Towards A Self-Managing Software Patching Process Using Black-Box
Persistent-State Manifests
John Dunagan, Roussi Roussev, Brad Daniels, Aaron Johnson,
Chad Verbowski, Yi-Min Wang
Microsoft Research, Redmond, Washington
Contact: [email protected]
Abstract
We describe a new approach to self-managing software patching. We identify visibility into patch impact as the key missing component in automating the current patching process, and we present a suite of components that provides this visibility by constructing black-box persistent-state manifests through self-monitoring of dependencies. Additionally, we use the component suite to measure the actual impact of recent patches on several important commercial applications.
1.
Introduction
Software patching is a significant source of expense and frustration for IT staffs. Organizations are concerned that patches will destabilize their existing applications, and this concern results in significant delays in applying released patches to publicly announced vulnerabilities. This delay in applying released patches has allowed the outbreak of highly disruptive worms, such as the recent SQL Slammer worm [P03].
State-of-the-art patch management tools automate many aspects of the patching process. Commercial products such as Microsoft Baseline Security Analyzer, Tivoli, Microsoft Systems Management Server, or Corporate Windows Update offer the ability to automatically check for the availability of relevant patches, download and apply them [MBSA, Tiv, SMS, WU].
The greatest bottleneck in the patching process is the time required to test a patched subset of systems for stability before rolling out the patch to all systems [BAC03]. Organizations deploying a patch typically want to test patches even after they have been tested by the corporation releasing the patch. One common reason for this second round of testing is the existence of third-party and in-house applications that have not previously been tested. Even when the patch is known to only update one or two libraries, organizations often cannot take advantage of this knowledge to reduce or target the testing load because they typically do not have an exhaustive list of the library dependencies on their machines. They may not even have an exhaustive list of the software that is in regular use on each machine, even though accurate
inventory is a recommended best practice in systems management [ITIL, MOF].
Time spent testing reflects a decision by organizations to prioritize stability over vulnerability. Applying a security patch will reduce vulnerability, but also risks causing some applications to stop functioning correctly [BAC03]. The recent increase in Internet worms and the economic losses due to such worms suggest that the cost of remaining vulnerable is increasing, and that organizations may increasingly need to focus their limited testing resources more precisely [P03].
In this paper, we present a suite of components that provide visibility into patch impact with the goal of reducing the testing bottleneck. In conjunction with these components, we propose policies for patch deployment that allow limited testing resources to be targeted towards the patches most likely to be destabilizing and the machines that provide the best coverage of impacted applications. To the extent that these policies are adopted, they allow the testing bottleneck in patch management to be reduced or eliminated.
The goal of self-management is to reduce the amount of human labor required to manage computer systems. A principal technique for accomplishing this is to increase the level of abstraction at which humans interact with these systems. Our components collect and analyze the information necessary to present system administrators with recommended actions at an increased level of abstraction. An example recommended action would be to patch the smallest subset of the computers in an organization such that every application directly impacted by the patch is present on at least one of the computers. Our components enable this high-level goal to be mapped to an explicit list of computers that need to be patched and applications that need to be tested.
The policy we propose for estimating the likelihood that a patch will be destabilizing is based on the following thesis: patches from one software provider that impact dynamic libraries or configuration files loaded by applications from another software provider are the least likely to have been previously tested together. The organization releasing the patch may be able to test some applications beforehand, but it is unlikely to be able to test all third-party applications affected by the patch. These
patch-application combinations pose the greatest concern during patch deployment.
The policy we propose for targeted rollout during the testing phase is to patch the minimum number of machines that still provides the required coverage of impacted applications. Our suite of components provides the self-monitoring infrastructure to allow this targeted deployment.
Even with this ability to target, an organization may still not have sufficient testing resources to thoroughly test patches before deployment. In this case, these same polices can also guide the deployment of patches automatically. If a phased rollout is desired, the patches can be incrementally rolled out to machines based on each machine’s mix of running applications – the component suite provides sufficient visibility that an organization can avoid patching all of the machines performing one operation at once. If instead the desire is to classify some patches for immediate deployment, and to delay other patches for testing, those patches that do not directly affect libraries or configuration settings used by mission-critical third-party applications can be identified and chosen for immediate deployment. We present preliminary results in Section 7 that this policy would allow the immediate deployment of a large class of patches.
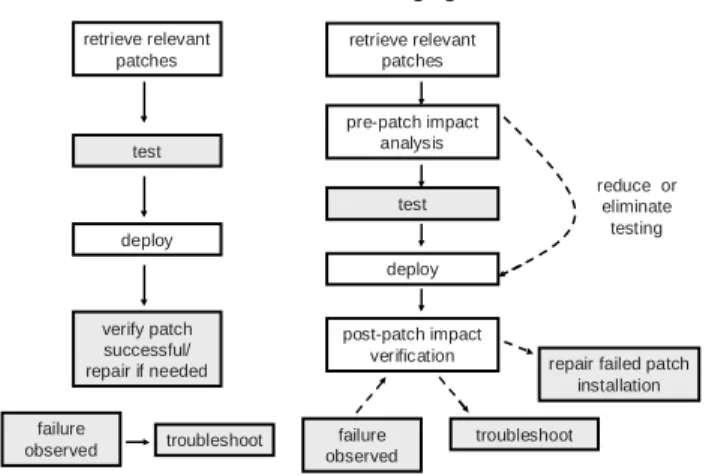
The current state of the art in managing computers still involves the detection of failures followed by troubleshooting. In software patching, the two common failure scenarios are failure for the patch to take effect, and failure of some other application because of the patch’s effect. To enable a more self-managing patching process, our component suite verifies that patches have successfully been installed, and in the case that a failure has been observed in an application, guides the troubleshooting process by helping to assess whether the patch is at fault. Figure 1 shows the current patching process and the self-managing patching process that these components enable.
To obtain the information necessary for performing these operations, our components must determine for each machine whether a patch updates libraries and/or configuration settings loaded only by the system, only by non-mission-critical third-party applications (as specified by organizational policy), or by mission-critical third-party applications. We refer to an explicit list of an application’s dependencies as an application manifest. To construct these manifests, we trace all accesses to the persistent store. To contrast this approach with white-box approaches such as explicit specification of dependencies by developers, we introduce the term black-box persistent-state manifest.
To the best of our knowledge, our component suite is the first technology to be both non-participatory and
complete with respect to dynamic dependencies on the persistent store. Previous work on dependency analysis
has often required explicit dependency specification (e.g., Redhat Package Manager [RPM97], Debian’s DEB [DEB], or Slackware’s TGZ [SLA]). This requires the correct
participation of all module providers to be effective, which renders it fragile [BAC03]. The previous work that did not require participation has fallen short in completeness by not capturing dynamic dependencies. For example, Hart et al in their work on static dependency analysis [HD02] listed live tracing that would capture dynamic library dependencies as important future work. Our components work with legacy applications for which no explicit dependency information is available, and they capture all dynamic library loads (and other persistent store interactions) that occur in a running system.
retrieve relevant patches test deploy verify patch successful/ repair if needed reduce or eliminate testing troubleshoot post-patch impact verification retrieve relevant patches test pre-patch impact analysis deploy
repair failed patch installation failure
observed observedfailure troubleshoot
Current Process Self-Managing Process
Figure 1: Current versus self-managing patching process. Shaded boxes denote steps requiring system administrator involvement. The self-managing process will reduce or eliminate system administrator involvement.
We summarize the three contributions we make towards enabling a self-managing patching process as follows: First, we design and implement non-participatory complete self-monitoring of application dependencies to enable pre-patch impact analysis. Second, we identify and evaluate patch management policies that allow the targeting of limited testing resources, and which in the case of severely constrained testing resources will allow the automatic deployment of many patches while still singling out those patches most likely to be destabilizing. Third, we identify and support an adoption path from current system administration practices to this mostly self-managing patching process.
We organize the remainder of the paper as follows: In Section 2, we describe an abstract model of dependency analysis, and we characterize our suite of components with respect to this abstract model. In Section 3, we describe the Online Analyzer, an always-running process that performs self-monitoring by tracking persistent store dependencies and maintaining an up-to-date map of these dependencies. In Section 4 we justify our design goal of improving the patching process on today’s systems, and we speculate on the limits of an ideal self-managing patching process. In Section 5 we describe how our components provide
pre-patch impact analysis, and the self-managing strategy that this enables. In Section 6 we describe how our components can be used to verify that an applied patch has taken effect, and the implications for self-management. In Section 7 we describe our initial results studying recently released security patches, analyzing the effectiveness of our components in enabling targeted testing, and classifying those patches least likely to be destabilizing because they do not update dynamic libraries or configuration settings directly loaded by third-party applications. In Section 8 we discuss related work, and in Section 9 we discuss the limitations of our current implementation and our planned future work. Finally, in Section 10 we conclude.
2.
Modeling Dependency and Impact
We model applications as objects that depend on other objects. As mentioned previously, an application manifest is an explicit list of an application’s dependencies. The particular application manifest our components use is a black-box persistent-state manifest. We model patches as objects that affect other objects. A patch manifest is an explicit list of the objects that a patch updates. We perform patch impact analysis by doing a simple reachability query from a patch to all the applications that depend on objects potentially updated by the patch.
Our current implementation analyzes application dependencies on objects in the file system and the registry, a persistent store used for configuration information on Windows systems [SR00]. In a non-Windows environment, configuration files are typically used in place of the registry, and our techniques would straightforwardly map to this environment as well.
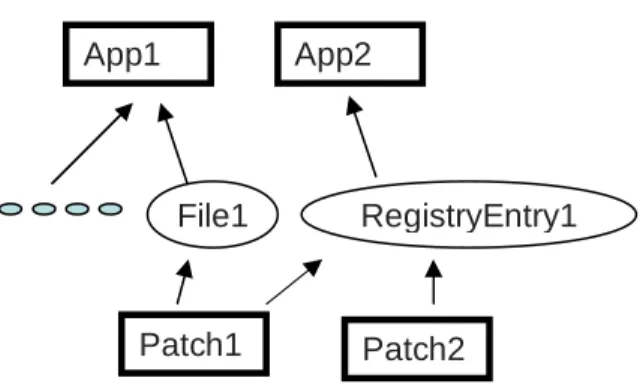
This amount of coverage is sufficient to detect application dependencies on dynamic libraries (DLLs), configuration files, and configuration information stored in the registry. An example model that our current implementation could produce is given in Figure 2.
Figure 2: Example Dependency and Impact Model. Although our current implementation only targets file and registry dependencies, the model can be straightforwardly extended to incorporate other dependencies. Modeling dependencies due to inter-process
communication would simply involve the addition of edges to the graph. Modeling the update of individual settings within a configuration file could be accomplished by splitting the single node representing the configuration file in to a collection of nodes representing the individual settings within the file. An example of this splitting technique is already present in our treatment of the registry; we could have treated every write to a registry entry as updating the entire registry, but instead we choose to represent every item within the registry as a separate object.
Previewing the discussion of our patch analysis results in Section 7, we find that many security patches update DLLs that are loaded by the system, but not by individual applications. This justifies our modeling approach: a model that treats all updates as potentially destabilizing to the applications that depend on the updated items can still significantly reduce the testing requirements for many patches.
3.
Self-Monitoring of Dependencies
To construct application manifests, we use an always-running process that is loaded during boot on every machine where we want to enable pre-patch impact analysis. We refer to this process as the Online Analyzer, or OA. The OA constructs application manifests through drivers that trace all file and registry accesses. Every application (as identified by its process name) is mapped to every file or registry item that it has ever been observed to use, either as a read or a write.
This tracing approach has significant advantages over two alternative approaches to producing similar application dependency information: explicit specification by developers, and static analysis (e.g., [DLS02]). Explicit application manifests are not yet available for most commercial applications, and one of our design goals is to support patch impact analysis on legacy applications. To the extent that explicit manifests do become available, they can be used in place of the black-box manifests we currently construct.
Static analysis tools have not yet been shown to be capable of resolving application dependencies on a per-machine basis. For example, an application may load either one of two different dynamic libraries depending on environment variable specifications. Tracing effectively resolves these dependencies to the actual file that is loaded. Tracing and static analysis do provide different coverage guarantees. In tracing, only dependencies that occur on exercised code paths are discovered. This is a desirable property in this setting. The OA will correctly assess all the dependencies that are exercised by the test workload (as well as the production workload), and this is exactly the set of dependencies that should be considered when making testing decisions.
RegistryEntry1 File1
Patch1 Patch2
We currently have the OA deployed to 30 machines. Our preliminary results are that the memory, CPU and disk overhead of this approach are acceptable on a developer-class machine subject to a typical developer work-load. A more precise characterization of the OA’s performance is a subject of future work.
4.
Towards Self-Management
We have targeted improving the patching process on today’s systems for several reasons. First, the economic importance of the current install base justifies research into improving the manageability of today’s systems. However, there are two additional reasons to target the legacy in research on self-managing systems.
First, improving manageability for legacy applications forced us to adopt a non-participatory approach. A significant benefit of this kind of approach is that it handles future applications without requiring additional development resources. By avoiding this requirement, improved manageability becomes a feature of the system, rather than a cost born by application developers.
A second benefit to improving manageability for legacy applications was that it allowed us to better evaluate the effectiveness of our approach. One difficulty in manageability research is that the actual source of management costs is often visible only after an application has been widely deployed. By targeting legacy applications, we are able to validate that the problem we are solving is a significant part of the manageability problem. By improving manageability for the legacy, we also gain an understanding grounded in experience for designing tomorrow’s systems to be more self-managing.
As mentioned in the Introduction, a principal technique in self-management is to allow humans to interact with the system at a higher level of abstraction. However, it is not clear that it will ever be beneficial to raise this level of abstraction so high that system administrators do not have control over when patch deployment happens. Consider the example of a company that is about to broadcast the World Cup – given the choice between patching their software now, and patching their software after the broadcast, a human operator would definitely make the right choice. In contrast, the state of the art in allowing computers to understand business objectives does not make one comfortable entrusting this decision to an autonomic agent.
Lastly, although other approaches to reducing the costs associated with patching do exist, these approaches are complementary to ours. For example, increasing the reliability of patches is clearly good, but it will not remove the need to manage their deployment and to test patched applications. Similarly, increased automation of the testing process (another approach to improving patch manageability) complements our ability to target testing resources.
5.
Pre-Patch Impact Analysis
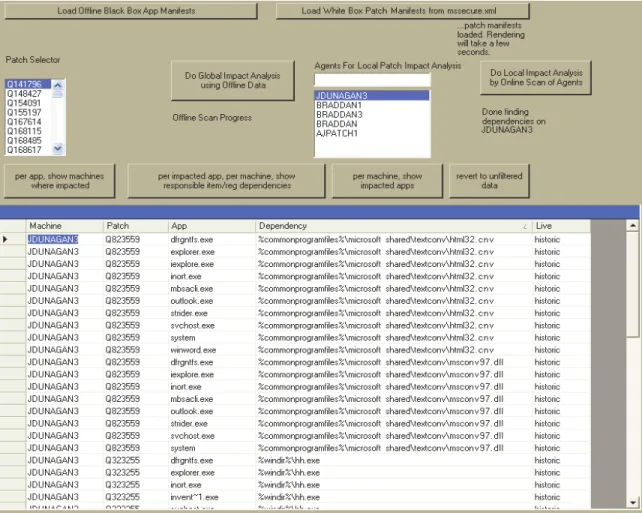
The Pre-Patch Impact Analysis component that we have developed can be composed programmatically with other components, or it can be accessed through a UI (depicted in Figure 4). An ideal self-managing patching process should be realized through the programmatic composition of this component with the OA. An administrator can specify the appropriate policy governing patch rollout, and the component suite can implement this policy, involving the administrator only when specified to do so by the policy.
Although we are primarily interested in the self-managing scenarios enabled by the Pre-Patch Impact Analysis component, we will also describe a scenario in which a system administrator interacts with the component directly. By helping system administrators perform their current responsibilities, we hope to facilitate adoption of our component suite. Once our component suite is deployed, the transition to a self-managing patching process is primarily a matter of policy specification.
The task of the Pre-Patch Impact Analysis component is to intersect patch manifests and application manifests. From this, the component can determine the set of applications on each machine that a given patch potentially impacts.
To obtain patch manifests, we use a published source of this information, mssecure.xml – this source contains information for all security-related patches released for Windows. This file is used by the Microsoft Baseline Security Analyzer [MBSA] to determine whether a given machine is missing any security-related patches; for each patch, mssecure.xml specifies the files and registry entries that the patch updates to close a particular security hole. Although there are alternative sources of this information, such as programmatically inspecting the patch executable, tracing the actions of the patch on a test machine, or examining system meta-data that records the effect of the patch (such as the Windows Uninstall meta-data), this published source was the most convenient for us.
Once the component has a manifest for a set of patches that are of interest, the component calls the OA with the patch manifest. The OA then returns the list of impacted applications based on all file and registry accesses that have occurred since the OA was installed.
We now describe a representative system administration scenario that is enabled by the UI to the Pre-Patch Impact Analysis component. Administrators managing the deployment of patches to a large number of machines can use current tools to automatically detect which machines require a certain patch and then to copy the patch to the target machine. The UI to the Pre-Patch Impact Analysis component allows the administrator to query which applications might be impacted on each machine, and which file or registry item results in the impact. Once the decision to apply the patch has been
made, current tools (e.g., [SMS]) can be used to apply the patch without administrator involvement.
To further reduce the barrier to deploying our components, we have designed the components to also support a different performance tradeoff. The OA can periodically upload dependency information to a central server, thereby trading off memory overhead at the production system for I/O overhead. The central server then builds a global table of per-machine per-application file and registry dependencies. This allows access to all the functionality of the Pre-Patch Impact Analysis component with the one caveat that dependencies are slightly less current (i.e., they do not reflect file and registry accesses that occurred for the first time after the last upload). If this degradation in coverage is acceptable, automatic decisions about patching can be made based on the data at the central server (referring again to Figure 4, this functionality is currently exposed in the UI through the “Load Offline Black Box App Manifests” button). We expect that the periodic upload approach will often be a worthwhile tradeoff for Pre-Patch Impact Analysis on heavily utilized systems.
6.
Post-Patch Impact Verification
We now describe the Post-Patch Impact Verification component. This component is designed to be used after the patch has been deployed. After deployment, the patch management process still requires verifying that the patch took effect and assigning responsibility if an application failure coincides with the patch deployment.
To verify that the patch took effect, the Post-Patch Impact Verification component scans the volatile state of all processes on the system for all currently loaded DLLs. For each DLL, the component checks that the version being loaded is the same as the version specified in the patch manifest. Automatic verification that a patch has taken effect is necessary to prevent the system administrator from having to check this manually.
If an application failure coincides with patch deployment, the Post-Patch Impact Verification component helps the administrator assign responsibility for the failure. Using the component, the system administrator may quickly deduce whether any of the DLLs that a failing application is loading were updated by the patch. Previewing our discussion in Section 7, many patches only update DLLs loaded by the system -- in this case, the system administrator could assess that the patch is unlikely to be the cause of the problem. The administrator can also use the component to see whether the application is loading a DLL that has recently been updated through some other means, and whether this instead might be the cause of the failure [WRV03].
7.
Experimental Evaluation and Discussion
7.1. Pre-Patch Impact AnalysisWe evaluated our methods and tools against eight widely-used Windows applications and eight recent patches. We selected both applications produced by Microsoft and applications produced by independent software vendors (ISVs). Also, one of the Microsoft applications that we selected is a server application, Internet Information Server (IIS). We used five patches that updated widely used DLLs, and three patches that updated DLLs only loaded by the system. Although we have not yet performed an exhaustive categorization of released security patches, our preliminary results are that this split is representative --- many security patches update DLLs only loaded by the system. The patches we evaluated are:
MS02-012: Malformed Data Transfer Request can Cause Windows SMTP Service to Fail (Q313450)
MS02-050: Certificate Validation Flaw Might Permit Identity Spoofing (Q329115)
MS03-026: Buffer Overrun in RPC May Allow Code Execution (Q823980)
MS03-030: Unchecked Buffer in DirectX Could Enable System Compromise (Q819696)
MS04-007: An ASN.1 vulnerability could allow code execution (Q828028)
MS03-023: Buffer Overrun in the HTML Converter Could Allow Code Execution (Q823559)
MS02-054: Unchecked Buffer in File Decompression Functions May Allow Attacker to Run Code (Q329048) MS03-001: Unchecked Buffer in the Locator Service Might Permit Code to Run (Q810833)
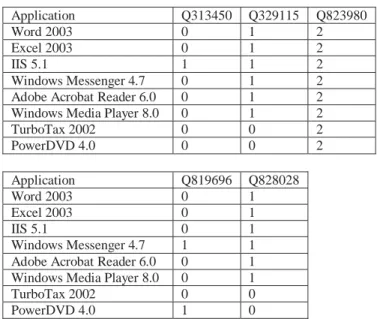
We first performed pre-patch impact analysis on the patches. Table 1 shows the five patches that have direct impact on at least one of the applications. The remaining three patches had no impact on any applications, and therefore could be automatically applied in an environment with constrained testing resources by the policy we propose. The values of each data cell represent the number of modules loaded by the application that were updated by the particular patch.
Based on the preliminary results, we believe that pre-patch impact analysis could allow many security related patches to be applied automatically. In our future work, we plan to expand the scope of this study to include a wider and more thorough survey of patch impact.
Table 1: Patches with direct impact on the applications Application Q313450 Q329115 Q823980 Word 2003 0 1 2 Excel 2003 0 1 2 IIS 5.1 1 1 2 Windows Messenger 4.7 0 1 2
Adobe Acrobat Reader 6.0 0 1 2
Windows Media Player 8.0 0 1 2
TurboTax 2002 0 0 2 PowerDVD 4.0 0 0 2 Application Q819696 Q828028 Word 2003 0 1 Excel 2003 0 1 IIS 5.1 0 1 Windows Messenger 4.7 1 1
Adobe Acrobat Reader 6.0 0 1
Windows Media Player 8.0 0 1
TurboTax 2002 0 0
PowerDVD 4.0 1 0
7.2. Post-Patch Impact Verification
We evaluated our post-patch impact verification component in three scenarios: verifying the successful application of a patch, troubleshooting a configuration failure that coincided with a patch install, and troubleshooting an application failure caused by a faulty patch. To test that our component can successfully verify the application of a patch, we used the same previous eight patches. The component succeeded.
To evaluate the ability of our component to aid in troubleshooting a configuration failure coinciding with a patch installation, we first applied the three unimpactful patches previously discussed, and then simulated a configuration failure (registry value corruption) affecting Word 2003 and an environment problem (network layer failure) affecting Internet Information Server 5.1. Since the impact verification component showed that the patch installation had no impact on those applications, a system administrator troubleshooting this problem would have fruitfully been directed towards a different line of analysis. For example, methods such as the Strider troubleshooter [WVD03] or a related network troubleshooting tool could be used to further isolate the problem.
To evaluate the scenario where a faulty patch is responsible for an application failure, we applied a known-to-be-defective Remote Access Service (RAS) patch (MS02-029: Unchecked Buffer in Remote Access Service Phonebook Could Lead to Code Execution Q318138). After applying this patch, non-administrators could no longer connect to VPNs using Network and Dial-up Connections. The post-patch impact verification component (see Figure 3), showed that this recently installed patch had affected the RAS service (hosted in the selected svchost.exe), suggesting that the patch was indeed
a good candidate for the problem cause. Although we only identify the patch as a potential cause, this is a useful step in narrowing down possibilities during the troubleshooting process.
Figure 3: The Post-Patch Impact Verification component using a UI embedded within the Windows Task Manager. The depicted patch is Q318138. The RAS service is hosted in the selected svchost process with PID 804. The bottom pane displays the list of recently updated modules loaded by the selected process in the middle pane.
8.
Related Work
Work related to ours falls into two main categories: the study of patches and vulnerabilities, and the creation of dependency analysis tools. In 1996, Farmer [F96] surveyed approximately 2,200 high-profile commerce sites, and determined that nearly two thirds of the sites contained serious vulnerabilities. The percentage of unpatched systems was twice as much as that of randomly selected hosts. It is presumed that those numbers are significantly lower now, due to improvements in the patching process and increased business pressures, but the vast propagation of worms like Code Red, Blaster and Slammer suggests that unpatched systems continue to present a significant security risk.
The most thorough study of patch reliability that we are aware of was undertaken by Beatie et al [BAC03] in 2003. The authors provide a risk assessment model for applying software patches --- if a system is patched very quickly, the risk that a buggy patch will be applied is presumed to be increased; if patching is delayed, the risk of compromise is increased. The authors also surveyed common problems with patches, and the time it takes for them to be uncovered and fixed.
A large number of dependency analysis tools exist, but the one most closely related to our work is due to Sun and Couch [SC01]. Their tool, sowhat, performs global impact analysis of dynamic library dependencies in Solaris based on static analysis. The focus on static analysis means that their tool does not require an always-running process, but it also means that the tool does not capture run-time calls to dlopen() to load a library by name. Dependency Walker [DW] is a similar tool targeted at the Windows environment, and until recently it had the same limitation. Even in its latest version, it is restricted to monitoring a single application, rather than the whole system.
Less directly related to our work is the use of tracing for other systems management tasks. The use of tracing for problem determination has appeared in two previous publications [CKF+02, WVD03]. However, to the best of our knowledge, our work represents the first attempt to use tracing for patch management.
Another related research topic is the explicit specification of dependencies and the use of these specifications. Larsson et al. [LC01] argue that dependency information has traditionally been used only in the software development process, but is increasingly necessary for software deployment and management. Keller et al. [KE02] describe an approach to specifying high level dependencies using an XML-based framework. We hope that in the future, our approach of deriving dependencies through tracing will increase the usefulness of specifications by allowing them to be automatically populated.
9.
Limitations and Future Work
The limitations of our current component suite primarily relate to the use of process name as an identifier for applications, and the forms of dependency that we track. In our future work, we plan to address the first of these limitations by replacing process name with identifiers that more closely correspond to an end-user’s logical notion of an application.
Identifying an application with a process is a problem for multi-process applications, where multiple processes all comprise a single logical application. However, a second limitation is that it does not handle surrogacy; modern systems support a variety of scenarios where one application hosts another application, such as Internet Explorer running an ActiveX Control. Although a user might understand the ActiveX Control to logically comprise a distinct application, such as a payroll administration tool, the components will report dependencies of this tool as dependencies for Internet Explorer. Addressing surrogacy will be part of our work deriving better identifiers for applications.
The principal limitation of our dependency monitoring is that we do not monitor inter-process communication. For example, if a patch impacts SQL server, the components can only notify the administrator that SQL
server has been impacted; the components will fail to mention any applications that access SQL server through either local or remote procedure calls (LPC/RPC). This is also a limitation that we plan to address in future work.
10.
Conclusion
We have constructed a suite of components for analyzing patch impact. To achieve this, we made the following contributions: the formulation of a model for dependency analysis, the construction of a non-participatory self-monitoring dependency infrastructure, and the formulation of reasonable policies for patch self-management. To justify our approach, we present preliminary results showing that when testing resources are severely constrained, this approach could allow the least destabilizing security patches to be identified and deployed automatically.
By providing visibility into the patching process, we hope to enable a more self-managing patching process, and to significantly reduce the load on system administrators. Additionally, we designed our components to be easily deployable. A traditional barrier to the deployment of self-managing systems is that they require infrastructure, and this infrastructure only provides value when applications are written to take advantage of the infrastructure. We address this by building components that help system administrators perform their current responsibilities better, while also forming the infrastructure for a self-managing patching process.
In the future, we plan to extend the functionality of the components we have developed and to characterize their performance impact under a variety of deployment scenarios. We hope that these components will aid in the development of larger self-managing systems that can accommodate legacy applications.
References
[BAC03] S.Beatie, S.Arnold, C. Cowan, P. Wagle and C. Wright, “Timing the Application of Security Patches for Optimal Uptime,” in Proc. Usenix LISA, 2002
[CKF+02] M. Chen, E. Kiciman, E. Fratkin, A. Fox, and E. Brewer, “Pinpoint: Problem Determination in Large, Dynamic, Internet Services,” in Proc. Int. Conf. on
Dependable Systems and Networks (IPDS Track), 2002.
[DEB] Debian GNU/Linux, http://www.debian.org. [DLS02] M. Das, S. Lerner, and M. Seigle, “ESP: Path-Sensitive Program Verification in Polynomial Time,” in
Proc. ACM SIGPLAN Conf. on Programming Language Design and Implementation (PLDI), June 2002.
[F96] D. Farmer, “Shall We Dust Moscow? Security Survey of Key Internet Hosts and Various Semi-Relevant Reflections”, http://www.fish.com/survey.
[HD02] J. Hart and J. D’Amelia, “An Analysis of RPM Validation Drift,” in Proc. Usenix LISA, 2002.
[ITIL] ITIL Configuration Management Database, http://www.itil-itsm-world.com/itil-1.htm.
[KE02] A. Keller and C. Ensel, “An Approach for Managing Service Dependencies with XML and the Resource Description Framework,” in Journal of Network
and Systems Management, Vol. 10, No. 2, June 2002.
[LC01] M. Larsson and I. Crnkovic, “Configuration Management for Component-based Systems,” in Proc. Int.
Conf. on Software Engineering (ICSE), May 2001.
[MBSA] Microsoft Baseline Security Analyzer,
www.microsoft.com/technet/security/tools/mbsahome.mspx.
[MOF] Microsoft Operations Framework, http://www.microsoft.com/mof.
[P03] Richard Pethia, “Congressional Testimony: Attacks on the Internet in 2003”, http://usinfo.state.gov/journals/itgic/1103/ijge/gj11a.htm. [RPM97] E. Bailey, Maximum RPM, 1997.
[SC01] Y. Sun and A. L. Couch, “Global Analysis of Dynamic Library Dependencies,” in Proc. LISA, 2001.
[SLA] The Slackware Linux Project, http://www.slackware.com.
[SMS] Microsoft SMS, www.microsoft.com/smserver. [SR00] D. A. Solomon and M. Russinovich, “Inside Microsoft Windows 2000,” Microsoft Press, 3rd edition, Sep. 2000.
[Tiv] Tivoli, http://www.tivoli.com.
[WRV03] Y. M. Wang, R. Roussev, C. Verbowski, A. Johnson, and D. Ladd, “AskStrider: What Has Changed on My Machine Lately?” Microsoft Research Technical Report MSR-TR-2004-03.
[WU] Microsoft Windows Update, http://windowsupdate.microsoft.com.
[WVD03] Y. M. Wang, C. Verbowski, J. Dunagan, Y. Chen, H. J. Wang, C. Yuan, and Z. Zhang, “STRIDER: A Black-box, State-based Approach to Change and Configuration Management and Support,” in Proc. Usenix
LISA (Best Paper), pp. 159-172, Oct. 2003.
Figure 4: Screenshot of UI for Pre-Patch Impact Analysis Component. The top row of buttons is for loading application and patch manifests. The middle row of buttons allows the selection of interesting patches from the set of all manifested patches, and the launch of queries to machines running the OA but not uploading dependency information. The final row of buttons allows the execution of a pre-defined set of queries over the impact analysis result.