where a more flexible, less guaranteed approach can be beneficial, like in testing environments or in appli-cation where data are intrinsically dispersed and centralising them would be costly. Some re-quirements and possible solutions are presented. BoincVM [38] is an integrated Cloud com-puting platform that can be used to harness volunteer comcom-puting resources such as laptops, desktops and server farms, for computing CPU intensive scientific applications. It leverages on existing technologies (the BOINC platform and VirtualBox) along with some projects currently under development: VMWrapper, VMController and CernVM. Thus, it is a kind
of volunteer-on-Cloud approach, whereas C@H can be classified as a Cloud-on-volunteer model.
In [3] the authors investigate how a mixture of dedicated (and so highly available) and non-dedicated (and so highly volatile) hosts can be used to provision a processing tier of a large-scale Web service. They propose an operational model that guarantees long-term avail-ability despite of host churn, by ranking non-dedicated hosts according to their availavail-ability behavior. Through experimental simulation results they demonstrate that the technique is effective in finding a suitable balance between costs and service quality. Although the tech-nique is interesting and the results are encouraging, in the paper there is no evidence of either a possible implementation or an architecture design of the overall infrastructure framework that should implement the idea.
An approach that can be categorized into the volunteer Cloud is the P2P Cloud. It has been proposed in several papers as the ones cited above, and particularly in storage Cloud contexts. An interesting implementation of such idea is proposed in [22]. In particular, this work specifically focuses on the peer reliability, proposing a distributed mechanism in or-der to enable churn resistant reliable services that allows to reserve, to monitor and to use resources provided by the unreliable P2P system and maintains long-term resource reser-vations through controlled redundant resource provision. The evaluation results obtained through simulation show that using KAD measurements on the prediction of the lifetime of peers allows for 100% successful reservations under churn with very low traffic overhead. As in the above case, there is no real implementation of the proposed solution. Anyway, the monitoring and prediction tools developed can be of interest for C@H.
Federation, InterCloud and resource provisioning from multiple Clouds. Manage-ment of resources in Cloud is a complex topic. In [4, 37] examples of resource manageManage-ment techniques are discussed, while in [26] a policy-based technique facing the resource man-agement in Cloud environment is proposed. Even if Cloud computing is an emerging field, the need to move out from the limitations of provisioning from a single provider is gain-ing interest both in academic and commercial research. In [25], the authors move from a data center model (in which clusters of machines are dedicated to running Cloud infras-tructure software) to an ad-hoc model for building Clouds. The proposed architecture aims at providing management components to harvest resources from non-dedicated machines already in existence within an enterprise. The need for intermediary components (Cloud coordinators, brokers, exchange) is explained in [11], where the authors outline an archi-tecture for a federated network of Clouds (the InterCloud). The evaluation is conducted on a simulated environment modeled through the CloudSim framework, showing significant improvements in average turnaround time and make-span in some test scenarios. Federa-tion issues in Cloud environments have been considered, and some research projects fo-cuses on this specific topic actively investigate possible solutions, such as RESERVOIR [36] and more recently mOSAIC [31] and OPTIMIS [21]. With specific regards to [31, 21], the approach they propose is to implement a brokering system that acquires resources from different Cloud Providers and offers them in a custom way to their users. As regards the brokering solution for federation, C@H pioneeringly identified and proposed such modality since 2009 [16].
SLA Management in Clouds.In service oriented environments several proposals ad-dressing the negotiation of dynamic and flexible SLAs have appeared [19]. However, to the best of our knowledge, none of the main commercial IaaS providers (Amazon, Rackspace, GoGRID, ...) is offering negotiable SLA. What they usually propose is an SLA contract that specifies simple grants on uptime percentage or network availability. Moreover, most of the
providers offer additional services (for example Amazon CloudWatch) which monitor the state of target resources (i.e., cpu utilization and bandwidth).
Open Cloud Engine software like Eucalyptus, Nimbus, OpenNebula, also implement monitoring services for the private Cloud Provider, but do not provide solutions for SLA negotiation and enforcement. A survey of the SLAs offered by commercial Cloud Providers can be found in [44]. In [24] the authors describe a system able to combine SLA-based resource negotiations with virtualized resources, pointing out how in current literature there is no approach taking into account both these aspects. A global infrastructure aiming at offering SLA on any kind of Service Oriented Infrastructure (SOI) is the objective of the SLA@SOI project [39], which proposes a general architecture that can be integrated in many existing solutions. Anyway, this interesting solution is hard to be fully adopted in an infrastructure composed of unreliable resources such as the ones targeted by the C@H project. Recently, in the context of the mOSAIC project, some offerings exist in order to offer user-oriented SLA services to final users [35, 1].
A critical analysis. Due to the large number of computational resources often available in different environments, (like scientific labs, office terminals, academic clusters) there is a clear need of building solutions which are able to reuse such resources in a Cloud computing fashion. The above described state of art illustrates that a few attempts were done in order to apply volunteer computing approaches towards such direction. The main limit of such solution is related to different aspects: (1) definition of the real use cases where the volunteer computing approach can be applied, (2) integration with resources that come from commercial providers and (3) a clear evaluation of the quality of services obtained with such resources.
The first open issue needs a clear identification of the type of resources that can be shared with the volunteer approach and their possible usage. At the best of authors’ knowledge such analysis is not yet available, let alone [3], which is a work in progress paper which partly anticipates some of the ideas presented here.
The second problem, instead, is strictly related to what is calledCloud federation, i.e., the idea of integrating resources from different Cloud providers using different techniques (like brokering or Cloud bursting). As outlined above, there is a lot of interest towards feder-ation, but few results take into consideration the effect of integrating commercial-based and volunteer-based resources, and the different issues that arise in such a context. In any case, even though brokering solutions are now available, few of them are stable; furthermore the techniques to be adopted are open and the way in which the brokering functionalities should be offered is, at state of art, not clearly defined.
The third problem is a well-known one in literature: how to grant service level agree-ment over Cloud providers? Even if a lot of effort exists in such direction, no one has come out with a stable proposal. Commercial Cloud Providers use natural language to describe the functionalities, the terms of use and the service levels of their offers. Research projects (like SLA@SOI, Contrail, Optimis, above described) try to offer frameworks that can be integrated in Cloud Providers, but are usually heavy to maintain and hard to customize. The only available standard (WS-Agreement) has only one stable framework implementing its features (WSAG4J). Moreover all such proposals focus on integration of SLA management system from the Cloud Provider perspective. Implementing SLA mechanisms on top of fed-erated resources is still an open question. Existing solutions (i.e. SLA@SOI) focus on how to integrate SLA management framework in complex datacenters; the problem is translated into a resource optimization problem. Some results focus on how to optimize the resources at brokering level, i.e. after the resources are obtained and without control over the physical infrastructure. More recently solutions aiming at offering SLA functionalities on the top of
brokering systems have been proposed [10, 8, 33, 7]. To the best of the authors’ knowledge, none of them take into account volunteer and time-bounded availability scenarios.
3 System Overview
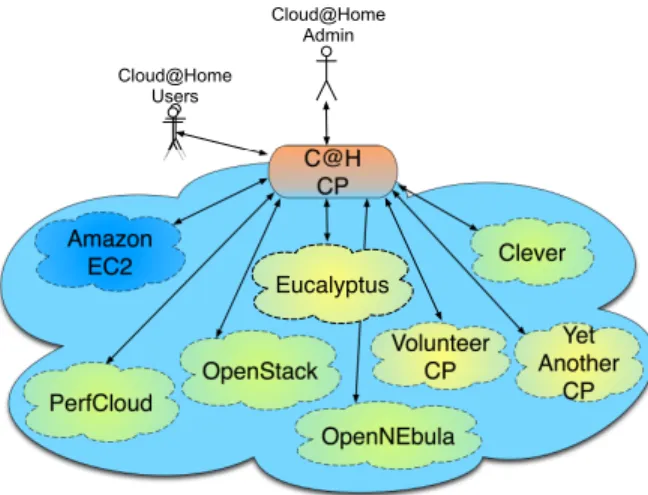
From a wider perspective, C@H aims at merging the Cloud and the Volunteer computing paradigms. C@H collects infrastructure resources from different providers and offers them to the end users through a uniform interface, in an IaaS fashion. As depicted in Fig. 1, C@H resources are gathered from heterogeneous providers, potentially ranging from commercial Cloud providers, offering highly reliable services, to single PCs, voluntarily shared by their owners, who, by their nature, are not able to provide guarantees on the QoS.
PerfCloud Clever OpenNEbula Yet Another CP C@H CP Cloud@Home Users Cloud@Home Admin OpenStack Amazon EC2 Volunteer CP Eucalyptus
Fig. 1: Resource aggregation from different Cloud providers.
The main goal of C@H is to provide a set of tools for building up a new, enhanced provider of resources (namely, aC@H provider) that is not yet another classic Cloud provider, but instead acts as an aggregator of resources offered by third party providers. A C@H provider collects heterogeneous resources from different Cloud providers adopting diverse resource management policies, and offers such resources to the users in a uniform way. This results in an added value infrastructure that also provides mechanisms and tools for imple-menting, managing and achieving QoS requirements defined through, and managed by, a specific SLA process.
Indeed, in order to deal with the heterogeneity and churn of resources, a C@H provider can use a set of tools and services dedicated to the SLA management, monitoring and en-forcement.
A goal of C@H is to release the above discussed tools to the Cloud community. Any interested organization may use such tools to build a C@H provider. Nothing prevents the instantiation of multiple C@H providers, each one collecting and aggregating resources by different resource providers. Furthermore, a resource provider is allowed to join any C@H system they wish. As explained in Section 5, the availability of resources for a given request
is assessed by the C@H provider at run-time, and the management of the resource status (free, busy, etc.) is up to the resource provider itself.
To implement the Cloud@Home wide and ambitious vision it was necessary to ade-quately design and organize the work into phases according to the project aims and goals. In this paper we focus on the first phase towards Cloud@Home, which aims at identifying, specifying and implementing the C@H building blocks and its core architecture restricting the scope to private Cloud providers.
3.1 Actors
On the backend side, the C@H provider interfaces with Cloud providers and performs the brokering of their services. It has to deal with the different levels of the service quality they are natively able to deliver. On the frontend side, the C@H provider has to allow the final users to access the resources in a uniform way, providing them with the required, sustainable QoS specified through the SLA process. In such a context, it is possible to identify three main actors involved in the C@H management process: Users, Admins and Resource Owners.
AC@H Userinteracts with the C@H provider in order to request resources along with the desired quality of service. The C@H Users are also provided with tools to negotiate the desired QoS and, at service provision time, to check that the promised QoS is actually being delivered.
AC@H Adminbuilds up and manages the C@H provider. The C@H Admin is the man-ager of the C@H infrastructure and, in particular, is in charge of the infrastructure activation, configuration and management. The C@H Admin decides which services provided by the infrastructure must be activated/deactivated. Furthermore, in case of QoS/SLA enabled in-frastructures and services, the C@H Admin specifies the policies that have to be adopted to carry out the SLA negotiation process and the QoS enforcement.
AResource Ownershares its resources with the C@H system. Besides private sharers, the category of Resource Owners also encompasses commercial offerers (e.g., mainstream IaaS Cloud providers). In other terms a Resource Owner is a potential Cloud provider for C@H, even if some Resource Owners are not able to provide any standalone Cloud service. The role of Resource Owners can be classified and specialized as public contributors (i.e., well known public Cloud automatically enrolled by the system) and volunteer contributors. Volunteer contributors are Resources Owners that voluntarily share their resources to build up a C@H provider. We can further categorize volunteer contributors as:
– Private Clouds: standalone administrative domains, which may have own QoS-SLA management and other resource facilities and services. They can be voluntarily involved in the C@H according to their administrators needs and wills thus becoming contribu-tors.
– Individuals:anyone who wants to voluntarily share their own desktop, laptop, cluster or generic resource/device with a C@H community.
In this paper we specifically focus on private Clouds, narrowing the issues and related solu-tions to such class of volunteer contributors. In other words, here we restrict the concept of volunteer to just private Cloud contributors.
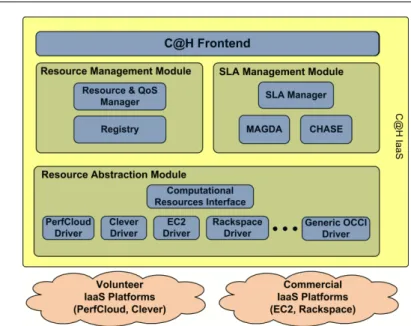
Fig. 2: The C@H system architecture.
3.2 A Modular Architecture
According to the scenario above discussed, in the following we identify the main blocks and modules of the C@H architecture, just considering private Clouds as Resource Owners. This includes the basic functionalities and mechanisms for implementing a C@H provider on top of private Cloud contributors. It can be also considered as the core architecture, the starting point to extend and generalize when public Clouds and/or individuals will be involved into C@H as Resource Owners.
The main goal of the architecture is to address some of the issues arised above. The ar-chitecture offers a set of components that can be easily used to build up its own Cloud Bro-kering solution. In Fig. 2 the C@H core architecture is depicted: it is organized into modules each composed of units providing specific functionalities, namedC@H components. C@H components are themselves delivered as resources hosted on Cloud providers. Following and applying the separation of concerns principle, four main modules have been logically identified, grouping the main C@H functionalities: the Resource Abstraction module, the SLA Management module, the Resource Management module and the Frontend module. As shown above, some of the main components are thought to deal with SLA issues.
The Resource Abstraction module hides the heterogeneity of resources (computing, storage and sensor elements) collected from Resource Owners and offers the C@H User a uniform way to access them. It provides a layer of abstraction adopting a standard, implementation-agnostic representation. It also implementsdriversin order to convert requests expressed in the intermediate representation to actual invocations on the interface of the Resource Owner. On top of the Resource Abstraction module C@H provides tools for the management of the SLAs that have to be negotiated with the C@H Users. The definition of formal guaran-tees on the performance that the resources must deliver is achieved through theSLA Man-agementmodule. C@H Users can negotiate the quality level of the requested resources. The negotiation process relies on performance prediction and on statistics of providers’ historical
availability in order to assess the sustainability of C@H Users’ requests. Statistics are built from information collected on the actual performance and QoS recorded for the supplied resources. A mobile agent-based monitoring service is responsible for gathering those data. The Resource Management module is the core of the system. It is in charge of the provision of resources and of the SLA enforcement. The most important functionalities provided by such module are related to the resource management. In particular this mod-ule is responsible for resource enrolment, discovery, allocation/re-allocation, activation/de-activation. These activities are carried out in accordance with the SLA goals and applying the procedures defined in the SLA modules.
Finally, theFrontend module acts as an interface to the C@H IaaS for both the C@H Admin and the C@H Users. It just collects C@H Admin and User requests and dispatches them to the appropriate system module.
In terms of implementation, C@H components are able to interact with each other through standardized, service-oriented interfaces. Such a choice enables flexible component deploying schemes. Pushing the virtualization paradigm to its limits, a single C@H Com-ponent can even be offered as a customized virtual machine hosted by any Cloud provider.
4 Resource Abstraction
C@H mainly acts as an intermediary, acquiring different types of infrastructural resources from different Resource Owners and delivering them to C@H Users. To cope with resources and providers heterogeneity, aresource abstraction’s scheme have been devised. The Re-source Abstraction module encompasses the components providing the abstraction and the necessary logic to map resources into real implementations.
Heterogeneous resources lack of uniformity in some specific characteristics, proper-ties and aspects, as they consist of dissimilar or diverse elements. Such differences can be broadly categorized according to three resource aspects:
Type - a possible classification could be based on the resource intended function (i.e., the resource type), distinguishing amongcomputing,sensor andstorage resources. Such specific aspect of resource heterogeneity has been investigated in [17]. In the present work, we specifically focus on computing resources, since we are mainly interested in describing the high level mechanisms and solutions to deal with QoS, SLA and resource management in C@H. However the proposed solutions do not depend on the type of resources and can be easily adapted to sensor and storage resources.
Hardware - resources can physically differ in their characteristics, ranging from the inter-nal architecture (CPU, symmetric multiprocessor, shared memory, etc.) to the devices (number of cores, controllers, buses, disks, network interfaces, memories, etc.) and so on. Hardware heterogeneity issues of computing resources can be mainly addressed by virtualization.
Software - software environments can differ on operating systems, compilers, libraries, pro-tocols, applications, etc. In Cloud context, as above, computing resource heterogeneity is overcome through virtualization.
To cope with this complexity, we decide to adopt an implementation-agnostic represen-tation and access interface for every class of resources, embracing current standardization efforts whenever possible.
Another issue to adequately take into account is the delivery of resources from providers, for which the specificacquisition modality must be defined and reflected in the interface.
Based on the abstractions discussed above, acomputing resource interfacehas been de-signed to enable access to the provisioned infrastructure. First of all, computing resources are defined in terms of basic blocks like Virtual Machines and Virtual Clusters. A reference standard has been chosen as the native interface to be supported for computing resources management: the OGFOpen Cloud Computing Interface(OCCI, [30]). As for the delivery of resources, currently C@H defines two acquisition modalities for computing resources:
Charged - resources obtained from public Cloud provider at a certain cost or fees and pro-viding guaranteed QoS levels;
Volunteer - resources obtained from Resource Owners that voluntarily support C@H. These might range from Cloud-enabled academic clusters, which deliver their resources for free (possibly subjected to internal administration policies and restrictions), to labora-tory providing single machines outside their working time, to single desktops willing to contribute to the infrastructure. Such resources are intermittent but, in case of private Cloud volunteer contributors the availability is slotted, i.e., the private Cloud provider defines a time window, an interval, or more specifically a series of intervals, in which and when it is available as C@H Resource Owner. Otherwise, in case of individuals, no guarantees are provided on the shared resources.
In this paper, restricting the scope to just private Cloud volunteer contributors, we assume resources are provided specifying the availability time windows.
Besides the just described computing resource interface, the Resources Abstraction module contains components to support the practical implementation of such interface. These are theProvider Drivers that implement tools for the acquisition of resources by enabling the interaction with the Resource Owners. They receive OCCI-compliant resource requests from other components, convert them into the target provider’s interface, perform the actual invocation to the Resource Owner and return the results that are again converted into OCCI. In this way, it is possible to interact with several open and commercial Cloud platforms too, like Amazon EC2 and Rackspace. An OCCI generic driver is provided too, so that Resource Owners whose infrastructure implements this interface are automatically able to interact with the higher level services by directly exchanging OCCI-compliant messages and requests.
In the current implementation, mainly focusing on private Cloud contributors, we have implemented drivers forPerfCloud[12] andClever[42] providers, two Cloud frameworks adopted in the context of the C@H project. PerfCloud is a solution for integrating Cloud and Grid paradigms, an open problem that is attracting growing research interest [27, 43]. The PerfCloud approach aims at building an IaaS (Infrastructure as a Service) Cloud en-vironment upon a Grid infrastructure, leasing virtual computing resources that usually (but not necessarily) are organized in virtual clusters. Clever builds a Cloud provider out of in-dependent hosts through a set of peer-to-peer based services. The choice of a decentralized P2P infrastructure allows the framework to provide fault-tolerance with respect to issues like host volatility.
In case a new Cloud framework wants to join C@H, it ought to provide an OCCI-compliant interface or implement a driver for its own infrastructure.
5 Resource management
From a high level point of view, a C@H provider is an intermediary (or broker) for the acquisition of resources from different Resource Owners. In this way, it delegates the
low-level management of the infrastructure to interface with such Resource Owners. Two important tasks of a C@H provider are therefore thesearchfor Resource Owners (providers) and theacquisitionof resources that eventually will be delivered to the final C@H Users. This section describes the C@H components implementing such tasks: the Registry and the Resource & QoS Manager.
5.1 Registry
The Registry component collects information on resource providers and on the way their offered resources can be assessed. It provides a simple interface through which resource providers can subscribe to C@H (i.e., decide to share their resources to C@H). At subscrip-tion time, resource providers must supply a Resource Provider Descriptor (RPD) file. As briefly shown in Listing 1, the file contains the following sections:
CloudEngine - identifies the Cloud solution adopted by the provider. This information is needed by the C@H to set up the correct drivers. As discussed in Section 4, drivers for PerfCloud and Clever have been fully developed. Other engines must to use the generic OCCI driver in order to interact with C@H.
WindowShare - contains the schedule of the time windows during which the resource provider is willing to share resources to the C@H. This information is used by the C@H when new user requests arrive, to filter out providers that are not willing to share their re-sources at the time requested by the C@H User.
Security - contains the subsection(s) dedicated to the kind of credentials accepted by the provider. In the example proposed, the provider adopts the PerfCloud engine, which makes use of GSI credentials from the Globus Security Infrastructure [40]. In this case, a subset of the information contained in the PKI certificate is reported. In order to gain access, the user needs the credentials for the target Virtual Organization.
AccessPoint - contains the information needed to access the target provider (IP address and qualified names, in the example).
Listing 1: Resource Provider Descriptor
[..] <Provider> <CloudEngine>PerfCloud</CloudEngine> <WindowShare> <Window> <Day>WorkingDay</Day> <From>6:00 PM CEST</From> <To>6:00 AM CEST</To> </Window> <Window> <Day>HolyDay</Day> <From>12:00 AM CEST</From> <To>12:00 PM CEST</To> </Window> </WindowShare> <Security> <GRIDAuthentication> <VirtualOrganization>Cloud@Home</VirtualOrganization> <Issuer>O=Grid, OU=GlobusTest, OU=simpleCA-CloudAtHome, CN
<Subject>O=Grid, OU=GlobusTest, OU=simpleCA-CloudAtHome, CN=Globus Simple CA</Subject>
</GRIDAuthentication> <Security> <AccessPoint> <IP>193.206.100.159</IP> <Name>Antares.ing.unina2.it</Name> <Name>Antares</Name> </AccessPoint> </Provider> [..]
At discovery time, i.e. when resources must be enrolled to satisfy a C@H User’s request, the Registry can be queried to retrieve the list of providers that are eligible to serve the request according to their WindowShare and Security settings.
5.2 Resource & QoS Manager
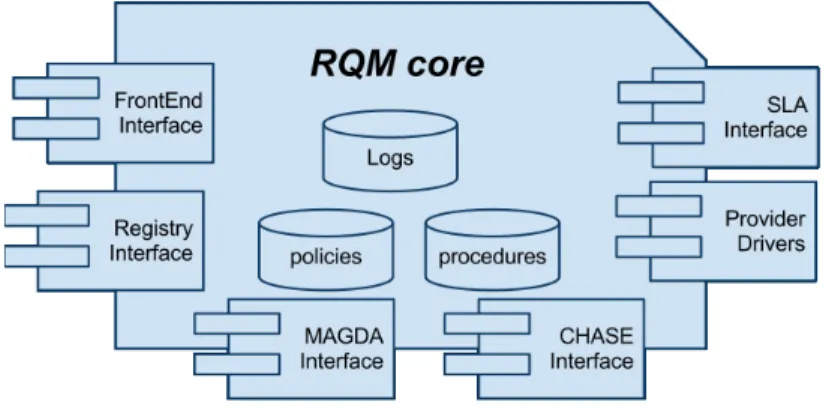
The Resource & QoS Manager (RQM) is a crucial component in the C@H architecture, as it is responsible of acquiring the virtual resources from the providers and ensuring that the negotiated QoS is being delivered. As shown in Fig. 3, the crosscutting tasks of the RQM require it to be able to interface with all other subsystems. To this end, the RQM has been designed as an asynchronous event-based system, denoted as RQMCore, which reacts to requests coming from other components.
Fig. 3: The Resource & Qos Manager
The RQM core tasks areRequest ManagementandSLA Enforcement. Request Manage-ment consists in the translation of C@H User requests into actual resource selection and allocation. Resource requests that do not involve SLA negotiations are directly forwarded to the RQM by the Frontend. SLA-based resource requests are handed to the RQM by the SLA Manager (described in subsection 6.1): the associated policies and procedures that must be used in SLA Enforcement are defined through the SLA Manager and stored in the RQM Core databases.
To fulfill these tasks, the RQM performs many activities. A workflow view of the activi-ties and the interactions they entail is described in section 8.2.2, while an overview from the RQM perspective is provided here. Activities related to Request Management include:
Provider Selection.The RQM can query the Registry to obtain the list of subscribed providers. The query can include filtering criteria on parameters specified in the Resource Provider Descriptor of Listing 1.
Resource acquisition.Once a suitable provider has been found, the Provider Drivers are set up to carry out resource acquisition.
Logging.The RQM logs all its operations and their status for further inspection and bookkeeping.
More complex activities involve cooperation between multiple modules and are oriented to the management of SLA-based requests and SLA Enforcement:
Availability guarantees.To provide availability guarantees, the RQM needs a forecast of the availability level of resources shared by a provider. The availability of a provider resource can be described with the well-known equation:
ProviderAvailability= MT BF
MT BF+MT T R. (1)
where MTBF is themean time between failuresand (MTTR) is themean time to re-pairof a single resource provided by the corresponding Cloud provider. To estimate the MTBF of a provider resource, the RQM firstly retrieves historical heartbeat provider data available from the monitoring subsystem, which is based on the Mobile Agents based GriD Architecture (MAGDA) described in the next section 6.3. The historical data can be used to obtain a forecast of the provider MTBF by invoking the forecast service provided by the Cloud@Home Autonomic Service Engine (CHASE), a component described in section 6.2. With regards to the MTTR, it can be defined as:
MT T R=Tf d+Tboot (2)
where
– Tf dis the time required to detect a resource failure. This is related to the rate with which the monitoring subsystem performs checks, which is bounded by the MAGDA timeout, a parameter that specifies how often MAGDA agents have to report on the resource status.
– Tbootis the time required for the system to boot up another virtual machine in substitution of the failed one. Such time depends on both the computing power of the virtual machine and on the complexity of the VM image. Again, the RQM can obtain a forecast for this value by feeding the forecast service in CHASE with historical boot time data (logs of virtual machines boot times) obtained from MAGDA.
Once the MTBF and the MTTR are evaluated, the RQM is able to compute the provider availability through Equation 1.
Alert reaction.The RQM uses alerts generated by the monitoring subsystem to activate the SLA Enforcement process. The policies to be activated are expressed through simple triples [<parameter>, <condition>, <procedure>], which formalize the procedures that have to be triggered when a given parameter satisfies a certain condition. The policies offered to the C@H administrator are represented in terms of a simple template, which en-ables the administrator to configure them: the responsibility of the correctness of the policies is up to the administrator. The current implementation uses a format akin to JSON.
Let us describe an example use of policies. Through the MAGDA monitoring compo-nent, the C@H system uses heartbeat messages to verify if a node is alive. It stores the heartbeat information using two variables:HBfail, representing the number of failures, andHBsuccess, representing the number of consecutive success heartbeats. We wish to specify a policy to use the heartbeat results to detect a machine crash and perform a restart. The policy states that if the number of failed heartbeats hits a certain thresholdX, the ma-chine must be restarted. However, random failed heartbeats may happen, for example for a very short network unavailability, that are not symptoms of a crashed machine. To avoid the accumulation of randomly failed heartbeats, we reset theHBfailcounter if there are at leastYconsecutive success heartbeats. The described policy can be specified as follows:
{Policy:
[[Heartbeat,HBfail>X,restart],
[Heartbeat,HBsuccess>Y,resetHBfail], [Heartbeat,HBsuccess>Y,resetHBsuccess]] }
whererestart,resetHBFailandresetHBsuccessare identifiers of proce-dures that respectively restart the virtual machine (the first) and reset the heartbeats counters (the other two). The procedure definitions are collected in a database local to the RQM.
When multiple policies are applicable to the current situation (i.e. all their conditions evaluate to true), all the policies are applied without any order. Again, the responsibility of verifying that this does not lead to the application of conflicting policies is up to the C@H administrator.
Performance guarantees.When the SLA involves application-level performance pa-rameters, the RQM can provide guarantees through predictions on the performance of a resource configuration, provided by the CHASE simulation-based performance prediction service. To enable the predictions, the RQM must provide CHASE with a description of the application (included in the user request), the user QoS requirements (part of the SLA) and benchmark data of the provider machines (obtained through the monitoring subsystem).
6 Service Level Agreement management
One of the most critical Cloud-related issues is the management of the Service Level Agree-ment. This is particularly true for C@H, since it tries to mix the Cloud and the volunteer paradigms. The volunteer contribution in C@H dramatically complicates the SLA man-agement task: the “volatility” of resources (resources providers can asynchronously join or leave the system without any message) has to be taken into account when enforcing QoS re-quirements. In C@H, the SLA Management module is in charge of the negotiation and the monitoring of SLAs, and collaborates with the RQM component for the enforcement of the QoS. The SLA Management module is composed of three components: theSLA Manager, theCloud@Home Autonomic Service Engine(CHASE) [34] and theMobile Agent Based Grid Architecture(MAGDA) [6]. The features of these components are briefly discussed in the following.
6.1 SLA Manager
The SLA Manager is in charge of managing the SLA templates to be offered to C@H Users. A C@H User can refer to these templates to start the negotiation procedure with the SLA
Manager, that will eventually produce an SLA. In this case, resources (which are the negoti-ation object of the SLA) are virtualized, and in general can be provided by several, different Cloud providers enforcing different management policies: SLAs are then crucial to guaran-tee the quality of virtualized resources and services in such heterogeneous environment.
We recall that the resource context we are addressing is heterogeneous, from different points of view. As discussed in Section 4, C@H aggregates resource providers that are by their nature heterogeneous: on the one hand the commercial providers, seeking to maximize the profit, and on the other one the volunteer providers, that just share their underutilized resources. Secondly, the provided resources themselves are heterogeneous in terms of com-putational power they are able to supply. The SLA management must take into account this heterogeneity, and enforce the appropriate strategy according to the nature of the providers and the resources being involved.
Stated thatresource availabilityis the only QoS parameter that C@H is currently ad-dressing, when commercial providers are involved in the provision of resources the C@H’s SLA strategy will guarantee no more than what the providers’ proprietary SLA are claiming to guarantee, and will apply the very same penalties for unattended QoS. When, instead, providers voluntarily share resources, the SLA produced for a specific provision aims at just forecasting the minimum service level (again, in terms of resource availability) that C@H will likely be able to sustain. The client of volunteered resources is aware that the resources are volatile, and that C@H strives to guarantee the provision; should the forecast service perform worse than the agreed minimum level, no penalty would be applied. For volunteer scenarios, we are planning to develop an incentive mechanism (supported by the SLA framework itself) that awards those providers that are able to guarantee at best the “promised” QoS. The basic principle is that the better the SLA is honoured, the more credits the provider gains. Credits can then be used by providers to “acquire” new resources within the federation.
The SLA Manager adopts the WS-Agreement protocol [2] for the user-C@H interac-tions. WS-Agreement compliant templates are used by the C@H Users to specify the re-quired quality level. An example of template filled with the C@H User’s rere-quired functional and non functional parameters is reported in the following:
Listing 2: Resource and Availability request in WS-Agreement
<ws:ServiceDescriptionTerm ws:Name="CLUSTER REQUEST" ws:ServiceName ="SET VARIABLE"> <mod:Cluster xmlns:mod="http://occi-wg.org/model"> <Compute> <architecture>x86</architecture> <cpuCores>4</cpuCores> [...] <title>compute1</title> </Compute> <Compute> <architecture>x86</architecture> [...] <title>compute2</title> </Compute> [...] </Cluster> </ws:ServiceDescriptionTerm> [...]
<wsag:GuaranteeTerm wsag:Name="Availability" wsag:ServiceScope="C@H Cluster">
<wsag:Variable wsag:Name="NodeAvailability" wsag:Metric="ch:availability" /> <wsag:ServiceLevelObjective> 97.0 </wsag:ServiceLevelObjective> <wsag:Variable wsag:Name="Duration" wsag:Metric="ch:hours" /> <wsag:ServiceLevelObjective> 8 </wsag:ServiceLevelObjective> </wasg:Variables> [..] </wsag:GuaranteeTerm>
In theServiceDescriptionTermsection the features of the needed resource are expressed (in this case the C@H User is asking for a cluster of two nodes). It is important to remark that the resource features’ request complies with the OCCI specification format. At acquisition time, this information will be extracted from the SLA and used to make explicit request to OCCI-compliant providers. As for theDurationparameter in the GuaranteeTerm section, it will be used at discovery time to filter out providers that do not share resources at the time, and for the duration, requested by the C@H User. Finally, through theNodeAvailability
parameter the C@H User specifies the required QoS (non-functional parameters), which in this specific case is targeted at 97.0%.
6.2 CHASE
CHASE (Cloud@Home Autonomic Service Engine) is a framework that allows to add self-optimization capabilities to grid and Cloud systems. It evolves from an existing framework for the autonomic performance management of service oriented architectures [13]. The en-gine allows to identify the best set of resources to be acquired and the best way to use them from the application point of view. CHASE is a modular framework that follows the auto-nomic computing paradigm, providing components to fully manage a grid/Cloud computing element. For the operation of CHASE as a stand-alone autonomic manager, the interested reader is invited to consult the work in [34]. Focus here is on the design of the services pro-vided by the framework to support the operativeness of C@H, namely theforecast service
and theperformance prediction service.
The forecast service provides a forecast of future values from historical data. It takes as input a time series of values and produces forecast based on autoregressive methods. The forecast service is used when the RQM needs to evaluate the provider availability, for which estimates for MTBF and MTTR are required. For the MTBF, historical data of heartbeat failure are used to produce the forecast. For the MTTR, historical boot times of the specific virtual machine image on a specific provider are used. The collection of historical data is made through the MAGDA platform, described in the next subsection.
The performance prediction service is a simulation-based estimator of application per-formance parameters, like execution time and resource usage. In particular, the CHASE simulator, fed with a) an application description, b) information regarding the current state of the system in terms of resource availability and load, and c) the user’s requested QoS, builds a parameterized objective function to be optimized. The optimization engine drives the simulator to explore the space of possible configurations in order to find a configuration
that meets the demands. The performance prediction service is used during the negotiation to evaluate the sustainability of performance guarantees. It can be also invoked when the monitored QoS agreed in the SLA is at risk of violation. New simulations are run with up-to-date settings in order to search for alternative scheduling decisions (like migrating or adding more VMs) that can solve the QoS problem.
6.3 Mobile Agent based Application Monitoring
The MAGDA (Mobile Agent Based Grid Architecture) component constantly carries out the monitoring of the QoS level provided by the leased resources. MAGDA [6] is a mobile agent platform implemented as extension of JADE, a FIPA standard [23] compliant agent platform developed by TILAB [9]. The MAGDA toolset allows to create an agent-enabled Cloud in which mobile agents are deployed on different virtual machines which are con-nected by a real or a virtual network. The details of how the MAGDA platform can interact with Cloud environments are discussed in past work [18]. The emphasis here will be on the description of the MAGDA-based monitoring service. This has been designed as a multi-agent system that distributes tasks among specialized multi-agents. It contemplates both static and mobile agents: the former are responsible for performing complex reasoning on the knowl-edge base, so they are statically executed where the data reside; the latter usually need to move to the target resources in order to perform local measurements or to get system infor-mation. TheArchiveris a static agent that configures the monitoring infrastructure, collects and stores measurements, computes statistics. According to the parameters to be monitored, the kind of measurement and the provider technology, the archiver starts differentMeters, which are implemented as mobile agents that the Archiver can dispatch where it needs. Ob-serversperiodically check a set of rules to detect critical situations. They query the Archiver to know about the statistics and eventually notify applications if some checks have failed. Applications can use aAgent-busservice to subscribe themselves for being alerted about each detected event. They can also invoke MAGDA services to start, stop or reconfigure the monitoring infrastructure. Finally, applications can access the complete knowledge base to retrieve information about Cloud configuration, monitoring configuration, statistics and the history of past failed checks.
In the current prototype, the Meters are used to collect three kinds of metrics:
– Image boot times: a Meter is configured to start-up as soon as the MAGDA platform is loaded. This provides an estimate of the time required to boot the virtual machine.
– Heartbeats: heartbeats are sent by the Meters to verify the liveness of the resource on which they are residing.
– Benchmark figures: Meters are able to execute different kind of benchmarks, which vary from simple local data sampling (actual CPU utilization, memory available, etc.) to distributed benchmarking (evaluating distributed data collection, or evaluating the global state with snapshot algorithms).
The MAGDA component poses a number of issue in terms of deployment. The agent platform, the Archiver and the bus service can be deployed as a dedicated virtual machine which coordinates all the available agents. MAGDA Meters, instead, must be installed inside the virtual machines of the user. A dedicated Java-based agent execution environment is installed and configured as a start-up service in the user VM. From the portal hosted in theC@H Frontend, it is possible to manage (start, stop, migrate, etc.) the mobile agents in order to control monitoring or other functionalities on top of all the computational resources
hosting a MAGDA container. In the current implementation, if the user does not accept the installation of the agent platform and the roaming of mobile agents in its virtual machine, the system cannot provide the required monitoring and the associated services like health check and performance prediction.
7 Frontend
The main role of theC@H Frontendwithin the C@H architecture is to provide anaccess pointto the system functionalities.
The Frontend provides the reference links to all the C@H components, thus operating as a glue entity for the C@H architecture. It serves the incoming requests by triggering appropriate processes on the specific C@H components in charge of serving such requests.
In order to provide a user-friendly and comprehensive interface to the system, the Fron-tend was implemented as an extensible and customizable Web portal. Furthermore, in accor-dance with the “everything-as-a-service” philosophy, the developed Frontend component, as the other C@H components, can be deployed as a virtual machine image, enabling the setup of an infrastructure access point with a modest amount of work (as shown in Section 8).
More specifically, the Frontend component has to manage both the C@H User and the C@H Admin incoming requests. For this reason it has been split into two parts as discussed in the following.
7.1 User Frontend
The main goal of the C@H User Frontend is to provide access to tools and the services im-plemented by the system in favor of the end users. Such tools base on and involve lower level functionalities and operations that are hidden to the users, masquerading the C@H internal organization and resource provisioning model in a Cloud-fashion. Moreover, ubiquity and fault tolerance have to be guaranteed, following a service oriented provisioning model. For such a reason the C@H User Frontend is implemented as a Web service, providing suitable SOAP and/or REST interfaces.
The User Frontend exposes the main services allowing end users to access C@H re-sources. In case the C@H provider implements guarantees on the resource provisioning, adequate services for negotiating the SLA and for monitoring the agreed QoS level on the resources are required. In such cases the Frontend pre-processes, splits and forwards the incoming requests to the corresponding SLA and QoS management components according to the specified requirements.
More specifically the C@H User Frontend exposes the following functionalities:
– resource negotiation- through which the C@H User can trigger the resource negotiation process with the SLA Management module (in particular, downloading SLA templates, issuing SLA proposals, proposing SLA counter offers);
– resource management - allowing the C@H User to manage (activate/deactivate) the leased resources obtained by the C@H IaaS through the Resource Management module;
– SLA monitoring- providing the C@H User tools for monitoring the status of the SLA regulating the resource provision through a specific interface to the SLA Manager;
– settings and preference management - allowing the C@H User to customize the user interface with specific user settings and configurations.
7.2 Admin Frontend
From the provider perspective one of the most interesting characteristic of the C@H system is to provide a service for building up a C@H provider and the corresponding Infrastructure-as-a-Service by selecting the basic components and services it has to provide. In this way a C@H Admin can customize its service (i.e. the IaaS Cloud provisioning), can decide to either include SLA/QoS management or provide the infrastructure without any guarantee (best effort), and finally can specify where they have to be deployed.
The Admin Frontend implements the services to set-up, customize and implement such choices, driving the Admin through all the required steps for a correct C@H service estab-lishment. More specifically such services are:
– system management- allows the administrator to set-up, configure and deploy a C@H infrastructure and to customize all the services it provides, and therefore also the Fron-tend interface;
– negotiation management- through which negotiation policies can be defined, fine-tuned and deployed;
– QoS management- allows the administrator to specify the QoS policies that must be put in force to sustain the SLAs.
The basic components that needs be included in any C@H provider configuration are those of the Resource Abstraction module. A minimal C@H system configuration, building an IaaS with no QoS guarantees, must provide such tools and services, that just imple-ment the basic system manageimple-ment mechanisms. In case the Admin needs to set-up a C@H infrastructure providing QoS on top of resources, it is necessary to enhance the minimal configuration with the Resource and SLA management modules, thus deploying the whole configuration shown in Fig. 2.
Different configurations can be identified to best fit and meet the Admin requirements, not necessarily involving all the C@H components identified above.
It is important to remark that the component selection is not directly performed by the C@H Admin that just customizes the C@H provisioning model they want to implement. The component selection is therefore automatically performed by the Frontend tools according to the requirements specified by the Admin. The deployment is instead mainly in charge of the Admin.
8 C@H in action
In the previous sections the C@H system has been described from a static perspective. The stress has been on the C@H architectural modules and components, and on the function-ality that each analyzed entity is able to offer. The current section, instead, intends to give the reader a dynamic view of the C@H system, focusing on the activities that are triggered within the system and on the interactions taking place among the components of the archi-tecture.
8.1 Process View
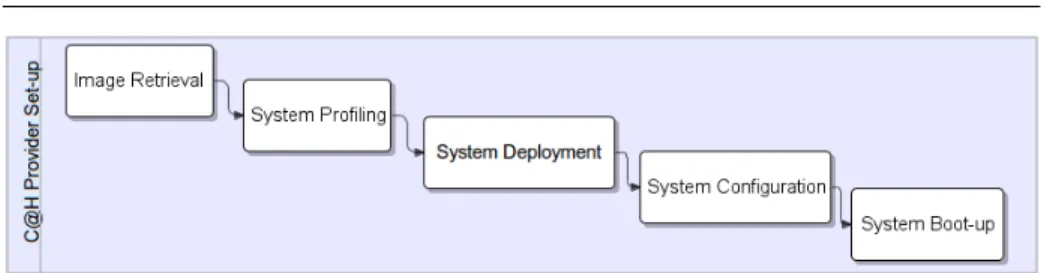
Some activities must be carried out in order to create from scratch a new C@H system and to get it ready to work, as shown in Fig. 4. In the first stage (image retrieval) the overall C@H
Fig. 4: C@H infrastructure set-up process
system image, made up of specific software components, must be retrieved. Several versions of the C@H system are available, each providing a different flavor of services, ranging from the very basic to the full-fledged.
As discussed in Section 7, the basic version is equipped with just the Resource Abstrac-tion module. The C@H User is aware that they will not get any guarantee on the performance of the resources provided, and can not claim support in case of QoS degradation. Thus, the service will be provided on a best-effort basis. The full-fledged version of the C@H system, instead, is featured with the SLA/QoS management service. In the following we will discuss the activities to be carried on in the case that a full-fledged C@H system must be set-up.
Once the image is retrieved, thesystem profilingactivity is performed, during which the C@H Admin specifies the policies and the strategies that will have to be adopted for SLA ne-gotiation and enforcement respectively. After that, the components can be deployed (system deployment), configured in order to properly work with each other (system configuration), and run (system boot-up).
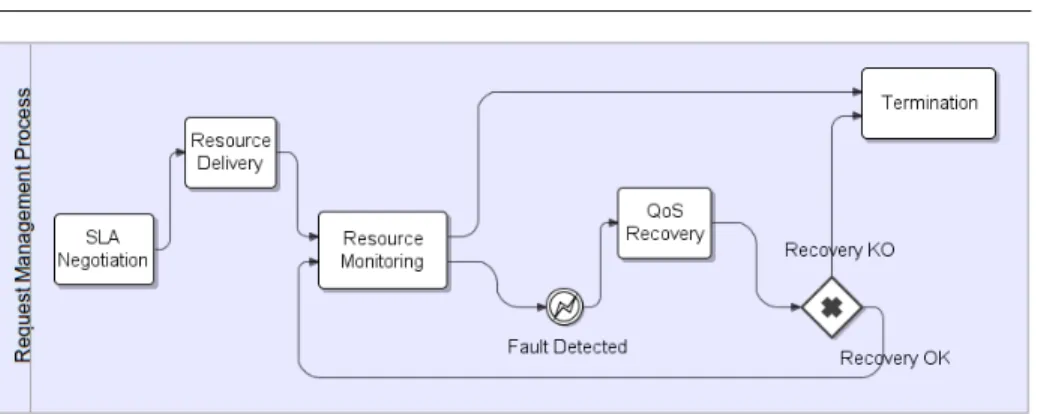
The C@H system is then up and ready to accept C@H User requests. The overall request management process (shown in Fig. 5) involves many activities, some of which are optional, in the sense that they can be either triggered or not, depending on the C@H User’s specific request. Such process starts with theSLA negotiationof the resource functional parameters and, optionally, of the QoS level (non-functional parameters) that the C@H system must support at provision time. In the latter case, upon a successful termination of the negotiation activity, the C@H User will receive a formal guarantee (in the form of an SLA) that the requested resources will be provisioned and, if required, the QoS levels will be sustained.
Should the negotiation fail, the request would be simply discarded and the C@H User would have to issue a new request. Otherwise, upon a successful negotiation, the requested resources are activated and assigned to the C@H User (resource delivery). From this point onwards, the C@H User can use the resources. If the SLA also requested QoS, a monitoring infrastructure is set-up to take under constant control the performance of the delivered re-sources (resource monitoring): in such activity, the non-functional parameters contributing to the overall QoS (namely, the availability) are monitored to ensure that none of the SLA terms is being violated.
Whenever any QoS parameter is about to be violated, a recovery action is triggered (QoS recovery): in this step countermeasures are taken in order to bring the QoS back to “safe” levels. Upon a successful recovery, the originally requested QoS is restored and the monitoring process, which had been temporarily put on stand-by, is resumed in order to detect new possible faults. Should instead the recovery fail, the resource provision would be stopped and the SLA would be terminated. Finally, unless the C@H User or the C@H system decides (for any reason) to prematurely force the termination, the resource provision
Fig. 5: Request management process
will end up at the termination time specified in the SLA, and the resources will be released (termination).
8.2 Interaction view
This subsection describes in detail through a practical approach how to set up a C@H provider and how this latter negotiates and enforces QoS on top of resources voluntarily shared by their Cloud providers. In subsection 8.2.1, we first show how a C@H Admin can build and set up the C@H components that implement the C@H infrastructure according to the IaaS service they want to provide (with or without fault tolerance, QoS-SLA man-agement, etc.). The QoS negotiation and enforcement dynamics are described in subsec-tion 8.2.2 and subsecsubsec-tion 8.2.3, respectively. As regards the described scenarios, the target resources taken into account are academic clusters hosting a Cloud middleware (e.g., Eu-calyptus [28], Nimbus [29], PerfCloud [12], Clever [42], OpenStack [41]) able to provide Virtual Clusters (VCs).
We also assume that such clusters have a reliable frontend during the provider availabil-ity time windows, whereas computing nodes are unreliable since, for example, they might crash due to power outages or they might be periodically unavailable for a while to perform reconfiguration or maintenance. The scenario we consider implements a C@H infrastructure able to satisfy C@H User requests of VCs including specific QoS requirements. In partic-ular, the QoS is expressed in terms of availability, i.e., the fraction of time (percentage) the node must be up and reachable with respect to a 24 hours base time, as specified in Sec-tion 5.2. In order to do that, we assume all the nodes belong to the same Cloud provider. Although C@H is able to pick resources from different providers, in this specific case all resources are acquired by the same provider. The VC images host the MAGDA agent-based monitoring service.
8.2.1 System Setup
The C@H Admin is the actor in charge of the deployment and the setup of the C@H infras-tructure. As already pointed out in Section 3, C@H components are provided with service-oriented interfaces. Such a choice enables flexible deployment schemes. Inspired by the “as-a-service” paradigm, individual (or group of) components can be packaged together and run within virtual machines offered by any (even commercial) Cloud provider.
: C@H Admin
: Cloud Provider SLA CH : CP VM Manage CH : CP VM : C@H_Frontend
1 : buildup_C@H_PROV()
The system is now ready to accept requests from C@H Users 2 : activateImages() 3 : activate()<<create>>
4
5 : activate()<<create>> 6 7 : images_URL
8 : configure_SLA_CHASE_MAGDA_SENSOR The Cloud Provider repository stores
the pre-packaged C@H components' images
9 : configure_FRONTEND_RESOURCEDISCOVERY_RQM 10 : images_URL
Fig. 6: Cloud@Home system setup
The C@H Admin interacts with the C@H frontend in order to specify the services they want to enable in the C@H provider and to configure them with QoS/SLA policies and strategies. This operation is performed by just selecting the required functionalities and specifying the policies, the strategies and the provider on which such services will be de-ployed. Therefore the Admin Frontend automatically selects the components of the C@H IaaS the Admin wants to provide. In order to implement the considered scenario, he must set up a C@H infrastructure able to provide SLA/QoS services. Thus, it is necessary to build up a C@H IaaS with all the modules and components shown in Fig. 2, and specifically with the SLA management module. The C@H project repository stores ready-to-run VMs (in the formats suitable for the different Cloud providers) pre-packaged with the C@H components for QoS management. Before deploying the system, such images must be retrieved from the repository. In the specific scenario taken into account, according to the C@H Admin requirements, the Frontend needs to get the following images:
– SLA CH:packaged with theSLA Manager,CHASEandMAGDAcomponents.
– Manage CHpackaged with theFrontend,RegistryandRQMcomponents.
– VCFEandVCnode, i.e., the images of the virtual cluster frontend (VCFE) and virtual node (VCnode), respectively.
The sequence diagram in Fig. 6 shows the setup workflow. Only one instance for each of the first two images (SLA CHandManage CH) has to be deployed.
The C@H Admin initially interacts with the Admin Frontend sending its requirements, policies, parameters and configurations and also the Cloud provider for deploying the C@H IaaS service (step 1). Thus, the Frontend invokes theactivateImagesprimitive on the target Cloud provider (step 2) that retrieves and launches theSLA CHimage (step 3-4). After-wards, the Cloud provider retrieves and runs theManage CH(step 5), obtaining the cor-responding URLs (step 6) that forwards to the Frontend along with with theSLA CHVM one (step 7). In steps 8 and 9 the C@H software components running on the images just bootstrapped are configured. Once the Frontend terminates such configuration forwards the image URLs to the Admin that can directly interact with them (step 10). The C@H system is now up and ready to accept requests from C@H Users.
AvailableProviders
loop
: C@H User
: C@H_Frontend : C@H_SlaManager : C@H_RQM : CHASE : MAGDA : Cloud Provider
: C@H_MAGDA_Agent : Cluster : C@H_Registry 1 : getTemplates() 2 : getTemplates() 3 : templates 4 : templates 5 : negotiateSLA()
6 : negotiateSLA() 7 : evaluateSLA() 8 : getAvailableProviders()
9 : AvailableProviders
10 : getHistoricalData() 11 : Data 12 : evaluateSustainability()
13 : SustainabilityResult
14 [SustainabilityOK] : acquireResource() <<create>>15 : new()
16 : resource_URL 17 : resource_URL
18 : [ResourcesAquired]: monitorResources()
19 : resourceURL 20 *[Node] : new()
<<create>> 21 22 : upload_MAGDA_Agents 23 : Ok 24 : resources_aquired 25 : createSLA() 26 : SLA_EPR 27 : SLA_EPR
Fig. 7: Resource negotiation and acquisition in C@H
8.2.2 Negotiation
In Fig. 7, the (one-shot) negotiation and cluster activation process is shown, assuming that the VC images are already available on the target Cloud provider. The C@H User initially requests the C@H SLA templates (steps 1–4). WS-Agreement compliant templates are used to guide the C@H User in the specification of the required quality level as reported in Listing 2.
The one-shot negotiation is performed in steps 5–27. The RQM, which coordinates the negotiation process in collaboration with the Registry and SLA Manager services, has to assess the sustainability of the SLA proposal.
First, the Registry is queried to retrieve the candidate providers that can supply resources for the specific request (steps 8–9). For each candidate provider, availability and perfor-mance are estimated, as discussed in Section 5.2. In the selection process, candidates are iteratively checked one by one: the first candidate provider matching the required QoS is chosen to serve the request. With regards to the node availability, the RQM retrieves moni-toring data from the MAGDA platform (steps 10–11), which are used to obtain a prediction of the MTBF and the MTTR from CHASE (step 12). The same interaction is used for per-formance guarantees: benchmark values are retrieved from MAGDA and sent to CHASE
to obtain performance predictions. If CHASE finds a suitable configuration of resources, it sends back an acknowledgement to the RQM (step 13).
In case a candidate matches the QoS requirements (SustainabilityOK), the RQM pro-ceeds with the acquisition of the resources (steps 14–17). Should the selected provider have run out of resources, the next provider in the candidate list would then be checked against the QoS requirements and, if suitable, would be asked for supplying the resources.
The process iterates until a candidate provider passes the sustainability test and is able to provision the requested resources. In that case (ResourcesAcquired), the resources are acquired and activated (step 18) and the URL is provided back to the C@H User through the Frontend (step 19). An agent-based monitoring infrastructure, instructed with the QoS target to be accomplished, is then set up (steps 20–23), and the outcome of whole process is notified to the SLA Manager (step 24). Finally, the SLA is created (step 25) and its end-point-reference (EPR) is notified to the C@H User (steps 26-27).
If no suitable provider is found, the C@H User will have to to fill out a new template to renegotiate the service level, and the overall process will restart from step 5.
8.2.3 Fault recovery and SLA enforcement
Assuming the virtual cluster of nodes is up and that the MAGDA agents are running on the virtual nodes, reporting the observed status to the C@H MAGDA component, the use case here considered, described in Fig. 8, concerns a scenario in which a virtual node of the VC becomes unreachable.
When a VM fails, the fault is detected by the C@H MAGDA component since the MAGDA agent on the faulty VM stops sending status reports. The failure could be due to temporary node unavailability, for example because of network problems, or to node reconfigurations or reboots. Otherwise, it could be a permanent fault due to hardware or software outages. Therefore, a recovery procedure is started by the MAGDA agent on cluster frontend in order to ascertain what is actually going on.
If the MAGDA agent does not reply within a given time (the timeout shown in step 1, tai-lored on the availability requested in the SLA), the C@H MAGDA sends acritical recovery
message to the RQM (step 2). According to the fault alert and to the QoS requirements es-tablished by the SLA policy to be enforced, the RQM decides if and when to begin the fault recovery process (step 3). The internal recovery procedure activates a new VM on the Cloud provider and integrates it into the existing cluster (steps 4–9). Finally, a new MAGDA agent is sent and launched into the new node (steps 10–14), and the successful QoS adjustment is notified to the C@H Frontend (step 15).
The above described process is able to guarantee the required availability if the SLA is correctly negotiated and the system is correctly monitored. In such process we evaluate the steady state availability, defined on a long interval, ideally infinite. Thus we do not need fast recovery procedures but instead we have to negotiate on values that likely can be granted in the future. The monitoring system stores the history of the infrastructure and from the statistics thus collected it evaluates the detection and reaction times. In this way the system is able (thanks to MAGDA monitoring and CHASE predictions) to predict how many failures will occur. Furthermore the system is tuned to deal with the worst cases in order to respect the SLA, thus providing a tolerance above the required availability threshold. However, the SLA enforcement is triggered whenever a failure event is detected and not only when the SLA level (e.g. the system availability value) is below the threshold. It is up to the C@H administrator to correctly identify the SLA to grant and to define the penalties depending on the chosen business model.